Command Palette
Search for a command to run...
Das Erste Chinesische vLLM-Dokument Ist Online! Die Neueste Version Erhöht Den Durchsatz Um Das 2,7-fache Und Reduziert Die Latenz Um Das 5-fache, Wodurch Die Inferenz Großer Sprachmodelle Schneller Wird!

Heute erstreckt sich die Entwicklung großer Sprachmodelle (LLMs) von der iterativen Aktualisierung von Skalenparametern hin zur Anpassung und Innovation von Anwendungsszenarien. Dabei treten auch eine Reihe von Problemen zutage. Beispielsweise ist die Effizienz der Argumentationsverbindung gering und die Verarbeitung komplexer Aufgaben dauert lange, was es schwierig macht, die Anforderungen von Szenarien mit hohen Echtzeitanforderungen zu erfüllen. Im Hinblick auf die Ressourcennutzung ist der Verbrauch von Rechen- und Speicherressourcen aufgrund des großen Maßstabs des Modells enorm und es kommt zu einer gewissen Verschwendung.
In Anbetracht dessenEin Forschungsteam der University of California, Berkeley (UC Berkeley) hat vLLM (Virtual Large Language Model) im Jahr 2023 als Open Source veröffentlicht.Dies ist ein Framework, das speziell für die Beschleunigung der Argumentation großer Sprachmodelle entwickelt wurde. Aufgrund seiner hervorragenden Argumentationseffizienz und Ressourcenoptimierung hat es weltweit große Aufmerksamkeit erregt.
Um es inländischen Entwicklern zu erleichtern, sich über vLLM-Versionsaktualisierungen und aktuelle Entwicklungen zu informieren,HyperAI Super Neural Network hat jetzt das erste chinesische vLLM-Dokument veröffentlicht.Von technischem Wissen bis hin zu praktischen Tutorials, von topaktuellen Trends bis hin zu wichtigen Updates finden sowohl Anfänger als auch erfahrene Experten die wesentlichen Inhalte, die sie benötigen.
Chinesische vLLM-Dokumentation:
Tracing vLLM: Open Source-Geschichte und Technologieentwicklung
Der Prototyp von vLLM entstand Ende 2022. Als ein Forschungsteam an der University of California in Berkeley ein automatisiertes Parallel-Reasoning-Projekt namens „alpa“ einsetzte, stellte es fest, dass es sehr langsam lief und eine geringe GPU-Auslastung aufwies. Forscher sind sich durchaus bewusst, dass es im Bereich der Argumentation mit großen Sprachmodellen enormen Optimierungsspielraum gibt. Da es jedoch kein Open-Source-System auf dem Markt gab, das für die Inferenz großer Sprachmodelle optimiert war, beschlossen sie, selbst ein Framework für die Inferenz großer Sprachmodelle zu erstellen.
Nach unzähligen Experimenten und Debuggings widmeten sie sich dem virtuellen Speicher und der Paging-Technologie im Betriebssystem und schlugen darauf basierend im Jahr 2023 den bahnbrechenden Aufmerksamkeitsalgorithmus PagedAttention vor, der Aufmerksamkeitsschlüssel und -werte effektiv verwalten kann. Auf dieser Grundlage bauten die Forscher eine verteilte LLM-Service-Engine mit hohem Durchsatz (vLLM), die eine nahezu vollständige null Verschwendung von KV-Cache-Speicher erreichte.Das Engpassproblem bei der Speicherverwaltung im Zusammenhang mit großen Sprachmodellen wurde gelöst.Im Vergleich zu Hugging Face Transformers wird ein 24-mal höherer Durchsatz erreicht, und diese Leistungsverbesserung erfordert keine Änderungen an der Modellarchitektur.
Erwähnenswerter ist, dass vLLM nicht auf Hardware beschränkt ist. Es ist nicht nur auf Nvidia-GPUs beschränkt, sondern öffnet sich auch für viele Hardwarearchitekturen auf dem Markt, wie AMD-GPUs, Intel-GPUs, AWS Neuron und Google TPU, was die effiziente Argumentation und Anwendung großer Sprachmodelle in verschiedenen Hardwareumgebungen wirklich fördert. Heute kann vLLM mehr als 40 Modellarchitekturen unterstützen und hat Unterstützung und Sponsoring von mehr als 20 Unternehmen erhalten, darunter Anyscale, AMD, NVIDIA und Google Cloud.
Im Juni 2023 wurde der Open-Source-Code von vLLM offiziell veröffentlicht. In nur einem Jahr überstieg die Anzahl der Sterne von vLLM auf Github 21,8.000.Derzeit hat das Projekt 31.000 Sterne.
Im September desselben Jahres veröffentlichte das Forschungsteam das Papier „Efficient Memory Management for Large Language Model Serving with PagedAttention“, in dem die technischen Details und Vorteile von vLLM näher erläutert werden. Das Team hat seine Forschung zu vLLM nicht eingestellt und führt weiterhin iterative Verbesserungen in Bereichen wie Kompatibilität und Benutzerfreundlichkeit durch. Wie kann vLLM beispielsweise im Hinblick auf die Hardwareanpassung zusätzlich zur Nvidia-GPU auf weiterer Hardware ausgeführt werden? Beispielsweise in der wissenschaftlichen Forschung, wie sich die Systemleistung und die Inferenzgeschwindigkeit weiter verbessern lassen. Diese spiegeln sich auch in den Versionsupdates von vLLM wider.
Papieradresse:
https://dl.acm.org/doi/10.1145/3600006.3613165
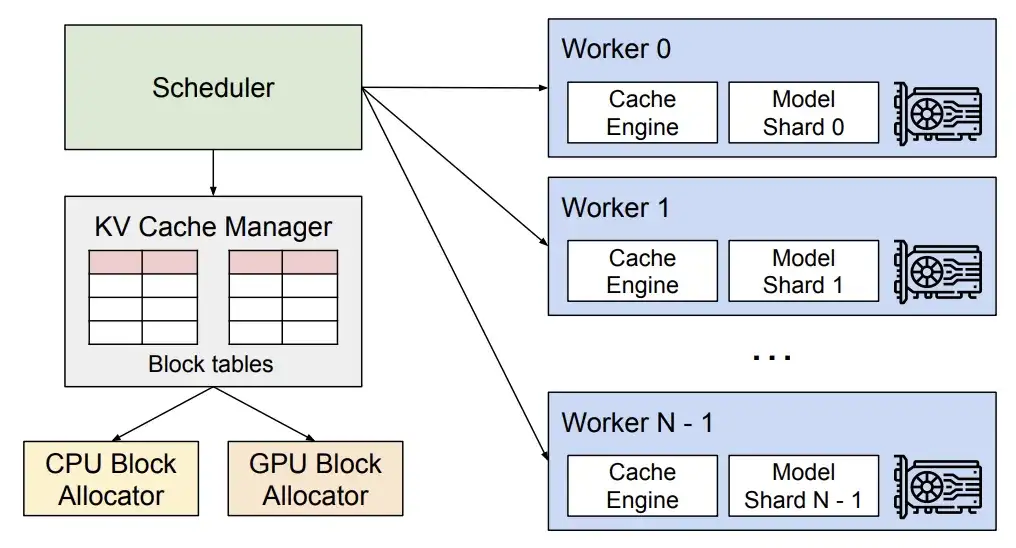
vLLM v0.6.4 Update
2,7-mal höherer Durchsatz und 5-mal geringere Latenz
Erst letzten Monat wurde vLLM auf Version 0.6.4 aktualisiert, die wichtige Fortschritte bei der Leistungsverbesserung, der Modellunterstützung und der multimodalen Verarbeitung erzielt hat.
In Bezug auf die Leistung führt die neue Version eine mehrstufige Planung und eine asynchrone Ausgabeverarbeitung ein.Optimierte GPU-Auslastung und erhöhte Verarbeitungseffizienz, wodurch der Gesamtdurchsatz verbessert wird.
vLLM Technische Analyse
* Durch die mehrstufige Planung kann vLLM die Planung und Eingabevorbereitung mehrerer Schritte gleichzeitig abschließen, sodass die GPU mehrere Schritte kontinuierlich verarbeiten kann, ohne für jeden Schritt auf CPU-Anweisungen warten zu müssen. Dadurch wird die CPU-Arbeitslast verteilt und die Leerlaufzeit der GPU reduziert.
* Durch die asynchrone Ausgabeverarbeitung kann die Ausgabeverarbeitung parallel zur Modellausführung durchgeführt werden. Insbesondere verarbeitet vLLM die Ausgabe nicht mehr sofort, sondern verzögert die Verarbeitung, indem es die Ausgabe von Schritt n verarbeitet, während Schritt n+1 ausgeführt wird. Dies kann zwar zu einem zusätzlichen Schritt pro Anforderung führen, die deutliche Verbesserung der GPU-Auslastung gleicht diese Kosten jedoch mehr als aus.
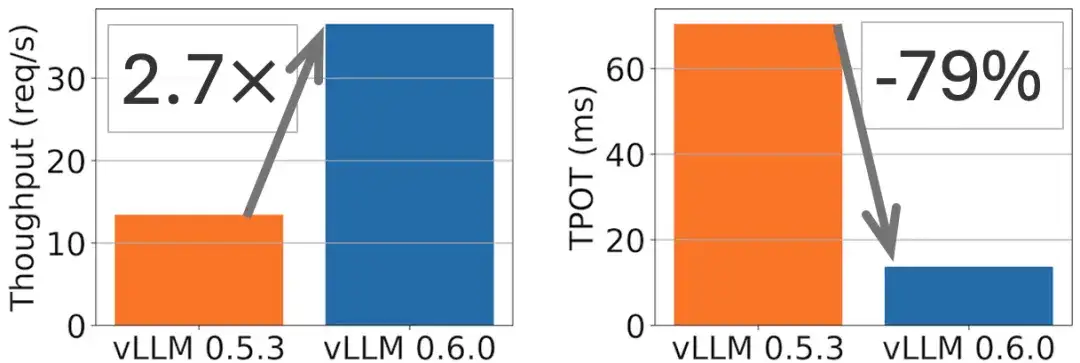
Beispielsweise kann beim Modell Llama 8B eine 2,7-fache Durchsatzverbesserung und eine 5-fache TPOT-Reduzierung (Token Per Output Time) erreicht werden, wie in der folgenden Abbildung dargestellt.
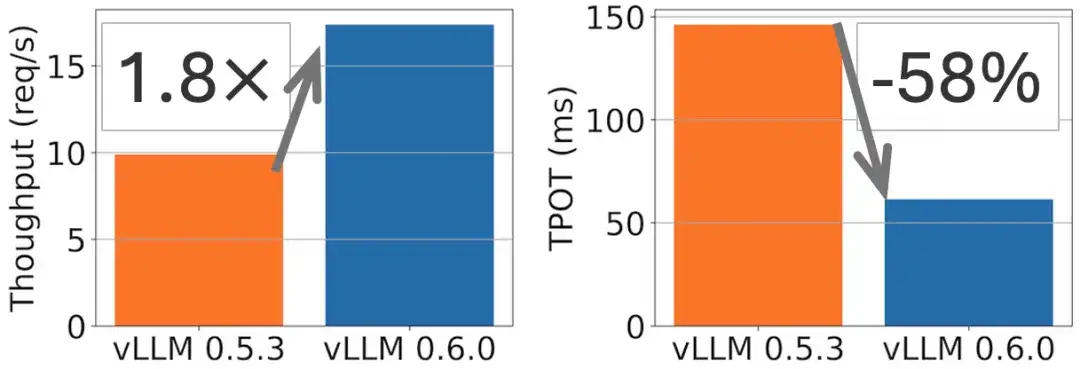
Beim Modell Llama 70B wurde eine 1,8-fache Durchsatzverbesserung und eine 2-fache TPOT-Reduzierung erreicht, wie in der folgenden Abbildung dargestellt.
In Bezug auf die Modellunterstützung hat vLLM neue Anpassungen für hochmoderne große Sprachmodelle wie Exaone, Granite und Phi-3.5-MoE integriert. Im multimodalen Bereich wurde die Funktion der Mehrbildeingabe hinzugefügt (das Phi-3-Vision-Modell wird in der offiziellen Dokumentation als Beispiel verwendet) sowie die Möglichkeit, mehrere Audioblöcke von Ultravox zu verarbeiten, wodurch der Anwendungsbereich von vLLM bei multimodalen Aufgaben weiter erweitert wird.
Die erste vollständige Version der chinesischen vLLM-Dokumentation ist online
Es besteht kein Zweifel, dass vLLM als wichtige technologische Innovation im Bereich großer Modelle die aktuelle Entwicklungsrichtung des effizienten Denkens darstellt. Um es inländischen Entwicklern zu ermöglichen, die dahinter stehenden fortgeschrittenen technischen Prinzipien bequemer und genauer zu verstehen, wird vLLM in die Entwicklung inländischer Großmodelle eingeführt und so die Entwicklung dieses Bereichs gefördert. Freiwillige der HyperAI-Community haben das erste chinesische vLLM-Dokument durch offene Zusammenarbeit und doppelte Überprüfung der Übersetzung und des Korrekturlesens erfolgreich fertiggestellt.Jetzt vollständig auf hyper.ai gestartet.
Chinesische vLLM-Dokumentation:
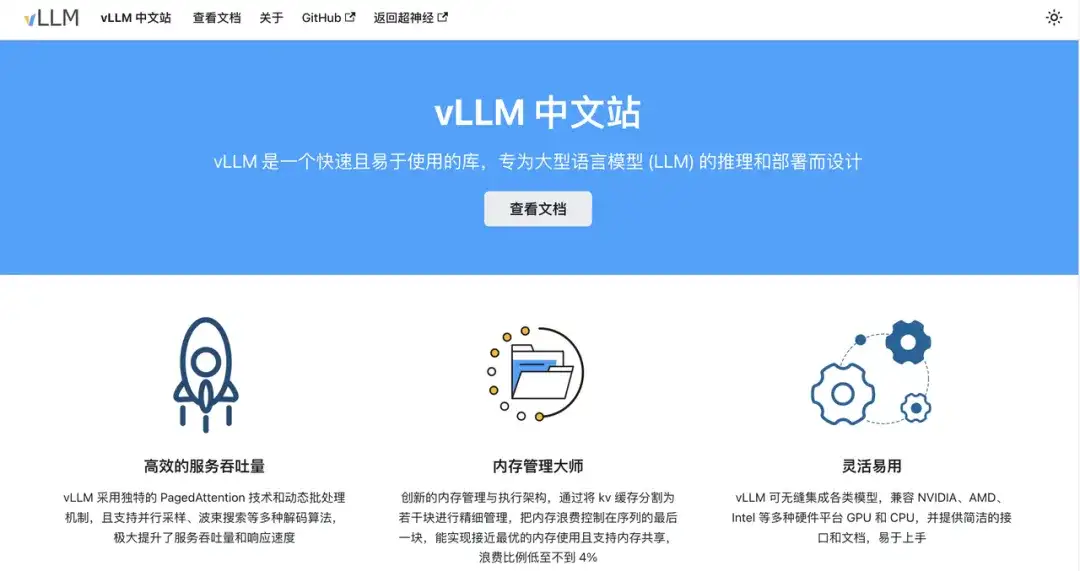
vLLM Dieses Dokument bietet Ihnen:
* Grundlegende Konzepte von Grund auf
* Schnellstart-Tutorial zum Klonen mit einem Klick
* Zeitnah aktualisierte vLLM-Wissensdatenbank
* Freundliche und offene chinesische Gemeinschaftsökologie
Open-Source-Brücken bauen:
Gemeinsame Reise des Community-Aufbaus von TVM, Triton und vLLM
Im Jahr 2022 veröffentlichte HyperAI die erste Apache TVM-Dokumentation in China. (Klicken Sie hier, um den Originaltext anzuzeigen: Die chinesische TVM-Website ist offiziell gestartet! Das umfassendste „Nachschlagewerk“ zur Bereitstellung von Machine-Learning-Modellen finden Sie hier)Da sich inländische Chips rasant weiterentwickeln, stellen wir inländischen Compiler-Ingenieuren die Infrastruktur zur Verfügung, um TVM zu verstehen und zu erlernen.Gleichzeitig haben wir uns mit Apache TVM PMC Dr. Feng Siyuan und anderen zusammengeschlossen, um die aktivste chinesische TVM-Community in China zu bilden.Durch Online- und Offline-Aktivitäten konnten wir die Teilnahme und Unterstützung der wichtigsten inländischen Chiphersteller gewinnen, darunter mehr als tausend Chipentwickler und Compiler-Ingenieure.

Adresse der chinesischen TVM-Dokumentation:
Im Oktober 2024 starteten wir die chinesische Triton-Website (Klicken Sie hier, um den Originaltext anzuzeigen: Das erste vollständige chinesische Triton-Dokument ist online! Beginn einer neuen Ära der GPU-Inferenzbeschleunigung), wodurch die technischen Grenzen und der inhaltliche Umfang der KI-Compiler-Community weiter erweitert werden.
Adresse der chinesischen Dokumentation von Triton:
Auf unserem Weg zum Aufbau der KI-Compiler-Community haben wir auf die Meinung aller gehört und die Branchentrends im Auge behalten. Der Grund für die Veröffentlichung der chinesischen vLLM-Dokumentation liegt in unserer Beobachtung, dass mit der rasanten Entwicklung großer Modelle die Aufmerksamkeit und Nachfrage der Menschen für die Verwendung von vLLM steigt. Wir hoffen, Entwicklern eine Plattform zum Lernen, zur Kommunikation und zur Zusammenarbeit bieten zu können und gemeinsam die Popularisierung und Entwicklung von Spitzentechnologien im chinesischen Kontext voranzutreiben.
Die Aktualisierung und Pflege der chinesischen Dokumente von TVM, Triton und vLLM sind für uns die grundlegende Arbeit beim Aufbau der chinesischen Community. Wir freuen uns darauf, in Zukunft weitere Partner zu begrüßen, die sich uns anschließen, um eine offenere, vielfältigere und integrativere KI-Open-Source-Community aufzubauen!
Sehen Sie sich die vollständige chinesische vLLM-Dokumentation an:
Auf GitHub vLLM Chinesisch:
https://github.com/hyperai/vllm-cn
Diesen Monat veranstaltet HyperAI in Shanghai ein Offline-Treffen zum technischen Austausch mit dem Titel „Meet AI Compiler“. Bitte scannen Sie den QR-Code und vermerken Sie „AI Compiler“, um der Veranstaltungsgruppe beizutreten und so schnell wie möglich relevante Informationen zur Veranstaltung zu erhalten.

Quellen:
1.https://blog.vllm.ai/2024/09/05/perf-update.html








