Command Palette
Search for a command to run...
Open-Source-allgemeines Medizinisches Sprachmodell Mit 176 Milliarden Parametern! BUPT/PKU/China Three Gorges University Schlug MedFound Vor, Dessen Denkfähigkeit Der Von Fachärzten Nahe Kommt

Ein altes Sprichwort sagt: „Irren ist menschlich“, doch im medizinischen Bereich kann ein Fehler wie eine Fehldiagnose verheerende Folgen haben. Einerseits besteht für die Patienten im schlimmsten Fall ein Fehlalarm, andererseits besteht im schlimmsten Fall eine Verzögerung bei der Behandlung der Krankheit. In beiden Fällen erleidet der Patient psychische Schäden, Sachschäden und sogar Lebensschäden. Andererseits können Fehlurteile bei Ärzten das Image des Arztes als Lebensretter schädigen und sogar die Glaubwürdigkeit des gesamten medizinischen Systems beeinträchtigen. Entgegen den Erwartungen kommt es jedoch im In- und Ausland immer noch häufig zu Fehldiagnosen.
Chen Xiaohong, ehemaliger Chefredakteur der Zeitschrift „Clinical Misdiagnosis and Mistreatment“ und einer der Autoren der medizinischen Monographie „Misdiagnosis“, erwähnte in einem Interview, dass die in der in- und ausländischen Literatur in Stichprobengrößen angegebenen Fehldiagnoseraten im Allgemeinen bei etwa 20% bis 40% liegen. Darüber hinaus enthält sein Buch „Misdiagnosis“ entsprechende Statistiken. Beispielsweise wird darin erwähnt, dass in 200 Diskussionsdaten zur klinischen Pathologie, die von mehreren repräsentativen inländischen medizinischen Fachzeitschriften zwischen 1973 und 1980 veröffentlicht wurden, die Fehldiagnoserate bei 48 % lag. Man kann sagen, dass Fehldiagnosen mittlerweile zu einem der größten Hindernisse für den Fortschritt der Humanmedizin geworden sind.
Um das Problem der Fehldiagnosen zu lösen, versuchten in der Antike medizinische Werke wie „Krankenberichte über die Kombination chinesischer und westlicher Medizin“, „Medizinische Fehler“ und „Medizinische Korrekturen“ ihr Bestes, die Lehren aus Fehldiagnosen in die Krankenakten aufzunehmen, um zukünftige Generationen zu warnen. In der heutigen Zeit sind die Mittel zur klinischen Diagnose mithilfe moderner medizinischer Methoden wie B-Ultraschall, CT und MRT immer umfangreicher und ausgefeilter geworden. Allerdings kann die Medizin als praktische Wissenschaft und forschende Disziplin Fehldiagnosen nie völlig vermeiden. Daher können wir den Weg für die Weiterentwicklung der Medizin nur ebnen, wenn wir die Zahl der Fehldiagnosen weiter senken und die Genauigkeit und Zugänglichkeit der Krankheitsdiagnose verbessern.
Indem es KI für die Wissenschaft als neues Paradigma betrachtet, liefert es neue Ideen zur Lösung der oben genannten Probleme. Vor ein paar TagenEin interdisziplinäres Team aus Medizintechnikern, bestehend aus Professor Wang Guangyu von der Beijing University of Posts and Telecommunications, Professor Song Chunli vom Peking University Third Hospital und Professor Yang Jian von der China Three Gorges University, hat MedFound (176B) eingeführt und verifiziert, das biomedizinische Sprachmodell mit der größten Anzahl von Parametern.Darüber hinaus haben wir MedFound-DX-PA entwickelt, ein umfassendes Sprachmodell für die allgemeine medizinische Diagnose, das über Kenntnisse und Denkfähigkeiten verfügt, die denen von Experten nahe kommen, und in verschiedenen medizinischen Szenarien eine effiziente und genaue Diagnoseunterstützung bieten kann.
Die entsprechenden Ergebnisse wurden in Nature Medicine unter dem Titel „A generalist medical language model for disease diagnosis assistance“ veröffentlicht.

Papieradresse:
https://www.nature.com/articles/s41591-024-03416-6
Folgen Sie dem offiziellen Konto und antworten Sie mit „MedFound“, um das vollständige PDF zu erhalten
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 200 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Was ist die Innovation von MedFound?
Das größte Open-Source-Biomedizin-Sprachmodell mit der größten Anzahl von Parametern
Das Forschungsteam erklärte, dass der Mangel an gut konzipierten, öffentlich verfügbaren LLMs, die speziell auf den klinischen Alltag zugeschnitten sind, der Hauptgrund dafür sei, dass LLMs in der biomedizinischen Anwendung noch in den Kinderschuhen stecken. MedFound ist auf der Grundlage des allgemeinen domänenübergreifenden Großsprachenmodells BLOOM-176B vortrainiert, einem allgemeinen medizinischen Großsprachenmodell mit einer Parameterskala von 176 Milliarden.
Um sicherzustellen, dass das Modell umfassendes allgemeines medizinisches Wissen erwerben kann, hat das Forschungsteam speziell einen medizinischen Korpusdatensatz namens MedCorpus erstellt, der umfangreiches medizinisches Wissen und klinische Praxis integriert. Es besteht aus insgesamt 6,3 Milliarden Texttoken aus 4 Datensätzen, darunter MedText, PubMed Central Case Report (PMC-CR), MIMIC-III-Note und MedDX-Note. Diese Datensätze umfassen chinesische und englische medizinische Literatur, Fachbücher und 8,7 Millionen echte elektronische Patientenakten, die eine wichtige Grundlage für die Anwendbarkeit des Modells auf die Diagnose in verschiedenen Disziplinen bilden.
Es ist erwähnenswert, dass MedFound laut dem Forschungsteam nun Open Source ist und Forschern, Klinikern und medizinischen Einrichtungen auf der ganzen Welt grundlegende Dienste für große Modelle bereitstellen kann.
Projektadresse:
https://github.com/medfound/medfound?tab=readme-ov-file
Innovative klinisch-diagnostische Argumentationsfähigkeiten machen ihn zu einem „lebenden Arzt“
Ein wichtiger Unterschied zwischen Maschinen und Menschen besteht zudem darin, dass menschliche Ärzte aufgrund ihrer eigenen Erfahrungen und Wissensreserven sinnvolle Rückschlüsse auf den wahren Zustand des Patienten ziehen und so eine differenzierte Behandlung ermöglichen können. Das Forschungsteam stellte fest, dass einige aktuelle Studien lediglich klinisches Wissen in LLM für medizinische Fragen und Antworten oder Gespräche einbeziehen, aber nicht die Fähigkeit zur klinisch-diagnostischen Argumentation widerspiegeln.
Beispielsweise veröffentlichten Sainan Zhang und Jisung Song ein Ergebnis in Nature, in dem sie eine Konversationsschnittstelle namens Chat Ella entwickelten, die auf Transferlernen und Feinabstimmung von GPT-2 basiert. Das System kann chronische Krankheiten anhand der vom Benutzer beschriebenen Symptome genau vorhersagen. Am Ende der Arbeit erwähnten die Forscher jedoch auch die Mängel der Studie und wiesen auf einige Einschränkungen der Ergebnisse im Denkprozess hin, beispielsweise die Unfähigkeit, den Denkprozess zu erklären. Der Titel des Artikels lautet „Ein auf Chatbots basierendes Frage- und Antwortsystem für die Hilfsdiagnose chronischer Krankheiten auf der Grundlage eines großen Sprachmodells“.
Papieradresse:
https://www.nature.com/articles/s41598-024-67429-4
Um eine rigorose Krankheitsdiagnose zu erreichen, reicht es daher nicht aus, dass das große Modell über umfassende interdisziplinäre medizinische Kenntnisse verfügt, sondern es muss auch in der Lage sein, komplexe Schlussfolgerungen zu ziehen.Basierend auf dem MedFound-Modell hat das Forschungsteam durch zweistufige Trainingsoptimierung außerdem MedFound-DX entwickelt, ein großes Sprachmodell für die allgemeine medizinische Diagnose mit Kenntnissen und Denkfähigkeiten, die denen von Experten nahe kommen.Wie in der folgenden Abbildung dargestellt:
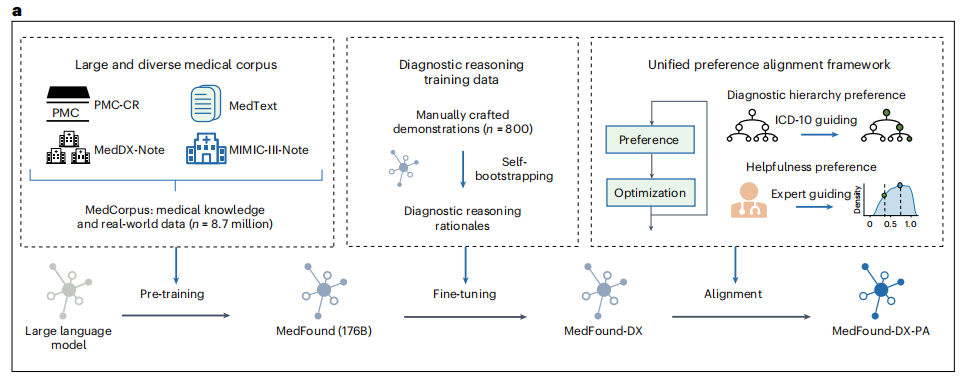
Konkret verwendete das Forschungsteam in der ersten Phase die Chain of Thought (CoT)-Methode, die auf selbstgesteuerten Strategien basiert, um dem großen Modell zu ermöglichen, automatisch Diagnosegrundlagen und Denkprozesse wie bei medizinischen Experten zu generieren. Allerdings können generative LLMs „Halluzinationen“ hervorrufen oder falsche Tatsachen erfinden, und wenn diese Diagnosen übernommen werden, können die Folgen verheerend sein.
Daher führte das Forschungsteam in der zweiten Phase auch einen einheitlichen Rahmen für die Präferenzausrichtung ein, um LLM an das Wissenssystem der Berufsfelder und die klinischen Diagnosepräferenzen anzupassen und sicherzustellen, dass das Modell bei der Diagnosestellung nicht nur wissenschaftlich und vernünftig ist, sondern auch mit der Logik und den Werten medizinischer Experten in der klinischen Praxis übereinstimmt. Das Framework integriert „Diagnostic Preference Hierarchy“ und „Helpfulness Preference“, die beide den Direct Preference Optimization (DPO)-Algorithmus verwenden – einen einfachen Algorithmus, der kein Reinforcement Learning erfordert. Einerseits kann es das Modell dahingehend leiten, die Genauigkeit der Krankheitsidentifizierung im Detail zu verbessern, und andererseits kann es auch die Wirksamkeit und Glaubwürdigkeit der Modellbegründung verbessern und das Risiko irreführender und falscher Informationen verringern.
Es ist erwähnenswert, dass das Forschungsteam bei der Feinabstimmung und Ausrichtung dieses Teils auch speziell einen Datensatz namens MedDX-FT erstellt hat, der Demonstrationen von Denkprozessen enthält, die von Ärzten manuell auf der Grundlage echter Krankenakten zum Training und zur Feinabstimmung geschrieben wurden. Der Datensatz besteht aus einem Seed-Set basierend auf manuellen Demonstrationen und 109.364 EHR-Notizen.
Erstaunliche Demonstrationsergebnisse zeigen seine potenziellen Anwendungsmöglichkeiten
Während der Evaluierungsphase erstellte das Forschungsteam auch einen Datensatz MedDX-Bench, der drei klinische Datensätze enthält: MedDX-Test, MedDX-OOD und MedDX-Rare.
* Der MedDX-Test-Datensatz wird zur Bewertung der diagnostischen Leistung von MedFound-DX-PA in verschiedenen Bereichen verwendet und enthält 11.662 medizinische Aufzeichnungen mit der gleichen Verteilung wie der Trainingsdatensatz.
* MedDX-OOD und MedDX-Rare sind externe Validierungssätze. Ersterer enthält 23.917 Datensätze häufiger Krankheiten und letzterer 20.257 Datensätze zu 2.105 seltenen Krankheiten, die eine Long-Tail-Verteilung aufweisen.
Das Evaluierungsexperiment besteht im Wesentlichen aus drei Phasen, nämlich der In-Distribution-Evaluierung (ID), der Out-of-Distribution-Evaluierung (OOD) und der Long-Tail-Evaluierung der Krankheitsverteilung. Zu den Vergleichsobjekten zählen führende Open-Source- und Closed-Source-LLMs wie MEDITRON-70B, Clinical Camel-70B, Llama 3-70B und GPT-4o.
Die Ergebnisse zeigen, dass seine Leistung besser ist als die anderer führender LLMs.Beispielsweise beträgt bei der Diagnoseleistung häufiger Krankheiten die durchschnittliche Top-3-Genauigkeit von MedFound-DX-PA 84,2% (unter ID-Einstellung), im Vergleich dazu beträgt die Diagnosegenauigkeit von GPT-4o nur 62%; Bei der Diagnoseleistung bei seltenen Krankheiten beträgt die durchschnittliche Top-3-Genauigkeit von MedFound-DX-PA in 8 Fachgebieten 80,7%, und GPT-4o belegt mit durchschnittlich 59,1% den zweiten Platz.
Es ist erwähnenswert, dass beim Vergleich zwischen MedFound-DX-PA und Endokrinologen und Pulmonologen die diagnostischen Genauigkeitsraten 74,7% bzw. 72,6% betrugen, was viel höher war als bei Ärzten mit weniger bzw. mittlerer Berufserfahrung und vergleichbar mit denen von Ärzten mit mehr Berufserfahrung. Im Hinblick auf die Zusatzdiagnose kann es den Ärzten dieser beiden Abteilungen helfen, die diagnostische Genauigkeit von 11,9% bzw. 4,4% zu verbessern. Die folgende Abbildung ist ein intuitiver Modelldiagnosefall.
Wie in der Abbildung unten dargestellt, lautete die Erstdiagnose des Arztes „akute Bronchitis“. Das MedFound-Modell hob die Vorgeschichte wiederkehrender Bronchitis des Patienten hervor. Aufgrund der Hinweise des Modells korrigierte der Arzt die Diagnose in eine akute Verschlimmerung einer chronischen Bronchitis.

Wie in der Abbildung unten dargestellt, diagnostizierte der Arzt bei dem Patienten zunächst eine subklinische Hypothyreose. Das MedFound-Modell deutete auf die Möglichkeit einer zugrunde liegenden Autoimmun-Schilddrüsenerkrankung hin und der Arzt korrigierte das Ergebnis zu Autoimmun-Thyreoiditis.

Es ist ersichtlich, dass MedFound nicht nur das Potenzial hat, die diagnostische Effizienz und Genauigkeit zu verbessern, sondern auch das Potenzial hat, ein diagnostischer Assistent für klinisches Personal zu werden.Dies stellt eine starke Unterstützung für die zukünftige Entwicklung intelligenter klinischer Diagnose und Behandlung sowie personalisierter Medizin dar.
AI4S macht weiterhin Fortschritte und die Ära der Implementierung ist angebrochen
Wang Guangyu's Team macht weiter Fortschritte
Bei dieser gemeinsamen Anstrengung hat jedes Team sein Bestes gegeben und mit seinem Fachwissen zu diesem Erfolg beigetragen. Es ist erwähnenswert, dass Professor Wang Guangyu von der Beijing University of Posts and Telecommunications einer der korrespondierenden Autoren dieser Studie ist.
Tatsächlich ist dies nicht das erste Mal, dass das Team von Professor Wang Guangyu KI in die Biomedizin integriert.Als erster Gewinner des Science Exploration Award nach den 90er Jahren ist Wang Guangyu seit langem berühmt und hat eine Reihe international führender akademischer Leistungen veröffentlicht.Seine Arbeiten wurden in führenden internationalen Fachzeitschriften wie Cell, Nature Medicine und Nature Biomedical Engineering veröffentlicht.

So veröffentlichte beispielsweise Professor Wang Guangyu im Jahr 2020 als erster korrespondierender Autor eine Studie mit dem Titel „Klinisch anwendbares KI-System zur genauen Diagnose und Prognose einer COVID-19-Pneumonie mittels Computertomographie“ in der renommierten internationalen Fachzeitschrift Cell. Die Studie konzentrierte sich auf die damals grassierende COVID-19-Pneumonie und verwendete insgesamt mehr als 530.000 CT-Bilder, um ein KI-Diagnosemodell auf Grundlage der Läsionssegmentierung mit einer diagnostischen Genauigkeitsrate von bis zu 92,49% zu erstellen.
Papieradresse:
https://www.cell.com/pb-assets/products/coronavirus/CELL_CELL-D-20-00656.pdf

Im Jahr 2023 veröffentlichte das Team von Wang Guangyu erneut zwei Forschungsarbeiten in Nature Medicine. In einem Artikel mit dem Titel „Deep-Learning-fähige Protein-Protein-Interaktionsanalyse zur Vorhersage der Infektiosität und Variantenentwicklung von SARS-CoV-2“ wurde ein künstliches Intelligenz-Framework namens UniBild vorgeschlagen, das die Auswirkungen von SARS-CoV-2-Spike-Protein-Varianten auf den Menschen effektiv und skalierbar vorhersagen kann.
Papieradresse:
https://www.nature.com/articles/s41591-023-02483-5

In einem weiteren Artikel mit dem Titel „Optimierte Glykämiekontrolle bei Typ-2-Diabetes durch bestärkendes Lernen: ein Proof-of-Concept-Versuch“ wird ein modellbasiertes bestärkendes Lernframework RL-DITR vorgeschlagen, das ein Patientenmodell zur Verfolgung des individuellen Blutzuckerstatus und ein Richtlinienmodell zur mehrstufigen Planung der Langzeitpflege umfasst, das Ärzten und Patienten dabei helfen kann, dynamische und flexible Insulinbehandlungspläne festzulegen.
Papieradresse:
https://www.nature.com/articles/s41591-023-02552-9
Wang Guangyu sagte: „Wir haben diesbezüglich Erwartungen. Ich persönlich hoffe, leistungsfähigere KI-Methoden entwickeln und sie zur Lösung vieler wichtiger biomedizinischer Probleme einsetzen zu können, beispielsweise zur Bekämpfung plötzlich auftretender Epidemien oder von Krebs.“
Die Integration von KI und Biomedizin beschleunigt sich
Tatsächlich steht die Integration von KI und Biomedizin schon seit langem im Fokus großer Labore. Aufgrund der Besonderheiten des medizinischen Bereichs bestehen für die KI größere Möglichkeiten, in diesem Bereich eine Rolle zu spielen, und mehr Teams sind bereit, tiefer in diesen Bereich einzudringen.
So entwickelte beispielsweise ein Team der Chinesischen Universität Hongkong im Jahr 2024 ein virtuelles Arztsystem mit mehreren Konsultationsrunden auf LLM-Basis namens DrHouse, das mithilfe intelligenter Geräte die Genauigkeit und Zuverlässigkeit von Diagnosen verbessern kann und gleichzeitig durch eine ständig aktualisierte medizinische Wissensbasis und fortschrittliche Diagnosealgorithmen eine extrem lange Lebensdauer hat und intelligente und zuverlässige medizinische Beurteilungen liefert. Das zugehörige Dokument trägt den Titel „DrHouse: Ein LLM-gestütztes diagnostisches Schlussfolgerungssystem durch Nutzung von Ergebnissen aus Sensordaten und Expertenwissen“.
Papieradresse:
https://arxiv.org/abs/2405.12541
Darüber hinaus veröffentlichte das Team von Wang Yanfeng und Xie Weidi von der Shanghai Jiaotong University im Jahr 2024 entsprechende Ergebnisse. In der Studie wurde erwähnt, dass das Team ein mehrsprachiges medizinisches Korpus – MMedC – erstellt hat, das etwa 25,5 Milliarden Token enthält und sechs Hauptsprachen abdeckt. Gleichzeitig wurde auch ein mehrsprachiger Benchmark für medizinische Multiple-Choice-Fragen vorgeschlagen – MMedBench. Das endgültige Modell des Forschungsteams, MMed-Llama 3, verfügt zwar nur über 8 Milliarden Parameter, weist aber bei MMedBench und englischen Benchmarks eine mit GPT-4 vergleichbare Leistung auf.
Man kann erkennen, dass sich der Sturm der Integration von KI und Biomedizin verschärft hat. Mit ihrer enormen Rechenleistung, neuartigen Algorithmen und der Fähigkeit, große Datenmengen leichter zu verarbeiten, macht KI die traditionelle wissenschaftliche Forschung effizienter und intelligenter. Noch spannender ist, dass diese schrittweise fortschreitenden Ergebnisse letztendlich dazu führen werden, dass die Anwendung schneller auf den Markt kommt. Eine Ära, in der die Umsetzung das Wichtigste ist, scheint still und leise angebrochen zu sein.
Quellen:
1.https://mp.weixin.qq.com/s/9mhp6luTzQeNhqpEKw9CWQ
2.https://mp.weixin.qq.com/s/WlamJ7N9YKrOJljvEvE9cA
3.https://mp.weixin.qq.com/s/r-S9qkVU645K-ZdaLGYhBA
4.https://mp.weixin.qq.com/s/BfByFCWC9VN6iABnPq1iDw









