Command Palette
Search for a command to run...
Die Von Alphafold3 Abhängige Datenbank Wurde Verpackt Und Gestartet! ICLR-Komplettnotenpapier IC-Light: Helle Tonmerkmale Genau Identifizieren

AlphaFold2 hat seit seiner Veröffentlichung im AI4S-Bereich für Aufsehen gesorgt und in diesem Jahr sogar den Nobelpreis gewonnen. In seiner verbesserten Version kann AlphaFold3 nicht nur die Struktur von Proteinen vorhersagen, sondern auch die Struktur der Wechselwirkungen zwischen Proteinen und verschiedenen anderen biologischen Molekülen, einschließlich der Art und Weise, wie sich Liganden (kleine Moleküle) und Nukleinsäuren (DNA und RNA) zusammenfinden und miteinander interagieren.
Erst letzten Monat hat Google DeepMind die AlphaFold3-Modellgewichte und seine Abhängigkeitsdatenbank für die akademische Forschung als Open Source freigegeben. HyperAl hat jetzt die Abhängigkeitsdatenbank AlphaFold3 gestartet. Jeder ist herzlich eingeladen, beim Lesen des Artikels die technologischen Durchbrüche von AlphaFold3 kennenzulernen!
Online-Nutzung:https://go.hyper.ai/wVItz
Vom 9. bis 13. Dezember gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 3
* Community-Artikelauswahl: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadlines im Januar: 9
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Alphafold3 ist von der Datenbank abhängig
Die Datenbank enthält eine große Anzahl von Protein- und RNA-Datenbanken, auf die AlphaFold 3 angewiesen ist, darunter 9 Datenbanken: BFD small, MGnify, PDB, PDB seqres, UniProt, UniRef90, NT, RFam und RNACentral.
Direkte Verwendung:https://go.hyper.ai/wVItz
2. Mol-Instructions – Großer Anweisungsdatensatz für Biomoleküle
Der Datensatz enthält drei Arten von Anweisungen: molekülorientierte Anweisungen, proteinorientierte Anweisungen und biomolekulare Textanweisungen. Ziel ist es, umfangreiche Anweisungsdaten bereitzustellen, um das Verständnis und die Vorhersagefähigkeiten großer Sprachmodelle im Bereich der Biomoleküle zu verbessern.
Direkte Verwendung:https://go.hyper.ai/Gut1y
3. CoSQL-Konversationstext zum SQL-Datensatz
CoSQL enthält über 3.000 Konversationsgruppen und insgesamt über 10.000 kommentierte SQL-Abfragen, die sich über 200 Datenbanken erstrecken. Um die Robustheit des Modells zu prüfen, gibt es zwischen den von den verschiedenen Datengruppen verwendeten Datenbanken keine Überschneidungen.
Direkte Verwendung:https://go.hyper.ai/9Blzy

4. QAngaroo-Datensatz zum mehrstufigen Schlussfolgerungslesen
Der Datensatz besteht aus zwei Teilen: WikiHop und MedHop. Ziel ist es, eine Leseverständnismethode zu entwickeln, die Multi-Hop-Schlussfolgerungen durchführen kann, d. h., aus in verschiedenen Dokumenten verstreuten Fakten sind mehrere Schlussfolgerungsschritte erforderlich, um neue Fakten abzuleiten.
Direkte Verwendung:https://go.hyper.ai/u1qRw

5. TCM Ancient Books Traditionelle Chinesische Medizin Ancient Books Dataset
Dieser Datensatz enthält etwa 700 alte chinesische Medizintexte und umfasst medizinische Klassiker von der Zeit vor der Qin-Dynastie bis zur späten Qing-Dynastie und der Republik China. Diese Dokumente umfassen nicht nur medizinische Theorien, Rezepte, Pharmakologie usw., sondern enthalten auch umfangreiche klinische Fälle und medizinisches Enzyklopädiewissen.
Direkte Verwendung:https://go.hyper.ai/8Vh6A
6. IndustryCorpus2 Healthcare-Datensatz-Teilmenge
Bei diesem Datensatz handelt es sich um eine hochwertige Datenressourcenbibliothek speziell für die Forschung und Anwendung im Bereich der medizinischen Gesundheit. Es wurde einem strengen Prüf- und Bereinigungsprozess unterzogen, um die Genauigkeit und Zuverlässigkeit der Daten sicherzustellen. Es deckt ein breites Spektrum an Datentypen im Gesundheitsbereich ab, darunter Krankenakten, medizinische Literatur und Patientenfeedback, und bietet Forschern und Entwicklern eine umfassende Perspektive für die Erforschung und Innovation.
Direkte Verwendung:https://go.hyper.ai/G9qn2
7. P-MMEval Mehrsprachiger Multitasking-Benchmark-Datensatz
Der Datensatz enthält 3 grundlegende Datensätze zur Verarbeitung natürlicher Sprache (NLP) und 5 erweiterte fähigkeitsspezifische Datensätze, die Aufgaben wie Codegenerierung, Wissensverständnis, mathematisches Denken, logisches Denken und Befolgen von Anweisungen abdecken.
Direkte Verwendung:https://go.hyper.ai/qbzhv
8. ShenNong TCM-Datensatz ShenNong TCM-Datensatz
Dieser Datensatz enthält mehr als 110.000 Anweisungsdaten, die durch eine entitätszentrierte Selbstinstruktionsmethode generiert werden. Es konzentriert sich auf die Kernelemente und verschiedenen Absichtsszenarien im Bereich der traditionellen chinesischen Medizin. Es kann nicht nur die Fähigkeit des Modells verbessern, Fragen im Zusammenhang mit der traditionellen chinesischen Medizin zu beantworten, sondern auch bei der Diagnose der traditionellen chinesischen Medizin helfen und personalisierte medizinische Beratung bieten.
Direkte Verwendung:https://go.hyper.ai/Okruv
9. DS-1000 Codegenerierungs-Benchmark-Datensatz
Der Datensatz enthält 1.000 reale Data-Science-Fragen von StackOverflow und deckt 7 weit verbreitete Data-Science-Bibliotheken in Python ab, wie z. B. NumPy, Pandas, TensorFlow usw.
Direkte Verwendung:https://go.hyper.ai/AL4h0
10. IndustryCorpus2-Tourismus-Geographie Tourismusgeographie-Datensatz
Dieser Datensatz ist eine Teilmenge des Tourismusgeographie-Datensatzes von IndustryCorpus2, der ein breites Spektrum an Datentypen im Bereich der Tourismusgeographie abdeckt, darunter Vorstellungen von Sehenswürdigkeiten, Reiseführer, Touristenrezensionen und geografische Informationen, und reichhaltige Anwendungsszenarien für verschiedene Forschungs- und Anwendungsfelder wie die Verarbeitung natürlicher Sprache, maschinelles Lernen, Data Mining und Tourismus-Empfehlungssysteme bietet.
Direkte Verwendung:https://go.hyper.ai/FIAM9
Ausgewählte öffentliche Tutorials
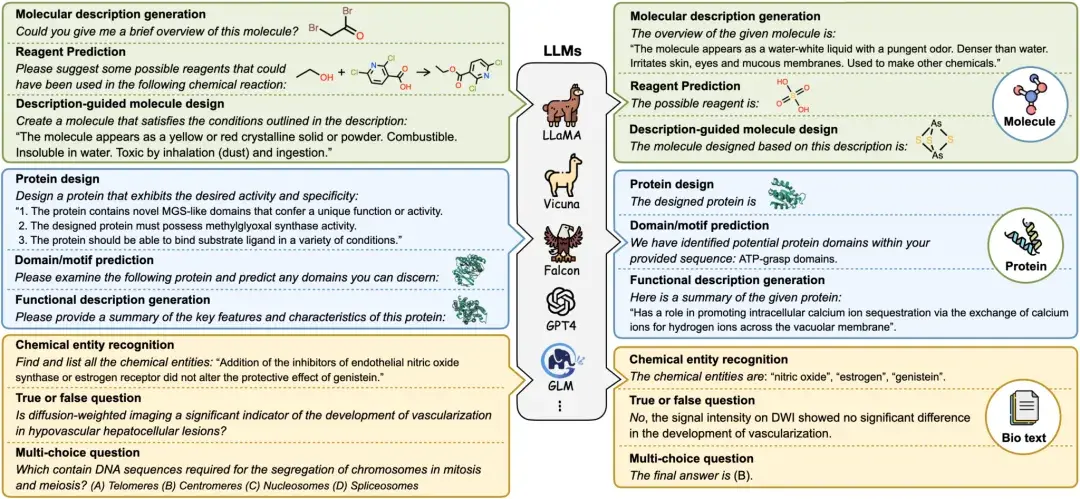
1. Allegro-Videogenerierungsdemo
Allegro kann einfache Texteingaben in hochauflösende Videoinhalte mit einer Auflösung von 720p, 15 Bildern pro Sekunde und einer maximalen Videolänge von 6 Sekunden umwandeln. Das Modell zeigt eine hervorragende Leistung im Bereich der Videosynthese und zeichnet sich sowohl durch Qualität als auch durch zeitliche Kohärenz aus.
Dieses Tutorial ist ein Tutorial zur Modellinferenz. Da es lange dauert, bis das Modell ein Video generiert, kann dieses Tutorial einen 5-Sekunden-Videoeffekt erzeugen.
Online ausführen:https://go.hyper.ai/MgUVZ
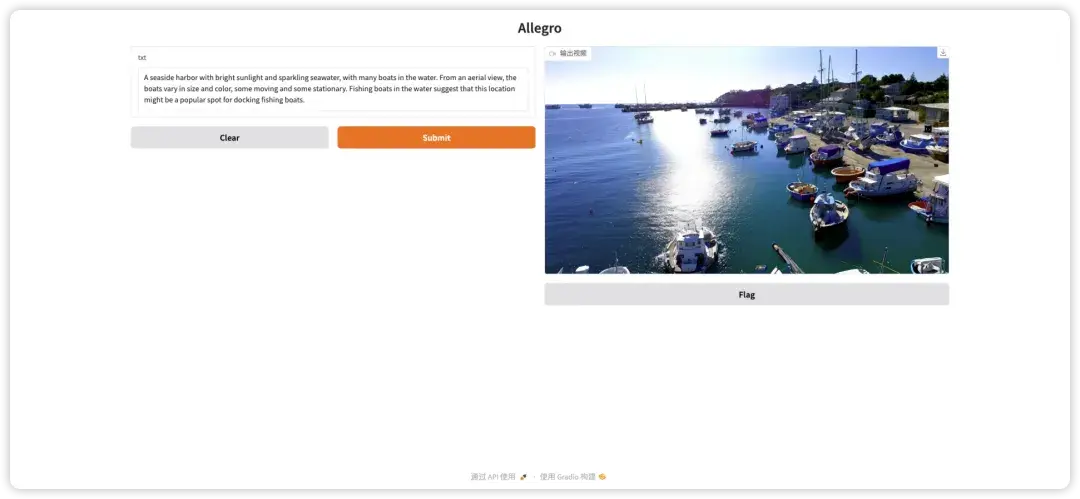
2. IC-Light v2: Demo zum Upgrade der KI-Lichtsteuerung
IC-Light steht für Imposing Consistent Light, ein Projekt, das eine Neubeleuchtung von Bildern durch Modelle des maschinellen Lernens zum Ziel hat. Dieses Tutorial ist eine aktualisierte Version von IC-Light v2. Im Vergleich zum ursprünglichen IC-Light basiert das Training dieser Version auf dem Flux-Modell, wodurch die Beleuchtungs- und Toneigenschaften des Bildes genauer erkannt und ein detaillierterer und realistischerer Fusionseffekt erzielt werden können.
Klicken Sie auf den Link unten und folgen Sie dem Tutorial, um die Lichteffekte in Ihrem Bild zu steuern.
Online ausführen:https://go.hyper.ai/hg0cM
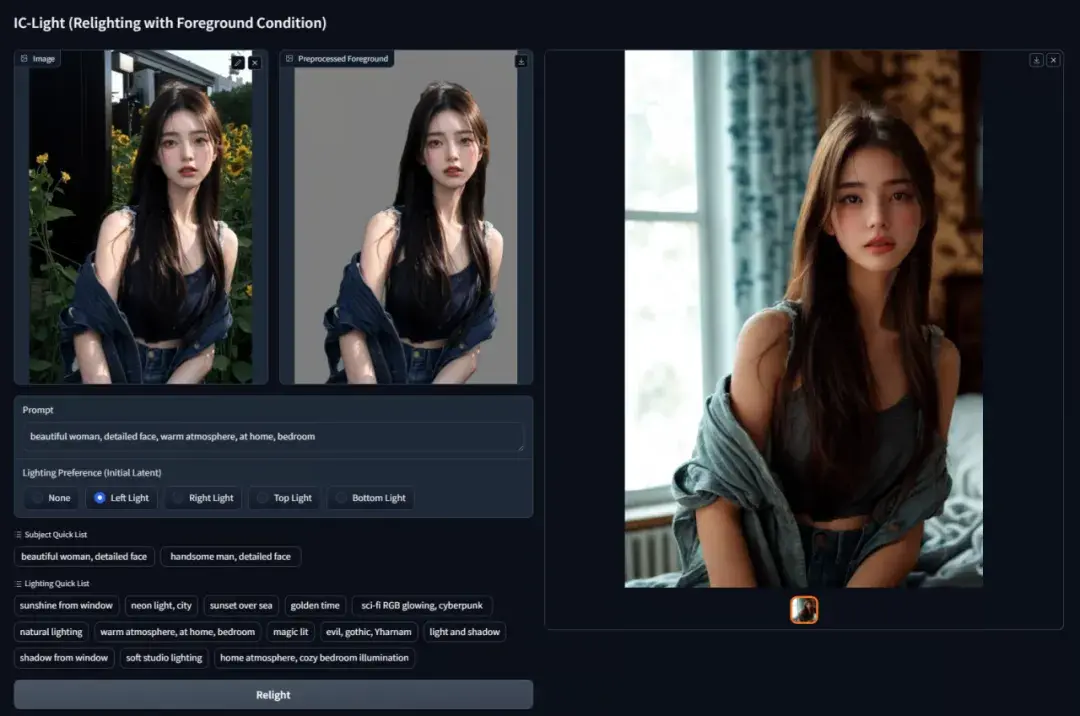
3. Hunyuan3D: Generieren Sie 3D-Assets in nur 10 Sekunden
Hunyuan3D ist ein generatives 3D-Diffusionsmodell, das eine leichte und eine Standardversion umfasst, die beide die Generierung hochwertiger 3D-Assets aus Text- und Bildeingaben unterstützen. Nach der qualitativen und quantitativen mehrdimensionalen Bewertung schnitt Hunyuan3D-1.0 in Bezug auf geometrische Details, Texturdetails, Konsistenz von Textur und Geometrie, 3D-Rationalität und Anweisungskonformität sehr gut ab.
Dieses Tutorial ist eine abgespeckte Version von Hunyuan3D. Klicken Sie auf den Link unten und folgen Sie den Anweisungen des Tutorials, um die 3D-Modellerstellung kennenzulernen.
Online ausführen:https://go.hyper.ai/Rsrno
Community-Artikel
Als Startup-Unternehmen sollte die Stärke von CuspAI nicht unterschätzt werden. Die Seed-Finanzierungsrunde erreichte 30 Millionen US-Dollar und war damit eine der größten Seed-Finanzierungsrunden in Europa in diesem Jahr. Darüber hinaus ist der Experte für maschinelles Lernen Max Welling einer der Mitbegründer des Unternehmens und der Nobelpreisträger und Turing-Award-Gewinner Geoffrey Hinton ist Vorstandsberater seines Unternehmens. Dieser Artikel ist eine ausführliche Einführung in CuspAI.
Den vollständigen Bericht ansehen:https://go.hyper.ai/3fQFG
Mit der zunehmenden Verbreitung der KI-Technologie in unserem Alltagsleben ist die „Erklärbarkeit“ von Modellen allmählich zu einem Problem geworden, das dringend angegangen werden muss. Dieses Problem tritt insbesondere bei Aufgaben zur Zeitreihenprognose auf. Um die Vorhersage von Zeitreihen zu einem „sichtbaren“ Prozess zu machen, hat das Team von Lu Feng von der Huazhong University of Science and Technology in Zusammenarbeit mit dem Team von Akademiker Zomaya von der University of Sydney und dem Tongji Hospital eine neue Methode vorgeschlagen: CGS-Mask. Durch die Kombination von Zeitreihenvorhersage und Interpretierbarkeit kann diese Methode nicht nur die Vorhersagegenauigkeit des Modells verbessern, sondern auch die Vorhersageergebnisse intuitiver und erklärbarer machen. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/TFEsd
Ein Forscherteam der Stanford University und des Arc Institute in den USA schlug ein genombasiertes Modell Evo vor, das als Titelartikel in Science veröffentlicht wurde. Es ermöglicht eine Zero-Shot-Vorhersage und hochpräzise Generierung bei multimodalen Aufgaben von DNA, RNA und Protein. Der Abschnitt „HyperAI Hyper-Neural Tutorial“ ist jetzt online: „Evo: Vorhersage und Generierung vom molekularen bis zum genomischen Maßstab“, der mit dem Klonen per Mausklick schnell erlernt werden kann!
Den vollständigen Bericht ansehen:https://go.hyper.ai/5WPGm
Der KI-Pate Hinton wurde in eine Familie von Genies hineingeboren, war jedoch ein notorischer Schulabbrecher. sein Startup-Unternehmen hatte nur drei Mitarbeiter, wurde aber von Google für 44 Millionen Dollar übernommen; Er verbrachte fast ein halbes Jahrhundert mit der Entwicklung neuronaler Netzwerke, drückte jedoch offen sein Bedauern aus ... Welche Lebenserfahrungen haben ihn zu dem gemacht, was er heute ist? Dieser Artikel ist ein ausführlicher Bericht über Hinton.
Den vollständigen Bericht ansehen:https://go.hyper.ai/EHWs6
vLLM ist ein Framework, das für die Beschleunigung der Argumentation großer Sprachmodelle entwickelt wurde und bei dem die Verschwendung von KV-Cache-Speicher nahezu auf Null reduziert wird. Die neueste Version v0.6.4 führt eine mehrstufige Planung und asynchrone Ausgabeverarbeitung ein, wodurch die GPU-Auslastung weiter optimiert und die Verarbeitungseffizienz verbessert wird. Um inländischen Entwicklern den Einstieg in die vLLM-Versionsaktualisierungen und neuesten Entwicklungen zu erleichtern, hat die HyperAI Super Neural Community die Lokalisierung der chinesischen vLLM-Dokumentation abgeschlossen.
Chinesische vLLM-Dokumentation anzeigen:https://vllm.hyper.ai/
Beliebte Enzyklopädieartikel
1. Mel-Frequenz-Cepstrum-MFCCs
2. Reziproke Sortierfusion RRF
3. Maskierte Sprachmodellierung (MLM)
4. Pareto-Front
5. Datenerweiterung
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








