Command Palette
Search for a command to run...
Online-Tutorial |. GPT-4V Besiegen? Das Superleistungsfähige Multimodale Open-Source-Großmodell LLaVA-OneVision Wird Offiziell Eingeführt!

Large Language Model (LLM) und Large Multimodal Model (LMM) sind zwei zentrale Entwicklungsrichtungen im Bereich der künstlichen Intelligenz. Während sich LLM auf die Verarbeitung und Generierung von Textdaten konzentriert, geht LMM einen Schritt weiter und zielt darauf ab, mehrere Datentypen, darunter Text, Bilder und Videos, zu integrieren und zu verstehen. Heute ist LLM relativ ausgereift und ChatGPT und andere Algorithmen beherrschen das Textverständnis bereits fließend. Die Menschen beginnen, ihre Aufmerksamkeit auf das Verständnis multimodaler Daten zu richten, die es Modellen ermöglichen, „Bilder zu lesen und Videos anzusehen“.
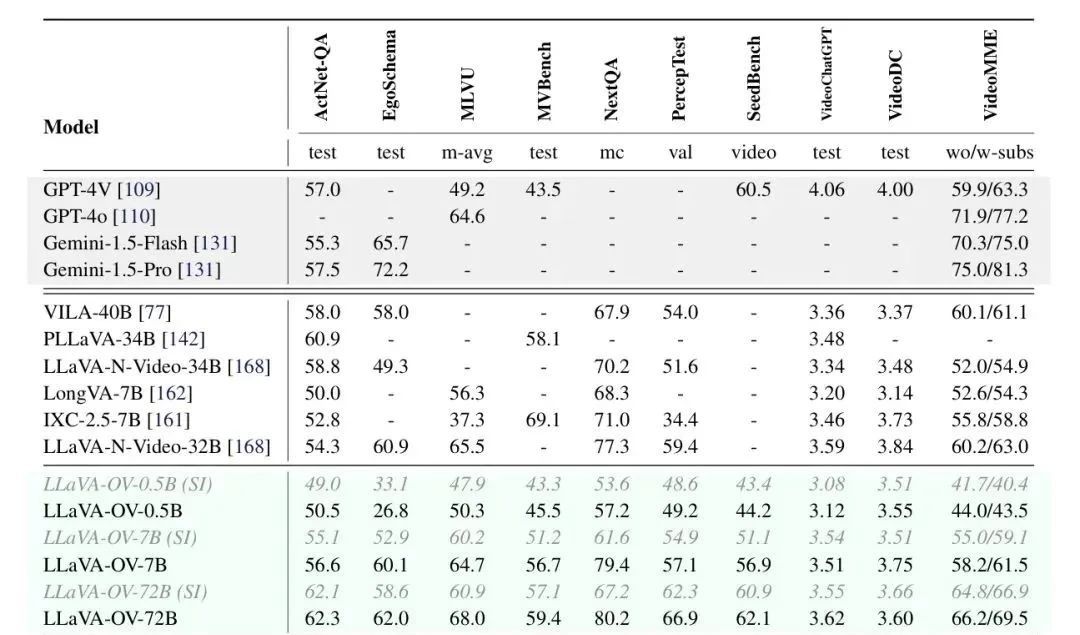
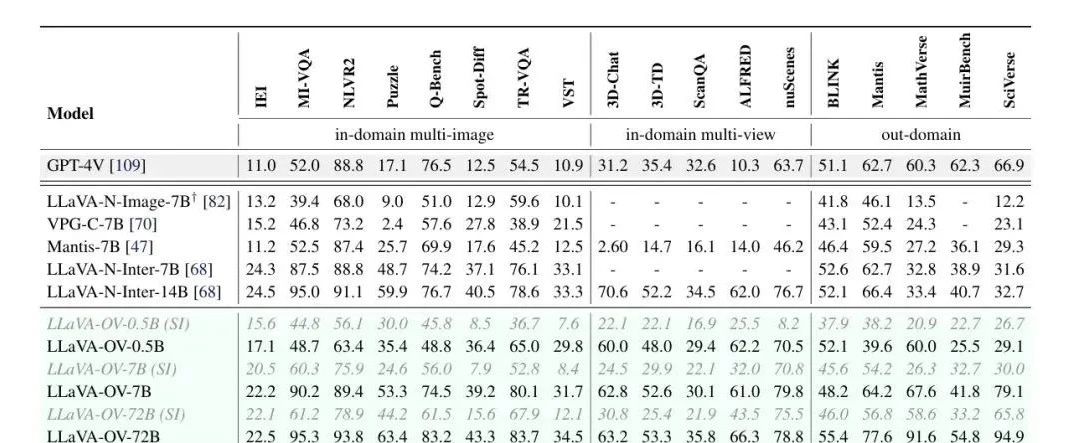
Kürzlich haben Forscher von ByteDance, der Nanyang Technological University, der Chinese University of Hong Kong und der Hong Kong University of Science and Technology gemeinsam das multimodale Großmodell LLaVA-OneVision als Open Source veröffentlicht, das bei Einzelbild-, Mehrfachbild- und Videoaufgaben eine hervorragende Leistung gezeigt hat. LMMs-Eval, ein für große multimodale Modelle entwickelter Evaluierungsrahmen, zeigt, dass LLaVA-OneVision-72B GPT-4V und GPT-4o bei den meisten Benchmarks übertrifft, wie die folgende Abbildung zeigt:
Das HyperAI Hyperneuron-Tutorial ist jetzt verfügbar„LLaVA-OneVision Multimodale Rundum-Sichtmodell-Demo“Benutzer können eine Vielzahl visueller Aufgaben problemlos bewältigen, indem sie sie einfach klonen und mit einem Klick starten. Ob es sich um die Analyse statischer Bilder oder das Parsen dynamischer Videos handelt, es kann qualitativ hochwertige Ergebnisse liefern.
Adresse des Tutorials:
Demolauf
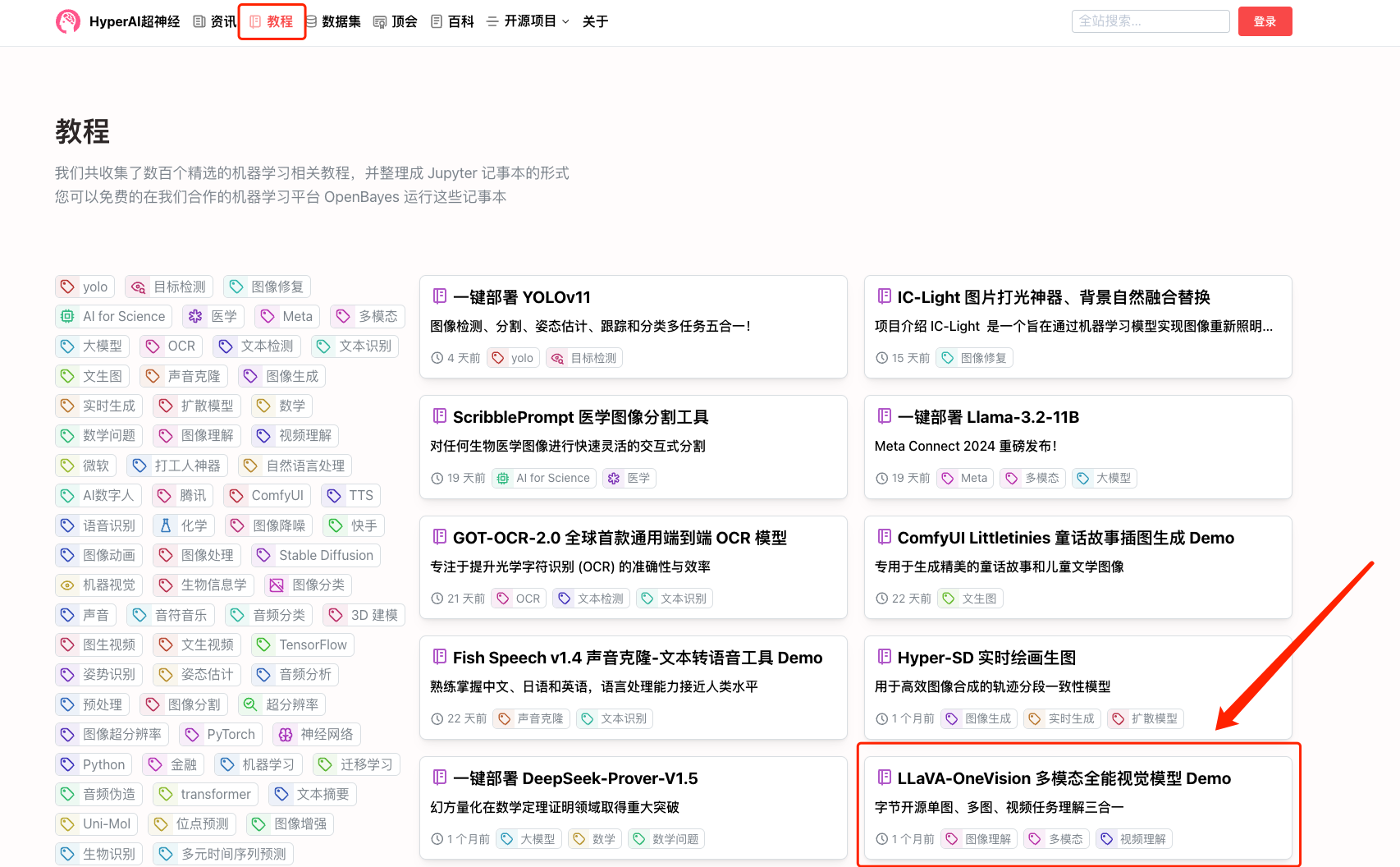
1. Melden Sie sich bei hyper.ai an, wählen Sie auf der Tutorial-Seite „LLaVA-OneVision Multimodal Universal Vision Model Demo“ aus und klicken Sie auf „Dieses Tutorial online ausführen“.
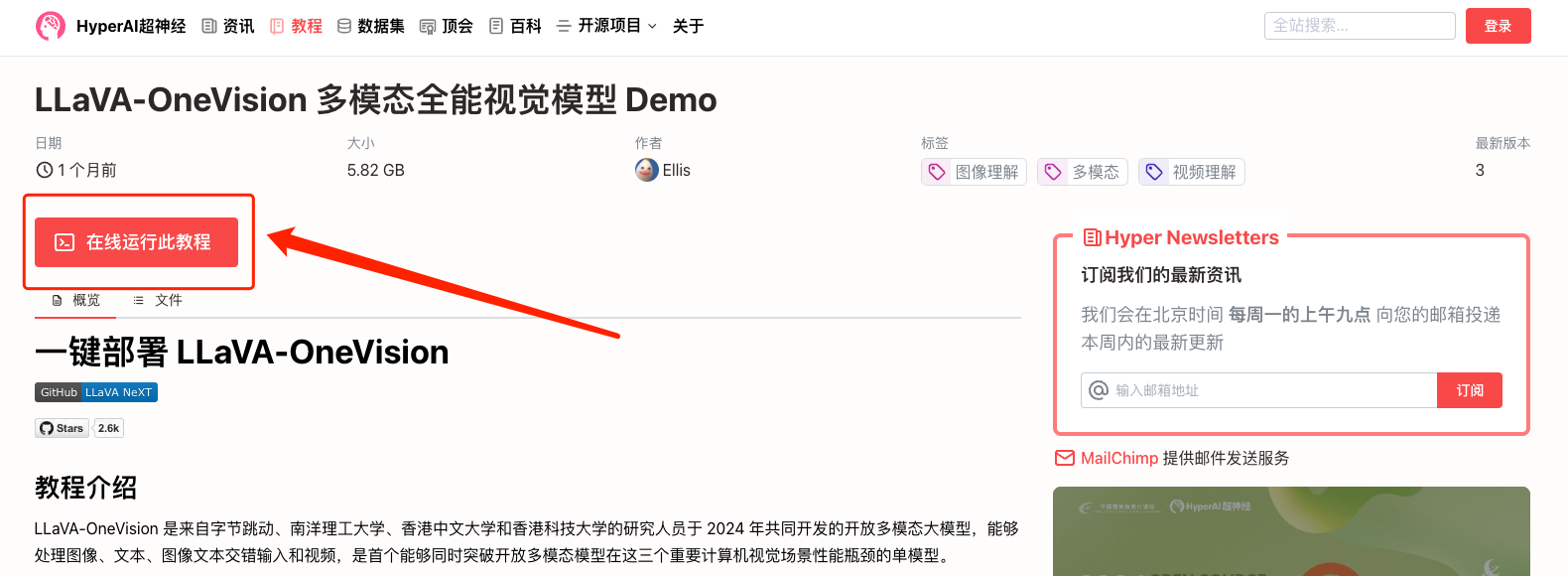
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
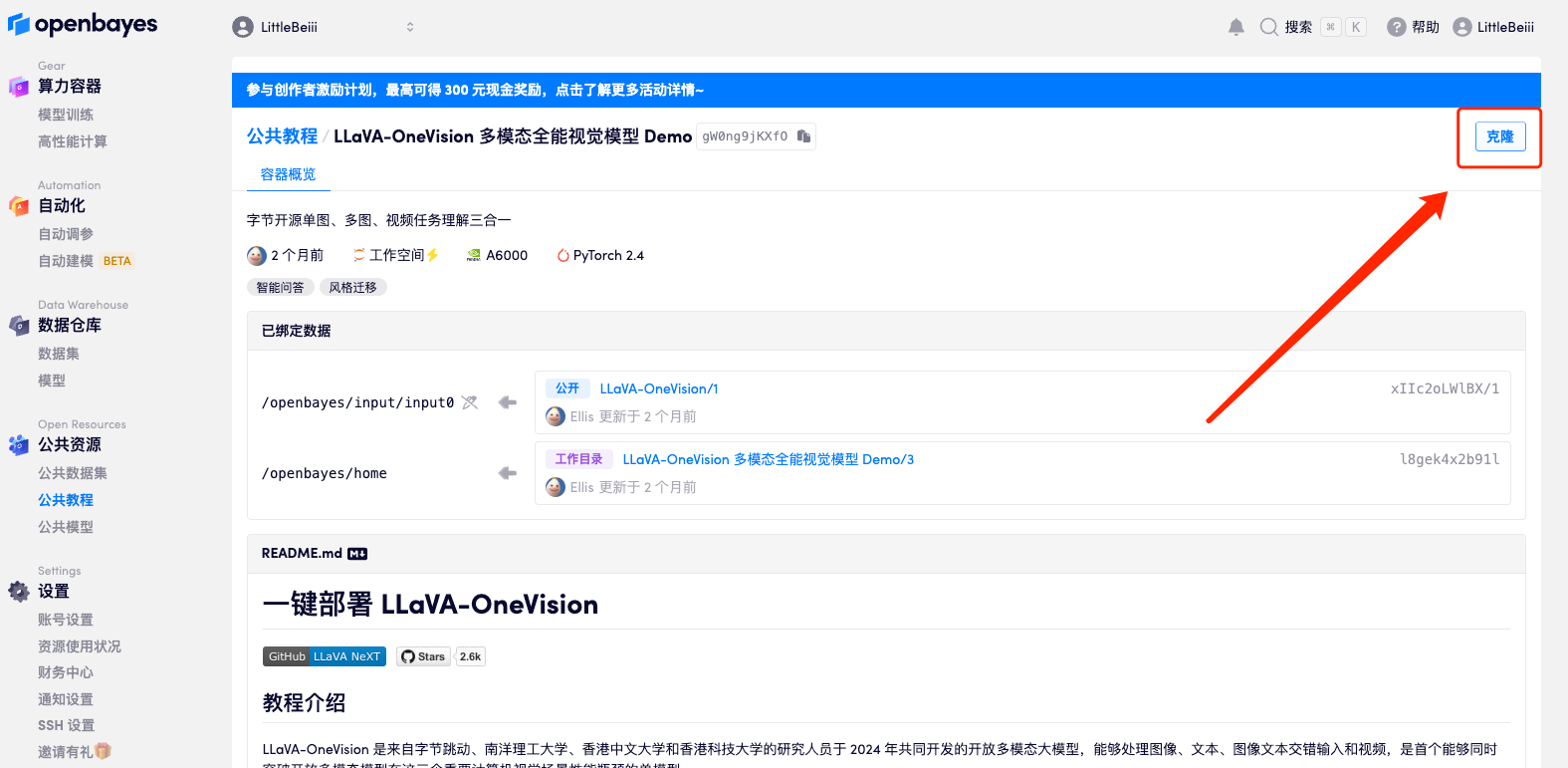
3. Klicken Sie unten rechts auf „Weiter: Hashrate auswählen“.
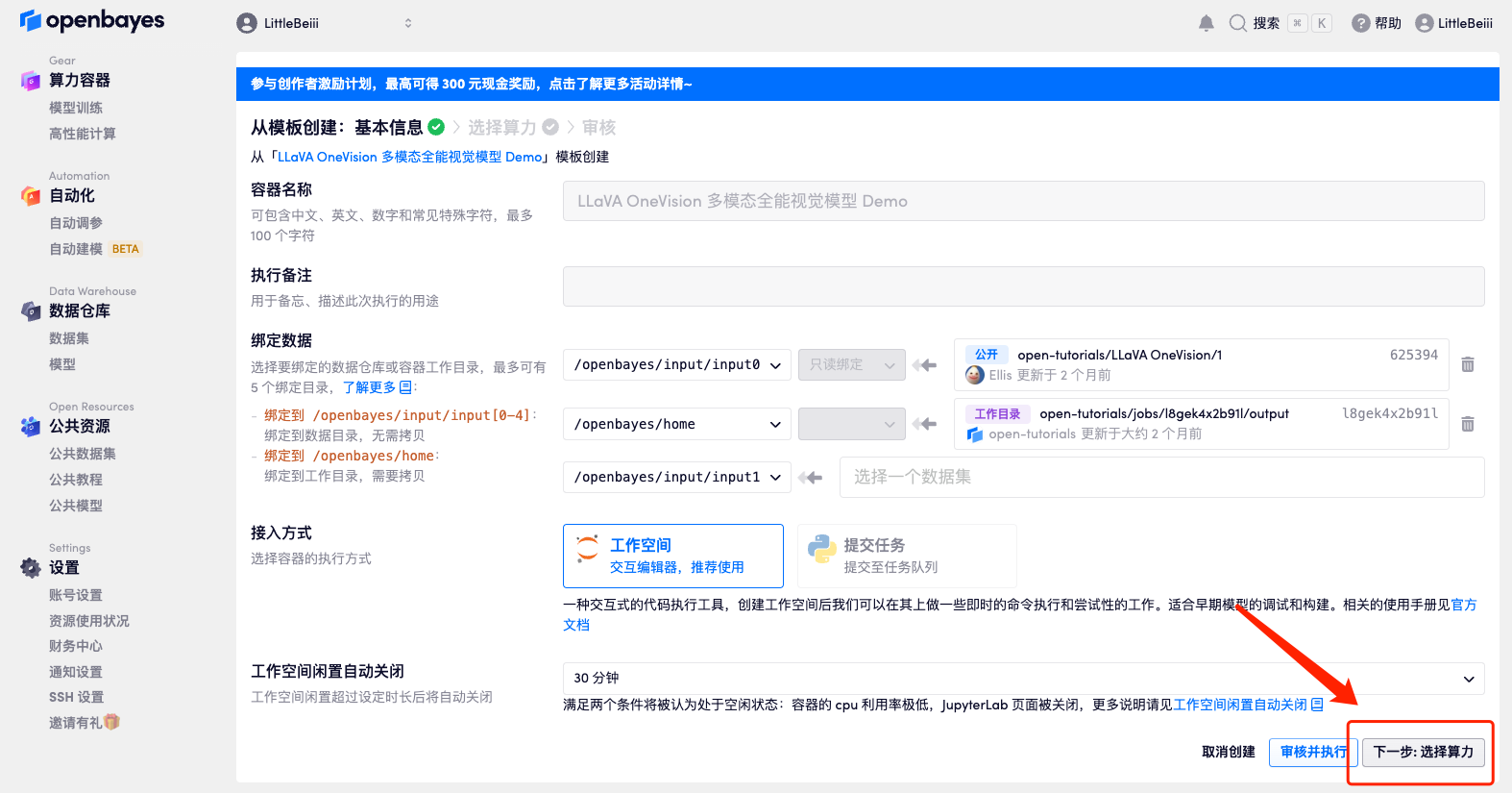
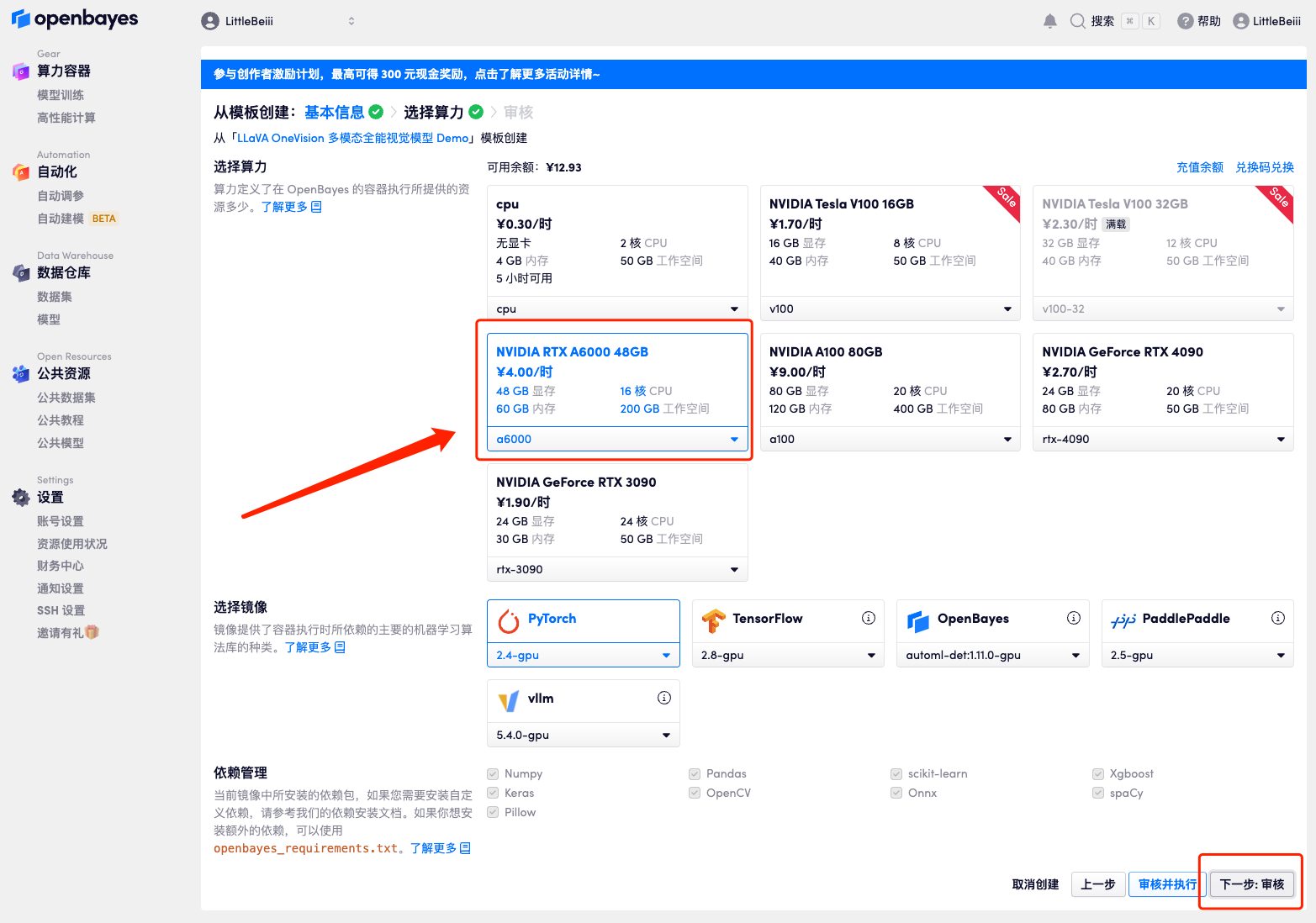
4. Wählen Sie nach dem Seitensprung das Bild „NVIDIA RTX A6000“ und „PyTorch“ aus und klicken Sie auf „Weiter: Überprüfen“.Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit zu erhalten!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_QZy7
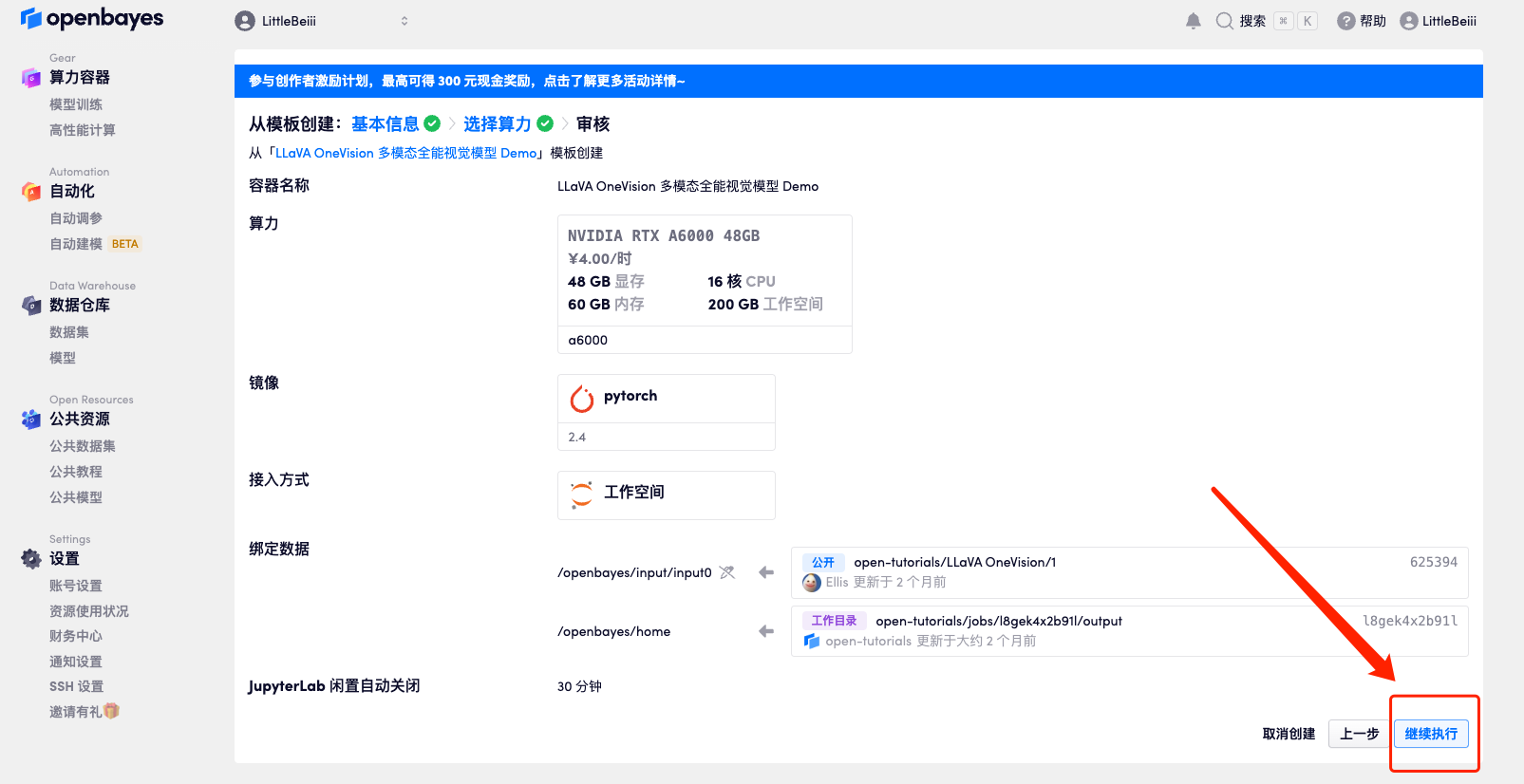
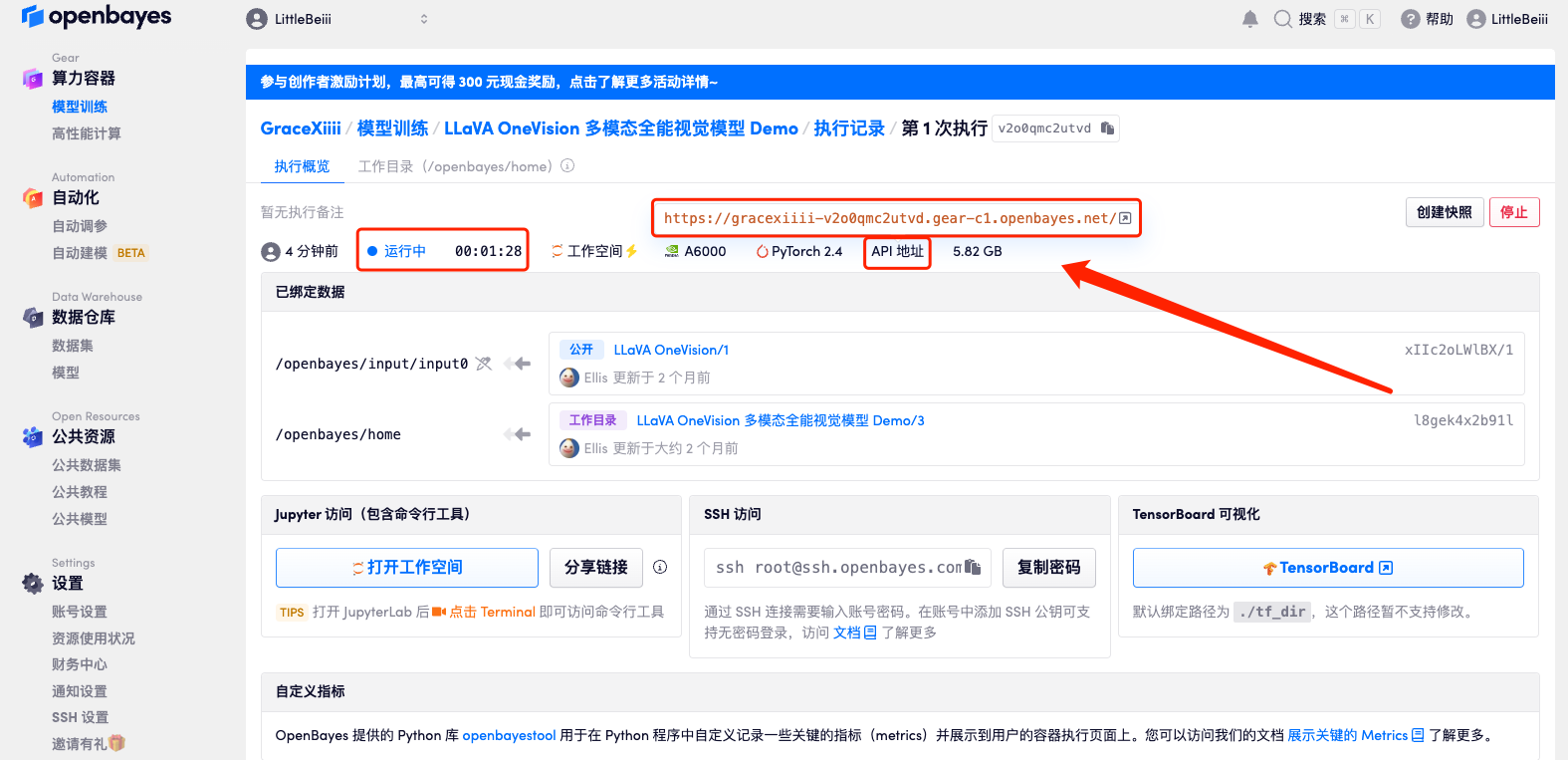
5. Klicken Sie nach der Bestätigung auf „Weiter“ und warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 3 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen.Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.Da das Modell zu groß ist, müssen Sie, nachdem der Container anzeigt, dass er ausgeführt wird, etwa 1 Minute warten, bevor Sie die API-Adresse öffnen, da sonst „BadGateway“ angezeigt wird.
Effektdemonstration
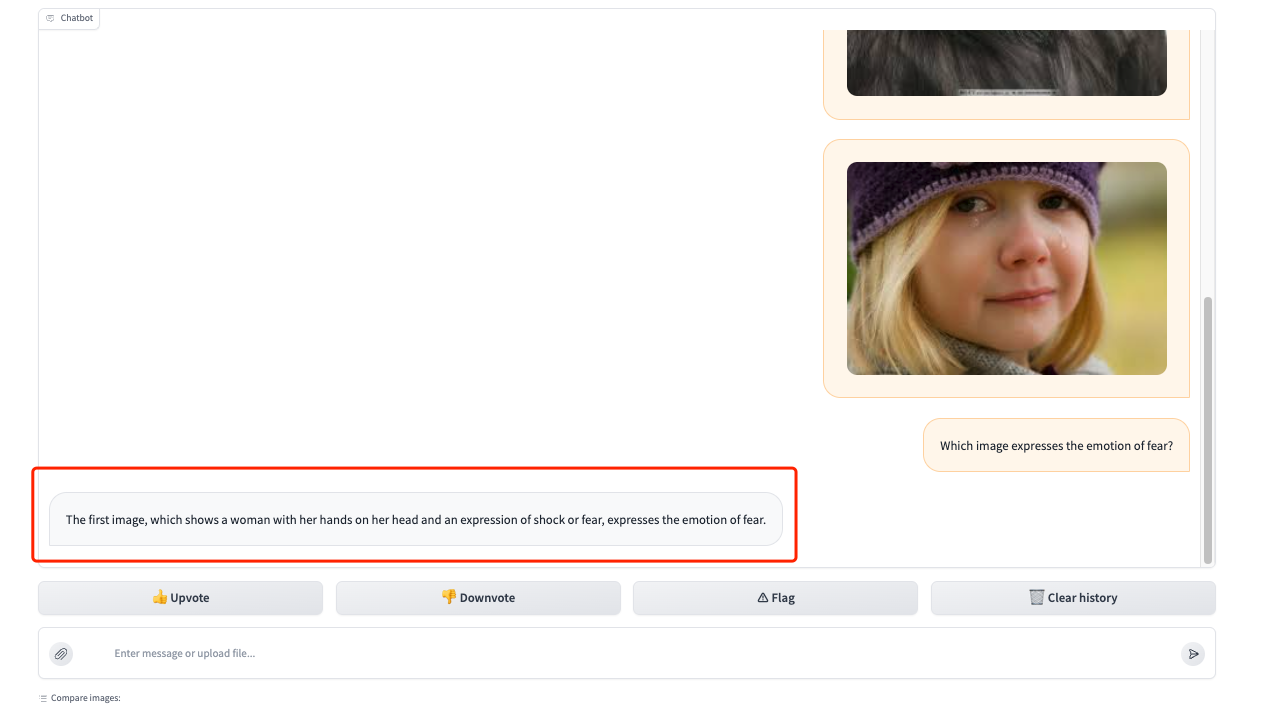
1. Nachdem wir die Demo-Oberfläche geöffnet haben, testen wir zunächst ihre Fähigkeit, Bilder zu verstehen. Laden Sie im roten Rahmenbereich 3 Fotos mit unterschiedlichen Emotionen hoch und geben Sie unsere Frage ein: „Welches Bild drückt die Emotion Angst aus?“ Sie können sehen, dass es unsere Frage genau beantwortet und eine Beschreibung des Bildes liefert (das erste Bild, das eine Frau mit den Händen auf dem Kopf und einem Ausdruck von Schock oder Angst zeigt, drückt die Emotion der Angst aus).


2. Es verfügt außerdem über hervorragende Videoverständnisfunktionen. Laden Sie eine Videosammlung mit Highlights eines olympischen Laufwettbewerbs hoch und fragen Sie: „Worum geht es in diesem Video?“ Sie können sehen, dass es die Ereignisse des Wettkampfs genau wiedergeben und die Video-Szenen und Details beschreiben kann, wie etwa die Hautfarbe der Athleten, Emotionen und Sponsorenlogos rund um das Stadion.

Antwortübersetzung:
Bei dem Video scheint es sich um einen Clip von Leichtathletik-Wettkämpfen zu handeln, hauptsächlich vom 100-Meter-Sprint. Es zeigt Athleten in den Startblöcken, die sich auf den Wettkampf vorbereiten. Ein Athlet trägt ein gelb-grünes Outfit, was darauf schließen lässt, dass er Jamaika vertreten könnte, da dies die Farben der jamaikanischen Flagge sind. Das Video fängt die Intensität und Konzentration der Athleten bei ihren Startvorbereitungen, beim Abstoßen aus den Startblöcken und beim anschließenden Sprint über die Strecke ein. Die Athleten tragen Uniformen mit dem Logo ihrer Nationalmannschaft oder ihres Sponsors und überall im Stadion sind Logos verschiedener Sponsoren wie TOYOTA und TDK zu sehen. Das Video enthält außerdem Nahaufnahmen der Gesichter der Athleten, die ihre Konzentration und Entschlossenheit zeigen. In der Schlussszene sieht man die Athleten beim Sprinten, wobei ein Athlet die anderen anführt, was darauf schließen lässt, dass ein Wettkampf im Gange ist.
Wir haben eine „Stable Diffusion Tutorial Exchange Group“ eingerichtet. Willkommen, Freunde, treten Sie der Gruppe bei, um verschiedene technische Probleme zu diskutieren und Anwendungsergebnisse auszutauschen ~
Scannen Sie den unten stehenden QR-Code, um HyperaiXingXing zu WeChat hinzuzufügen (WeChat-ID: Hyperai01), und notieren Sie „SD Tutorial Exchange Group“, um dem Gruppenchat beizutreten.









