Command Palette
Search for a command to run...
Das Shanghai AI Lab Und Andere Haben Den Multimodalen Medizinischen Benchmark GMAI-MMBench Veröffentlicht, Der 284 Datensätze Enthält, Die 18 Klinische Aufgaben abdecken.

„Bei einem so intelligenten medizinischen Gerät müssen sich die Patienten nur darauf legen, um den gesamten Prozess vom Scannen über die Diagnose und Behandlung bis hin zur Reparatur abzuschließen und einen gesunden Neustart zu erreichen.“ Dies ist eine Handlung aus dem Science-Fiction-Film „Elysium“ aus dem Jahr 2013.

Heutzutage werden die medizinischen Szenen aus Science-Fiction-Filmen mit der rasanten Entwicklung der künstlichen Intelligenz hoffentlich Realität. Im medizinischen Bereich können groß angelegte visuelle Sprachmodelle (LVLMs) eine Vielzahl von Datentypen wie Bilder, Text und sogar physiologische Signale verarbeiten, wie etwa DeepSeek-VL, GPT-4V, Claude3-Opus, LLaVA-Med, MedDr, DeepDR-LLM usw., und zeigen ein großes Entwicklungspotenzial bei der Diagnose und Behandlung von Krankheiten.
Bevor LVLMs jedoch in der klinischen Praxis eingesetzt werden können, müssen Benchmarktests durchgeführt werden, um die Wirksamkeit der Modelle zu bewerten. Aktuelle Benchmarks basieren jedoch in der Regel auf spezifischer wissenschaftlicher Literatur und konzentrieren sich hauptsächlich auf ein einzelnes Feld, da ihnen unterschiedliche Wahrnehmungsgranularitäten fehlen. Dies erschwert eine umfassende Bewertung der Wirksamkeit und Leistung von LVLMs in realen klinischen Szenarien.
Als Reaktion darauf schlug das Shanghai Artificial Intelligence Laboratory in Zusammenarbeit mit mehreren wissenschaftlichen Forschungseinrichtungen, darunter der University of Washington, der Monash University und der East China Normal University, den GMAI-MMBench-Benchmark vor. GMAI-MMBench basiert auf 284 Downstream-Task-Datensätzen aus der ganzen Welt und deckt 38 medizinische Bildgebungsverfahren, 18 klinisch relevante Aufgaben, 18 Abteilungen und 4 Wahrnehmungsgranularitäten im Visual Question Answering (VQA)-Format ab, mit vollständiger Datenstrukturklassifizierung und multiperzeptueller Granularität.
Die zugehörige Forschung mit dem Titel „GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI“ wurde für den NeurIPS 2024 Dataset Benchmark ausgewählt und als Vorabdruck auf arXiv veröffentlicht.

Papieradresse:
https://arxiv.org/abs/2408.03361v7
Der „GMAI-MMBench Medical Multimodal Evaluation Benchmark Dataset“ ist jetzt auf der offiziellen Website von HyperAI verfügbar und kann mit einem Klick heruntergeladen werden!
Adresse zum Herunterladen des Datensatzes:
https://go.hyper.ai/xxy3w
GMAI-MMBench: Der bislang umfassendste Open-Source-Benchmark für allgemeine medizinische KI
Der gesamte Konstruktionsprozess von GMAI-MMBench kann in drei Hauptschritte unterteilt werden:
Zunächst durchsuchten die Forscher Hunderte von Datensätzen aus globalen öffentlichen Datenbanken und Krankenhausdaten. Nach der Überprüfung, Vereinheitlichung der Bildformate und Standardisierung der Beschriftungsausdrücke blieben ihnen 284 Datensätze mit qualitativ hochwertigen Beschriftungen erhalten.
Es ist erwähnenswert, dass diese 284 Datensätze eine Vielzahl medizinischer Bildgebungsaufgaben wie 2D-Erkennung, 2D-Klassifizierung und 2D/3D-Segmentierung abdecken und von professionellen Ärzten kommentiert werden, wodurch die Vielfalt der medizinischen Bildgebungsaufgaben sowie eine hohe klinische Relevanz und Genauigkeit sichergestellt werden.
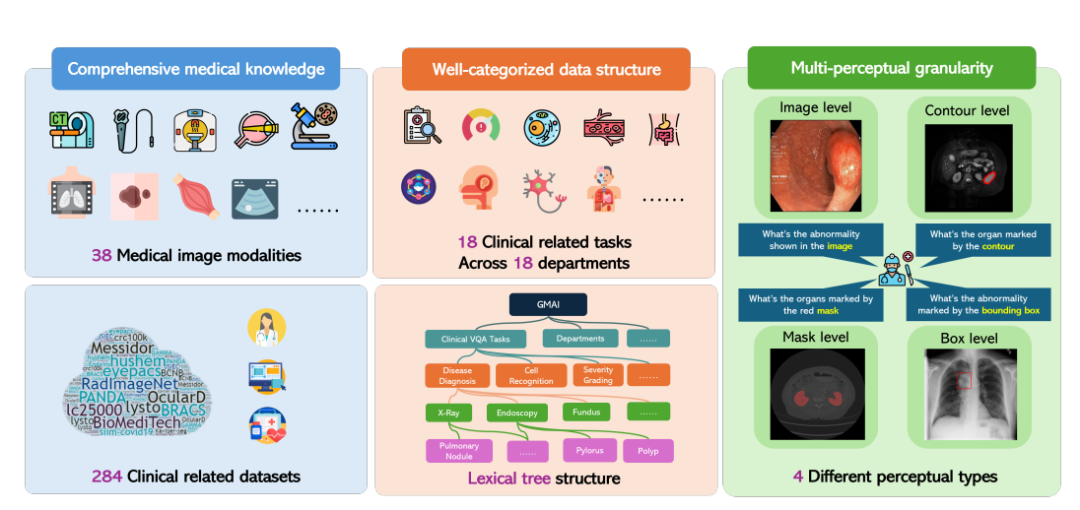
Anschließend klassifizierten die Forscher alle Bezeichnungen in 18 klinische VQA-Aufgaben und 18 klinische Abteilungen. Dadurch war es möglich, die Vor- und Nachteile von LVLMs in verschiedenen Aspekten umfassend zu bewerten, was für Modellentwickler und Benutzer mit spezifischen Anforderungen praktisch ist.
Konkret entwickelten die Forscher ein Klassifizierungssystem namens „lexikalische Baumstruktur“, das alle Fälle in 18 klinische VQA-Aufgaben, 18 Abteilungen, 38 Modalitäten usw. unterteilt. „Klinische VQA-Aufgabe“, „Abteilung“ und „Modalität“ sind Begriffe, die zum Abrufen der erforderlichen Bewertungsfälle verwendet werden können. Beispielsweise können Onkologieabteilungen onkologiebezogene Fälle auswählen, um die Leistung von LVLMs bei onkologischen Aufgaben zu bewerten, wodurch die Flexibilität und Benutzerfreundlichkeit für spezifische Anforderungen erheblich verbessert wird.
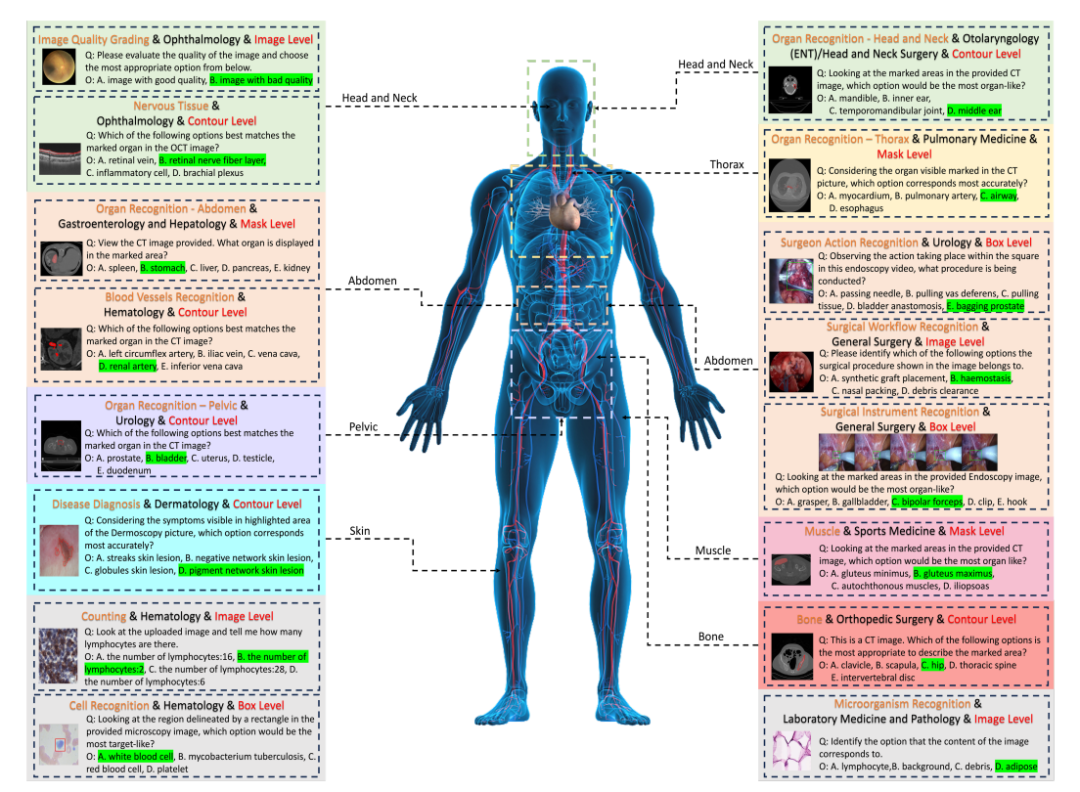
Schließlich generierten die Forscher Frage-Antwort-Paare basierend auf dem Fragen- und Optionenpool, der jedem Etikett entsprach.Jede Frage muss Bildmodalität, Aufgabenaufforderungen und entsprechende Informationen zur Annotation-Granularität enthalten. Der endgültige Benchmark wurde durch zusätzliche Validierung und manuelles Screening erreicht.
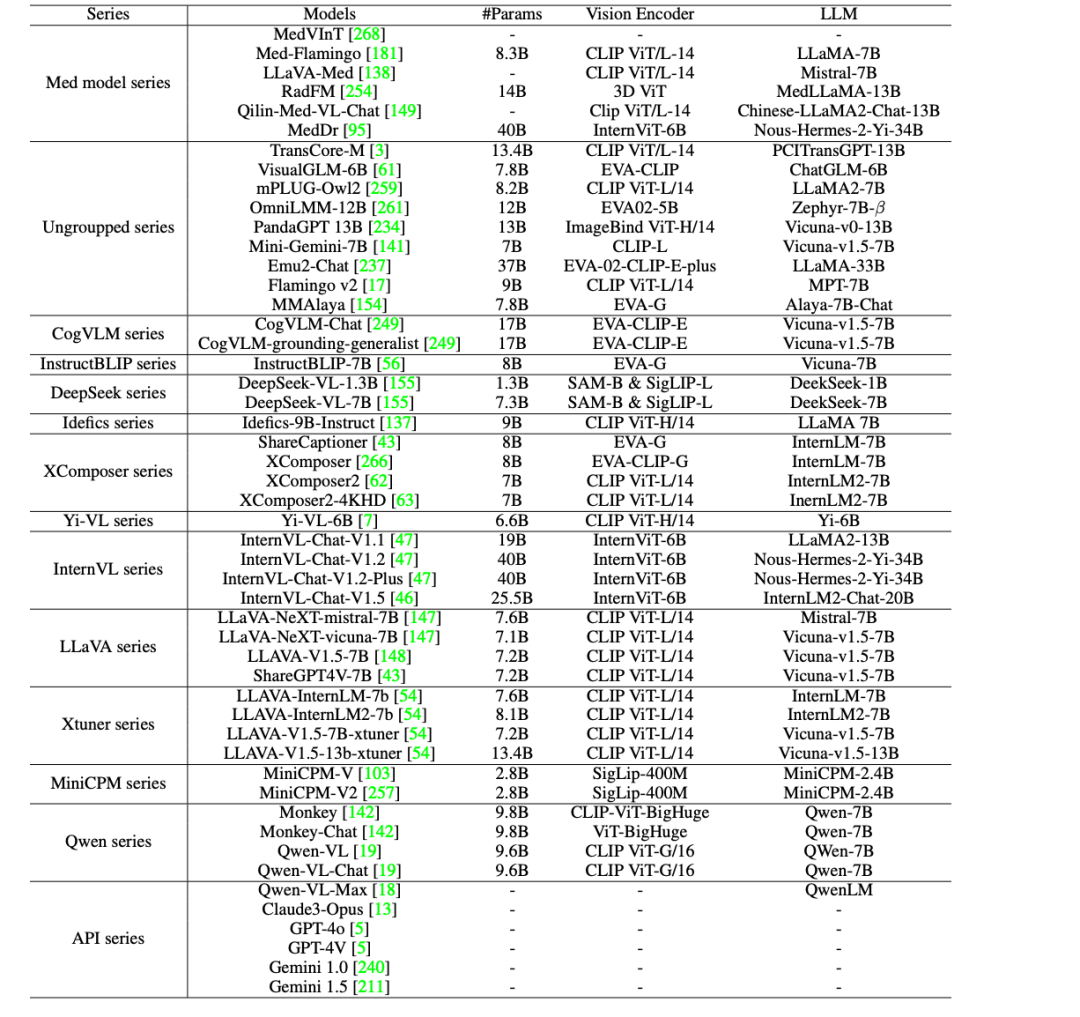
50 Modelle bewertet, welches im GMAI-MMBench-Benchmark die Nase vorn hat
Um die klinische Anwendung von KI im medizinischen Bereich weiter voranzutreiben,Die Forscher bewerteten 44 Open-Source-LVLMs (darunter 38 allgemeine Modelle und 6 medizinspezifische Modelle) und kommerzielle Closed-Source-LVLMs wie GPT-4o, GPT-4V, Claude3-Opus, Gemini 1.0, Gemini 1.5 und Qwen-VL-Max auf GMAI-MMBench.
Die Ergebnisse zeigen, dass die aktuellen LVLMs noch immer fünf wesentliche Mängel aufweisen:
* Bei klinischen Anwendungen besteht noch Verbesserungsbedarf: Selbst das leistungsstärkste Modell, GPT-4o, hat die Anforderungen für praktische klinische Anwendungen erfüllt, seine Genauigkeit beträgt jedoch nur 53,96%, was zeigt, dass aktuelle LVLMs bei der Bewältigung medizinischer Probleme nicht ausreichen und noch viel Raum für Verbesserungen besteht.
* Vergleich von Open-Source-Modellen mit kommerziellen Modellen: Open-Source-LVLMs wie MedDr und DeepSeek-VL-7B haben eine Genauigkeit von etwa 44%, was die kommerziellen Modelle Claude3-Opus und Qwen-VL-Max bei einigen Aufgaben übertrifft und eine mit Gemini 1.5 und GPT-4V vergleichbare Leistung bietet. Allerdings besteht immer noch eine erhebliche Leistungslücke im Vergleich zum leistungsstärksten GPT-4o.
* Die meisten medizinspezifischen Modelle haben Schwierigkeiten, das allgemeine Leistungsniveau von LVLMs für allgemeine Zwecke (Genauigkeit von etwa 30%) zu erreichen, mit Ausnahme von MedDr, das eine Genauigkeit von 43,69% erreicht.
* Die Leistung der meisten LVLMs ist bei unterschiedlichen klinischen VQA-Aufgaben, Abteilungen und Wahrnehmungsgranularitäten ungleichmäßig. Insbesondere ist die Genauigkeit von Annotationen auf Box-Ebene bei Experimenten mit unterschiedlicher Wahrnehmungsgranularität immer am niedrigsten, sogar noch niedriger als die von Annotationen auf Bild-Ebene.
* Zu den Hauptfaktoren, die zu Leistungsengpässen führen, zählen Wahrnehmungsfehler (wie etwa die falsche Identifizierung von Bildinhalten), mangelndes medizinisches Fachwissen, irrelevante Antwortinhalte und die Verweigerung der Beantwortung von Fragen aufgrund von Sicherheitsprotokollen.
Zusammenfassend deuten diese Auswertungsergebnisse darauf hin, dass die Leistungsfähigkeit aktueller LVLMs in medizinischen Anwendungen noch viel Raum für Verbesserungen bietet und weiter optimiert werden muss, um den tatsächlichen klinischen Anforderungen gerecht zu werden.
Erfassung medizinischer Open-Source-Datensätze zur Förderung intelligenter Gesundheitsversorgung
Im medizinischen Bereich sind hochwertige Open-Source-Datensätze zu einer wichtigen treibenden Kraft für den Fortschritt in der medizinischen Forschung und klinischen Praxis geworden. Zu diesem Zweck hat HyperAI einige medizinbezogene Datensätze für Sie ausgewählt, die im Folgenden kurz vorgestellt werden:
PubMedVision – Großer medizinischer VQA-Datensatz
PubMedVision ist ein umfangreicher und hochwertiger medizinischer multimodaler Datensatz, der 2024 von einem Forschungsteam des Shenzhen Big Data Research Institute, der Chinese University of Hong Kong und des National Health Data Institute erstellt wurde und 1,3 Millionen medizinische VQA-Proben enthält.
Um die Ausrichtung der Grafik- und Textdaten zu verbessern, verwendete das Forschungsteam das große visuelle Modell (GPT-4V), um die Bilder neu zu beschreiben und Dialoge in 10 Szenarien zu erstellen. Dabei wurden die Grafik- und Textdaten in ein Frage-und-Antwort-Format umgeschrieben, wodurch das Erlernen medizinischen visuellen Wissens verbessert wurde.
Direkte Verwendung:https://go.hyper.ai/ewHNg
MMedC Großes mehrsprachiges medizinisches Korpus
MMedC ist ein mehrsprachiges medizinisches Korpus, das 2024 vom Smart Healthcare Team der School of Artificial Intelligence der Shanghai Jiao Tong University erstellt wurde. Es enthält ungefähr 25,5 Milliarden Token in sechs Hauptsprachen: Englisch, Chinesisch, Japanisch, Französisch, Russisch und Spanisch.
Das Forschungsteam hat außerdem das mehrsprachige medizinische Basismodell MMed-Llama 3 als Open Source veröffentlicht. Es zeigte in mehreren Benchmarks außergewöhnlich gute Ergebnisse, übertraf bestehende Open-Source-Modelle deutlich und eignet sich besonders für die individuelle Feinabstimmung im medizinischen Bereich.
Direkte Verwendung:https://go.hyper.ai/xpgdM
MedCalc-Bench-Datensatz für medizinische Berechnungen
MedCalc-Bench ist ein Datensatz, der speziell für die Bewertung der medizinischen Rechenkapazitäten großer Sprachmodelle (LLMs) entwickelt wurde. Es wurde 2024 gemeinsam von neun Institutionen veröffentlicht, darunter der National Library of Medicine der National Institutes of Health und der University of Virginia. Dieser Datensatz enthält 10.055 Trainingsinstanzen und 1.047 Testinstanzen, die 55 verschiedene Rechenaufgaben abdecken.
Direkte Verwendung:https://go.hyper.ai/XHitC
OmniMedVQA – Umfangreicher medizinischer VQA-Evaluierungsdatensatz
OmniMedVQA ist ein umfangreicher Visual Question Answering (VQA)-Evaluierungsdatensatz mit Schwerpunkt auf dem medizinischen Bereich. Dieser Datensatz wurde 2024 gemeinsam von der Universität Hongkong und dem Shanghai Artificial Intelligence Laboratory veröffentlicht. Er enthält 118.010 verschiedene Bilder, die 12 verschiedene Modalitäten abdecken und mehr als 20 verschiedene Organe und Teile des menschlichen Körpers betreffen, und alle Bilder stammen aus realen medizinischen Szenen. Ziel ist es, einen Bewertungsmaßstab für die Entwicklung großer medizinischer multimodaler Modelle bereitzustellen.
Direkte Verwendung:https://go.hyper.ai/1tvEH
MedMNIST-Datensatz für medizinische Bilder
MedMNIST wurde am 28. Oktober 2020 von der Shanghai Jiao Tong University veröffentlicht. Es handelt sich um eine Sammlung von 10 öffentlichen medizinischen Datensätzen mit insgesamt 450.000 28*28 medizinischen multimodalen Bilddaten, die verschiedene Datenmodi abdecken und zur Lösung von Problemen im Zusammenhang mit der medizinischen Bildanalyse verwendet werden können.
Direkte Verwendung:https://go.hyper.ai/aq7Lp
Oben sind die von HyperAI in dieser Ausgabe empfohlenen Datensätze. Wenn Sie hochwertige Datensatzressourcen sehen, können Sie uns gerne eine Nachricht hinterlassen oder einen Artikel einreichen, um uns davon zu berichten!
Weitere hochwertige Datensätze zum Download:https://go.hyper.ai/jJTaU
Quellen:
https://mp.weixin.qq.com/s/vMWNQ-sIABocgScnrMW0GA









