Command Palette
Search for a command to run...
Ausgewählt Für NeurIPS 2024! Das Team Der Chinesischen Akademie Der Wissenschaften Schlug Ein Neues Framework Für Die nicht-invasive Gehirnentschlüsselung Vor Und Legte Damit Den Grundstein Für Die Entwicklung Von Gehirn-Computer-Schnittstellen Und Kognitiven Modellen
Können Sie sich vorstellen, die Bilder zu visualisieren, die Sie sehen, denken oder von denen Sie sogar träumen? Dies ist nicht bloß eine wilde Fantasie. Bereits 2008 stellte Jack Gallant, Neurowissenschaftler an der University of California, Berkeley, seine Hypothese in Nature vor. Sie verwendeten die funktionelle Magnetresonanztomographie (fMRI) – eine nicht-invasive funktionelle Bildgebungstechnologie des Gehirns –, um die Aktivität des visuellen Kortex des Probanden zu „lesen“ und visualisierten dann die vom Probanden gesehenen Bilder durch visuelle Rekonstruktion.Dies war für Wissenschaftler auf der ganzen Welt ein Weckruf, das Gehirn zu entschlüsseln.
Im Vergleich zur invasiven Gehirndekodierungstechnologie wird die nicht-invasive Gehirndekodierungstechnologie, die durch fMRI repräsentiert wird, hoch geschätzt, da sie die Gehirndekodierung auf einfachere und sicherere Weise ermöglicht. Es verfügt über einen großen potenziellen Anwendungswert in vielen Bereichen, beispielsweise in der kognitiven neurowissenschaftlichen Forschung, bei Anwendungen von Gehirn-Computer-Schnittstellen und in der klinisch-medizinischen Diagnose.
Die nichtinvasive Dekodierung von Gehirnsignalen wird jedoch durch individuelle Unterschiede und die Komplexität der neuronalen Signaldarstellung erschwert und bleibt eine zentrale Herausforderung im Dekodierungsprozess des Gehirns.Einerseits basieren traditionelle Methoden auf maßgeschneiderten Modellen und einer großen Anzahl teurer Experimente. Andererseits ist es aufgrund des Mangels an genauer Semantik und Interpretierbarkeit für herkömmliche Methoden schwierig, die visuelle Erfahrung einer Person bei visuellen Rekonstruktionsaufgaben genau zu reproduzieren.
Als Reaktion darauf hat das Team von Professor Zeng Yi vom Institut für Automatisierung der Chinesischen Akademie der Wissenschaften auf innovative Weise ein multimodales Integrationsframework entwickelt, das fMRI-Merkmalsextraktoren mit großen Sprachmodellen kombiniert, um das Problem der visuellen Rekonstruktion der Gehirnaktivität zu lösen..Mithilfe von Vision Transformer 3D (ViT3D) kombinierten die Forscher die 3D-Gehirnstruktur mit visueller Semantik, richteten fMRI-Funktionen mit mehrstufigen visuellen Einbettungen durch einen effizienten einheitlichen Merkmalsextraktor aus und extrahierten Informationen aus einzelnen experimentellen Daten, ohne dass ein bestimmtes Modell erforderlich war. Darüber hinaus enthält der Extraktor mehrstufige visuelle Funktionen, die die Integration mit großen Sprachmodellen (LLMs) vereinfachen. Durch die Erweiterung von fMRI-Datensätzen und mit fMRI-Bildern verknüpften Textdaten können multimodale große Modelle entwickelt werden.
Das Ergebnis mit dem Titel „Neuro-Vision to Language: Verbesserung der auf Gehirnaufzeichnungen basierenden visuellen Rekonstruktion und Sprachinteraktion“ wurde von NeurIPS 2024 angenommen.
Forschungshighlights:
* Diese Studie verbessert die Fähigkeit, visuelle Reize durch Gehirnsignale zu rekonstruieren, vertieft das Verständnis der relevanten neuronalen Mechanismen und eröffnet neue Wege zur Interpretation der Gehirnaktivität
* Der auf Vision Transformer 3D basierende fMRI-Feature-Extraktor kombiniert 3D-Gehirnstruktur und visuelle Semantik und richtet sie auf mehreren Ebenen aus, wodurch die Notwendigkeit spezifischer Themenmodelle entfällt und gültige Daten in nur einem einzigen Experiment extrahiert werden. Dies reduziert die Trainingskosten erheblich und verbessert die Benutzerfreundlichkeit in realen Szenarien
* Durch die Erweiterung der fMRI-bildbezogenen Textdaten wurde ein multimodales Großmodell erstellt, das fMRI-Daten dekodieren kann. Dies verbesserte nicht nur die Dekodierungsleistung des Gehirns, sondern erweiterte auch seinen Anwendungsbereich, einschließlich visueller Rekonstruktion, komplexer Argumentation, Konzeptlokalisierung und anderer Aufgaben.
Papieradresse:
https://nips.cc/virtual/2024/poster/93607
Folgen Sie dem offiziellen Konto und antworten Sie mit „Brain signal decoding“, um das vollständige PDF zu erhalten
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Datensatz: Basierend auf dem Datensatz natürlicher Szenen wird die Testzuverlässigkeit streng bewertet
Zu den im Experiment verwendeten Datensätzen gehören der Natural Scenes Dataset (NSD)-Datensatz und der COCO-Datensatz.Der NSD-Datensatz enthält hochauflösende 7-Tesla-fMRI-Scans von 8 gesunden erwachsenen Teilnehmern, aber in der spezifischen experimentellen Analyse analysierten die Forscher hauptsächlich die 4 Personen, die die gesamte Datenerfassung abgeschlossen hatten.
Die Forscher haben den NSD-Datensatz außerdem vorverarbeitet, um eine zeitliche Neuabtastung durchzuführen und so zeitliche Unterschiede in den Schnitten zu korrigieren. Außerdem haben sie eine räumliche Interpolation durchgeführt, um Kopfbewegungen und räumliche Verzerrungen auszugleichen. Beispielsweise können Änderungen wie das Zuschneiden zu einer Nichtübereinstimmung zwischen dem Originaltitel und dem Begrenzungsrahmen der Instanz führen, wie in der folgenden Abbildung gezeigt. Um die Datenkonsistenz sicherzustellen, haben die Forscher die zugeschnittenen Bilder neu annotiert, mit BLIP2 8 Bildunterschriften für jedes Bild erstellt und mit DETTR Begrenzungsrahmen für diese Bilder generiert.

Da einige Bilder abgeschnitten sind, besteht eine Nichtübereinstimmung zwischen der ursprünglichen Beschriftung und dem Begrenzungsrahmen der Instanz.
Um die Kompatibilität zwischen fMRI-Daten und LLMs sicherzustellen und die Befolgung von Anweisungen sowie vielfältige Interaktionen zu erreichen, hat das Team bei der Annotation von NSD mithilfe natürlicher Sprache außerdem sieben Dialogtypen erweitert, und zwar: kurze Beschreibungen, ausführliche Beschreibungen, fortlaufende Dialoge, komplexe Denkaufgaben, Anweisungsrekonstruktion und Konzeptlokalisierung.
Um schließlich die Standardisierung der Daten sicherzustellen, verwendeten die Forscher eine trilineare Interpolation, um die Daten auf eine einheitliche Dimension zu bringen, stellten die fMRI-Normalisierung auf 83 × 104 × 81 ein und teilten die Daten in 14 × 14 × 14 Patches auf, nachdem sie an den Rändern Null-Padding angewendet hatten, um lokale Informationen zu erhalten.
Modellarchitektur: ein multimodales Integrationsframework, das die Extraktion von fMRI-Merkmalen und LLMs integriert
Um die visuelle Rekonstruktion der Gehirnaktivität zu lösen und das Fusionsproblem von LLMs und multimodalen Daten zu beseitigen, hat das Forschungsteam auf innovative Weise ein multimodales Integrationsframework entwickelt, das die fMRI-Merkmalsextraktion und ein großes Sprachmodell integriert.Wie in der folgenden Abbildung dargestellt:
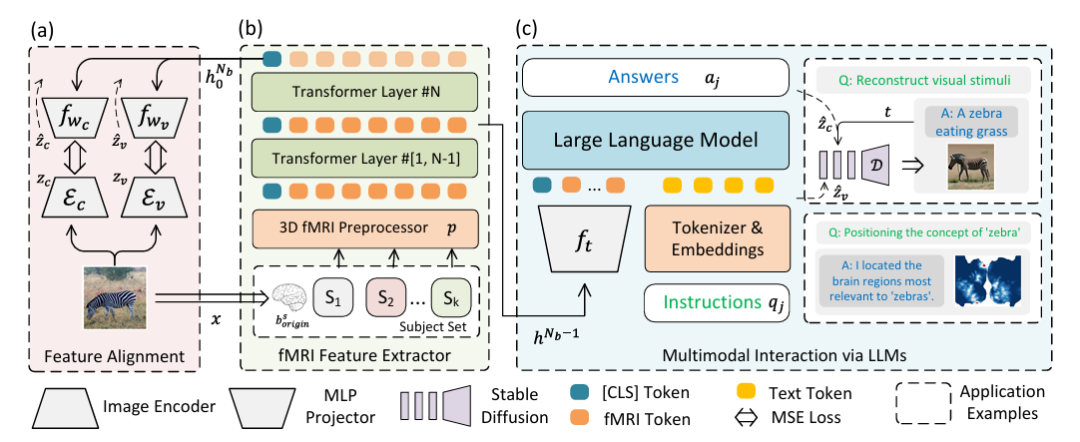
Speziell,Teil (a) der obigen Abbildung beschreibt den Zwei-Stream-Pfad für die Merkmalsausrichtung mithilfe von Variational Autoencoder (VAE) und CLIP-Einbettung.Im experimentellen Umfeld werden CLIP ViT-L/14 und AutocoderKL als Bildmerkmalsextraktoren integriert und zwei zweischichtige Perzeptronen fwc und fwv mit einer verborgenen Dimension von 1024 werden zur Ausrichtung mit VAE- (zv = Ev) bzw. CLIP- (zc = Ec) Merkmalen verwendet.
Teil (b) der obigen Abbildung beschreibt einen 3D-fMRI-Präprozessor p und einen fMRI-Feature-Extraktor (fMRl Feature Extractor).Für fMRI-Daten wurde ein 16-Schicht-Transform-Encoder mit einer verborgenen Größe von 768 zum Extrahieren von Merkmalen verwendet, und die Klassenbezeichnung der letzten Schicht wurde als Ausgabe verwendet. Kehren Sie dann zur Ausrichtung zu Abbildung (a) zurück, um eine qualitativ hochwertige visuelle Rekonstruktion zu erreichen.
Teil (c) der obigen Abbildung zeigt multimodale LLMs, die mit fMRI integriert sind.Das heißt, multimodale Interaktion wird durch LLM erreicht (Multimodale Interaktion über LLMs). Der Hauptzweck besteht darin, die extrahierten Merkmale in LLMs einzugeben, um Anweisungen in natürlicher Sprache zu verarbeiten und Antworten oder visuelle Rekonstruktionen zu generieren. Dieser Teil verwendet den vorletzten verborgenen Zustand des Netzwerks hᴺᵇ⁻¹ als multimodalen Marker für fMRI-Daten, fₜ ist ein zweischichtiges Perzeptron, „Anweisung“ stellt die Anweisung in natürlicher Sprache dar und „Antwort“ stellt die von LLMs generierte Reaktion dar.
Nach der anweisungsbasierten Feinabstimmung kann das Modell direkt über natürliche Sprache kommunizieren und die visuelle Rekonstruktion und Positionserkennung von in natürlicher Sprache ausgedrückten Konzepten unterstützen, wobei UnCLIP für die visuelle Rekonstruktion und GradCAM für die Konzeptlokalisierung verwendet werden. In der Abbildung steht D für eingefrorenes UnCLIP.
Experimentelle Ergebnisse: Drei große Experimente und mehrere Vergleiche zeigen, dass das neue Framework bei der Dekodierung von Gehirnsignalen gute Ergebnisse liefert
Um die Leistung des vorgeschlagenen Rahmens zu bewerten, führten die Forscher verschiedene Arten von Experimenten durch, etwa Untertitelung und Fragenbeantwortung, visuelle Rekonstruktion und Konzeptlokalisierung, und verglichen sie mit anderen Methoden, um die Machbarkeit und Effizienz des Rahmens zu überprüfen.
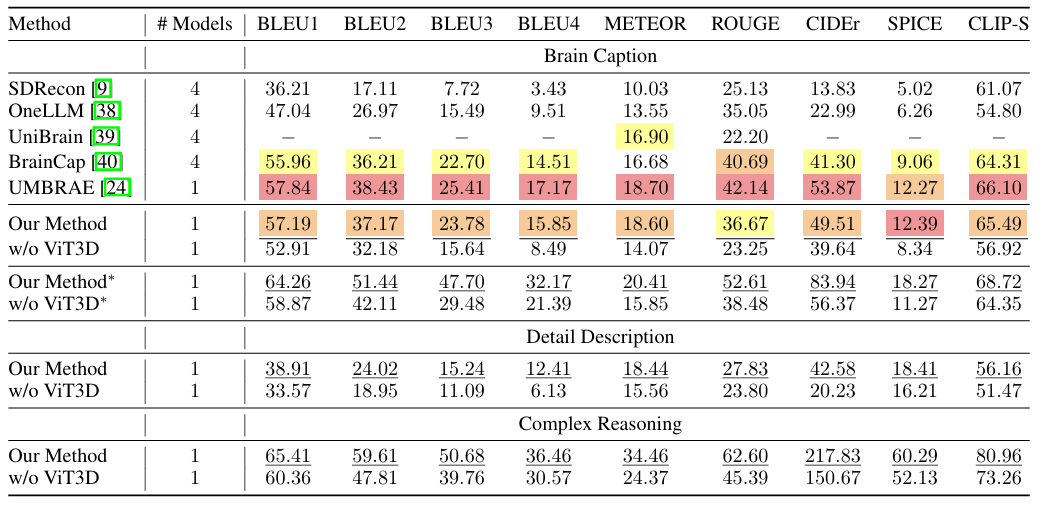
Wie in der folgenden Abbildung dargestellt, zeigt das vorgeschlagene Framework bei den meisten Indikatoren der Brain-Caption-Aufgabe eine hervorragende Leistung. Darüber hinaus verfügt das Framework über eine gute Generalisierungsfähigkeit, ohne dass für jedes Thema ein separates Modell trainiert oder fachspezifische Parameter eingeführt werden müssen.Die Forscher kombinierten außerdem Aufgaben zur detaillierten Beschreibung und zum komplexen Denken. Auch bei diesen beiden Aufgaben erreichte das Framework Spitzenleistungen und zeigte, dass es nicht nur einfache Bildunterschriften erstellen, sondern auch detaillierte Beschreibungen erstellen und komplexes Denken durchführen kann.
Im visuellen Rekonstruktionsexperiment, wie in der Abbildung unten gezeigt. Die vorgeschlagene Methode eignet sich gut für die Merkmalsübereinstimmung auf hoher Ebene und demonstriert die Fähigkeit des Modells, LLMs effektiv zur Interpretation komplexer visueller Daten zu nutzen.Die Robustheit gegenüber verschiedenen visuellen Reizen bestätigt das umfassende Verständnis der fMRI-Daten durch die vorgeschlagene Methode. Bei Experimenten ohne Schlüsselkomponenten wie LLM- und VAE-Funktionen sinken die Punktzahlen, was die Bedeutung jedes einzelnen Elements des untersuchten Ansatzes unterstreicht, der für das Erreichen hochmoderner Ergebnisse von entscheidender Bedeutung ist.
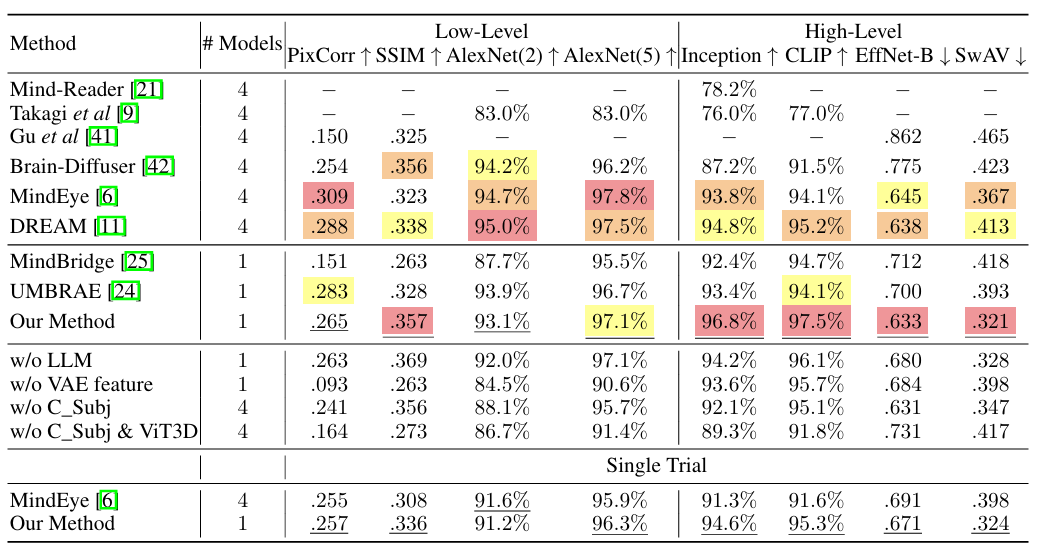
Darüber hinaus führten die Forscher eine Einzelversuchsvalidierung durch und entschieden sich dafür, ähnlich dem MindEye-Ansatz nur den ersten visuellen Reiz zu verwenden. Die Ergebnisse zeigen, dass die vorgeschlagene Methode selbst unter strengeren Bedingungen nur eine geringe Leistungsverschlechterung aufweist.Es beweist seine Machbarkeit in der praktischen Anwendung.
In den Konzeptlokalisierungsexperimenten haben die Forscher zunächst LLMs feinabgestimmt, um Zielkonzepte aus der natürlichen Sprache zu extrahieren, die nach der Kodierung durch den CLIP-Textkodierer zu den Zielen von GradCAM wurden. Um die Lokalisierungsgenauigkeit zu verbessern, trainierten die Forscher drei Modelle mit unterschiedlichen Patchgrößen (14, 12 und 10) und verwendeten die vorletzte Schicht aller Modelle, um semantische Merkmale zu extrahieren. Wie in der Abbildung unten gezeigt, zeigt diesDie vorgeschlagene Methode ist in der Lage, die Positionen verschiedener Semantiken in Gehirnsignalen desselben visuellen Reizes zu unterscheiden.

Um die Wirksamkeit dieser Methode zu überprüfen, führten die Forscher eine Ablationsstudie zu semantischen Konzepten durch. Nach der Lokalisierung der Konzepte in den ursprünglichen Gehirnsignalen werden die Signale in den identifizierten Voxeln auf Null gesetzt und die modifizierten Gehirnsignale werden dann zur Merkmalsextraktion und visuellen Rekonstruktion verwendet. Wie in der folgenden Abbildung gezeigt, führt das Entfernen der neuronalen Aktivität in bestimmten Gehirnregionen, die mit bestimmten semantischen Konzepten verbunden sind, dazu, dass die entsprechende Semantik bei der visuellen Rekonstruktion ignoriert wird.Dies bestätigt die Gültigkeit des Ansatzes zur Konzeptlokalisierung in Gehirnsignalen und zeigt die Fähigkeit der Methode, semantische Informationen aus der Gehirnaktivität zu extrahieren und zu modifizieren, was für das Verständnis der semantischen Informationsverarbeitung im Gehirn von entscheidender Bedeutung ist.

Insgesamt nutzt unser Framework die Leistungsfähigkeit von Vision Transformer 3D mit fMRI-Daten, erweitert durch die Integration von LLMs, was zu erheblichen Verbesserungen bei der Rekonstruktion visueller Reize aus Gehirnsignalen führt und ein präziseres und interpretierbareres Verständnis der zugrunde liegenden neuronalen Mechanismen ermöglicht. Diese Errungenschaft eröffnet einen neuen Forschungspfad zur Dekodierung und Interpretation der Gehirnaktivität und ist von großer Bedeutung für die Neurowissenschaft und die Gehirn-Computer-Schnittstelle.
Die Wahrheit über die Funktionsweise des menschlichen Gehirns entschlüsseln und das geheimnisvollste Instrument der Natur erforschen
Das Gehirn ist das wichtigste biologische Organ des Menschen und das komplexeste Instrument der Natur. Es verfügt über Hunderte Milliarden Nervenzellen und Billionen verbindender Synapsen, die neuronale Netzwerke und neuronale Schaltkreise bilden, die verschiedene Gehirnfunktionen dominieren. Und mit der kontinuierlichen Weiterentwicklung der Biowissenschaftstechnologie und der künstlichen Intelligenz wird die Wahrheit über die Funktionsweise des Gehirns immer klarer.
Erwähnenswert ist, dass das Institut für Automatisierung der Chinesischen Akademie der Wissenschaften, an dem dieser Artikel veröffentlicht wurde, in meinem Land führend in der Entwicklung künstlicher Intelligenz ist und seit langem Forschungen auf dem Gebiet der Gehirnforschung betreibt, insbesondere zur Kodierung und Dekodierung visueller Informationen im menschlichen Gehirn. Neben dem oben erwähnten Team von Professor Zeng Yi hat das Institut zahlreiche hochrangige Arbeiten zur Gehirnforschung veröffentlicht, die in international renommierten Fachzeitschriften erschienen sind.
So wurden beispielsweise Ende 2008 die Forschungsergebnisse des Teams um Professor He Huiguang von der Fakultät mit dem Titel „Reconstructing Perceived Images from Human Brain Activities with Bayesian Deep Multiview Learning“ in die international anerkannte Fachzeitschrift IEEE Transactions on Neural Networks and Learning Systems im Bereich neuronale Netzwerke und maschinelles Lernen aufgenommen.
In dieser Studie stellte das Forschungsteam den Zusammenhang zwischen visuellen Bildern und Gehirnreaktionen auf wissenschaftlich fundierte Weise dar.Das Problem der visuellen Bildrekonstruktion wird in ein Bayes'sches Inferenzproblem fehlender Ansichten in einem latenten Variablenmodell mit mehreren Ansichten umgewandelt. Diese Forschung bietet nicht nur ein leistungsstarkes Instrument zur Erforschung des Mechanismus der visuellen Informationsverarbeitung im Gehirn, sondern spielt auch eine gewisse Rolle bei der Förderung der Entwicklung von Gehirn-Computer-Schnittstellen und gehirnähnlicher Intelligenz.
Neben dem Institut für Automatisierung der Chinesischen Akademie der Wissenschaften nutzt auch ein Forschungsteam der National University of Singapore fMRI, um die von den Versuchspersonen gesehenen Bilder aufzuzeichnen und sie anschließend mithilfe von Algorithmen des maschinellen Lernens in Bilder umzuwandeln. Die entsprechenden Ergebnisse wurden auf arXiv unter dem Titel „Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding“ veröffentlicht.

Darüber hinaus drängen auch viele kommerzielle Unternehmen darauf, die „Welt des Gehirns“ zu erforschen.Vor nicht allzu langer Zeit teilte Elon Musk auf der Neurosurgeons Conference 2024 auch seine Erkenntnisse zu seinem Brain-Computer-Interface-Unternehmen Neuralink und der Brain-Computer-Interface-Technologie.Einige meinten sogar, die Kosten für Gehirn-Computer-Schnittstellen sollten nicht zu hoch sein.
Kurz gesagt kann man sagen, dass die Technologie zur Gehirnentschlüsselung ein kontinuierlicher und sich schnell entwickelnder Prozess ist. Ob von wissenschaftlichen Forschungseinrichtungen oder kommerziellen Unternehmen gefördert, sie alle nutzen den Ostwind der künstlichen Intelligenz und des maschinellen Lernens, um den Beginn des Zeitalters des intelligenten Gehirns kontinuierlich zu beschleunigen. Man kann auch davon ausgehen, dass sich der wissenschaftliche Fortschritt zwangsläufig in Anwendungen niederschlagen wird, etwa in der Entwicklung von Gehirn-Computer-Schnittstellen, dem Einsatz von Maschinen zum Wohle von Patienten mit geschädigtem Nervensystem usw.









