Command Palette
Search for a command to run...
Inferenzgeschwindigkeit Um Das 1,7-fache Erhöht, vLLM v1-Version Veröffentlicht! Der Erste Multimodale Schritt-für-Schritt-Benchmark VRC-Bench Wird Mit Über 4.000 Annotationsschritten Gestartet

Vor dem Hintergrund der stark gestiegenen Nachfrage nach Inferenz großer Modelle wurde im letzten Monat die Version v1.0 des AI-Frameworks für Inferenz großer Modelle vLLM offiziell eingeführt. Im Vergleich zu früheren Versionen wurde die Rechenleistung deutlich optimiert, das API-Design ist stabiler geworden, das Hardwarepotenzial wurde vollständig entfesselt und die Inferenzgeschwindigkeit wurde um das 1,7-fache erhöht! Es bietet stärkere Unterstützung für die effiziente Bereitstellung von Modellen mit zig Milliarden Parametern.
derzeit,Das vLLM-Einführungstutorial wurde auf der offiziellen Website von hyper.ai veröffentlicht. Es führt Sie von der Installation bis zur Bedienung, sodass Sie vLLM schnell beherrschen!
vLLM-Tutorial für den Einstieg:https://go.hyper.ai/qHl62
Weitere chinesische vLLM-Dokumente und Tutorials finden Sie unter → https://vllm.hyper.ai
Vom 5. bis 14. Februar gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 6
* Community-Artikelauswahl: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Februar: 3
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. VRC-Bench Visual Reasoning Benchmark-Datensatz
Der Datensatz deckt Herausforderungen in acht verschiedenen Bereichen ab, darunter visuelles Denken, mathematisches und logisches Denken, wissenschaftliches Denken, kulturelles und soziales Verständnis usw. Er enthält mehr als 4.000 manuell überprüfte Denkschritte, mit denen die Genauigkeit und logische Kohärenz des Modells beim mehrstufigen Denken umfassend bewertet werden kann.
Direkte Verwendung:https://go.hyper.ai/AV43N

2. Multimodaler raumzeitlicher Datensatz von Terra
Terra ist ein multimodaler raumzeitlicher Datensatz mit globaler Abdeckung, der 45 Jahre raumzeitlicher Daten aus aller Welt bereitstellt und 6,48 Millionen hochauflösende Gitterpunkte abdeckt. Sein Ziel ist es, die zukünftige Forschung im Bereich des raumzeitlichen Data Mining zu fördern und die Realisierung einer umfassenderen raumzeitlichen Intelligenz zu unterstützen.
Direkte Verwendung:https://go.hyper.ai/9eev3

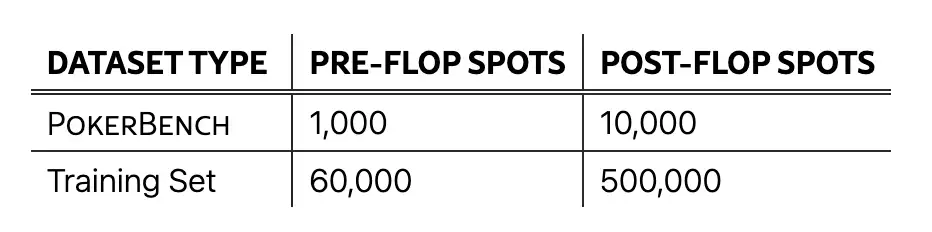
3. PokerBench-Datensatz zur Pokerspielbewertung
Der Datensatz enthält 11.000 Schlüsselszenen, aufgeteilt in 1.000 Szenen vor dem Flop und 10.000 Szenen nach dem Flop, deckt ein breites Spektrum an Spielsituationen ab und dient der Bewertung der Leistung von Large Language Models (LLMs) in komplexen, strategischen Pokerspielen.
Direkte Verwendung:https://go.hyper.ai/HK73H
Dieser Datensatz enthält Daten zu Touristenattraktionen aus 352 Städten in China. Die CSV-Datei für jede Stadt enthält 100 Standorte. Zu den Daten gehören Standortname, Website, Adresse, Vorstellung der Attraktion, Öffnungszeiten, Bild-URL, Bewertung, empfohlene Besuchsdauer, empfohlene Besuchssaison, Ticketinformationen, Tipps und andere Informationen.
Direkte Verwendung:https://go.hyper.ai/uZ5Wh
5. GF-Minecraft-Spielvideodatensatz
Dieser Datensatz sammelt 70 Stunden Spielvideos, indem er vordefinierte zufällige Aktionssequenzen ausführt und sie kommentiert. Der Datensatz ist mit 3 Biomen (Wald, Ebene, Wüste), 3 Wetterbedingungen (klar, regnerisch, Gewitter) und 6 Zeiträumen (z. B. Sonnenaufgang, Mittag, Mitternacht) vorkonfiguriert und generiert mehr als 2.000 Videoclips.
Direkte Verwendung:https://go.hyper.ai/25DAe
6. NCIFD National Culture Fine-tuning Dataset
Bei diesem Datensatz handelt es sich um einen Feinabstimmungsdatensatz für die nationale Kultur für große Modelle. Er enthält 151.159 Datenelemente und deckt sieben Hauptbereiche ab: Architektur, Kleidung, Handwerk, Ernährung, Etikette, Sprache und Bräuche.
Direkte Verwendung:https://go.hyper.ai/Vd6ZP
7. AceMath Instruct Trainingsdaten-Datensatz zum mathematischen Denken
Dieser Datensatz wurde 2025 von NVIDIA zum Trainieren des AceMath-Modells veröffentlicht, mit dem Ziel, die Leistung des Modells bei mathematischen Denkaufgaben zu verbessern.
Direkte Verwendung:https://go.hyper.ai/pT5Tr
8. ComplexFuncBench Datensatz zur Auswertung komplexer Funktionsaufrufe
Der Datensatz umfasst 1.000 Beispiele komplexer Funktionsaufrufe in 5 realen Szenarien, darunter 600 Beispiele aus einer einzelnen Domäne, jeweils 150 Beispiele für Hotels, Flüge, Mietwagen und Sehenswürdigkeiten sowie 400 Beispiele aus mehreren Domänen. Die Taxidomäne hat nur 2 Funktionen, daher wird sie nur domänenübergreifend verwendet.
Direkte Verwendung:https://go.hyper.ai/v0p4c
9. TravelPlanner Reiseplanungsdatensatz
Der Datensatz enthält 1.225 kuratierte Planungsabsichten und Referenzpläne. Der Datensatz wird im Kontext der Reiseplanung erstellt und erfordert einen Sprachagenten, der auf der Grundlage einer gegebenen Abfrage einen umfassenden Reiseplan erstellt, der Transport, tägliche Mahlzeiten, Sehenswürdigkeiten und Unterkunft umfasst.
Direkte Verwendung:https://go.hyper.ai/22AhZ
10. Daten zur Wasserlöslichkeit – Datensatz anorganischer Verbindungen
Dieser Datensatz enthält experimentelle Daten zur Wasserlöslichkeit von Hunderten anorganischer Verbindungen. Die Daten stammen aus mehreren Referenzen und sind für den Bereich der Materialinformatik geeignet. Alle Löslichkeitsdaten werden in Gramm gelösten Stoffs pro 100 Gramm Wasser ausgedrückt.
Direkte Verwendung:https://go.hyper.ai/dqL1y
Ausgewählte öffentliche Tutorials
1. vLLM-Tutorial: Eine Schritt-für-Schritt-Anleitung für Anfänger
vLLM ist ein Framework, das speziell für die Beschleunigung der Argumentation großer Sprachmodelle entwickelt wurde. Aufgrund seiner hervorragenden Argumentationseffizienz und Ressourcenoptimierungsfähigkeiten hat es weltweit große Aufmerksamkeit erregt. Die Forscher erstellten eine verteilte LLM-Service-Engine (vLLM) mit hohem Durchsatz, erreichten eine nahezu null Verschwendung von KV-Cache-Speicher und lösten das Engpassproblem bei der Speicherverwaltung im Zusammenhang mit großen Sprachmodellen.
Dieses Lernprogramm zeigt Ihnen Schritt für Schritt, wie Sie vLLM konfigurieren und ausführen, und bietet eine vollständige Anleitung von der Installation bis zum Start. Klicken Sie auf den Link unten und folgen Sie dem Tutorial zur Bereitstellung von vLLM.
Online ausführen:https://go.hyper.ai/qHl62
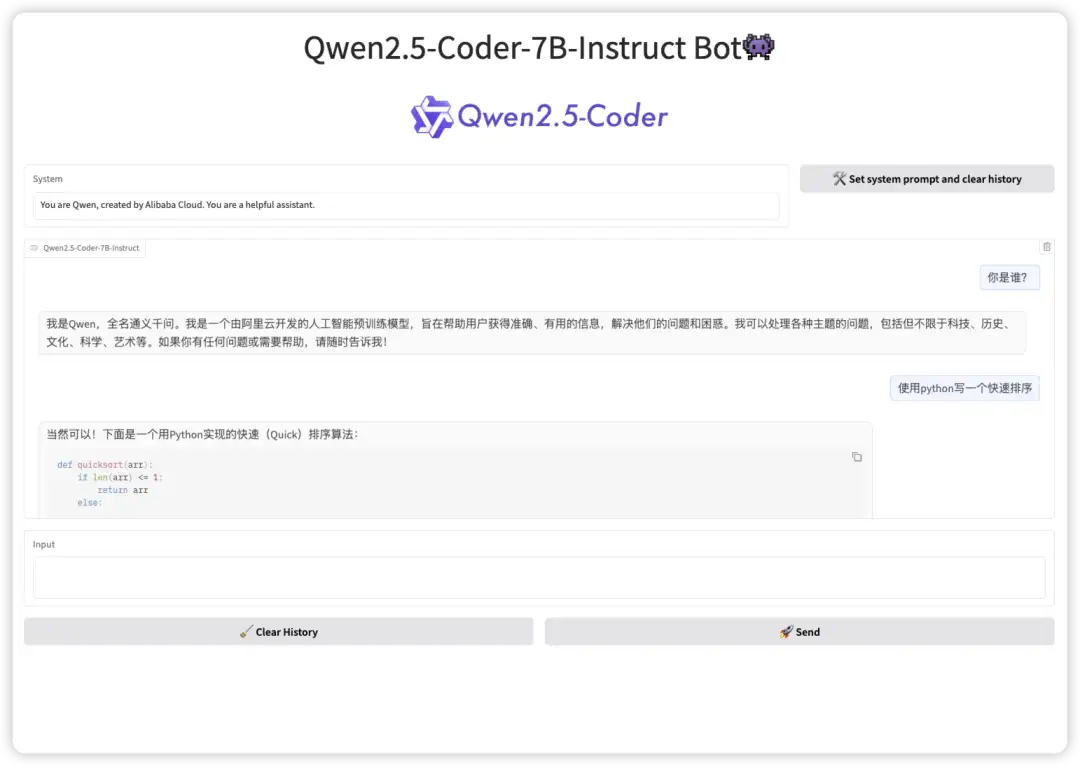
2. Ein-Klick-Bereitstellung von Qwen2.5-Coder
Qwen2.5-Coder ist ein künstlicher Intelligenzassistent mit leistungsstarken Codegenerierungsfunktionen. Es unterstützt die Codeausgabe mit klarer Logik und standardisierter Syntax und bietet eine Artefaktfunktion, mit der Benutzer schnell verschiedene visuelle Projekte erstellen und implementieren können. In Bezug auf die Entwicklung von Minispielen kann Qwen2.5-Coder Spielcode basierend auf Spielregeln, Grafikstil und Anforderungen an die Benutzererfahrung generieren. Auf dieser Basis können Entwickler es individuell anpassen, optimieren und schnell eigene Spielewerke auf den Markt bringen.
Dieses Projekt kann über die Gradio-Schnittstelle eine interaktive Front-End-Schnittstelle generieren. Die relevanten Modelle und Abhängigkeiten wurden bereitgestellt. Sie können dem Modell Anweisungen geben und den erforderlichen Code mit einem Klick generieren.
Online ausführen:https://go.hyper.ai/JVOTN
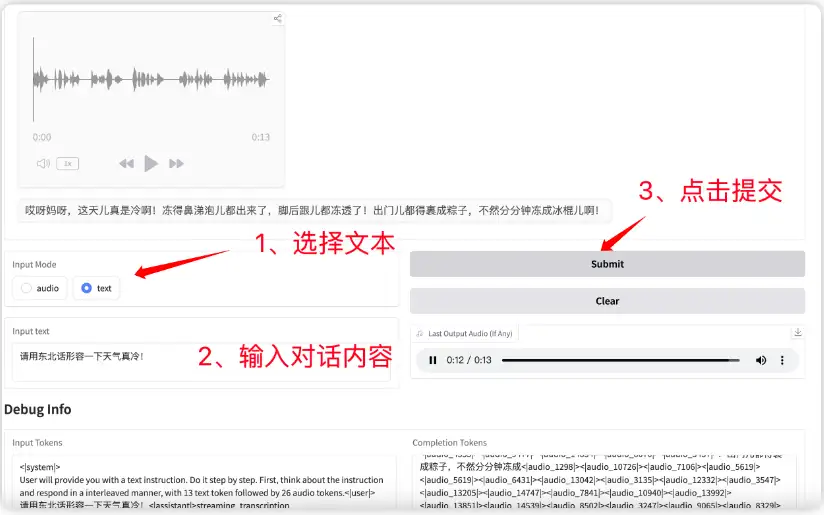
3. GLM-4-Voice End-to-End-Konversationsmodell Chinesisch-Englisch
GLM-4-Voice ist ein End-to-End-Sprachmodell, das chinesische und englische Sprache direkt verstehen und generieren, Sprachgespräche in Echtzeit führen und Benutzeranweisungen befolgen kann, um Sprachattribute wie Emotionen, Intonation, Sprechgeschwindigkeit und Dialekt zu ändern.
Gehen Sie zur offiziellen Website, um den Container zu klonen und zu starten, kopieren Sie die API-Adresse direkt und Sie können mit dem Modell kommunizieren.
Online ausführen:https://go.hyper.ai/s4MId
4. Linly-Dubbing Video-Download mit einem Klick + Übersetzung + Synchronisation + Untertitel
Linly-Dubbing ist ein intelligentes, mehrsprachiges KI-Synchronisations- und Übersetzungstool für Videos, das Videoinhalte automatisch in mehrere Sprachen übersetzen und Untertitel generieren kann.
Klicken Sie auf den Link unten, um Ihre kreative Reise sofort zu beginnen und die mehrsprachige KI-Synchronisierung und Übersetzung von Videos zu realisieren.
Online ausführen:https://go.hyper.ai/xEAzn
5. DrawingSpinUp: 2D-Charakterzeichnung → 3D-Animation
DrawingSpinUp ist eine innovative Technologie zur Generierung von 3D-Animationen, die flache Charakterzeichnungen in dynamische Animationen mit 3D-Effekten umwandelt und dabei den Stil und die Eigenschaften des Originalkunstwerks sorgfältig bewahrt.
Befolgen Sie die Schritte des Tutorials, um realistische und detaillierte 3D-Animationen zu erstellen.
Online ausführen:https://go.hyper.ai/H9fV1
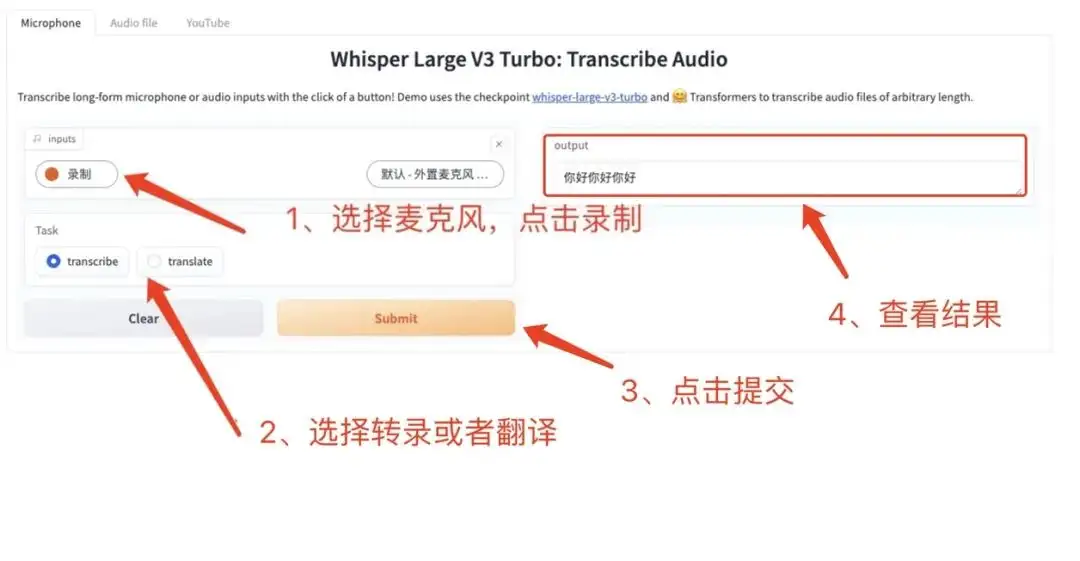
6. Whisper-large-v3-turbo Spracherkennungs- und Übersetzungsdemo
Whisper ist ein universelles Spracherkennungsmodell. Es wird anhand eines großen und vielfältigen Audiodatensatzes trainiert und kann mehrere Aufgaben ausführen, beispielsweise mehrsprachige Spracherkennung und Sprachübersetzung.
Dieses Tutorial ist ein Ein-Klick-Bereitstellungstutorial für Whisper-Large-V3-Turbo. Es ist 8-mal schneller als Whisper-Large-V3 und das fast ohne Qualitätsverlust. Die entsprechende Umgebung und die Abhängigkeiten wurden installiert und Sie können sie erleben, indem Sie sie klonen und mit einem Klick starten.
Online ausführen:https://go.hyper.ai/3P9nk
Community-Artikel
Das KI-Biopharmaunternehmen Generate: Biomedicines integriert mit seiner einzigartigen programmierbaren Biologieplattform nicht nur künstliche Intelligenz tief in die Proteintechnik, sondern hilft Wissenschaftlern auch dabei, effizientere Lösungen für traditionell schwer medikamentös behandelbare Zielmoleküle zu entwickeln. Vor Kurzem gab Generate bekannt, dass es eine strategische Investition vom Samsung Science & Life Science Fund erhalten hat. Die Bedeutung dahinter liegt auf der Hand. Dieser Artikel ist ein ausführlicher Bericht über das Unternehmen. Klicken Sie hier, um ihn schnell zu lesen.
Ereigniszusammenfassung anzeigen:https://go.hyper.ai/fVtKK
In den letzten Jahren wurde die KI im Bereich der Erforschung der alten chinesischen Literatur immer stärker eingesetzt. Im Juni 2024 schlug die Anyang Normal University in Zusammenarbeit mit der Huazhong University of Science and Technology, der South China University of Technology usw. ein bedingtes Diffusionsmodell vor, das für die Entschlüsselung von Orakelknochen optimiert ist. Die Ergebnisse wurden nicht nur für ACL 2024 ausgewählt, sondern gewannen auch erfolgreich den Preis für das beste Papier. Dies zeigt, dass KI die Arbeitseffizienz von Forschern steigert. Weitere Einzelheiten zur Interpretation von Orakelknochen durch KI finden Sie im Folgenden.
Den vollständigen Bericht ansehen:https://go.hyper.ai/xzw4c
Die rasante Entwicklung der medizinischen künstlichen Intelligenz ist untrennbar mit der Unterstützung hochwertiger Datensätze verbunden. Von der Krankheitsdiagnose über die Arzneimittelentwicklung bis hin zur personalisierten Medizin spielen Datensätze eine unverzichtbare Rolle bei der Förderung der Anwendung von maschinellem Sehen, großen Modellen usw. im medizinischen Bereich. Dieser Artikel organisiert 10 Datensätze im medizinischen Bereich und behandelt die chinesische Medizin von Shennong, alte Bücher zur chinesischen Medizin, medizinisches Denken, medizinische Fragen und Antworten usw. Sie können direkt zum Herunterladen klicken.
Den vollständigen Bericht ansehen:https://go.hyper.ai/NHlJ0
Die rasante Entwicklung der künstlichen Intelligenz hat der Arzneimittelforschung neue Möglichkeiten eröffnet. Kürzlich haben Forscher des Biowissenschaftsunternehmens Cellarity und NVIDIA gemeinsam eine neuartige Methode zur gezielten Moleküloptimierung auf Basis des latenten Verstärkungslernens (MOLRL) vorgeschlagen, die bei Aufgaben im Zusammenhang mit der Arzneimittelentdeckung, insbesondere bei der gezielten Molekülerzeugung und der Multiparameteroptimierung, eine überragende Leistung zeigte. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/YBhnM
In der sechsten Folge der Live-Übertragungsreihe „Meet AI4S“ teilte Professor Zheng Wei, Professor an der School of Statistics and Data Science der Nankai University, allen die Einschränkungen von AlphaFold und zukünftige Optimierungsrichtungen mit und erklärte, welche Algorithmen und Forschungsthemen in der akademischen Gemeinschaft einer Erforschung wert sind. Weitere Einzelheiten finden Sie weiter unten.
Den vollständigen Bericht ansehen:https://go.hyper.ai/YgCip
Beliebte Enzyklopädieartikel
1. Reziproke Sortierfusion RRF
2. Modellparameter
3. Kolmogorov-Arnold-Darstellungssatz
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








