Command Palette
Search for a command to run...
Online-Tutorial: Bereitstellung Großer Modelle Ohne Druck! Ein-Klick-Bedienung Von Llama 3.1 405B Und Mistral Large 2

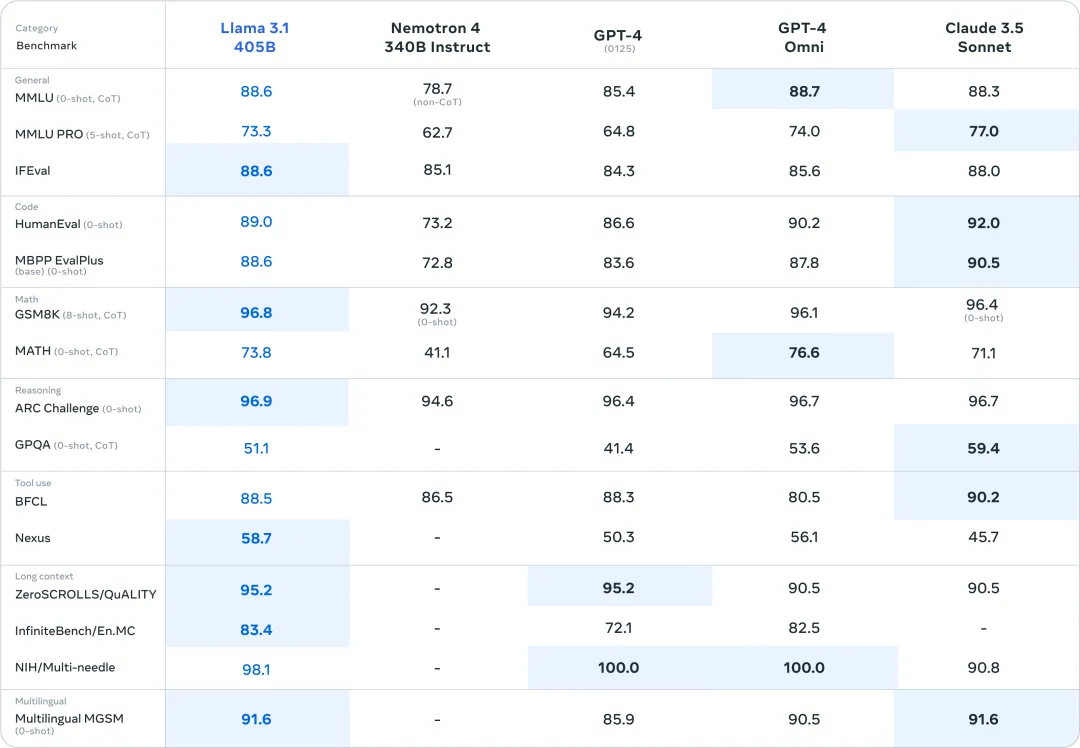
Am 23. Juli Ortszeit hat Meta Llama 3.1 offiziell veröffentlicht. Die übergroße 405B-Parameterversion eröffnete den Höhepunkt des Open-Source-Modells deutlich. In mehreren Benchmarktests konnte es mit seiner Leistung mit den bestehenden SOTA-Modellen GPT-4o und Claude 3.5 Sonnet mithalten oder sie sogar übertreffen.
Am Tag der Veröffentlichung von Llama 3.1 schrieb Zuckerberg außerdem einen langen Artikel mit dem Titel „Open Source AI is the Way Forward“ (Open Source-KI ist der Weg nach vorn), in dem er sagte, dass Llama 3.1 einen Wendepunkt für die Branche darstellen werde. Gleichzeitig möchte die Branche die leistungsstarken Funktionen von Llama 3.1 unbedingt ausprobieren und ist andererseits auch gespannt auf die Reaktion großer Closed-Source-Modelle.
Interessanterweise brachte Mistral AI Mistral Large 2 auf den Markt, als Llama 3.1 gerade um den Thron wetteiferte, um das Modell 405B direkt zu konfrontieren und wies auf seine Schwachstelle hin: Schwierigkeiten bei der Bereitstellung.
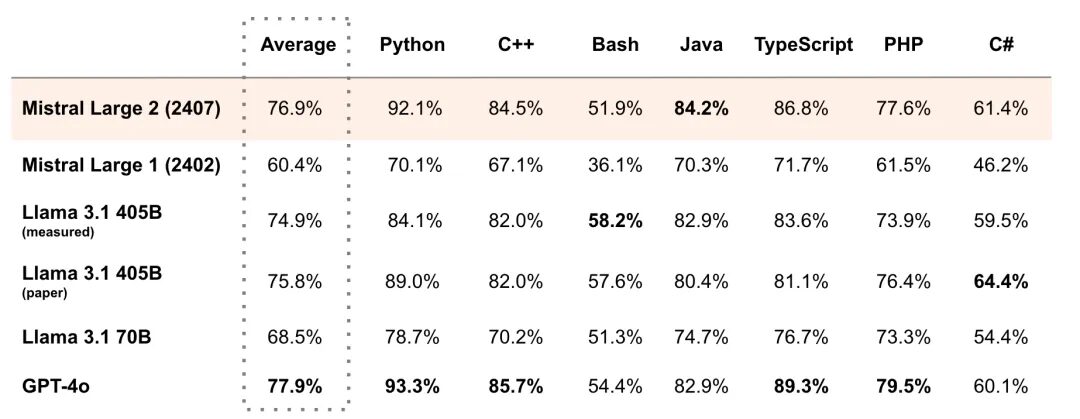
Es besteht kein Zweifel, dass die von der 405B-Parameterskala geforderten Hardwarefunktionen keine Schwelle darstellen, die von einzelnen Entwicklern leicht überschritten werden kann, und die meisten Enthusiasten können dem nur zögernd zusehen. Das Modell Mistral Large 2 verfügt nur über 123B-Parameter, also weniger als ein Drittel der 405B von Llama 3.1, und auch die Einsatzschwelle ist entsprechend niedriger, aber die Leistung kann mit der von Llama 3.1 mithalten.
Beispielsweise übertraf Mistral Large 2 im Benchmarktest für mehrere Programmiersprachen MultiPL-E mit seiner Durchschnittspunktzahl Llama 3.1 (405 B) und lag 11 TP3 T hinter GPT-4o. Es hat Llama 3.1 405B in Python, C++, Java usw. übertroffen. Wie es in der offiziellen Erklärung heißt, eröffnet Mistral Large 2 neue Grenzen im Leistungs-/Servicekosten-Verhältnis von Bewertungsmetriken.
Auf der einen Seite steht die aktuelle „Obergrenze“ der Parameterskala des Open-Source-Modells, auf der anderen Seite steht der Marktführer der neuen Open-Source-Ära mit extrem hoher „Kosteneffizienz“. Ich glaube, das möchte sich niemand entgehen lassen! Keine Sorge, HyperAI hat ein Ein-Klick-Bereitstellungstutorial für Llama 3.1 405B und Mistral Large 2407 veröffentlicht. Sie müssen keine Befehle eingeben, klicken Sie einfach auf „Klonen“, um es auszuprobieren.
* Verwenden Sie Open WebUI, um das Llama 3.1 405B-Modell mit einem Klick bereitzustellen:
* Verwenden Sie Open WebUI, um Mistral Large 2407 123B mit einem Klick bereitzustellen:
Gleichzeitig haben wir auch fortgeschrittene Tutorials vorbereitet, die Sie je nach Bedarf auswählen können:
* Bereitstellung des OpenAI-kompatiblen API-Dienstes für Llama 3.1 405B-Modell mit einem Klick:
* Ein-Klick-Bereitstellung des OpenAI-kompatiblen API-Dienstes des Modells Mistral Large 2407 123B:
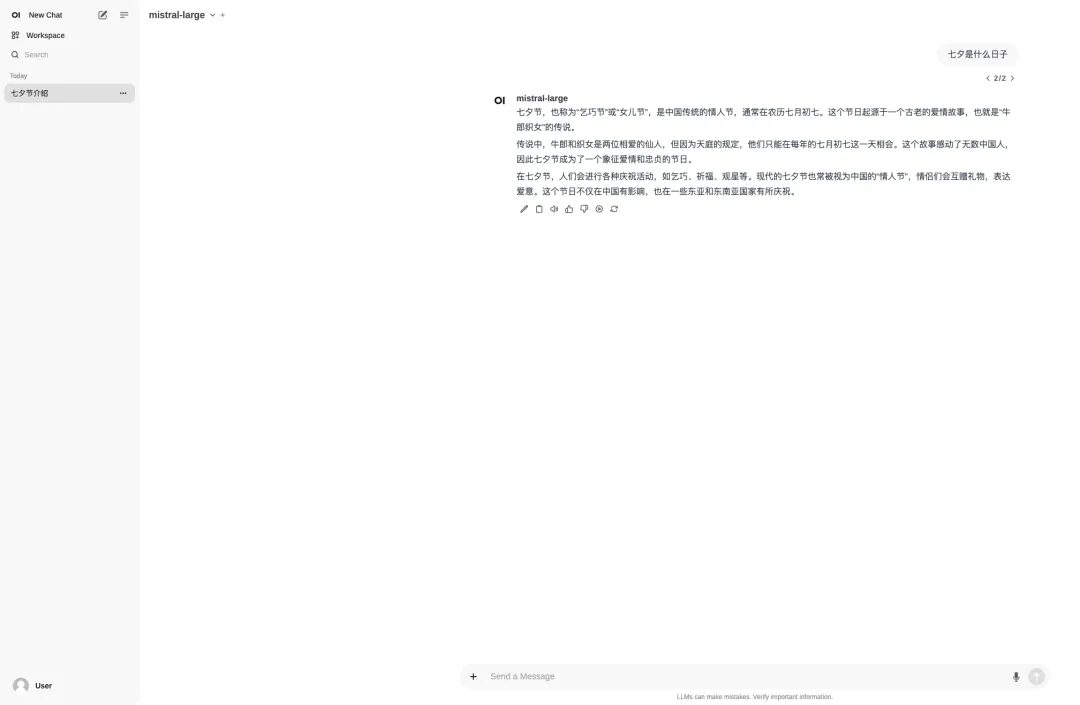
Ich habe Open WebUI verwendet, um Mistral Large 2407 123B mit einem Klick bereitzustellen und einen Test durchzuführen. Bei den großen Modellen scheiterte häufig das Problem „9,9 oder 9,11, was ist größer“, und auch Mistral Large 2 war vor diesem Problem nicht gefeit:

Interessierte Freunde, kommt und erlebt es, das ausführliche Tutorial ist wie folgt ⬇️
Demolauf
In diesem Text-Tutorial werden die einzelnen Arbeitsschritte anhand der Beispiele „Verwenden Sie Open WebUI, um Mistral Large 2407 123B mit einem Klick bereitzustellen“ und „Bereitstellen Sie den OpenAI-kompatiblen API-Dienst des Modells Llama 3.1 405B mit einem Klick bereit“ erläutert.
Verwenden Sie Open WebUI, um Mistral Large 2407 123B mit einem Klick bereitzustellen
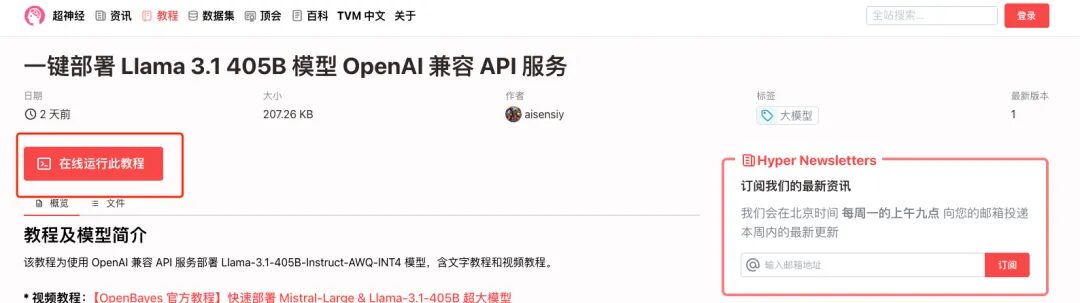
1. Melden Sie sich bei hyper.ai an, wählen Sie auf der Tutorial-Seite „Mistral Large 2407 123B mit Open WebUI bereitstellen“ und klicken Sie auf „Dieses Tutorial online ausführen“.
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
3. Klicken Sie unten rechts auf „Weiter: Hashrate auswählen“.
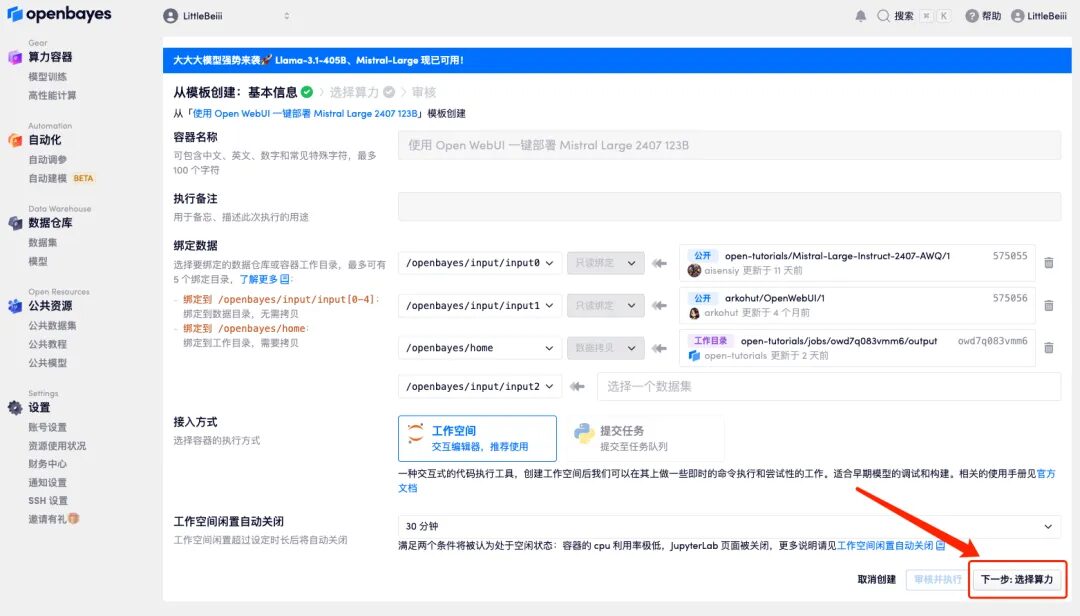
4. Wählen Sie nach dem Seitensprung das Bild „NVIDIA RTX A6000-2“ und „vllm“ aus und klicken Sie auf „Weiter: Überprüfen“.Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit zu erhalten!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
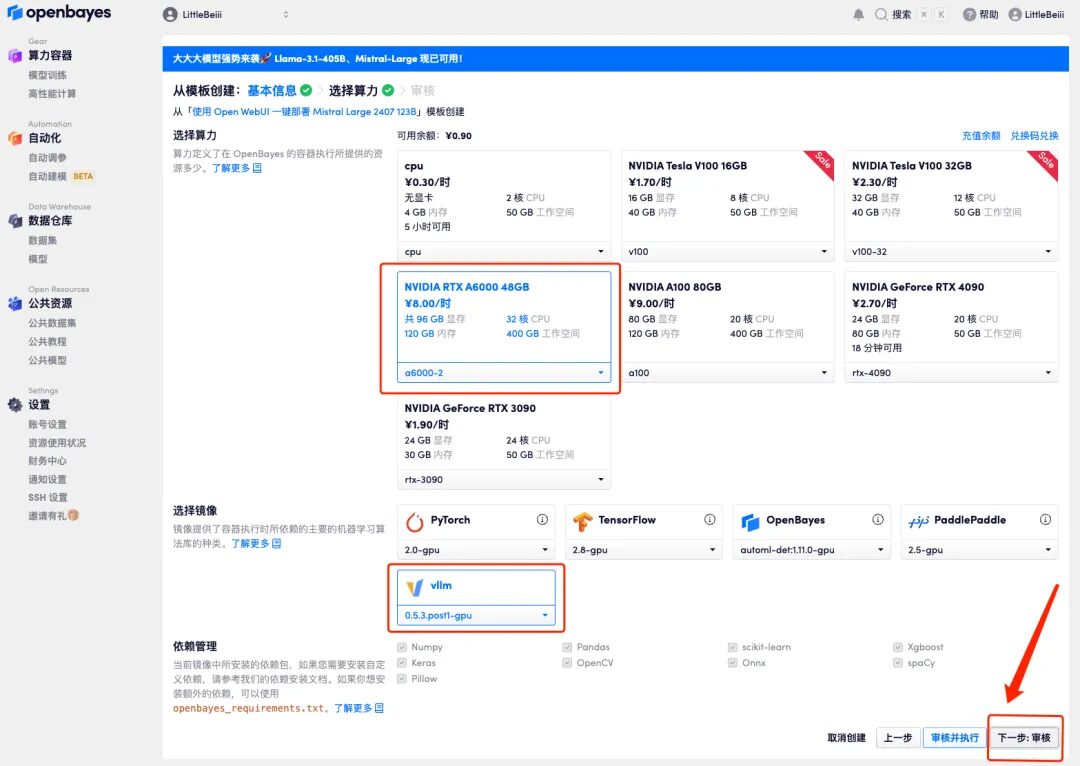
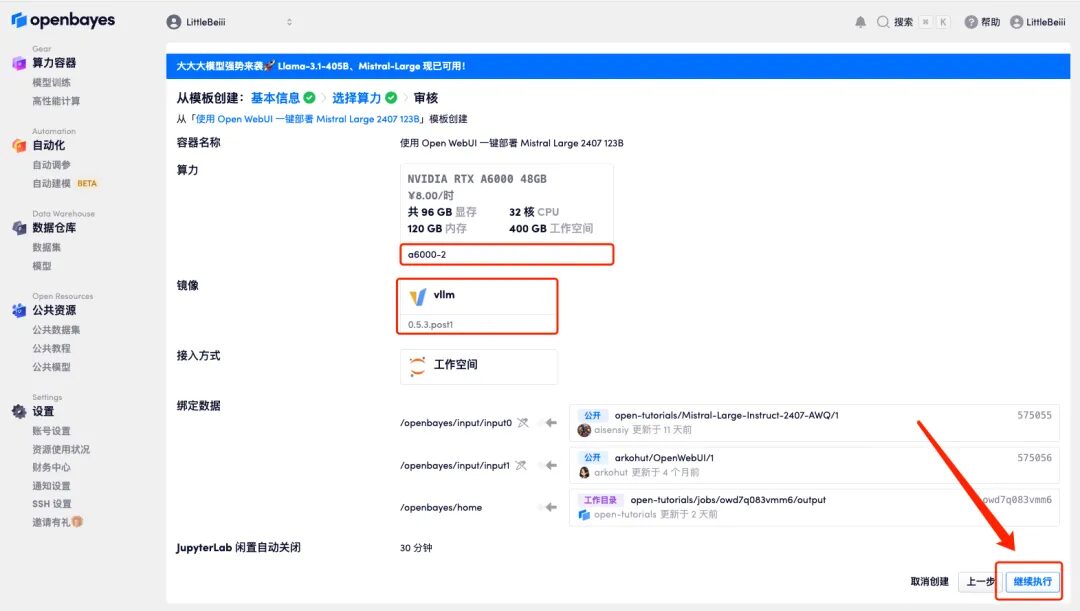
5. Klicken Sie nach der Bestätigung auf „Weiter“ und warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 2 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen.Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
Wenn das Problem länger als 10 Minuten besteht und sich das System immer noch im Status „Ressourcen werden zugewiesen“ befindet, versuchen Sie, den Container zu stoppen und neu zu starten. Wenn das Problem durch einen Neustart immer noch nicht behoben wird, wenden Sie sich bitte an den Kundenservice der Plattform auf der offiziellen Website.
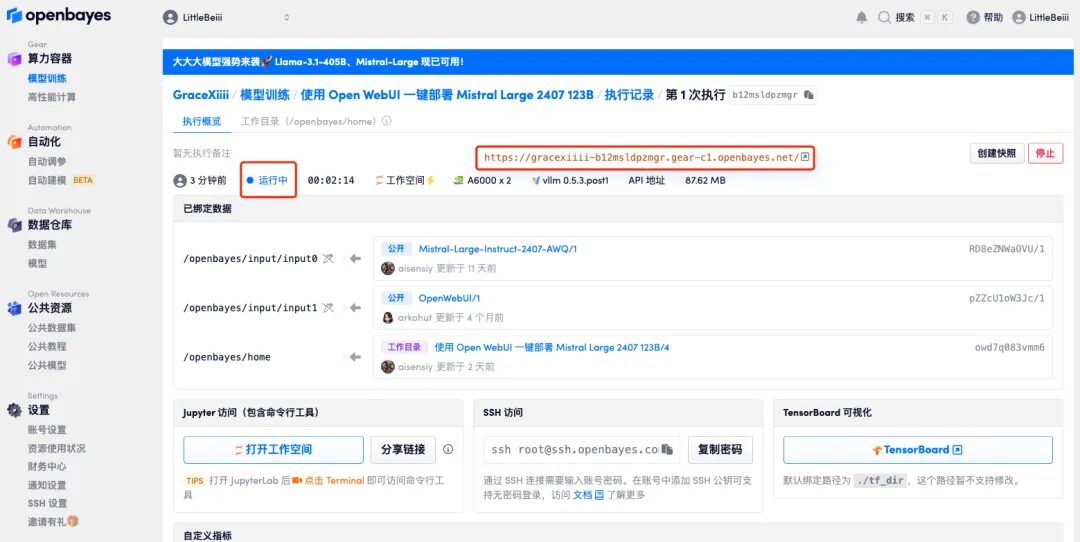
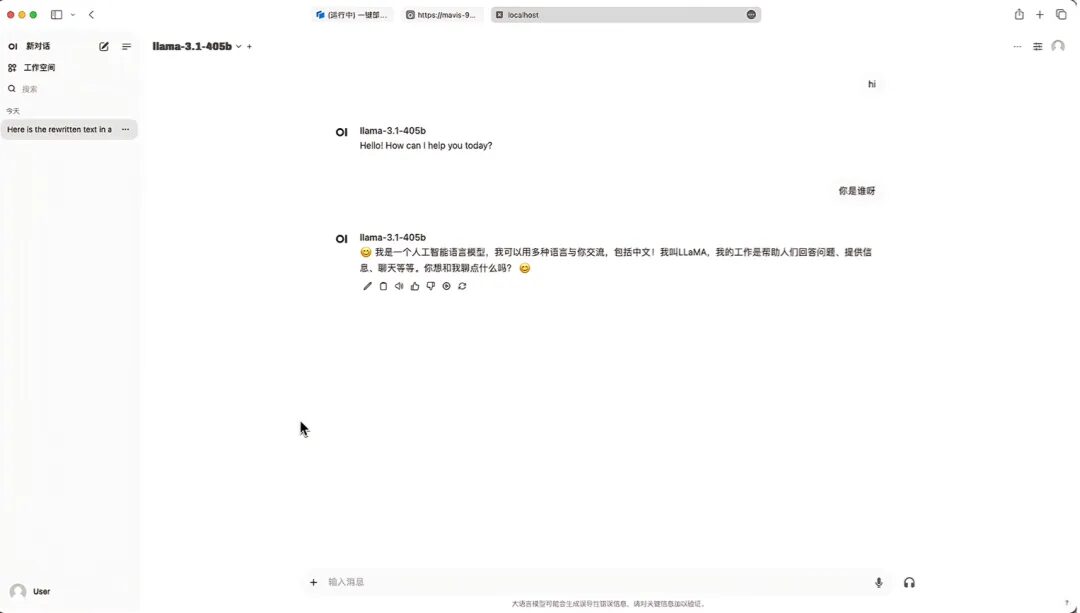
6. Nach dem Öffnen der Demo können Sie sofort mit dem Gespräch beginnen.
Bereitstellung des OpenAI-kompatiblen API-Dienstes Llama 3.1 405B-Modells mit nur einem Klick
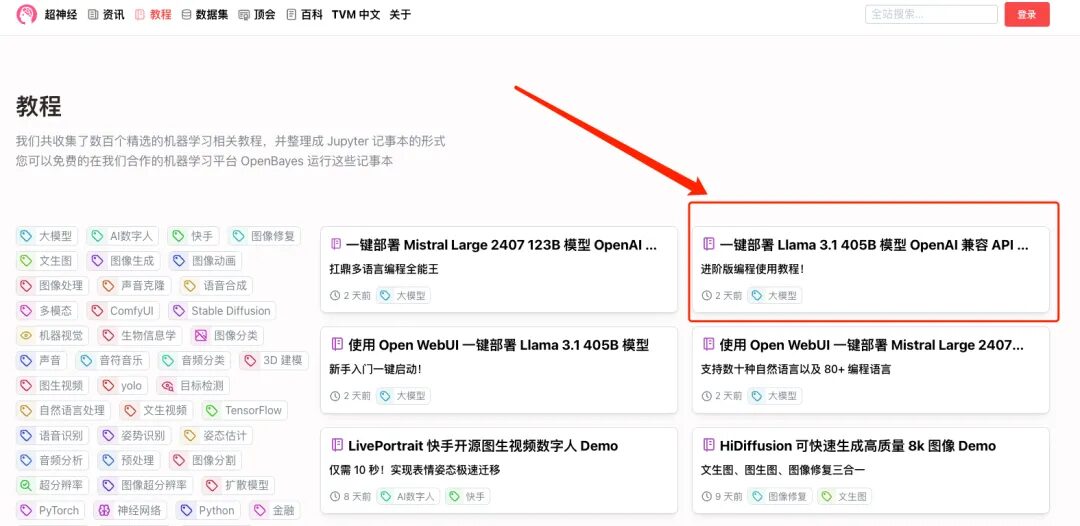
1. Wenn Sie einen OpenAI-kompatiblen API-Dienst bereitstellen möchten, wählen Sie auf der Lernprogrammoberfläche „Ein-Klick-Bereitstellung des OpenAI-kompatiblen API-Dienstes des Modells Llama 3.1 405B“ aus. Klicken Sie auf „Lernprogramm online ausführen“
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
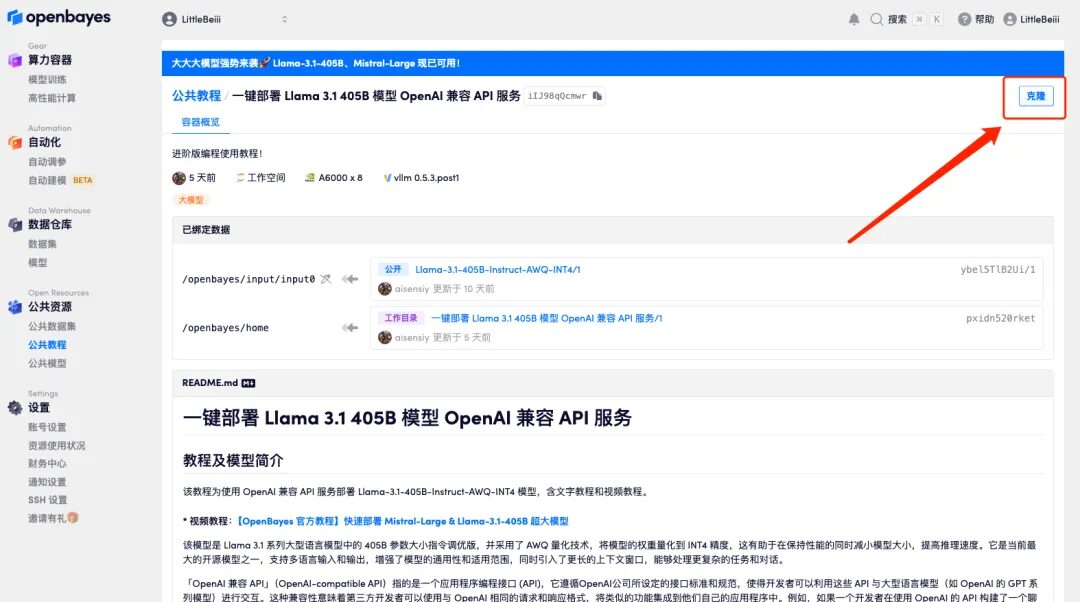
3. Klicken Sie unten rechts auf „Weiter: Hashrate auswählen“.
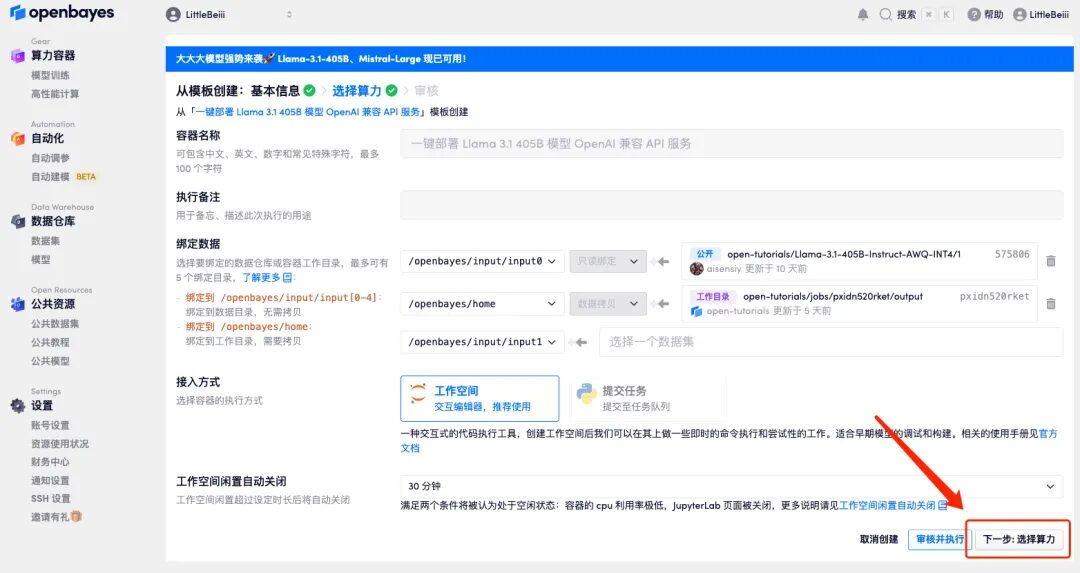
4. Nach dem Seitensprung muss aufgrund der Größe des Modells die Rechenressource „NVIDIA RTX A6000-8“ ausgewählt werden, und das Bild wählt weiterhin „vllm“ aus. Klicken Sie auf „Weiter: Überprüfen“.
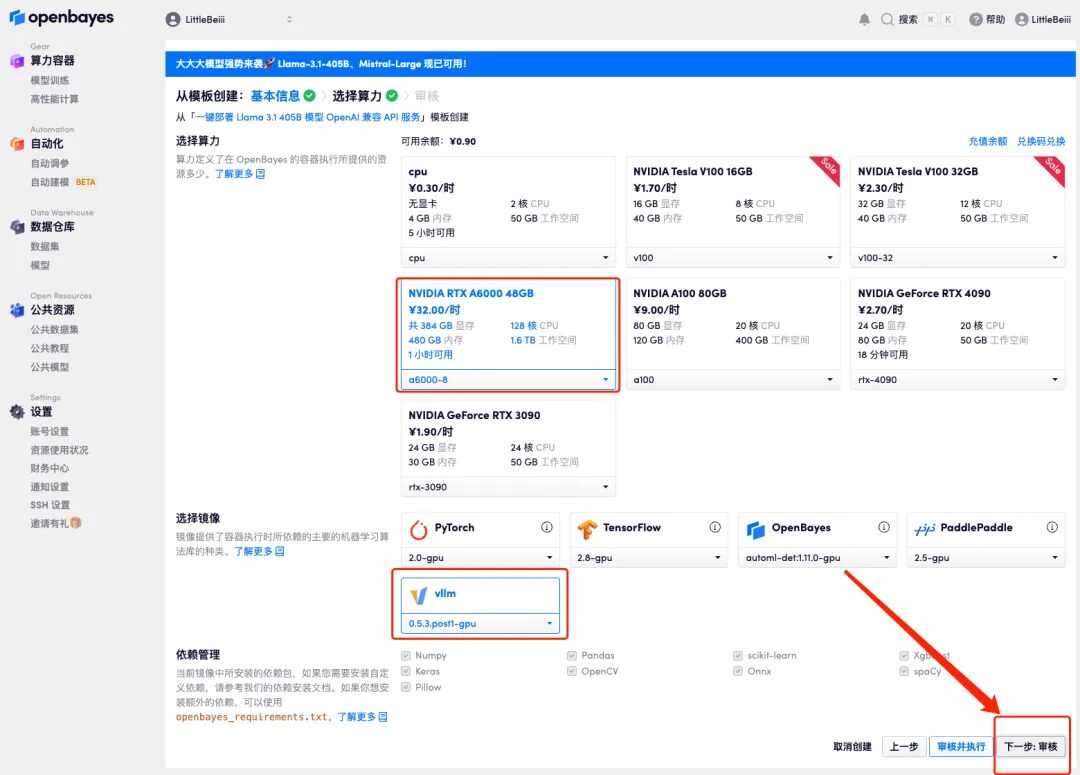
5. Klicken Sie nach der Bestätigung auf „Weiter“ und warten Sie, bis die Ressourcen zugewiesen wurden. Das erste Klonen dauert etwa 6 Minuten. Nachdem der Status als „Läuft“ angezeigt wird, beginnt das Modell automatisch mit dem Laden.
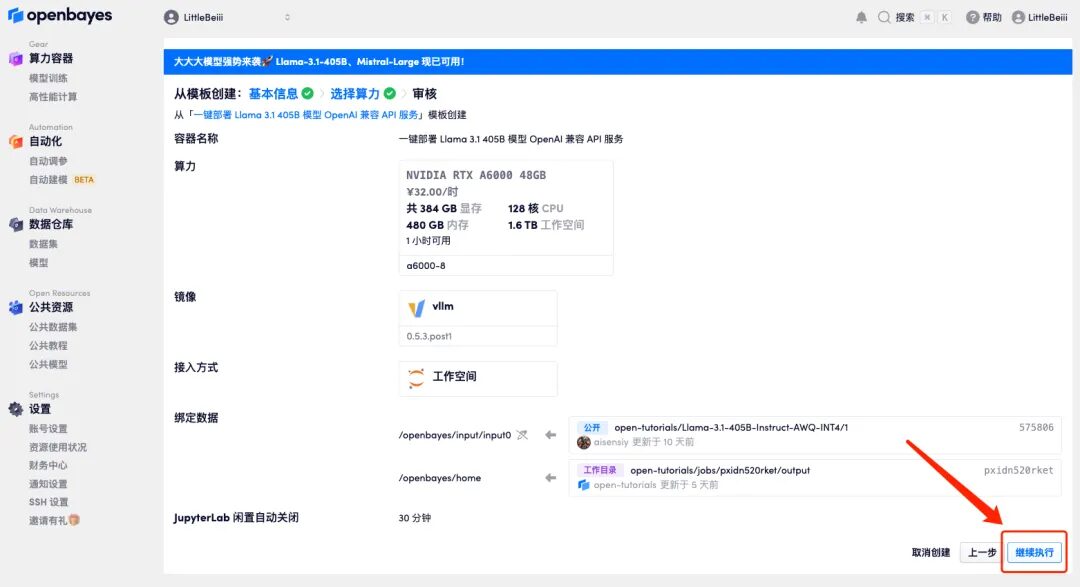
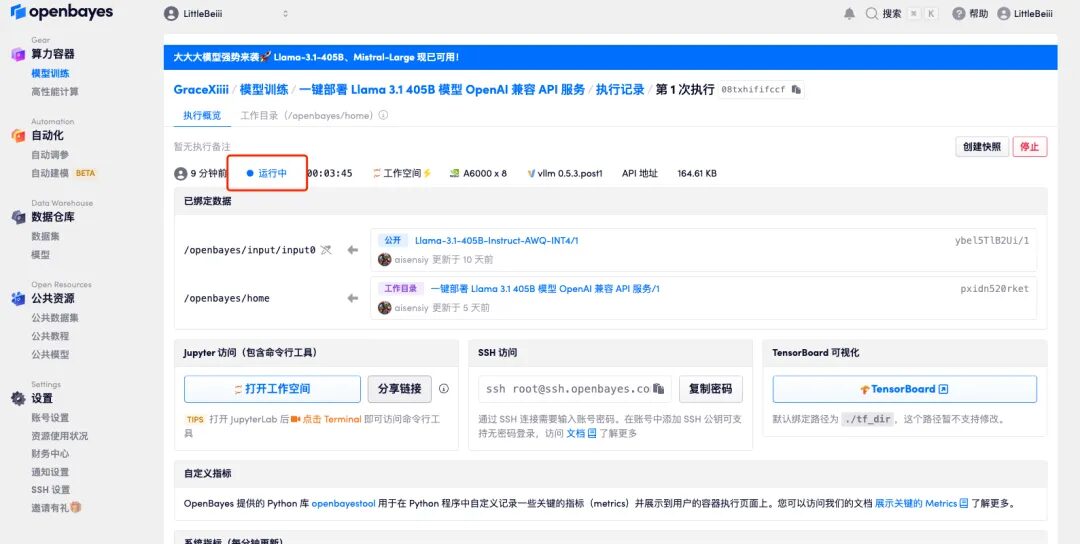
6. Scrollen Sie zum Ende der Seite. Wenn das Protokoll die folgenden Routing-Informationen anzeigt, bedeutet dies, dass der Dienst erfolgreich gestartet wurde. Öffnen Sie die API-Adresse.
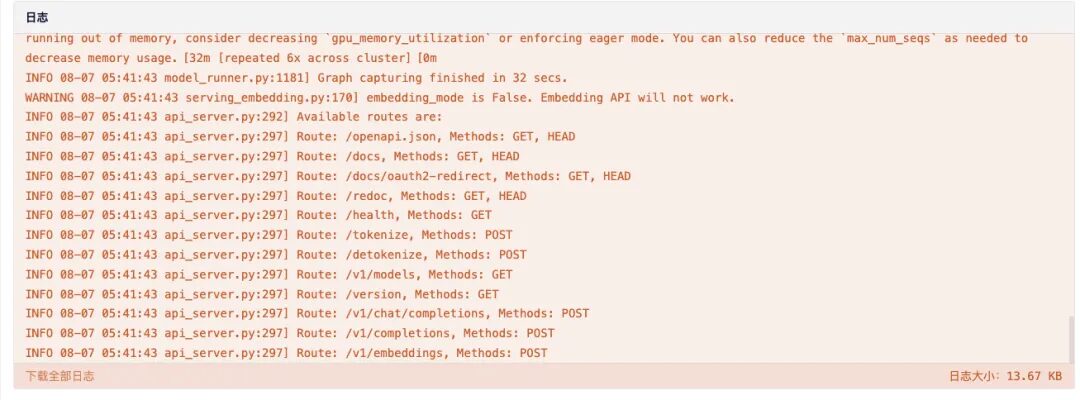
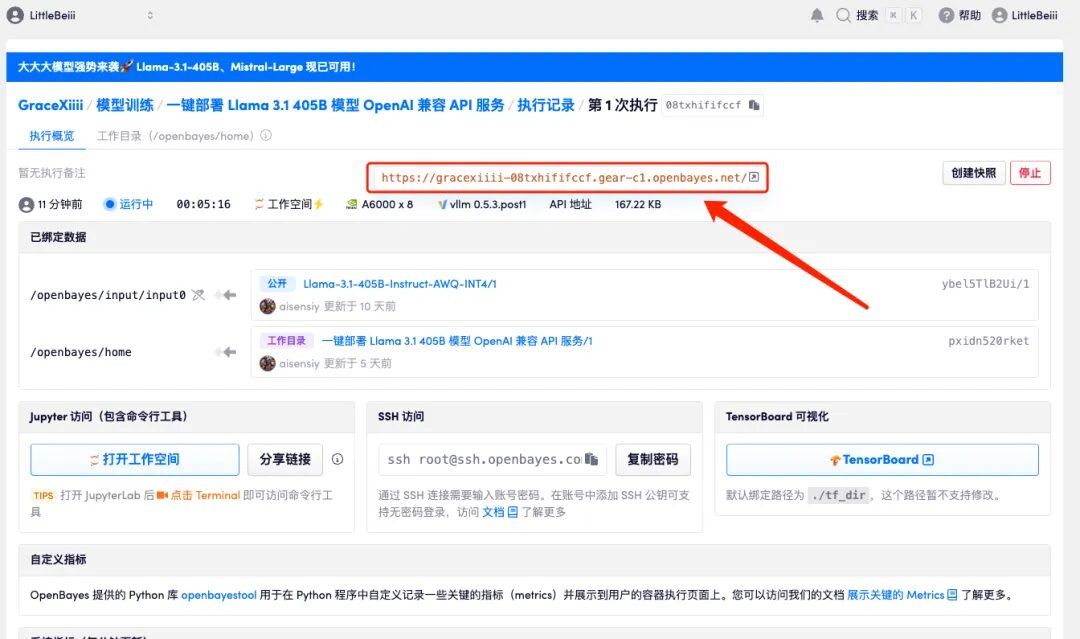
7. Nach dem Öffnen werden standardmäßig die 404-Informationen angezeigt. Wenn Sie im roten Feld einen zusätzlichen Parameter „/v1/models“ hinzufügen, werden die Bereitstellungsinformationen des aktuellen Modells angezeigt.




8. Starten Sie lokal einen Open WebUI-Dienst, starten Sie eine zusätzliche Verbindung in „Externe Verbindung“, geben Sie die vorherige API-Adresse in „OpenAPI“ ein und fügen Sie „/v1“ hinzu. Hier ist kein „API-Schlüssel“ festgelegt, geben Sie ihn einfach selbst ein. Klicken Sie unten rechts auf „Speichern“.
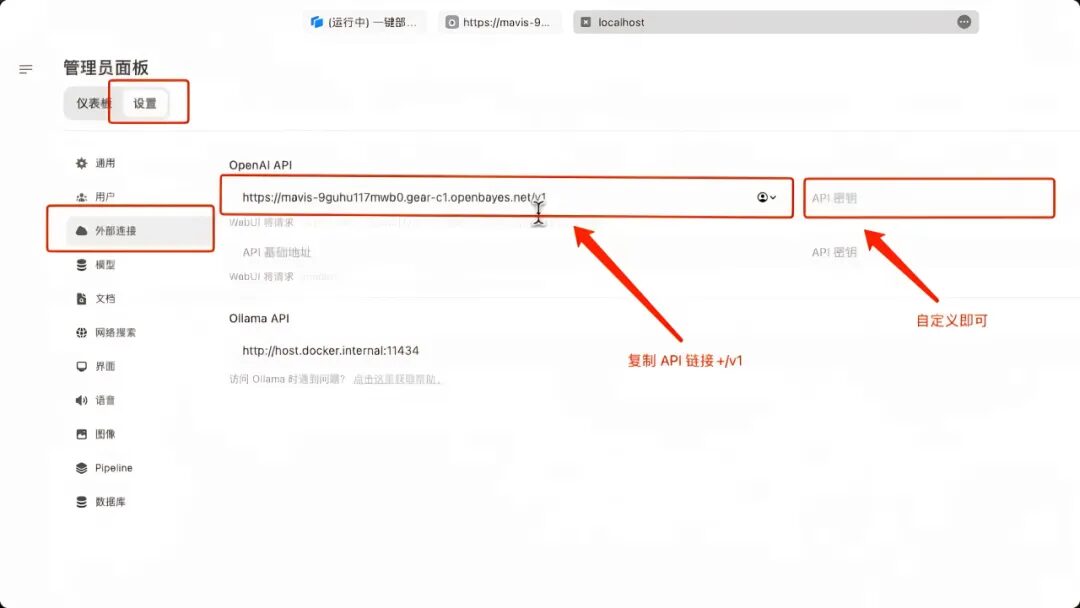
9. Nach dem Speichern wird Llama-3.1-405B unter „Modell auswählen“ angezeigt. Nach der Modellauswahl können Sie das Gespräch beginnen!
Abschließend empfehle ich eine Online-Aktivität zum wissenschaftlichen Austausch. Interessierte Freunde können den QR-Code scannen, um teilzunehmen!









