Command Palette
Search for a command to run...
Ausgewählt Für ECCV 2024! Das MIT Hat Mit ScribblePrompt Ein Allgemeines Modell Für Die Segmentierung Medizinischer Bilder Vorgeschlagen, Das Mehr Als 54.000 Bilder Abdeckt Und SAM übertrifft.

Der Laie beobachtet die Aufregung, während der Experte auf die Details achtet. Dieser Satz ist im Bereich der medizinischen Bildgebung eine absolute Wahrheit. Darüber hinaus ist es selbst für einen Experten nicht einfach, die „Tricks“ in komplexen medizinischen Bildern wie Röntgenaufnahmen, CT-Scans oder MRTs genau zu erkennen. Bei der Segmentierung medizinischer Bilder geht es darum, bestimmte Teile mit besonderer Bedeutung aus komplexen medizinischen Bildern herauszutrennen und relevante Merkmale zu extrahieren, um Ärzten dabei zu helfen, präzisere Diagnosen und Behandlungspläne für Patienten zu erstellen und wissenschaftlichen Forschern eine zuverlässigere Grundlage für die Durchführung pathologischer Untersuchungen zu bieten.
Dank der Entwicklung von Computer- und Deep-Learning-Technologien in den letzten JahrenDie Methode der medizinischen Bildsegmentierung beschleunigt sich schrittweise von der manuellen Segmentierung zur automatisierten Segmentierung, und trainierte KI-Systeme sind zu einer wichtigen Hilfe für Ärzte und Forscher geworden.Aufgrund der Komplexität und Professionalität medizinischer Bilder selbst ist ein Großteil der Arbeit beim Systemtraining jedoch immer noch auf erfahrene Experten angewiesen, die Trainingsdaten manuell segmentieren und erstellen, was ein zeit- und arbeitsintensiver Prozess ist. Gleichzeitig sind bestehende Segmentierungsmethoden auf der Grundlage von Deep Learning in der Praxis mit zahlreichen Herausforderungen konfrontiert, beispielsweise mit Anwendbarkeitsproblemen und Anforderungen an die flexible Interaktion.
Um die Einschränkungen bestehender interaktiver Segmentierungssysteme in praktischen Anwendungen zu beheben, hat sich ein Team des Computer Science and Artificial Intelligence Laboratory (MIT CSAIL) des Massachusetts Institute of Technology mit Forschern des Massachusetts General Hospital und der Harvard Medical School zusammengetan, um ein neues interaktives Segmentierungssystem zu entwickeln, mit dem Gesichter identifiziert und segmentiert werden können.Wir schlagen ein allgemeines Modell für die interaktive Segmentierung biomedizinischer Bilder vor: ScribblePrompt, ein auf neuronalen Netzwerken basierendes Segmentierungstool, das Annotatoren mithilfe verschiedener Annotationsmethoden wie Kritzeleien, Klicks und Begrenzungsrahmen unterstützt, um Aufgaben der biomedizinischen Bildsegmentierung flexibel durchzuführen, selbst für nicht trainierte Beschriftungen und Bildtypen.
Die Forschungsarbeit mit dem Titel „ScribblePrompt: Schnelle und flexible interaktive Segmentierung für jedes biomedizinische Bild“ wurde in die international renommierte akademische Plattform arXiv aufgenommen und von der führenden internationalen akademischen Konferenz ECCV 2024 angenommen.
Forschungshighlights:
* Führen Sie schnell und präzise alle biomedizinischen Bildsegmentierungsaufgaben durch und übertreffen Sie dabei die Leistung vorhandener hochmoderner Modelle, insbesondere bei nicht trainierten Beschriftungen und Bildtypen
* Bietet flexible und vielfältige Anmerkungsstile, einschließlich Kritzeln, Klicken und Begrenzungsrahmen
* Höhere Rechenleistung, die schnelle Inferenz auch auf einer einzelnen CPU ermöglicht
* In einer Benutzerstudie mit Fachexperten reduzierte das Tool die Annotationszeit im Vergleich zu SAM um 28%

Papieradresse:
https://arxiv.org/pdf/2312.07381
Downloadadresse für den MedScribble-Datensatz:
Das „ScribblePrompt Medical Image Segmentation Tool“ wurde im Abschnitt „HyperAI Super Neural Tutorial“ eingeführt. Sie können es starten, indem Sie es mit einem Klick klonen. Die Adresse des Tutorials lautet:
Große Datensätze, umfassende Abdeckung von Modelltraining und Leistungsbewertung
Die Studie baut auf umfangreichen Bemühungen zur Datensatzerfassung auf, beispielsweise MegaMedical, das 77 frei zugängliche biomedizinische Bilddatensätze für Training und Auswertung zusammenstellt, die 54.000 Scans, 16 Bildtypen und 711 Beschriftungen abdecken.
Diese Datensatzbilder decken verschiedene biomedizinische Bereiche ab, darunter Scans von Augen, Brust, Wirbelsäule, Zellen, Haut, Bauchmuskeln, Hals, Gehirn, Knochen, Zähnen und Läsionen; Zu den Bildtypen gehören Mikroskope, CT, Röntgen, MRT, Ultraschall und Fotografien.
Was die Trennung zwischen Training und Evaluation betrifft,Das Forschungsteam unterteilte die 77 Datensätze in 65 Trainingsdatensätze und 12 Evaluierungsdatensätze.Von den 12 Bewertungsdatensätzen wurden die Daten von 9 Bewertungsdatensätzen für die Modellentwicklung, Modellauswahl und endgültige Bewertung verwendet, und die Daten der anderen 3 Bewertungsdatensätze wurden nur für die endgültige Bewertung verwendet.
Jeder Datensatz ist im Verhältnis 6:2:2 in Trainingssatz, Validierungssatz und Testsatz unterteilt, wie in der folgenden Abbildung dargestellt.

Die folgenden beiden Bilder sind „Validierungs- und Testdatensätze“ und „Trainingsdatensätze“.Unter ihnen sind die „Validierungs- und Testdatensätze“ während des ScribblePrompt-Modelltrainings unsichtbar.
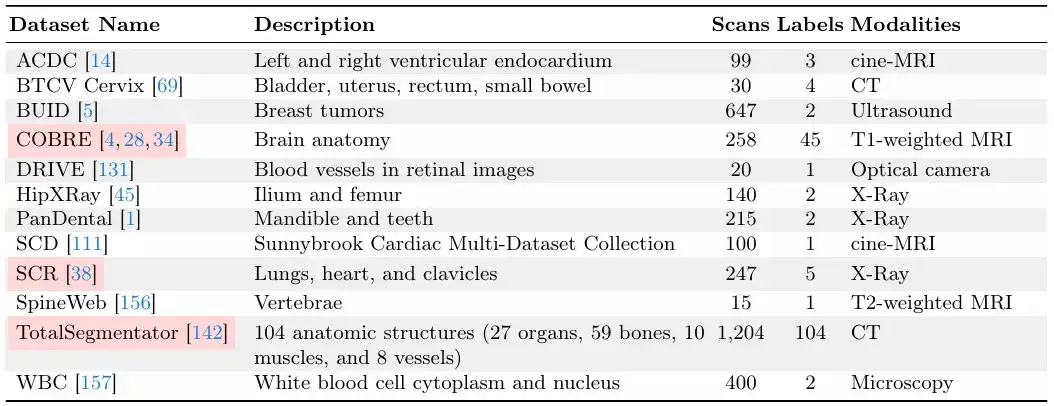
Angesichts der relativen Größe der Datensätze stellte das Forschungsteam sicher, dass jeder Datensatz eine eindeutige Anzahl von Scans enthielt.
Effiziente Architektur für schnelles Denken, Aufbau praktischer Segmentierungstools
Das Forschungsteam schlug eine flexible und interaktive Segmentierungsmethode mit starker praktischer Anwendbarkeit vor, die auf neue Bereiche und Interessensgebiete der biomedizinischen Bildgebung ausgeweitet werden kann.
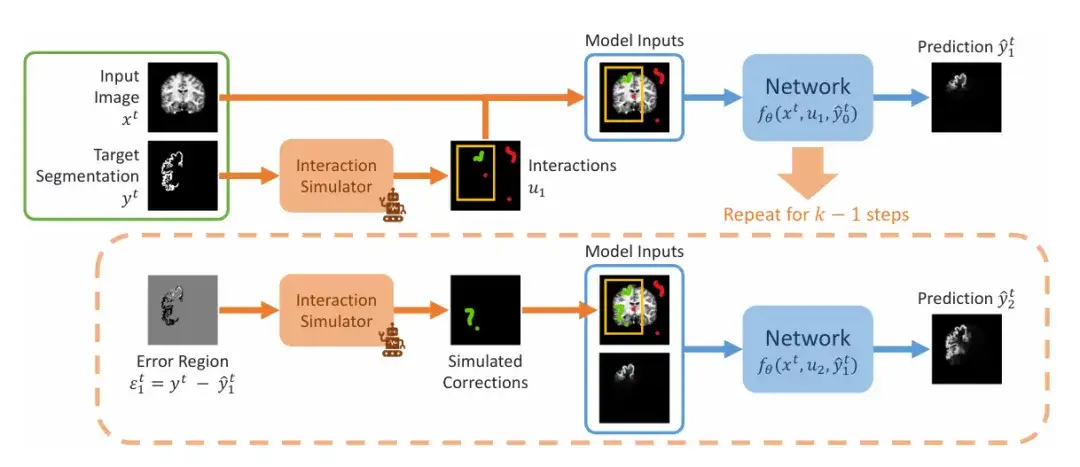
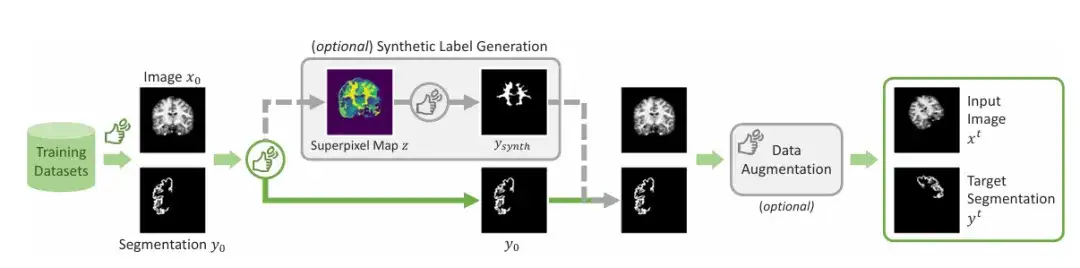
Das Forschungsteam demonstrierte die sequentiellen Schritte der Simulation der Interaktionssegmentierung während des Trainings, wie in der folgenden Abbildung dargestellt. Als Eingabe wird ein Bildsegmentierungspaar (xᵗ,yᵗ) gegeben. Das Team simuliert zunächst einen ersten Satz von Interaktionen u₁, der Begrenzungsrahmen, Klicks oder Kritzeleien enthalten kann, und beginnt dann mit dem ersten Vorhersageschritt, wobei der Anfangswert auf 0 gesetzt wird. Im zweiten Schritt simulierte das Team die vorherigen Vorhersagen im Fehlerbereich und fügte sie nach der Simulationskorrektur zum ersten Satz von Interaktionen hinzu, um u₂ zu erhalten. Dies wird wiederholt, um eine Reihe von Vorhersagen zu erstellen.
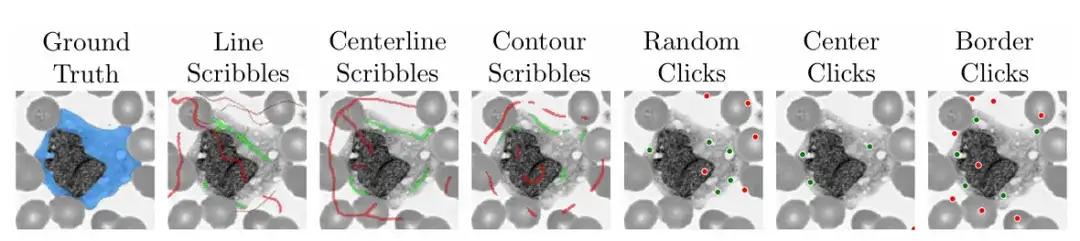
Um die Praktikabilität und Benutzerfreundlichkeit des Modells zu gewährleisten,Das Forschungsteam verwendete den Algorithmus während des Trainings auch, um praktische Szenarien zu simulieren, in denen das Kritzeln, Klicken und Eingeben von Begrenzungsrahmen in verschiedenen Bereichen medizinischer Bilder beschrieben wurde.
Zusätzlich zu den allgemein gekennzeichneten Bereichen,Das Team führte einen Mechanismus zur Erzeugung synthetischer Etiketten ein.Mithilfe eines Superpixel-Algorithmus wird eine Karte potenzieller synthetischer Beschriftungen erstellt. Anschließend wird eine Beschriftung abgetastet, um das in der Abbildung gezeigte „Ysynth“ zu generieren. Schließlich wird eine zufällige Datenerweiterung angewendet, um das Endergebnis zu erhalten. Dieser Ansatz funktioniert, indem Teile eines Bildes mit ähnlichen Werten gefunden und dann neue Regionen identifiziert werden, die für medizinische Forscher von Interesse sein könnten, und ScribblePromt trainiert wird, diese zu segmentieren. Wie in der Abbildung unten gezeigt.
Diese Forschungspräsentation verwendet zur Demonstration hauptsächlich zwei Netzwerkarchitekturen. Eine besteht darin, ScribblePrompt mithilfe einer effizienten, vollständig konvolutionalen Architektur ähnlich UNet zu demonstrieren, und die andere besteht darin, ScribblePrompt mithilfe einer visuellen Konverterarchitektur zu demonstrieren.
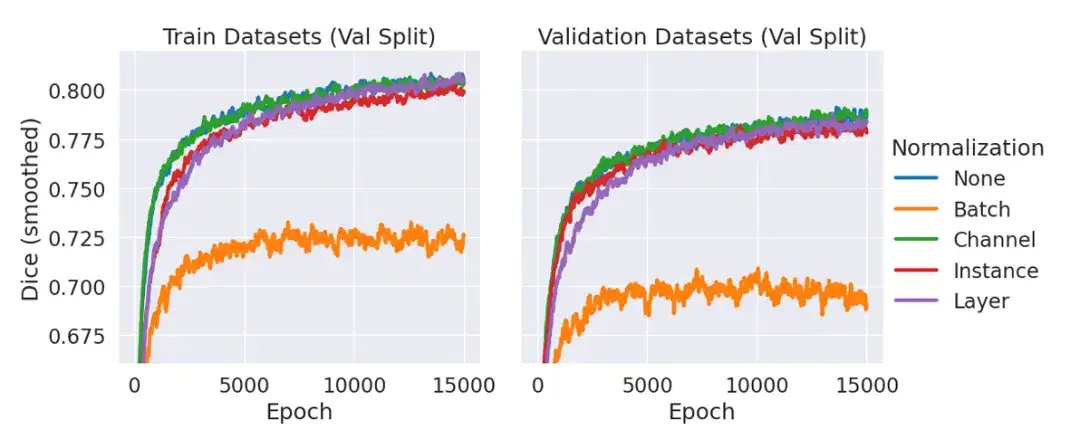
Unter diesen verwendet ScribblePrompt-UNet ein 8-Schicht-CNN und folgt einer Decoderstruktur, die der beliebten UNet-Architektur ohne Batch-Norm ähnelt. Jede Faltungsschicht verfügt über 192 Merkmale und verwendet die PReLu-Aktivierung. Es sollte erklärt werden, dass der Grund für das Fehlen einer Normalisierungsschicht darin liegt, dass das Team in vorläufigen Experimenten festgestellt hat, dass die Einbeziehung der Normalisierung die durchschnittlichen Würfel der Validierungsdaten im Vergleich zur Nichtverwendung einer Normalisierungsschicht nicht verbesserte, wie in der folgenden Abbildung gezeigt.
ScribblePrompt-SAM übernimmt das minimale SAM-Modell ViT-b und optimiert seinen Decoder. Die SAM-Architektur kann Vorhersagen entweder im Einzelmaskenmodus oder im Mehrfachmaskenmodus treffen, wobei der Decoder anhand eines Eingabebilds und Benutzerinteraktionen eine einzelne vorhergesagte Segmentierung ausgibt. Im Multimaskenmodus sagt der Decoder 3 mögliche Segmentierungen voraus und sagt dann die Segmentierung mit dem höchsten IoU über die MLP-Ausgabe voraus. Um die Ausdruckskraft der Architektur zu maximieren, trainieren und bewerten wir ScribblePrompt-SAM im Multimaskenmodus.
ScribblePrompt zeigt Überlegenheit gegenüber bestehenden Methoden
In dieser Studie verglich das Forschungsteam ScribblePrompt-UNet und ScribblePrompt-SAM mit bestehenden hochmodernen Methoden, darunter SAM, SAM-Med2D, MedSAM und MIDeepSeg, durch manuelle Kritzelexperimente, simulierte Interaktionen und Benutzerstudien mit erfahrenen Anmerkungen.
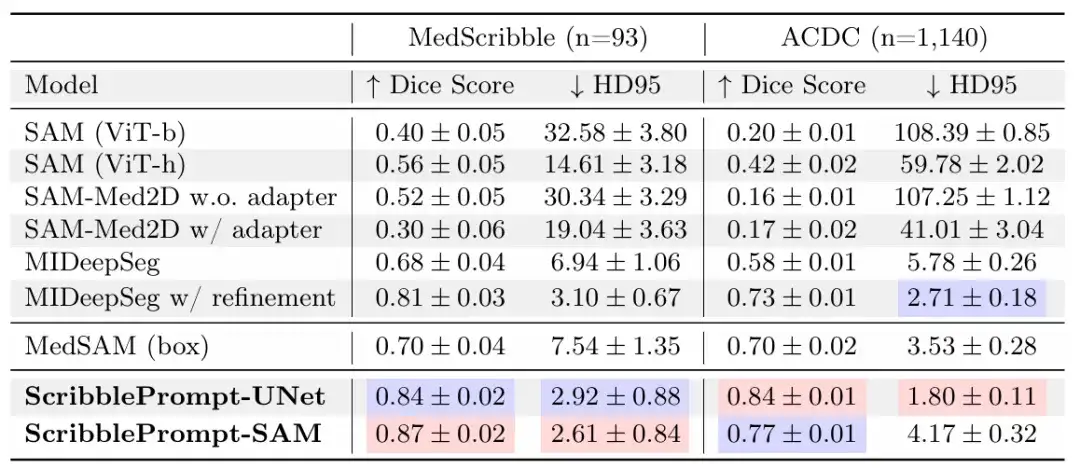
Im manuellen Graffiti-ExperimentDie Ergebnisse zeigen, dass ScribblePrompt-UNet und ScribblePrompt-SAM die genaueste Segmentierung im experimentellen manuellen Scribble-Datensatz und im einstufigen manuellen Scribble des ACDC-Scribble-Datensatzes erzeugen, wie in der folgenden Tabelle dargestellt.
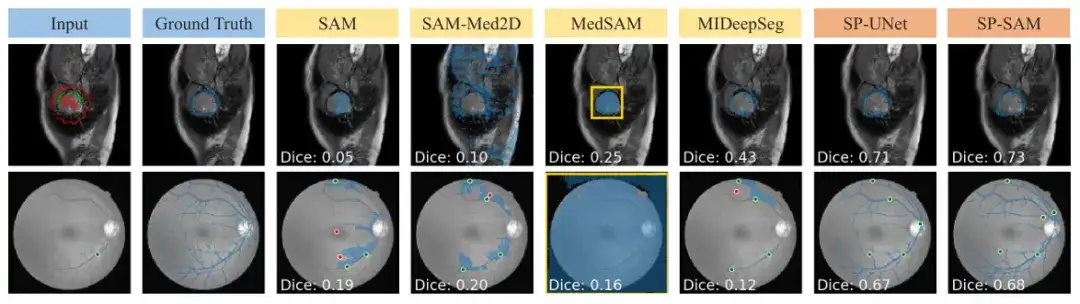
SAM und SAM-Med 2D können nicht problemlos auf Kritzeleingaben verallgemeinert werden, da sie nicht trainiert wurden. MedSAM bietet bessere Vorhersagen als andere SAM-Baselines, die die SAM-Architektur verwenden, kann jedoch keine negativen Kritzeleien ausnutzen und übersieht daher häufig Segmentierungen mit Lücken, wie in der folgenden Abbildung gezeigt. Darüber hinaus sind die anfänglichen Vorhersagen des MIDeepSeg-Netzwerks schlecht, verbessern sich jedoch nach Anwendung des Verfeinerungsprozesses.
Im simulierten InteraktionsexperimentDie Ergebnisse zeigen, dass bei allen simulierten Interaktionsprozessen und allen Interaktionszeiten beide Versionen von ScribblePrompt den Basismethoden überlegen sind. Wie in der Abbildung unten gezeigt.
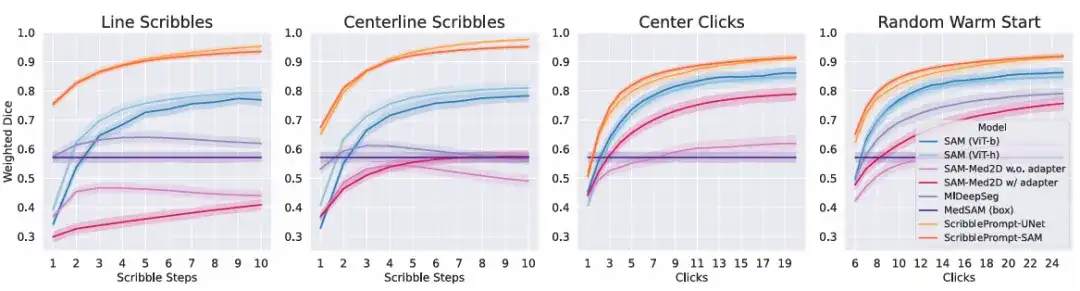
Um den tatsächlichen Nutzen von ScribblePrompt weiter zu bewerten,Das Team führte eine Benutzerstudie mit erfahrenen Annotatoren durch.Diese Vergleichsrunde findet zwischen ScribblePrompt-UNet und SAM (Vit-b) statt, das im obigen Klickexperiment die höchste Würfelpunktzahl erzielte. Die Ergebnisse zeigten, dass die Teilnehmer bei der Verwendung von ScribblePrompt-UNet genauere Segmentierungen erstellten, wie in der folgenden Tabelle dargestellt. Mit ScribblePrompt-UNet dauerte jede Segmentierung im Durchschnitt etwa 1,5 Minuten, mit SAM dagegen mehr als 2 Minuten pro Segmentierung.

Sechzehn Teilnehmer berichteten, dass die Zielsegmentierung mit ScribblePrompt einfacher sei als mit SAM. 15 von ihnen sagten, sie würden ScribblePrompt bevorzugen, und der verbleibende Teilnehmer hatte keine Präferenz. Darüber hinaus bevorzugten 93,81 TP3T der Teilnehmer ScribblePrompt gegenüber der SAM-Basislinie, da es die entsprechenden Segmente für Kritzelkorrekturen verbesserte, und 87,51 TP3T der Teilnehmer bevorzugten ScribblePrompt auch für die klickbasierte Bearbeitung.
Die obigen Ergebnisse bestätigen erneut die häufigsten Gründe, warum Teilnehmer ScribblePrompt bevorzugen: Selbstkorrektur und umfangreiche interaktive Funktionen. Dies ist mit anderen Methoden nicht möglich. Beispielsweise hat SAM bei der Segmentierung der Netzhautvenen selbst mit mehreren Korrekturen Schwierigkeiten, genaue Vorhersagen zu treffen.
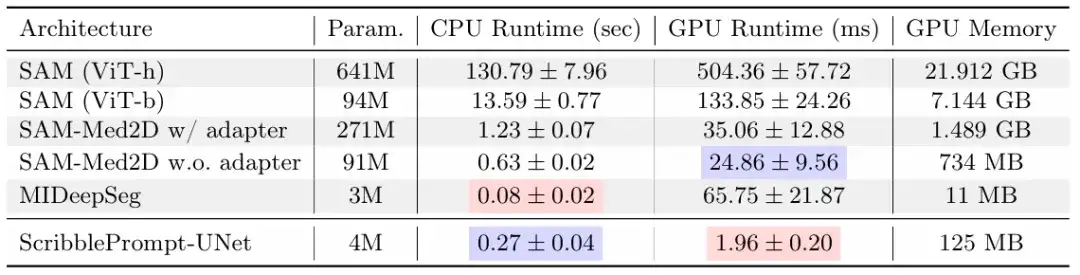
Darüber hinaus zeichnet sich ScribblePrompt durch geringe Kosten und eine einfache Bereitstellung aus. Die Studie ergab, dass ScribblePrompt-UNet auf einer einzelnen CPU nur 0,27 Sekunden pro Vorhersage benötigt und die Fehlerquote unter 0,04 Sekunden liegt. Wie in der Abbildung oben gezeigt, handelt es sich bei der GPU um eine Nvidia Quatro RTX8000 GPU. Während SAM (Vit-h) auf der CPU mehr als 2 Minuten pro Vorhersage benötigt, dauert SAM (Vit-b) etwa 14 Sekunden pro Vorhersage. Dies zeigt zweifellos die Anwendbarkeit dieses Modells in Umgebungen mit extrem geringen Ressourcen.
Entlastung von medizinischem Personal und Forschern von zeit- und arbeitsintensiver Arbeit
Künstliche Intelligenz zeigt seit langem großes Potenzial in der Bildanalyse und der Verarbeitung anderer hochdimensionaler Daten. Die Segmentierung medizinischer Bilder ist als häufigste Aufgabe in der biomedizinischen Bildanalyse und -verarbeitung natürlich zu einem der wichtigsten Testfelder für die Stärkung der künstlichen Intelligenz geworden.
Zusätzlich zu dieser StudieWie im Artikel erwähnt, ist SAM auch eines der Haupttools, das in den letzten Jahren die meiste Aufmerksamkeit der entsprechenden wissenschaftlichen Forschungsteams auf sich gezogen hat.HyperAI hat bereits Folgeforschungen zu verwandten Themen durchgeführt, wie zum Beispiel „Die neueste Anwendung von SAM 2 wurde gestartet! Das Team der Universität Oxford hat Medical SAM 2 veröffentlicht und damit die SOTA-Liste der medizinischen Bildsegmentierung aktualisiert.“In dem Artikel berichtete das Team der Universität Oxford über seine Entdeckung des Potenzials von SAM bei der Segmentierung medizinischer Bilder.
Die Studie stellte ein medizinisches Bildsegmentierungsmodell namens Medical SAM 2 vor, das von einem Team der Universität Oxford entwickelt wurde. Es wurde auf Grundlage des SAM 2-Frameworks entwickelt und eignet sich nicht nur hervorragend für die Segmentierung medizinischer 3D-Bilder, indem es medizinische Bilder wie Videos behandelt, sondern bietet auch eine neue Funktion zur Segmentierung mit einer einzigen Eingabeaufforderung. Der Benutzer muss lediglich einen Hinweis für ein neues bestimmtes Objekt geben, und die Segmentierung ähnlicher Objekte in nachfolgenden Bildern kann vom Modell ohne weitere Eingaben automatisch abgeschlossen werden.
sicherlich,Neben SAM gibt es zahlreiche weitere Studien zu medizinischen Bildsegmentierungsmethoden auf Basis von Deep Learning.So wurde beispielsweise eine Studie mit dem Titel „Scribformer: Transformer Makes CNN Work Better for Scribble-based Medical Image Segmentation“ in der international renommierten Fachzeitschrift und Zeitschrift IEEE Transactions on Medical Imaging veröffentlicht.
Die Studie wurde von einem Forscherteam verschiedener Institutionen veröffentlicht, darunter der Xiamen University, der Peking University, der Chinese University of Hong Kong, der ShanghaiTech University und der University of Hull in Großbritannien.Die Studie schlug eine neue CNN-Transformer-Hybridlösung für die durch Graffiti überwachte Segmentierung medizinischer Bilder namens ScribFormer vor.
Kurz gesagt: Ob es sich nun um die Ergebnisse der Forschung des MIT, auf SAM basierende Innovationen oder andere neue Methoden handelt, der Zweck ist derselbe. Wie das Sprichwort sagt: Alle Wege führen nach Rom. Der Einsatz künstlicher Intelligenz im medizinischen Bereich soll der Medizin und der Gesellschaft zugutekommen.
Hallee E Wong, die Hauptautorin des ScribblePrompt-Artikels und Doktorandin am MIT, sagte:„Wir möchten die Arbeit des medizinischen Personals durch ein interaktives System ergänzen, nicht ersetzen.“
Quellen:
1.https://news.mit.edu/2024/scribbleprompt-helping-doctors-annotate-medical-scans-0909
2.https://arxiv.org/pdf/2312.0738








