Command Palette
Search for a command to run...
Das Tutorial Zur Verwendung Von A6000 Mit Einer Einzelnen Karte Zum Starten Von AlphaFold3 Mit Einem Klick Ist Jetzt Online! 360-Grad-Motion-Capture-Datensatz Veröffentlicht, Der Mehr Als 70.000 Videos Und 50 Physische Objekte Umfasst

Letzte Woche hat HyperAl die AlphaFold3-Abhängigkeitsdatenbank aktualisiert, aber viele Freunde berichteten, dass die Daten zu groß und schwierig bereitzustellen seien.
Diese Woche,Auf der offiziellen Website von hyper.ai wurde die „AlphaFold3 Protein Prediction Demo“ gestartet.Die relevanten Daten und Modelle wurden installiert und konfiguriert und belegen weniger als 300 MB persönlichen Speicherplatz. Außerdem ist nur eine einzige A6000-Karte erforderlich, um AlphaFold3 schnell bereitzustellen und zur Vorhersage von Proteinen zu verwenden.
Online-Nutzung:https://go.hyper.ai/KHIRR
Vom 16. bis 20. Dezember gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 3
* Community-Artikelauswahl: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadlines im Januar: 9
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Datensatz zur Drohnenerkennung
Der Datensatz besteht aus über 10.000 Drohnenbildern mit kommentierten Begrenzungsrahmen um jede Drohne. Begrenzungsrahmen liefern präzise Positionsinformationen zum Erkennen und Verfolgen von Drohnen vor unterschiedlichen Hintergründen und in unterschiedlichen Umgebungen. Der Datensatz eignet sich zum Trainieren und Evaluieren von Computer-Vision-Modellen für Objekterkennungsaufgaben, insbesondere in Anwendungen wie Überwachung, Drohnenerkennung und autonomes Tracking.
Direkte Verwendung:https://go.hyper.ai/686JV

2. 360Motion-Datensatz Motion Capture-Datensatz
Die V1-Version dieses Datensatzes enthält 72.000 Videos zu 50 verschiedenen Entitäten, beispielsweise verschiedenen Tieren, und 6 Unreal Engine (UE)-Szenen, darunter 1 Wüstenszene und 2 HDRI-Szenen. Darüber hinaus enthält der Datensatz auch 121 verschiedene Trajektorienvorlagen, die den Forschern umfangreiche Bewegungsmuster und Verhaltensänderungen liefern.
Direkte Verwendung:https://go.hyper.ai/rsmeQ

Dieser Datensatz wird verwendet, um Hirntumore mithilfe verschiedener Modelle zu klassifizieren und zu segmentieren. Es enthält insgesamt 7.153 Bilder, darunter 1.621 Gliombilder, 1.775 Meningiombilder, 1.757 Hypophysenbilder und 2.000 tumorfreie (gesunde Gehirn-)Bilder.
Direkte Verwendung:https://go.hyper.ai/zgX7A
4. LAION-SG Großer, hochwertiger Datensatz zum Verständnis von Bildern
LAION-SG enthält 540.005 Szenengraph-Bild-Paare mit Objekt-, Attribut- und Relationsanmerkungen, die in Trainings-, Validierungs- und Testsätze unterteilt sind. Die Bilder im Datensatz stammen aus dem Datensatz LAION-Aesthetics V2 (6.5+) und der Annotationsprozess verwendet GPT-4o für die automatische Annotation.
Direkte Verwendung:https://go.hyper.ai/HHT6V

5. Datensatz zu Kleidungsattributen Datensatz zu Kleidungsattributen
Der Datensatz enthält 1.856 Bilder mit 26 grundlegenden Kleidungsmerkmalen, wie etwa lange Ärmel, Kragen und Streifenmuster. Die Etiketten wurden mit Amazon Mechanical Turk gesammelt.
Direkte Verwendung:https://go.hyper.ai/7f3ej

6. Erkennen Sie KI-generierte Gesichter – Gesichtserkennungsdatensatz
Der Datensatz enthält 3.203 hochwertige Bilder von echten Gesichtern und KI-generierten synthetischen Gesichtern, darunter 2.202 echte Bilder und 1.001 KI-generierte Bilder, und ist für Anwendungen des maschinellen Lernens und Deep Learning konzipiert. Ziel ist es, Gesichtsbildressourcen bereitzustellen, die zwischen echten und von KI generierten Gesichtern unterscheiden können. Es eignet sich für Aufgaben wie die Erkennung von Deep Fakes, die Überprüfung der Bildauthentizität und die Analyse von Gesichtsbildern und kann Spitzenforschung und -anwendungen unterstützen.
Direkte Verwendung:https://go.hyper.ai/SwMXL

7. U-MATH-Datensatz zum mathematischen Denken
Der Datensatz enthält 1,1.000 unveröffentlichte Mathematikaufgaben auf College-Niveau, die aus echtem Unterrichtsmaterial stammen, und deckt sechs Kernthemen der Mathematik ab: Elementarmathematik, Algebra, Differentialrechnung, Integralrechnung, Analysis mit mehreren Variablen sowie Folgen und Reihen.
Direkte Verwendung:https://go.hyper.ai/FcNc2
8. Open01-SFT überwachter Feinabstimmungsdatensatz
Der OpenO1-SFT-Datensatz konzentriert sich auf die Aktivierung der Gedankenkettenfähigkeit von Sprachmodellen mithilfe der Methode der überwachten Feinabstimmung (SFT), mit dem Ziel, die Fähigkeit des Modells zur Generierung kohärenter logischer Schlussfolgerungssequenzen zu verbessern. Es enthält 77.685 Datensätze, die nicht nur Chinesisch, sondern auch Englisch abdecken, wodurch der Datensatz in mehrsprachigen Umgebungen nützlich ist.
Direkte Verwendung:https://go.hyper.ai/KlyzY
9. QwQ-LongCoT-130K Feinabstimmungsdatensatz
Der QwQ-LongCoT-130K-Datensatz ist ein SFT-Datensatz (Supervised Fine-Tuning), der für das Training großer Sprachmodelle (LLMs) wie O1 entwickelt wurde. Dieser Datensatz enthält etwa 130.000 Instanzen, von denen jede eine mit dem Modell QwQ-32B-Preview generierte Antwort ist.
Direkte Verwendung:https://go.hyper.ai/kE9aG
Der Datensatz wurde mithilfe der Suchanfrage „Maschinelles Lernen und Gesundheitswesen“ von Google Patents zusammengestellt und umfasst erteilte Patente in Bereichen von der medizinischen Bildgebung über Diagnosetools bis hin zu KI-gesteuerten Behandlungsempfehlungen.
Direkte Verwendung:https://go.hyper.ai/8p1M5
Ausgewählte öffentliche Tutorials
1. Demo zur AlphaFold3-Proteinvorhersage
AlphaFold3 ist ein Tool für künstliche Intelligenz (KI), das 2024 von Google DeepMind entwickelt wurde. Das AlphaFold 3-Modell verwendet eine diffusionsbasierte Architektur, die nicht nur Proteinstrukturen vorhersagen kann, sondern auch die Strukturen von Komplexen, einschließlich Nukleinsäuren, kleinen Molekülen, Ionen und modifizierten Rückständen, genau vorhersagen kann.
Dieses Tutorial zeigt, wie Sie AlphaFold3 schnell bereitstellen und zur Vorhersage von Proteinen verwenden können. Sie benötigen zum Ausführen des Erlebnisses nur eine einzige A6000-Karte.
Online ausführen:https://go.hyper.ai/KHIRR
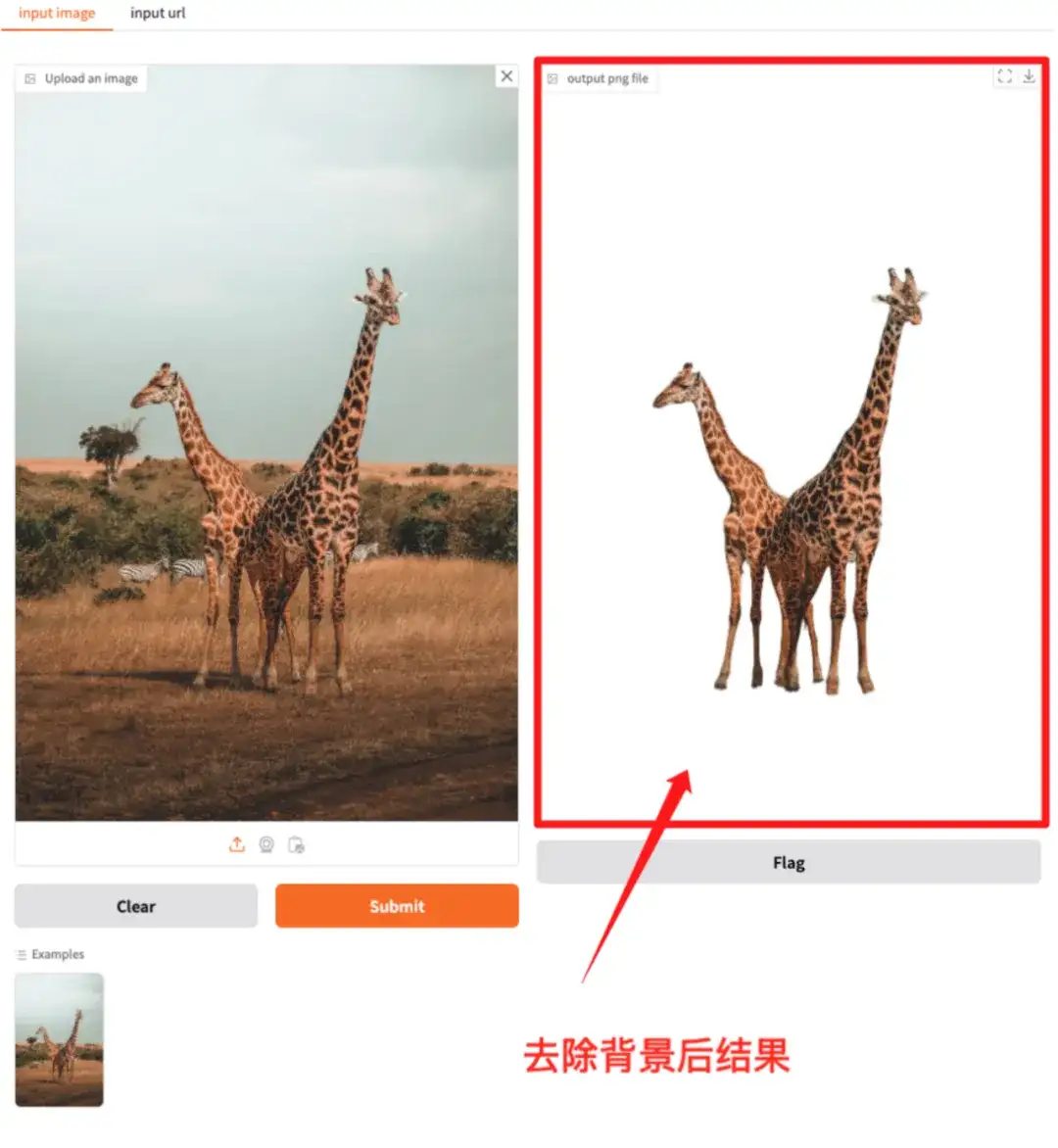
2. RMBG-2.0: Open-Source-Modell zur Hintergrundentfernung
RMBG-2.0 ist ein Open-Source-Hintergrundsubtraktionsmodell, das dazu dient, Vordergrund und Hintergrund in einer Vielzahl von Kategorien und Bildtypen effektiv zu trennen.
Das Modell hat die Umgebung und Abhängigkeiten konfiguriert. Sie können die API-Adresse eingeben, um das Zuschneiden von Bildern mit einem Klick zu erleben.
Online ausführen:https://go.hyper.ai/FF10L
3. DePLM: Optimierung von Proteinen mit rauschfreien Sprachmodellen (kleine Stichproben)
Das Denoised Protein Language Model (DePLM) kann die vom Proteinsprachenmodell erfassten evolutionären Informationen als eine Mischung aus relevanten und irrelevanten Informationen für die optimierten Zieleigenschaften behandeln, wobei irrelevante Informationen als „Rauschen“ betrachtet und eliminiert werden. Dadurch wird die Genauigkeit des Modells bei der Vorhersage der adaptiven Proteinlandschaft verbessert und die Identifizierung der funktionell optimalen Sequenz für die Optimierung unterstützt.
In diesem Tutorial geht es um das Training und die Inferenz des von der Zhejiang-Universität veröffentlichten Denoising Protein Language Model (DePLM). Die entsprechenden Ergebnisse wurden für „NeurIPS 24“ ausgewählt. Die Plattform hat die erforderliche Umgebung und den erforderlichen Datensatz konfiguriert. Sie können Training und Inferenz durchführen, indem Sie die im Tutorial angegebenen Befehle direkt ausführen.
Online ausführen:https://go.hyper.ai/ktd87
Wir haben außerdem eine Tutorial-Austauschgruppe zum Thema „Stabile Diffusion“ eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Community-Artikel
Kürzlich gab Enveda, ein KI-Pharma-Startup in den USA, den Abschluss einer Serie-C-Finanzierungsrunde in Höhe von 130 Millionen US-Dollar bekannt, womit sich die Gesamtfinanzierungssumme auf 360 Millionen US-Dollar beläuft. Darüber hinaus erhielt ENV-294, der erste mithilfe der Enveda-Plattform entdeckte Arzneimittelkandidat, Ende Oktober dieses Jahres die IND-Zulassung der US-amerikanischen FDA und trat in die Phase I der klinischen Erprobung ein. Dieser Artikel ist ein ausführlicher Bericht über das Unternehmen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/rMk2U
Aufgrund der besonderen geografischen Lage des Qinghai-Tibet-Plateaus sind Daten zum Oberflächenwärmefluss in einigen zerklüfteten Gebieten sehr rar. Um dieses Problem zu lösen, hat die Fakultät für Geowissenschaften der Zhejiang-Universität ein geographisches, neuronales Netzwerk-gewichtetes Regressionsmodell mit verbesserter Interpretierbarkeit vorgeschlagen, das einen neuen Forschungsrahmen und technische Unterstützung für ein umfassendes Verständnis der Wärmeflussverteilung und des geodynamischen Mechanismus des Qinghai-Tibet-Plateaus bietet. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/vqQDi
In der fünften Live-Übertragung von Meet AI4S stellte Wang Zeyuan, Doktorand am Knowledge Engine Laboratory der Zhejiang-Universität, eine für NeurlPS 2024 ausgewählte Errungenschaft vor und führte eine Demo vor. Er stellte auch seine Erfahrungen mit der Unterwerfung vor. Es enthält zahlreiche praktische Informationen. Klicken Sie also, um es schnell anzusehen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/PLyBo
Googles DeepMind und Google Research haben eine Reihe von Ergebnissen im Bereich der Wettervorhersage veröffentlicht. Dabei werden kurzfristige, mittelfristige und langfristige Prognosen berücksichtigt, traditionelle Methoden mit KI integriert und schrittweise ein „sechseckiger Krieger“ für die Wettervorhersage aufgebaut.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Cvzkc
Beliebte Enzyklopädieartikel
1. Reziproke Sortierfusion RRF
2. Maskierte Sprachmodellierung (MLM)
3. Nukleare Norm
4. Kolmogorov-Arnold-Darstellungssatz
5. Datenerweiterung
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!








