Command Palette
Search for a command to run...
Nach Einem Schlaganfall War Sie 18 Jahre Lang sprachlos. KI Und Gehirn-Computer-Schnittstelle Helfen Ihr, „mit Gedanken Zu sprechen“.

Zweig sagte einmal:Das größte Glück im Leben eines Menschen besteht darin, seine Bestimmung in der Mitte seines Lebens zu entdecken, wenn er jung und stark ist.
Was ist das größte Unglück des Menschen?
Meiner Meinung nach ist das größte Unglück im Leben eines MenschenNichts ist schlimmer, als mitten im Leben plötzlich die Fähigkeit zu sprechen und sich zu bewegen zu verlieren.——Über Nacht verwandelten sich Träume, Karrieren und Wünsche in nichts und das Leben wurde auf den Kopf gestellt.
Ann ist ein unglückliches Beispiel.
30 Jahre alt, Aphasie aufgrund eines Schlaganfalls
Eines Tages im Jahr 2005 litt Ann, die immer bei guter Gesundheit gewesen war, plötzlich unter Schwindel, undeutlicher Aussprache, Tetraplegie und Muskelschwäche. Bei ihr wurde diagnostiziertHirnstamminfarkt(Was wir im täglichen Leben als „Schlaganfall“ bezeichnen),Begleitet von einer Dissektion der linken Vertebralarterie und einem Verschluss der Arteria basilaris.
Dieser unerwartete Schlaganfall brachte Ann eineLocked-in-SyndromEin Nebeneffekt dieser Krankheit: Betroffene verfügen über alle Sinne und das Bewusstsein, können jedoch keine Muskeln im Körper mobilisieren. Die Patienten können sich weder selbstständig bewegen noch sprechen, manche können nicht einmal atmen.
Wie das Wort „eingesperrt“ wörtlich ausdrückt, ist der Körper, der gewöhnliche Menschen durch Tausende von Bergen und Flüssen trägt, zu einem Käfig geworden, der die Seele des Patienten versiegelt.
Ann war damals erst 30 Jahre alt, seit 2 Jahren und 2 Monaten verheiratet, ihre Tochter war gerade 13 Monate alt und sie war Mathematiklehrerin an einer High School in Kanada. „Mir wurde über Nacht alles genommen.“ Ann benutzte das Gerät später, um diesen Satz langsam auf dem Computer zu tippen.

Nach Jahren der Physiotherapie konnte Ann atmen, ihren Kopf leicht bewegen, mit den Augen blinzeln und ein paar Worte sprechen, aber das war es auch schon.
Sie sollten wissen, dass im normalen Leben die durchschnittliche Sprechgeschwindigkeit 160–200 Wörter/MinuteIm Jahr 2007 zeigte eine Studie der Abteilung für Psychologie an der Universität von Arizona, dass Männer im Durchschnitt 15,669 Wörter, sagen Frauen im Durchschnitt 16,215 Wörter (im Durchschnitt entspricht ein Wort 1,5–2 chinesischen Schriftzeichen).
In einer Welt, in der Sprache das wichtigste Mittel der zwischenmenschlichen Kommunikation ist, kann man sich vorstellen, wie viele von Anns Bedürfnissen aufgrund ihrer eingeschränkten Ausdrucksfähigkeit zum Schweigen gebracht wurden.Bei einer Aphasie geht nicht nur die Lebensqualität verloren, sondern auch die Persönlichkeit und Identität.Und wie viele gelähmte und aphasische Menschen auf der Welt sind in der gleichen Situation wie Ann?
18 Jahre lang gelähmt, spricht er wieder
Der größte Wunsch eines jeden Menschen, der aufgrund einer Lähmung seine Sprache verloren hat, ist die Wiederherstellung der Fähigkeit zur vollständigen und natürlichen Kommunikation.Gibt es in der heutigen hochentwickelten technologischen Welt eine Möglichkeit, die Macht der Technologie zu nutzen, um Patienten die Fähigkeit zur zwischenmenschlichen Kommunikation wiederherzustellen?
haben!
Kürzlich hat ein Forscherteam der University of California, San Francisco und der University of California, BerkeleyNutzung von KI zur Entwicklung einer neuen Gehirn-Computer-TechnologieAnn, die 18 Jahre lang sprachlos war, erlangte ihre "Sprechen"und erzeugen lebendigeGesichtsausdrücke, und hilft Patienten dabei, in Echtzeit mit anderen in einer Geschwindigkeit und Qualität zu kommunizieren, die einer normalen sozialen Interaktion entspricht.

Dies ist das erste Mal in der Geschichte der Menschheit, dass Sprache und Gesichtsausdrücke aus Gehirnsignalen synthetisiert wurden!
Frühere Untersuchungen des UC-Teams haben gezeigt, dass es möglich ist, Sprache aus der Gehirnaktivität gelähmter Menschen zu dekodieren, allerdings nur in Form von Textausgabe und mit begrenzter Geschwindigkeit und begrenztem Wortschatz.
Diesmal wollen sie noch einen Schritt weiter gehen:Es ermöglicht eine schnellere Textkommunikation mit großem Wortschatz und stellt gleichzeitig die mit dem Sprechen verbundenen Sprach- und Gesichtsbewegungen wieder her.
Basierend auf maschinellem Lernen und Brain-Computer-Interface-Technologie erzielte das Forschungsteam die folgenden Ergebnisse, die am 23. August 2023 in Nature veröffentlicht wurden:
► FürText, die Gehirnsignale der Probanden mit einer Geschwindigkeit von 78 Wörtern pro Minute in Text umzuwandeln, mit einer durchschnittlichen Wortfehlerrate von 25%, das mehr als viermal schneller ist als das derzeit von den Probanden verwendete Kommunikationsgerät (14 Wörter/Minute);
►FürSprachaudio, schnelle Synthese von Gehirnsignalen in verständliche und personalisierte Laute, die mit der Stimme des Probanden vor der Verletzung übereinstimmen;
►FürDigitaler Gesichtsavatar, wodurch eine virtuelle Gesichtsbewegungssteuerung für sprachliche und nicht-sprachliche Kommunikationsgesten erreicht wird.

Link zum Artikel:
https://www.nature.com/articles/s41586-023-06443-4
Sie müssen neugierig sein.Wie wurde dieses epochale Wunder erreicht?Als Nächstes wollen wir dieses Dokument im Detail analysieren und sehen, wie die Forscher das Virus wieder zum Leben erweckt haben.
1. Zugrundeliegende Logik Gehirnsignale → Sprache + Mimik
Das menschliche Gehirn gibt Informationen über periphere Nerven und Muskelgewebe aus, während die Sprachfähigkeit von der Großhirnrinde erzeugt wird. "Sprachzentrum"kontrolliert.
Der Grund, warum Schlaganfallpatienten an Aphasie leiden, liegt darin, dass die Blutzirkulation behindert ist und der Sprachbereich des Gehirns aufgrund von Sauerstoffmangel und Mangel an wichtigen Nährstoffen geschädigt wird, was dazu führt, dass ein oder mehrere Mechanismen der Sprachkommunikation nicht richtig funktionieren können und es zu Sprachstörungen kommt.
Als Reaktion darauf entwickelte ein Forscherteam der University of California, San Francisco und Berkeley eine „Multimodale neuronale Sprachprothese“, wobei ein großflächiges, hochdichtes kortikales Elektroenzephalogramm (ECoG) verwendet wird, um den Text und die audiovisuelle Sprachausgabe zu dekodieren, die durch den im gesamten sensorischen Kortex (SMC) verteilten Stimmtrakt dargestellt werden, d. h., es werden Gehirnsignale an der Quelle erfasst und mit technischen Mitteln in entsprechenden Text, Sprache und sogar Gesichtsausdrücke „übersetzt“.
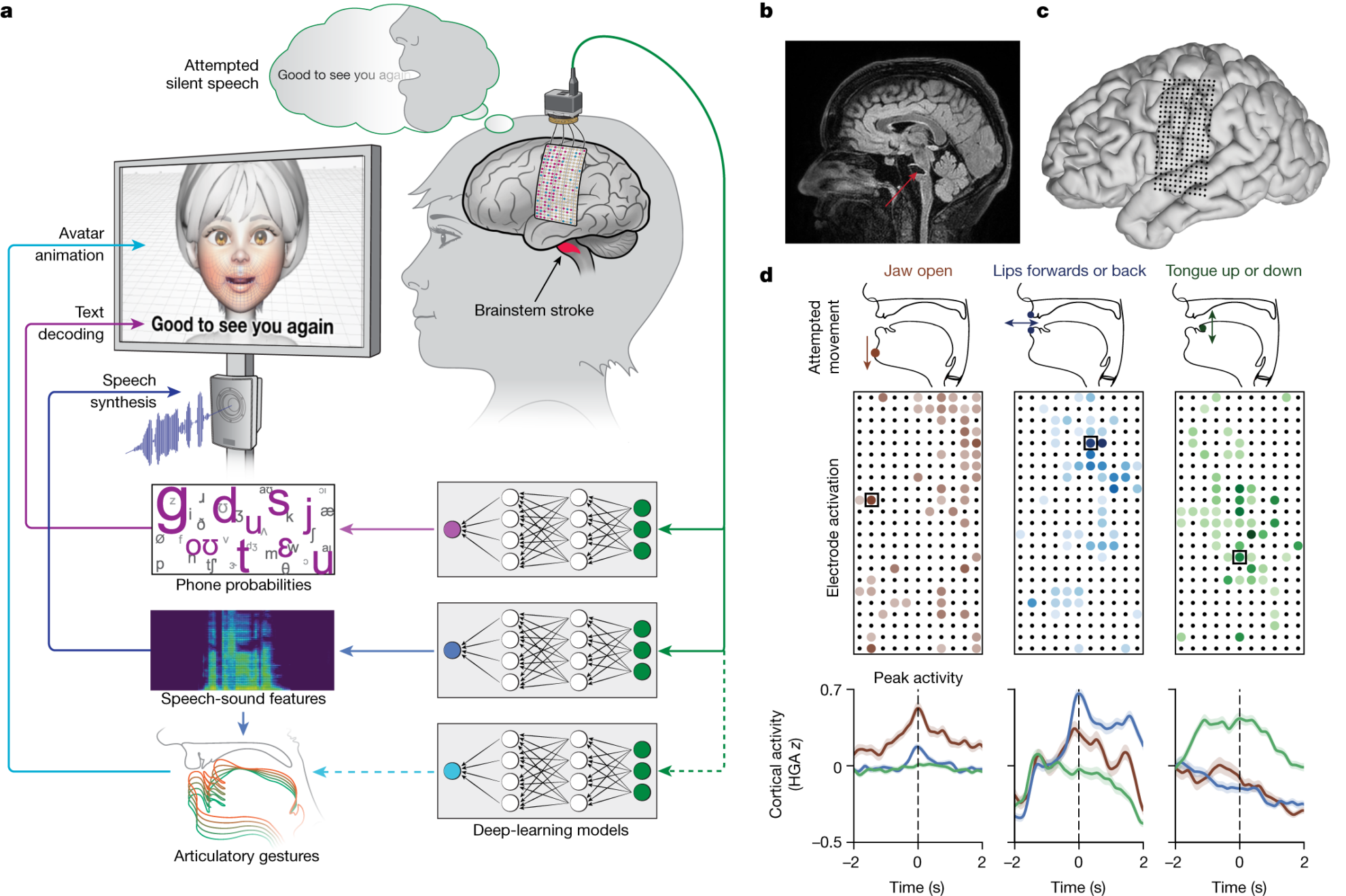
2. Prozess und Umsetzung Gehirn-Computer-Schnittstelle + KI-Algorithmus
Das erste sind physische Mittel.
Die Forscher implantierten einEEG-Array mit hoher DichteUndTranskutaner Docking-Anschluss, die Bereiche im Zusammenhang mit Sprachproduktion und Sprachwahrnehmung abdecken.
Das Array besteht aus 253Die scheibenförmigen Elektroden werden verwendet, um Gehirnsignale abzufangen, die ursprünglich an Anns Zunge, Kiefer, Rachen und Gesichtsmuskulatur gesendet werden. Ein Kabel wird in einen an Anns Kopf befestigten Anschluss gesteckt und verbindet die Elektroden mit einer Reihe von Computern.

Der zweite ist die Algorithmuskonstruktion.
Um Anns einzigartige Sprachsignale zu identifizieren,Das Forschungsteam arbeitete mehrere Wochen mit ihr zusammen, um das Deep-Learning-Modell zu trainieren und zu evaluieren.
Die Forscher erstellten einen Satz von 1.024 gängigen Sätzen auf Grundlage des NLTK-Twitter-Korpus und des Cornell Film Corpus und wiesen Ann an, in einer natürlichen Sprechgeschwindigkeit leise zu sprechen. Sie wiederholt immer wieder verschiedene Ausdrücke aus ihrem 1.024 Wörter umfassenden Konversationswortschatz.Bis der Computer die mit diesen Geräuschen verbundenen Muster der Gehirnaktivität erkennt.
Es ist erwähnenswert, dass dieses Modell die KI nicht darauf trainiert, ganze Wörter zu erkennen.Stattdessen wurde ein System geschaffenWörter anhand von Phonemen entschlüsselnBeispielsweise enthält „Hallo“ vier Phoneme: „HH“, „AH“, „L“ und „OW“.
Basierend auf dieser Methode muss ein Computer nur 39 Phoneme lernen, um jedes englische Wort zu entschlüsseln.Es verbessert nicht nur die Genauigkeit, sondern erhöht auch die Geschwindigkeit um das Dreifache.
Hinweis: Ein Phonem ist die kleinste Lauteinheit einer Sprache, die die Aussprachemerkmale der Sprache beschreiben kann, einschließlich Artikulationsort, Aussprachemethode und Stimmbandvibration. Beispielsweise bestehen die Phoneme von „an“ aus /ə/ und /n/.
Dieser Vorgang der Phonem-Dekodierung ähnelt dem Vorgang, bei dem ein Baby das Sprechen lernt. Nach allgemein anerkannter Auffassung im Bereich der Entwicklungslinguistik können Neugeborene zwischen den verschiedenen Sprachen der Welt unterscheiden. 800 individuellPhonem. Vorschulkinder verstehen möglicherweise nicht die Schreibweise und Bedeutung von Wörtern und Sätzen, aber sie können durch das Wahrnehmen, Unterscheiden und Nachahmen von Phonemen nach und nach die Aussprache erlernen und Sprache verstehen.
Schließlich gibt es noch die Sprach- und Gesichtsausdruckssynthese.
Der Grundstein ist gelegt, im nächsten Schritt geht es darum, Stimme und Mimik zu zeigen.Die ForscherSprachsyntheseUndDigitaler Avatarum dieses Problem zu lösen.
Stimmeentwickelten die Forscher anhand von Aufnahmen von Anns Stimme vor ihrem Schlaganfall einen synthetischen Sprachalgorithmus, um den digitalen Avatar so ähnlich wie möglich klingen zu lassen.
GesichtsausdrückeAnns digitaler Avatar wurde mit einer von Speech Graphics entwickelten Software erstellt und erscheint als Animation eines weiblichen Gesichts auf dem Bildschirm.
Die Forscher haben den maschinellen Lernprozess angepasst.Um die Software auf die Signale abzustimmen, die Anns Gehirn sendet, wenn sie versucht zu sprechen, wodurch das Öffnen und Schließen des Kiefers, das Vorschieben und Zurückziehen der Lippen, die Auf- und Abbewegung der Zunge sowie Gesichtsbewegungen und Gesten gezeigt werden, die Freude, Trauer und Überraschung ausdrücken.

Zukunftsaussichten
„Unser Ziel ist es, eine vollständige, konkrete Form der Kommunikation wiederherzustellen“, sagte Edward Chang, MD, Chef der Neurochirurgie an der UCSF., was für uns die natürlichste Art ist, mit anderen zu sprechen … Das Ziel, hörbare Sprache mit echten Avataren zu kombinieren, ermöglicht die vollständige Manifestation menschlicher Sprachkommunikation, die weit mehr ist als nur Sprache.
Der nächste Schritt für das Forschungsteam istErstellen Sie eine drahtlose Version,Die physische Verbindung von Gehirn-Computer-Schnittstellen auflösen, wodurch gelähmte Menschen diese Technologie nutzen können, um ihre persönlichen Mobiltelefone und Computer frei zu steuern, was tiefgreifende Auswirkungen auf ihre Unabhängigkeit und soziale Interaktion haben wird.
Von Sprachassistenten auf Mobiltelefonen, elektronischer Gesichtserkennung beim Bezahlen bis hin zu Roboterarmen in Fabriken und Sortierrobotern an Produktionslinien,KI erweitert die menschlichen Gliedmaßen und Sinne und dringt nach und nach in jeden Aspekt unserer Produktion und unseres Lebens ein.
Die Forscher konzentrieren sich auf die besondere Gruppe gelähmter und aphasischer Menschen und nutzen die Möglichkeiten der KI, um ihnen dabei zu helfen, ihre natürliche Kommunikationsfähigkeit wiederherzustellen. Dies soll die Kommunikation zwischen den Patienten und ihren Verwandten und Freunden verbessern und ihre Möglichkeiten zur Wiedererlangung zwischenmenschlicher Interaktion erweitern.Und schließlichHohe Lebensqualität der Patienten.
Wir freuen uns über diesen Erfolg und darauf, weitere gute Nachrichten darüber zu hören, wie KI der Menschheit nützt.
Referenzlinks:
[1] https://www.sciencedaily.com/releases/2023/08/230823122530.htm
[2] http://mrw.so/6nWwSB








