Command Palette
Search for a command to run...
Ausgewählt Für ACL 2024! Die Huazhong University of Science and Technology Stellt Zero-Shot-Learning Vor Und Veröffentlicht Ein Bedingtes Diffusionsmodell, Das Für Die Entschlüsselung Von Orakelknocheninschriften Optimiert ist.

Die Schrift ist ein Symbol der Zivilisation und das markanteste Kennzeichen einer Nation. Als ältestes bekanntes und systematisches Schriftsystem meines Landes trägt die Oracle-Bone-Schrift (OBS) die Kultur und Zivilisation der chinesischen Nation in sich. Seit 1899, als ein Wissenschaftler in einem chinesischen Apothekenladen zufällig einen Schildkrötenpanzer mit Orakelknocheninschriften entdeckte, ist die Erforschung von Orakelknocheninschriften ein heißes Thema in der akademischen Gemeinschaft.
Bei allen Studien zu Orakelknochen stehen die Identifizierung und Interpretation im Mittelpunkt. Allerdings gibt es unter den mehr als 4.500 Orakelknochenzeichen, die bisher entdeckt wurden, immer noch etwa 3.000 Zeichen, die nicht erkannt wurden, und die Orakelknochenforschung ist in eine Engpassphase eingetreten, die nur schwer zu durchbrechen ist.
Mit dem Aufkommen der KI-Technologie bietet sich den Forschern durch den Einsatz moderner Technologie zum Verständnis dieser alten Sprache eine neue Möglichkeit der Erforschung. Bisherige Forschungsmethoden basierten jedoch hauptsächlich auf dem Wissen und Verständnis der entzifferten Orakelknochen.So verwenden Sie KI zur Unterstützung bei der Entzifferung unbekannter Wörter mit zahlreichen Problemen wie nicht digitalem Text, stark beschädigten Proben, fehlendem Korpus usw.Es handelt sich noch immer um ein neues Gebiet, das erforscht werden muss.
Als Reaktion darauf verwendete das Forschungsteam von Bai Xiang und Liu Yuliang von der Huazhong University of Science and Technology zusammen mit der University of Adelaide, der Anyang Normal University und der South China University of Technology ein bildbasiertes generatives Modell, umTrainiert wurde ein bedingtes Diffusionsmodell namens Oracle Bone Script Decipher (OBSD), das für die Entschlüsselung von Oracle Bone Script optimiert ist.Das Modell verwendet unbekannte Kategorien von Orakelknocheninschriften als bedingte Eingabe, um entsprechende Bilder moderner chinesischer Schriftzeichen zu generieren, und bietet damit einen neuartigen Ansatz für die Aufgabe der Erkennung alter Schriftzeichen, die in der natürlichen Sprachverarbeitung nur schwer zu lösen ist.
Die zugehörige Forschung mit dem Titel „Deciphering Oracle Bone Language with Diffusion Models“ wurde von der ACL 2024-Hauptkonferenz angenommen.
Forschungshighlights:
* Bereitstellung eines neuartigen Ansatzes für Aufgaben zur Erkennung alter chinesischer Schriftzeichen durch Verwendung von Bildgenerierungstechnologie
* OBSD verwendet lokale Analyse-Sampling-Technologie, um die Fähigkeit des Modells zu verbessern, komplexe Zeichenmuster zu unterscheiden und zu interpretieren
* Nachweis der Wirksamkeit von OSBD bei der Dekodierung durch umfassende Ablationsstudien und Benchmarktests

Papieradresse:
https://doi.org/10.48550/arXiv.2406.00684
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Datensatz: Verwendung des größten Repository von Oracle, wobei die OCR-Technologie als Benchmark verwendet wird
Um das vorgeschlagene OSBD-Modell zu trainieren und zu bewerten,Für diese Studie wurden der HUST-OBS-Datensatz und der EVOBC-Datensatz ausgewählt.Sie sind eine der größten Sammlungen von Orakelknocheninschriften und enthalten 1.590 verschiedene Zeichen, die in 71.698 Bildern dargestellt sind.
Da die Entzifferung unbekannter Orakelknochen in der Regel eine umfassendere professionelle Überprüfung erfordert, wurden in dieser Studie die entzifferten Texte nur als Testsatz verwendet, wodurch der gesamte Auswertungsprozess vereinfacht wurde. Noch wichtiger ist, dass die Studie auch die im Testsatz ausgewählten Zeichenkategorien ausdrücklich aus dem Trainingssatz ausschloss, um sicherzustellen, dass das Modell zum Knacken von Zeichen verwendet wurde, die nie verarbeitet wurden. Der Datensatz ist im Verhältnis 9:1 in Trainings- und Testsätze unterteilt und bietet so einen zuverlässigen Rahmen für die Auswertung.
Obwohl das OSBD-Modell aus der Perspektive der Bildgenerierung eine Orakel-Entschlüsselung durchführt, sind herkömmliche Bildgenerierungsmetriken wie SSIM für diese Aufgabe nicht geeignet. Daher wurde in dieser Studie die OCR-Technologie als objektiveres Maß zur Bestimmung erfolgreicher Entschlüsselungsergebnisse eingesetzt. Konkret passten die Forscher das OBS-OCR-Tool an, indem sie einen einfachen Klassifikator mit einem ResNet-101-Backbone-Netzwerk verwendeten, das speziell anhand eines großen Datensatzes mit 88.899 Kategorien moderner chinesischer Schriftzeichen trainiert wurde, um die Ausgabe des Modells auszuwerten.
Die Ergebnisse zeigen, dass Das angepasste OCR-Tool erreichte eine Erkennungsgenauigkeit von 99,87%.Die Zuverlässigkeit der Entschlüsselungsergebnisse wurde nachgewiesen. Gleichzeitig wurde im Rahmen dieser Studie auch das chinesische Open-Source-OCR-Tool PaddleOCR 1 zur weiteren Evaluierung umfassend vorgestellt. Diese duale OCR-Methode bietet eine starke Garantie für die Wirksamkeit des Modells beim Entziffern von Orakelknochen.
Rekonstruieren Sie das OBSD-Modell basierend auf dem bedingten Diffusionsmodell
Diese Studie stellt den Trainingssatz als S = {(si, ci) | dar. si ist eine Oracle-Instanz, ci∈C}, d. h., es werden Oracle-Instanzen mit einem Satz moderner chinesischer Schriftzeichen in einer bekannten Kategorie C abgeglichen und neue Zeichenformen vorgeschlagen, wo vorhandene Übereinstimmungen fehlen. Um dies zu erreichen,Diese Studie konvertiert das Orakelknochen-Zeichenbild X auf der Grundlage des Diffusionsmodells in sein modernes chinesisches Äquivalent.
Wie in der folgenden Abbildung dargestellt, ist das Modell in zwei Phasen unterteilt:
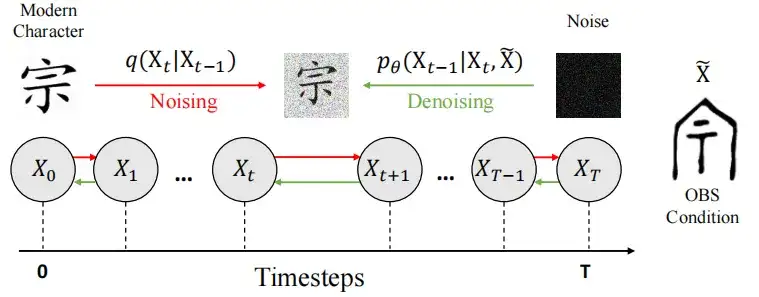
Im Frühstadium (Noising),Die Forscher fügten Rauschen in das Bild X0 des modernen chinesischen Schriftzeichens ein und verwendeten einen steuerbaren Markow-Kettenprozess, um es in einen Zustand zu überführen, der reinem Rauschen ähnelte, wodurch schließlich eine Gauß-Verteilung N (0, I) entstand.
In der RauschunterdrückungsphaseDie Forscher verwendeten die U-Net-Architektur, um das Modell fθ zu trainieren, damit es Rauschen e vorhersagt und das Bild wiederherstellt. Außerdem verwendeten sie et ∼ N(0, I), um Zufälligkeit einzuführen und so die Vielfalt der Generierungsergebnisse des Modells zu verbessern. Das endgültige Dekodierungsergebnis ist das generierte, rauschfreie Bild X0.
Auf dieser Grundlage integriert das OBSD-Modell die anfängliche Entschlüsselungsphase und die Zero-Shot-Verfeinerungsphase, um die Entschlüsselungsgenauigkeit zu verbessern, wie in der folgenden Abbildung dargestellt.
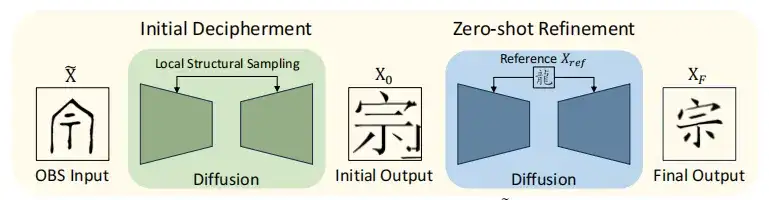
Zunächst wird das Orakelbild X bedingt diffundiert, um das ursprüngliche Bild X0 anzunähern, das dann durch eine Zero-Shot-Lernmethode verbessert wird, und Xref wird als Referenz verwendet, um die Struktur zu korrigieren und zu verbessern. Durch die im Verbesserungsprozess gewonnenen Erkenntnisse zur Struktur des Textes konnte schließlich das Textergebnis XF generiert werden, das den modernen chinesischen Schriftzeichen entspricht.
Einführung des LSS-Konzepts zur Verbesserung der Fähigkeit des Modells, alte Schriftzeichen mit modernen chinesischen Schriftzeichen zu verbinden
In tatsächlichen Anwendungsfällen kann das auf diese Weise trainierte Modell die entsprechenden modernen chinesischen Schriftzeichen jedoch nicht genau generieren, sondern bildet stattdessen basierend auf einer großen Anzahl zufälliger Fragmente Unsinn, wie in der folgenden Abbildung dargestellt.

Die Forscher vermuten, dass der Grund für dieses Ergebnis darin liegt, dass das Diffusionsmodell hauptsächlich darauf ausgelegt ist, natürliche Bilder zu erzeugen, bei der Entzifferung von Orakelknocheninschriften jedoch große Unterschiede in der Struktur zwischen Orakelknocheninschriften und modernen chinesischen Schriftzeichen auftreten.Dies macht es für das standardmäßige bedingte Diffusionsmodell unmöglich, die Zielschriftzeichen des modernen Chinesisch genau zu rekonstruieren.
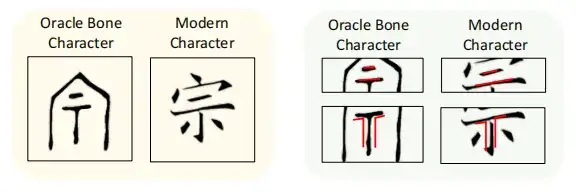
Um dieser Herausforderung zu begegnen,In dieser Studie wurde das Konzept des Local Structure Sampling (LSS) eingeführt.Helfen Sie dem Diffusionsmodell dabei, die lokale Radikalstruktur von Orakelknocheninschriften den entsprechenden modernen chinesischen Schriftzeichen zuzuordnen und verbessern Sie so die Fähigkeit des Modells, alte Schriftzeichen mit modernen chinesischen Schriftzeichen zu verknüpfen. Die Studie ergab außerdem, dass trotz der beträchtlichen strukturellen Entwicklung von den alten chinesischen Schriftzeichen zu den modernen chinesischen Schriftzeichen bestimmte lokale Strukturen erhalten geblieben sind.
Damit das Diffusionsmodell die Eigenschaften der lokalen Struktur erlernen kann, verwendet das LSS-Modul eine gleitende Fenstermethode, um das Zielbild mit den modernen chinesischen Schriftzeichen X0∈RHxWx3 und das entsprechende Orakelknochenbild X∈RHxWx3 in D kleine Blöcke der Größe p×p aufzuteilen, die als X(d) und Xt(D)∈Rp×p×3 bezeichnet werden, D=1,2…D, p=64. Hier stellt Xt ein modernes Textbild dar, dem zum Zeitpunkt t ein Gaußsches Rauschen ϵt hinzugefügt wurde.
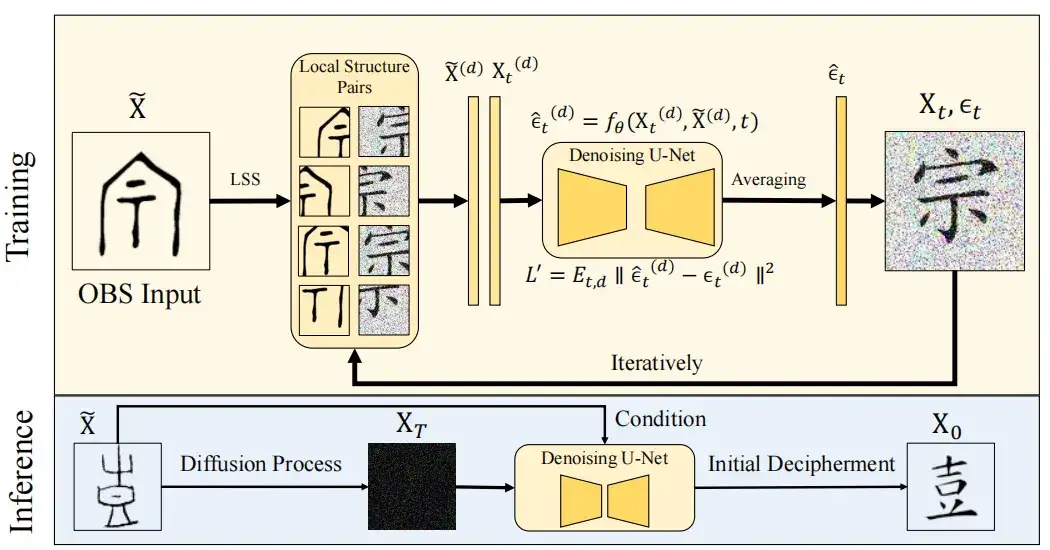
Basierend auf dieser Methode,Das Modell kann Patches iterieren und optimieren, indem es die lokale Struktur von Orakelknocheninschriften und subtile Unterschiede in der Struktur chinesischer Schriftzeichen lernt.Die Einzigartigkeit unserer Methode besteht darin, dass sie die Überlappungen zwischen benachbarten Regionen bei jedem Zeitschritt t mittelt, ohne die Rauschunterdrückung abzuschließen, um eine gleichmäßige Wirkung auf gemeinsame Regionen sicherzustellen. Gleichzeitig wurden in dieser Studie Kantenunterschiede vermieden und die visuelle Konsistenz des rekonstruierten Bildes durch Glättung der regionalen Übergänge während des Abtastvorgangs aufrechterhalten.
Einführung von Zero-Shot-Lernmethoden zur Verbesserung der Fähigkeit des Modells, die Charakterstruktur zu verstehen
Obwohl bei der Generierung moderner chinesischer Schriftzeichen durch lokale Strukturproben einige Fortschritte erzielt wurden, stoßen die ersten Entzifferungsbemühungen noch immer auf offensichtliche Hindernisse wie strukturelle Deformationen und Artefakte.

Dies liegt an der verwendeten Viele-zu-eins-Trainingsmethode, die mehrere Orakelknocheninschriften einem modernen chinesischen Schriftzeichenbild zuordnet.Dies führt zu Verwirrung und Ungenauigkeiten bei der Erfassung der Charakterentwicklung.Und aufgrund der begrenzten Anzahl moderner chinesischer Schriftzeichen erscheint die Struktur unvollständig.
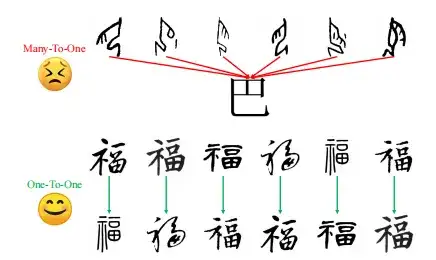
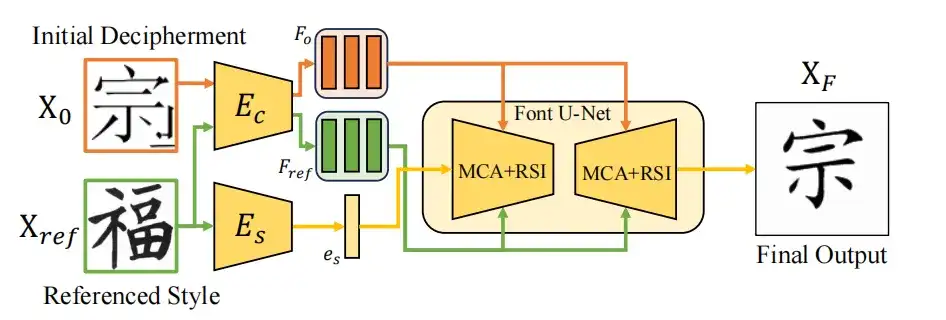
Um diese Herausforderungen zu meistern,In dieser Studie wurde eine Zero-Shot-Lernstrategie vorgeschlagen, um das Strukturverständnis des Modells durch die Verwendung verschiedener moderner chinesischer Schriftzeichenstile zu verbessern.Im tatsächlichen Betrieb trainierte die Studie das Modul eins zu eins anhand von 20 verschiedenen modernen chinesischen Schriftarten. Dadurch lernte es die strukturellen Transformationen zwischen verschiedenen modernen chinesischen Schreibstilen und verbesserte die Fähigkeit des Modells, die Zeichenstruktur zu verstehen.
Wie in der folgenden Abbildung dargestellt, basiert diese Zero-Shot-Lernmethode auf einem universellen Rahmen für die Übertragung von Schriftstilen. Durch ein duales Encodersystem wird der Stil des Quellschriftbilds X0 an den Zielstil Xref angepasst, wobei die Inhaltsintegrität erhalten bleibt. Der Stilcodierer Es extrahiert das Stilmerkmal es aus Xref, während der Inhaltscodierer Ec Xo und Xref verarbeitet, um das mehrskalige Inhaltsmerkmal Fo zu erhalten, das von Font U-Net mit mehrskaliger Inhaltsaggregation (MCA) und Referenzstruktur verfeinert wird. Nach Abschluss des Trainings kann das Zero-Shot-Lernmodul direkt verwendet werden, um die vom Diffusionsmodell generierten Ergebnisse zu optimieren.
OSBD-Leistungsbewertung: Die Erkennungsgenauigkeit ist unter mehreren Bewertungskriterien am höchsten
Um die Leistung von OSBD quantitativ zu bewerten, wurden in dieser Studie zwei verschiedene Bewertungskriterien verwendet: Einzelrunden-Entschlüsselung und Mehrrunden-Entschlüsselung. Da es keine speziellen Tools zur Entschlüsselung von Orakelknochen gibt, verwendet diese Studie einen vergleichenden Rahmen, um führende Bild-zu-Bild-Übersetzungsmethoden an diese Aufgabe anzupassen.
Zu diesen Methoden gehören insbesondere GAN-basierte Methoden wie Pix2Pix, CycleGAN, DRIT++ und Diffusionsmodelle wie CDE, Palette und BBDM. Diese Einstellung stellt sicher, dass die OBSD-Methode im Kontext modernster Bildkonvertierung ausgewertet werden kann und gewährleistet eine angemessene Konsistenz der Trainings- und Testbedingungen.
In einer einzigen Runde der EntschlüsselungsbewertungOBSD hat beim Knacken von Oracle Bones erhebliche Vorteile gegenüber modifizierten Bild-zu-Bild-Konvertierungsmethoden.Wie in der Abbildung unten gezeigt.
Die von OSBD durch OBS-OCR und PaddleOCR erreichte Top-1-Genauigkeit beträgt 41,0% bzw. 30,0% und ist damit besser als bei anderen Methoden. Mit steigendem Ranking zeigt sich eine klare Tendenz zur Verbesserung der Genauigkeit. Unter den Top 500 Genauigkeiten erreicht OSBD eine OBS-OCR-Erkennungsgenauigkeit von 64,5%.
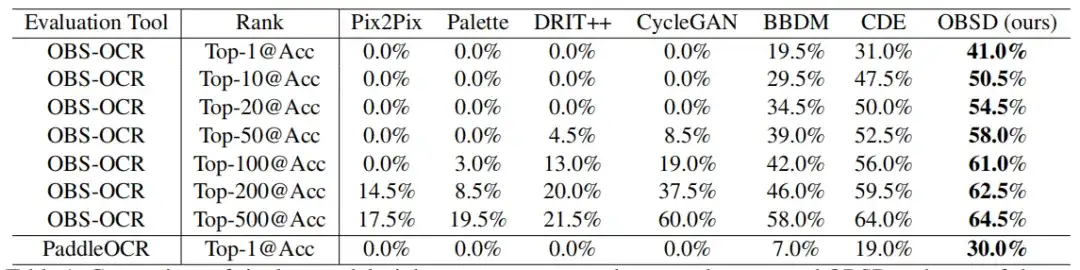
Es ist erwähnenswert, dass alle GAN-basierten Methoden (wie Pix2Pix, Palette, DRIT++ und CycleGAN) in diesem Fall die schlechteste Effektivität mit einer Top-1-Genauigkeit von 0,% aufweisen. Dies kann daran liegen, dass es für GAN selbst schwierig ist, die komplexen und subtilen Zuordnungsbeziehungen zu erfassen, die zum Entschlüsseln von Oracle Bones erforderlich sind.
In mehreren Runden der EntschlüsselungsbewertungDie Erfolgsquote von OBS-OCR verbesserte sich im Laufe mehrerer Versuche schrittweise.Der Indikator hat sich kontinuierlich von einer Erfolgsrate von 41,0% auf 80,0% verbessert, wie in der folgenden Abbildung dargestellt.
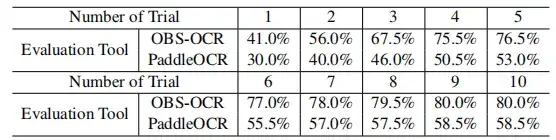
Der Wachstumstrend des PaddleOCR-Indikators zeigte ebenfalls einen Aufwärtstrend, beginnend bei 30,0% und schließlich bis zu 58,5%. Diese Ergebnisse bestätigen alle, dass durch aufeinanderfolgende Versuche schrittweise Verbesserungen erzielt werden können.
Um die Auswirkungen der einzelnen Komponenten weiter zu untersuchen, wurde im Rahmen dieser Studie auch eine Ablationsstudie durchgeführt, die sich auf das LSS-Modul und das Zero-Shot-Learning konzentrierte. Die Ergebnisse zeigen, dass die Dekodierung von Orakelknocheninschriften nur mithilfe des grundlegenden bedingten Diffusionsmodells Einschränkungen unterliegt und eine deutlich geringere Genauigkeit aufweist. Insbesondere führt das Trainieren eines Diffusionsmodells ohne jegliche Erweiterung zu Ergebnissen, die im Wesentlichen bedeutungslos sind.
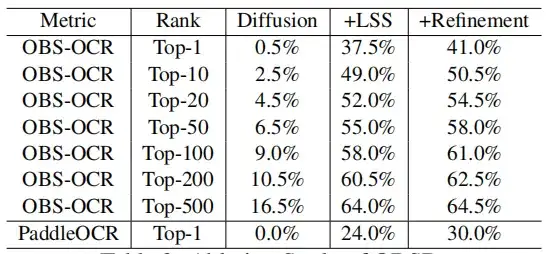
Durch die Einführung des LSS-ModulsDie Erkennungsgenauigkeit von OBS-OCR wurde auf 37,5% verbessert.PaddleOCR wurde auf 24% verbessert. Durch die Verwendung des Zero-Shot-Learning-Moduls mit LSS kann die Top-1-Genauigkeit von OBS-OCR und PaddleOCR um weitere 3,5% bzw. 6% verbessert werden.
Abschließend führt diese Studie auch eine qualitative Studie zu verschiedenen Bild-zu-Bild-Übersetzungsmodellen durch.
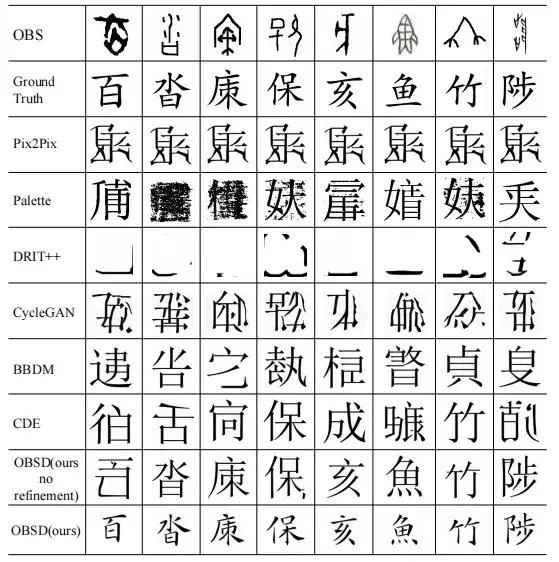
Die Ergebnisse zeigen, dass Orakelknocheninschriften, die mit der OBSD-Methode eingegeben werden, die genaueste Entzifferung moderner chinesischer Schriftzeichen ermöglichen und die komplexen Details von Orakelknocheninschriften erkennen lassen. Diese Ergebnisse unterstreichen nicht nur die Wirksamkeit von OSBD, sondern auch sein Potenzial als Expertentool zur Entschlüsselung von Orakelsprachen.
Wenn Orakelknocheninschriften auf künstliche Intelligenz treffen, erhält das alte Schriftsystem endlich neues Leben
Auf dem Gebiet der Erforschung alter chinesischer Schriftzeichen, insbesondere der Erforschung der Orakelknochenschrift, war die Huazhong University of Science and Technology schon immer führend. Sie ist eine der ersten Universitäten in China, die eine unabhängige Datenbank mit Orakelknochenskripten erstellt hat. Mit der rasanten Entwicklung der künstlichen Intelligenztechnologie ist die intelligente Verarbeitung von Text und Bildern zu einem der wichtigsten Themen der künstlichen Intelligenzforschung geworden. Die Huazhong University of Science and Technology, vertreten durch das Forschungsteam von Bai Xiang und Liu Yuliang, ist erneut zum Pionier und Marktführer im Bereich der Text- und Bildintelligenz geworden.
Professor Bai Xiang ist ein national herausragender Nachwuchswissenschaftler und IAPR-Stipendiat. Derzeit ist er Dekan der School of Software an der Huazhong University of Science and Technology und Direktor des Hubei Engineering Research Center for Machine Vision and Intelligent Systems. Vorher,Monkey, entwickelt von Professor Bai Xiang Das multimodale Großmodell hat in der Open-Source-Version von OpenCompass den ersten Platz der maßgeblichen Großmodellliste gewonnen.Die Ergebnisse wurden auf die innovativen Produkte der führenden Softwareunternehmen von Wuhan angewendet.
Als Kernmitglied von Bai Xiangs Team wurde Liu Yuliang für das 9. Nachwuchsförderungsprojekt der China Association for Science and Technology ausgewählt. Er konzentrierte sich auf Text- und Bildintelligenz und erzielte eine Reihe von Arbeitsergebnissen in den Bereichen intelligente Dokumentanalyse, visuelles und natürliches Sprachverständnis sowie multimodale Großmodelle.
Um mit der Weiterentwicklung und Reife der Technologie größere Durchbrüche in der Orakelknochenforschung zu erzielen, haben sich Bai Xiang und Professor Liu Yuliang entschlossen für eine intensive Zusammenarbeit mit der Anyang Normal University entschieden, einer der führenden Institutionen für Orakelknochenforschung in China. Im Jahr 2018 wurde der Bau des Schlüssellabors für Oracle-Informationsverarbeitung des Bildungsministeriums an der Anyang Normal University genehmigt. Im Jahr 2019 wurde „Yinqiwenyuan“, eine vom Labor sorgfältig aufgebaute Big-Data-Plattform für Oracle Bone Script, die die Dokumentbibliothek, Katalogbibliothek und Zeichenbibliothek von Oracle Bone Script integriert, der Welt vorgestellt.Dies ist die umfassendste, standardisierteste und maßgeblichste Oracle-Datenplattform der Welt.Seine Eröffnung markiert den Eintritt der Orakelknochenforschung in das intelligente Zeitalter.
Es ist erwähnenswert, dass Liu Yongge, einer der korrespondierenden Autoren dieses Artikels, Direktor des Key Laboratory of Oracle Information Processing des Bildungsministeriums an der Anyang Normal University ist.
Um die Orakelknochenforschung besser zu dokumentieren und zu verbreiten, konzentrierte sich das Labor im Jahr 2023 auf zwei wichtige Dinge: Einerseits startete es gemeinsam mit Tencent SSV, der Anyang Workstation des Instituts für Archäologie der Chinesischen Akademie der Sozialwissenschaften und dem Anyang Municipal Cultural Relics Bureau den „Oracle Bone Global Digital Return Plan“. Dabei werden Kameras mit Hunderten Millionen Pixeln eingesetzt, um eine hochpräzise Restaurierung und den Schutz physischer Orakelknochen im digitalen Raum zu erreichen. Andererseits hat das vom Labor und Tencent gemeinsam gestartete Miniprogramm „Amazing Oracle“ Oracle der Öffentlichkeit näher gebracht.
Um es Wissenschaftlern zu erleichtern, Informationen zum Orakelknochen-Spleißen leichter zu finden und die Zeit für die Datenerfassung in der frühen Phase der Forschung zu verkürzen,Anfang 2023 erstellten Yang Yi, Huang Bo und Cheng Minghui, Doktoranden des Zentrums für die Erforschung ausgegrabener Dokumente und antiker Schriftzeichen der Universität Fudan, gemeinsam die Informationsdatenbank „Jade and Pearl“ zum Orakelknochenspleißen.Es vereint mehr als 6.700 Sätze von Orakelknochen-Spleißergebnissen vieler Wissenschaftler seit der Veröffentlichung der „Oracle Bone Collection“. Es ist nicht nur für die akademische Gemeinschaft zu einem Online-Tool für die Suche nach wichtigen Ergebnissen zum Spleißen von Orakelknochen geworden, sondern bietet auch vielen Orakelknochen-Enthusiasten außerhalb des „Elfenbeinturms“ die Möglichkeit, an der Arbeit zur Lösung von Orakelknochenfragmenten teilzunehmen und Korrekturen sowie neue Informationen zum Spleißen von Orakelknochen bereitzustellen.
Es ist ersichtlich, dass die Oracle-Bone-Forschung mit Hilfe digitaler Technologien wie Big Data, Cloud Computing und künstlicher Intelligenz in eine neue Ära eingetreten ist. Da die Forschungen immer intensiver werden, bin ich davon überzeugt, dass diese „unpopuläre Geheimfertigkeit“ in naher Zukunft weitere Codes enthüllen und als sehr wichtige Referenz für die Entzifferung anderer antiker Schriftzeichen dienen wird.








