Command Palette
Search for a command to run...
Laden Sie Meta, Den Größten Datensatz Zur Videosegmentierung, Mit Einem Klick Herunter! Enthält 50,9.000 Videos Aus Der Realen Welt, Die 47 Länder Abdecken

Im April 2023 veröffentlichte Meta das Segment Anything Model (SAM) und behauptete, „alles segmentieren“ zu können. Diese innovative Errungenschaft, die traditionelle Computer Vision (CV)-Aufgaben untergräbt, hat in der Branche breite Diskussionen ausgelöst und wurde schnell in der Forschung in vertikalen Bereichen wie der medizinischen Bildsegmentierung angewendet. Vor Kurzem wurde SAM erneut aktualisiert.Meta hat Segment Anything Model 2 (SAM 2) als Open Source veröffentlicht und damit einen weiteren bahnbrechenden Meilenstein im Bereich der Computer Vision gesetzt.
Von der Bildsegmentierung bis zur Videosegmentierung,SAM 2 zeigt eine überlegene Leistung bei der Echtzeit-Cue-Segmentierung.Das Modell führt die Segmentierungs- und Trackingfunktionen von Bildern und Videos in einem einheitlichen Modell ein. Es kann jedes Objekt in einem Bild oder Video genau identifizieren und segmentieren, indem es einfach eine Eingabeaufforderung (Klick, Kästchen oder Maske) in das Videobild eingibt. Diese einzigartige Zero-Sample-Learning-Fähigkeit verleiht SAM 2 eine extrem hohe Vielseitigkeit.Es weist ein großes Anwendungspotenzial in den Bereichen Medizin, Fernerkundung, autonomes Fahren, Robotik, getarnte Objekterkennung usw. auf. Meta ist zuversichtlich: „Wir glauben, dass unsere Daten, Modelle und Erkenntnisse ein wichtiger Meilenstein in der Videosegmentierung und verwandten Wahrnehmungsaufgaben werden!“
Es stimmt. Sobald SAM 2 auf den Markt kam, konnten es alle kaum erwarten, es zu benutzen, und die Wirkung war unglaublich!

Weniger als zwei Wochen nachdem SAM 2 als Open Source freigegeben wurde, verwendeten Forscher der Universität Toronto es für medizinische Bilder und Videos und veröffentlichten ein Papier!

Originalarbeit:
https://arxiv.org/abs/2408.03322
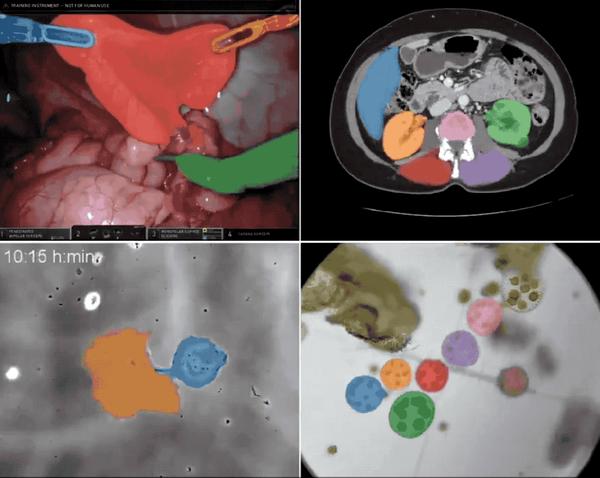
Modelle benötigen Daten zum Trainieren und SAM 2 ist keine Ausnahme. Gleichzeitig hat Meta auch den umfangreichen Datensatz SA-V, der zum Trainieren von SAM 2 verwendet wurde, als Open Source freigegeben.Es wird berichtet, dass dieser Datensatz zum Trainieren, Testen und Bewerten generischer Objektsegmentierungsmodelle verwendet werden kann.HyperAI hat auf seiner offiziellen Website „SA-V: Meta Building the Largest Video Segmentation Dataset“ veröffentlicht, das mit einem Klick heruntergeladen werden kann!
Direkter Download des SA-V-Videosegmentierungsdatensatzes:
https://go.hyper.ai/e1Tth
Weitere hochwertige Datensätze zum Download:
https://go.hyper.ai/P5Mtc
Über vorhandene Datensätze zur Videosegmentierung hinaus! SA-V deckt mehrere Themen und Szenarien ab
Metaforscher haben mithilfe von Data Engine einen großen und vielfältigen Videosegmentierungsdatensatz SA-V gesammelt, wie in der folgenden Tabelle dargestellt.Der Datensatz enthält 50,9K Videos, 642,6K Masklets (191K manuell annotiert mit Hilfe von SAM 2, 452K automatisch generiert von SAM 2),Im Vergleich zu anderen gängigen Datensätzen zur Videoobjektsegmentierung (VOS) hat SA-V die Anzahl der Videos, Masklets und Masken deutlich verbessert.Die Anzahl der annotierten Masken ist 53-mal so hoch wie die aller vorhandenen VOS-Datensätze.Es bietet eine umfangreiche Datenressource für zukünftige Computer Vision-Arbeiten.
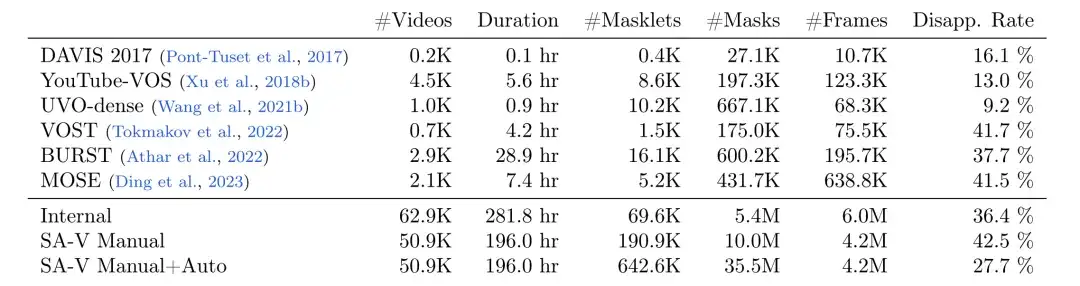
Vergleich der Anzahl der Maskenfragmente, der Anzahl der Masken, der Anzahl der Frames und der Verschwinderate
* Das SA-V-Handbuch enthält nur manuell markierte Etiketten
* SA-V Manual+Auto kombiniert manuell annotierte Beschriftungen mit automatisch generierten Maskensegmenten
Es wird davon ausgegangen, dass die Anzahl der in SA-V enthaltenen Videos den vorhandenen VOS-Datensatz übersteigt und die durchschnittliche Videoauflösung 1401 × 1037 Pixel beträgt.Die gesammelten Videos decken verschiedene Alltagsszenen ab.Einschließlich 54% Videos von Innenaufnahmen und 46% Videos von Außenaufnahmen mit einer durchschnittlichen Länge von 14 Sekunden. Auch,Auch die Themen dieser Videos sind vielfältig.Zu den Masken gehören Orte, Objekte, Szenen usw., von großen Objekten (wie Gebäuden) bis hin zu feinkörnigen Details (wie Innendekoration).
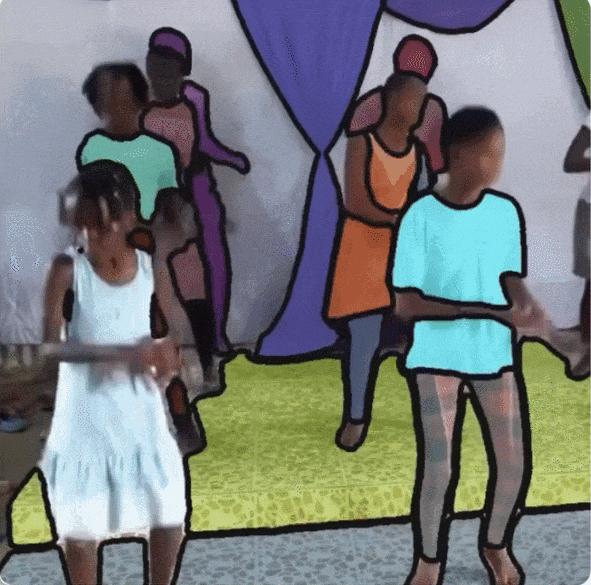
Wie in der Abbildung unten gezeigt,Die Videos in SA-V decken 47 Länder ab.Und von verschiedenen Teilnehmern betrachtet, ist aus Abbildung a ersichtlich, dass im Vergleich zur Maskengrößenverteilung von DAVIS, MOSE und YouTubeVOS der normalisierte Maskenbereich (normalisierte Maskenfläche) von SA-V kleiner als 0,1 88% überschreitet.
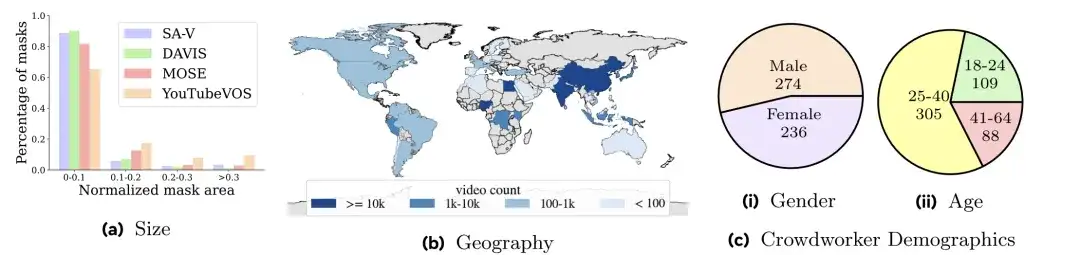
Die Forscher unterteilten den SA-V-Datensatz anhand der Videoautoren und ihrer geografischen Standorte.Stellen Sie sicher, dass sich ähnliche Objekte in den Daten nur minimal überschneiden.Um die SA-V-Validierung und die SA-V-Testsätze zu erstellen, konzentrierten sich die Forscher bei der Auswahl der Videos auf anspruchsvolle Szenen. Dabei mussten die Kommentatoren Objekte identifizieren, die sich schnell bewegen, von anderen Objekten verdeckt werden oder Muster beim Verschwinden/Wiederauftauchen aufweisen. Schließlich gibt es 293 Masklets und 155 Videos im SA-V-Validierungssatz und 278 Masklets und 150 Videos im SA-V-Testsatz. Darüber hinaus nutzten die Forscher intern verfügbare lizenzierte Videodaten, um den Trainingssatz weiter zu erweitern.
Direkter Download des SA-V-Videosegmentierungsdatensatzes:
https://go.hyper.ai/e1Tth
Oben sind die von HyperAI in dieser Ausgabe empfohlenen Datensätze. Wenn Sie hochwertige Datensatzressourcen sehen, können Sie uns gerne eine Nachricht hinterlassen oder einen Artikel einreichen, um uns davon zu berichten!
Weitere hochwertige Datensätze zum Download:
https://go.hyper.ai/P5Mtc








