Command Palette
Search for a command to run...
Online-Tutorials | Die YOLO-Serie Wurde in 10 Jahren Um 11 Versionen Aktualisiert, Und Das Neueste Modell Hat Bei Mehreren Zielerkennungsaufgaben SOTA Erreicht
YOLO (You Only Look Once) ist einer der einflussreichsten Echtzeit-Objekterkennungsalgorithmen im Bereich der Computer Vision.Es wird von der Industrie aufgrund seiner hohen Präzision und Effizienz bevorzugt und findet breite Anwendung beim autonomen Fahren, der Sicherheitsüberwachung, der medizinischen Bildgebung und in anderen Bereichen.
Das Modell wurde erstmals 2015 von Joseph Redmon, einem Doktoranden der University of Washington, veröffentlicht. Es war Vorreiter bei der Behandlung der Objekterkennung als einzelnes Regressionsproblem, ermöglichte eine durchgängige Objekterkennung und erlangte schnell breite Anerkennung unter Entwicklern. Anschließend brachten Teams, darunter Alexey Bochkovskiy, Glenn Jocher (Ultralytics-Team) und die Abteilung für visuelle Intelligenz von Meituan, mehrere wichtige Versionen heraus.
Mittlerweile hat die Zahl der Stars der Modelle der YOLO-Serie auf GitHub Hunderttausende erreicht, was ihren Einfluss auf dem Gebiet der Computervision verdeutlicht.

Die Modellreihe YOLO zeichnet sich durch ihre einstufige Erkennungsarchitektur aus, die keine komplexe Generierung von Kandidatenboxen für Regionen erfordert und die Zielerkennung in einer einzigen Vorwärtsausbreitung abschließen kann, wodurch die Erkennungsgeschwindigkeit erheblich verbessert wird. Im Vergleich zu herkömmlichen zweistufigen Detektoren (wie Faster R-CNN)YOLO verfügt über eine schnellere Inferenzgeschwindigkeit, kann die Echtzeitverarbeitung von Bildern mit hoher Bildrate realisieren und optimiert die Hardwareanpassungsfähigkeit,Wird häufig in eingebetteten Geräten und Edge-Computing-Szenarien verwendet.
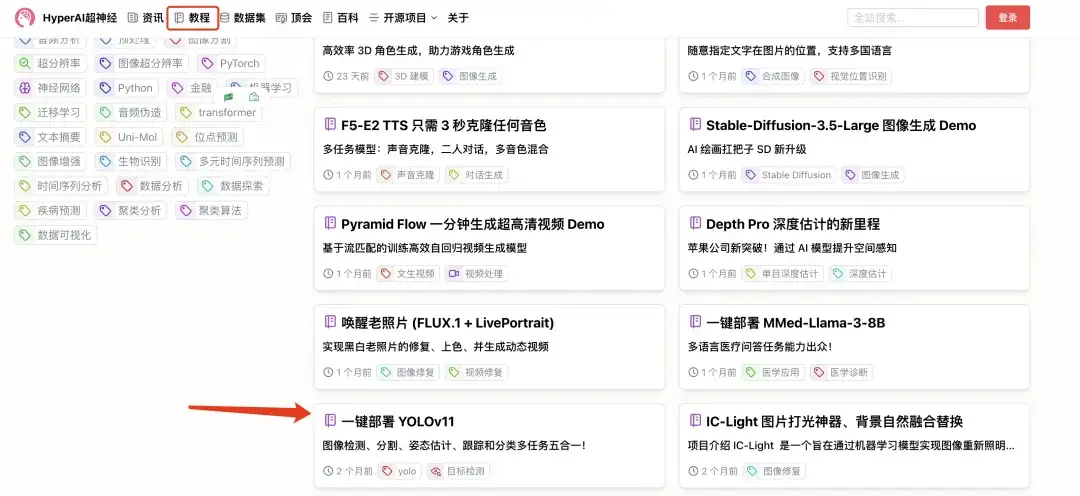
derzeit,Im Abschnitt „Tutorial“ der offiziellen Website von HyperAI wurden mehrere Versionen der YOLO-Serie veröffentlicht, die mit einem Klick bereitgestellt und ausprobiert werden können~
Am Ende dieses Artikels verwenden wir die neueste Version von YOLOv11 als Beispiel, um das Tutorial zur Bereitstellung mit einem Klick zu erläutern.
1. YOLOv2
Veröffentlichungszeit:2017
Wichtiges Update:Es wurden Ankerboxen vorgeschlagen und Darknet-19 wurde als Backbone-Netzwerk verwendet, um Geschwindigkeit und Genauigkeit zu verbessern.
Kompilieren Sie YOLO-V2 im DarkNet-Modell mit TVM:
2. YOLOv3
Veröffentlichungszeit:2018
Wichtiges Update:Durch die Verwendung von Darknet-53 als Backbone-Netzwerk wird die Genauigkeit bei gleichzeitiger Beibehaltung der Echtzeitgeschwindigkeit erheblich verbessert. Außerdem wird eine mehrskalige Vorhersage (FPN-Struktur) vorgeschlagen, die zu erheblichen Verbesserungen bei der Erkennung von Objekten unterschiedlicher Größe und der Verarbeitung komplexer Bilder führt.
Kompilieren Sie YOLO-V3 im DarkNet-Modell mit TVM:
3 , YOLOv5
Veröffentlichungszeit:2020
Wichtiges Update:Durch die Einführung eines automatischen Ankerrahmen-Anpassungsmechanismus bleiben die Echtzeit-Erkennungsfunktionen erhalten und die Genauigkeit verbessert. Um das Training und die Bereitstellung zu vereinfachen, wird eine leichtere PyTorch-Implementierung verwendet.
Bereitstellung mit einem Klick:https://go.hyper.ai/jxqfm
4 , YOLOv7
Veröffentlichungszeit:2022
Wichtiges Update:Basierend auf dem Expanded Efficient Layer Aggregation Network werden die Parameternutzung und die Rechenleistung verbessert, wodurch eine bessere Leistung mit weniger Rechenressourcen erreicht wird. Zusätzliche Aufgaben wie die Posenschätzung im COCO-Keypoint-Datensatz hinzugefügt.
Bereitstellung mit einem Klick:https://go.hyper.ai/d1Ooq
5 , YOLOv8
Veröffentlichungszeit:2023
Wichtiges Update:
Es verwendet ein neues Backbone-Netzwerk und führt einen neuen ankerfreien Erkennungskopf und eine neue Verlustfunktion ein, die frühere Versionen hinsichtlich durchschnittlicher Genauigkeit, Größe und Latenz übertrifft.
Bereitstellung mit einem Klick:https://go.hyper.ai/Cxcnj
6 , YOLOv10
Veröffentlichungszeit:Mai 2024
Wichtiges Update:Eliminiert die Anforderung der Non-Maximum Suppression (NMS) und reduziert so die Inferenzlatenz. Durch die Einbindung großer Kernel-Convolution- und partieller Self-Attention-Module lässt sich die Leistung verbessern, ohne den Rechenaufwand wesentlich zu erhöhen. Verschiedene Komponenten wurden vollständig optimiert, um Effizienz und Genauigkeit zu verbessern.
Bereitstellung der YOLOv10-Zielerkennung mit einem Klick:
Bereitstellung der YOLOv10-Objekterkennung mit einem Klick:
7 , YOLOv11
Veröffentlichungszeit:September 2024
Wichtiges Update:Es bietet modernste (SOTA) Leistung bei mehreren Aufgaben, darunter Erkennung, Segmentierung, Posenabschätzung, Verfolgung und Klassifizierung, und nutzt Funktionen aus einer breiten Palette von KI-Anwendungen und -Domänen.
Bereitstellung mit einem Klick:https://go.hyper.ai/Nztnq
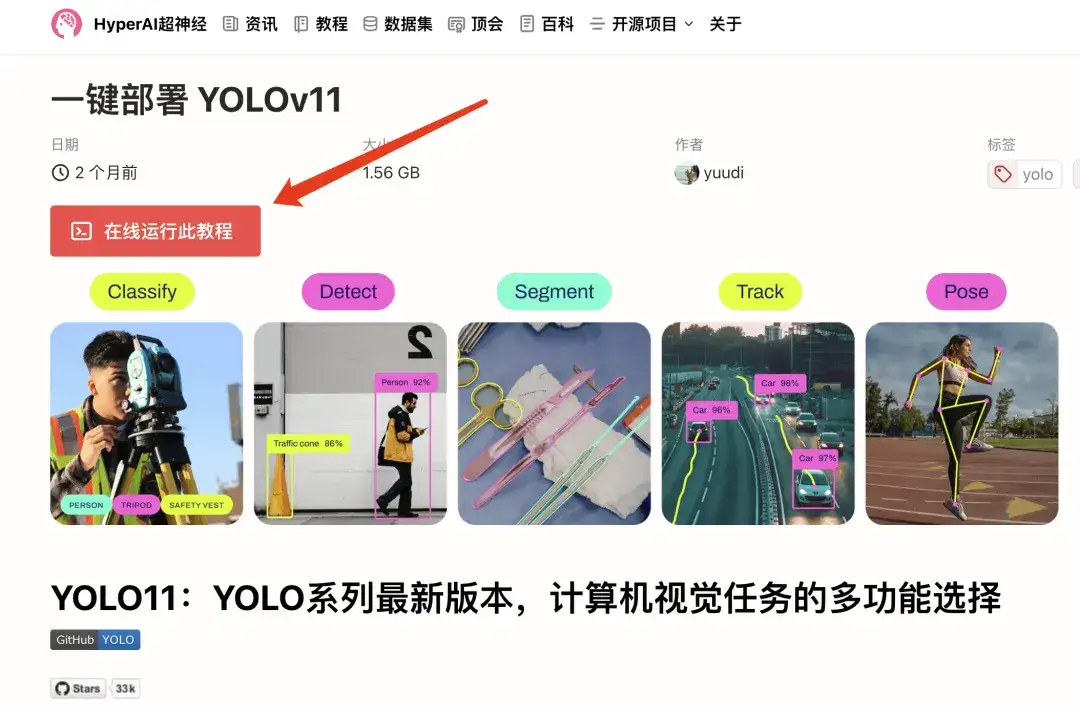
YOLOv11-Tutorial zur Ein-Klick-Bereitstellung
Im Abschnitt „HyperAI HyperNeural-Tutorial“ wurde jetzt „One-Click-Bereitstellung von YOLOv11“ eingeführt. Das Tutorial hat die Umgebung für alle eingerichtet. Sie müssen keine Befehle eingeben. Klicken Sie einfach auf „Klonen“, um schnell die leistungsstarken Funktionen von YOLOv11 zu erleben!
Adresse des Tutorials:https://go.hyper.ai/Nztnq
Demolauf
1. Melden Sie sich bei hyper.ai an, wählen Sie auf der Tutorial-Seite „YOLOv11-Bereitstellung mit einem Klick“ und klicken Sie auf „Dieses Tutorial online ausführen“.
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
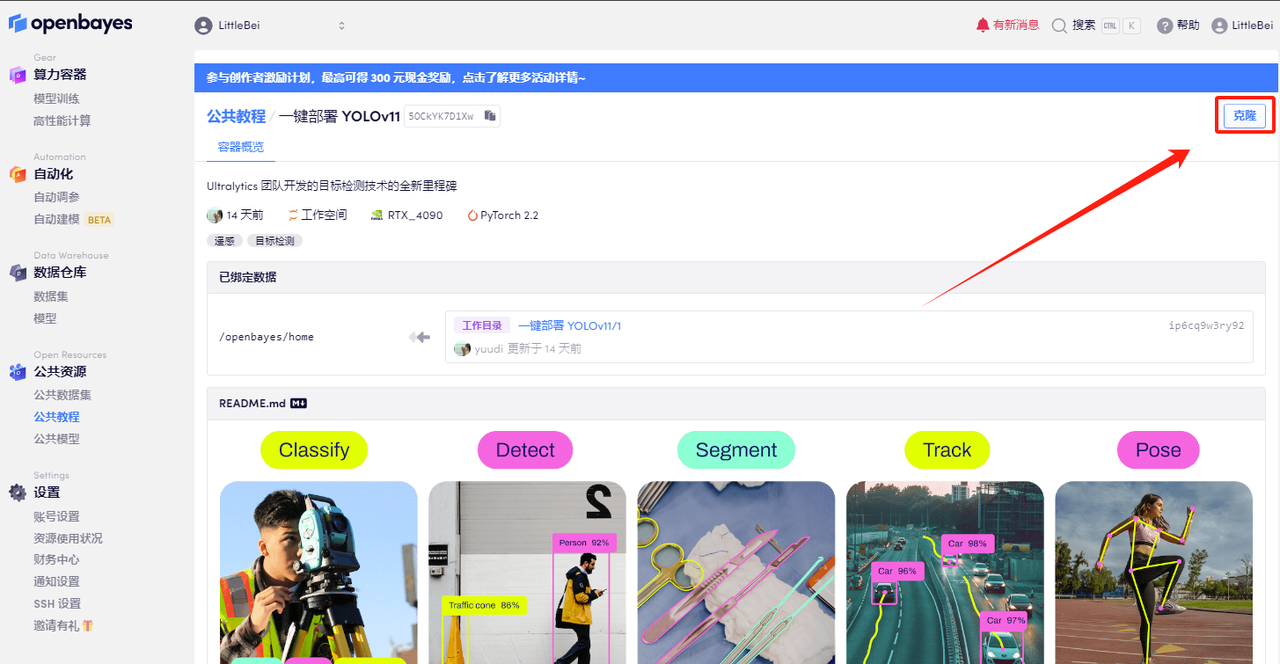
3. Klicken Sie unten rechts auf „Weiter: Hashrate auswählen“.
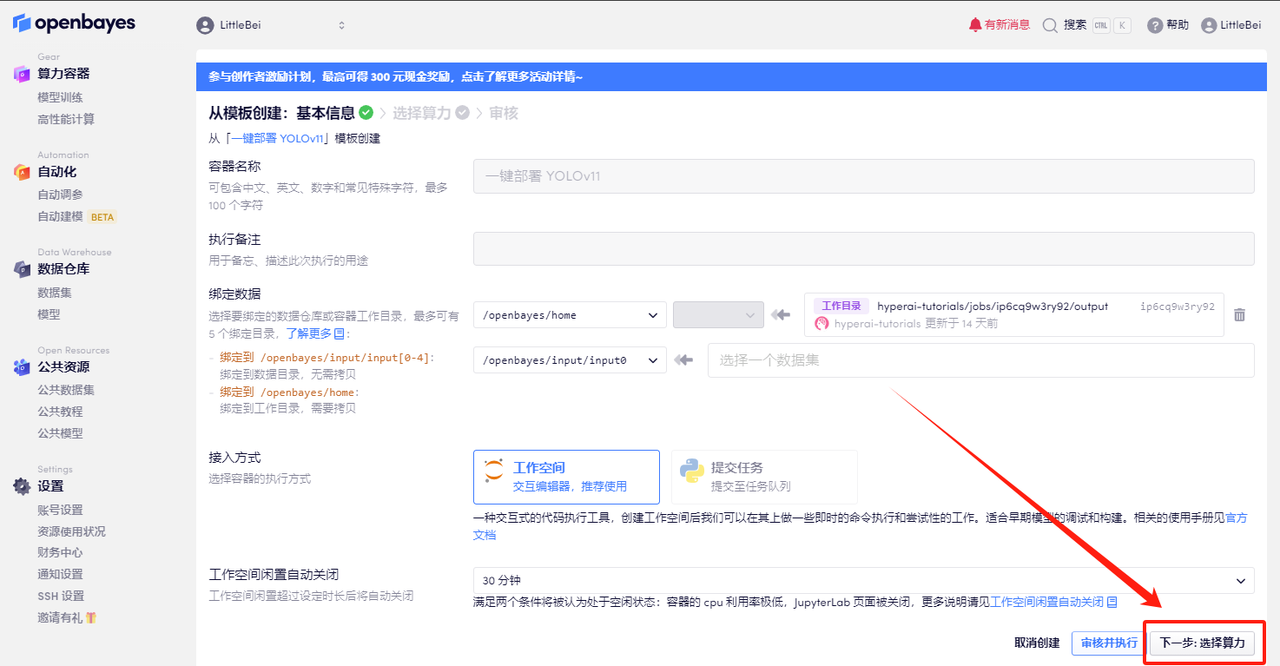
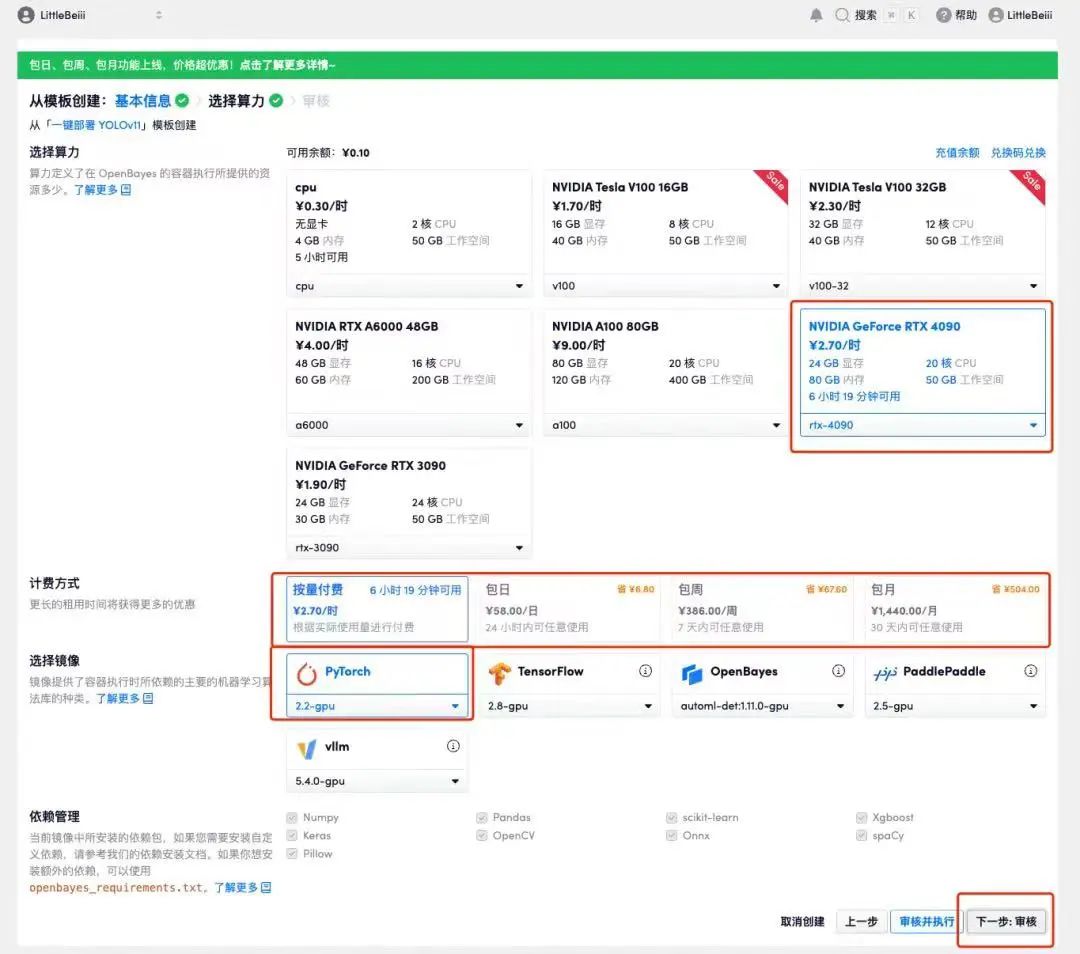
4. Wählen Sie nach dem Seitenwechsel die Bilder „NVIDIA RTX 4090“ und „PyTorch“ aus. Benutzer können je nach Bedarf zwischen „Pay as you go“ oder „Tages-/Wochen-/Monatspaket“ wählen. Klicken Sie nach Abschluss der Auswahl auf „Weiter: Überprüfen“.Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit zu erhalten!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_QZy7
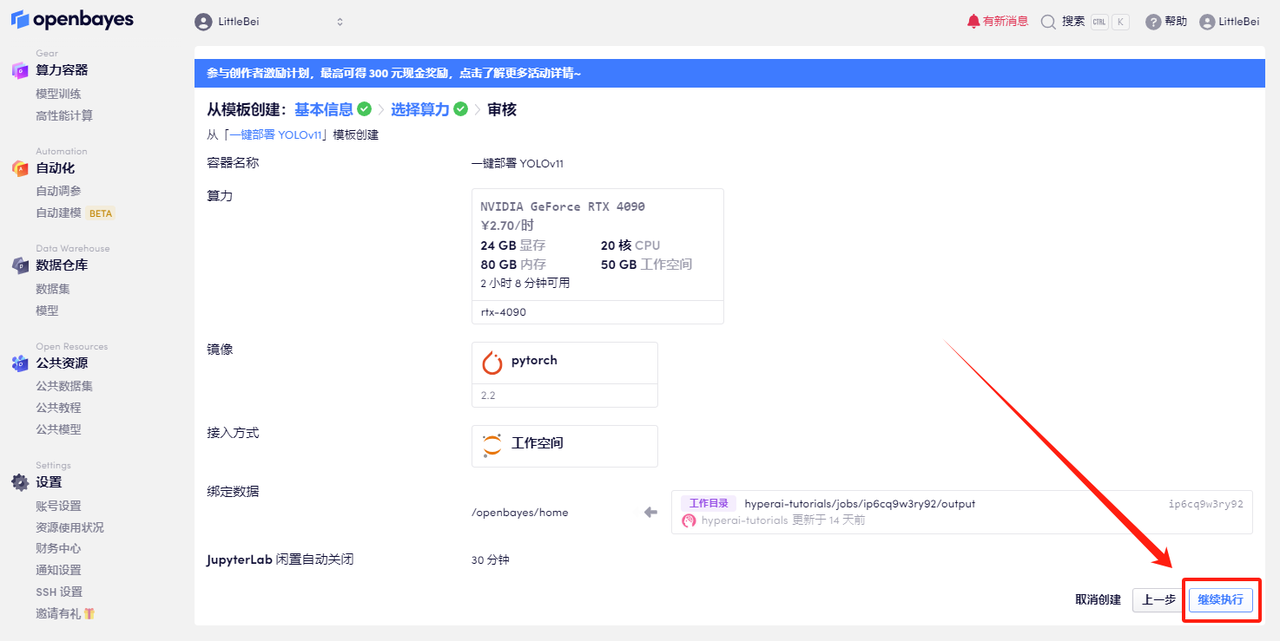
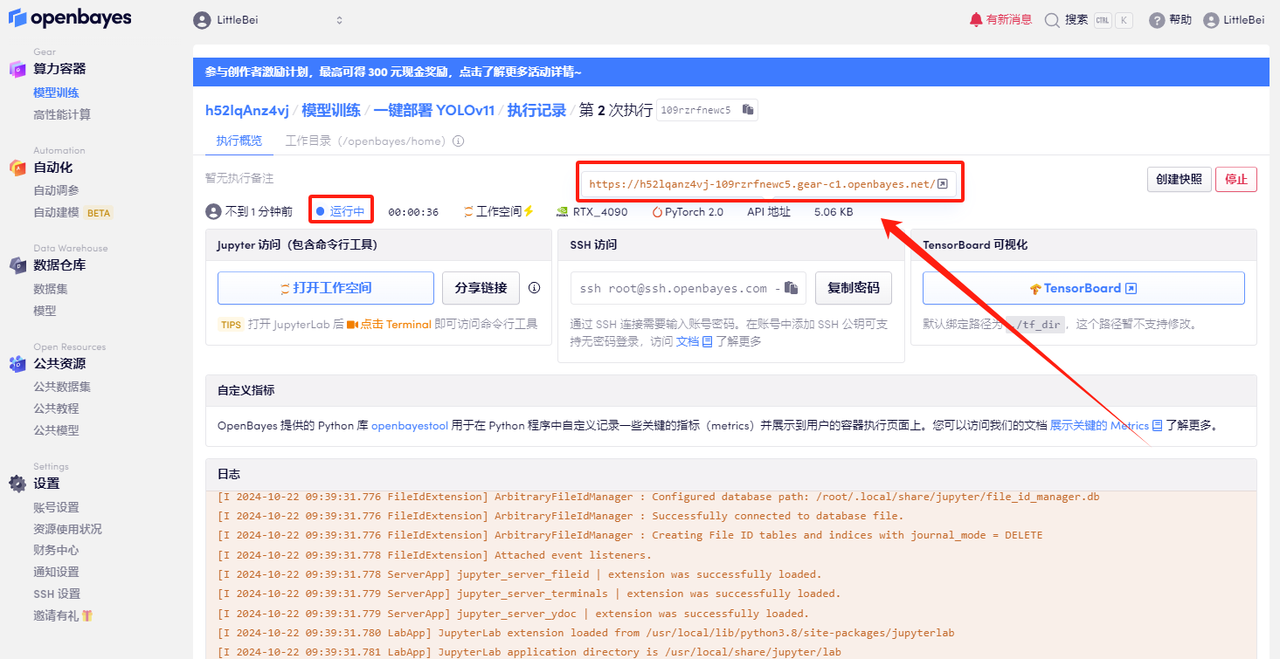
5. Klicken Sie nach der Bestätigung auf „Weiter“ und warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 2 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
Effektdemonstration
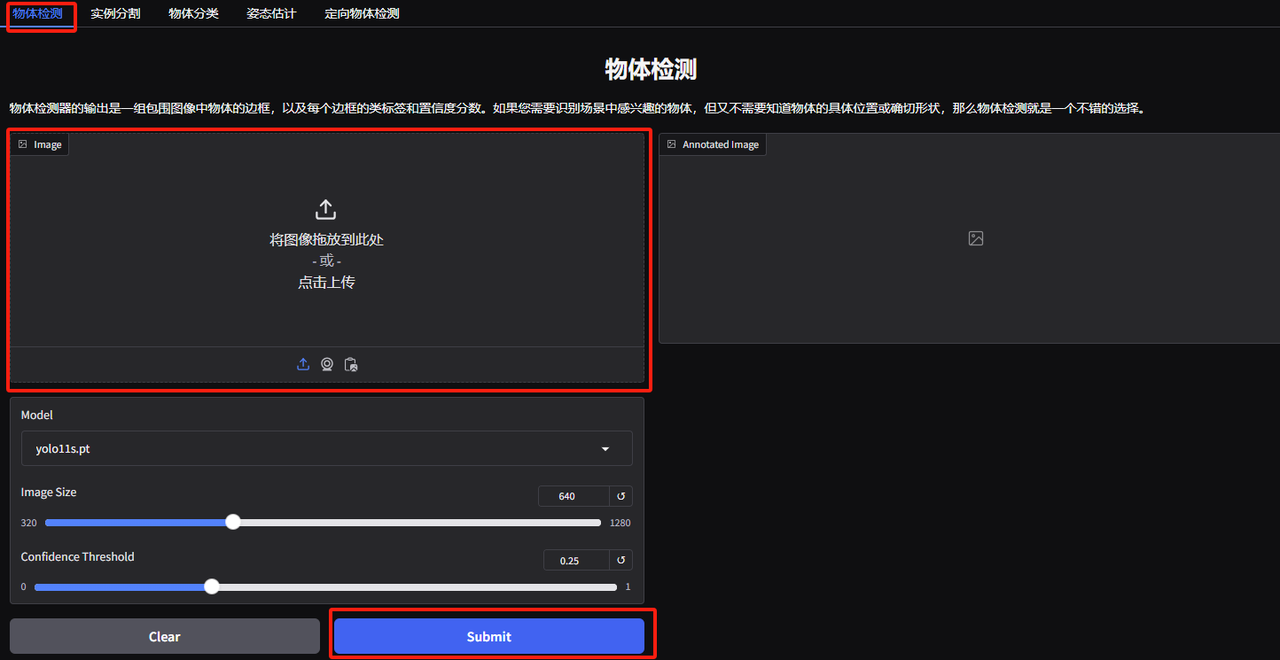
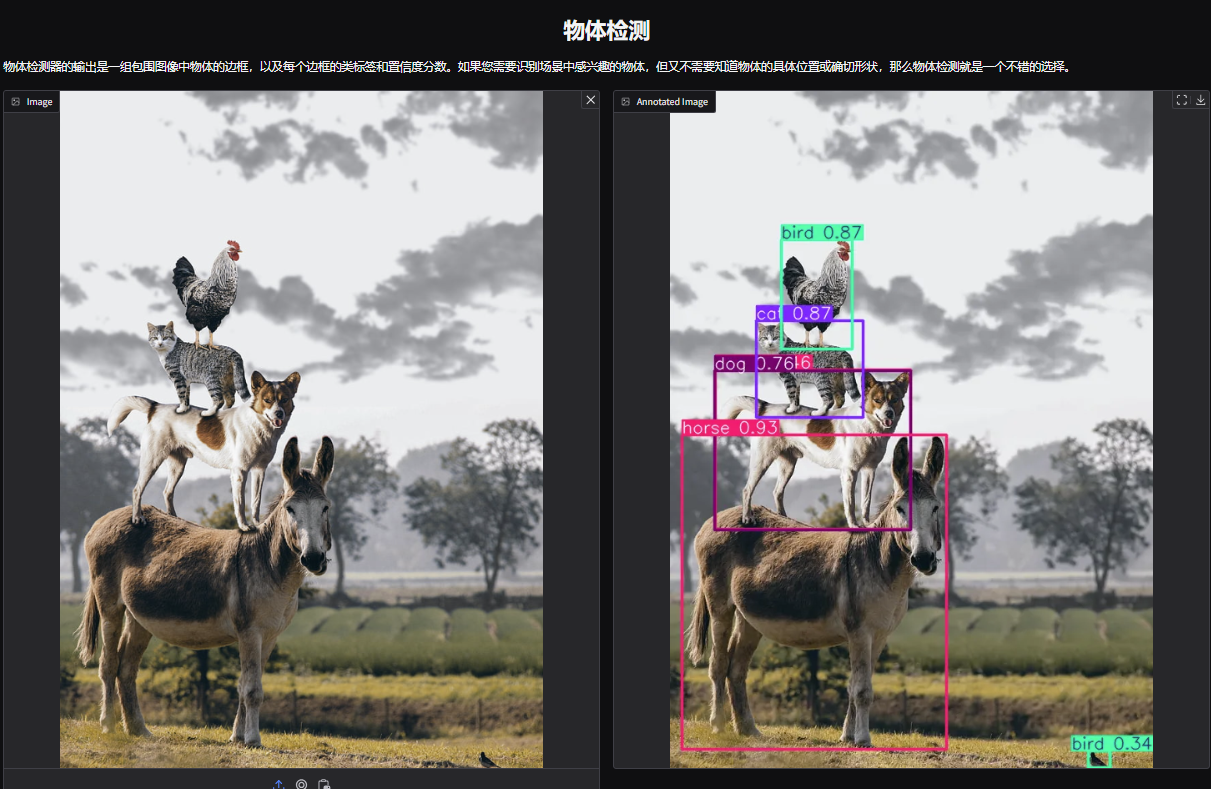
1. Öffnen Sie die Demoseite zur Objekterkennung von YOLOv11. Ich habe ein Bild von gestapelten Tieren hochgeladen, die Parameter angepasst und auf „Senden“ geklickt. Sie können sehen, dass YOLOv11 alle Tiere auf dem Bild genau erkannt hat. Es stellt sich heraus, dass in der unteren rechten Ecke ein kleiner Vogel versteckt ist! Ist Ihnen das aufgefallen?
Die folgenden Parameter stellen dar:
* Modell:Bezieht sich auf die zur Verwendung ausgewählte YOLO-Modellversion.
* Bildgröße:Die Größe des Eingabebildes. Das Modell wird die Bildgröße während der Erkennung auf diese Größe ändern.
* Vertrauensschwelle:Der Vertrauensschwellenwert bedeutet, dass bei der Zielerkennung durch das Modell nur die Erkennungsergebnisse als gültige Ziele betrachtet werden, deren Vertrauen diesen festgelegten Wert überschreitet.
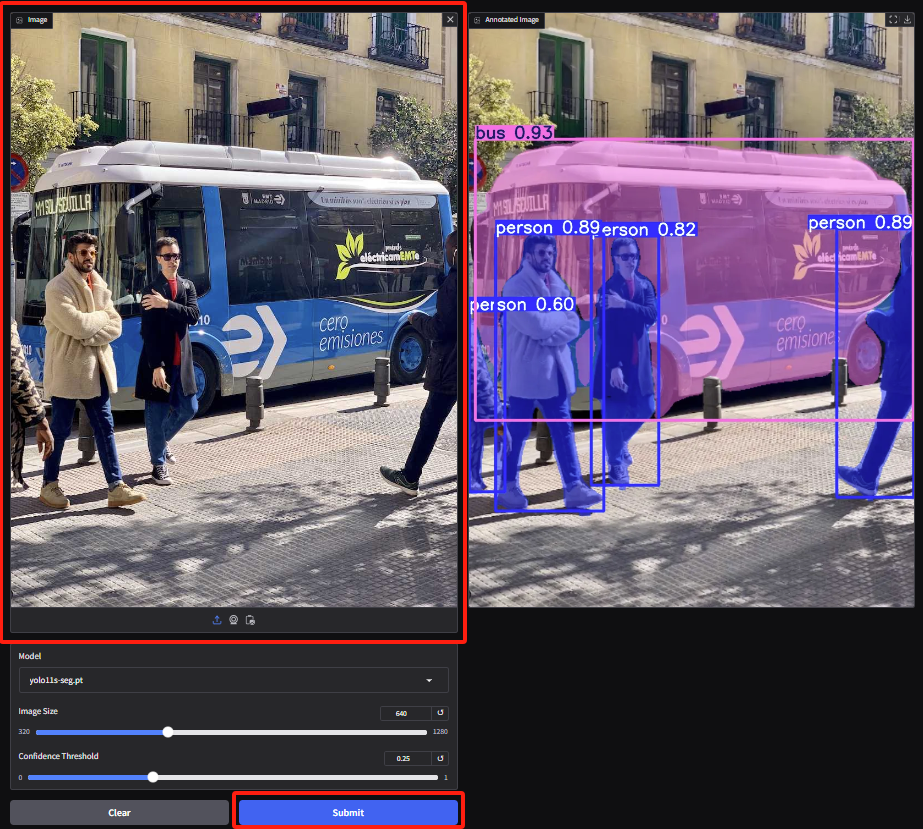
2. Rufen Sie die Demoseite zur Instanzsegmentierung auf, laden Sie das Bild hoch und passen Sie die Parameter an. Klicken Sie dann auf „Senden“, um den Segmentierungsvorgang abzuschließen. Selbst bei Okklusionen leistet YOLOv11 hervorragende Arbeit bei der genauen Segmentierung der Personen und der Umrisse des Busses.
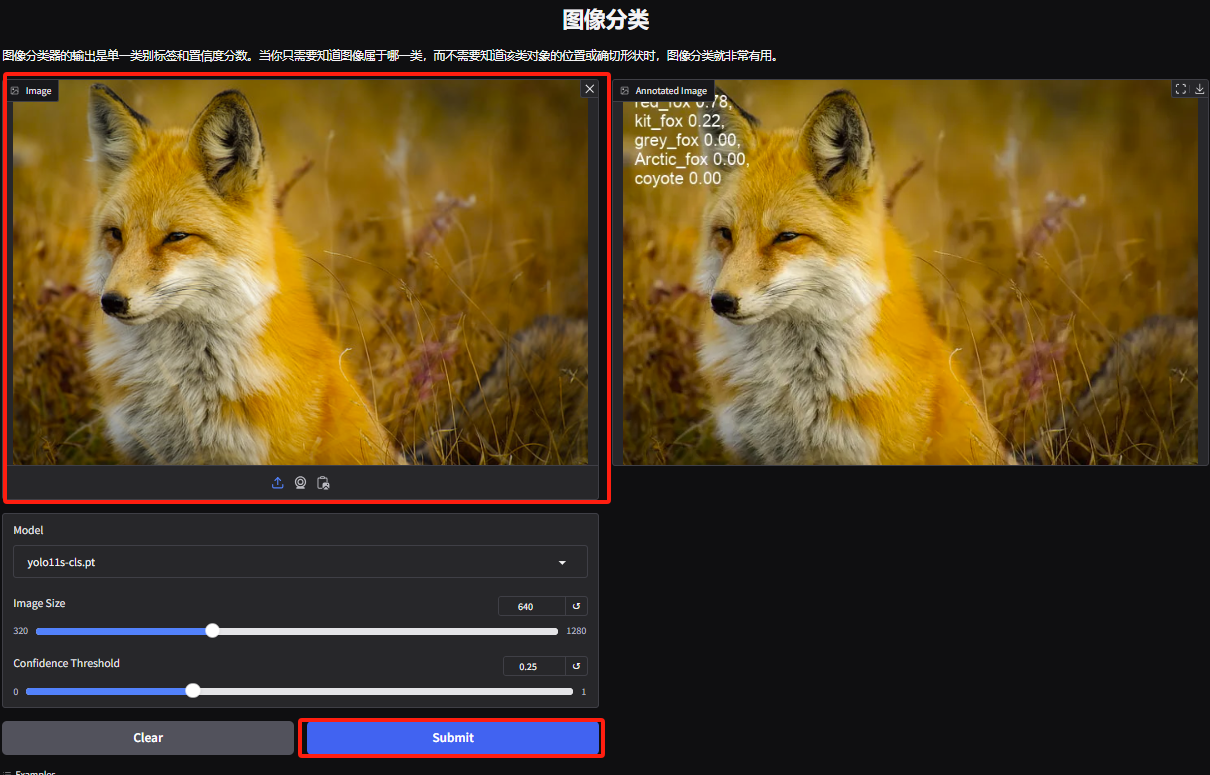
3. Rufen Sie die Demoseite zur Objektklassifizierung auf. Der Redakteur hat ein Bild eines Fuchses hochgeladen. YOLOv11 kann die spezifische Fuchsart auf dem Bild genau als Rotfuchs erkennen.
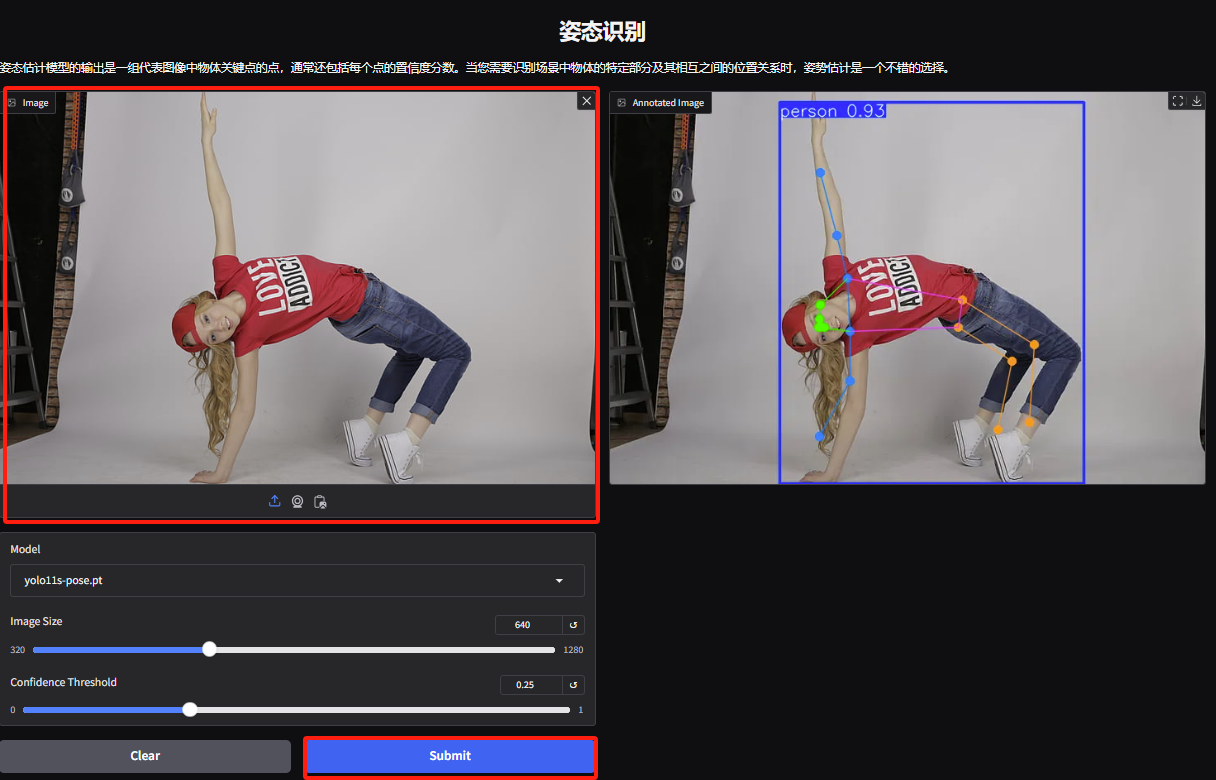
4. Rufen Sie die Demoseite zur Gestenerkennung auf, laden Sie das Bild hoch, passen Sie die Parameter entsprechend dem Bild an und klicken Sie auf „Senden“, um die Gestenbewegungsanalyse abzuschließen. Sie können sehen, dass die übertriebenen Körperbewegungen der Figur genau analysiert werden.
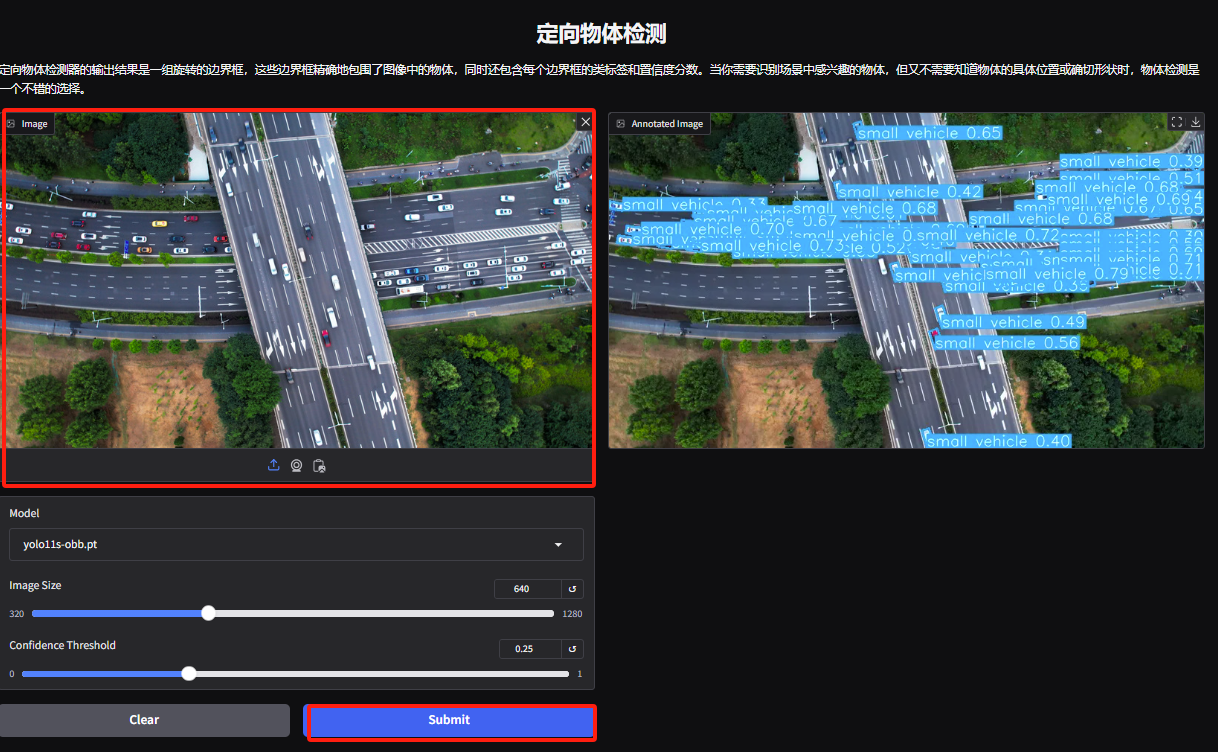
5. Laden Sie auf der Demoseite zur gezielten Objekterkennung ein Bild hoch und passen Sie die Parameter an. Klicken Sie dann auf „Senden“, um den genauen Standort und die Klassifizierung des Objekts zu ermitteln.