Command Palette
Search for a command to run...
Erleben Sie Als Erster Das Unsichtbare Wasserzeichen Von SynthID! Machen Sie KI-generierte Inhalte Kontrollierbarer; Ein Umfangreicher Audio-Untertitel-Datensatz Mit 6 Millionen Audiodateien Ist Jetzt Online

In einer Zeit, in der KI-generierte Inhalte immer beliebter werden, ist die Frage, wie man schnell unterscheiden kann, ob Inhalte manuell erstellt oder KI-generiert wurden, zu einem heißen Thema geworden. Dabei geht es nicht nur um die Authentizität der Nachrichten und den Schutz des Urheberrechts, sondern auch um die Netzwerksicherheit.
Vor Kurzem hat Google DeepMind die SynthID-Text-Technologie eingeführt, die durch Optimierung des Token-Wahrscheinlichkeitswerts im Textgenerierungsprozess Wasserzeichen verlustfrei einbetten kann, ohne die Qualität des Textes zu beeinträchtigen, und eine extrem hohe Erkennungseffizienz aufweist. Im Vergleich zu herkömmlichen Technologien wird eine höhere Klassifizierungsgenauigkeit bei geringeren Latenzkosten erreicht und so eine innovative Lösung für die KI-Inhaltsüberwachung bereitgestellt.
Auf der offiziellen Website von hyper.ai wurde jetzt ein Tutorial zur Verwendung von SynthID-Text veröffentlicht. Sie können es klonen und mit einem Klick starten, um der KI-Generierung digitale Wasserzeichen hinzuzufügen:
Ein-Klick-Startlink:
Vom 18. bis 22. November gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 3
* Community-Artikelauswahl: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadlines von November bis Dezember: 3
Besuchen Sie die offizielle Website: hyper.ai
Ausgewählte öffentliche Datensätze
1. MEHR Multimodaler Datensatz zur Extraktion von Objekt-Entitäts-Beziehungen
Der Datensatz enthält 21 verschiedene Beziehungstypen und deckt mehr als 20.000 multimodale Beziehungsfakten ab, die auf 3.559 Paaren von Textbeschriftungen und entsprechenden Bildern annotiert sind.
Direkte Verwendung:https://go.hyper.ai/LlfTx

2. Guavenfruchtkrankheiten - Datensatz zu Guavenfruchtkrankheiten
Der Datensatz enthält 473 beschriftete Bilder von Guavenfrüchten, die Vorverarbeitungsschritten wie Unscharfmaskierung und CLAHE (kontrastbegrenzte adaptive Histogramm-Entzerrung) unterzogen wurden, wodurch sich die Anzahl der Bilder auf 3.784 erhöht. Jedes Bild wird in ein konsistentes RGB-Format von 512 × 512 Pixeln vorverarbeitet.
Direkte Verwendung:https://go.hyper.ai/RRLEd

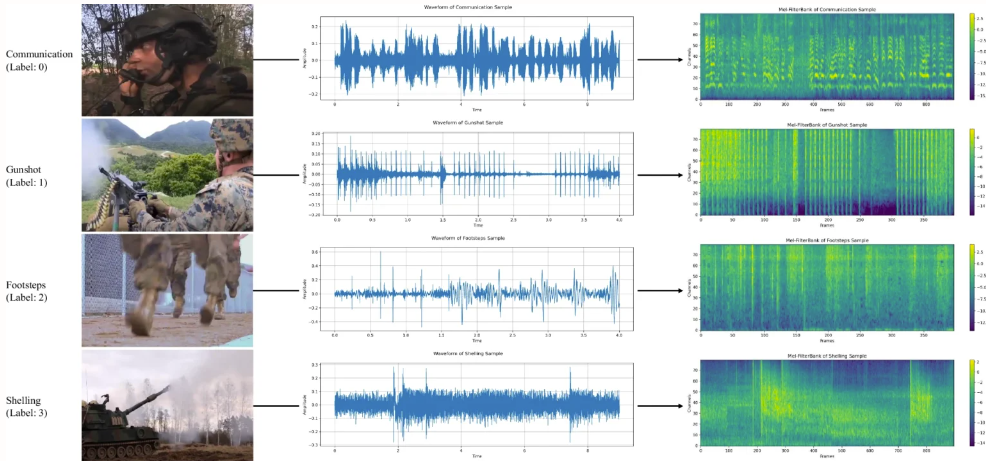
3. MAD Militär-Audiodatensatz
Der MAD-Datensatz soll das Training und die Bewertung von Audioklassifizierungssystemen unterstützen, insbesondere bei Audioklassifizierungsaufgaben im Zusammenhang mit militärischen Aktivitäten wie Schüssen, Artilleriefeuer oder Explosionen. Der Datensatz wurde aus mehreren Militärvideos extrahiert und enthält 8.075 Tonbeispiele, die in 7 Kategorien unterteilt sind und insgesamt etwa 12 Stunden Audio ergeben.
Direkte Verwendung:https://go.hyper.ai/kxqH3
4. MMPR Multimodal Reasoning Preference Dataset
Der MMPR-Datensatz enthält 750.000 Beispiele ohne eindeutig richtige Antworten und 2,5 Millionen Beispiele mit eindeutig richtigen Antworten. Die Beispiele decken mehrere Bereiche ab, wie etwa VQA, Wissenschaft, Grafik, Mathematik, OCR und Dokumente, um Vielfalt zu gewährleisten. Der Datensatz zielt darauf ab, die Leistung von Modellen bei multimodalen Denkaufgaben zu verbessern und gleichzeitig potenzielle negative Effekte während des Trainings zu vermeiden.
Direkte Verwendung:https://go.hyper.ai/bbHH0

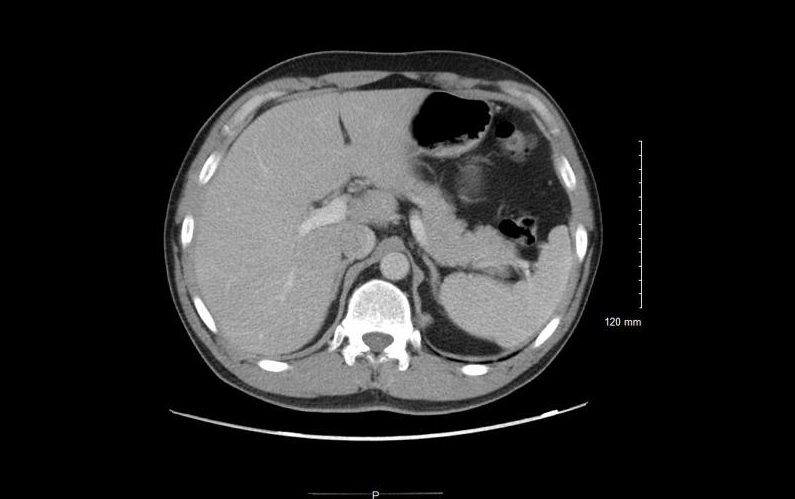
5.ROCOv2 radiologischer multimodaler medizinischer Bilddatensatz
Der ROCOv2-Datensatz kombiniert radiologische Bilder mit zugehörigen medizinischen Konzepten und Beschreibungen und enthält mehr als 70.000 radiologische Bilder, die eine Vielzahl klinischer Muster, anatomischer Regionen und Richtungen (für Röntgenstrahlen) abdecken, und jedes Bild verfügt über eine entsprechende medizinische Konzeptbeschreibung.
Direkte Verwendung:https://go.hyper.ai/XgqCa
6. PDFM Geographic Index Dataset
Der PDFM Geo-Index-Datensatz enthält echte Daten, die zur Auswertung von auf Populationsdynamik basierenden Einbettungen verwendet werden. Es enthält umfassende zusammenfassende Informationen zum menschlichen Verhalten, die aus Karten, Suchtrendzusammenfassungen und Umweltfaktoren wie Wetter und Luftqualität gewonnen wurden.
Direkte Verwendung:https://go.hyper.ai/jpzY1
7. Mantis-Instruct Multi-Image-Anweisungs-Tuning-Datensatz
Bei dem Datensatz handelt es sich um einen multimodalen Datensatz mit verschachteltem Text und Bild, der sich auf die Feinabstimmung von Anweisungen für mehrere Bilder konzentriert und aus 14 Teilmengen mit 721.000 Beispielen zum Trainieren der Mantis-Modellfamilie besteht. Der Datensatz deckt eine Vielzahl von Mehrbildfähigkeiten ab, darunter Koreferenz, Argumentation, Vergleich und zeitliches Verständnis.
Direkte Verwendung:https://go.hyper.ai/dOtuR
8. MASSW Wissenschaftlicher Workflow-Datensatz
Der MASSW-Datensatz enthält mehr als 152.000 von Experten begutachtete Veröffentlichungen von 17 führenden Informatikkonferenzen und decken einen Zeitraum der letzten 50 Jahre ab. Der Datensatz definiert fünf Schlüsselaspekte des wissenschaftlichen Arbeitsablaufs: Kontext, Schlüsselideen, Methoden, Ergebnisse und beabsichtigte Wirkung. Diese Aspekte wurden verwendet, um Informationen aus jeder Veröffentlichung zu extrahieren und zu strukturieren und so eine strukturierte Zusammenfassung zu erstellen.
Direkte Verwendung:https://go.hyper.ai/2pUy8
9. AudioSetCaps Audio-Untertitel-Datensatz
Der Audio-Untertitel-Datensatz AudioSetCaps enthält mehr als 6,11 Millionen 10-Sekunden-Audiodateien. Jede Audiodatei wird von einem beschreibenden Titel und drei Frage-und-Antwort-Paaren als Metadaten begleitet, um den endgültigen Titel zu generieren.
Direkte Verwendung:https://go.hyper.ai/3QCQP
10. Datensatz zur Traditionellen Chinesischen Medizin SFT Diagnosedatensatz zur Traditionellen Chinesischen Medizin
Dieser Datensatz enthält ungefähr 1 GB hochwertigen Inhalt, darunter klinische Fälle aus verschiedenen Bereichen der TCM, berühmte Bücher, medizinische Enzyklopädien und Glossare. Der Datensatz besteht hauptsächlich aus internen Daten aus Nicht-Netzwerkquellen. 99% ist in vereinfachtem Chinesisch mit hervorragender Qualität und beträchtlicher Informationsdichte und eignet sich daher für Vorschulungs- oder fortlaufende Vorschulungszwecke.
Direkte Verwendung:https://go.hyper.ai/zb7Uf
Ausgewählte öffentliche Tutorials
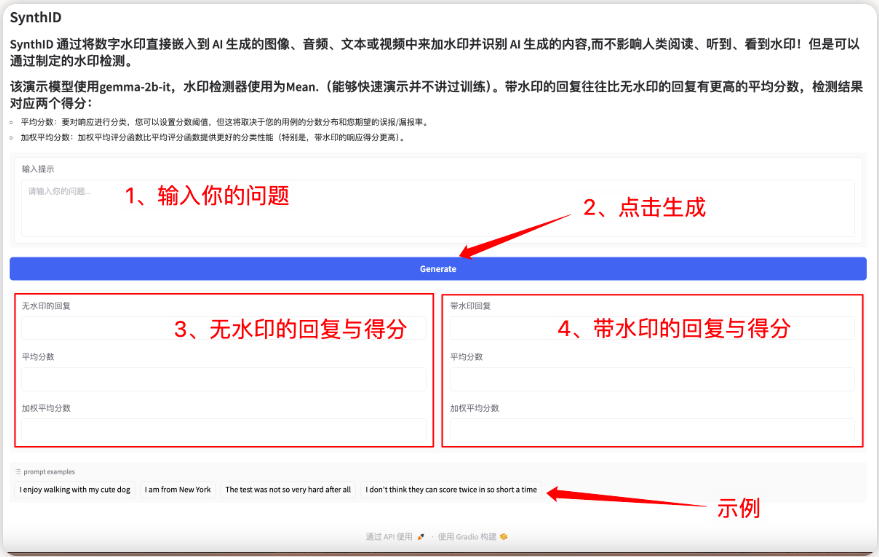
1. SynthID-Text KI-Tool zur Generierung von Textwasserzeichen
Das Modell ist eine Wasserzeichentechnik zum Identifizieren und Überprüfen von Texten, die von Large Language Models (LLMs) generiert werden. Dadurch kann die Textqualität aufrechterhalten und eine hohe Erkennungsgenauigkeit erreicht werden, während die Latenzkosten minimiert werden. Der Kern liegt darin, durch leichte Anpassung des Token-Wahrscheinlichkeitswerts im Generierungsprozess nahezu unmerkliche Wasserzeichen einzubetten, ohne die Textqualität und das Benutzererlebnis zu beeinträchtigen, wodurch eine hohe Erkennungsgenauigkeit erreicht wird.
Dieses Projekt kann über die Gradio-Schnittstelle eine interaktive Front-End-Schnittstelle generieren. Die entsprechenden Modelle und Abhängigkeiten wurden bereitgestellt und der Wasserzeichentext kann mit nur einem Klick generiert werden.
Online ausführen:https://go.hyper.ai/lQ1UK
2. Evo: Sequenzvorhersage und -generierung vom molekularen bis zum Genommaßstab
Evo ist ein biologisch fundiertes Modell, das die grundlegenden Sprachen der Biologie verallgemeinert: DNA, RNA und Proteine. Das Modell ist in der Lage, Vorhersageaufgaben und generative Designs durchzuführen und deckt die Sequenzvorhersage und -generierung im Maßstab von Molekülen bis hin zu ganzen Genomen ab.
Klicken Sie auf den Link unten und folgen Sie dem Tutorial, um Sequenzen im Genommaßstab vorherzusagen.
Online ausführen:https://go.hyper.ai/LgFWm
3. VASP-Tutorial: 1-1. DFT-Berechnung eines isolierten Sauerstoffatoms
VASP ist ein Softwarepaket zur Durchführung von Berechnungen elektronischer Strukturen und Simulationen der Quantenmechanik und Molekulardynamik. Es handelt sich um eine der beliebtesten kommerziellen Softwareprogramme für Materialsimulation und computergestützte Materialforschung. Seine hohe Genauigkeit und leistungsstarken Funktionen machen es zu einem wichtigen Werkzeug für Forscher zur Vorhersage und Entwicklung von Materialeigenschaften. Es wird häufig in der Festkörperphysik, den Materialwissenschaften, der Chemie, der Molekulardynamik und anderen Bereichen verwendet.
Dieses Tutorial ist der erste Teil des offiziellen VASP-Tutorials: DFT-Berechnungen isolierter Sauerstoffatome. Klicken Sie auf den Link unten und folgen Sie dem Tutorial, um DFT-Hochleistungsberechnungen von Grund auf zu starten.
Online ausführen:https://go.hyper.ai/pa2NX
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Community-Artikel
Die inverse molekulare Faltung spielt eine Schlüsselrolle bei der Entwicklung von Medikamenten und Materialien, doch die Forschung in der Vergangenheit hat sich selten auf die inverse Faltung allgemeiner Moleküle konzentriert. Als Reaktion darauf schlug ein Team des Future Industries Research Center der Westlake University ein einheitliches Modell namens UniIF für die umgekehrte Faltung aller Moleküle vor. Experimentelle Ergebnisse zeigen, dass UniIF bei mehreren Aufgaben wie Proteindesign, RNA-Design und Materialdesign Spitzenleistungen erzielt hat. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/efhze
Bei der interdisziplinären Anwendung der KI-Technologie ist die Frage, wie diskrete und kontinuierliche Variablen kombiniert werden können, um die Qualität der Kristallmaterialerzeugung zu verbessern, zu einem Kernproblem im Bereich der Kristallmaterialerzeugung geworden. Um dieses Problem zu lösen, hat Meta FAIR Lab das Materialgenerierungsmodell FlowLLM veröffentlicht. Die Effizienz dieses Modells bei der Erzeugung stabiler Materialien ist im Vergleich zu früheren Modellen um mehr als 300% verbessert, und die Effizienz bei der Erzeugung von SUN-Materialien ist ebenfalls um etwa 50% verbessert. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/KJzjz
Kürzlich haben die Shanghai Jiao Tong University und das Shanghai Artificial Intelligence Laboratory erfolgreich ein vortrainiertes Proteinsprachenmodell mit Strukturerkennungsfunktionen entwickelt – ProSST. Das Modell ist auf einem großen Datensatz mit 18,8 Millionen Proteinstrukturen vortrainiert und kann Proteinstruktur- und Aminosäuresequenzinformationen effektiv integrieren, wodurch es bei überwachten Lernaufgaben bestehende Modelle deutlich übertrifft. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/qi5ei
Das Shanghai Artificial Intelligence Laboratory und andere wissenschaftliche Forschungseinrichtungen haben den GMAI-MMBench-Benchmark vorgeschlagen, der 284 Downstream-Task-Datensätze weltweit abdeckt, darunter 38 medizinische Bildgebungsmodalitäten, 18 klinisch verwandte Aufgaben, 18 Abteilungen und 4 Wahrnehmungsgranularitäten im visuellen Frage-und-Antwort-Format. Es handelt sich um den bislang umfassendsten allgemeinmedizinischen Benchmark. Darüber hinaus fasst dieser Artikel auch weitere medizinische Datensätze inklusive Links zur One-Click-Nutzung für Sie zusammen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/csr2M
Beliebte Enzyklopädieartikel
1. Sigmoidfunktion
2. Nukleare Norm
3. Künstliche neuronale Netze
4. Datenerweiterung
5. Quantenneuronales Netzwerk
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
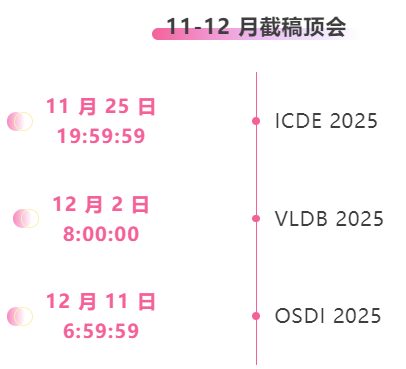
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung inländischer beschleunigter Download-Knoten für über 1300 öffentliche Datensätze
* Enthält über 400 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 500 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:
Abschließend empfehle ich ein „Creator Incentive Program“. Interessierte Freunde können den QR-Code scannen, um teilzunehmen!









