Command Palette
Search for a command to run...
Erste! Vier Große Universitäten Haben Gemeinsam Y-Mol Ins Leben Gerufen, Ein Großes Sprachmodell Für Die Arzneimittelforschung Und -entwicklung, Wobei Die Gesamtleistung LLaMA2 Anführt

Große Sprachmodelle, die durch ChatGPT, ChatGLM und LLaMA dargestellt werden, sind für Menschen zu leistungsstarken Werkzeugen geworden, mit denen sie die unbekannte Welt erkunden können. Diese Modelle mit Milliarden von Parametern haben durch sorgfältiges Training umfangreicher Textkorpora leistungsstarke Fähigkeiten bei der Textgenerierung und dem Kontextverständnis bewiesen. Die meisten dieser Modelle sind bei allgemeinen Aufgaben zwar gut geeignet, stehen jedoch in bestimmten Bereichen, insbesondere in der Arzneimittelentwicklung, vor erheblichen Herausforderungen.
Anders als im Bereich der natürlichen Sprachverarbeitung fehlt im Bereich der Arzneimittelforschung und -entwicklung ein einheitliches Standardparadigma und der Forschungs- und Entwicklungsprozess ist komplex und kostspielig. Darüber hinaus sind mehrere Disziplinen wie Computerchemie, Strukturbiologie und Bioinformatik beteiligt. Die relevanten Daten sind schwer zu erhalten und die Kennzeichnung der Interaktionsdaten zwischen drogenbezogenen Einheiten erfordert ausgefeiltes Domänenwissen.Zusammengenommen schränken diese Faktoren die Anwendung großer Sprachmodelle in der Arzneimittelforschung und -entwicklung ein.
Als Reaktion darauf schlugen Forschungsteams der Hunan University, der Central South University, der Hunan Normal University und der Xiangtan University gemeinsam ein großes Sprachmodell Y-Mol vor, das auf multiskaligem biomedizinischem Wissen basiert. Y-Mol ist ein autoregressives Sequenz-zu-Sequenz-Modell, das auf verschiedene Textkorpora und Anweisungen abgestimmt werden kann, wodurch die Leistung und das Potenzial des Modells bei der Arzneimittelentwicklung erheblich verbessert werden. Dies ist ein neuer Durchbruch auf dem Gebiet der Arzneimittelentwicklung unter Verwendung großer Sprachmodelle.
Die Studie mit dem Titel „Y-Mol: A Multiscale Biomedical Knowledge-Guided Large Language Model for Drug Development“ wurde als Vorabdruck auf arxiv veröffentlicht.
Forschungshighlights:
* Y-Mol ist das erste große Sprachmodell, das für die Arzneimittelforschung entwickelt wurde
* Y-Mol erstellt einen informationsreichen Anweisungsdatensatz durch die Integration von biomedizinischem Wissen auf mehreren Ebenen
* Y-Mol zeichnet sich durch hervorragende Leistungen bei Arzneimittelwechselwirkungen, Arzneimittel-Ziel-Wechselwirkungen und der Vorhersage molekularer Eigenschaften aus und zeigt ausgeprägte Fähigkeiten im Verständnis und in der Vielseitigkeit bei verschiedenen Aufgaben der Arzneimittelentwicklung.

Papieradresse:
https://doi.org/10.48550/arXiv.2410.11550
Folgen Sie dem offiziellen Konto und antworten Sie mit „Medikamentenentwicklungsmodell“, um das vollständige PDF zu erhalten
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Erkunden Sie zwei Arten von Datensätzen vollständig, um ein umfassendes biomedizinisches Korpus aufzubauen
Für die Erstellung des Vortrainingsdatensatzes für Y-Mol wurden in der Studie zwei Arten von Datensätzen ausgewählt:Ein Textkorpus aus biomedizinischen PubMed-Publikationen; überwachte Anweisungen, die auf einem biomedizinischen Wissensgraphen basieren, und Inferenzdaten, die aus Expertenmodellen extrahiert wurden.
Um das reichhaltige biomedizinische Wissen in Publikationen gründlich zu erforschen,Im Rahmen der Studie wurden über 33 Millionen Publikationen aus verschiedenen Disziplinen von Online-Publikationsplattformen wie PubMed extrahiert und vorverarbeitet.Wie in Abbildung A unten dargestellt, extrahierten die Forscher sichtbare Abstracts und Einleitungen aus diesen Veröffentlichungen als biomedizinische Textdaten (rekonstruierter Text), um die Qualität und Relevanz des Korpus sicherzustellen.
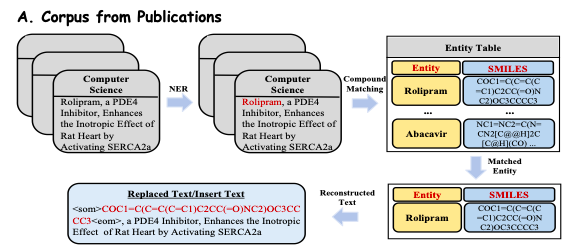
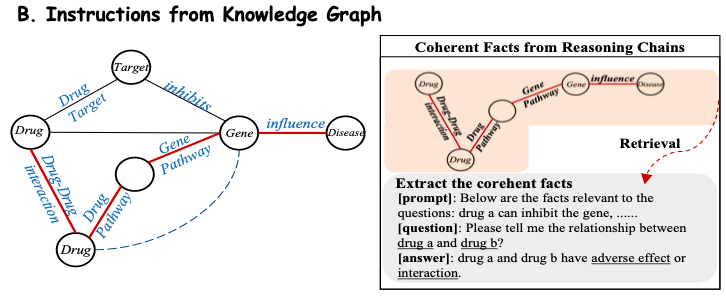
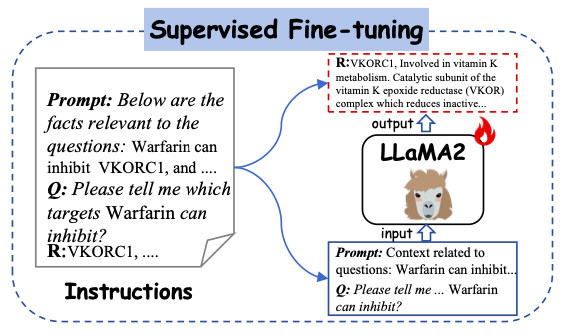
Um Domänenwissen effizient aus der biomedizinischen Wissensbasis zu extrahieren, wandelt diese Studie die Fakten in der Wissensbasis in natürliche Spracheingaben um.Wie in Abbildung B unten dargestellt, geht diese Studie davon aus, dass jede Argumentationskette im Teilgraphen eine klare relationale Semantik aufweist, sodass jeder zusammenhängende Pfad extrahiert und unter Verwendung einer sorgfältig entworfenen Vorlage als Eingabekontext in eine Beschreibung in natürlicher Sprache umgewandelt wird. Die Studie kombiniert dann diese konstruierten Kontexte mit den entsprechenden Fragen und gibt sie in Y-Mol ein, um überwachte Antworten auszugeben.
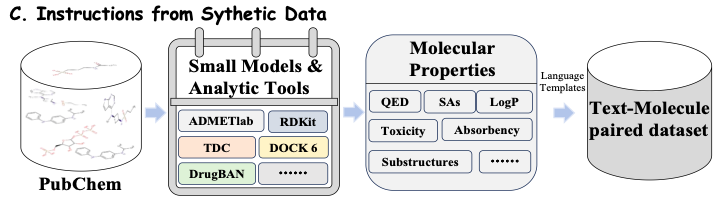
Um darüber hinaus umfassende Anweisungen auf der Grundlage von Arzneimitteleigenschaften und Domänenwissen zu erhalten, wurden in dieser Studie fachkundige synthetische Daten aus vorhandenen kleinen Modellen zur Erstellung von Anweisungen verwendet und das Spektrum des Arzneimittelwissens auf Y-Mol verfeinert.Letztendlich brachte die Studie 11,2 Millionen Korpuseinträge und 2,3 Millionen sorgfältig ausgearbeitete Anweisungen zusammen.
Wie in Abbildung C unten gezeigt, wurden in dieser Studie eine Reihe fortschrittlicher molekularer Werkzeuge und Computermodelle wie ADMETlab, RDKit, TDC und DrugBAN zusammengeführt, um für ein bestimmtes Arzneimittelmolekül umfassendere molekulare Eigenschaften zu extrahieren. Diese Tools und Modelle extrahieren molekulare Informationen mit unterschiedlichen Eigenschaften aus öffentlich verfügbaren Datensätzen, darunter QED, SAs, LogP, Toxizität, Absorption und Substrukturen. Auf diese Weise kann die Forschung kontinuierlich die neuesten Modelle und Tools integrieren und ihre Vorhersagedaten zum Trainieren der Modelle verwenden. Dadurch kann sich Y-Mol in Echtzeit weiterentwickeln und seine führende Position im Bereich der Arzneimittelentwicklung behaupten.
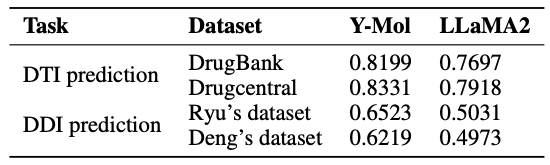
Schließlich zeigt die Studie, wie in der folgenden Abbildung dargestellt, die Datenverteilung von Y-Mol für verschiedene Aufgaben während der Vortrainings- und überwachten Feinabstimmungsphasen. Um die Leistung von Y-Mol bei der Vorhersage von Arzneimittel-Ziel-Interaktionen (DTI) und Arzneimittel-Arzneimittel-Interaktionen (DDI) umfassend zu testen, müssen wir die Inferenzfähigkeit bewerten.Das Forschungsteam wählte die weithin anerkannten Benchmark-Datensätze DrugBank und DrugCentral zur DTI-Vorhersage aus.
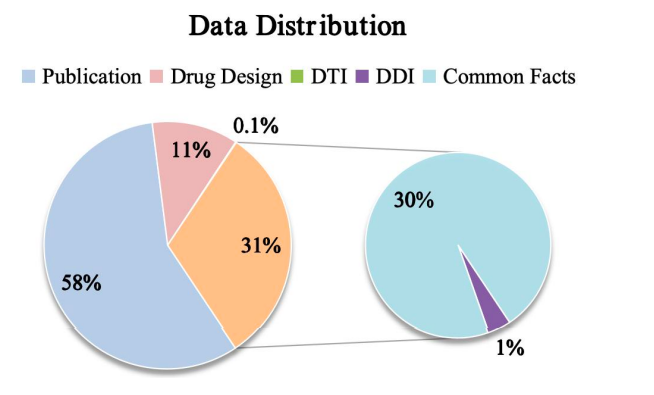
Gleichzeitig nutzten die Forscher den von Ryu und Deng bereitgestellten Datensatz, um die Leistung der DDI-Vorhersage zu bewerten.Diese Bewertungsmethoden wurden sorgfältig ausgewählt, um sicherzustellen, dass Y-Mol im Bereich der Arzneimittelentwicklung fair und umfassend nach Industriestandards getestet werden kann, um seine Wirksamkeit nachzuweisen.
Ryus Datensatz: https://doi.org/10.1073/pnas.1803294115
Dengs Datensatz: https://doi.org/10.1093/bioinformatics/btaa501
Y-Mol: Basierend auf LLaMA2-7b, für die Arzneimittelentwicklung bestimmt
In dieser Studie wurde LLaMA2-7b als grundlegendes großes Sprachmodell ausgewählt, um ein fortgeschrittenes Trainings- und Argumentationsframework speziell für die Arzneimittelentwicklung zu erstellen – Y-Mol. Wie in der Abbildung unten gezeigt,Die Entwicklung von Y-Mol gliederte sich in zwei Hauptphasen:
Erste,Y-Mol ist anhand eines umfangreichen Korpus biomedizinischer Veröffentlichungen vortrainiert und optimiert LLaMA2 durch selbstüberwachtes Vortraining, sodass Y-Mol ein grundlegendes Verständnis des Hintergrundwissens zur Arzneimittelentwicklung erlangt.Dann,LLaMA2 wird mithilfe von medikamentenbezogenem Fachwissen und synthetischen Expertendaten weiter überwacht und optimiert. Durch diesen Prozess wird eine große Menge an arzneimittelbezogenen Informationen in Y-Mol eingegeben, wodurch das Verständnis des Modells für die Interaktionsmechanismen im Arzneimittelentwicklungsprozess verbessert wird.
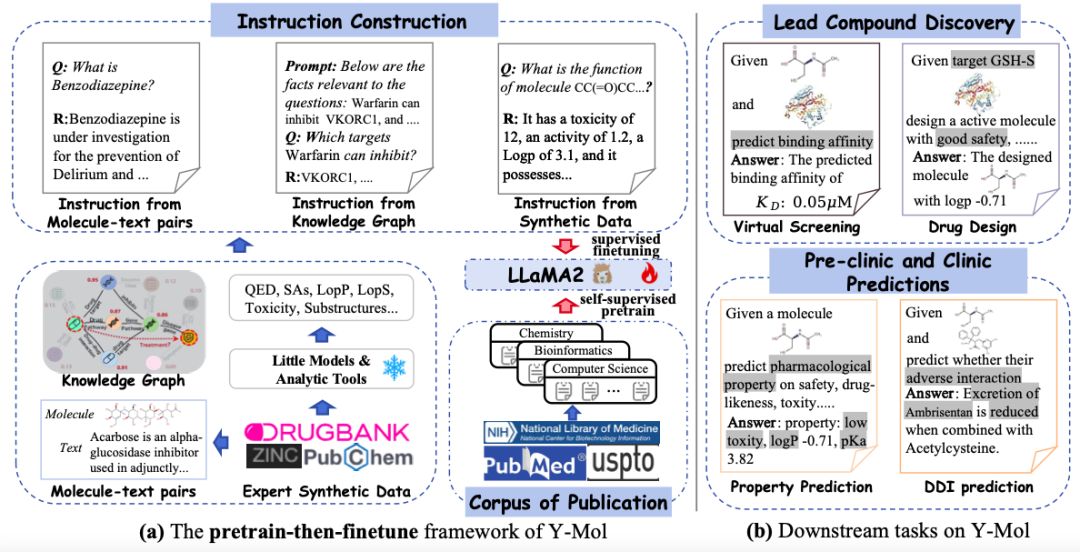
Im Rahmen der Studie wurde sorgfältig ein vielfältiger Satz von Anweisungen entwickelt und Y-Mol fein abgestimmt. Diese Anweisungen umfassen Anweisungen aus Molekül-Text-Paaren und Beschreibungen, die aus Arzneimitteldatenbanken extrahiert wurden. Diese Beschreibungen stellen die Eigenschaften, Struktur und Funktion von Arzneimitteln in natürlicher Sprache dar und enthalten umfangreiche semantische Informationen, die dazu beitragen, die Konsistenz zwischen Menschen und großen Sprachmodellen bei der Wahrnehmung von Arzneimittelentitäten zu verbessern.
Wie in der folgenden Abbildung gezeigt, verwendet diese Studie die generierten Anweisungen als Eingabe für überwachtes Lernen und speist sie in Y-Mol ein. Insbesondere werden konstruierte Eingabekontexte und Fragen in Y-Mol eingegeben und diese konstruierten Antworten werden verwendet, um die vom Modell generierten Ausgaben zu überwachen.
Nachdem die Forscher Y-Mol anhand dieser generierten Anweisungen sorgfältig feinabgestimmt hatten, wandten sie es auf eine Reihe nachgelagerter Aufgaben an und deckten dabei mehrere Bereiche ab, von der Entdeckung führender Verbindungen bis hin zu präklinischen und klinischen Vorhersagen. Durch diese überwachte Feinabstimmungsmethode kann Y-Mol komplexe Probleme bei der Arzneimittelentwicklung genauer verstehen und bewältigen und bietet so ein leistungsstarkes Tool für die computergestützte Arzneimittelentwicklung.
Forschungsergebnisse: Y-Mol hat die beste Vorhersageleistung
Um die Wirksamkeit von Y-Mol im Bereich der Arzneimittelforschung und -entwicklung umfassend zu verifizieren, wurde im Rahmen der Studie eine Reihe von Aufgaben sorgfältig konzipiert, die verschiedene Phasen abdecken, wie etwa die Entdeckung von Leitsubstanzen, die vorklinische Forschung und klinische Vorhersagen.Im Einzelnen handelt es sich dabei um folgende verschiedene Hauptaufgaben: (1) virtuelles Screening und Arzneimitteldesign zur Entdeckung führender Verbindungen; (2) Vorhersage der physikalischen und chemischen Eigenschaften entdeckter Leitsubstanzen im präklinischen Stadium; und (3) Vorhersage potenzieller unerwünschter Arzneimittelwirkungen im klinischen Stadium.
Beim virtuellen ScreeningDie Identifizierung unbekannter Wechselwirkungspaare zwischen Arzneimittel und Zielmolekül ist von entscheidender Bedeutung. Wie in der folgenden Tabelle gezeigt, wurden die AUC-Werte von Y-Mol in den Datensätzen von DrugBank und DrugCentral im Vergleich zu LLaMA2 um 5,02% bzw. 4,13% verbessert. Dies weist darauf hin, dass Y-Mol bei der DTI-Vorhersage von Datenquellen mit mehreren Maßstäben gute Ergebnisse erzielt und seine überlegene Leistung beim virtuellen Screening demonstriert.
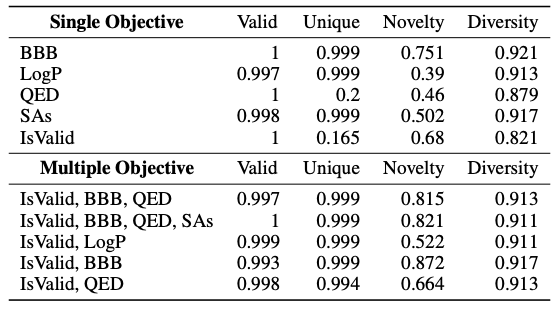
Bei der Entwicklung von ArzneimittelnUm die Leistung von Y-Mol bei der Entdeckung neuer Leitsubstanzen zu überprüfen, wurde im Rahmen der Studie auch eine Aufgabe zur Herstellung wirksamer Verbindungen unter bestimmten Bedingungen entwickelt. Das heißt, bei einer gegebenen Zielbedingung und einer beschreibenden Abfrage wurde bewertet, ob Y-Mol die entsprechenden SMILES-Sequenzmoleküle aus den Kontextinformationen genau generieren konnte.
Wie in der folgenden Tabelle gezeigt, wurden in dieser Studie Standardindikatoren wie „Gültig“, „Einzigartig“, „Neuheit“ und „Vielfalt“ eingeführt, um verschiedene Einzelziele wie BBB und LogP vorherzusagen. Die Ergebnisse zeigten, dass Y-Mol insgesamt eine bessere Leistung zeigte. Im Vergleich dazu war lediglich die Domänenanpassungsfähigkeit des LLaMA2-7b-Modells schlecht und konnte keine wirksamen Moleküle erzeugen. Gleichzeitig wurde in der Studie auch die Leistungsfähigkeit von Y-Mol im Arzneimitteldesign unter verschiedenen Gesichtspunkten getestet. Die Ergebnisse zeigten, dass Y-Mol auch in diesem Fall gute Ergebnisse erzielte.
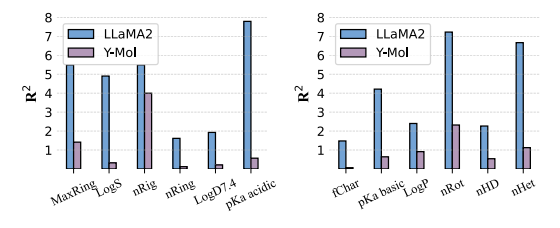
Bei der Vorhersage molekularer EigenschaftenWie in der folgenden Abbildung gezeigt, weist Y-Mol in allen Aufgaben niedrigere R²-Werte auf als LLaMA2, was darauf hindeutet, dass Y-Mol über eine stärkere Generalisierungsfähigkeit bei der Vorhersage physikochemischen Eigenschaften verfügt.
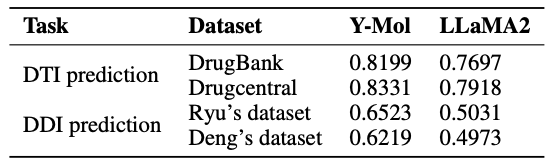
Während der klinischen Phase der Arzneimittelentwicklung ist die Vorhersage potenzieller Wechselwirkungen zwischen Arzneimitteln der Schlüssel zur Gewährleistung einer sicheren Arzneimittelanwendung.Wie in der folgenden Abbildung gezeigt, schneidet Y-Mol bei der Identifizierung potenzieller Arzneimittelwechselwirkungen (DDIs) gut ab.
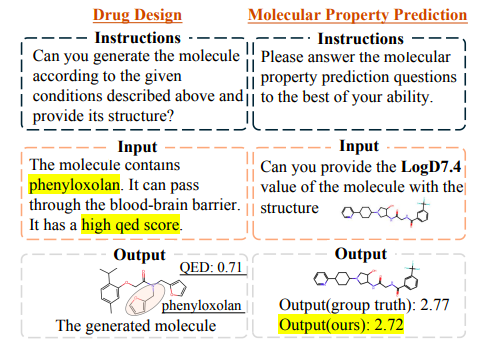
Wie in der Abbildung unten gezeigt,Die von Y-Mol entwickelten Medikamente erfüllen die in der Abfrage gestellten Einschränkungen effektiv. Ebenso kann Y-Mol den LogD7.4 eines gegebenen Moleküls genau vorhersagen, und das vorhergesagte Ergebnis liegt sehr nahe am tatsächlichen Wert.Dies zeigt die Wirksamkeit von Y-Mol bei der Lösung von Aufgaben der Arzneimittelentwicklung.
KI-Technologie: ein neuer Motor in der Arzneimittelentwicklung
Tatsächlich haben Wissenschaftler im langen Prozess der Arzneimittelentwicklung nach neuen Technologien gesucht, die den Prozess beschleunigen können. In den letzten Jahren haben KI-Technologien in diesem Bereich großes Anwendungspotenzial gezeigt. Sie können nicht nur die Krankheitsmechanismen gründlich verstehen, sondern spielen auch in Schlüsselphasen wie der Arzneimittelentdeckung und klinischen Studien eine wichtige Rolle.
In der GeschäftsweltEinige Unternehmen haben bei der Entwicklung von KI-Medikamenten bemerkenswerte Ergebnisse erzielt. So gab beispielsweise das KI-Arzneimittelentwicklungsunternehmen Insilico Medicine Anfang des Jahres bekannt, dass es einen neuen klinischen Arzneimittelkandidaten mit einem neuartigen Mechanismus zur Behandlung der idiopathischen Lungenfibrose entdeckt habe, der in zahlreichen Experimenten an menschlichen Zellen und Tiermodellen verifiziert worden sei. Darüber hinaus hat Huawei Cloud mit dem Shanghai Institute of Materia Medica der Chinesischen Akademie der Wissenschaften zusammengearbeitet, um das Arzneimittelmolekülmodell Pangu auf den Markt zu bringen, das eine durch künstliche Intelligenz unterstützte Arzneimittelentwicklung für den gesamten Prozess der Herstellung niedermolekularer Arzneimittel ermöglichen und die Effizienz und Genauigkeit der Arzneimittelforschung und -entwicklung verbessern kann.
Im Bereich der wissenschaftlichen ForschungEiner der Autoren dieser Studie, das Team von Professor Zeng Xiangxiang an der Hunan-Universität, entwarf auch ein großes Sprachmodell für Peptidsequenzen und trainierte das Modell durch schrittweises Hinzufügen von Berechnungs- und Screeningbedingungen. In nur drei Monaten wurden mit dem Modell erfolgreich 29 potenzielle antimikrobielle Peptide entwickelt und synthetisiert, von denen 26 eine antimikrobielle Breitbandaktivität zeigten. In Experimenten an Mäusen zeigten drei antimikrobielle Peptide eine antibakterielle Wirkung, die mit der von der FDA zugelassener Antibiotika vergleichbar war. Zudem wurde während der kontinuierlichen Kultivierung und Überwachung über einen Zeitraum von bis zu 25 Tagen keine offensichtliche Arzneimittelresistenz beobachtet. Dieses Ergebnis wurde von Nature Communications offiziell anerkannt.
Link zum Artikel:
https://www.nature.com/articles/s41467-024-51933-2
Darüber hinaus hat ein weiterer Autor dieser Studie, Professor Cao Dongsheng von der Central South University, zusammen mit Professor Hou Tingjun und Professor Xie Changyu von der Zhejiang University kürzlich das molekulare Optimierungstool Prompt-MolOpt entwickelt. Der Algorithmus verwendet eine Prompt-Learning-Trainingsstrategie, um die Anwendung von Zero-Shot-Learning und Few-Shot-Learning bei der Multi-Property-Optimierung zu realisieren.
Link zum Artikel:
https://www.nature.com/articles/s42256-024-00916-5
Vom tiefgreifenden Verständnis der Krankheitsmechanismen über die Beschleunigung der Arzneimittelentdeckung bis hin zur Optimierung des Designs klinischer Studien entwickelt sich die KI-Technologie zu einem neuen Motor für die Arzneimittelforschung und -entwicklung. Mit dem fortschreitenden technologischen Fortschritt wird sie in der zukünftigen medizinischen Forschung eine immer wichtigere Rolle spielen.









