Command Palette
Search for a command to run...
Das Open-Source-Datenverarbeitungstool 10k Star Wird Mit Einem Klick Gestartet! Unterstützt Die Erkennung Von 176 Sprachen; Der Erste Datensatz Zur Erkennung Herabfallender Objekte in Hochhäusern Ist Online, Einschließlich Fast 2.000 Videos in 18 Szenen

Im Bereich der künstlichen Intelligenz war die multimodale Datenverarbeitung schon immer ein schwieriges Problem. Angesichts komplexer PDFs, Webseiten und E-Books in mehreren Formaten ist es nicht einfach, wichtige Informationen effektiv zu extrahieren.
Das Shanghai Artificial Intelligence Laboratory und das OpenDataLab-Team haben mit MinerU ein Open-Source-Tool zur intelligenten Datenextraktion auf den Markt gebracht, das multimodale PDF-Dokumente mit Elementen wie Bildern, Formeln, Tabellen usw. in ein leicht zu analysierendes Markdown-Format konvertieren kann. Es unterstützt auch das Extrahieren von Inhalten aus Webseiten und E-Books und löst so das Problem, automatisch hochwertige Daten aus komplexen Dokumenten zu extrahieren.
Auf der offiziellen Website von hyper.ai wurde die „Demo des One-Stop-Datenextraktionstools MinerU“ veröffentlicht.Scrollen Sie nach unten, um den Link zu erhalten~
Vom 26. bis 30. August gibt es Updates auf der offiziellen Website von hyper.ai:
* Auswahl an hochwertigen Tutorials: 3
* Hochwertige öffentliche Datensätze: 10
* Community-Artikelauswahl: 3 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im September: 7
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Tutorials
1. MinerU – das zentrale Datenextraktionstool
MinerU ist ein Tool, das PDF in maschinenlesbare Formate (wie Markdown, JSON) konvertiert, die problemlos in jedes beliebige Format extrahiert werden können, die genaue Erkennung von 176 Sprachen unterstützt und eine präzise Sprachtypidentifizierung durchführt. Das Modell und die Umgebung wurden bereitgestellt. Sie können das große Modell gemäß den Anweisungen des Tutorials zur Inferenzgenerierung verwenden.
Direkte Verwendung:https://go.hyper.ai/MIitP
2. Bereitstellung von LongWriter-glm4-9b mit einem Klick
LongWriter ist ein Open-Source-Projekt der Tsinghua-Universität, das mithilfe eines Long-Context Large Language Model (LLM) sehr lange Texte (mehr als 10.000 Wörter) generiert. Dieses Tutorial ist eine Ein-Klick-Bereitstellungsdemo des Modells. Sie müssen nur den Container klonen und starten und die generierte API-Adresse direkt kopieren, um die Inferenz des Modells zu erleben.
Direkte Verwendung:https://go.hyper.ai/Xvktt
Die Verwendung herkömmlicher digitaler Menschen-Trainingsprogramme zur Generierung eines hochwertigen digitalen Menschen erfordert oft viel Zeit und Rechenressourcen und stellt auch hohe Anforderungen an das Trainingsmaterial. Das Aufkommen von MuseV und MuseTalk hat zu neuen Durchbrüchen im Bereich der digitalen Menschen geführt. Nachdem mit MuseV digitale Menschenvideos erstellt wurden, werden mit MuseTalk Lippenbewegungen und Audio synchronisiert. Eine vollständige digitale Menschenproduktion kann in nur wenigen Minuten erreicht werden. Alle wurden in das öffentliche Tutorial-Modul von hyper.ai hochgeladen und können mit einem Klick geklont und online ausgeführt werden!
MuseV-Tutorial:https://go.hyper.ai/9fExW
MuseTalk-Tutorials:https://go.hyper.ai/wiw8g
Ausgewählte öffentliche Datensätze
1. FADE-Datensatz zur Erkennung fallender Objekte um Gebäude
Der FADE-Datensatz enthält 1.881 Videos, die 18 Szenen, 8 verschiedene Kategorien fallender Objekte, 4 verschiedene Wetterbedingungen und 4 Videoauflösungen abdecken. Die Vielfalt und Spezialisierung des FADE-Datensatzes machen ihn zu einer wertvollen Ressource für die Untersuchung der Erkennung herabfallender Gegenstände rund um Gebäude.
Direkte Verwendung:https://go.hyper.ai/8u8Sr
2. ChiPBench Al-Chip-Layout-Algorithmus-Datensatz
ChiPBench ist ein umfassender Benchmark, der speziell dafür entwickelt wurde, die Wirksamkeit vorhandener KI-basierter Chipplatzierungsalgorithmen bei der Verbesserung der endgültigen PPA-Metrik des Designs zu bewerten. Das Forschungsteam sammelte 20 Schaltkreise aus verschiedenen Bereichen (wie CPU, GPU und Mikrocontroller). Diese Designs ermöglichen die Bewertung der Auswirkungen des Platzierungsalgorithmus auf das endgültige Design-PPA.
Direkte Verwendung:https://go.hyper.ai/LN4Ab
3. Datensatz menschlicher Gesichter
Der Datensatz enthält ungefähr 9,6.000 Gesichtsbilder, davon 5.000 echte Gesichtsbilder und 4.63.000 KI-generierte Gesichtsbilder.
Direkte Verwendung:https://go.hyper.ai/N5nVT
4. TableBench-Benchmark-Datensatz zur Beantwortung von Tabellenfragen
Der Datensatz enthält 886 Beispiele aus 18 Domänen und soll die Überprüfung von Fakten, das numerische Denken, die Datenanalyse und Visualisierungsaufgaben erleichtern.
Direkte Verwendung:https://go.hyper.ai/Qcs2F
5. Deepfake-Erkennungs-Videoerkennungsdatensatz
Der Datensatz enthält mehr als 363 Originalclips mit 28 Schauspielern in 16 verschiedenen Szenen. Diese hochwertigen Videos bieten eine solide Grundlage für das Training von Modellen anhand realer Inhalte. Neben den Originaldaten enthält der Datensatz auch mehr als 3.000 bearbeitete Videos, die mit der DeepFakes-Methode erstellt wurden.
Direkte Verwendung:https://go.hyper.ai/Jw59B
6. Fahrzeugklassifizierung Fahrzeugbildklassifizierungsdatensatz
Dieser Datensatz ist für die Aufgabe der Fahrzeugklassifizierung konzipiert und enthält 5,6.000 Bilder, die in 7 Kategorien unterteilt sind. Jede Kategorie stellt einen anderen Fahrzeugtyp dar (Autorikscha, Fahrrad, Auto, Motorrad, Flugzeug, Schiff, Zug) und alle Bilder liegen im JPEG-Format mit der Erweiterung .jpg vor. Perfekt zum Erstellen und Testen von Bildklassifizierungsmodellen zur Unterscheidung zwischen verschiedenen Fahrzeugtypen.
Direkte Verwendung:https://go.hyper.ai/e9LNg
7. Erkennung auf Gleisen Datensatz zur Erkennung menschlichen Verhaltens auf Gleisen
Der Datensatz enthält 3.766 Bilder von Menschen auf Bahngleisen mit einer Auflösung von 1.080×1.080. Jedes Bild ist mit Begrenzungsrahmen versehen, die die Anwesenheit von Menschen und ihre Aktionen auf den Gleisen markieren.
Direkte Verwendung:https://go.hyper.ai/dsr49
8. Ref-AVS-Datensatz zur audiovisuellen Szenensegmentierung
Der Ref-AVS-Datensatz ist ein Benchmark für Objektsegmentierungsaufgaben in audiovisuellen Szenen. Der Datensatz enthält 48 Videos von hörbaren Objekten, speziell klassifiziert in: 20 Musikinstrumente, 8 Tiere, 15 Maschinen und 5 Menschen.
Direkte Verwendung:https://go.hyper.ai/pGHwm
9. COSMOS 1050K-Datensatz zur Segmentierung medizinischer Bilder
Der Datensatz umfasst 53 öffentliche medizinische Datensätze, die vom Forschungsteam zusammengestellt wurden und 18 Modalitäten, 84 Objekte, 1050.000 2D-Bilder und 6033 Masken abdecken.
Direkte Verwendung:https://go.hyper.ai/nHETv
10. Enthält 140.000 Bilder! HUST-OBC Oracle-Datensatz verhilft dem Team zum ACL Best Paper Award
Dieser Datensatz ist ein hochwertiger HUST-OBC-Datensatz, der von Wang Pengjie und anderen aus dem Forschungsteam von Professor Bai Xiang an der Huazhong University of Science and Technology vorgeschlagen wurde. Es wird aus drei verschiedenen Quellen gesammelt, darunter Bücher, Websites und vorhandene Datensätze. Der Datensatz enthält zwei Arten von Oracle-Bone-Beispielbildern. Bei einem handelt es sich um die Orakelknochenbilder, die aus den verarbeiteten Scans der originalen Orakelknochenabreibungen gewonnen wurden, und bei dem anderen um die handschriftlichen Orakelknochenbilder, die auf den originalen Orakelknochen basieren, die weiter unterteilt sind in Bilder, die auf Abreibungen basieren, und handschriftliche Bilder, die auf Glyphen basieren.
Direkte Verwendung:https://go.hyper.ai/46AiA
Weitere öffentliche Datensätze finden Sie unter:
Community-Artikel
Das Team der Universität Oxford hat ein medizinisches Bildsegmentierungsmodell namens Medical SAM 2 entwickelt. Das Modell basiert auf dem SAM 2-Framework und behandelt medizinische Bilder wie Videos. Es eignet sich nicht nur gut für die Segmentierung medizinischer 3D-Bilder, sondern bietet auch eine neue Funktion zur Einzeleingabeaufforderungssegmentierung. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Forschungspapiers.
Den vollständigen Bericht ansehen:https://go.hyper.ai/04VFX
In der zweiten Folge der Live-Übertragungsreihe „Meet AI4S“ stellte Li Yuzhe, Postdoktorand im Labor von Zhang Qiangfeng an der School of Life Sciences der Tsinghua-Universität, die neuesten Forschungsergebnisse des Teams unter dem Titel „Exploring AI Applications in Genomics: Taking the Spatial Transcriptome Data Characterization Algorithm SPACE as an Example“ vor. Dieser Artikel ist eine Abschrift seiner Rede, die voller praktischer Informationen ist.
Den vollständigen Bericht ansehen:https://go.hyper.ai/eRQeT
Auf der AI for Bioengineering Summer School erläuterte Professor Hong Liang von der Shanghai Jiao Tong University unter dem Motto „Der Einzug der KI in Leben und Wissenschaft“ auf leicht verständliche Weise die Anwendung von KI in der wissenschaftlichen Forschung, insbesondere im Proteindesign, und gab einen Ausblick auf die zukünftige Entwicklung von KI für die Wissenschaft. Dieser Artikel ist eine Abschrift der wichtigsten Punkte aus der Rede von Professor Hong Liang.
Den vollständigen Bericht ansehen:https://go.hyper.ai/TWBIk
Beliebte Enzyklopädieartikel
1. DALL-E
2. Schnittmenge über Union (IoU)
3. Maskierte Sprachmodellierung (MLM)
4. Neuronales Strahlungsfeld (NeRF)
5. Reziproke Sortierfusion RRF
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
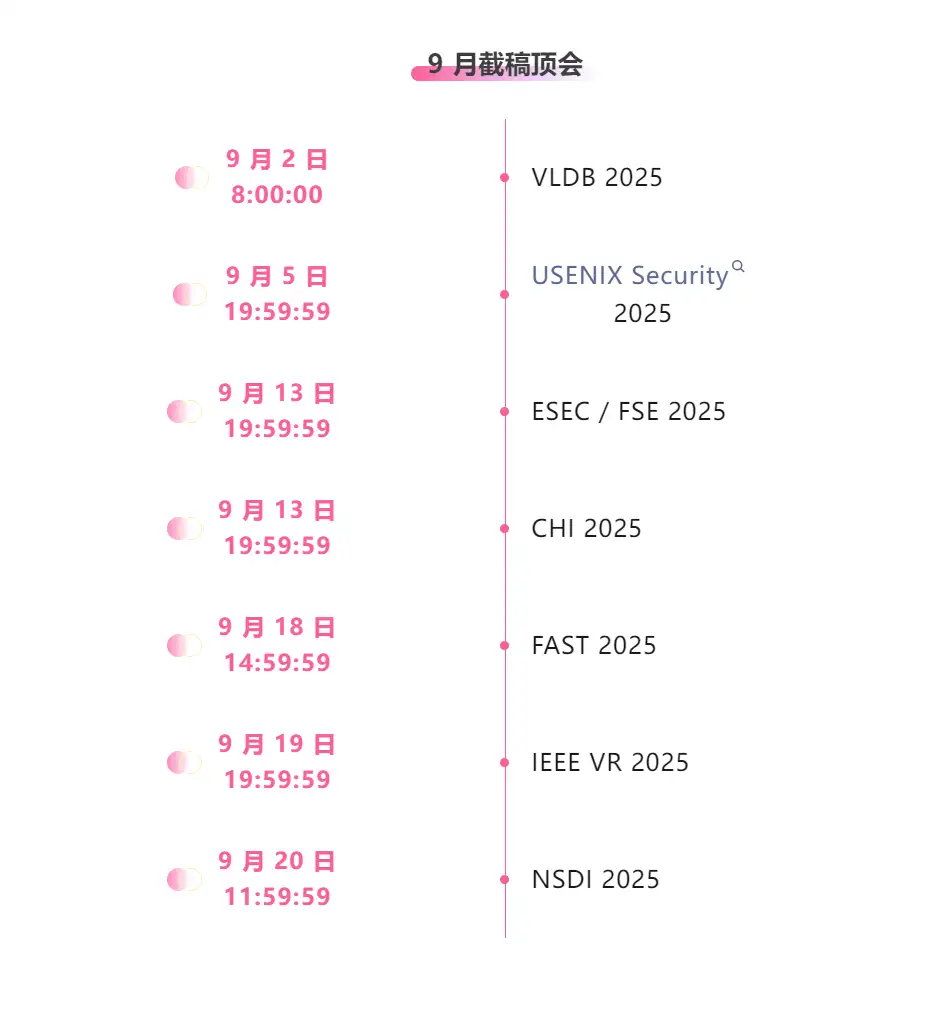
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung inländischer beschleunigter Download-Knoten für über 1300 öffentliche Datensätze
* Enthält über 400 klassische und beliebte Online-Tutorials
* Interpretation von über 100 AI4Science-Papierfällen
* Unterstützt die Suche nach über 500 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








