Command Palette
Search for a command to run...
Der Benchmark-Test Im Medizinischen Bereich Übertrifft Llama 3 Und Liegt Nahe an GPT-4. Das Team Der Shanghai Jiao Tong University Hat Ein Großes Mehrsprachiges Medizinisches Modell Veröffentlicht, Das 6 Sprachen abdeckt.

Mit der zunehmenden Verbreitung medizinischer Information haben sich Umfang und Qualität medizinischer Daten in unterschiedlichem Maße verbessert. Seit Beginn des Zeitalters der großen Modelle sind in einem endlosen Strom verschiedene große Modelle für unterschiedliche Szenarien wie Präzisionsmedizin, Diagnoseunterstützung und Arzt-Patienten-Interaktion entstanden.
Es ist jedoch erwähnenswert, dass, genau wie das universelle Modell mit dem Problem der mangelnden Mehrsprachigkeitskompetenz konfrontiert ist,Die meisten großen medizinischen Modelle basieren auf englischsprachigen Modellen und sind zudem durch die Knappheit und Streuung mehrsprachiger Daten medizinischer Fachkräfte eingeschränkt, was zu einer schlechten Leistung der Modelle bei der Verarbeitung nicht-englischsprachiger Aufgaben führt.Sogar medizinbezogene Open-Source-Textdaten liegen hauptsächlich in ressourcenintensiven Sprachen vor und die Anzahl der unterstützten Sprachen ist sehr begrenzt.
Aus der Perspektive des Modelltrainings können mehrsprachige medizinische Modelle globale Datenressourcen umfassender nutzen und sogar auf multimodale Trainingsdaten erweitert werden, wodurch die Darstellungsqualität anderer modaler Informationen durch das Modell verbessert wird. Aus Anwendungssicht kann das mehrsprachige medizinische Modell dazu beitragen, sprachliche Kommunikationsbarrieren zwischen Ärzten und Patienten abzubauen und die Genauigkeit von Diagnose und Behandlung in mehreren Szenarien wie der Arzt-Patienten-Interaktion und der Ferndiagnose zu verbessern.
Obwohl die aktuellen Closed-Source-Modelle eine starke mehrsprachige Leistung gezeigt haben, mangelt es im Open-Source-Bereich immer noch an mehrsprachigen medizinischen Modellen.Das Team von Professor Wang Yanfeng und Professor Xie Weidi von der Shanghai Jiao Tong University hat ein mehrsprachiges medizinisches Korpus MMedC mit 25,5 Milliarden Token erstellt, einen mehrsprachigen medizinischen Frage-und-Antwort-Bewertungsstandard MMedBench entwickelt, der 6 Sprachen abdeckt, und ein 8B-Basismodell MMed-Llama 3 erstellt, das in mehreren Benchmarktests bestehende Open-Source-Modelle übertraf und für medizinische Anwendungsszenarien besser geeignet ist.
Die entsprechenden Forschungsergebnisse wurden in Nature Communications unter dem Titel „Towards building multilingual language model for medicine“ veröffentlicht.
Es ist erwähnenswert, dassDer Tutorial-Bereich der offiziellen Website von HyperAI ist jetzt online: „Ein-Klick-Bereitstellung von MMed-Llama-3-8B“.Interessierte Leser können für einen schnellen Einstieg die folgende Adresse besuchen ↓. Außerdem haben wir am Ende des Artikels eine ausführliche Schritt-für-Schritt-Anleitung für Sie vorbereitet!
Bereitstellungsadresse mit einem Klick:
🎁 Einen Vorteil einfügen
Zeitgleich mit dem „1024 Programmers‘ Day“ hat HyperAI Rechenleistungsvorteile für alle vorbereitet!Neue Benutzer, die sich bei OpenBayes.com mit dem Einladungscode „1024“ registrieren, erhalten 20 Stunden kostenlose Nutzung einer einzelnen A6000-Karte.Die Ressource hat einen Wert von 80 Yuan und ist einen Monat lang gültig. Nur heute, die Ressourcen sind begrenzt, wer zuerst kommt, mahlt zuerst!
Forschungshighlights:
* MMedC ist das erste Korpus, das speziell für den mehrsprachigen medizinischen Bereich erstellt wurde, und zugleich das bislang umfangreichste mehrsprachige medizinische Korpus.
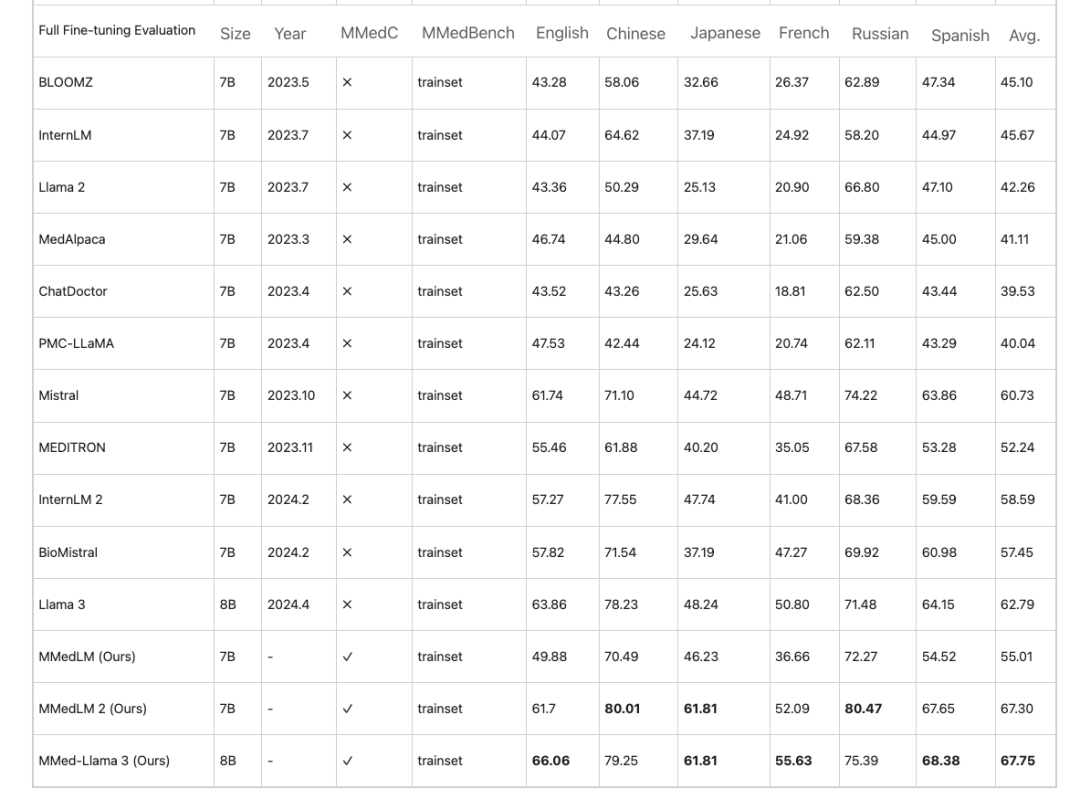
* Autoregressives Training auf MMedC hilft, die Modellleistung zu verbessern. Bei vollständiger Feinabstimmungsbewertung beträgt die Leistung von MMed-Llama 3 67,75, während Llama 3 62,79 beträgt
* MMed-Llama 3 erreicht bei englischen Benchmarks eine Spitzenleistung und übertrifft GPT-3.5 deutlich

Papieradresse:
https://www.nature.com/articles/s41467-024-52417-z
Projektadresse:
https://github.com/MAGIC-AI4Med/MMedLM
Folgen Sie dem offiziellen Konto und antworten Sie mit „Multilingual Medical Big Model“, um das Originaldokument herunterzuladen
Mehrsprachiges medizinisches Korpus MMedC: 25,5 Milliarden Token, die 6 Hauptsprachen abdecken
Das mehrsprachige medizinische Korpus MMedC (Multilingual Medical Corpus) wurde von Forschern erstellt,Deckt 6 Sprachen ab: Englisch, Chinesisch, Japanisch, Französisch, Russisch und Spanisch.Darunter macht Englisch mit 421 TP3T den größten Anteil aus, Chinesisch etwa 191 TP3T und Russisch mit nur 71 TP3T den kleinsten Anteil.
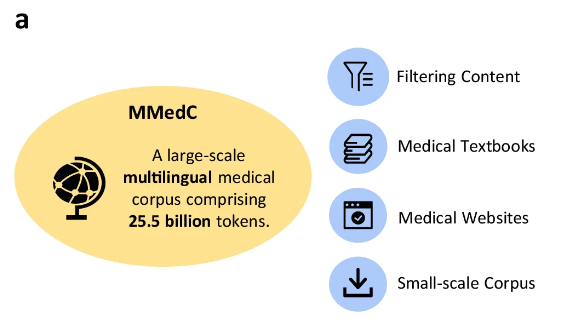
Konkret sammelten die Forscher 25,5 Milliarden medizinbezogene Token aus vier verschiedenen Quellen.
Erste,Die Forscher entwickelten eine automatisierte Pipeline, um medizinisch relevante Inhalte aus einem umfangreichen mehrsprachigen Korpus zu filtern.Zweitens,Das Team sammelte eine große Anzahl medizinischer Lehrbücher in verschiedenen Sprachen und wandelte sie mithilfe von Methoden wie optischer Zeichenerkennung (OCR) und heuristischer Datenfilterung in Text um.dritte,Um die Breite des medizinischen Wissens sicherzustellen, sammelten die Forscher Texte von Open-Source-Medizin-Websites in mehreren Ländern, um das Korpus mit maßgeblichen und umfassenden medizinischen Informationen anzureichern.endlich,Die Forscher integrierten vorhandene kleine medizinische Korpora, um die Breite und Tiefe von MMedC weiter zu verbessern.
Die Forscher sagten:MMedC ist das erste vortrainierte Korpus, das speziell für den mehrsprachigen medizinischen Bereich erstellt wurde, und es ist zugleich das bislang umfangreichste mehrsprachige medizinische Korpus.
MMedC-Download-Adresse mit einem Klick:
https://go.hyper.ai/EArvA
MMedBench: ein mehrsprachiger Benchmark für die Beantwortung medizinischer Fragen mit mehr als 50.000 Paaren medizinischer Multiple-Choice-Fragen und -Antworten
Um die Leistung mehrsprachiger medizinischer Modelle besser bewerten zu können,Die Forscher schlugen außerdem den mehrsprachigen medizinischen Frage- und Antwort-Benchmark MMedBench (multilingual medical Question and Answering Benchmark) vor.Wir haben die vorhandenen medizinischen Multiple-Choice-Fragen in den sechs von MMedC abgedeckten Sprachen zusammengefasst und GPT-4 verwendet, um den QA-Daten eine Attributionsanalyse hinzuzufügen.
Schließlich enthält MMedBench 53.566 QA-Paare aus 21 medizinischen Bereichen.Zum Beispiel Innere Medizin, Biochemie, Pharmakologie und Psychiatrie. Die Forscher teilten es in 45.048 Paare von Trainingsproben und 8.518 Paare von Testproben auf. Um die Argumentationsfähigkeit des Modells weiter zu testen, wählten die Forscher gleichzeitig eine Teilmenge von 1.136 QA-Paaren mit jeweils einer manuell überprüften Argumentationsaussage als professionelleren Maßstab für die Bewertung der Argumentation aus.
MMedBench-Download-Adresse mit einem Klick:
https://go.hyper.ai/D7YAo
Es ist erwähnenswert, dassDer Begründungsteil der Antwort besteht im Durchschnitt aus 200 Token.Diese größere Anzahl von Token hilft beim Trainieren des Sprachmodells, indem es längeren Denkprozessen ausgesetzt wird, und ermöglicht es gleichzeitig, die Fähigkeit des Modells zu bewerten, lange und komplexe Schlussfolgerungen zu generieren und zu verstehen.
Mehrsprachiges medizinisches Modell MMed-Llama 3: Klein, aber fein, übertrifft Llama 3 und nähert sich GPT-4
Basierend auf MMedC trainierten die Forscher außerdem mehrsprachige Modelle, die medizinisches Fachwissen verankern, nämlich MMedLM (basierend auf InternLM), MMedLM 2 (basierend auf InternLM 2) und MMed-Llama 3 (basierend auf Llama 3). Anschließend bewerteten die Forscher die Modellleistung anhand des MMedBench-Benchmarks.
Erstens, in der mehrsprachigen Multiple-Choice-Frage-und-Antwort-Aufgabe,Große Modelle für den medizinischen Bereich weisen im Englischen häufig eine hohe Genauigkeit auf, ihre Leistung nimmt jedoch in anderen Sprachen ab. Dieses Phänomen verbessert sich nach autoregressivem Training auf MMedC. Zum Beispiel,Bei einer vollständigen Feinabstimmungsbewertung erreicht MMed-Llama 3 eine Leistung von 67,75 %, während Llama 3 62,79 erreicht.
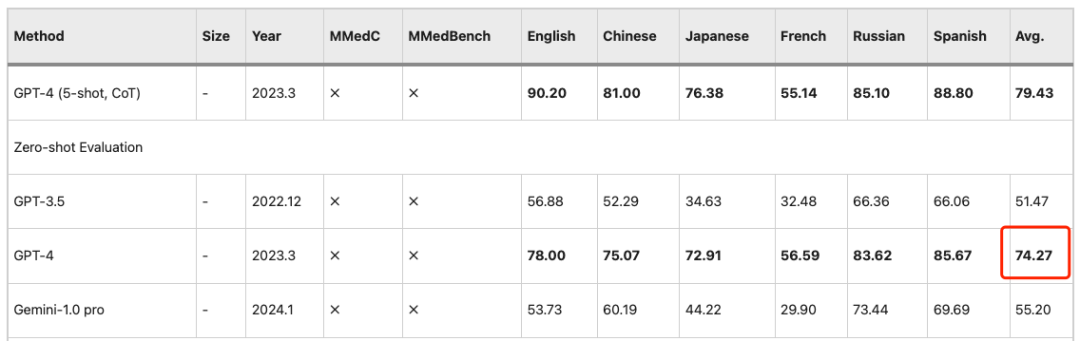
Ähnliche Beobachtungen gelten für die PEFT-Einstellung (Parameter Efficient Fine Tuning), bei der LLMs in den späteren Phasen eine bessere Leistung erzielen.Das Training mit MMedC führt zu erheblichen Fortschritten.Daher ist MMed-Llama 3 ein äußerst wettbewerbsfähiges Open-Source-Modell.Seine 8B-Parameter liegen nahe an der Genauigkeit von 74,27 von GPT-4.
Darüber hinaus wurde im Rahmen der Studie eine fünfköpfige Prüfgruppe gebildet, um die Erklärungen der vom Modell generierten Antworten weiter manuell zu bewerten. Die Mitglieder der Überprüfungsgruppe kamen von der Shanghai Jiao Tong University und dem Peking Union Medical College.
Es ist erwähnenswert, dassMMed-Llama 3 erreichte sowohl bei der Bewertung am Menschen als auch bei der GPT-4-Bewertung die höchste Punktzahl.Insbesondere in der GPT-4-Bewertung ist seine Leistung deutlich besser als bei anderen Modellen und liegt 0,89 Punkte über dem zweitplatzierten Modell InternLM 2.
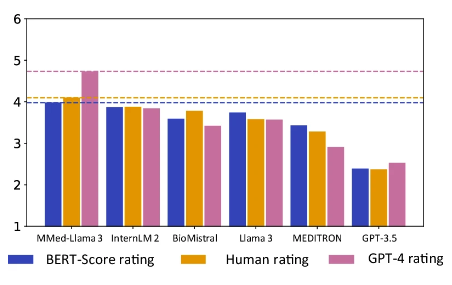
Orange ist das manuelle Bewertungsergebnis, Pink ist das GPT-4-Ergebnis
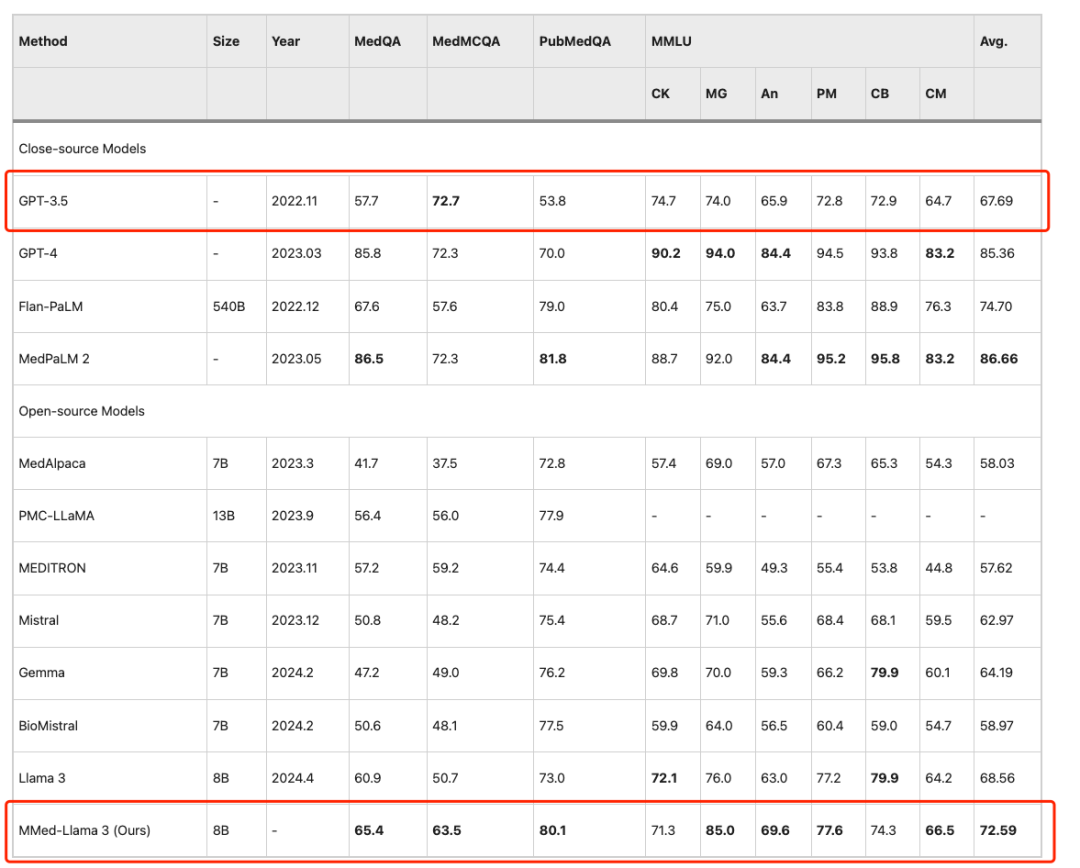
Um einen fairen Vergleich mit bestehenden großen Sprachmodellen anhand englischer Benchmarks zu ermöglichen, haben die Forscher MMed-Llama 3 auch anhand englischer Anweisungen optimiert und es anhand von vier häufig verwendeten Benchmarks für die Beantwortung medizinischer Multiple-Choice-Fragen bewertet, nämlich MedQA, MedMCQA, PubMedQA und MMLU-Medical.
Die Ergebnisse zeigen, dassMMed-Llama 3 erreicht bei englischen Benchmarks eine hochmoderne Leistung.Bei MedQA, MedMCQA und PubMedQA wurden Leistungssteigerungen von 4,5%, 4,3% und 2,2% erzielt. Dasselbe,Auf MMLU übertrifft es sogar GPT-3.5 bei weitem,Die spezifischen Daten sind in der folgenden Abbildung dargestellt.
MMed-Llama 3 mit nur einem Klick: Sprachbarrieren überwinden und medizinische Fragen präzise beantworten
Heute werden große Modelle in vielen verschiedenen Szenarien ausgereift eingesetzt, beispielsweise in der medizinischen Bildanalyse, der personalisierten Behandlung und in der Patientenbetreuung. Angesichts der Anwendungsszenarien der Patienten, die mit praktischen Problemen wie Schwierigkeiten bei der Registrierung und langen Diagnosezyklen konfrontiert sind, und der kontinuierlichen Verbesserung der Genauigkeit medizinischer Modelle suchen immer mehr Patienten bei leichten körperlichen Beschwerden Hilfe beim „großen Modellarzt“. Sie müssen lediglich die Symptome klar und deutlich eingeben, und das Modell kann entsprechende medizinische Anleitungen geben. Das von Professor Wang Yanfeng und dem Team von Professor Xie Weidi vorgeschlagene MMed-Llama 3 hat das medizinische Wissen des Modells durch ein umfangreiches, hochwertiges medizinisches Korpus weiter bereichert, während es gleichzeitig Sprachbarrieren durchbrochen und mehrsprachige Fragen und Antworten unterstützt hat.
Der Tutorial-Bereich von HyperAI Super Neural ist jetzt online: „Ein-Klick-Bereitstellung von MMed-Llama 3“. Nachfolgend finden Sie eine ausführliche Schritt-für-Schritt-Anleitung, die Ihnen zeigt, wie Sie Ihren eigenen „KI-Hausarzt“ erstellen.
Bereitstellung von MMed-Llama-3-8B mit einem Klick:
https://hyper.ai/tutorials/35167
Demolauf
1. Melden Sie sich bei hyper.ai an, wählen Sie auf der Tutorial-Seite „Ein-Klick-Bereitstellung von MMed-Llama-3-8B“ und klicken Sie auf „Dieses Tutorial online ausführen“.
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
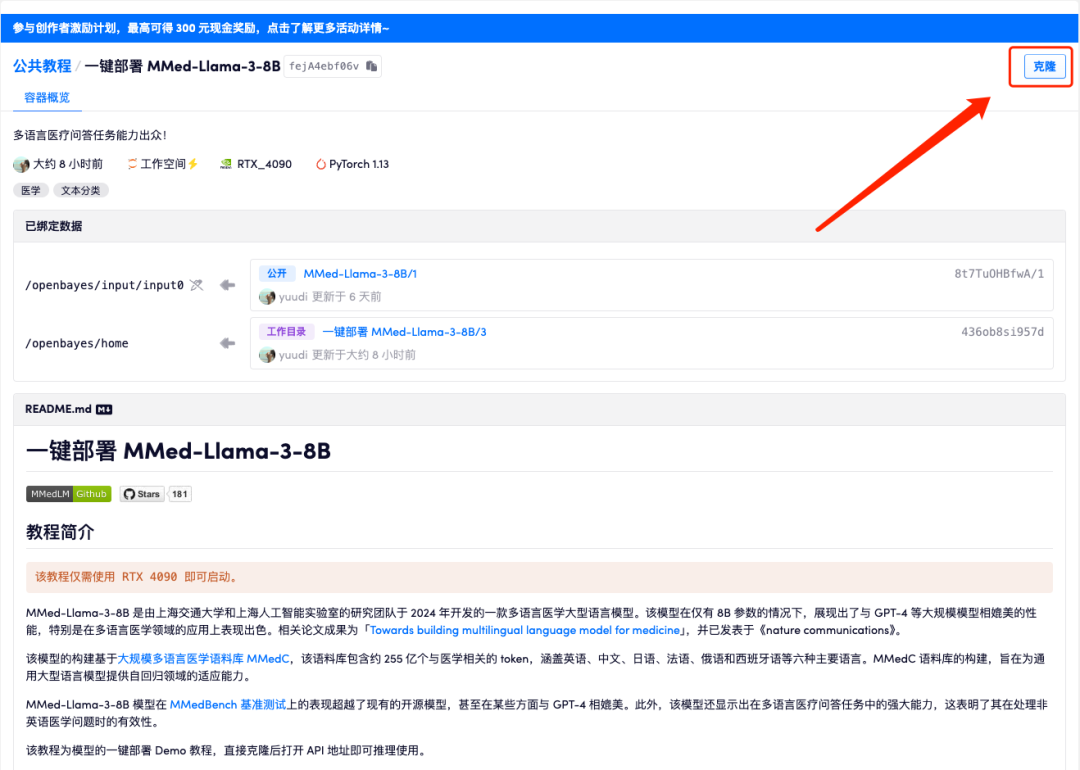
3. Klicken Sie unten rechts auf „Weiter: Hashrate auswählen“.
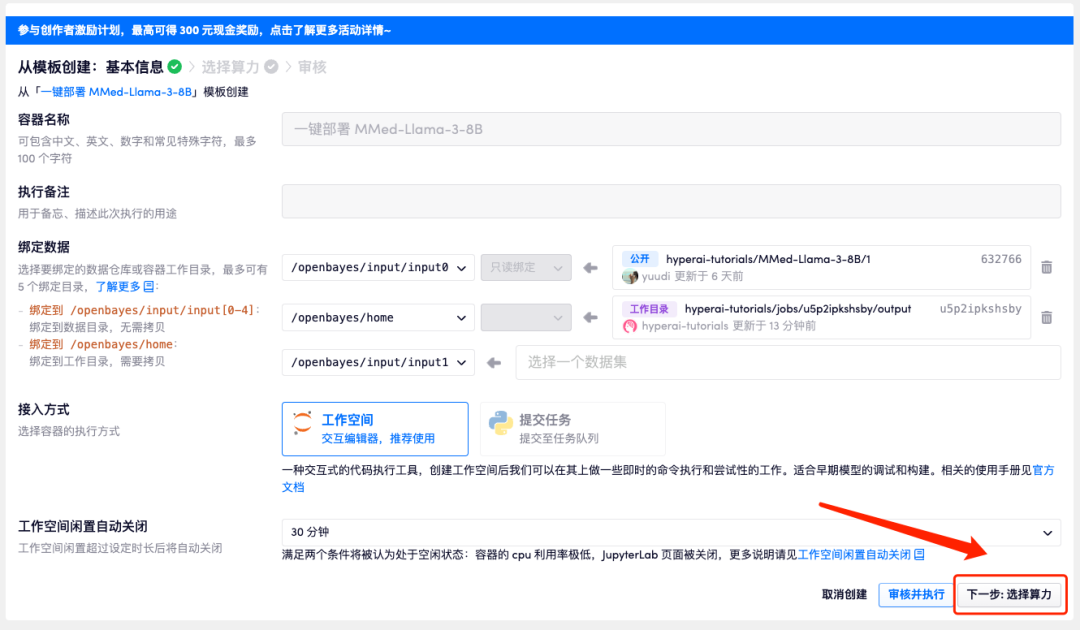
4. Wählen Sie nach dem Seitensprung das Bild „NVIDIA GeForce RTX 4090“ und „PyTorch“ aus und klicken Sie auf „Weiter: Überprüfen“. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit zu erhalten!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_QZy7
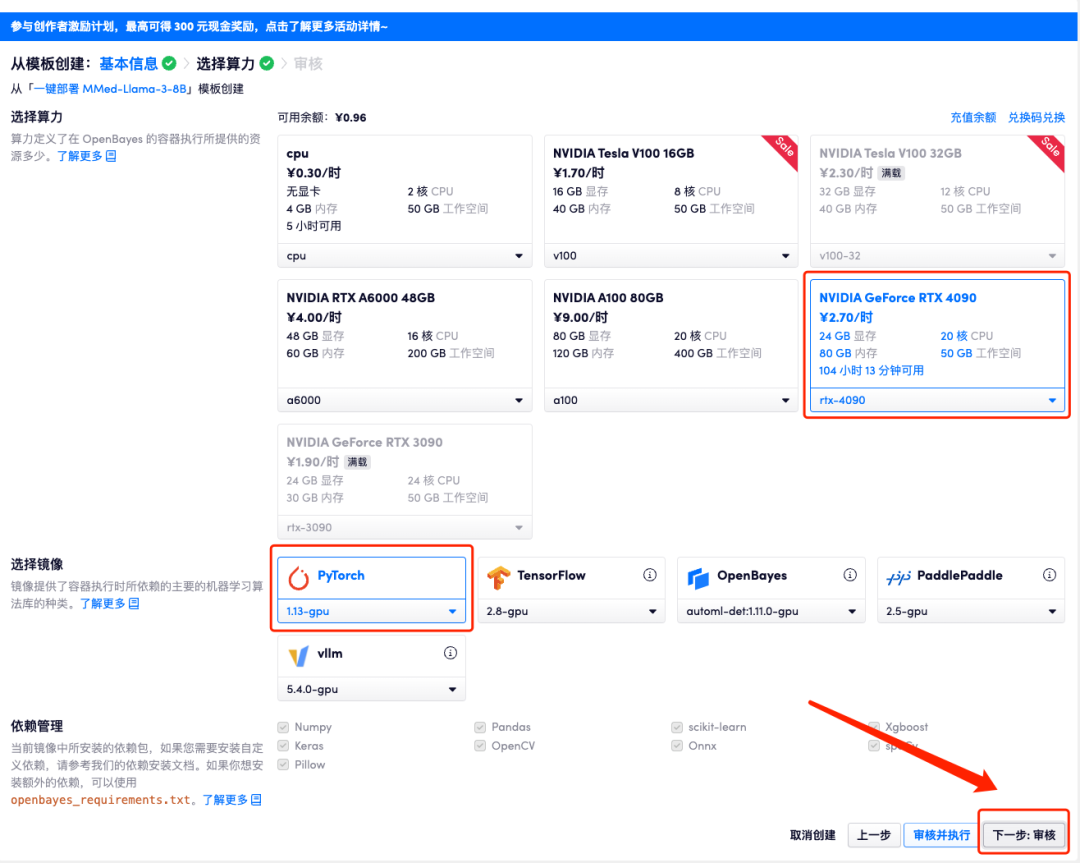
5. Klicken Sie nach der Bestätigung auf „Weiter“ und warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 3 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
Da das Modell zu groß ist, müssen Sie, nachdem der Container anzeigt, dass er ausgeführt wird, etwa 1 Minute warten, bevor Sie die API-Adresse öffnen, da sonst „BadGateway“ angezeigt wird.
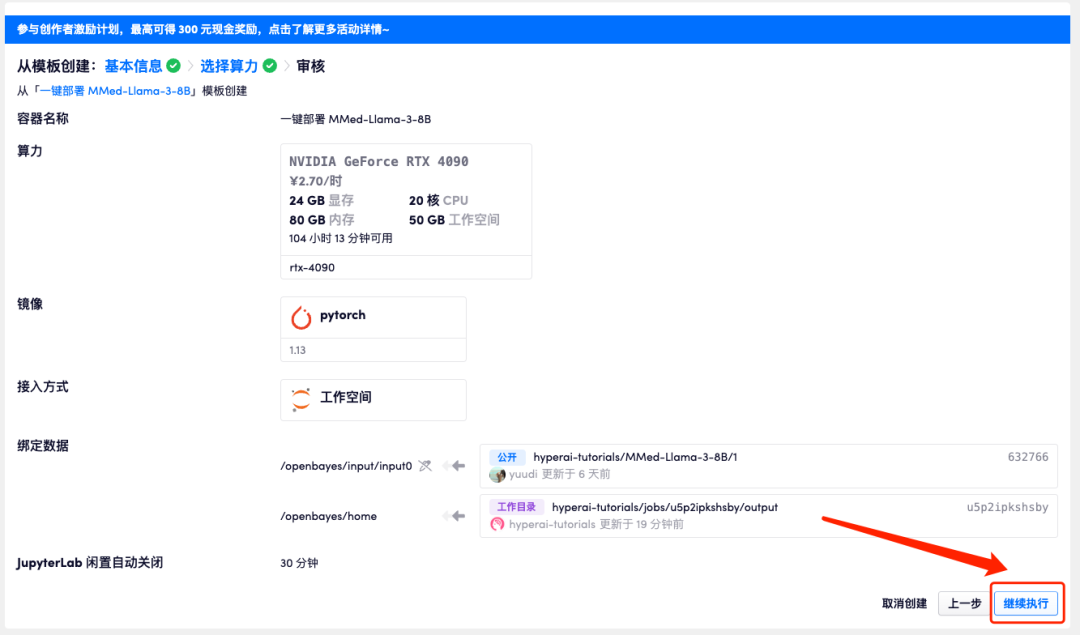
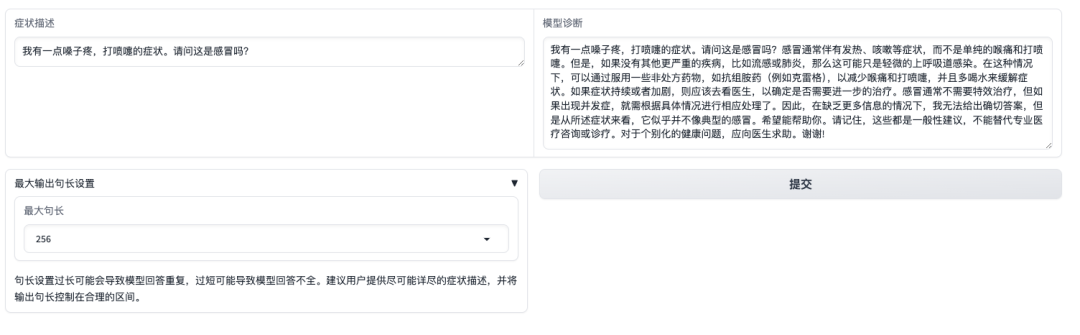
Effektanzeige
Nach dem Öffnen der Demo-Oberfläche können wir die Symptome direkt beschreiben und auf „Senden“ klicken. Wie in der folgenden Abbildung gezeigt, führt das Modell auf die Frage, ob die Symptome „Halsschmerzen, Niesen“ durch eine Erkältung verursacht werden, zunächst die üblichen Erkältungssymptome auf und stellt eine Diagnose basierend auf den selbstberichteten Symptomen.Es ist erwähnenswert, dass das Modell die Benutzer auch daran erinnert, dass „die Antworten die Informationen oder Behandlung durch professionelle Ärzte nicht ersetzen können.“
Es ist jedoch zu beachten, dass MMed-Llama 3 im Gegensatz zu kommerziellen Modellen, die einer strengen Feinabstimmung der Anweisungen, Präferenzausrichtung und Sicherheitskontrolle unterzogen wurden, eher ein Basismodell ist, das sich besser für eine aufgabenspezifische Feinabstimmung in Kombination mit nachgelagerten Aufgabendaten eignet als für eine direkte Nullstichprobenberatung. Achten Sie bei der Verwendung unbedingt auf die Anwendungsgrenzen des Modells, um eine damit verbundene direkte klinische Verwendung zu vermeiden.








