Command Palette
Search for a command to run...
Der Chinesische Feinabstimmungsdatensatz Von Llama 3.1 Ist Jetzt Online Und Große Modelle Können Mit Einem Klick Bereitgestellt Werden

Der KI-Kreis im Juli war voller kleiner und großer Modelle und es war aufregend! Die meisten Studenten können mit kleinen Modellen wie GPT-4o und Mistral-Nemo umgehen, aber sehr große Modelle wie Llama-3.1-405B und Mistral-Large-2 bereiten vielen Studenten Probleme.
Mach dir keine Sorgen!Auf der offiziellen Website von hyper.ai finden Sie im Tutorial-Bereich Tutorials zum Starten dieser beiden supergroßen Modelle mit „Open WebUI“ und „OpenAI-kompatiblem API-Dienst“!Darüber hinaus ist auch der chinesische Feinabstimmungsdatensatz DPO-zh-en-emoji online. Scrollen Sie nach unten, um den Link zu erhalten~
Vom 5. bis 9. August gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige Tutorial-Auswahl: 5
* Hochwertige öffentliche Datensätze: 10
* Community-Artikelauswahl: 3 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im August: 2
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Tutorials
1. Verwenden Sie Open WebUI, um Mistral Large 2 / Llama 3.1 405B mit einem Klick bereitzustellen
Dieses Tutorial verwendet OpenWebUI, um Mistral Large 2 / Llama 3.1 405B mit einem Klick bereitzustellen. Die entsprechende Umgebung und Konfiguration wurde eingerichtet. Sie müssen den Container nur klonen und starten, um die Inferenz zu erleben.
* Führen Sie die Bereitstellung des Mistral Large 2-Modells online aus:
* Führen Sie die Bereitstellung des Llama 3.1 405B-Modells online aus:
2. Bereitstellung des OpenAI-kompatiblen API-Dienstes Mistral Large 2 / Llama 3.1 405B-Modells mit einem Klick
Dieses Tutorial dient der Bereitstellung von Mistral-Large-Instruct-2407-AWQ mithilfe der OpenAI-kompatiblen API. „OpenAI-kompatible API“ bedeutet, dass Drittanbieterentwickler dasselbe Anforderungs- und Antwortformat wie OpenAI verwenden können, um ähnliche Funktionen in ihre eigenen Anwendungen zu integrieren. Nachdem Sie dieses Tutorial gestartet haben, können Sie in jedem OpenAI-kompatiblen SDK eine Verbindung zu diesem Modell herstellen. Im Vergleich zum vorherigen Tutorial ist es komplizierter und für diejenigen geeignet, die über grundlegende Programmierkenntnisse verfügen.
* Führen Sie die Bereitstellung des Mistral Large 2-Modells online aus:
* Führen Sie die Bereitstellung des Llama 3.1 405B-Modells online aus:
3. Verwenden Sie Gibbs-Diffusion zur blinden Bildentrauschung
GDiff steht für Gibbs-Diffusion, eine bayesianische Blind-Rauschunterdrückungsmethode, die das Problem der nachträglichen Abtastung von Signal- und Rauschparametern löst. Dieses Tutorial ist eine Testmethode basierend auf dem Artikel „Listening to the Noise: Blind Denoising with Gibbs Diffusion“. Sie können die Forschungsergebnisse erleben, indem Sie den Schritten des Tutorials folgen.
Online ausführen:https://go.hyper.ai/y2wIU
Ausgewählte öffentliche Datensätze
1. DPO-zh-en-emoji Emoji-Fragen-Antwort-Datensatz
Dieser Datensatz ist für die Feinabstimmung großer Sprachmodelle konzipiert. Es enthält eine große Menge an Frage-Antwort-Paaren. Zu jeder Frage gibt es zwei Antwortversionen: Chinesisch und Englisch. Die Antworten enthalten auch lustige und humorvolle Elemente, einschließlich der Verwendung von Emojis. Das shareAI-Team hat es verwendet, um das Modell Llama 3.1 8B zu optimieren.
Direkte Verwendung:https://go.hyper.ai/Y90pZ
2. UrbanSARFloods v1 Hochwasserkartierungs-Benchmark-Datensatz
UrbanSARFloods ist ein Datensatz, der sich der Kartierung von Überschwemmungen in städtischen und offenen Gebieten widmet. Er enthält 8.879 Bildausschnitte im Format 512 × 512 Pixel, deckt 807.500 Quadratkilometer ab und erfasst 18 Hochwasserereignisse. Dadurch wird das Problem gelöst, dass städtischen Überschwemmungen in bestehenden groß angelegten SAR-gestützten Hochwasserkartierungsstudien nicht genügend Aufmerksamkeit geschenkt wird.
Direkte Verwendung:https://go.hyper.ai/yOXx7
3. VRSBench – Großer, hochwertiger Benchmark-Datensatz für visuelle Sprache zur Fernerkundung
Der Datensatz ist ein Mehrzweck-Benchmark-Datensatz in visueller Sprache, der für das Verständnis von Fernerkundungsbildern entwickelt wurde. Es enthält 29.614 manuell überprüfte, detailliert beschriftete Bilder, 52.472 Objektreferenzen und 123.221 Frage-Antwort-Paare. Ziel ist es, die Entwicklung allgemeiner, groß angelegter visueller Sprachmodelle für Fernerkundungsbilder voranzutreiben.
Direkte Verwendung:https://go.hyper.ai/O7DtC
4. ATLAS hochauflösender 3D-Charaktertextur-Datensatz
Der vollständige Name dieses Datensatzes lautet „ArTicuLated humAn textureS“ (kurz: ATLAS). Es handelt sich um den größten hochauflösenden (1.024 × 1.024) 3D-Datensatz menschlicher Texturen, der 50.000 hochpräzise Texturen mit Textbeschreibungen enthält. Die relevanten Papierergebnisse wurden für ECCV 2024 ausgewählt.
Direkte Verwendung:https://go.hyper.ai/Zx1nj
5. MIND Microsoft News-Datensatz
MIND enthält ungefähr 160.000 englische Nachrichtenartikel und mehr als 15 Millionen Impression-Protokolle von 1 Million Benutzern, die aus anonymen Verhaltensprotokollen der Microsoft News-Website gesammelt wurden. Es soll als Benchmark-Datensatz für Nachrichtenempfehlungen dienen und die Forschung im Bereich Nachrichtenempfehlungen und Empfehlungssysteme fördern.
Direkte Verwendung:https://go.hyper.ai/lVOyX
6. BoWFire-Datensatz zur Branderkennungssegmentierung
Der BoWFire-Datensatz ist ein Bilddatensatz speziell für die Flammenerkennung, der die Genauigkeit der Branderkennung verbessern und Fehlalarme reduzieren soll. Der Datensatz enthält Brandbilder aus verschiedenen Notfallsituationen, beispielsweise Gebäudebrände, Industriebrände, Autounfälle und Unruhen.
Direkte Verwendung:https://go.hyper.ai/73AYY
7. CNN/DailyMail-Nachrichtenartikeldatensatz
Der Datensatz enthält mehr als 300.000 Nachrichtenartikel von Journalisten von CNN und Daily Mail und soll bei der Entwicklung von Modellen helfen, die lange Textabsätze in ein oder zwei Sätzen zusammenfassen können.
Direkte Verwendung:https://go.hyper.ai/AbidL
8. Doodle-Datensatz Doodle-Bilddatensatz
Der Datensatz enthält mehr als 1 Million Bilder aus 340 Graffiti-Kategorien, die für maschinelle Lernaufgaben verarbeitet werden können.
Direkte Verwendung:https://go.hyper.ai/Ns4M4
9. Yoga-16 Menschlicher Yoga-Aktionsbilddatensatz
Der Yoga-16-Datensatz zielt darauf ab, die Klassifizierungsgenauigkeit von Modellen zur Erkennung von Yoga-Stellungen zu verbessern. Es ist in drei Hauptverzeichnisse unterteilt: Training, Test und Validierung, von denen jedes 16 Unterverzeichnisse enthält, die 16 verschiedenen Yoga-Stellungen entsprechen.
Direkte Verwendung:https://go.hyper.ai/iMe0Z
10. Datensatz mit Bildern von Menschen Datensatz mit Bildern von Männern und Frauen
Der Datensatz enthält zwei Bildordner für Personenkategorien: männlich und weiblich. Die Bilder umfassen Gesichter, Oberkörper und ganze Körper. Es kann für verschiedene Projekte wie Geschlechtserkennung, Personenidentifikation und Bildklassifizierung verwendet werden.
Direkte Verwendung:https://go.hyper.ai/6UJb7
Weitere öffentliche Datensätze finden Sie unter:
https://hyper.ai/datasets
Community-Artikel
Zur zweiten Folge der Live-Übertragungsreihe „Meet AI4S“ war Li Yuzhe eingeladen, ein Postdoktorand im Labor von Zhang Qiangfeng an der Tsinghua-Universität. Am 21. August wird Dr. Li Yuzhe in Form einer Online-Liveübertragung die KI-Methoden in der räumlichen Transkriptomik und Einzelzell-Omics-Forschung mit allen teilen.
Ereignisdetails anzeigen:https://go.hyper.ai/GIzpo
Google Research und MIT haben sich zusammengetan, um den IJCAI 2024 Best Paper Award zu gewinnen! Antworten Sie auf IJCAI 2024 im offiziellen WeChat-Konto, um die Sammlung des IJCAI 2024 Best Paper Award, Outstanding Paper Award, AIJ Classic Paper Award und Outstanding Paper Award zu erhalten.
Den vollständigen Bericht ansehen:https://go.hyper.ai/ZGzI2
Das Team unter der Leitung von Professor Huang Tianyin, Prorektor und Direktor der medizinischen Fakultät der Tsinghua-Universität, das Team unter der Leitung von Professor Sheng Bin vom Institut für Informatik der Fakultät für Elektrotechnik der Shanghai Jiao Tong University/Schlüssellabor für künstliche Intelligenz des Bildungsministeriums, das Team unter der Leitung von Professor Jia Weiping und Professor Li Huating vom Sechsten Volkskrankenhaus der medizinischen Fakultät der Shanghai Jiao Tong University und das Team unter der Leitung von Professor Qin Yuzong von der National University of Singapore und dem Singapore National Eye Centre arbeiteten zusammen, um erfolgreich das weltweit erste integrierte Vision-Large-Language-Modellsystem DeepDR-LLM für die Diagnose und Behandlung von Diabetes zu entwickeln. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/qnzSp
Beliebte Enzyklopädieartikel
1. Schnittmenge über Union (IoU)
2. Reziproke Sortierfusion RRF
3. Kontrastives Lernen
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Lang- und Kurzzeitgedächtnis Langzeit-Kurzzeitgedächtnis
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
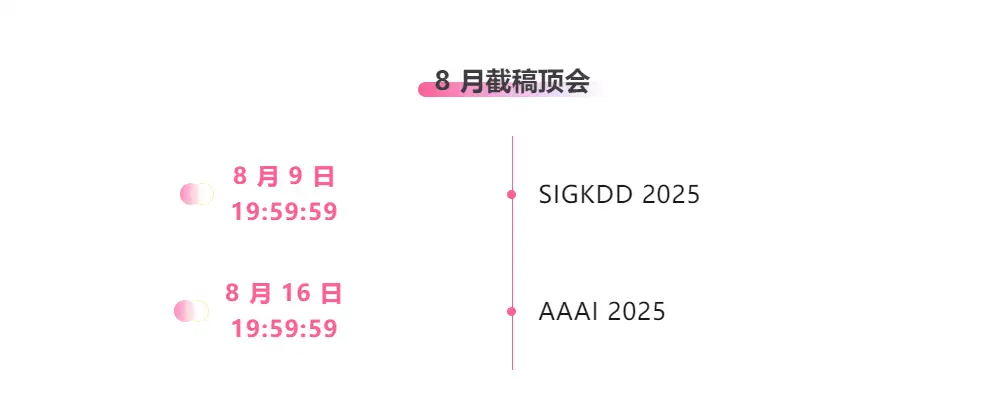
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung inländischer beschleunigter Download-Knoten für über 1300 öffentliche Datensätze
* Enthält über 400 klassische und beliebte Online-Tutorials
* Interpretation von über 100 AI4Science-Papierfällen
* Unterstützt die Suche nach über 500 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








