Command Palette
Search for a command to run...
Für Die Pathologiebildanalyse Im Ultragroßen Maßstab! Die Huazhong University of Science and Technology Schlägt Ein Medizinisches Bildsegmentierungsmodell Vor, Um Die Genauigkeit Der Diagnose Des Sjögren-Syndroms Zu Verbessern
Trockener Mund, trockene Augen, trockene Haut, begleitet von unerklärlichen Muskelschmerzen und allgemeiner Müdigkeit jeden Tag. Wenn bei Ihnen die oben genannten Symptome auftreten, sollten Sie neben dem trockenen Wetter im Winter auch auf eine häufige, aber oft übersehene Krankheit achten: das Sjögren-Syndrom (SS).
Das Sjögren-Syndrom ist eine Autoimmunerkrankung, die durch eine hohe Lymphozyteninfiltration der exokrinen Drüsen gekennzeichnet ist.Etwa 5 Millionen Menschen in unserem Land leiden an dieser Krankheit. Im Frühstadium der Erkrankung kommt es zur Zerstörung der exokrinen Drüsen (Speicheldrüsen, Tränendrüsen etc.) durch stark infiltrierte Lymphozyten und damit zu einer Funktionsbeeinträchtigung. Die Patienten leiden häufig unter Mundtrockenheit und trockenen Augen und können auch Symptome wie Schmerzen in beiden Schultergelenken aufweisen. Gleichzeitig beeinträchtigt die Krankheit auch andere wichtige Organe wie Lunge, Leber und Nieren und beeinträchtigt sogar die Fruchtbarkeit.

Eine frühzeitige Erkennung und Diagnose des Sjögren-Syndroms ist von entscheidender Bedeutung, und die fokale lymphatische Sialadenitis (FLS) ist eines der wichtigsten Kriterien für die Diagnose des Sjögren-Syndroms. Durch die Entnahme pathologischer Abschnitte der kleinen Speicheldrüsen des Patienten und die Durchführung einer mikroskopischen Untersuchung gemäß den vorhandenen Diagnosekriterien,Wurden mehr als 50 Lymphozytenaggregate pro 4 mm2 Gewebeprobe gefunden, galt dies als typische Läsion.
Ein vollständiges Pathologie-Scanbild kann jedoch 100.000 x 100.000 Pixel erreichen, also etwa 1 Milliarde Pixel. Ärzte müssen das gesamte Bild sorgfältig untersuchen und die Anzahl der Lymphozytenaggregationsherde bestimmen. Dies ist nicht nur zeitaufwändig, sondern beruht häufig auch auf der Erfahrung und dem subjektiven Urteil professioneller Ärzte, wodurch das Risiko einer Fehldiagnose oder einer verpassten Diagnose steigt.
Um die oben genannten Herausforderungen zu bewältigen,Professor Tu Wei und Professor Lu Feng von der Huazhong University of Science and Technology haben das medizinische Bildsegmentierungsmodell M2CF-Net vorgeschlagen, das auf Computer-Vision-Technologie basiert, die in den Bereichen autonomes Fahren und Gesichtserkennung bekannt ist.Durch die Integration von Bilderkennungstechnologien mit mehreren Auflösungen und Maßstäben kann das M2CF-Net-Modell nicht nur subtile Unterschiede in pathologischen Bildern „sehen“, sondern auch wichtige Biomarker – Lymphozytenaggregationsherde – genau lokalisieren und zählen und so Ärzten dabei helfen, schnellere und genauere Diagnosen zu stellen.
Die Forschungsergebnisse wurden auf der IEEE International Conference on Medical Artificial Intelligence (MedAI) 2023 unter dem Titel „M2CF-Net: A Multi-Resolution and Multi-Scale Cross Fusion Network for Segmenting Pathology Lesion of the Focal Lymphocytic Sialadenitis“ veröffentlicht.
Forschungshighlights:
* Das Problem der Identifizierung winziger Lymphozytencluster in ultragroßen Gewebepathologiebildern wurde gelöst
* Durch die Integration mehrerer Auflösungen und Maßstäbe übertrifft M2CF-Net die anderen drei gängigen Modelle zur semantischen Segmentierung medizinischer Bilder
* M2CF-Net eignet sich gut zur Verarbeitung von Bildern mit unscharfen Grenzen, kleinen Objekten und komplexen Texturen. Seine segmentierten Bilder haben komplexere Formen und stimmen sehr gut mit der vom Menschen annotierten Grundwahrheit überein

Papieradresse:
https://doi.ieeecomputersociety.org/10.1109/MedAI59581.2023.00063
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Datensatz: Klinische Daten des Tongji-Krankenhauses
Diese Studie verwendet einen Satz pathologischer Datensätze kleiner Speicheldrüsenabschnitte des Tongji-Krankenhauses.Unter anderem wurden Patienten mit primärem Sjögren-Syndrom kleine Speicheldrüsen entfernt.
*Kleine Speicheldrüsen sind unter der Schleimhaut der menschlichen Mundhöhle und des Rachens verteilt. Ihre Funktion besteht darin, Speichel abzusondern, die Mundhöhle feucht zu halten, die Verdauung zu unterstützen und das Mundgewebe vor Infektionen zu schützen.
Durch die Färbung pathologischer Abschnitte kleiner Speicheldrüsen können Ärzte die klare Struktur der Zellen unter dem Mikroskop erkennen. Insbesondere überprüften die Forscher alle Objektträger zur Qualitätssicherung und um das Vorhandensein einer fokalen lymphatischen Pharyngitis zu bestätigen, die durch Ansammlungen von mehr als 50 Lymphozyten pro 4 Quadratmillimeter rund um die Drüse gekennzeichnet ist. Wenn eine Läsion vorliegt, wird sie markiert.
Der endgültige Datensatz besteht aus 203 Proben, darunter 171 positive Proben (die die Läsionsmerkmale erfüllen) und 32 negative Proben (die die Läsionsmerkmale nicht erfüllen).Die Forscher teilten diese Proben in einem bestimmten Verhältnis in Trainingssätze, Validierungssätze und Testsätze auf, die jeweils für das Modelltraining, die Anpassung und die Leistungsbewertung verwendet wurden. Im eigentlichen Prozess verarbeiteten die Forscher die Daten vor, was nicht nur den Rechenaufwand reduzierte, sondern auch die Generalisierungsfähigkeit des Modells verbesserte.
Entwurf einer groß angelegten Bildverarbeitungspipeline zur Optimierung des ersten Schritts des Modelltrainings
Das Ziel dieser Studie war es, den Läsionsbereich der fokalen lymphatischen Sialadenitis (FLS) aus Gewebeschnitten der kleinen Speicheldrüsen mit einer Auflösung von 100.000 * 100.000 zu extrahieren. Es ist jedoch nicht möglich, Gigapixel-Bilder direkt zum Training in neuronale Netzwerke einzugeben, hauptsächlich weil solche Bilder zu groß sind und die Rechenressourcen, die Trainingszeit, die vorhandenen Frameworks usw. nicht ausreichen, um sie zu unterstützen.
Aus diesem Grund haben die Forscher eine Pipeline für die Verarbeitung pathologischer Bilder im ultragroßen Maßstab entwickelt.Die Pipeline umfasst hauptsächlich drei Schritte: Extraktion von Regionen von Interesse (ROI), Fleckennormalisierung und Bildpatching (WSl Patching). Wie in der folgenden Abbildung dargestellt:
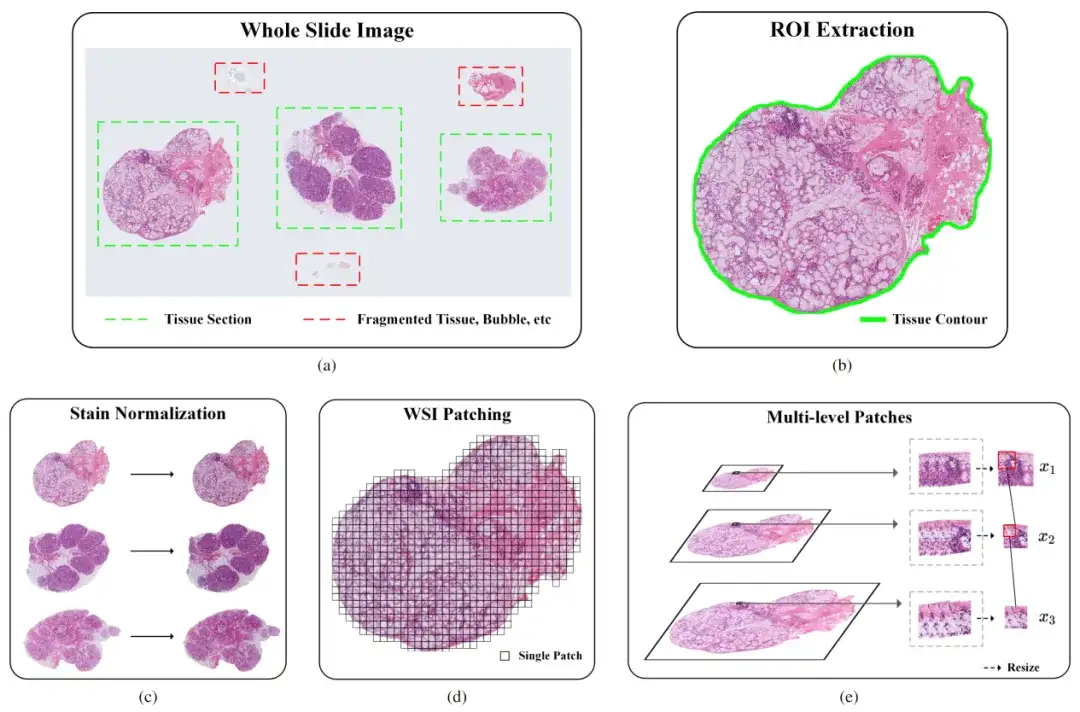
Teil 1: ROI-Extraktion
Um die Genauigkeit bei der Identifizierung bestimmter Gewebebereiche in pathologischen Bildern zu verbessern, verwendeten die Forscher zunächst einen auf einem Convolutional Neural Network (CNN) basierenden Klassifikator. Der Klassifikator hatte jedoch Schwierigkeiten bei der Verarbeitung komplexer Merkmale wie Blasen, fragmentiertem Gewebe und Artefakten, sodass seine Leistung nicht den Erwartungen entsprach. Um dieses Problem zu lösen, ergriff das Forschungsteam die folgenden Maßnahmen:
* Manuelle Annotation: Ein Teil der Proben wurde detailliert annotiert und das Klassifizierungsmodell wurde nach der Anreicherung des Datensatzes neu trainiert.
* Datenerweiterung: Verwenden Sie Techniken wie Rotation, Skalierung und Übersetzung, um die Vielfalt der Trainingsdaten zu erhöhen und so die Genauigkeit des Klassifikators zu verbessern.
Teil II: Färbestandardisierung
Der Hauptzweck der Standardisierung der Färbung pathologischer Bilder besteht darin, sicherzustellen, dass Bilder aus unterschiedlichen Quellen eine einheitliche visuelle Farbe und einen einheitlichen Kontrast aufweisen. Insbesondere aufgrund des Einflusses von Faktoren wie Farbstoffkonzentration, pH-Wert, Temperatur und Zeit kommt es im eigentlichen Färbeprozess häufig zu Problemen wie ungleichmäßiger Färbung oder inkonsistenter Intensität, was bei derselben Gewebeart zu unterschiedlichen optischen Effekten führt. Dieser Unterschied kann die Genauigkeit von Computer Vision-Modellen beeinträchtigen.
Um dieses Problem zu lösen, verwendeten die Forscher den Vahadane-Algorithmus. Der Algorithmus erzielt den Effekt der Farbstandardisierung, indem er die Farbeigenschaften des Quellbilds anpasst, um es dem Zielbild ähnlich zu machen. Insbesondere berechnet es die Farbmatrixtransformation zwischen dem Quellbild und dem Zielbild, um die Farbtransformation des Quellbildes zu erreichen.
Teil III: Bildsegmentierung
Damit soll das Problem behoben werden, dass die Bildgröße nach der ROI-Extraktion und Färbungsnormalisierung immer noch zu groß ist, sodass die Probe nicht zum Training in das Deep-Learning-Modell eingegeben werden kann. Die Forscher verwendeten eine patch-basierte Trainingsmethode, um das Bild in kleine Blöcke mit überlappenden Bereichen aufzuteilen. Dadurch wurde nicht nur die Effizienz des Modelltrainings verbessert, sondern auch die ursprünglichen Informationen erhalten.
Um die detaillierten Merkmale kleiner Lymphozyten in der Nähe größerer Gänge zu analysieren, ist es notwendig, Merkmale auf Gewebeebene über ein größeres Sichtfeld zu erfassen. Um jedoch die Genauigkeit der Segmentierungsergebnisse sicherzustellen, ist es notwendig, Merkmale auf Zellebene in einem kleineren Sichtfeld zu erfassen. Besonders wichtig ist, wie man zwischen beidem ein Gleichgewicht findet.
Zu diesem Zweck zogen die Forscher eine Methode zur Bildsegmentierung mit mehreren Auflösungen in Betracht, bei der es im Wesentlichen darum geht, das Originalbild mehrere Male herunterzuskalieren und aus diesen heruntergeskalierten Bildern Bildblöcke gleicher Größe zu extrahieren. Diese aus Bildern mit unterschiedlichen Abtastvergrößerungen ausgeschnittenen Patches verfügen über unterschiedlich große Sichtfelder, mit denen sich sowohl Merkmale auf Gewebeebene als auch auf Zellebene erfassen lassen.
Fusionsmodell mit mehreren Auflösungen und Maßstäben, effiziente Leistungsverbesserung
Das von den Forschern ausgewählte Modell M2CF-Net umfasst einen Multi-Branch-Encoder und einen fusionsbasierten Kaskadendecoder.Der Encoder führt ein Downsampling der Features von Patches mit unterschiedlichen Auflösungen in unterschiedlichen Maßstäben durch, während der Decoder einen kaskadierten Fusionsblock verwendet, um von Multi-Branch-Encodern generierte Feature-Maps zu fusionieren.
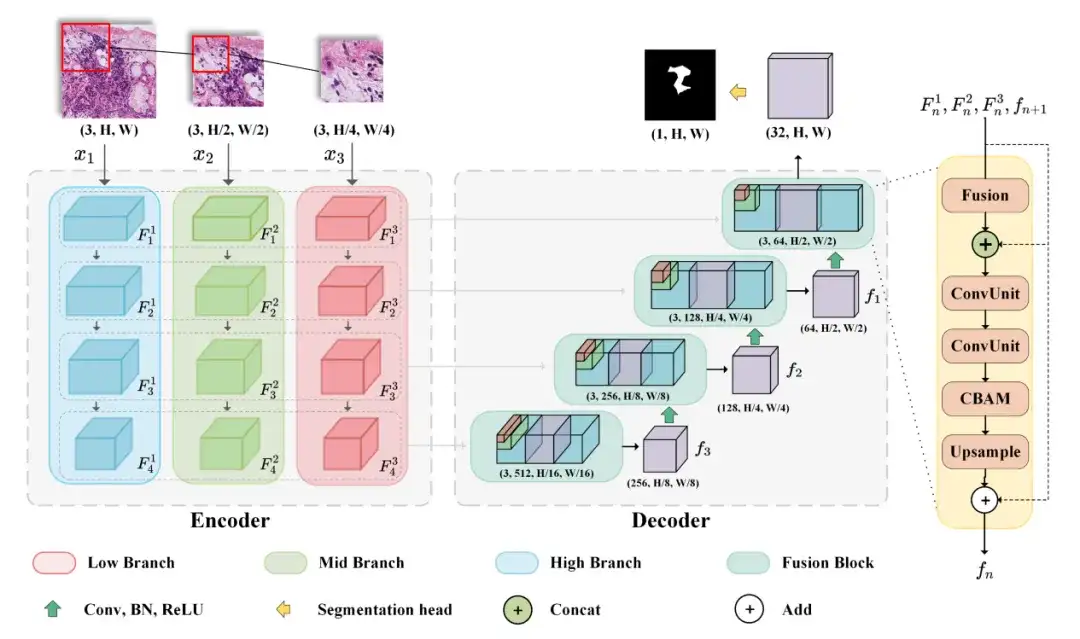
Um insbesondere gleichzeitig Merkmale auf Gewebe- und Zellebene zu erhalten, entwarfen die Forscher ein mehrzweigiges Netzwerk, ein typisches Encoder-Decoder-Architekturmodell, das Bilder unterschiedlicher Auflösungen als Eingabe akzeptieren kann. Der Encoder umfasst drei Eingabezweige, die Bilder mit unterschiedlicher Auflösung akzeptieren und während des Kodierungsprozesses Feature-Map-Kombinationen mit unterschiedlichen Sichtfeldern generieren. Der Decoder kann die vom Encoder generierten Feature-Maps mithilfe des kaskadierten Fusion-Blocks kombinieren, um die endgültige Vorhersagekarte auszugeben.
In diesem Prozess nutzten die Forscher auch räumliche Aufmerksamkeits- und Kanalaufmerksamkeitsmechanismen, um die Darstellungsmöglichkeiten der Eingabefunktionen zu verbessern. Schließlich wird BCEDice Loss als Verlustfunktion des Modells verwendet. Diese Verlustfunktion gewichtet den binären Kreuzentropieverlust und den Dice-Verlust, wodurch die Optimierungsrichtung des Modells effektiv gesteuert werden kann.
Experimentelles Fazit: M2CF-Net übertrifft die anderen drei gängigen Modelle zur semantischen Segmentierung medizinischer Bilder
Die Forscher verglichen ihr vorgeschlagenes Modell (M2CF-Net) mit vier anderen gängigen Modellen zur semantischen Segmentierung medizinischer Bilder – UNet, MSNet, HookNet und TransUNet. Die Ergebnisse zeigten, dass das M2CF-Net-Modell mehr Vorteile bei der Nutzung von Funktionen mit mehreren Auflösungen und Maßstäben bietet.
* UNet: verwendet eine Encoder-Decoder-Struktur, um mehrskalige Merkmale für eine genaue Segmentierung zu erfassen
* MSNet: Führt ein mehrskaliges Subtraktionsnetzwerk ein, um die Merkmalsextraktion zu verbessern und die Segmentierungsgenauigkeit zu steigern
* HookNet: Hook wird hinzugefügt, um Funktionen mit mehreren Auflösungen zu erfassen und zu nutzen, die U-Net-Struktur zu verbessern und die Segmentierung von Bildern unterschiedlicher Größe in medizinischen Bildern effektiv zu handhaben
* TransUNet: Basierend auf Transformer verbessert es die Segmentierungsgenauigkeit durch die Einführung eines Selbstaufmerksamkeitsmechanismus
Wie in der folgenden Abbildung dargestellt, stellten die Forscher fest, dass M2CF-Net den höchsten Dice von 69.40% erreichte und die Anzahl seiner Parameter nur halb so groß war wie die von TransUNet, das den dritten Platz belegte. Es übertraf UNet und MSNet, die weniger Parameter hatten, um 38,9% bzw. 22,5%.Es kann Merkmale unterschiedlicher Maßstäbe in Bildern effektiv erfassen und zusammenführen.

Insbesondere ist die Anzahl der Parameter (Params) von M2CF-Net geringer als die von TransUNet und HookNet, aber größer als die von UNet und MSNet. Dies liegt daran, dass TransUNet auf der Transformer-Architektur basiert, die im Vergleich zu CNN über mehr Parameter verfügt, und der Single-Branch-Decoder die Anzahl der Parameter von M2CF-Net geringer macht als die von HookNet. Allerdings führt die mehrzweigige Encoderstruktur in M2CF-Net zu einer höheren Parameteranzahl im Vergleich zum einzweigigen Eingabenetzwerk.
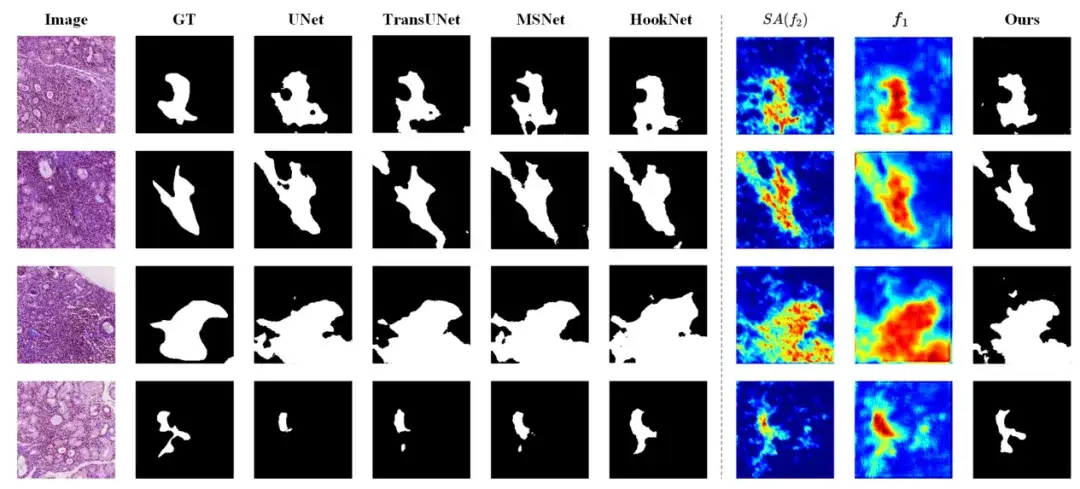
Darüber hinaus, nach eingehender Analyse,Die Studie ergab, dass M2CF-Net bei der Verarbeitung von Bildern mit unscharfen Grenzen, kleinen Objekten und komplexen Texturen gute Leistungen erbringt. Wie in der folgenden Abbildung gezeigt, weisen die Segmentierungsergebnisse von M2CF-Net komplexere Formen auf, die mit der vom Menschen annotierten Grundwahrheit übereinstimmen.
Computer-Vision-Technologie revolutioniert die medizinische Bildsegmentierung
Die medizinische Bildanalyse ist für die Krankheitsdiagnose von entscheidender Bedeutung. Mithilfe von Computertechnologie können medizinische Bilder präzise segmentiert und Läsionsbereiche, menschliche Organe und Infektionsherde effektiv identifiziert werden, wodurch die Diagnoseeffizienz verbessert wird. Dank der Weiterentwicklung moderner Technologien wie Deep Learning vollzieht sich in den letzten Jahren ein rascher Wandel von der manuellen zur automatisierten Bildsegmentierungstechnologie, und speziell trainierte KI-Systeme sind für medizinische Fachkräfte mittlerweile zu einem unverzichtbaren Hilfsmittel geworden.
Professor Tu Wei, stellvertretender Direktor der Abteilung für Rheumatologie und Immunologie, Tongji-Krankenhaus, Tongji Medical College, Huazhong University of Science and Technology,Er verfügt über mehr als 20 Jahre Erfahrung in der Diagnose und Behandlung von rheumatischen und immunologischen Erkrankungen und hat umfangreiche diagnostische Erfahrungen beim Sjögren-Syndrom. In dieser Studie analysierte Professor Tu Wei eingehend den pathologischen Diagnoseprozess des Sjögren-Syndroms, wies auf die Schlüsselpunkte hin, die leicht zu Verwechslungen führen können, und demonstrierte die Diagnoseergebnisse in verschiedenen Situationen anhand tatsächlicher Fälle. Nach der Beherrschung der pathologischen Diagnosemethode des Sjögren-Syndroms,Das Team von Professor Lu Feng schlug vor, zur Bewältigung diagnostischer Herausforderungen die Bildsegmentierungstechnologie in der Computervision einzusetzen.Die beiden Parteien haben fortschrittliche KI-Technologie genutzt, um einen neuen Weg für die Diagnose des Sjögren-Syndroms zu eröffnen.
Persönliche Homepage von Professor Tu Wei:
https://www.tjh.com.cn/MedicalService/outpatient_doctor.html?codenum=101110
Persönliche Homepage von Professor Lu Feng:
http://faculty.hust.edu.cn/lufeng2/zh_CN/index.htm
Zusätzlich zu den oben genannten Forschern gibt es viele Wissenschaftler, die sich der Spitzenforschung an der Schnittstelle zwischen medizinischer Bildgebung und KI widmen.
Beispielsweise hat ein Team des Computer Science and Artificial Intelligence Laboratory (MIT CSAIL) des Massachusetts Institute of Technology in Zusammenarbeit mit Forschern des Massachusetts General Hospital und der Harvard Medical School ein allgemeines Modell namens ScribblePrompt für die interaktive biomedizinische Bildsegmentierung vorgeschlagen.Dieses auf neuronalen Netzwerken basierende Segmentierungstool unterstützt nicht nur Annotatoren mit verschiedenen Annotationsmethoden wie Kritzeleien, Klicks und Begrenzungsrahmen bei der Durchführung flexibler biomedizinischer Bildsegmentierungsaufgaben, sondern funktioniert auch gut bei nicht trainierten Beschriftungen und Bildtypen.
Ich bin davon überzeugt, dass viele medizinische Fachbereiche wie die Onkologie und die Neurologie von der Entwicklung und Anwendung fortschrittlicherer Technologien in der klinischen Praxis profitieren werden und dass sich dem Bereich der medizinischen Bildanalyse bessere Entwicklungsaussichten eröffnen werden.








