Command Palette
Search for a command to run...
Sagen Sie Die Arbeitslosenquote Und Armutsquote in Den Vereinigten Staaten Genau voraus. Googles Grundlegendes Modell Der Bevölkerungsdynamik PDFM Wurde Als Open Source Veröffentlicht, Um Bestehende Geodatenmodelle Zu Verbessern

Krankheiten, Wirtschaftskrisen, Arbeitslosigkeit, Katastrophen … die Welt der Menschheit wird seit langem von verschiedenen Problemen „heimgesucht“.Das Verständnis der Bevölkerungsdynamik ist für die Lösung komplexer sozialer Probleme wie dieser von entscheidender Bedeutung.Regierungsbeamte können Daten zur Bevölkerungsdynamik nutzen, um die Ausbreitung von Krankheiten zu simulieren, Immobilienpreise und Arbeitslosenquoten vorherzusagen und sogar Wirtschaftskrisen vorherzusagen. Allerdings war es für Forscher und politische Entscheidungsträger in den letzten Jahrzehnten eine Herausforderung, die Bevölkerungsdynamik präzise vorherzusagen.
Traditionelle Ansätze zum Verständnis der Bevölkerungsdynamik basieren häufig auf Daten aus Volkszählungen, Umfragen oder Satellitenbildern. Diese Daten sind zwar wertvoll, weisen jedoch jeweils ihre eigenen Mängel auf. Beispielsweise sind Volkszählungen zwar umfassend, aber selten und kostspielig durchzuführen. Umfragen können zwar lokale Erkenntnisse liefern, es mangelt ihnen jedoch oft an Umfang und Allgegenwärtigkeit. und Satellitenbilder bieten zwar einen umfassenden Überblick, es fehlen jedoch detaillierte Informationen über menschliche Aktivitäten. Um diese Mängel auszugleichen, hat Google im Laufe der Jahre riesige Datensätze aufgebaut, in der Hoffnung, das demografische Verhalten zu verstehen.
Vor Kurzem hat Google ein neuartiges Population Dynamics Foundation Model (PDFM) vorgeschlagen, das maschinelles Lernen nutzt, um die umfangreichen, weltweit verfügbaren Geodaten zu integrieren und so die Möglichkeiten herkömmlicher Geomodelle erheblich zu erweitern.Die Forscher haben PDFM anhand von Interpolations-, Extrapolations- und Superauflösungsproblemen anhand von 27 Aufgaben aus den Bereichen Gesundheit, Sozioökonomie und Umwelt verglichen. Die Studie ergab, dass PDFM bei allen 27 Aufgaben und bei 25 Extrapolations- und Superauflösungsaufgaben eine hochmoderne Leistung bei der Interpolation erreichte.Die Forscher zeigten außerdem, dass PDFM mit einem hochmodernen Prognosebasismodell (TimesFM) kombiniert werden kann, um Arbeitslosen- und Armutsraten erfolgreich vorherzusagen und dabei vollständig überwachte Prognosemethoden zu übertreffen.
Die zugehörige Forschung wurde auf arXiv unter dem Titel „General Geospatial Inference with a Population Dynamics Foundation Model“ veröffentlicht. Gleichzeitig veröffentlichten die Forscher alle PDFM-Einbettungen und Beispielcodes auf GitHub, um der Forschungsgemeinschaft die Anwendung auf neue Anwendungsfälle zu erleichtern und die akademische Forschung und Praxis weiter zu stärken.
Adresse der Open Source des PDFM-Projekts:
https://github.com/google-research/population-dynamic
Forschungshighlights:
* Die Forscher führten eine entkoppelte Einbettungsarchitektur ein, die die Einbettungsdimension nach Datenquelle partitioniert. Dadurch wird sichergestellt, dass das Modell alle Eingaben verarbeiten und relevante Informationen für alle Daten behalten kann, während gleichzeitig die Interpretierbarkeit auf Datenquellenebene für nachgelagerte Aufgaben gewährleistet wird.
* Forscher haben gezeigt, wie PDFM zur Verbesserung von TimesFM, einem hochmodernen Basismodell für Prognosen, eingesetzt werden kann, um die Prognosen der Arbeitslosenquoten auf Bezirksebene und der Armutsquoten auf Postleitzahlenebene zu verbessern. Ähnliche Ansätze können auch verwendet werden, um andere vorhandene georäumliche Klassifizierungs- und Regressionsmodelle mithilfe von PDFM-Einbettungen zu verbessern.
* Durch starke Leistungen bei Interpolation, Extrapolation, Superauflösung und Vorhersageaufgaben zeigten die Forscher, dass PDFM problemlos auf eine Vielzahl von Anwendungsszenarien erweitert werden kann, die eine georäumliche Modellierung erfordern, darunter wissenschaftliche Forschung, öffentliches Wohlergehen, öffentliche und ökologische Gesundheit sowie kommerzielle Bereiche.

Papieradresse:
https://arxiv.org/abs/2411.07207
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Datensätze: Fünf gängige Datensätze
Zur Entwicklung von PDFM sammelten und organisierten die Forscher fünf große Datensätze, die geografische Gebiete auf Postleitzahlen- und Bezirksebene abdecken:
① Aggregierte Suchtrends:Die Forscher berechneten die Gesamtzahlen für die ersten 500 Abfragen im Juli 2022. Dazu waren mindestens 20 Suchvorgänge in jedem Postleitzahlengebiet erforderlich, was zu mehr als 1 Million eindeutigen Abfragen führte. Diese Suchanfragen wurden dann nach nationaler Popularität geordnet, gemessen an der Gesamtzahl der Postleitzahlen, in denen die jeweilige Suchanfrage auftauchte. Daraus wurden die 1.000 häufigsten Suchanfragen ausgewählt, die repräsentativ für die aggregierte Suchtrendaktivität auf Postleitzahlenebene im ganzen Land sind.
② Kartendatensatz (Karten):Die Forscher wählten die 1.192 häufigsten Point-of-Interest-Kategorien in Google Maps im Mai 2024 aus, die in mindestens 5%s Postleitzahl vorkamen. Jede Kategorie deckt ein breites Spektrum an interessanten Orten ab. So fallen in die Kategorie „Medizinische Einrichtungen“ beispielsweise Kinderkrankenhäuser und Universitätskliniken. Anschließend berechnete es die Gesamtzahl der verfügbaren Einrichtungen innerhalb jeder geografischen Grenze und generierte einen normalisierten 1.192-dimensionalen Merkmalsvektor auf Postleitzahlen- und Bezirksebene.
3. Geschäftsdatensatz:Für jede Sonderzielkategorie in den Kartendaten berechneten die Forscher die Summe der Besuche der entsprechenden Orte in diesen Kategorien innerhalb eines Monats, um die Auslastung dieser Kategorien zusammenzufassen.
④ Wetter und Luftqualität:Die Forscher sammelten Wetter- und Luftqualitätsdaten und fassten die stündlichen Daten für Juli 2022 zusammen und beschrieben sie anhand von Mittel-, Minimal- und Maximalwerten. Die vollständige Liste der Variablen umfasst: mittleren Luftdruck auf Meereshöhe, totale Bewölkung, U-Windkomponente in 10 m Höhe, V-Windkomponente in 10 m Höhe, Temperatur in 2 m Höhe, Taupunkttemperatur in 2 m Höhe, Sonneneinstrahlung, Gesamtniederschlagsrate, Luftqualitätsindex, Kohlenmonoxidkonzentration, Stickstoffdioxidkonzentration, Ozonkonzentration, Schwefeldioxidkonzentration, Konzentration einatembarer Partikel (<10 μm), Konzentration feiner Partikel (<2,5 μm).
⑤ Fernerkundung:Die Forscher kombinierten eingebettete Satellitenbilddaten, die aus der ViT16-L40-Version des SatCLIP-Modells generiert wurden, um Einbettungen zu erhalten, die nach dem Schwerpunkt jeder Postleitzahl indiziert sind. Das SatCLIP-Modell ist als global einsetzbarer Geocoder konzipiert und aggregiert 100.000 Kacheln aus Sentinel-2-Satellitenbildern vom 1. Januar 2021 bis zum 17. Mai 2023.
Die Forscher kombinierten den Datensatz mit einer Graph Neural Network (GNN)-Architektur, um ein Basismodell zu trainieren, das Einbettungen generiert, die eher allgemeiner als aufgabenspezifischer Natur sind.
Modellarchitektur: Georäumliche Probleme effizient und intuitiv mit GNN lösen
Der Aufbau des PDFM-Modells ist in der folgenden Abbildung dargestellt: In Phase 1Die Forscher kombinierten den Datensatz mit der Graph Neural Network (GNN)-Architektur, um ein Basismodell zu trainieren, das Einbettungen generiert, die eher allgemeiner als aufgabenspezifischer Natur sind.In Phase 2Mithilfe dieser Einbettungen und spezifischer Groundtruth-Daten für die jeweilige Aufgabe wird ein nachgelagertes Modell (wie etwa eine lineare Regression, ein einfaches mehrschichtiges Perzeptron oder ein gradientenverstärkter Entscheidungsbaum) erlernt, das auf eine Vielzahl von Aufgaben angewendet werden kann, darunter Interpolation, Extrapolation, Superauflösung und Prognose.
* Interpolationsaufgabe: bezieht sich auf das Ableiten und Ausfüllen der Werte unbekannter Datenpunkte basierend auf den Werten bekannter Datenpunkte
* Extrapolationsaufgaben: Extrapolation vorhandener Daten oder Erfahrungen, um Situationen, Trends oder Ergebnisse vorherzusagen, die über den derzeit bekannten Rahmen hinausgehen
* Super-Resolution-Aufgabe: Bezieht sich auf den Prozess der Aufwertung von Bildern oder Daten mit niedriger Auflösung durch Algorithmen auf eine hohe Auflösung
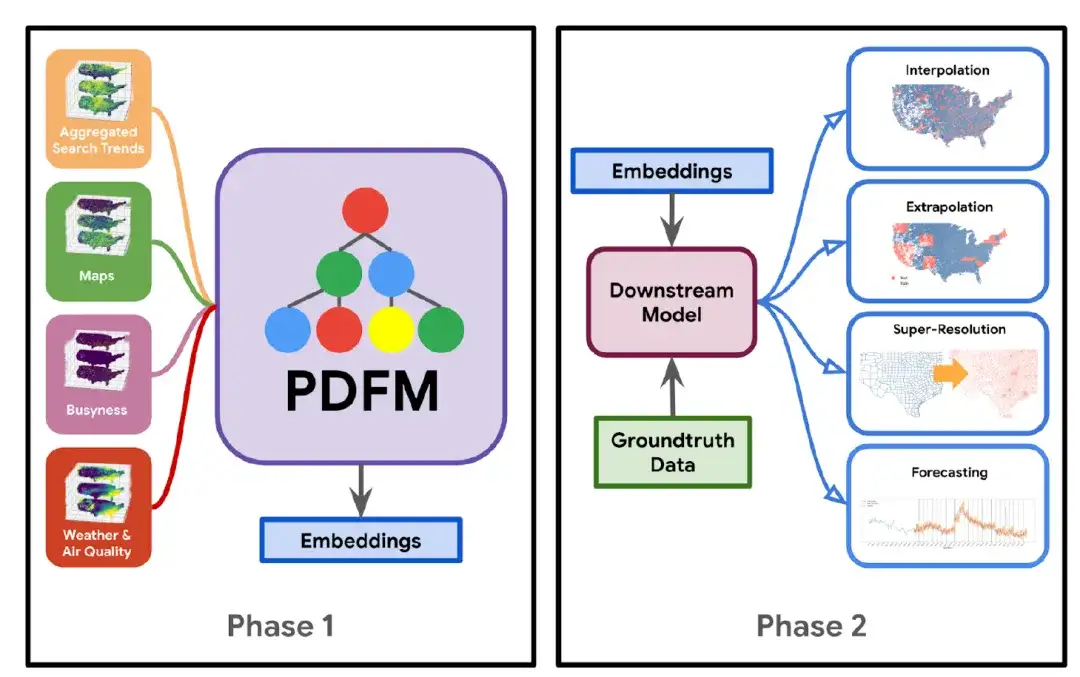
Der Kern des PDFM-Modells ist insbesondere das Graph Neural Network (GNN), das Positionseinbettungen in informationsreiche, niedrigdimensionale numerische Vektoren kodiert. Es besteht im Wesentlichen aus den folgenden fünf Teilen:
* Graphenkonstruktion:Die Forscher erstellten einen heterogenen Geodatengraphen, indem sie Landkreise und Postleitzahlen als Knotenpunkte verwendeten und Kanten durch Nachbarschaftsbeziehungen erstellten. Der erstellte Geodatengraph verfügt über einen homogenen Satz von Knoten, wobei Knoten auf Postleitzahlen- und Bezirksebene als Knotensatz desselben Typs behandelt werden, und einen heterogenen Satz von Kanten, wobei die Knoten durch unterschiedliche Arten von Kanten verbunden sind.
* Teilbildabtastung:Durch Subgraph-Sampling werden Subgraphen für das Training groß angelegter GNNs erstellt und dem Modell Zufälligkeit hinzugefügt. Es beginnt mit einem Startknoten, durchläuft jeden Kantensatz in der Breitensuche, tastet eine feste Anzahl von Knoten gewichtet ab und endet, wenn vier Hops erreicht sind.
Konkret begannen die Forscher mit einem Startknoten, durchliefen jeden Kantensatz in der Breitensuche, prüften eine feste Anzahl von Knoten gewichtet und beendeten den Vorgang, als die Distanz von vier Hops erreicht war. Dieser Ansatz führt zu einer Anzahl von Teilgraphen, die der Gesamtzahl der Knoten auf Postleitzahlen- und Bezirksebene entspricht.
* Vorverarbeitung:Auf alle Merkmale wird eine spaltenweise Normalisierung angewendet und die äußersten Enden des Merkmalswertebereichs werden durch Clipping komprimiert.
* Modellierungs- und Trainingsdetails:GraphSAGE (eine induktive Methode) wird verwendet, um Knoteneinbettungen durch Nutzung von Knotenmerkmalinformationen zu lernen. GraphSAGE lernt eine Funktion zum Generieren von Einbettungen aus lokalen Nachbarschaftsaggregationsinformationen. Für die Aggregationsarchitektur wird die in GraphSAGE vorgeschlagene Pooling-Architektur verwendet, bei der die Knotenzustände der benachbarten Knoten durch eine vollständig verbundene Schicht mit ReLU-Transformation geleitet werden und die transformierten alten Zustände und die Zustände der benachbarten Knoten durch elementweise Summation weiter aggregiert werden. Die Forscher verwendeten die GraphSAGE-Architektur, um die einmalige Nachrichtenübermittlung zu ermöglichen, indem sie nach der GNN-Schicht eine lineare Schicht der Größe 330 hinzufügten, um die Darstellung auf Knotenebene in eine komprimierte Einbettung zu kodieren.
* Hyperparameter-Tuning:Der Validierungssatz wird gleichmäßig aus den Seed-Knoten von 20% (einschließlich Landkreisen und Postleitzahlen) abgetastet, um die Tuning-Hyperparameter zu bilden, einschließlich der Abbruchrate, der Größe der Knoteneinbettungen, der Anzahl der verborgenen Einheiten und Ebenen von GraphSAGE, der Einbettungsgröße, der Regularisierung und der Lernrate.
Forschungsergebnisse: Starke Leistung bei Interpolation, Extrapolation, Superauflösung und Vorhersageaufgaben
PDFM ist ein flexibles grundlegendes Modellierungsframework, das eine Vielzahl georäumlicher Herausforderungen innerhalb der kontinentalen Vereinigten Staaten bewältigen kann. Durch die Integration unterschiedlicher Datensätze ist PDFM in 27 Gesundheits-, sozioökonomische und Umweltaufgaben eingebettet und übertrifft bestehende hochmoderne (SoTA) Standortkodierungsmethoden wie SatCLIP und GeoCLIP.
Bei Interpolationsaufgaben schneidet PDFM bei allen 27 Aufgaben gut ab. Bei Extrapolations- und Superauflösungsaufgaben liegt es bei 25 Aufgaben vorne. Darüber hinaus zeigten die Forscher, wie PDFM-Einbettungen die Leistung von Prognosemodellen wie TimesFM steigern und dadurch die Vorhersage wichtiger sozioökonomischer Indikatoren wie Arbeitslosenquoten auf Bezirksebene und Armutsquoten auf Postleitzahlenebene verbessern können.Dies unterstreicht sein breites Anwendungspotenzial in Forschung, Sozialwesen, öffentlicher und ökologischer Gesundheit sowie Wirtschaft.
Die spezifischen experimentellen Ergebnisse sind wie folgt:
① Interpolationsexperiment
Die folgende Abbildung zeigt die Ergebnisse des vollständigen Interpolationsexperiments zu 27 Aufgaben in drei Kategorien: Gesundheit, sozioökonomische Kategorie und Umwelt. Die Leistung verschiedener Modelle wird mithilfe des Indikators ² bewertet (ein höherer Wert zeigt an, dass das Modell die Varianz der Zielvariablenbezeichnung besser erklärt). Wie in der Abbildung gezeigt, übertrifft PDFM SatCLIP und GeoCLIP in den sozioökonomischen und gesundheitlichen Aufgabenkategorien deutlich.
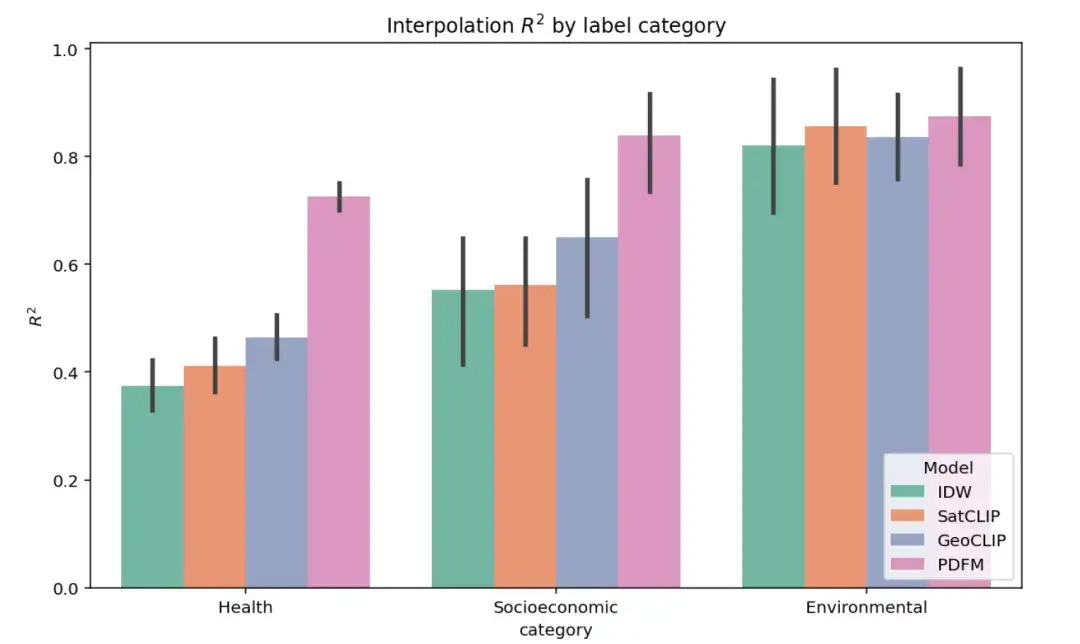
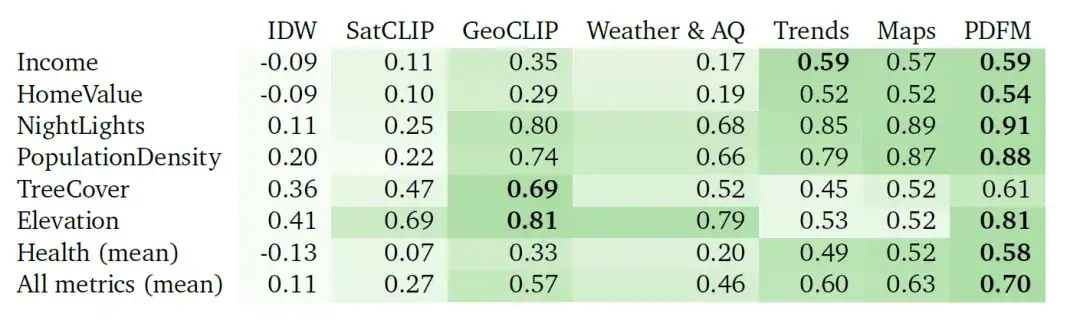
Die folgende Tabelle zeigt, wie gut PDFM bei 27 Gesundheits-, sozioökonomischen und Umweltaufgaben interpoliert, wie etwa Einkommen, Hauswert, Nachtlichter, Bevölkerungsdichte, Baumbedeckung, Höhe und Gesundheit (Durchschnitt). PDFM schneidet mit einem Durchschnitt von 0,83² für alle 27 Aufgaben, einschließlich eines Durchschnittswerts von 0,73² für 21 gesundheitsbezogene Aufgaben, durchweg besser ab.
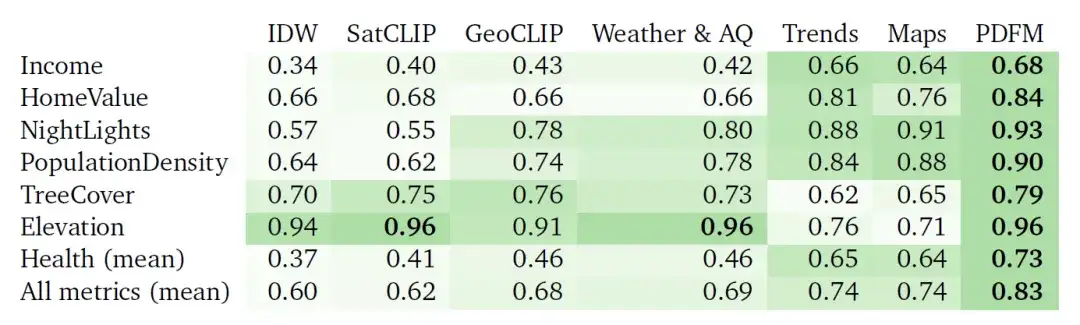
Tabelle: Interpolation²-Ergebnisse (höhere Werte sind besser). Die Experimente vergleichen die Leistung der auf inverser Distanzgewichtung (IDW) basierenden Interpolation, der SatCLIP-Einbettung, der GeoCLIP-Einbettung, der PDFM-Einbettung und ihrer Unterkomponenten (Wetter und Luftqualität, aggregierte Suchtrends, Karten und Geschäftigkeit) unter Verwendung von GBDT als nachgelagertes Modell.
2 Extrapolationsexperiment
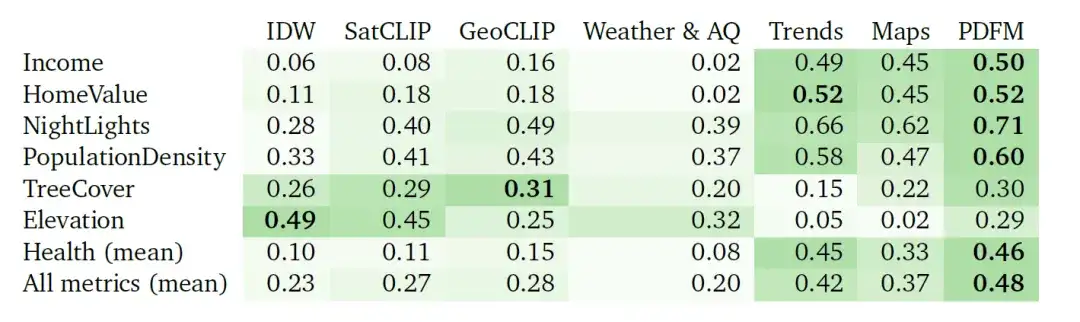
Die folgende Abbildung zeigt die vollständigen Ergebnisse des Extrapolationsexperiments zu 27 Aufgaben in drei Kategorien: Gesundheit, sozioökonomische Kategorie und Umwelt. Die Modellleistung wird weiterhin mithilfe des ²-Indikators bewertet. Wie aus der Abbildung hervorgeht, hat GeoCLIP zwar einen leichten Vorteil bei der Bewältigung der Umweltaufgabe, PDFM übertrifft jedoch alle anderen Basismodelle bei der Vorhersage von Gesundheits- und sozioökonomischen Variablen deutlich.
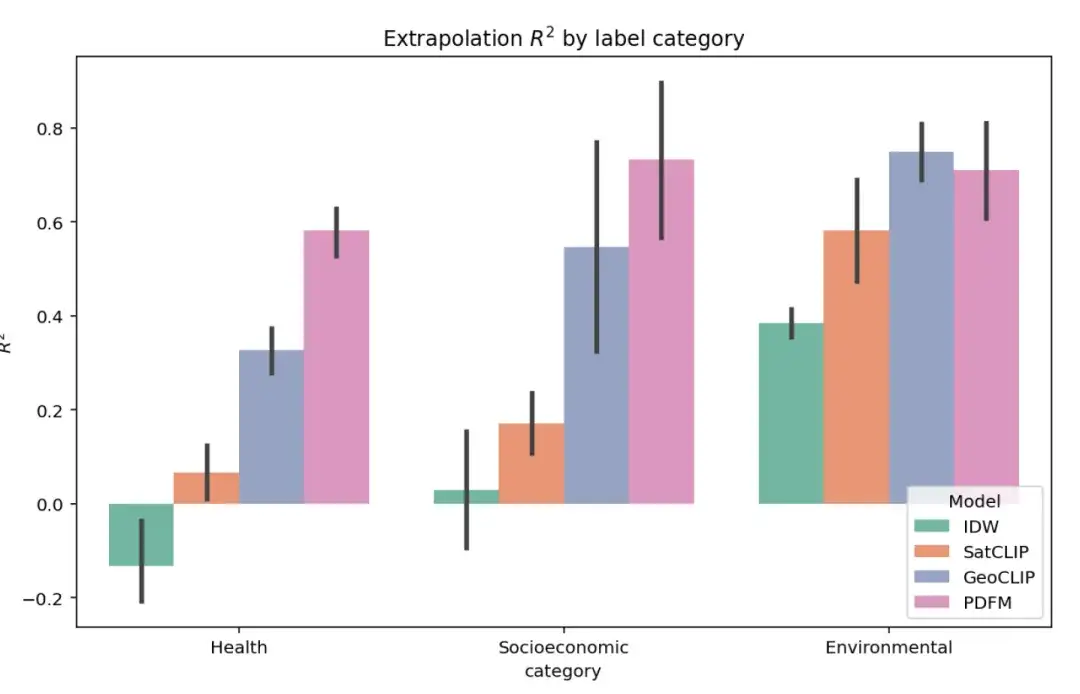
Aufgrund des erheblichen Mangels an gekennzeichneten Daten ist die Extrapolationsaufgabe eine Herausforderung. In diesem Fall zeigt PDFM eine hervorragende Leistung, wie in der folgenden Tabelle gezeigt, mit einem durchschnittlichen quadrierten Quadrat von 0,70 bei allen Kennzahlen und 0,58 bei gesundheitsbezogenen Kennzahlen. Mithilfe von Bildern mit Geotags erzielt GeoCLIP gute Ergebnisse bei der Vorhersage der Baumbedeckung (TreeCover) und erreicht einen Wert von ² =0,69. Damit übertrifft es PDFM und jede einzelne Modalität. Insgesamt übertrifft PDFM das Basismodell jedoch bei 25 von 27 Aufgaben, was seine Wirksamkeit in Extrapolationsszenarien unterstreicht.
3 Super-Resolution-Experiment
Die folgende Abbildung zeigt die vollständigen Ergebnisse des Superauflösungsexperiments für 27 Aufgaben, gruppiert nach Gesundheit, sozioökonomischer Kategorie und Umwelt, wobei der durchschnittliche Pearson-Korrelationskoeffizient (r) innerhalb des Landkreises als Metrik verwendet wurde (höhere Werte zeigen an, dass die Vorhersagen des Modells stärker mit den wahren Bezeichnungen auf Postleitzahlenebene korrelieren).
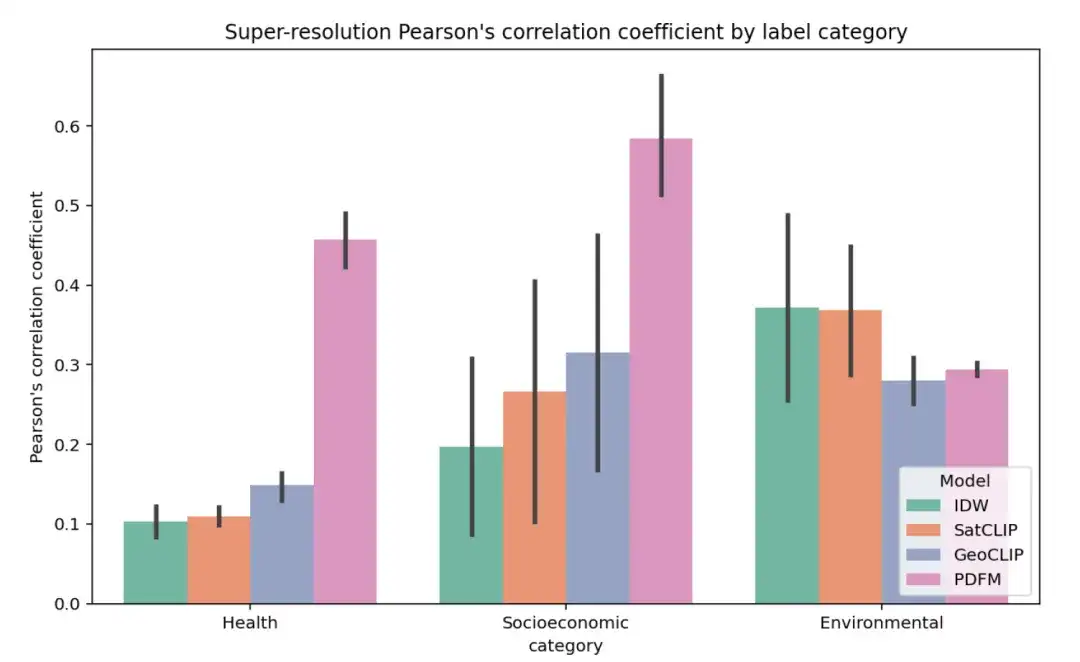
Die Aufgabe der Superauflösung ist schwieriger. Die Ergebnisse sind in der folgenden Tabelle zusammengefasst. IDW schneidet bei der Höhenmessung am besten ab, während GeoCLIP bei der Baumbedeckungsmessung die beste Leistung erbringt. Insgesamt schnitt PDFM bei 25 von 27 Aufgaben besser ab, mit einem durchschnittlichen Pearson-Korrelationskoeffizienten von 0,48.
④ Vorhersageaufgabe
Die Forscher bewerteten außerdem die Wirksamkeit der Verwendung von PDFM-Einbettungen zur Korrektur von Prognosefehlern von TimesFM (einem allgemeinen univariaten Prognosebasismodell). Dabei ging es ihnen vor allem darum, die Verbesserung dieser Einbettungen in zukünftigen Zeithorizonten (6-Monats-Prognosen der Arbeitslosenquote und Zweijahres-Prognosen der Armutsquote) zu bewerten. Die Ergebnisse in der folgenden Tabelle zeigen, dass das mit der PDFM-Einbettung kombinierte Modell die Basisleistung von TimesFM in Bezug auf die MAPE-Metrik übertrifft und auch besser ist als ARIMA. Dies zeigt, dass die PDFM-Einbettung den Prognoseeffekt von TimesFM erheblich verbessern kann.
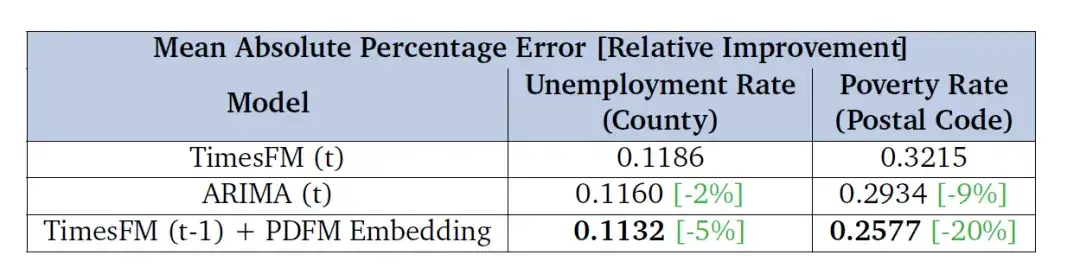
Die Forscher bewerteten die Leistung anhand der Arbeitslosenquoten auf Bezirksebene und der Armutsquoten auf Postleitzahlenebene in den Vereinigten Staaten und stellten den mittleren absoluten prozentualen Fehler (MAPE) in der Tabelle dar, wobei niedrigere Werte auf eine bessere Leistung hinweisen.
Georäumliche Künstliche Intelligenz (GeoAI) boomt
Die Geburt des PDFM-Modells kann als eine weitere eingehende Erforschung und Nutzung georäumlicher Daten betrachtet werden. Geodaten beziehen sich auf große Mengen raumzeitlicher Daten, die aus vielen verschiedenen Quellen in unterschiedlichen Formaten gesammelt werden. Dazu können Volkszählungsdaten, Satellitenbilder, Wetterdaten, Mobiltelefondaten, Kartenbilder und Social-Media-Daten gehören. Durch die wissenschaftliche Weitergabe, Analyse und Nutzung georäumlicher Daten können zahlreiche nützliche Erkenntnisse zur Entwicklung der menschlichen Gesellschaft gewonnen werden. So können beispielsweise Arbeitslosenquoten oder Immobilienpreise vorhergesagt, die Auswirkungen bestimmter Medikamente oder die Migration der Bevölkerung nach einer Katastrophe simuliert werden.
Allerdings ist die effektive Verarbeitung riesiger Mengen an Geodaten eine Herausforderung.Mit der Entstehung künstlicher neuronaler Netzwerkmodelle entstand das Konzept der georäumlichen künstlichen Intelligenz (GeoAI), und auch die Branche hat in dieser Hinsicht zahlreiche Untersuchungen durchgeführt.
Um beispielsweise die Interpretierbarkeit von Mineralisierungsvorhersagemodellen und die durch geologische Faktoren im Mineralisierungsprozess verursachte räumliche Nichtstationarität zu verbessern, schlug ein Forschungsteam der Zhejiang-Universität im April 2024 eine neue Methode der georäumlichen künstlichen Intelligenz vor: die geographische neuronale Netzwerk-gewichtete logistische Regression (GNNWLR). Das Modell integriert räumliche Muster und neuronale Netzwerke und kann in Kombination mit Shapleys additiver Interpretationstheorie nicht nur die Genauigkeit von Vorhersagen erheblich verbessern, sondern auch die Interpretierbarkeit von Mineralienvorhersagen in komplexen räumlichen Szenarien verbessern.
Im Juni 2024 veröffentlichten Forscher des GIS-Labors der Zhejiang-Universität eine Forschungsarbeit mit dem Titel „Ein neuronales Netzwerkmodell zur Optimierung der Messung der räumlichen Nähe im geografisch gewichteten Regressionsansatz: eine Fallstudie zu Hauspreisen in Wuhan“ im International Journal of Geographical Information Science, einer renommierten Zeitschrift auf dem Gebiet der Geoinformationswissenschaft. Sie führten auf innovative Weise eine Methode mit neuronalen Netzwerken ein, um mehrere räumliche Näherungsmaße (wie etwa euklidische Distanz, Reisezeit usw.) zwischen Beobachtungspunkten nichtlinear zu koppeln, um ein optimiertes räumliches Näherungsmaß (OSP) zu erhalten und so die Genauigkeit der Vorhersagen des Modells zu den Immobilienpreisen zu verbessern. Durch die Untersuchung simulierter Datensätze und empirischer Fälle von Immobilienpreisen in Wuhan wird nachgewiesen, dass das in der Arbeit vorgeschlagene Modell insgesamt eine bessere Leistung aufweist und komplexe räumliche Prozesse und geografische Phänomene genauer beschreiben kann.
Klicken Sie hier, um den ausführlichen Bericht anzuzeigen: Genaue Vorhersage der Immobilienpreise in Wuhan! Das GIS-Labor der Zhejiang-Universität schlug das osp-GNNWR-Modell vor: Es beschreibt komplexe räumliche Prozesse und geografische Phänomene präzise
Durch die kontinuierliche Weiterentwicklung der KI-Technologie wird die Geoinformationsbranche künftig über eine solidere technische Grundlage und komfortablere Entwicklungstools verfügen und die Menschheit so in das Zeitalter der geografischen Raumintelligenz führen.
Quellen:
1.https://arxiv.org/abs/2411.07207
2.https://research.google/blog/insights-into-population-dynamics-a-foundation-model-for-geospatial-inference/
3.https://www.ibm.com/cn-zh/topics/geospatial-data
4.https://mp.weixin.qq.com/s/eQz5N-cFTtGIkDk7IqMZxA
5.https://www.xinhuanet.com/science/2








