Command Palette
Search for a command to run...
Erreichen Sie Multitimbrales Mischen Und Klonen in 3 Sekunden! Das F5/E2 TTS-Tutorial Ist Online; Der Datensatz Für Psychologische Dialoge Von PsyDTCorpus 5k Wird Veröffentlicht, Der Den Sprachstil Psychologischer Berater Genau Simuliert

Im Zuge der rasanten Entwicklung des Stimmklonens ist es der KI gelungen, immer realistischere Stimmeffekte zu simulieren. Allerdings bestehen beim Zero-Sample-Learning und der Steuerung mehrerer Emotionen noch immer zahlreiche Herausforderungen.
Anfang des Jahres hat E2 TTS eine vereinfachte Methode zur Generierung von Text in Sprache implementiert, bei der der eingegebene Text einfach mit Füllmarkierungen auf die gleiche Länge wie die eingegebene Sprache aufgefüllt wird und dann eine Rauschunterdrückung durchgeführt wird, um Sprache zu generieren. Vor Kurzem hat F5 TTS auf diese Methode zurückgegriffen und die Leistung des Modells basierend auf der nicht-autoregressiven Generierungsmethode des Stream-Matchings weiter verbessert, sodass es nicht nur die Synthese mehrerer Sprachen unterstützt, sondern auch Emotionen und Sprechgeschwindigkeit an den Textinhalt anpassen kann, wodurch die Sprachsynthese langer Texte feiner und flüssiger wird.
Damit jeder die Klangerzeugungseffekte von F5 TTS und E2 TTS erleben kann,Auf der offiziellen Website von hyper.ai wurde das Tutorial zur F5/E2-TTS-Integration veröffentlicht, das mit einem Klick geklont werden kann~
Online ausführen:https://go.hyper.ai/SZxqv
Vom 4. bis 8. November gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 3
* Community-Artikelauswahl: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im November: 6
Besuchen Sie die offizielle Website: hyper.ai
Ausgewählte öffentliche Datensätze
1. Haartyp-Datensatz Haartyp-Datensatz
Hair Type Dataset ist ein Bilddatensatz zur Klassifizierung verschiedener Frisuren. Es enthält hochwertige Bilder von 4 Frisurentypen: glatt, wellig, lockig und Dreadlocks, mit insgesamt 1.992 Bildern. Dieser Datensatz hilft beim Trainieren von Modellen des maschinellen Lernens zur Identifizierung und Klassifizierung von Haartypen.
Direkte Verwendung:https://go.hyper.ai/aXYcj

2. AllClear Public Cloud-Entfernungsdatensatz
Der AllClear-Datensatz ist derzeit der größte öffentliche Datensatz zur Wolkenentfernung und enthält 23.742 weltweit verteilte Interessensgebiete (ROIs), die unterschiedliche Landnutzungsmuster abdecken, sowie insgesamt 4 Millionen Bilder. Es befasst sich mit dem Mangel an Benchmarks und vielfältigen Trainingsdaten in der Wolkenentfernungsforschung.
Direkte Verwendung:https://go.hyper.ai/e2BYC

3. Handgeschriebener arabischer Datensatz von Muharaf
Der Muharaf-Datensatz ist ein Datensatz für maschinelles Lernen, der sich auf die Erkennung handschriftlicher arabischer Schriften konzentriert. Dieser Datensatz enthält über 1,6.000 Bilder historischer handschriftlicher Seiten, die von Arabischexperten transkribiert wurden. Zu jedem Dokumentbild gehören die räumlichen Polygonkoordinaten der zugehörigen Textzeilen sowie Informationen zu den grundlegenden Seitenelementen.
Direkte Verwendung:https://go.hyper.ai/NN2UR
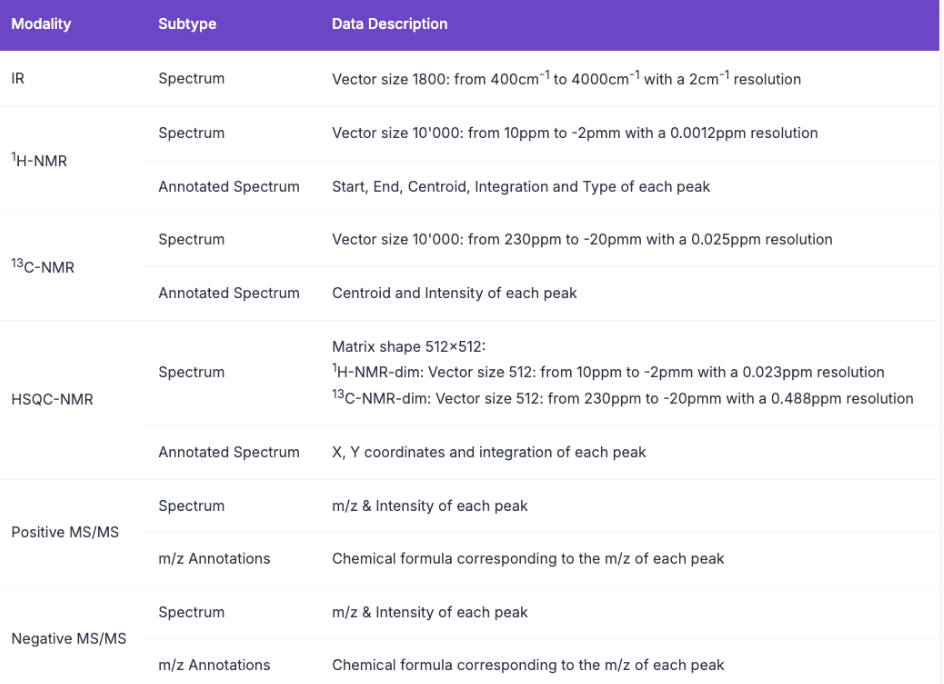
4. Multimodaler spektroskopischer chemischer multimodaler spektroskopischer Datensatz
Der Datensatz enthält simulierte 1H-NMR-, 13C-NMR-, HSQC-NMR-, Infrarot- und Massenspektrometrie-Spektraldaten (positive und negative Ionenmodi) von 790.000 Molekülen, die aus chemischen Reaktionen in Patentdaten extrahiert wurden. Es kann Informationen aus mehreren Spektralmodalitäten integrieren und die von menschlichen Experten zur Analyse molekularer Strukturen verwendeten Methoden simulieren. Dadurch besteht das Potenzial, die Strukturanalyse zu automatisieren und den Prozess der molekularen Entdeckung von der Synthese bis zur Strukturbestimmung zu vereinfachen.
Direkte Verwendung:https://go.hyper.ai/Z7zlr
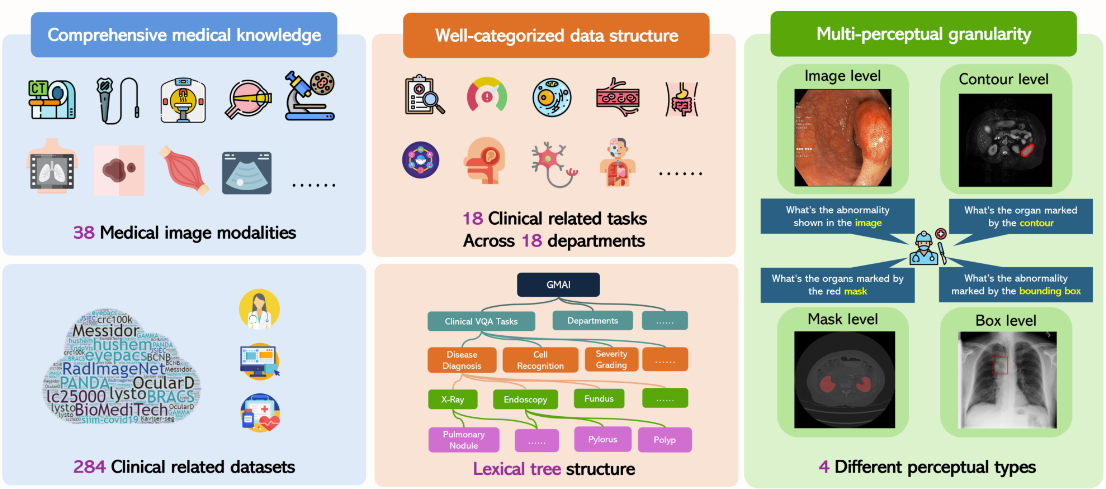
5. GMAI-MMBench Benchmark-Datensatz für die medizinische multimodale Bewertung
GMAI-MMBench ist ein multimodaler Bewertungsmaßstab, der den Bereich der allgemeinen medizinischen künstlichen Intelligenz voranbringen soll. Es enthält 284 Datensätze aus unterschiedlichen Quellen, darunter 38 medizinische Bildmodalitäten und 18 klinisch relevante Aufgaben, die 18 verschiedene medizinische Abteilungen abdecken, und wird mit 4 verschiedenen Wahrnehmungsgranularitäten ausgewertet, wodurch die Leistung von LVLMs aus mehreren Dimensionen berücksichtigt wird.
Direkte Verwendung:https://go.hyper.ai/FL799
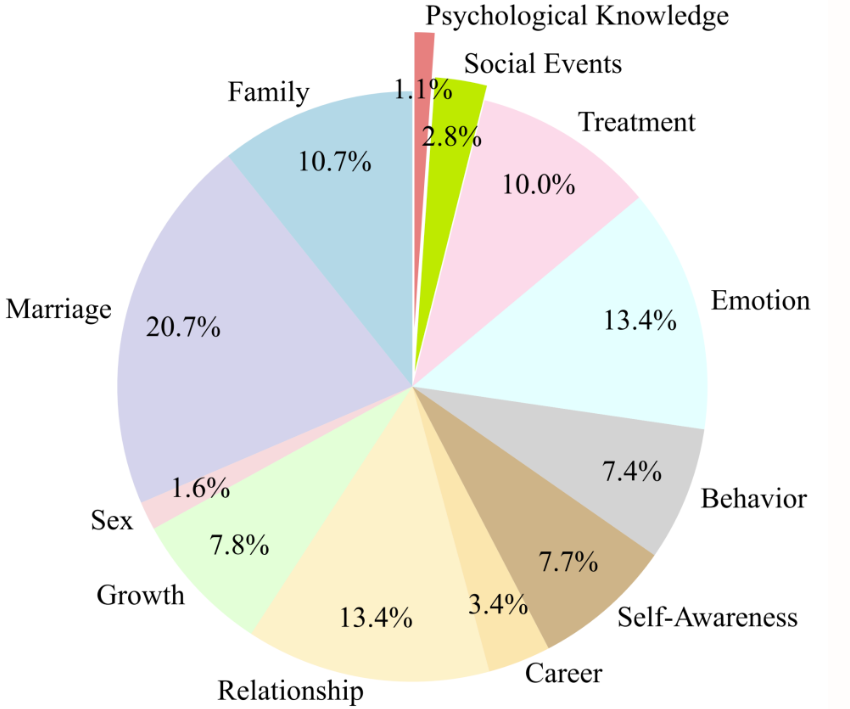
6. PsyDTCorpus Psychological Counselor Digital Twin Dataset
Das Hauptziel des PsyDTCorpus-Datensatzes besteht darin, den Sprachstil und die Beratungstechniken bestimmter psychologischer Berater zu simulieren, um die Entwicklung und Schulung des digitalen Zwillingsmodells für psychologische Berater SoulChat2.0 zu unterstützen. Dieser Datensatz enthält 5.000 hochwertige Gesprächsdaten zum Thema psychische Gesundheit mit Angaben zum Sprachstil des Beraters und den Methoden zur Anwendung therapeutischer Techniken.
Direkte Verwendung:https://go.hyper.ai/hGi4O
7. GTSinger Gesangs-Audiodatensatz
Bei diesem Datensatz handelt es sich um einen großen, qualitativ hochwertigen Open-Source-Gesangsdatensatz, der 80,59 Stunden Gesang enthält, der in professionellen Studios aufgenommen wurde. Diese Lieder werden von 20 professionellen Sängern in 9 verschiedenen Sprachen gesungen, darunter Chinesisch, Englisch, Japanisch, Koreanisch usw., und bieten Forschern eine Ressourcenbibliothek mit äußerst reichen Klangfarben und Stilen.
Direkte Verwendung:https://go.hyper.ai/wBcBz
8. OC22-Katalysator-Simulationsdatensatz
Bei diesem Datensatz handelt es sich um einen Katalysatorsimulationsdatensatz, nämlich den Open Catalyst 2022 (OC22)-Datensatz. Dieser Datensatz erweitert und ergänzt den OC20-Datensatz, enthält komplexere Katalysatorstrukturen und neue Reaktionstypen und bietet umfangreichere Daten zum Trainieren und Testen von KI-Modellen.
Direkte Verwendung:https://go.hyper.ai/M8Cpn
9. OQMD Open Source-Datensatz zu Quantenmaterialien
Der OQMD-Datensatz enthält die thermodynamischen und strukturellen Eigenschaften von mehr als 1,22 Millionen Materialien, berechnet mithilfe der Dichtefunktionaltheorie (DFT). Die Daten im Datensatz stammen aus der Inorganic Crystal Structure Database (ICSD) und umfassen DFT-Gesamtenergieberechnungen von fast 300.000 Verbindungen und Modifikationen gängiger Kristallstrukturen.
Direkte Verwendung:https://go.hyper.ai/dGOKs
10. Online-Materialdatenbank des Materials Project
Die Daten in der Materials Project-Datenbank umfassen Kristallstruktur und Energieeigenschaften sowie detaillierte Informationen wie elektronische Struktur und thermodynamische Eigenschaften. Ziel dieses Datensatzes ist es, mithilfe von Hochdurchsatz-Ab-Prinzipien-Berechnungen umfassende Leistungsdaten, Strukturinformationen und Ergebnisse computergestützter Simulationen für mehr als eine Million anorganische Materialien bereitzustellen und so den Entdeckungs- und Innovationsprozess neuer Materialien zu beschleunigen.
Direkte Verwendung:https://go.hyper.ai/tGIVs
Weitere öffentliche Datensätze finden Sie unter:
Ausgewählte öffentliche Tutorials
1. AnyText mehrsprachige visuelle Textgenerierung und -bearbeitung
AnyText ist ein mehrsprachiges visuelles Modell zur Textgenerierung und -bearbeitung. Es unterstützt die Textgenerierung in mehreren Sprachen wie Chinesisch, Englisch, Japanisch, Koreanisch usw. und unterstützt auch die Bearbeitung von Textinhalten in Eingabebildern. Die in diesem Modell verwendete Textgenerierungstechnologie bietet Möglichkeiten für neue AIGC-Anwendungen wie E-Commerce-Poster, Logodesign, kreative Graffiti und Emoticons.
Klicken Sie auf den Link unten, befolgen Sie die Schritte des Tutorials zum Klonen und Starten des Containers und nutzen Sie anschließend Ihre Kreativität zum Entwerfen von Bildern.
Online ausführen:https://go.hyper.ai/uMcNa
2. F5/E2 TTS klont jeden Ton in nur 3 Sekunden
Dieses Tutorial umfasst eine Demo der Verwendung der TTS-Modelle F5 und E2. F5 TTS kann durch Zero-Shot-Learning ohne zusätzliche Überwachung schnell eine natürliche, flüssige und originalgetreue Aussprache zum Originaltext erzeugen. E2 TTS kann die gesamte Sprachsequenz auf einmal generieren, wodurch die Generierungsgeschwindigkeit erheblich verbessert wird und gleichzeitig eine hochwertige Sprachausgabe gewährleistet bleibt.
Dieses Projekt kann über die Gradio-Schnittstelle eine interaktive Front-End-Schnittstelle generieren. Die relevanten Modelle und Abhängigkeiten wurden bereitgestellt. Sie können das Klonen von Sounds erleben, indem Sie es mit einem Klick starten.
Online ausführen:https://go.hyper.ai/SZxqv
3. Stable-Diffusion-3.5-Demo zur Generierung großer Bilder
Das Modell Stable Diffusion 3.5 Large ist ein Text-zu-Bild-Modell mit einem Multimodal Diffusion Generator (MMDiT), das erhebliche Verbesserungen bei Bildqualität, Typografie, Verständnis komplexer Eingabeaufforderungen und Ressourceneffizienz bietet. Seine enorme Größe von 8 Milliarden Parametern bietet Bilderzeugungsfunktionen auf professionellem Niveau, die sich besonders für Anforderungen zur Erzeugung hochauflösender Bilder eignen.
In diesem Lernprogramm wurde die Umgebung bereitgestellt, und Sie können gemäß den Anweisungen im Lernprogramm direkt hochauflösende Bilder generieren.
Online ausführen:https://go.hyper.ai/w5k5V

💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Community-Artikel
Vor Kurzem hat Meta den umfangreichen Open-Source-Datensatz „Open Materials 2024“ und eine Reihe unterstützender vortrainierter Modelle veröffentlicht. Darunter enthält der OMat24-Datensatz mehr als 110 Millionen Berechnungsergebnisse der Dichtefunktionaltheorie mit Schwerpunkt auf struktureller und kompositorischer Vielfalt. Der Datensatz ist jetzt auf der offiziellen Website von HyperAI verfügbar. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Forschungspapiers.
Den vollständigen Bericht ansehen:https://go.hyper.ai/3wP7R
Während der COSCon'24 veranstaltete HyperAI als Co-Produzenten-Community ein Open-Source-KI-Forum in Richtung KI für die Wissenschaft. Experten und Wissenschaftler der Shanghai Jiao Tong University, der Zhejiang University, der Tsinghua University und der Bayesian Computing-Plattform OpenBayes tauschten ihre Erkenntnisse zu zahlreichen Aspekten aus, darunter künstliche Intelligenz im medizinischen Bereich, künstliche Intelligenz für geografische Informationen, Cloud-Plattformen für intelligentes Computing für die wissenschaftliche Forschung und KI-gesteuerte komplexe urbane Systeme. Dieser Artikel ist ein Rückblick auf die Highlights des Forums. Klicken Sie hier für eine ausführliche Berichterstattung.
Ereigniszusammenfassung anzeigen:https://go.hyper.ai/s2RQU
Das KI-Pharmaunternehmen Terray Therapeutics hat eine Finanzierungsrunde der Serie B in Höhe von 120 Millionen US-Dollar abgeschlossen, die von Nvidias Risikokapitalzweig NVentures und dem neuen Investor Bedford Ridge Capital angeführt wurde. Dies ist zugleich Nvidias zweite Investition in Terray. Das Unternehmen hat außerdem den weltweit größten chemischen Datensatz erstellt und KI mit Nassexperimenten kombiniert, um auf der Datenseite einen geschlossenen Kreislauf zu bilden. Klicken Sie hier für eine ausführliche Erklärung.
Den vollständigen Bericht ansehen:https://go.hyper.ai/AWojF
In der vierten Folge der Live-Serie „Meet AI4S“ spricht Lan Kunyao, ein Ph.D. vom Cross-Media Language Intelligence Laboratory der Shanghai Jiao Tong University hielt eine Rede mit dem Titel „Plattform zur Diagnose und Beratung psychischer Gesundheit basierend auf großen Modellagenten“. Er stellte detailliert die Nutzungsschritte, technischen Highlights und Zukunftspläne der Psychologischen Klinik vor. Dieser Artikel ist eine Abschrift der wichtigsten Punkte der Rede, einschließlich einer Demo der intelligenten psychologischen Klinik. Klicken Sie hier, um es schnell anzusehen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/CHhKC
Beliebte Enzyklopädieartikel
1. Transformatormodell
2. Variationaler Autoencoder VAE
3. Künstliche neuronale Netze
4. Pareto-Front
5. Groß angelegtes Multitasking-Sprachverständnis (MMLU)
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung inländischer beschleunigter Download-Knoten für über 1300 öffentliche Datensätze
* Enthält über 400 klassische und beliebte Online-Tutorials
* Interpretation von über 100 AI4Science-Papierfällen
* Unterstützt die Suche nach über 500 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:
Abschließend empfehle ich ein „Creator Incentive Program“. Interessierte Freunde können den QR-Code scannen, um teilzunehmen!









