Command Palette
Search for a command to run...
Ausgewählt Für AAAI 2025! Es Ermöglicht Die Ausrichtung Und Fusion Multimodaler Medizinischer Bilder. Zwei Große Inländische Universitäten Schlugen Gemeinsam BSAFusion Vor
Ende 2024 gab die 39. jährliche AAAI-Konferenz für künstliche Intelligenz (AAAI 2025), die wichtigste internationale Konferenz für künstliche Intelligenz, die Ergebnisse der Papierannahme dieser Konferenz bekannt. Am Ende stachen von den 12.957 eingegangenen Einsendungen insgesamt 3.032 Arbeiten hervor und wurden aufgenommen, wobei die Annahmequote lediglich bei 23,41 TP3T lag.
In,Ein Forschungsprojekt, das gemeinsam von Li Huafeng, Zhang Yafei und Su Dayong von der School of Information Engineering and Automation der Kunming University of Science and Technology und Cai Qing von der School of Computer Science and Technology des Department of Information Science and Engineering der Ocean University of China durchgeführt wurde.——„BSAFusion: Ein bidirektionales schrittweises Feature-Alignment-Netzwerk für die nicht ausgerichtete medizinische Bildfusion“ erregte die Aufmerksamkeit von AI for Science-Forschern.Dieses Thema konzentriert sich auf den Bereich der medizinischen Bildverarbeitung, der in den letzten Jahren beispiellos an Bedeutung gewonnen hat, und schlägt eine bidirektionale, schrittweise Merkmalsausrichtung (BSFA) zur nicht ausgerichteten medizinischen Bildfusion vor.
Im Vergleich zu herkömmlichen Methoden erreichte diese Studie die gleichzeitige Ausrichtung und Fusion nicht ausgerichteter multimodaler medizinischer Bilder durch einen einstufigen Ansatz innerhalb eines einheitlichen Verarbeitungsrahmens. Dadurch wird nicht nur die Koordination von Doppelaufgaben erreicht, sondern auch das Problem der Modellkomplexität, das durch die Einführung mehrerer unabhängiger Merkmalscodierer entsteht, effektiv reduziert.

Folgen Sie dem offiziellen Konto und antworten Sie mit „Multimodal Medical Images“, um das vollständige PDF zu erhalten
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Medizinischer Fokus – Multimodale medizinische Bildfusion
Die sogenannte multimodale medizinische Bildfusion (MMIF)Dabei werden medizinische Bilddaten aus unterschiedlichen Bildgebungsverfahren wie CT, MRT, PET usw. zusammengeführt, um neue Bilder zu erzeugen, die umfassendere und genauere Informationen zu Läsionen enthalten. Die Forschung in dieser Richtung ist für die moderne Medizin und klinische Anwendungen von großem Wert.
Der Grund ist einfach. Nach Jahrzehnten der technologischen Entwicklung und Anhäufung ist die medizinische Bildgebung nicht nur in ihrer Form vielfältiger geworden, sondern findet auch immer breitere Anwendung. Wenn Menschen beispielsweise schwer stürzen, denken sie als Erstes daran, ins Krankenhaus zu gehen und dort Röntgenaufnahmen zu machen, um festzustellen, ob sie Knochenbrüche haben. Unter „Röntgenaufnahme“ versteht man in der Regel bildgebende medizinische Untersuchungen wie Röntgen, CT oder MRT.
Allerdings reicht es in der klinischen Medizin offensichtlich nicht aus, aus einem einzigen medizinischen Bild genügend Informationen zu extrahieren, um die Genauigkeit einer klinischen Diagnose sicherzustellen, insbesondere bei schwierigen und komplizierten Erkrankungen wie Tumoren, Krebszellen usw. Die multimodale medizinische Bildfusion ist zu einem der wichtigsten Trends in der Entwicklung der modernen medizinischen Bildgebung geworden. Bei der multimodalen medizinischen Bildfusion werden Bilder aus unterschiedlichen Zeiten und Quellen zur Registrierung in ein Koordinatensystem integriert. Dadurch wird nicht nur die Diagnoseeffizienz der Ärzte deutlich verbessert, sondern es werden auch wertvollere Informationen generiert, die den Ärzten dabei helfen können, eine professionellere Krankheitsüberwachung durchzuführen und wirksamere Behandlungspläne bereitzustellen.
Vor der Anwendung medizinischer Bilder haben viele Forscher das Problem der Bildfusion erkannt und weiter nach Methoden gesucht, um die Registrierung und Fusion von Bildern aus mehreren Quellen in ein einheitliches Framework zu integrieren, wie beispielsweise das berühmte MURF. Dies ist die erste Methode zur Diskussion und Lösung der Bildregistrierung und -fusion in einer Dimension. Zu seinen Kernmodulen gehören das Modul zur gemeinsamen Informationsextraktion, das Modul zur mehrskaligen Grobregistrierung und das Modul zur Feinregistrierung und -fusion.
Wie bereits erwähnt, sind diese Verfahren jedoch erstens nicht für die multimodale medizinische Bildfusion konzipiert und bieten nicht die erwarteten Vorteile im Bereich der medizinischen Bildgebung. Zweitens können diese Methoden die größte Herausforderung bei der multimodalen medizinischen Bildfusion nicht lösen:Das Problem der Inkompatibilität zwischen den für die Fusion verwendeten Merkmalen und den für die Ausrichtung verwendeten Merkmalen.
Insbesondere erfordert die Merkmalsausrichtung, dass die entsprechenden Merkmale konsistent sind, während die Merkmalsfusion erfordert, dass die entsprechenden Merkmale komplementär sind.
Das ist eigentlich nicht schwer zu verstehen. Bei der Merkmalsausrichtung geht es darum, durch verschiedene technische Mittel eine Übereinstimmung und Entsprechung verschiedener modaler Daten auf Merkmalsebene zu erreichen. Bei der Merkmalsfusion geht es darum, die Komplementarität zwischen verschiedenen Modalitäten voll auszunutzen, um die aus verschiedenen Modalitäten extrahierten Informationen in ein stabiles multimodales Modell zu integrieren.
Daher kann man sich die Schwierigkeiten für MMIF vorstellen. Diese Lücke muss nicht nur von jemandem gefüllt werden, sondern es muss auch jemand in der Lage sein, auf der Arbeit der Vorgänger aufzubauen, um die multimodale medizinische Bildfusion effizienter und bequemer zu gestalten. In der ZeitungSowohl das Team von Professor Li Huafeng als auch das Team von Associate Professor Cai Qing drückten diese ursprüngliche Absicht aus und setzten sie durch Forschungsexperimente in die Praxis um.
Aus technischer Sicht bietet diese Methode mehrere Designs mit innovativem Wert:
* Erstens löst diese Methode durch die gemeinsame Nutzung des Feature-Encoders das Problem der erhöhten Modellkomplexität, die durch die Einführung zusätzlicher Encoder zur Ausrichtung verursacht wird, und entwirft erfolgreich ein einheitliches und effektives Framework, das die merkmalsübergreifende Ausrichtung und Fusion integriert und so eine nahtlose Ausrichtung und Fusion erreicht.
* Zweitens wird die Methode der Modal Discrepancy-Free Feature Representation (MDF-FR) integriert, um eine globale Merkmalsintegration zu erreichen, indem jedem Eingabebild ein Modality Feature Representation Head (MFRH) angehängt wird, wodurch die Auswirkungen von Modalitätsunterschieden und multimodaler Informationsinkonsistenz auf die Merkmalsausrichtung erheblich reduziert werden.
* Schließlich wird eine bidirektionale schrittweise Deformationsfeldvorhersagestrategie vorgeschlagen, die auf der Unabhängigkeit des Vektorverschiebungspfads zwischen zwei Punkten basiert und die Probleme der großen Spannweite und der ungenauen Deformationsfeldvorhersage, die bei der herkömmlichen einstufigen Ausrichtungsmethode auftreten, wirksam lösen kann.
BSAFusion ist Vorreiter einer neuen Technologierichtung für die medizinische Bildfusion
Das vom Forschungsteam vorgeschlagene einstufige multimodale Rahmenwerk zur Registrierung und Fusion medizinischer Bilder,Es besteht hauptsächlich aus drei Kernkomponenten, nämlich MDF-FR, BSFA und MMFF (Multi-Modal Feature Fusion).Die Einzelheiten sind in der folgenden Abbildung dargestellt.
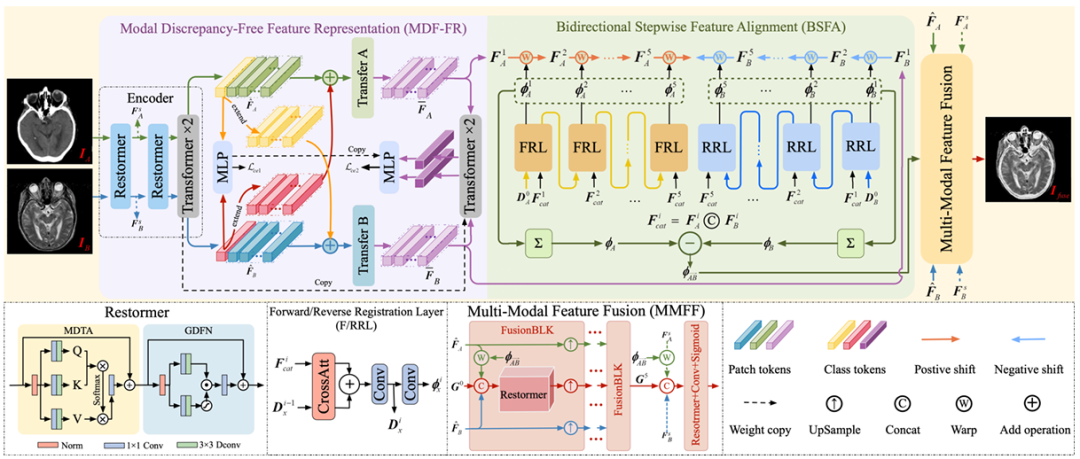
Es ist nicht schwer zu erkennen, dass in MDF-FR,Die Restormer- und Transformer-Ebenen bilden den Encoder des Netzwerks, um Merkmale aus den nicht ausgerichteten Bildpaaren zu extrahieren, wobei Restormer und Transformer jeweils über zwei Ebenen verfügen. Nach der Ausrichtung und Fusion zweier Merkmale werden die Merkmale in das nachfolgende MLP eingegeben, um die Vorhersageergebnisse zu erhalten.
Da die beiden Modalitäten sehr unterschiedlich sind, wird auch das modalübergreifende Matching und die Deformationsfeldvorhersage dieser Merkmale vor große Herausforderungen stellen. Daher können wir durch die Generierung modalitätsspezifischer Merkmalsdarstellungsköpfe die Auswirkungen von Modalitätsunterschieden auf die Vorhersage von Deformationsfeldern reduzieren und den Verlust nicht gemeinsam genutzter Informationen durch die Extraktion gemeinsam genutzter Informationen verhindern.
Später verwendete das Team weiterhin Transfer A und Transfer B, um die Unterschiede zwischen den Modi zu beseitigen. Jeder Transferblock besteht aus zwei Transformer-Schichten und es werden keine Parameter zwischen ihnen geteilt, um die Merkmale weiter zu extrahieren, die zur Vorhersage der Deformationsstelle erforderlich sind.
Ankunft bei BSFA,Das Forschungsteam entwickelte ein Deformationsfeld, um die Merkmale des Eingabebilds aus zwei Richtungen vorherzusagen – eine bidirektionale schrittweise Merkmalsausrichtungsmethode. Eine fünfschichtige Deformationsfeldvorhersageoperation wurde sowohl für Vorwärts- als auch für Rückwärtsvorhersagen entwickelt, entsprechend den fünf Zwischenknoten, die zwischen den beiden Eingabequellbildern eingefügt wurden. Diese Methode verbessert die allgemeine Robustheit des Ausrichtungsprozesses. Die für die Vorwärtsregistrierung zuständige Schicht ist FRL, und die für die Rückwärtsregistrierung zuständige Schicht ist RRL.
Schließlich im MMFF-ModulDas vorhergesagte Deformationsfeld wird angewendet, um die Merkmale auszurichten, und dann werden mehrere FusionBLK-Module verwendet, um die Merkmale zu verschmelzen. Schließlich wird das fusionierte Bild durch die Rekonstruktionsschicht erhalten und verschiedene Verlustfunktionen werden verwendet, um die Netzwerkparameter zu optimieren.
Um die Wirksamkeit und Genauigkeit des Experiments sicherzustellen, hat das Forschungsteam natürlich sorgfältige Vereinbarungen über die experimentellen Details getroffen. Bei den auf diesem Modell basierenden Experimenten folgte das Forschungsteam dem Protokoll bestehender Methoden.Für das Modelltraining wurden CT-MRI-, PET-MRI- und SPECT-MRI-Datensätze von Harvard verwendet.Diese Datensätze bestehen aus 144, 194 bzw. 261 streng registrierten Bildpaaren und die Größe jedes Objektpaares beträgt 256 x 256.
Um die in realen Szenarien gesammelten, falsch ausgerichteten Bildpaare zu simulieren, werden in diesem Experiment MRT-Bilder speziell als Referenzen angegeben und eine Mischung aus starren und nicht starren Deformationen auf Nicht-MRT-Bilder angewendet, um den erforderlichen Trainingssatz zu erstellen. Darüber hinaus wendete das Forschungsteam die gleiche Verformung auch auf 20, 55 und 77 Paare streng registrierter Bilder an, um einen nicht ausgerichteten Testsatz zu erstellen.
Der Trainingsprozess verwendet eine End-to-End-Methode, bei der 3.000 Epochen mit einer Batchgröße von 32 auf jedem Datensatz trainiert werden. Gleichzeitig wird der Adam-Optimierer verwendet, um die Modellparameter mit einer anfänglichen Lernrate von 5 x 10⁻⁵ zu aktualisieren. Verwenden Sie eine Cosinus-Annealing-Lernrate (LR), die mit der Zeit auf 5 x 10⁻⁷ abnimmt.
Die Experimente verwendeten das PyTorch-Framework und wurden auf einer einzelnen NVIDIA GeForce RTX 4090 GPU trainiert.
Basierend auf den präzisen experimentellen Details des Forschungsteams und den Standarddatensätzen für das Training zeigte diese Methode auch in experimentellen Experimenten hervorragende Ergebnisse.
Als experimentelle Vergleichsobjekte dienen die fünf fortschrittlichsten Verfahren zur Gelenkregistrierung, darunter UMF-CMGR, superFusion, MURF, IMF und PAMRFuse. Mit Ausnahme der letzten Gruppe sind die ersten vier nicht speziell für die multimodale medizinische Bildfusion konzipiert, stellen jedoch derzeit die besten Bildfusionsmethoden dar und eignen sich für MMIF. Wie in der folgenden Abbildung dargestellt:
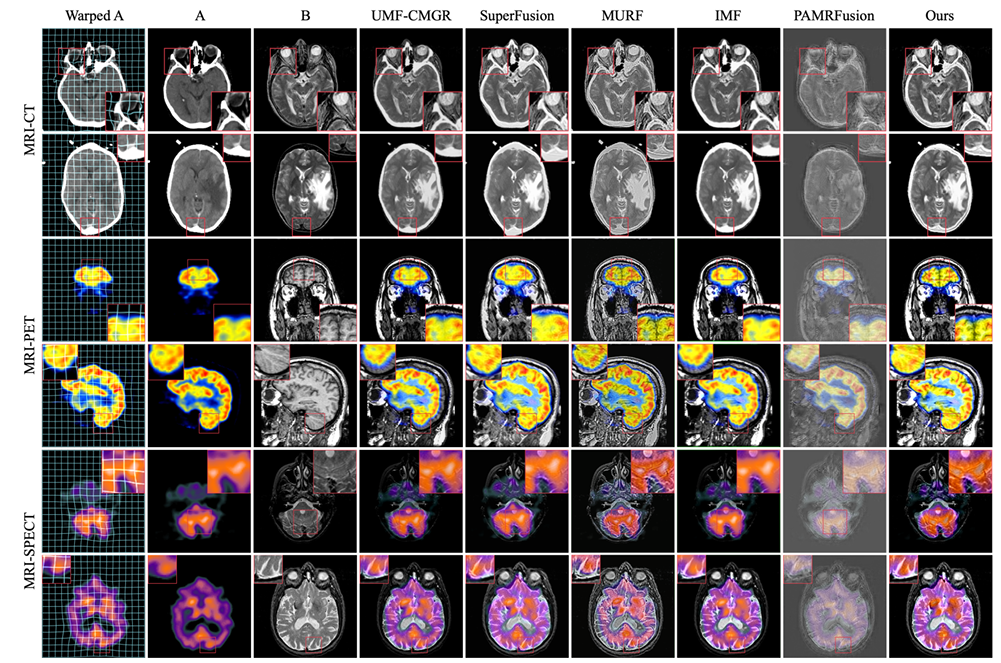
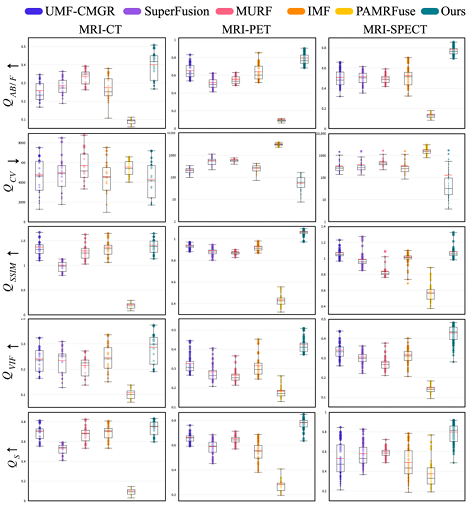
Die Ergebnisse sind offensichtlich. Die vom Forschungsteam vorgeschlagene Methode ist in Bezug auf Merkmalsausrichtung, Kontrasterhaltung und Detailerhaltung stärker überlegen und weist unter allen Indikatoren die beste Durchschnittsleistung auf.
Teams arbeiten zusammen, um medizinische klinische Anwendungen zu sichern
Einer der korrespondierenden Autoren dieses Forschungsthemas ist Cai Qing, außerordentlicher Professor an der School of Computer Science and Technology, Fakultät für Informationswissenschaft und -technik, Ocean University of China. Neben seiner Tätigkeit an der Ocean University of China bekleidet er auch wichtige Positionen in mehreren bedeutenden akademischen Institutionen wie der China Computer Federation (CCF).
Die Hauptforschungsgebiete von Professor Cai Qing sind Deep Learning, Computer Vision und medizinische Bildverarbeitung.Die multimodale medizinische Bildfusion ist als Teilgebiet der medizinischen Bildverarbeitung mit einer starken professionellen Wissensbarriere verbunden und die langjährige Erfahrung von Cai Qing kann bei diesem Projekt Anleitung und Unterstützung bieten.
Erwähnenswert ist, dass Associate Professor Cai Qing, nachdem er im vergangenen Jahr Erstautor eines für AAAI 2024 ausgewählten Papiers war, in diesem Jahr erneut Co-Erstautor und korrespondierender Autor war und insgesamt 3 Forschungsprojekte in AAAI 2025 aufgenommen wurden. Dazu gehört eine weitere Studie zur medizinischen Bildverarbeitung mit dem Titel „SGTC: Semantic-Guided Triplet Co-training for Sparsely Annotated Semi-Supervised Medical Image Segmentation“. In diesem Artikel schlagen die Forscher ein neues semantisch gesteuertes Triplet-Co-Training-Framework vor, das eine zuverlässige Segmentierung medizinischer Bilder durch die Annotation von nur 3 orthogonalen Scheiben einer kleinen Anzahl von Volumenproben erreichen kann und so das Problem des zeit- und arbeitsintensiven Bildannotationsprozesses löst.
Papieradresse:
https://arxiv.org/abs/2412.15526
Das andere Team für dieses Projekt ist das Team von Professor Li Huafeng und Zhang Yafei von der School of Information Engineering and Automation der Kunming University of Science and Technology.Unter ihnen wurde Professor Li Huafeng im Jahr 2021 in die aktuelle Liste der besten 2%-Wissenschaftler der Welt aufgenommen. Er forscht hauptsächlich in den Bereichen Computersehen, Bildverarbeitung und anderen Bereichen. Ein weiterer korrespondierender Autor dieses Artikels, Associate Professor Zhang Yafei, dessen Hauptforschungsgebiete Bildverarbeitung und Mustererkennung sind, hat viele regionale Projekte der National Natural Science Foundation of China und allgemeine Projekte der Yunnan Natural Science Foundation of China geleitet.
Professor Li Huafeng, einer der wichtigen akademischen Leiter dieses Projekts, hat zahlreiche Forschungsarbeiten zur medizinischen Bildverarbeitung veröffentlicht, beispielsweise bereits 2017 eine Studie mit dem Titel „Medical Image Fusion Based on Sparse Representation“ und 2023 eine Studie mit dem Titel „Feature dynamic alignment and refinement for infrared–visible image fusion: Translation robust fusion“.
Papieradresse:
https://liip.kust.edu.cn/servletphoto?path=lw/00000311.pdf
Papieradresse:
https://www.sciencedirect.com/science/article/abs/pii/S1566253523000519
Darüber hinaus hat Li Huafeng mehrfach mit Professor Zhang Yafei zusammengearbeitet, um gemeinsam verwandte Forschungsergebnisse zu veröffentlichen, beispielsweise die 2022 gemeinsam veröffentlichte Forschungsarbeit mit dem Titel „Medical Image Fusion with Multi-Scale Feature Learning and Edge Enhancement“. In dieser Studie schlug das Team ein medizinisches Bildfusionsmodell auf Basis von mehrskaligem Merkmalslernen und Kantenverbesserung vor, das das Problem unscharfer Grenzen zwischen verschiedenen Organen bei der medizinischen Bildfusion lindern kann. Die mit der vorgeschlagenen Methode erzielten Ergebnisse sind sowohl hinsichtlich der subjektiven visuellen Effekte als auch der objektiven quantitativen Bewertung besser als die Vergleichsmethode.
Papieradresse:
https://researching.cn/ArticlePdf/m00002/2022/59/6/0617029.pdf
Wie das Sprichwort sagt: Eine starke Allianz ist tadellos. Die professionellen akademischen Fähigkeiten von Professor Li Huafeng, Zhang Yafeis Team und Associate Professor Cai Qing auf dem Gebiet der medizinischen Bildverarbeitung sind zweifellos der Schlüssel zum Erfolg dieses Projekts. Wir freuen uns auf die weitere Zusammenarbeit zwischen den beiden Parteien und die Veröffentlichung weiterer Spitzenergebnisse im Bereich der KI für die Wissenschaft in der Zukunft.
Hybride multimodale medizinische Bildfusion wird zum Trend
Da die multimodale medizinische Bildfusion eine immer wichtigere Rolle spielt, wird sich ihre technologische Entwicklung zwangsläufig in Richtung Integration und Intelligenz bewegen.
Wie in diesem Thema erwähnt, stellten Forscher bei der Untersuchung von Fusionsmethoden auf Basis von Deep Learning fest, dass die CNN-basierte Methode und die Transformer-basierte Methode komplementäre Vorteile haben. Daher schlugen einige Forscher DesTrans, DFENet und MRSC-Fusion vor. Diese Studien verwenden einen hybriden Ansatz, um die Vorteile der beiden Technologien komplementär zu nutzen und so die Effizienz der Fusionsmethode zu verbessern.
Neben auf Deep Learning basierenden Fusionsmethoden umfassen multimodale medizinische Bildfusionsmethoden auch traditionelle Fusionsmethoden wie Multiskalentransformation, spärliche Darstellung, Subraum-basierte, auf markanten Merkmalen basierende, hybride Modelle usw. Ebenso sind hybride Ansätze auf Basis von Deep Learning und traditionellen Methoden entstanden.
Aus den oben genannten Forschungstrends können wir erkennen, dassIn Zukunft wird sich bei der Methode der multimodalen medizinischen Bildfusion zwangsläufig ein Entwicklungstrend zeigen, der auf Deep Learning als Mainstream basiert und gleichzeitig eine Vielzahl technischer Unterstützungen einbezieht.









