Command Palette
Search for a command to run...
Das Einzige Open-Source-70B-Modell Von Llama 3.3 Wird Online Ausgeführt, Die Leistung Ist Mit 405B Vergleichbar! Der LaTeX OCR-Datensatz Ist Jetzt Verfügbar, Um Bei Der Erkennung Mathematischer Formeln Zu Helfen

Erst in diesem Monat hat Meta das einzige Open-Source-Modell von Llama 3.3 veröffentlicht, Llama-3.3-70B-Instruct. Obwohl die Parametergröße nur 70 B beträgt, ist seine Leistung mit der des 405 B-Modells vergleichbar. Dies ist das letzte Modell der Llama 3-Serie. Zuckerberg sagte: „Auf Wiedersehen heißt Lama 4!“
Auf der offiziellen Website von hyper.ai wurde im Tutorial-Bereich die Funktion „One-click deployment of Llama-3.3-70B-Instruct“ eingeführt. Lasst uns gemeinsam das Endergebnis von Llama 3 erleben~
Online-Nutzung:https://go.hyper.ai/TthEw
Vom 23. bis 29. Dezember gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 3
* Community-Artikelauswahl: 6 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadlines im Januar: 9
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
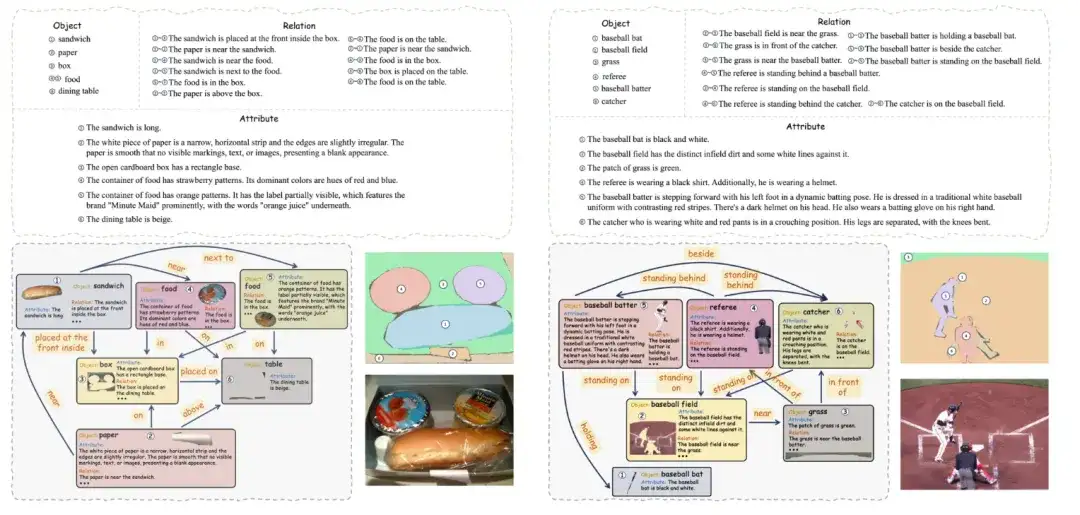
1. CompreCap-Bildbeschreibungsdatensatz
Der Datensatz enthält 560 Bilder, von denen jedes fein semantisch segmentiert und mit Objekten, Attributen und Beziehungen annotiert wurde, um eine vollständige orientierte Szenengraphstruktur zu bilden.
Direkte Verwendung:https://go.hyper.ai/icfaH
2. HelmetViolations Helmerkennungsdatensatz
Der Datensatz enthält insgesamt 1.004 Bilder, die im YOLOv9-Format annotiert sind, und umfasst 3 Kategorien: Nummernschild (Plate), mit Helm (WithHelmet) und ohne Helm (WithoutHelmet). Der Trainingssatz enthält 363 Bilder (Original + erweiterte Bilder); der Validierungssatz hat 53 Bilder; Der Testsatz ist im Export zur Modellauswertung enthalten.
Direkte Verwendung:https://go.hyper.ai/N0Yyg

3. SynCamVideo-Dataset Multi-Kamera Synchroner Video-Datensatz
Der Datensatz enthält 1.000 verschiedene Szenen, die jeweils von 36 Kameras aufgenommen wurden, wodurch insgesamt 36.000 Videos entstanden, mit 50 verschiedenen Tieren als „Hauptmotiven“ und 20 verschiedenen Orten aus Poly Haven als Hintergrund.
Direkte Verwendung:https://go.hyper.ai/oIJns

4. Flugzeugbildklassifizierung Flugzeugbildklassifizierungsdatensatz
Dieser Datensatz enthält 3.371 Flugzeugbilder, die in 10 Kategorieordner unterteilt sind. Jede Kategorie entspricht einem bestimmten Flugzeugmodell: A10, A400M, AG600, AH64, AV8B, An124, An22, An225, An72 und B1 usw.
Direkte Verwendung:https://go.hyper.ai/IL3uP

5. MangaZero-Comic-Bilddatensatz
Der MangaZero-Datensatz ist ein umfangreicher Comic-Bilddatensatz mit mehreren Zeichen und mehreren Zuständen, der speziell für Aufgaben zur Comic-Erstellung entwickelt wurde. Es enthält 43.264 Seiten Comics und 427.147 kommentierte Panels. Es unterstützt die Visualisierung verschiedener Charakterinteraktionen und -aktionen in aufeinanderfolgenden Frames und eignet sich für Aufgaben zur Comic-Generierung mit mehreren Charakteren und mehreren Zuständen.
Direkte Verwendung:https://go.hyper.ai/IpkjL
6. LaTeX OCR-Datensatz zur Erkennung mathematischer Formeln
Der LaTeX OCR-Datensatz ist ein Datensatz, der sich auf das komplexe Problem der Erkennung mathematischer Formeln im Bereich der optischen Zeichenerkennung (OCR) konzentriert. Der LaTeX OCR-Datensatz enthält mehrere Konfigurationen, jede mit unterschiedlichen Funktionen und Datenpartitionierung.
Direkte Verwendung:https://go.hyper.ai/lyK1J
7. FSQ OS Places Open Source-Standortdatensatz
Dieser Datensatz enthält mehr als 100 Millionen globale Points of Interest (POIs) aus über 200 Ländern und Regionen und macht Forschern, Entwicklern und Unternehmen umfangreiche Geodaten zugänglich. Es bietet 22 Kernattribute, darunter wichtige Informationen wie Ortsname, Adresse, Längen- und Breitengrad, die verschiedene Anwendungen wie Geodatenanalysen und Positionierungsdienste unterstützen.
Direkte Verwendung:https://go.hyper.ai/7oN5M
8. ProcessBench Mathematical Reasoning Benchmark-Datensatz
Dieser Datensatz enthält 3,4.000 Testbeispiele, wobei der Schwerpunkt auf mathematischen Problemen mit Wettbewerbs- und Olympia-Schwierigkeit liegt. Jedes Beispiel enthält eine Schritt-für-Schritt-Lösung und präzise Fehlermarkierungen von Fachexperten.
Direkte Verwendung:https://go.hyper.ai/fk3hq
9. Chinesischer medizinischer Dialog
Dieser chinesische medizinische Datensatz ist eine umfassende Ressource für die Entwicklung und Schulung von Sprachmodellen, die professionelle Gespräche und Empfehlungen im medizinischen Bereich ermöglichen. Es kombiniert mehrere Arten von Daten, darunter Lexikonwissen, Lehrbuchtexte, tatsächliche Arzt-Patienten-Gespräche und Evaluationsdaten, um die Genauigkeit und Praktikabilität des Modells zu verbessern.
Direkte Verwendung:https://go.hyper.ai/wkAXX
10. splsoNet-Tutorial-Datensatz zur Anisotropiekorrektur und Fehlausrichtungskorrektur
spIsoNet ist eine durchgängige, selbstüberwachte Deep-Learning-Software zur Behebung von Problemen mit Kartenanisotropie und Partikelfehlausrichtung, die durch das Problem der bevorzugten Orientierung verursacht werden. Dieser Datensatz wird in der Forschung verwendet und die entsprechenden Ergebnisse wurden in der internationalen Fachzeitschrift Nature Methods veröffentlicht.
Direkte Verwendung:https://go.hyper.ai/tFOqJ
Ausgewählte öffentliche Tutorials
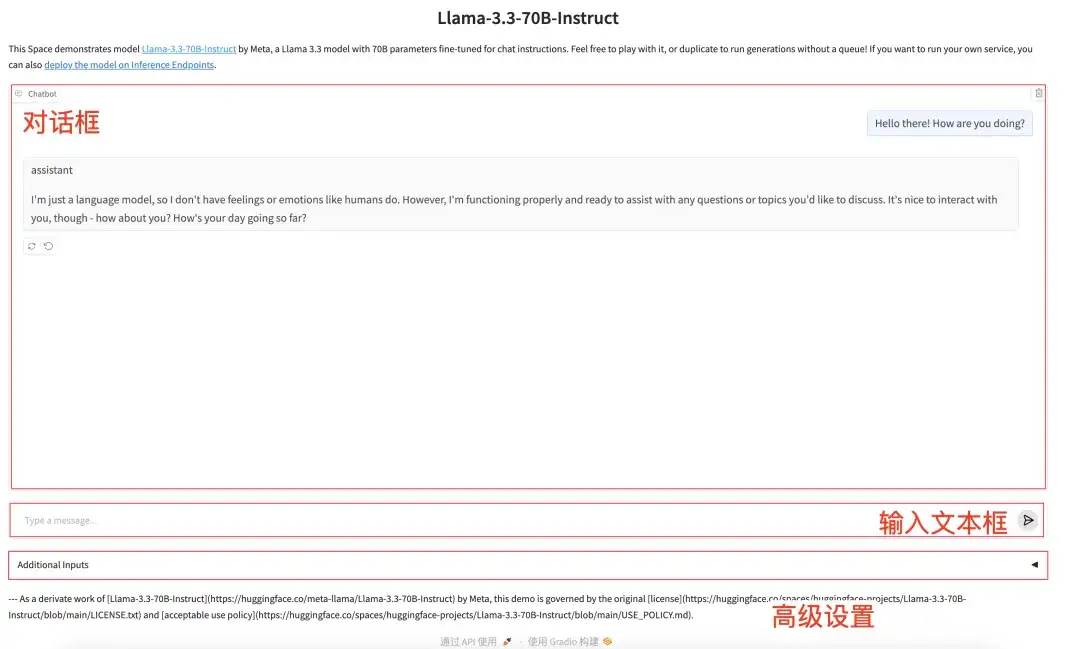
1. Ein-Klick-Bereitstellung von Llama-3.3-70B-Instruct
Llama-3.3-70B-Instruct ist ein großes Sprachmodell, das 2024 von Meta eingeführt wurde. Es ist das einzige Open-Source-Modell in der Llama 3.3-Reihe und verfügt über eine speziell optimierte Version zur Feinabstimmung von Anweisungen.
Das Modell hat die Umgebung und Abhängigkeiten konfiguriert. Sie können eine Konversation mit dem Modell beginnen, indem Sie die API-Adresse eingeben.
Online ausführen:https://go.hyper.ai/TthEw
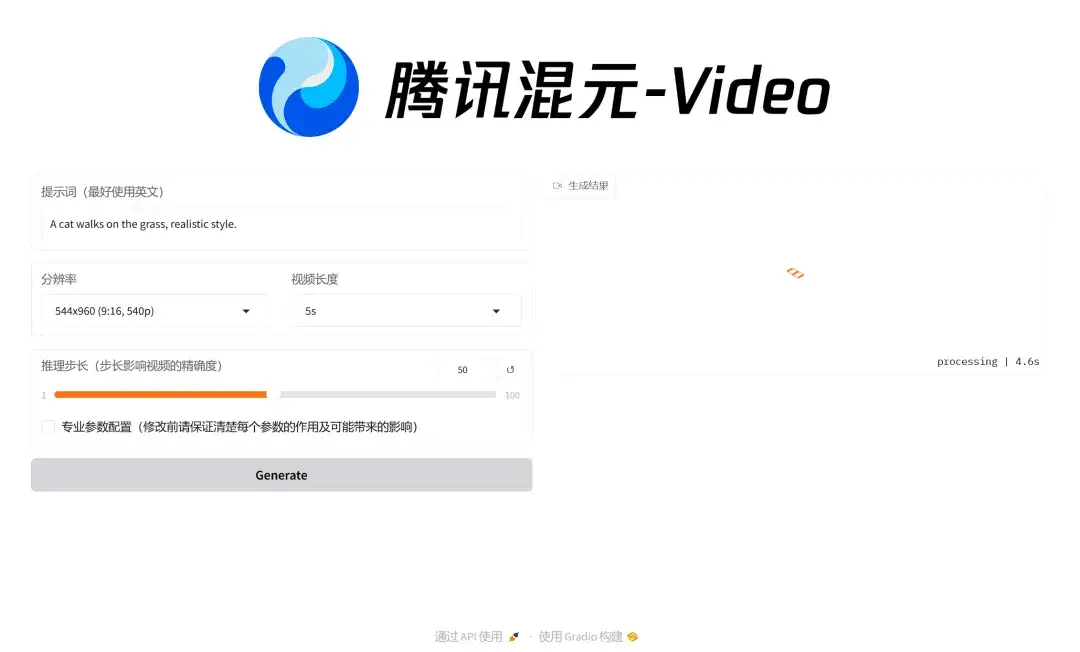
2. HunyuanVideo Tencent Hunyuan Wensheng Videodemo
HunyuanVideo möchte Benutzern dabei helfen, mithilfe künstlicher Intelligenz hochwertige Videoinhalte zu erstellen. HunyuanVideo ist mit 13 Milliarden Parametern das Wensheng-Videomodell mit der größten Anzahl an Parametern unter den aktuellen Open-Source-Modellen. Es kann Videoinhalte mit hoher physikalischer Genauigkeit und Szenenkonsistenz generieren, Benutzern ein hyperrealistisches visuelles Erlebnis bieten und frei zwischen realen und virtuellen Stilen wechseln.
Das Projekt bietet eine praktische Weboberfläche und Benutzer können Videos in verschiedenen Stilen erstellen, indem sie einfach eine einfache Textbeschreibung eingeben oder Bedingungen festlegen.
Online ausführen:https://go.hyper.ai/hEkOw
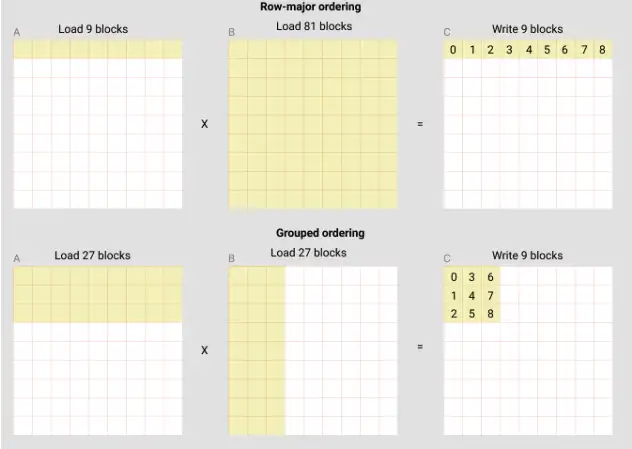
3. Triton-Tutorial: Matrizenmultiplikation
In diesem Tutorial schreiben Sie einen sehr kurzen, leistungsstarken FP16-Matrixmultiplikationskernel, der eine mit cuBLAS oder rocBLAS vergleichbare Leistung aufweist. Insbesondere lernen Sie Folgendes: mehrstufige Matrizenmultiplikation; mehrdimensionale Zeigerarithmetik; Neuanordnung von Programmen zur Verbesserung der Trefferquote des L2-Cache; und automatische Leistungsoptimierung.
Online ausführen:https://go.hyper.ai/riM7b
Community-Artikel
HyperAI hat 26 hochmoderne, zwischen 2023 und 2024 interpretierte Artikel ausgewählt und klassifiziert. Dieser Artikel konzentriert sich auf die KI-Forschung im Bereich der Materialchemie. Es handelt sich um eine umfassende Rezension. Klicken Sie also, um sie schnell zu lesen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/XnzcN
Als britisches Hightech-Chemieunternehmen hat Chemify die weltweit erste „chemische Turingmaschine“ und den weltweit ersten chemischen Compiler entwickelt. Es hat sich zum Ziel gesetzt, chemische Computertechnik, künstliche Intelligenz, Robotik, Automatisierung usw. in die Arzneimittelforschung und -entwicklung zu integrieren, um die digitale Entwicklung der Chemie voranzutreiben. Dieser Artikel ist ein ausführlicher Bericht über das Unternehmen. Klicken Sie hier, um ihn schnell zu lesen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/V5VWB
Professor Tu Wei, Professor Lu Feng und andere von der Huazhong University of Science and Technology haben ein medizinisches Bildsegmentierungsmodell vorgeschlagen, das Lymphozytenaggregationsherde in pathologischen Bildern von Patienten mit Sjögren-Syndrom genau identifizieren kann und Ärzten so hilft, schnellere und genauere Diagnosen zu stellen. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/EetpB
Das Team von Zhang Shixin an der China University of Geosciences (Peking) forscht seit 2014 an visuell-taktilen Sensoren. Sie haben mehrere Generationen von Sensortechnologie erforscht und entwickelt und diese als hochmoderne taktile Technologie bezeichnet: TactEdge. Dieser Artikel stellt die relevanten Forschungsergebnisse ausführlich vor. Klicken Sie hier, um es schnell zu lesen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/nOE2a
Dieser Artikel konzentriert sich auf die KI-Forschung im Gesundheitswesen. Wir haben 35 topaktuelle Papiere ausgewählt, die im Zeitraum 2023–2024 interpretiert wurden, damit Sie sie als supertrockene Ware mit uns teilen können. Klicken Sie hier, um schnell zu lesen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/CZdYT
Die University of California, Berkeley, Microsoft Research und andere haben eine multimodale Methode zur Proteingenerierung namens PLAID vorgeschlagen, die eine multimodale Generierung erreichen kann, indem sie knappere Modalitäten aus reichhaltigeren Datenmodalitäten generiert. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/nwnDy
Beliebte Enzyklopädieartikel
1. Sigmoidfunktion
2. Reziproke Sortierfusion RRF
3. Nukleare Norm
4. Großes Sprachmodell
5. Langzeit-Kurzzeitgedächtnis
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








