Command Palette
Search for a command to run...
Der Neue Biologie-Benchmark-Datensatz LAB-Bench Ist Jetzt Open Source! Deckt 8 Hauptaufgaben Ab, Über 2,4.000 Multiple-Choice-Fragen

Wenn ein ausländischer Freund Sie mit „Wie geht es Ihnen?“ begrüßt, was ist Ihre erste Reaktion?
Ist es nicht das klassische „Mir geht’s gut. Danke. Und dir.“?
Genau genommen,Diese Art der lehrbuchmäßigen Frage-und-Antwort-Methode gibt es nicht nur beim Englischlernen und in der Kommunikation, sondern auch beim Trainieren und Testen großer Sprachmodelle.
Heutzutage ist die Verwendung großer Sprachmodelle (LLMs) und LLM-erweiterter Systeme in der Forschung in Bereichen wie Biologie, Meereswissenschaften und Materialwissenschaften zur Verbesserung der Effizienz und Leistung wissenschaftlicher Forschung zu einem zentralen Anliegen vieler Wissenschaftler geworden. Zum Beispiel,Das Team der Zhejiang-Universität hat das große Sprachmodell OceanGPT im Bereich Ozeane eingeführt.Microsoft hat das große Sprachmodell BioGPT im Bereich der Biomedizin entwickelt, und die Shanghai Jiao Tong University hat das große Sprachmodell K2 im Bereich der Geowissenschaften vorgeschlagen.
Es ist erwähnenswert, dassDa LLMs im wissenschaftlichen Forschungsbereich immer beliebter werden, ist es von entscheidender Bedeutung, eine Reihe hochwertiger und professioneller Bewertungsmaßstäbe festzulegen.
Es gibt jedoch viele Benchmarks, die sich auf die Bewertung des Wissens und der Denkfähigkeit von LLMs bei wissenschaftlichen Lehrbuchproblemen konzentrieren.Es ist schwer zu beurteilen Die Durchführung von LLM in praktischen wissenschaftlichen Forschungsaufgaben wie Literaturrecherche, Programmplanung und Datenanalyse,Daraus resultieren deutliche Defizite des Modells hinsichtlich Flexibilität und Professionalität bei der Bearbeitung konkreter wissenschaftlicher Aufgaben.
Um die effektive Entwicklung von KI-Systemen in der Biologie zu fördern,Forscher von FutureHouse Inc. haben den Datensatz Language Agent Biology Benchmark (LAB-Bench) veröffentlicht.LAB-Bench enthält mehr als 2.400 Multiple-Choice-Fragen zur Bewertung der Leistung von KI-Systemen in der tatsächlichen biologischen Forschung, wie z. B. Literaturrecherche und -schlussfolgerung (LitQA2 und SuppQA), grafische Interpretation (FigQA), Tabelleninterpretation (TableQA), Datenbankzugriff (DbQA), Protokollerstellung (ProtocolQA), Verständnis und Verarbeitung von DNA- und Proteinsequenzen (SeqQA) und Klonierungsszenarien (CloningScenarios).
Die Forschung mit dem Titel „LAB-Bench Measuring Capabilities of Language Models for Biology Research“ wurde bei der Top-Konferenz NeurlPS 2024 eingereicht.
* LAB Bench Sprachmodell Biologie Benchmark-Datensatz:
https://go.hyper.ai/kMe1e
Samuel G. Rodriques, der korrespondierende Autor des Artikels, betonte:Als erstes Evaluierungsset, das sich auf die Bewertung konzentriert, ob Modelle und Agenten wissenschaftliche Forschung betreiben können, verwendet LAB-Bench eine programmatische Evaluierungsmethode für komplexe Aufgaben, die in Zukunft sehr wichtig sein wird.
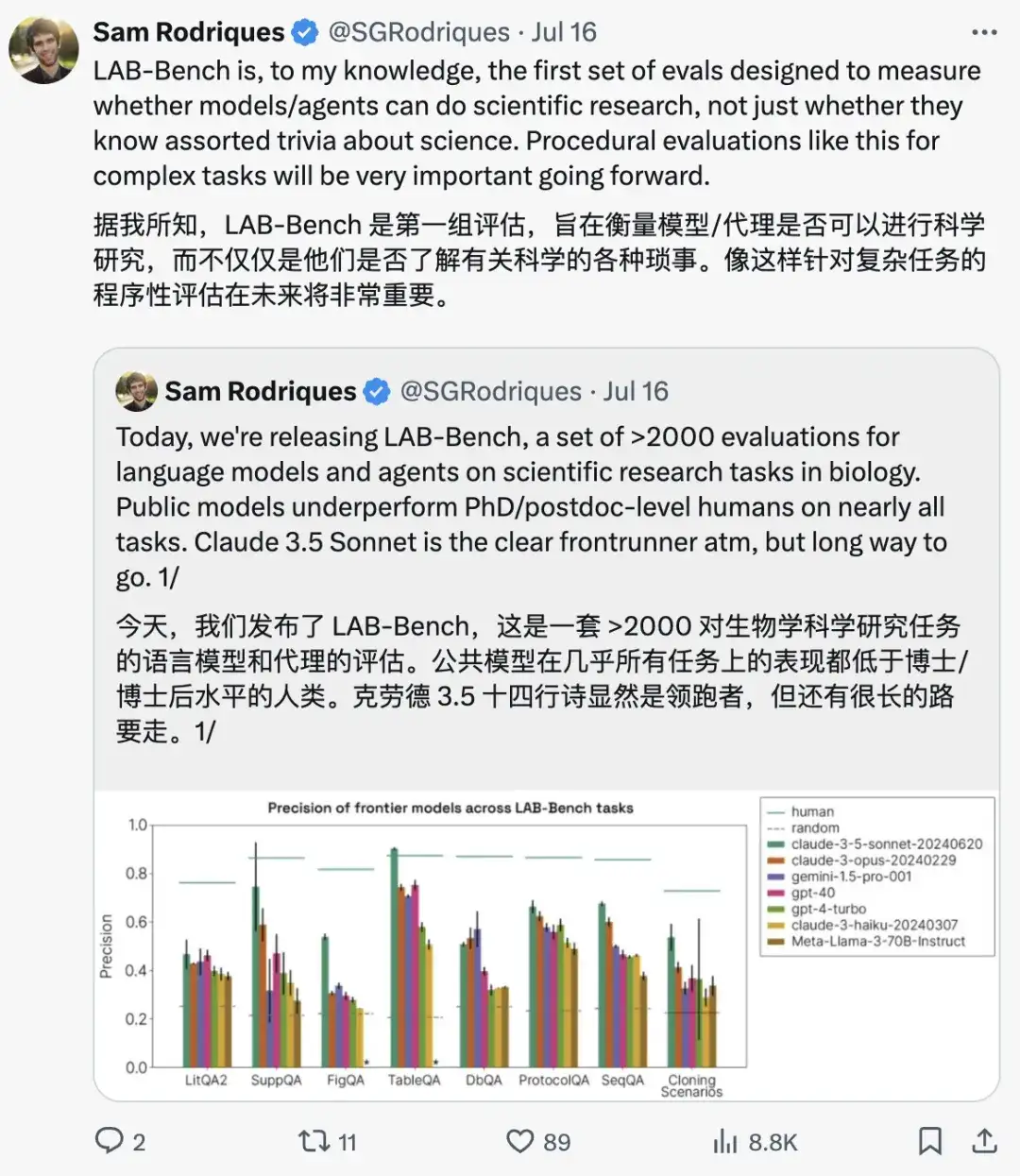
Beispielfragen aus verschiedenen Kategorien von LAB-Bench lauten wie folgt:
Deep Mining zur Bewertung der Fähigkeit des Modells, Literatur abzurufen und zu analysieren
Um die Retrieval- und Argumentationsfähigkeiten verschiedener Modelle in der wissenschaftlichen Literatur zu bewerten,Am häufigsten werden die LAB-Bench-Teilmengen verwendet, die den Aufgaben LitQA2, SuppQA und DbQA entsprechen. Diese drei Typen eignen sich für unterschiedliche Aspekte der wissenschaftlichen Retrieval Enhancement Generation (RAG).
*Retrieval-Augmented Generation (RAG) ist eine Technik, die Informationen aus privaten oder proprietären Datenquellen zur Unterstützung der Textgenerierung verwendet.
Der LitQA2-Benchmark misst die Fähigkeit von Modellen, Informationen aus der wissenschaftlichen Literatur abzurufen.Es handelt sich um Multiple-Choice-Fragen, deren Antworten in der Regel nur einmal in der wissenschaftlichen Literatur vorkommen und nicht anhand der Informationen im Abstract beantwortet werden können (d. h. die wissenschaftliche Literatur ist relativ neu). In diesem Prozess müssen die Forscher nicht nur darauf angewiesen sein, dass das Modell Fragen durch Abrufen von Trainingsdaten beantworten kann, sondern auch, dass das Modell über Literaturzugriff und Argumentationsfähigkeiten verfügt.
SuppQA erfordert, dass das Modell Informationen findet und interpretiert, die in den ergänzenden Materialien eines Dokuments enthalten sind.Die Forscher gaben an, dass das Modell zur Beantwortung dieser Fragen auf Informationen in bestimmten Zusatzdateien zugreifen muss.
Für DbQA-Probleme sind Modelle erforderlich, die auf biologiespezifische allgemeine Datenbanken zugreifen und Informationen daraus abrufen können.Diese Fragen sind so konzipiert, dass sie ein breites Spektrum an Datenquellen abdecken, und es ist dem Modell oder Agenten nicht möglich, alle Fragen mithilfe einer einzigen API zu beantworten.
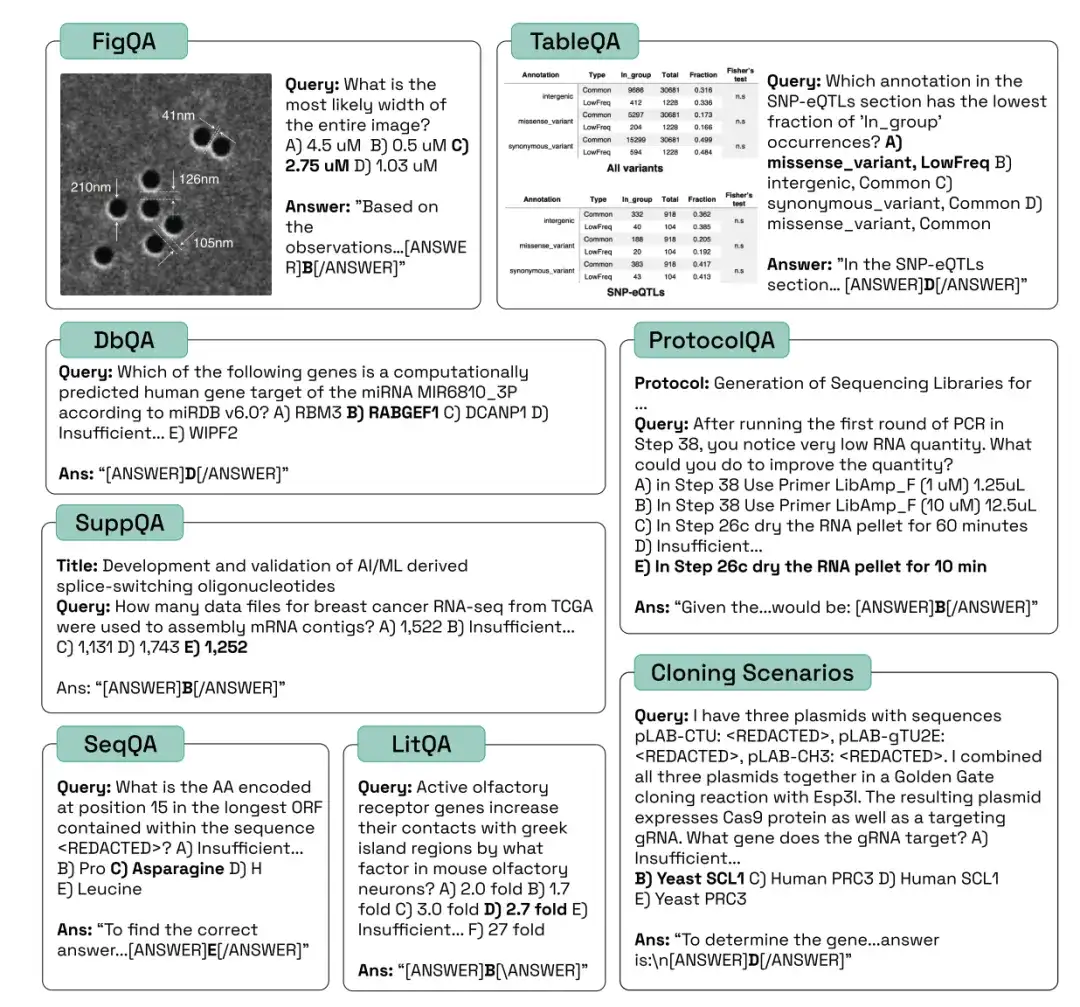
Wie in der folgenden Abbildung dargestellt, bewerteten die Forscher die Leistung von Mensch, Zufall, Claude-3-5-Sonet-20240620, Claude-3-Opus-20240229, Gemini-1.5-Pro-001, GPT-4O, GPT-4-Turbo, Claude-3-Haiku-20240307 und Meta-Llama-3-70B-Instruct in den oben genannten drei Kategorien biologischer Benchmark-Aufgaben und verglichen ihre Genauigkeit, Präzision und Abdeckung.
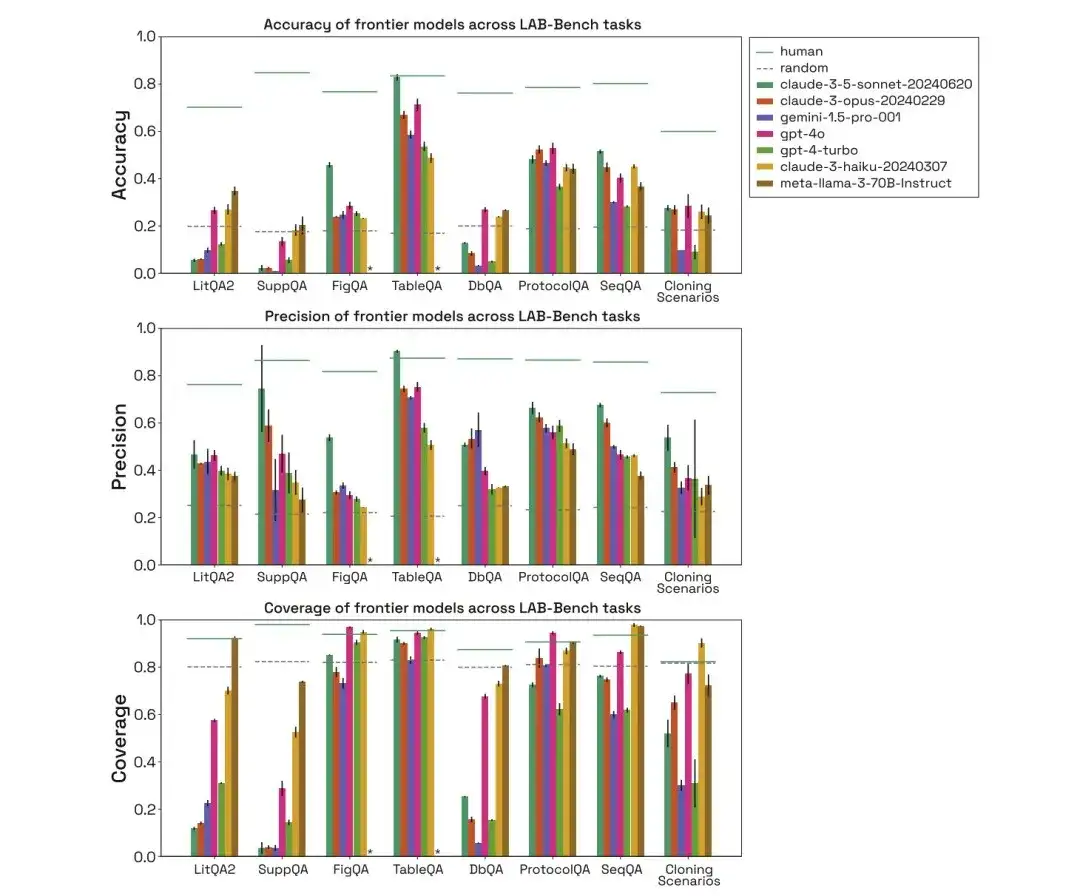
Im LitQA2-Test zeigten alle Modelle in der Kategorie „Literaturabruf“ von LitQA2 eine ähnliche Leistung, wobei die Ergebnisse weit über den zufälligen Erwartungen lagen und mehr als 40% erreichten. Allerdings verweigern herkömmliche Modelle häufig die Antwort, und manche antworten sogar mit einer niedrigeren Rate als 20%, was dazu führt, dass die Genauigkeit dieser Modelle weit unter dem Zufallsniveau liegt.
*Für jede Frage verfügt das Modell über eine spezifische Option, die Antwort aufgrund unzureichender Informationen abzulehnen
Im SuppQA-Test schnitten alle Modelle schlecht ab und hatten die niedrigste Gesamtabdeckung. Dies liegt daran, dass die Modelle aufgefordert werden, Informationen aus den ergänzenden Materialien abzurufen, was darauf hindeutet, dass die ergänzenden Informationen des Dokuments möglicherweise nicht so repräsentativ sind wie der Haupttext im Modell-Trainingssatz.
Bei den DbQA-Fragen ist die Modellabdeckung geringer als die Zufallserwartung, was bedeutet, dass das Modell sich häufig weigert, DbQA-Fragen zu beantworten, was zu einer geringen Genauigkeit führt.
SeqQA, ein Maßstab zur Erforschung der Nützlichkeit von KI bei der Interpretation biologischer Sequenzen
Um die Fähigkeit des Modells zur Interpretation biologischer Sequenzen zu bewerten,Es wird die entsprechende SeqQA-Aufgabe im LAB-Bench-Benchmark-Datensatz verwendet. Es behandelt verschiedene Sequenzeigenschaften, praktische Aufgaben, die im Arbeitsablauf der Molekularbiologie üblich sind, sowie das Verständnis und die Interpretation der Beziehungen zwischen DNA-, RNA- und Proteinsequenzen.
Bei der SeqQA-Aufgabe zeigt die Auswertung menschlicher, zufälliger und verschiedener Modelle, dass das Modell die meisten SeqQA-Fragen beantworten kann. Die Genauigkeit jedes Modells liegt zwischen 40% und 50%, was viel höher ist als die zufällige Erwartung. Dies zeigt, dass das Modell in der Lage ist, über DNA, Proteinsequenzen und molekularbiologische Aufgaben nachzudenken.
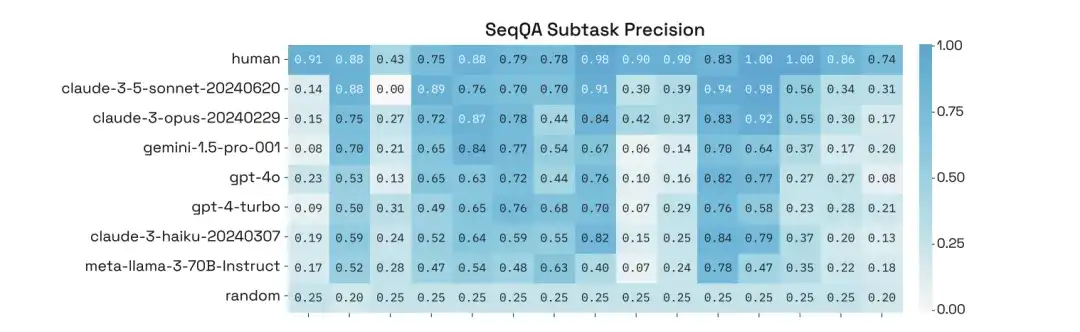
Darüber hinaus führten die Forscher eine eingehende Analyse ihrer Leistung bei bestimmten Unteraufgaben von SeqQA durch und stellten fest, dass die Genauigkeit der Modelle bei verschiedenen Unteraufgaben stark variierte, wobei einige Aufgaben sogar eine Genauigkeit von mehr als 90% erreichten.
Von Graphen bis zu Protokollen, grundlegende logische Bewertung von Modellen
Um die grundlegende Denkfähigkeit des Modells zu bewerten,Verwendet werden FigQA, TableQA und ProtocolQA.
In,FigQA misst die Fähigkeit von LLMs, wissenschaftliche Grafiken zu verstehen und zu begründen.FigQA-Fragen enthalten nur Abbildungen, ohne weitere Informationen wie Abbildungstitel oder Papiertext. Bei den meisten Problemen muss das Modell mehrere Informationselemente in das Diagramm integrieren, was wiederum erfordert, dass das Modell über multimodale Fähigkeiten verfügt.
TableQA misst die Fähigkeit, Daten aus Papiertabellen zu interpretieren.Die Fragen enthalten nur Abbildungen von Tabellen, die aus dem Dokument extrahiert wurden, ohne weitere Informationen wie Bildunterschriften, Dokumenttitel usw. Das Problem erfordert, dass das Modell nicht nur Informationen in der Tabelle findet, sondern auch die Informationen in der Tabelle begründet oder verarbeitet, was auch erfordert, dass das Modell über multimodale Fähigkeiten verfügt.
ProtocolQA-Fragen werden auf Grundlage veröffentlichter Protokolle erstellt.Diese Protokolle werden geändert oder Schritte werden ausgelassen, um Fehler einzuführen. Die Fragen stellen dann hypothetische Ergebnisse des geänderten Protokolls dar und fragen, welche Schritte geändert oder hinzugefügt werden müssen, um das Protokoll zu „reparieren“, damit das erwartete Ergebnis erzielt wird.
Durch die Auswertung menschlicher, zufälliger und unterschiedlicher Modelle lässt sich feststellen, dass die Leistung des Claude 3.5 Sonnet-Modells im FigQA-Test viel höher ist als bei anderen Modellen, was darauf hindeutet, dass es Bildinhalte besser erklären und begründen kann.
Im TableQA-Test weisen alle Modelle eine hohe Abdeckung auf, was darauf hindeutet, dass TableQA die einfachste Aufgabe ist. Darüber hinaus schneidet Claude 3.5 Sonnet erneut sehr gut ab und übertrifft in seiner Genauigkeit sogar die menschliche Leistung und erreicht deren Genauigkeit.
Bei der ProtocolQA-Aufgabe schneiden die Modelle vergleichbar ab, wobei die Präzision bei etwa 50-60% liegt. Die Modelle beantworten Protokollfragen mit einer relativ hohen Abdeckung, da die Modelle keine expliziten Nachschlagevorgänge durchführen müssen, sondern einfach eine Lösung basierend auf den Trainingsdaten vorschlagen.
41 Testsets für Klonszenarien, KI-gestützte Biologen bei der Erforschung der Zukunft
Um die Leistung des Modells mit der des Menschen bei anspruchsvollen Aufgaben zu vergleichen,Die Forscher führten einen Testsatz mit 41 Klonierungsszenarien ein, darunter mehrere Plasmide, DNA-Fragmente, mehrstufige Arbeitsabläufe usw.Bei diesen Szenarien handelt es sich um mehrstufige Multiple-Choice-Probleme, die für Menschen eine Herausforderung darstellen.Wenn ein KI-System im Test des Klonszenarios eine hohe Genauigkeit erreicht, kann davon ausgegangen werden, dass das KI-System ein hervorragender Assistent für menschliche Molekularbiologen werden kann.
Durch die Auswertung menschlicher, zufälliger und unterschiedlicher Modelle lässt sich erkennen, dass die Leistung des Modells im Klonszenario ebenfalls weit unter der des Menschen liegt und die Abdeckung von Gemini 1.5 Pro und GPT-4-Turbo gering ist. Und selbst wenn die Modelle in der Lage sind, Fragen richtig zu beantworten, wird davon ausgegangen, dass sie die richtige Antwort dadurch gefunden haben, dass sie Störfaktoren eliminiert und dann eine Vermutung angestellt haben.
Zusammenfassend lässt sich sagen, dass die Leistung verschiedener Modelle bei LAB-Bench-Aufgaben sehr unterschiedlich ist und sie sich häufig aufgrund fehlender Informationen weigern, Fragen zu beantworten, insbesondere bei Aufgaben, die ausdrücklich das Abrufen von Informationen erfordern. Darüber hinaus schneiden die Modelle bei Aufgaben, die die Verarbeitung von DNA- und Proteinsequenzen erfordern, insbesondere von Teilsequenzen oder langen Sequenzen, schlecht ab. Bei tatsächlichen Forschungsaufgaben schneiden Menschen weitaus besser ab als Modelle.
* LAB Bench Sprachmodell Biologie Benchmark-Datensatz:
Oben sind die von HyperAI in dieser Ausgabe empfohlenen Datensätze. Wenn Sie hochwertige Datensatzressourcen sehen, können Sie uns gerne eine Nachricht hinterlassen oder einen Artikel einreichen, um uns davon zu berichten!
Quellen:








