Command Palette
Search for a command to run...
Mein Herr, Die Zeiten Von Vincent Van Gogh Haben Sich Wieder Geändert! SD-Kernmitglieder Gründen Ihre Eigene Firma, Und Das Erste Modell FLUX.1 Ist Ein Harter Kampf Gegen SD 3 Und Midjourney

Von Midjourney mit seinen vielfältigen künstlerischen Stilen über DALL-E mit Unterstützung von OpenAI bis hin zur Open Source Stable Diffusion (kurz SD) wurden die Generierungsqualität und -geschwindigkeit des textbasierten Graphenmodells lange Zeit kontinuierlich verbessert, und schnelles Verständnis und Detailverarbeitung sind auch zu neuen Richtungen für die interne Zirkulation wichtiger Modelle geworden.
Nach dem Eintritt in das Jahr 2024 haben Midjourney und Stable Diffusion, die sich in der Phase des „Zwei-Pferde-Rennens“ befinden, sukzessive Anstrengungen unternommen. Zuerst wurde SD 3 veröffentlicht und dann wurde auch Midjourney V6.1 aktualisiert und iteriert. Wenn man jedoch noch immer in den Vergleich zwischen SD 3 und Midjourney vertieft ist,Eine neue Generation von „Teufeln“ wurde still und leise geboren – FLUX kam aus dem Nichts.
Wenn FLUX Charaktere generiert, insbesondere Szenen mit echten Menschen, kommt der Effekt Aufnahmen aus dem wirklichen Leben sehr nahe. Die Details wie Ausdruck, Hautglanz, Frisur und Farbe der Figur sind sehr realistisch.Es wurde einst als Nachfolger von Stable Diffusion gefeiert.Interessanterweise haben die beiden eine enge Beziehung.
Robin Rombach, der Gründer von Black Forest Labs, dem Team hinter FLUX, ist einer der Mitentwickler von Stable Diffusion. Nachdem er Stability AI verlassen hatte, gründete Robin Black Forest Labs.Und das Modell FLUX.1 auf den Markt gebracht.
Derzeit bietet FLUX.1 3 Versionen: Pro, Dev und Schnell. Die Pro-Version ist eine Closed-Source-Version, die über eine API bereitgestellt wird, kommerziell genutzt werden kann und gleichzeitig die leistungsstärkste Version ist. Die Dev-Version ist eine Open-Source-Version, die direkt aus der Pro-Version „destilliert“ wurde und über eine nichtkommerzielle Lizenz verfügt. Die Schnell-Version ist die schnellste optimierte Version, die angeblich bis zu 10-mal schneller läuft. Es ist Open Source und verwendet die Apache 2-Lizenz, geeignet für die lokale Entwicklung und den persönlichen Gebrauch.
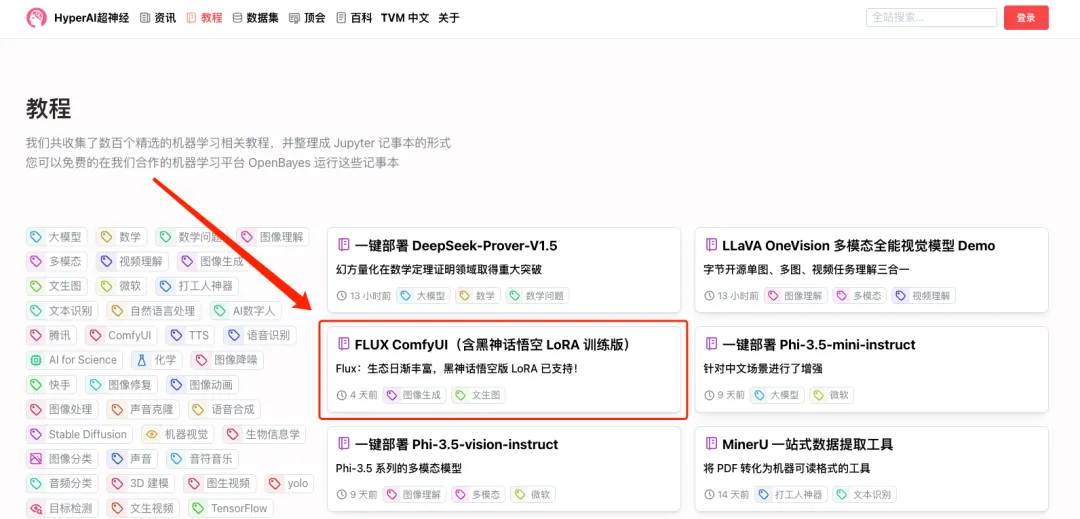
Ich glaube, dass viele von Ihnen diese neue Generation erstklassiger literarischer Bilder tatsächlich erleben möchten!Im Tutorial-Bereich der offiziellen Website von HyperAI (hyper.ai) wurde jetzt „FLUX ComfyUI (einschließlich Black Myth Wukong LoRA-Trainingsversion)“ eingeführt. Dabei handelt es sich um die ComfyUI-Version von FLUX [dev], die auch LoRA-Training unterstützt.
Wenn Sie Interesse haben, kommen Sie vorbei und erleben Sie es! Ich habe es für Sie ausprobiert und der Effekt ist genauso gut wie bei SD 3 und Midjourney↓

Dieselbe Eingabeaufforderung, generiert von 3 Modellen
* Aufforderung: Ein Mädchen hält ein Schild mit der Aufschrift „Ich bin eine KI“.
Darüber hinaus hat Jack-Cui, ein beliebter Up Master auf Bilibili, auch ein ausführliches Bedienungstutorial erstellt, um es jedem Schritt für Schritt beizubringen!
Adresse des Tutorials:
Bedienungsvideo:
https://www.bilibili.com/video/BV1xSpKeVEeM
Demolauf
FLUX ComfyUI Run
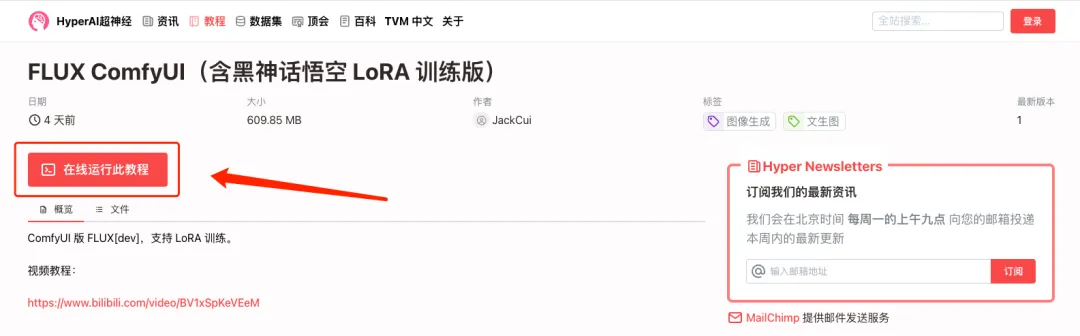
1. Melden Sie sich bei hyper.ai an und klicken Sie auf der Tutorial-Seite auf „Dieses Tutorial online ausführen“. „FLUX ComfyUI (einschließlich der Black Myth Wukong LoRA-Trainingsversion)“, klicken Sie auf „Dieses Tutorial online ausführen“.
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
3. Klicken Sie unten rechts auf „Weiter: Hashrate auswählen“.
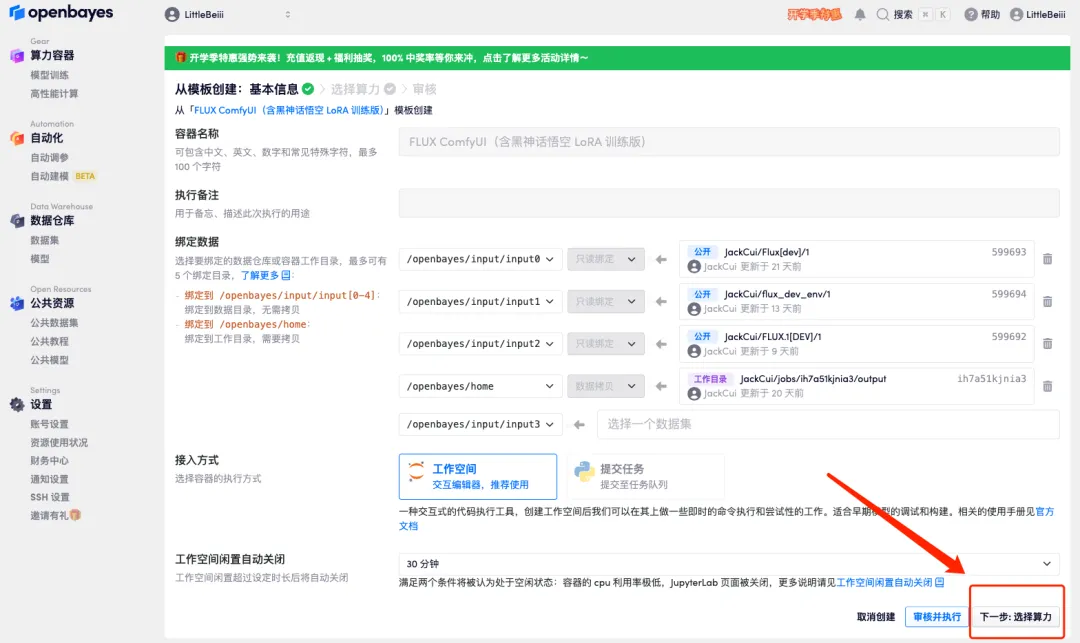
4. Wählen Sie nach dem Seitenwechsel das Bild „NVIDIA RTX 4090“ und „PyTorch“ aus und klicken Sie auf „Weiter: Überprüfen“.Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit zu erhalten!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
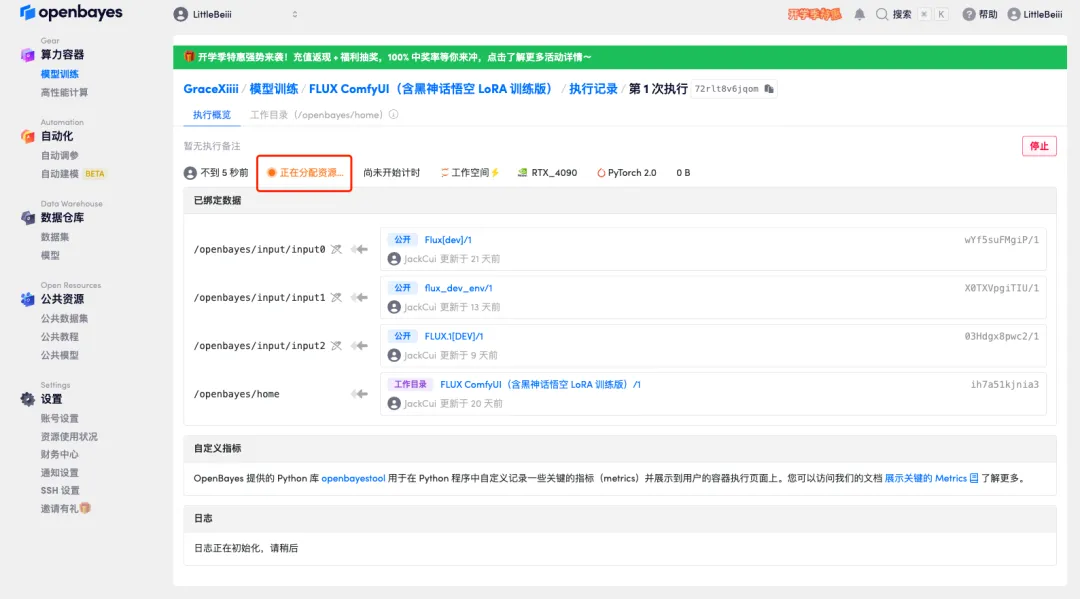
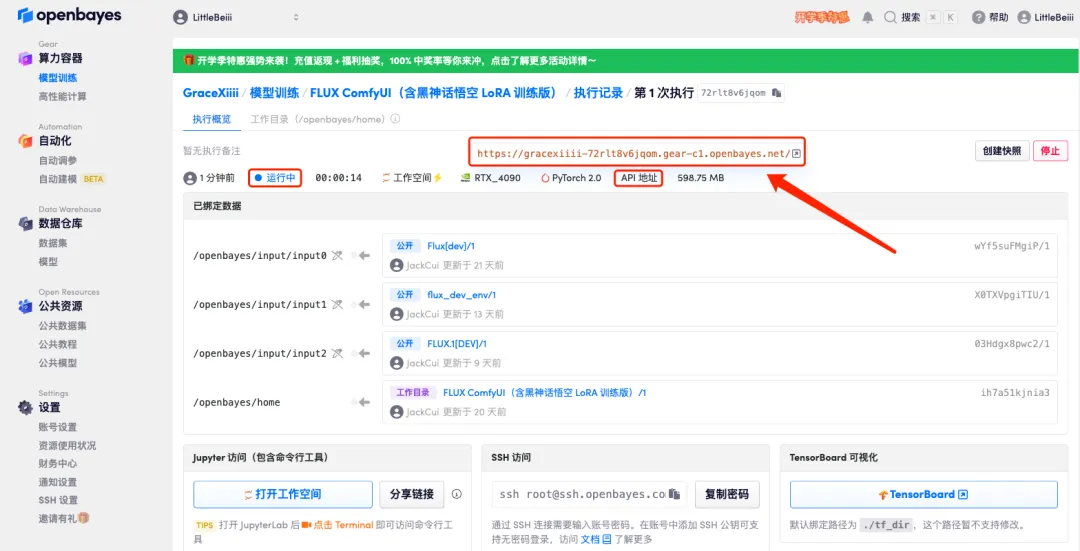
5. Klicken Sie nach der Bestätigung auf „Weiter“ und warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 1–2 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen.Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
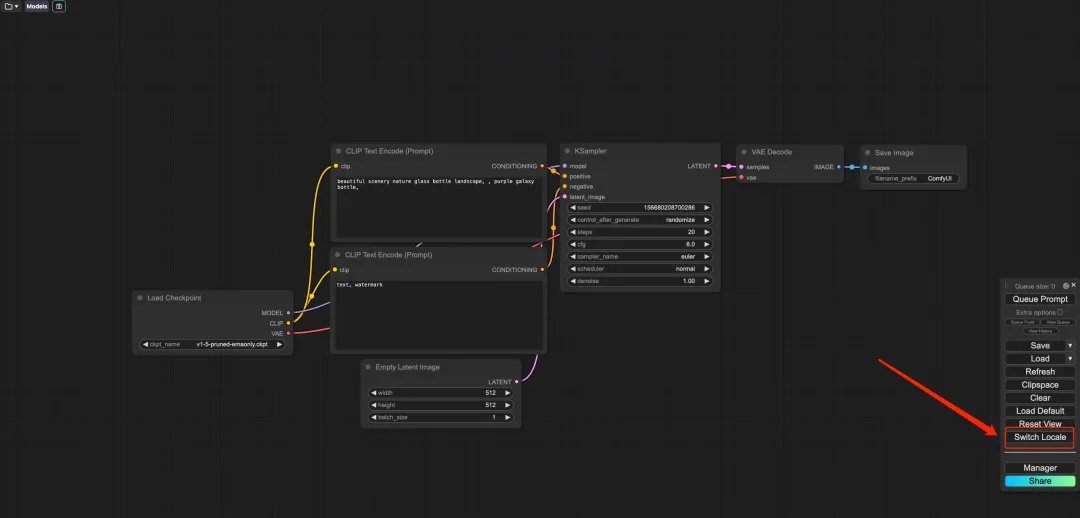
6. Klicken Sie nach dem Öffnen der Demo auf „Gebietsschema wechseln“, um die Sprache auf Chinesisch umzustellen.
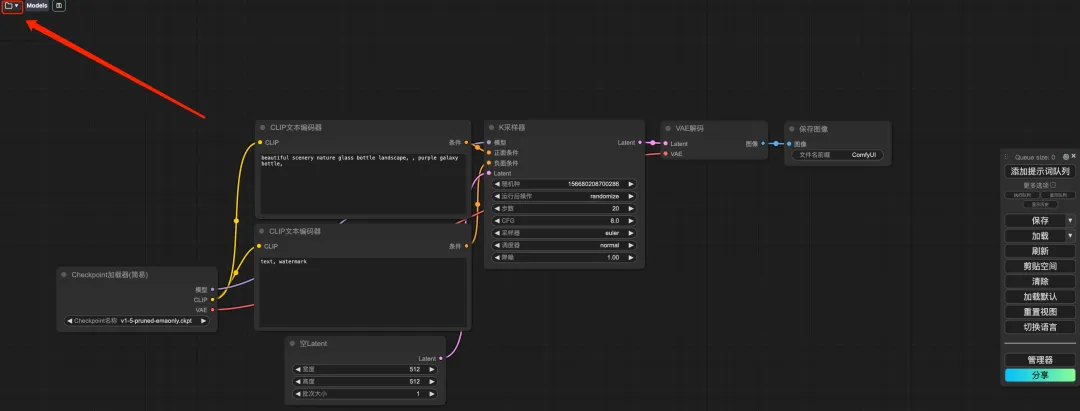
7. Klicken Sie nach dem Umschalten der Sprache auf das Ordnersymbol in der oberen linken Ecke, um den gewünschten Workflow auszuwählen.
* Wukong: Black Myth Wukong-Bilddemo
* TED: TED Live-Rede-Demo
* 3mm4w: Demo zum Schreiben von Text auf Bildern
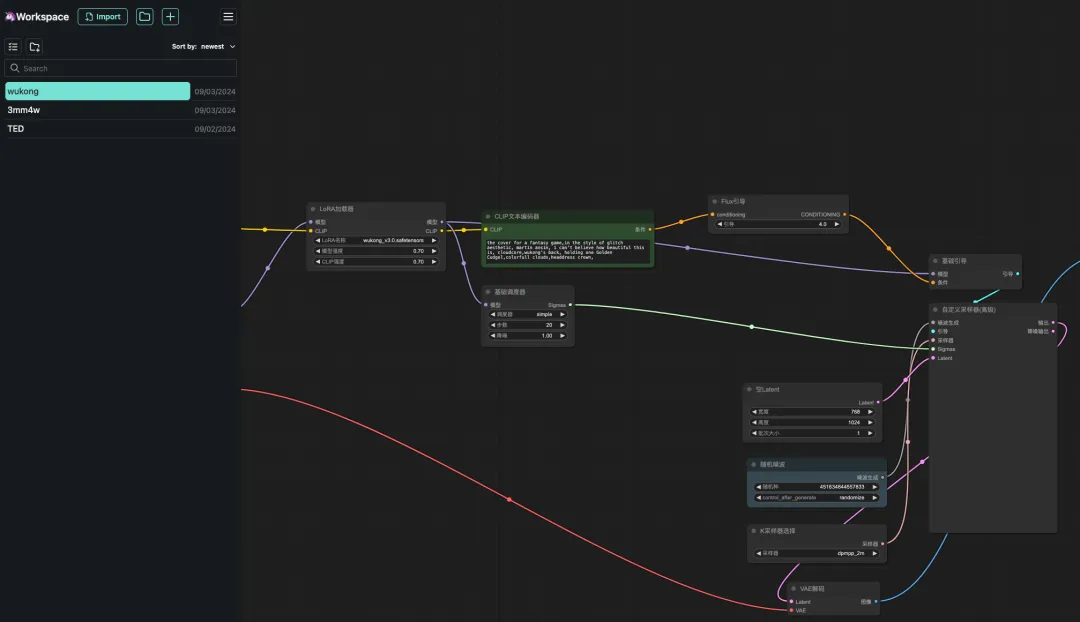
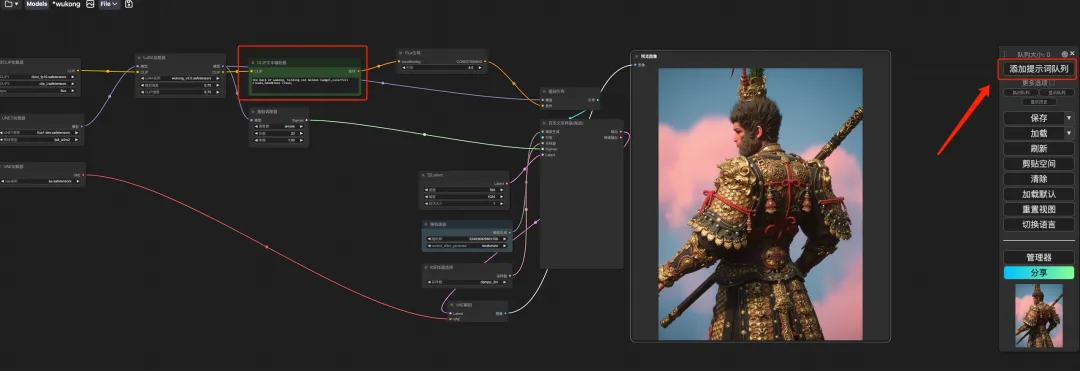
8. Wählen Sie den Workflow „Wukong“ aus, geben Sie die Eingabeaufforderung in den CLIP-Textgenerator ein (z. B. die Rückseite von Wukong, hält eine goldene Keule, bunte Wolken, Kopfschmuckkrone), klicken Sie auf „Eingabeaufforderungswortwarteschlange zum Generieren eines Bildes hinzufügen“, und Sie können sehen, dass das generierte Bild sehr schön ist.

FLUX LoRA-Schulung
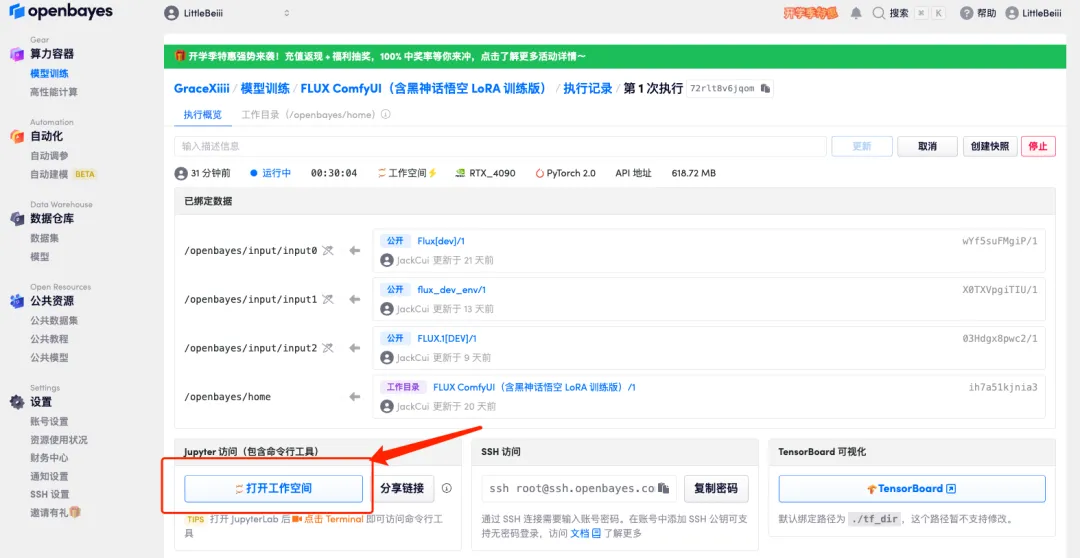
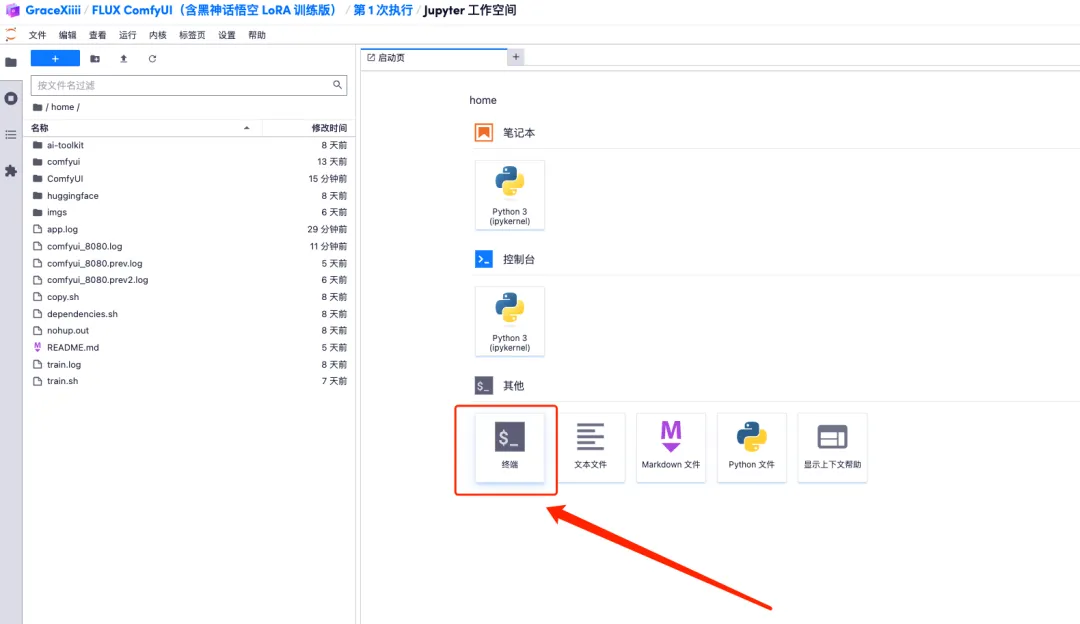
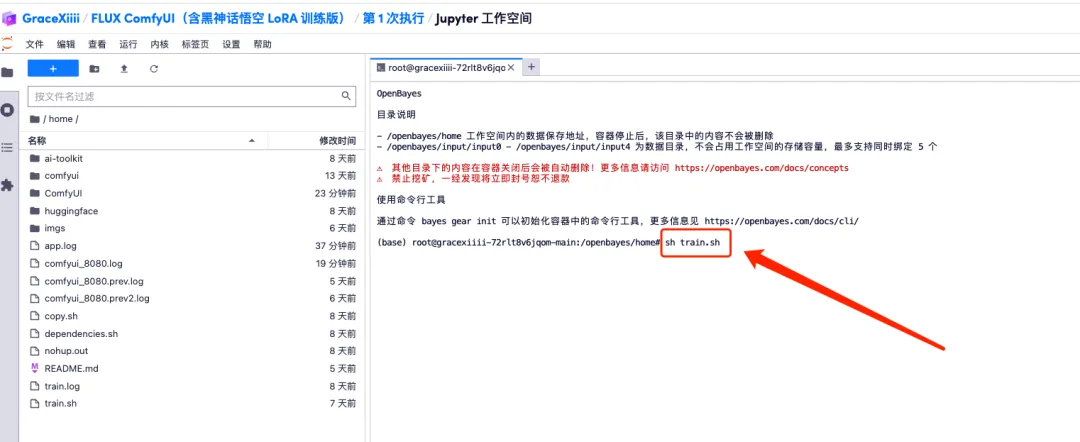
1. Um den Workflow anzupassen, müssen wir zuerst das LoRA-Modell trainieren. Kehren Sie jetzt zur Containeroberfläche zurück, klicken Sie auf „Arbeitsbereich öffnen“ und erstellen Sie ein neues Terminal.
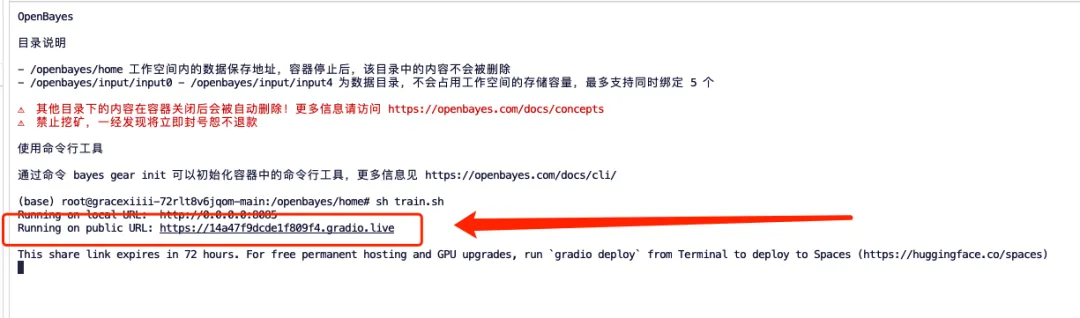
2. Geben Sie „sh train.sh“ in das Terminal ein und drücken Sie die Eingabetaste, um es auszuführen. Wenn „Auf öffentlicher URL ausgeführt“ angezeigt wird, klicken Sie auf den Link.
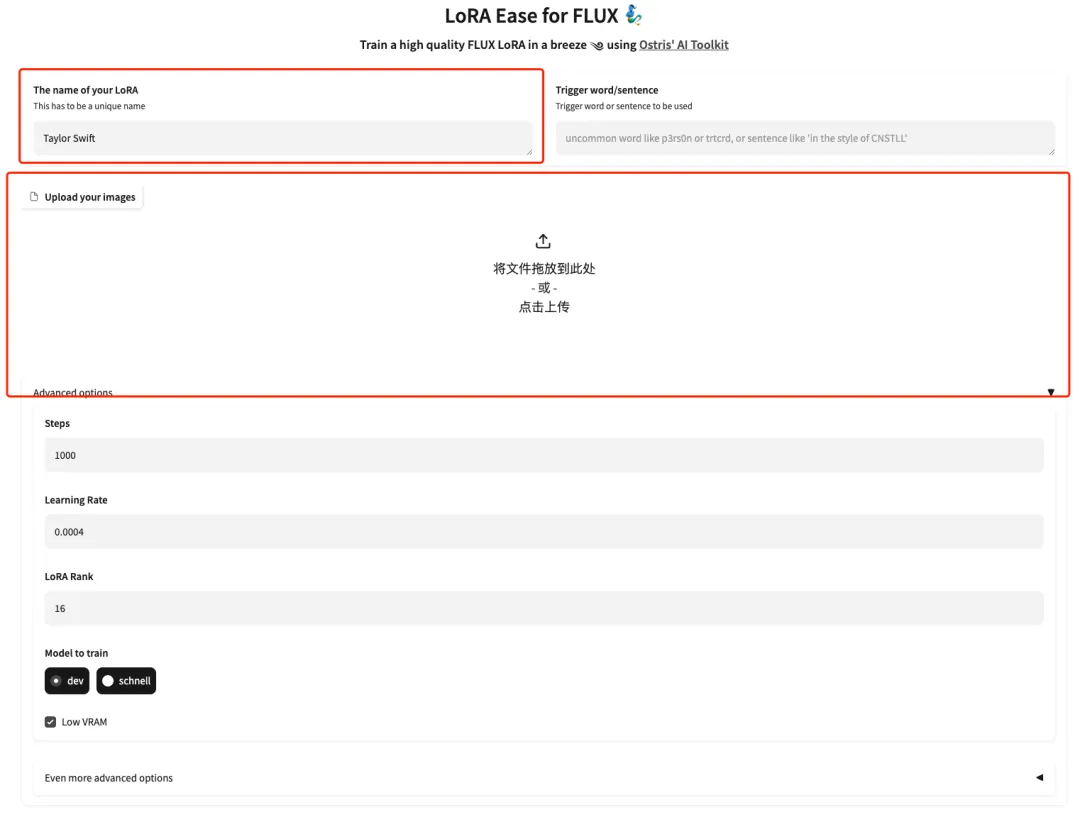
3. Nachdem die Seite gesprungen ist, geben Sie das Modell des Modells ein und laden Sie die Bilder hoch. Laden Sie hier 5 Fotos von Taylor Swift hoch.Bitte beachten Sie, dass es sich bei dem Bild um ein hochauflösendes Frontalfoto mit einem größeren Gesichtsverhältnis handeln muss. Je besser die Bildqualität, desto besser der Trainingseffekt.
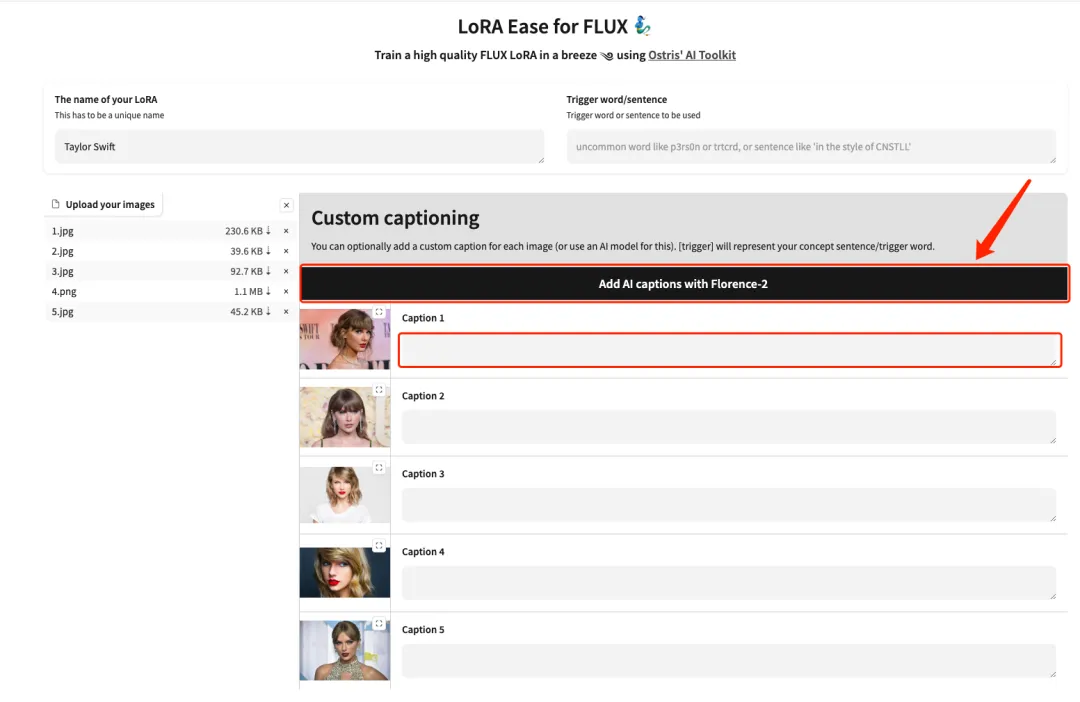
4. Fügen Sie nach dem erfolgreichen Hochladen nach jedem Bild manuell englische Textbeschreibungen hinzu oder klicken Sie auf „KI-Beschriftungen mit Florence-2 hinzufügen“, um automatisch Textbeschreibungen zu generieren.
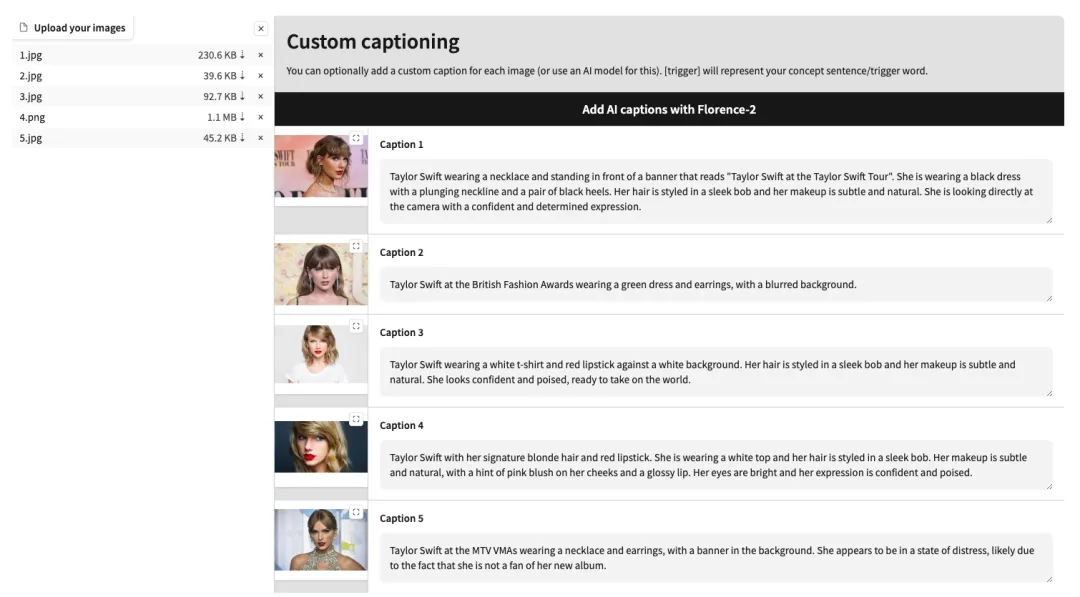
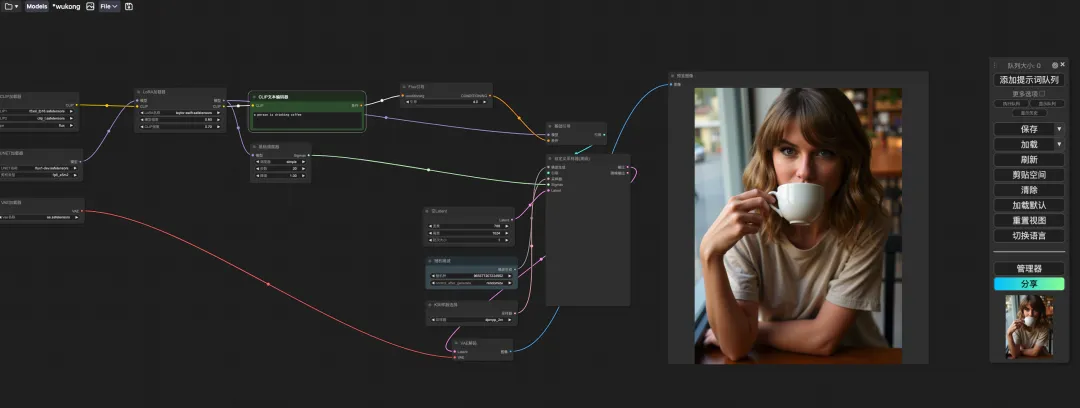
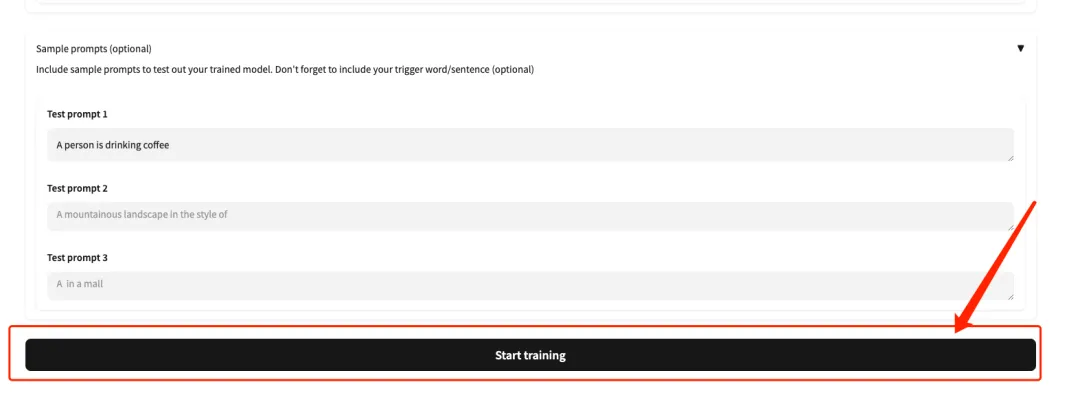
5. Scrollen Sie zum Ende der Seite, geben Sie eine Testaufforderung ein (z. B.: Eine Person trinkt Kaffee) und klicken Sie auf „Training starten“.
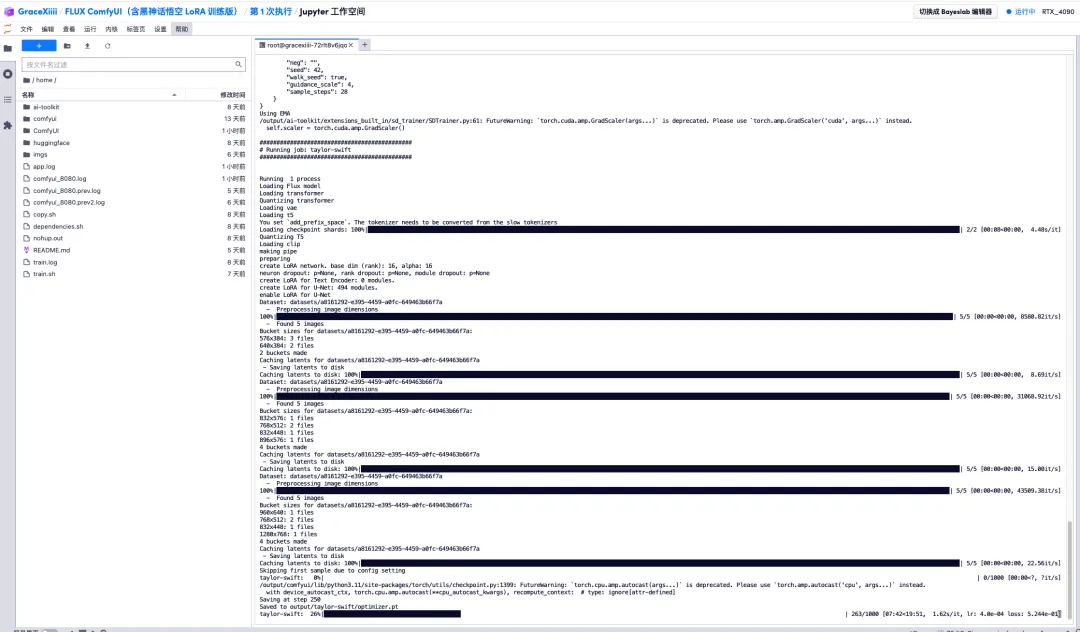
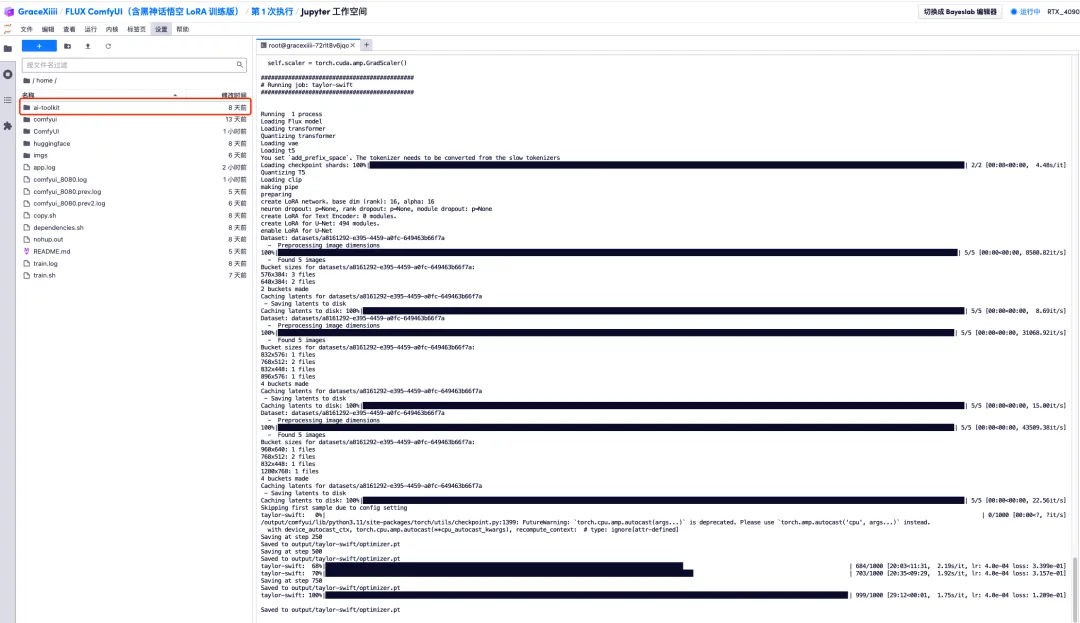
6. Nachdem wir einige Minuten gewartet haben, kehren wir zur Terminaloberfläche zurück und können den Trainingsfortschrittsbalken sehen. Die Schulung dauert etwa 40 Minuten. Wenn „Gespeichert in output/taylor-swift/optimizer.pt“ angezeigt wird, ist das Training abgeschlossen.
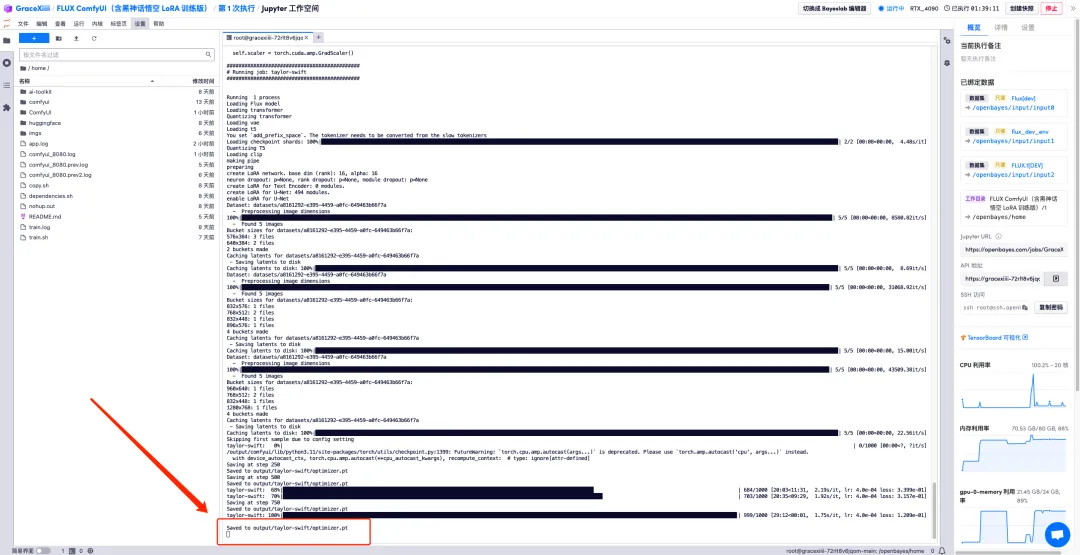
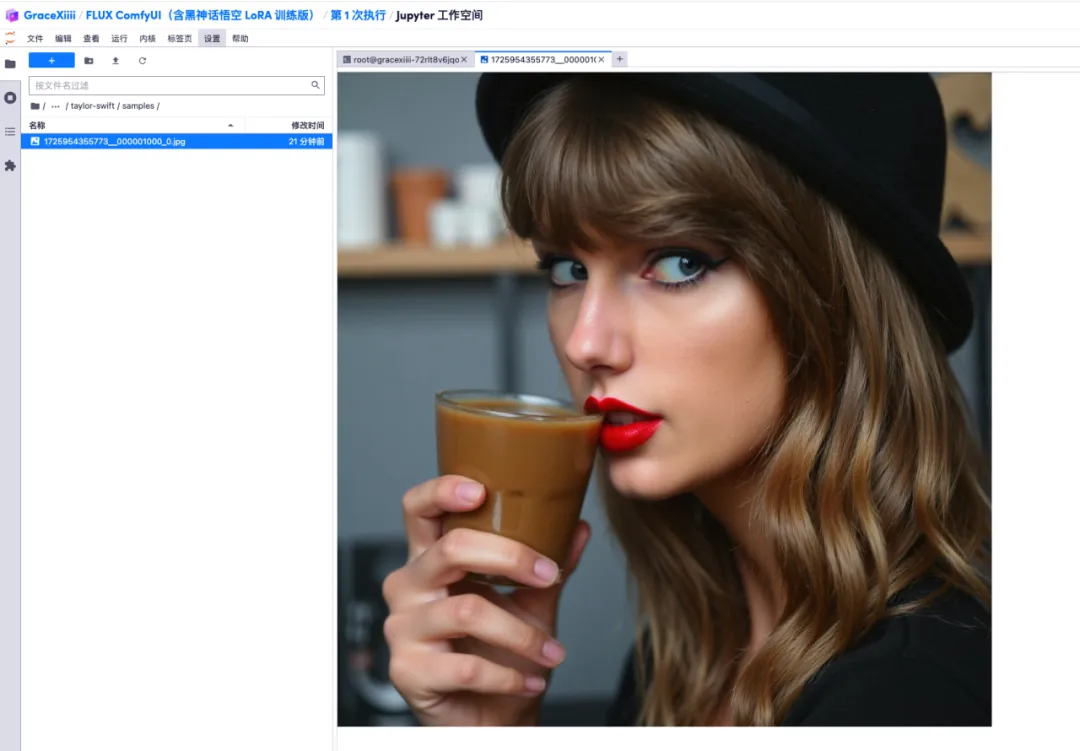
7. In der Datei „ai-toolkit“ – „output“ – „taylor swift“ – „sample“ auf der linken Seite können Sie die Wirkung unserer Testaufforderung sehen. Wenn der Effekt gut ist, beweist dies, dass unser Modell erfolgreich trainiert wurde.
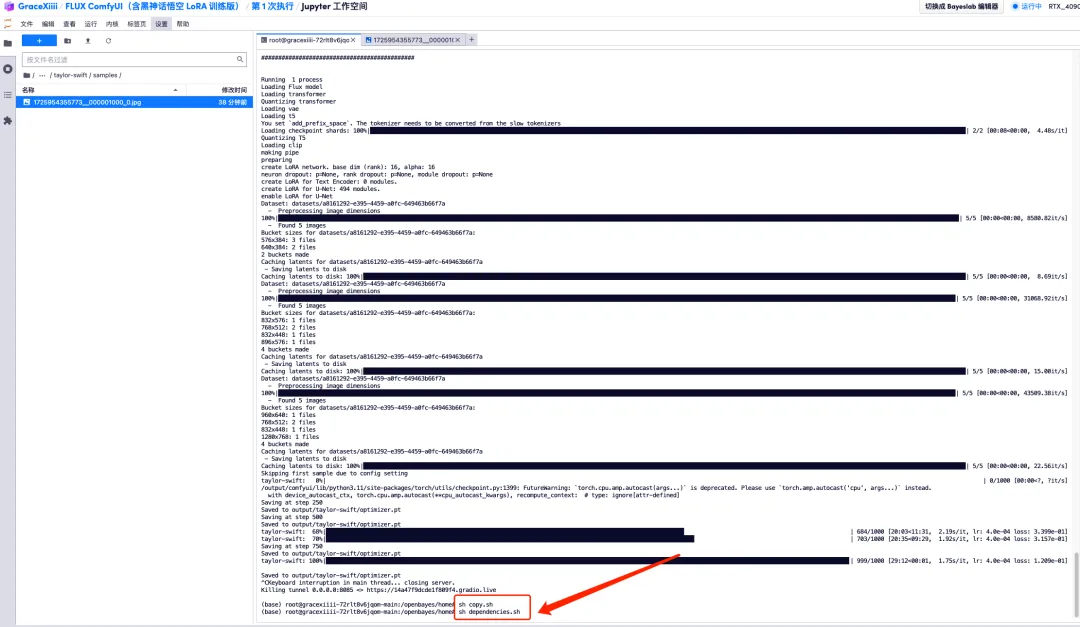
8. Nachdem das Modell trainiert ist, müssen wir den Trainingsdienst herunterfahren, um GPU-Ressourcen freizugeben, jetzt zur Tastenschnittstelle zurückkehren und „Strg+C“ drücken, um das Training zu beenden.
9. Führen Sie „sh copy.sh“ und dann „sh dependencies.sh“ aus, um ComfyUI zu starten, warten Sie 2 Minuten und öffnen Sie die API-Adresse auf der rechten Seite.
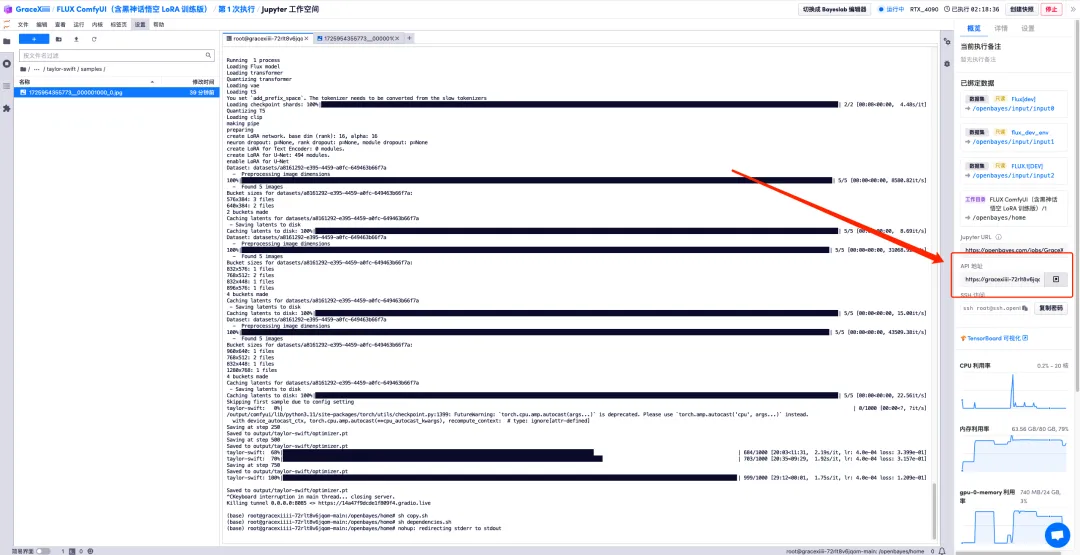
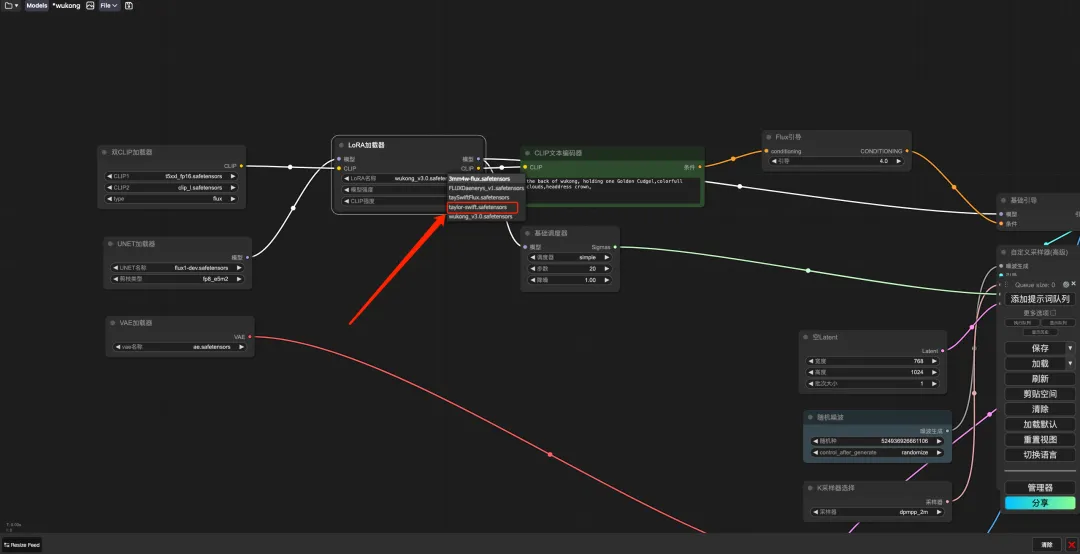
10. Wählen Sie nach dem Seitensprung das trainierte Modell im „LoRA Loader“ aus, geben Sie in „CLIP“ eine Eingabeaufforderung ein (z. B.: Eine Person trinkt Kaffee) und klicken Sie auf „Eingabeaufforderungswortwarteschlange hinzufügen“, um das Bild zu generieren.