Command Palette
Search for a command to run...
Stanford, Apple Und 23 Andere Institutionen Haben DCLM-Benchmarks veröffentlicht. Können Qualitativ Hochwertige Datensätze Die Skalierungsgesetze Durcheinanderbringen? Das Basismodell Bietet Die Gleiche Leistung Wie Llama3 8B

Da KI-Modelle weiterhin große Aufmerksamkeit erhalten, wird auch die Debatte über Skalierungsgesetze immer hitziger.
OpenAI hat Skalierungsgesetze erstmals im Jahr 2020 in dem Artikel „Scaling Laws for Neural Language Models“ vorgeschlagen. Sie gelten als Mooresches Gesetz für große Sprachmodelle. Seine Bedeutung lässt sich kurz wie folgt zusammenfassen:Mit zunehmender Modellgröße, Datensatzgröße und Gleitkommazahl der Berechnungen (die für das Training verwendet werden) verbessert sich die Leistung des Modells.
Unter dem Einfluss der Skalierungsgesetze glauben viele Anhänger immer noch, dass „groß“ immer noch das erste Prinzip zur Verbesserung der Modellleistung ist. Insbesondere große Unternehmen mit viel Geld sind stärker auf große und vielfältige Korpusdatensätze angewiesen.
In dieser Hinsicht ist Qin Yujia, ein Ph.D. vom Institut für Informatik der Universität Tsinghua wies darauf hin: „LLaMA 3 zeigt uns eine pessimistische Realität: Die Modellarchitektur muss nicht geändert werden, und eine Erhöhung des Datenvolumens von 2T auf 15T kann Wunder bewirken. Einerseits zeigt uns dies, dass das Basismodell auf lange Sicht eine Chance für große Unternehmen darstellt. Andererseits müssen wir angesichts der geringen Auswirkungen der Skalierungsgesetze möglicherweise mindestens zehn Größenordnungen mehr Daten (z. B. 150T) aussortieren, wenn wir in der nächsten Modellgeneration weiterhin Verbesserungen von GPT3 auf GPT4 sehen wollen.“

Als Reaktion auf die kontinuierliche Zunahme der für das Training von Sprachmodellen erforderlichen Datenmenge und auf Probleme wie die Datenqualität haben 23 Institutionen, darunter die University of Washington, die Stanford University und Apple, gemeinsam eine experimentelle Testplattform namens DataComp for Language Models (DCLM) vorgeschlagen. Der Kern dieser Plattform ist das 240.000 neue Kandidatenvokabular von Common Crawl. Durch die Korrektur des Trainingscodes werden Forscher ermutigt, neue Trainingssätze für Innovationen vorzuschlagen, was für die Verbesserung der Trainingssätze von Sprachmodellen von großer Bedeutung ist.
Verwandte Forschungsergebnisse wurden auf der akademischen Plattform unter dem Titel „DataComp-LM: Auf der Suche nach der nächsten Generation von Trainingssätzen für Sprachmodelle“ veröffentlicht. http://arXiv.org Vorgesetzter.
Forschungshighlights
* DCLM-Benchmark-Teilnehmer können mit Datenmanagementstrategien an Modellen mit 412 Millionen bis 7 Milliarden Parametern experimentieren
* Modellbasiertes Filtern ist der Schlüssel zum Erstellen hochwertiger Trainingssätze. Der generierte Datensatz DCLM-BASELINE unterstützt das Training eines 7B-Parameter-Sprachmodells von Grund auf auf MMLU unter Verwendung von 2,6T Trainingstoken und erreicht eine 5-Schuss-Genauigkeit von 64%
* Das DCLM-Basismodell ist auf MMLU vergleichbar mit Mistral-7B-v0.3 und Llama3 8B

Papieradresse:
https://arxiv.org/pdf/2406.11794v3
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
DCLM-Benchmark: Multiskalendesign von 400 M bis 7 B, um unterschiedliche Rechenskalenanforderungen zu erfüllen
DCLM ist eine Datensatz-Experimentierplattform zur Verbesserung von Sprachmodellen und der erste Maßstab für das Trainingsdatenmanagement von Sprachmodellen.
Wie in der Abbildung unten gezeigt,Der DCLM-Workflow besteht hauptsächlich aus vier Schritten: Auswählen einer Skala, Erstellen eines Datensatzes, Trainieren eines Modells und Bewerten des Modells anhand von 53 nachgelagerten Aufgaben.
Auswählen der Compute-Skala
Erstens haben die Forscher im Hinblick auf die Rechenskala fünf verschiedene Wettbewerbsstufen erstellt, die sich über drei Größenordnungen der Rechenskala erstrecken. Jede Ebene (z. B. 400M-1x, 1B-1x, 1B-5x, 7B-1x und 7B-2x) gibt den Modellparameterbetrag (z. B. 7B) und einen Chinchilla-Multiplikator (z. B. 1x) an. Die Anzahl der Trainingstoken für jede Größe beträgt das 20-fache der Anzahl der Parameter multipliziert mit dem Chinchilla-Multiplikator.
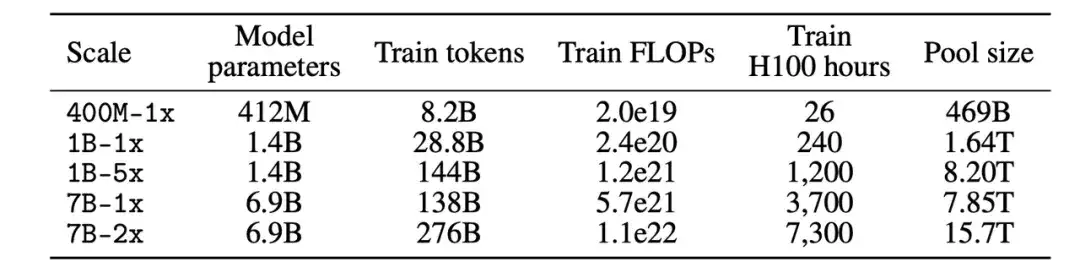
Erstellen eines Datensatzes
Zweitens können die Teilnehmer nach der Bestimmung der Parameterskala beim Erstellen eines Datensatzes einen Datensatz erstellen, indem sie Daten filtern (Filtern) oder mischen (Mischen).
In der FilterspurDie Forscher extrahierten einen standardisierten Korpus von 240T-Token aus der ungefilterten Crawler-Website Common Crawl, erstellten den DCLM-Pool und teilten ihn entsprechend der Rechenskala in 5 Datenpools auf. Die Teilnehmer schlagen Algorithmen vor und wählen Trainingsdaten aus einem Datenpool aus.
In der Mix-SpurDen Teilnehmern steht es frei, Daten aus mehreren Quellen zu kombinieren. Synthetisieren Sie beispielsweise Datendokumente aus DCLM-Pool, benutzerdefinierten Crawlerdaten, Stack Overflow und Wikipedia.
Trainieren des Modells
OpenLM ist eine auf PyTorch basierende Codebibliothek, die sich auf das FSDP-Modul für verteiltes Training konzentriert. Um die Auswirkungen von Datensatzinterferenzen zu eliminieren, verwendeten die Forscher für das Modelltraining auf jeder Datenskala eine feste Methode.
Basierend auf früheren Ablationsstudien zur Modellarchitektur und zum Training übernahmen die Forscher eine reine Decoder-Transformer-Architektur wie GPT-2 und Llama und trainierten das Modell schließlich in OpenLM.
Modellbewertung
endlich,Die Forscher bewerteten das Modell mithilfe des LLM-Foundry-Workflows und verwendeten 53 nachgelagerte Aufgaben, die für die grundlegende Modellbewertung geeignet waren, als Kriterien.Zu diesen nachgelagerten Aufgaben gehören die Beantwortung von Fragen und die Generierung offener Fragen. Sie decken zahlreiche Bereiche ab, beispielsweise Kodierung, Lehrbuchwissen und gesundes Denken.
Um den Datenaufbereitungsalgorithmus zu bewerten, konzentrierten sich die Forscher auf drei Leistungsindikatoren: MMLU-5-Schuss-Genauigkeit, CORE-Mittengenauigkeit und EXTENDED-Mittengenauigkeit.
Datensatz: Verwenden Sie DCLM, um hochwertige Trainingsdatensätze zu erstellen
Wie erstellt DCLM den hochwertigen Datensatz DCLM-BASELINE und quantifiziert die Wirksamkeit von Datenmanagementmethoden?
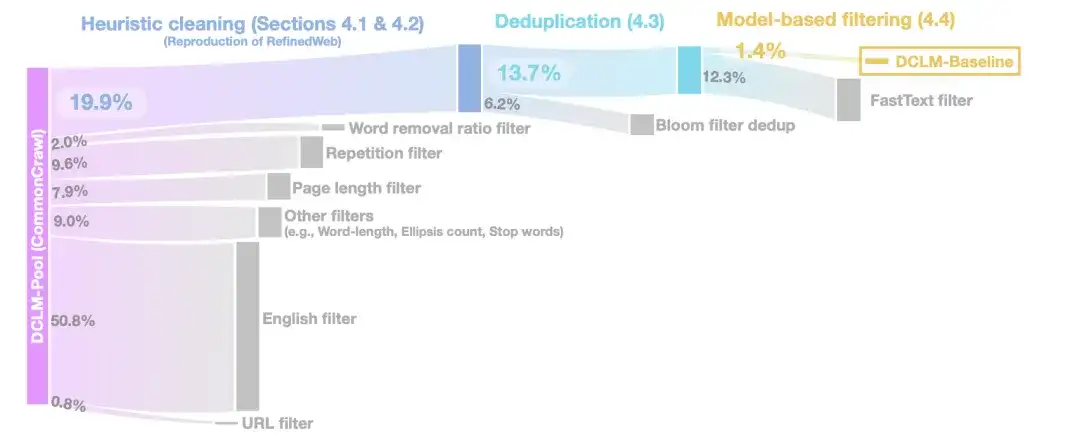
In der heuristischen ReinigungsphaseDie Forscher verwendeten die Methode von RefinedWeb zum Bereinigen der Daten, einschließlich der Entfernung von URLs (URL-Filter), englischen Filtern (Englisch-Filter), Seitenlängenfiltern (Seitenlängenfilter) und Filtern für doppelte Inhalte (Wiederholungsfilter).
In der DeduplizierungsphaseDie Forscher verwendeten Bloom-Filter, um die extrahierten Textdaten zu deduplizieren, und stellten fest, dass die modifizierten Bloom-Filter leichter auf 10-TB-Datensätze skalierbar waren.
Um die Qualität der Daten weiter zu verbessern,In der Phase der modellbasierten Filterung verglichen die Forscher sieben modellbasierte Filtermethoden.Unter Einbeziehung der Filterung mithilfe von PageRank-Werten, semantischer Deduplizierung (SemDedup), binärem FastText-Klassifizierer usw. wurde festgestellt, dass die auf FastText basierende Filterung alle anderen Methoden übertraf.
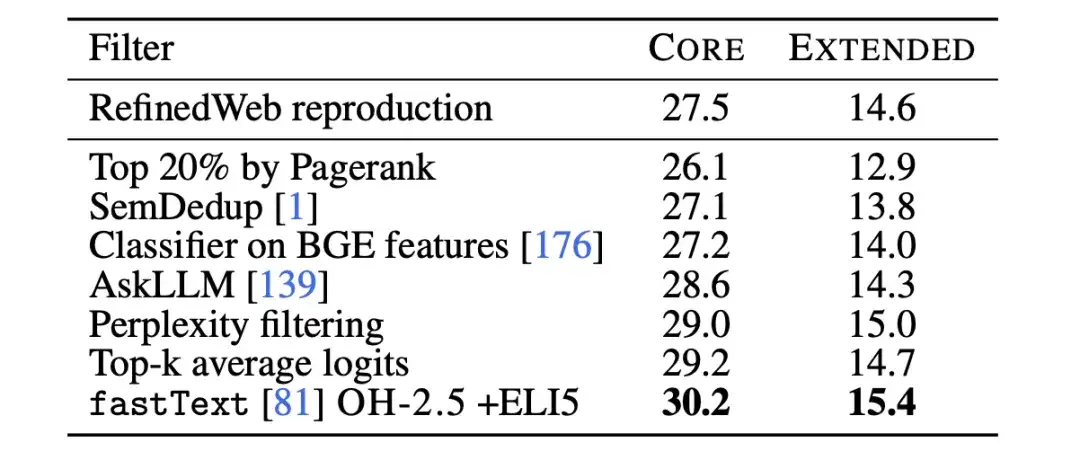
Anschließend verwendeten die Forscher Textklassifizierer-Ablationen, um die Einschränkungen der auf fastText basierenden Datenfilterung weiter zu untersuchen. Die Forscher trainierten mehrere verschiedene Varianten und untersuchten dabei unterschiedliche Auswahlmöglichkeiten für Referenzdaten, Merkmalsräume und Filterschwellenwerte, wie in der folgenden Abbildung dargestellt. Als Referenzdaten wählten die Forscher die häufig verwendeten Wikipedia-, OpenWebText2- und RedPajama-Bücher aus, die alle als Referenzdaten von GPT-3 verwendet werden.
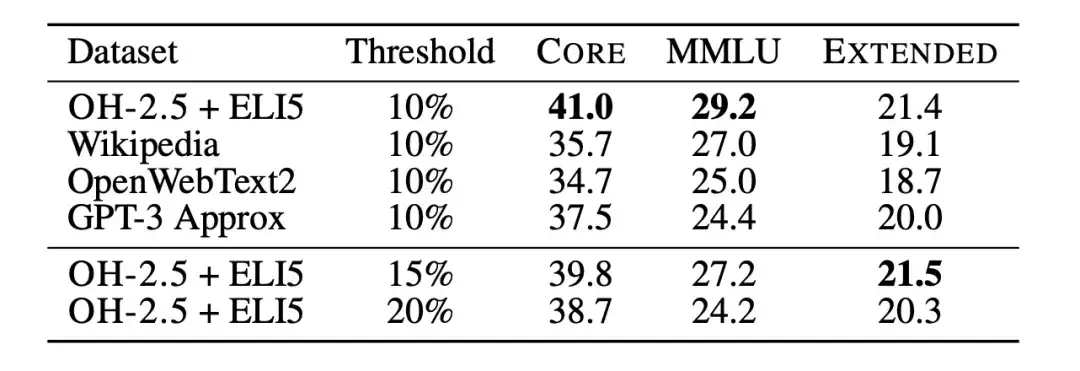
gleichzeitig,Die Forscher machten außerdem innovativen Gebrauch von Daten im Anweisungsformat und extrahierten Beispiele aus Posts mit hoher Punktzahl in den Subreddits OpenHermes 2.5 (OH-2.5) und r/ExplainLikeImFive (ELI5).Die Ergebnisse zeigen, dass die Methode OH-2.5 + ELI5 im Vergleich zu den üblicherweise verwendeten Referenzdaten eine Verbesserung von 3,5% auf CORE bewirkt.
Darüber hinaus stellten die Forscher fest, dass mit einem strengen Schwellenwert (d. h. einem Schwellenwert von 10%) eine bessere Leistung erzielt werden kann. Also,Die Forscher verwendeten fastText OH-2.5 + ELI5-Klassifikatorwerte, um die Daten zu filtern, und behielten die ersten 10%-Dokumente bei, um DCLM-BASELINE zu erhalten.
Forschungsergebnisse: Modellbasierte Filterung ist der Schlüssel zur Generierung hochwertiger Datensätze
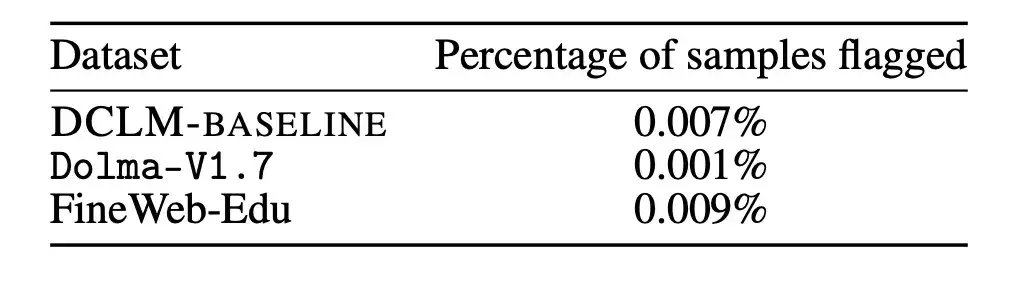
Zunächst analysierten die Forscher, ob eine Verunreinigung durch nicht ausgewertete Daten aus der Vorschulung die Ergebnisse beeinflussen könnte.
MMLU ist ein Benchmark zur Messung der Leistung großer Sprachmodelle und zielt darauf ab, die Fähigkeit des Modells, verschiedene Sprachen zu verstehen, umfassender zu untersuchen. Daher verwendeten die Forscher MMLU als Bewertungssatz und erkannten und beseitigten die in DCLM-BASELINE vorhandenen Probleme von MMLU. Anschließend trainierten die Forscher ein 7B-2x-Modell basierend auf DCLM-BASELINE, ohne die erkannte MMLU-Überlappung zu verwenden.
Die Ergebnisse sind in der folgenden Abbildung dargestellt. Die Entfernung kontaminierter Proben führt nicht zu einer Verringerung der Leistung des Modells. Daraus lässt sich erkennen, dassDie Leistungsverbesserung von DCLM-BASELINE im MMLU-Benchmark ist nicht auf die Aufnahme von Daten in MMLU in seinen Datensatz zurückzuführen.

Darüber hinaus haben die Forscher die oben genannte Entfernungsstrategie auch auf Dolma-V1.7 und FineWeb-Edu angewendet, um die Kontaminationsunterschiede zwischen DCLM-BASELINE und diesen Datensätzen zu messen. Es wurde festgestellt, dass die Verschmutzungsstatistiken von DLCM-BASELINE denen anderer Hochleistungsdatensätze in etwa ähneln.
Zweitens verglichen die Forscher das trainierte neue Modell auch mit anderen Modellen mit einer Parameterskala von 7B-8B. Die Ergebnisse zeigen, dass das auf Basis des DCLM-BASELINE-Datensatzes generierte Modell die auf Open-Source-Datensätzen trainierten Modelle übertrifft und mit den auf Closed-Source-Datensätzen trainierten Modellen konkurrieren kann.
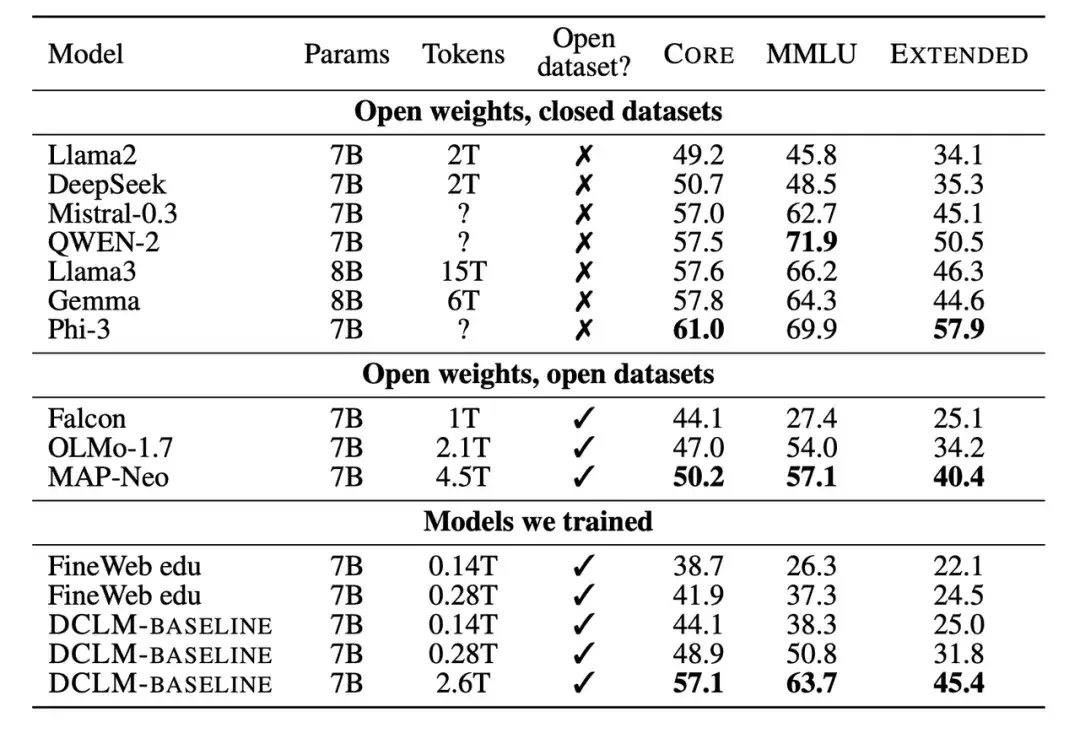
Zahlreiche experimentelle Ergebnisse zeigen, dassModellbasiertes Filtern ist der Schlüssel zur Bildung eines qualitativ hochwertigen Datensatzes, und das Datensatzdesign ist für das Trainieren von Sprachmodellen sehr wichtig.Der generierte Datensatz DCLM-BASELINE unterstützt das Training eines 7B-Parameter-Sprachmodells von Grund auf auf MMLU unter Verwendung von 2,6T-Trainingstoken und erreicht eine 5-Schuss-Genauigkeit von 64%.
Im Vergleich zum bisher fortschrittlichsten Open-Data-Sprachmodell MAP-Neo,Der generierte Datensatz DCLM-BASELINE verbessert MMLU um 6,6 % und reduziert gleichzeitig den für das Training erforderlichen Rechenaufwand um 40%.
Das Basismodell von DCLM ist vergleichbar mit Mistral-7B-v0.3 und Llama3 8B auf MMLU (63% und 66%) und weist bei 53 Aufgaben zum Verständnis natürlicher Sprache eine ähnliche Leistung auf, erfordert jedoch 6,6-mal weniger Rechenleistung zum Trainieren als Llama3 8B.
Skalierungsgesetze: Die zukünftige Richtung ist unklar, auf der Suche nach der nächsten Generation von Trainingssätzen für Sprachmodelle
Zusammenfassend besteht der Kern von DCLM darin, Forscher zu ermutigen, durch modellbasiertes Filtern hochwertige Trainingssätze zu erstellen und so die Modellleistung zu verbessern. Dies bietet auch einen neuen Ansatz zur Lösung von Problemen im Rahmen des Modelltrainingstrends „groß ist schön“.
Wie Qin Yujia, ein Ph.D. vom Institut für Informatik der Tsinghua-Universität sagte: „Es ist an der Zeit, die Datenmenge zu reduzieren.“ Durch die Analyse und Zusammenfassung mehrerer Arbeiten stellte er fest, dass „saubere Daten nach der Bereinigung + kleineres Modell dem Effekt von schmutzigen Daten + großem Modell näher kommen können“.
Anfang Juli erwähnte Bill Gates in der neuesten Folge des Podcasts „Next Big Idea“ das Thema Paradigmenwechsel in der KI-Technologie und glaubte, dass die Skalierungsgesetze zu Ende gingen. Die KI-Revolution in der Computerinteraktion hat noch nicht begonnen, aber ihr wirklicher Fortschritt liegt darin, metakognitive Fähigkeiten zu erreichen, die denen des Menschen näher kommen, und nicht einfach nur die Größe des Modells zu erhöhen.

Zuvor hatten viele führende Vertreter der heimischen Industrie auf der Beijing Zhiyuan Conference 2024 bereits ausführlich über die zukünftige Ausrichtung der Scaling Laws diskutiert.
Kai-Fu Lee, CEO von Zero One Everything, sagte, dass sich das Skalierungsgesetz als wirksam erwiesen habe und seinen Höhepunkt noch nicht erreicht habe, das Skalierungsgesetz jedoch nicht dazu verwendet werden könne, GPUs blind aufzustapeln. Sich einfach auf die Anhäufung von mehr Rechenleistung zu verlassen, um die Modelleffekte zu verbessern, wird nur dazu führen, dass Unternehmen oder Länder mit genügend GPUs gewinnen.
Zhang Yaqin, Dekan des Institute of Intelligent Industries an der Tsinghua-Universität, sagte, dass die Umsetzung des Skalierungsgesetzes hauptsächlich auf die Nutzung großer Datenmengen und die deutliche Verbesserung der Rechenleistung zurückzuführen sei. Dies wird auch in den nächsten fünf Jahren die Hauptrichtung der industriellen Entwicklung bleiben.

Yang Zhilin, CEO von Dark Side of the Moon, glaubt, dass es mit dem Scaling Law kein grundsätzliches Problem gibt. Solange mehr Rechenleistung und Daten zur Verfügung stehen und die Modellparameter größer werden, kann das Modell weiterhin mehr Intelligenz generieren. Er glaubt, dass sich Scaling Law weiterentwickeln wird, die Methoden von Scaling Law sich in diesem Prozess jedoch erheblich ändern könnten.
Wang Xiaochuan, CEO von Baichuan Intelligence, ist der Ansicht, dass wir zusätzlich zum Skalierungsgesetz nach neuen Transformationen bei Rechenleistung, Algorithmen, Daten und anderen Paradigmen suchen müssen, anstatt sie einfach in Wissenskompression umzuwandeln. Nur wenn wir aus diesem System aussteigen, haben wir eine Chance, uns in Richtung AGI zu bewegen.
Der Erfolg großer Modelle beruht größtenteils auf der Existenz von Skalierungsgesetzen, die wertvolle Hinweise für die Modellentwicklung, Ressourcenzuweisung und Auswahl geeigneter Trainingsdaten bieten. Wir wissen vielleicht noch nicht, wann die Skalierungsgesetze enden werden, aber der DCLM-Benchmark bietet ein neues Denkparadigma und die Möglichkeit, die Modellleistung zu verbessern.
Quellen:
https://arxiv.org/pdf/2406.11794v3
https://arxiv.org/abs/2001.08361








