Command Palette
Search for a command to run...
Meilenstein Von Universal Robots! Das MIT Schlägt Ein Strategiekombinationsframework PoCo Vor, Um Das Problem Heterogener Datenquellen Zu Lösen Und Die Flexible Ausführung Von Multitasking-Robotern Zu Ermöglichen

18 humanoide Roboter fungierten als „Begrüßer“ und winkten den Gästen im Chor zu. Dies war ein schockierender Anblick auf der Weltkonferenz für künstliche Intelligenz 2024, der den Menschen die rasante Entwicklung der Roboter in diesem Jahr intuitiv vor Augen führte.

1954 wurde der weltweit erste programmierbare Roboter „Unimate“ offiziell am Fließband von General Motors in Betrieb genommen. Nach mehr als einem halben Jahrhundert haben sich Roboter allmählich von klobigen Industriegiganten zu intelligenteren und flexibleren menschlichen Assistenten entwickelt. Unter ihnen hat die Technologie der künstlichen Intelligenz, insbesondere die bahnbrechenden Fortschritte bei der Verarbeitung natürlicher Sprache und der Computervision, einen Hochgeschwindigkeitsweg für die Entwicklung von Robotern geebnet, die enorme Rechenleistung und enorme Datenmengen nutzen.Training allgemeiner Roboterstrategien durch einfache Algorithmen wie Verhaltensklonen,Das unbegrenzte Potenzial zukünftiger Roboter wird schrittweise freigesetzt.

Die meisten aktuellen Roboter-Lernpipelines werden jedoch für eine bestimmte Aufgabe trainiert.Dadurch sind sie nicht in der Lage, mit neuen Situationen umzugehen oder andere Aufgaben zu erledigen.Darüber hinaus stammen die Trainingsdaten der Roboter hauptsächlich aus Simulationen, Demonstrationen am Menschen und Szenarien der Roboterfernsteuerung.Es besteht eine große Heterogenität zwischen den verschiedenen Datenquellen.Außerdem ist es für ein maschinelles Lernmodell schwierig, Daten aus so vielen Quellen zu integrieren, und das Training von Robotern mit allgemeinen Strategien war schon immer eine große Herausforderung.
Als Reaktion daraufForscher des MIT haben ein Framework zur robotergestützten Richtlinienkomposition, PoCo (Policy Composition), vorgeschlagen.Dieses Framework verwendet die probabilistische Synthese von Diffusionsmodellen, um Daten aus verschiedenen Feldern und Modalitäten zu kombinieren, und entwickelt Methoden zur Strategiesynthese auf Aufgaben-, Verhaltens- und Feldebene, um komplexe Roboterstrategiekombinationen zu erstellen. Es kann die Probleme der Datenheterogenität und Aufgabenvielfalt bei Aufgaben zur Verwendung von Roboterwerkzeugen lösen. Die zugehörige Forschung wurde auf arXiv unter dem Titel „PoCo: Policy Composition from and for Heterogeneous Robot Learning“ veröffentlicht.
Forschungshighlights:
* Keine Umschulung erforderlich, das PoCo-Framework kann Strategien für Trainingsdaten aus verschiedenen Bereichen flexibel kombinieren
* PoCo zeichnet sich durch hervorragende Ergebnisse bei der Verwendung von Werkzeugen sowohl in der Simulation als auch in der realen Welt aus und zeigt im Vergleich zu Methoden, die auf eine einzelne Domäne trainiert wurden, eine hohe Generalisierung auf Aufgaben in unterschiedlichen Umgebungen.

Papieradresse:
https://arxiv.org/abs/2402.02511
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Drei große Datensätze, die menschliche und maschinelle Daten, reale und simulierte Daten usw. abdecken.
Die in dieser Studie verwendeten Datensätze stammen hauptsächlich aus Videodaten menschlicher Demonstrationen, Daten realer Roboter und Simulationsdaten.
Datensatz zu Demonstrationsvideos von Menschen
In der freien Natur können Demonstrationsvideos von Menschen mit nicht kalibrierten Kameras aufgenommen werden. Insgesamt können bis zu 200 Spuren gesammelt werden.

Echter Roboterdatensatz
Die lokalen und globalen Ansichten der Szene werden durch die installierte Handgelenkkamera und die Overhead-Kamera erfasst, und die Werkzeughaltung, Werkzeugform und taktilen Informationen, wenn das Werkzeug das Objekt berührt, werden mithilfe von GelSight Svelte Hand erfasst. Für jede Aufgabe werden 50–100 Flugbahndemonstrationen gesammelt.
Simulationsdatensatz
Der simulierte Datensatz folgt Fleet-Tools, wo Expertendemonstrationen durch Keypoint-Trajektorienoptimierung generiert und insgesamt etwa 50.000 simulierte Datenpunkte gesammelt werden. Während des anschließenden Trainingsprozesses führten die Forscher eine Datenerweiterung sowohl der Punktwolkendaten als auch der Bewegungsdaten durch und speicherten feste Simulationsszenen zum Testen.
Darüber hinaus fügten die Forscher punktweises Rauschen und zufälliges Ablegen zu 512 Werkzeugen und 512 Objektpunktwolken aus Tiefenbildern und Masken hinzu, um die Robustheit des Modells zu verbessern.
Kombination von Strategien durch Wahrscheinlichkeitsverteilungsprodukt
Bei der Strategiekombination gaben die Forscher Trajektorieninformationen ein, die durch zwei Wahrscheinlichkeitsverteilungen pDM(⋅|c,T) und pD′M′(⋅|c′,T′) kodiert waren, und kombinierten die Informationen dieser beiden Wahrscheinlichkeitsverteilungen direkt, indem sie während der Inferenz Stichproben in der Produktverteilung nahmen.
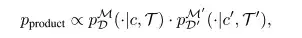
In,Produkt Es zeigt eine hohe Wahrscheinlichkeit auf allen Trajektorien, die beide Wahrscheinlichkeitsverteilungen erfüllen.Es kann Informationen beider Verteilungen effektiv kodieren.
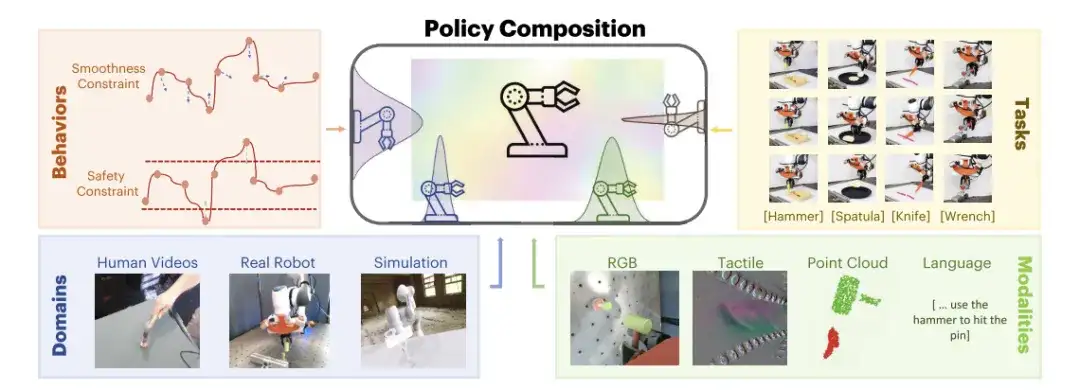
PoCo von Forschern vorgeschlagen,Zusammenführung von Informationen über Verhaltensweisen, Aufgaben, Kanäle und Domänen hinweg,Eine Umschulung ist nicht erforderlich; Informationen werden während der Vorhersage modular kombiniert und durch die Nutzung von Informationen aus mehreren Feldern kann eine Generalisierung der Aufgaben zur Werkzeugnutzung erreicht werden.
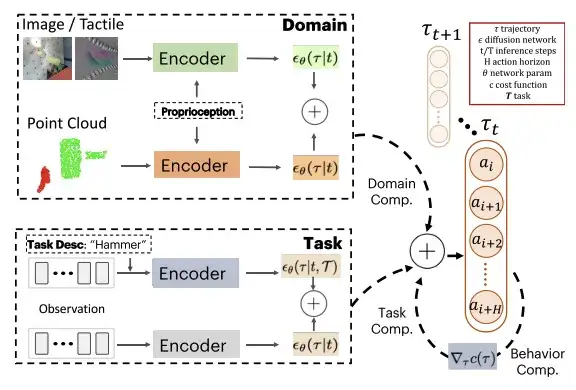
Es wird angenommen, dass sich die Diffusionsausgabe jedes Modells im selben Raum befindet, d. h., die Aktionsdimension und der Aktionszeitbereich sind gleich. Zur Testzeit wird PoCo mit Gradientenvorhersagen kombiniert. Dieser Ansatz kann auf die Kombination von Richtlinien aus verschiedenen Bereichen angewendet werden, beispielsweise auf die Kombination von Richtlinien, die mithilfe unterschiedlicher Modalitäten wie Bildern, Punktwolken und taktilen Bildern trainiert wurden. Es kann auch verwendet werden, um Strategien für verschiedene Aufgaben zu kombinieren und durch Verhaltenskombination zusätzliche Kostenfunktionen für gewünschte Verhaltensweisen bereitzustellen.
In diesem Zusammenhang lieferten die Forscher drei Beispiele: Zusammensetzung auf Aufgabenebene, Zusammensetzung auf Verhaltensebene und Zusammensetzung auf Domänenebene, um zu veranschaulichen, wie PoCo die Richtlinienleistung verbessern kann.
Zusammensetzung auf Aufgabenebene
Durch die Kombination auf Aufgabenebene werden Trajektorien, die möglicherweise Aufgabe T abschließen können, zusätzliche Gewichte hinzugefügt. Dadurch kann die endgültige Qualität der synthetisierten Trajektorie verbessert werden, ohne dass für jede Aufgabe ein separates Training erforderlich ist.Stattdessen wird eine allgemeine Richtlinie trainiert, mit der Multitasking-Ziele erreicht werden können.
Zusammensetzung auf Verhaltensebene
Durch diese Kombination können Informationen zur Aufgabenverteilung und zum Kostenziel kombiniert werden.Stellen Sie sicher, dass die synthetisierte Trajektorie sowohl die Aufgabe erfüllt als auch das angegebene Kostenziel optimiert.
Zusammensetzung auf Domänenebene
Diese Kombination kann Informationen nutzen, die von verschiedenen Sensormodalitäten und Domänen erfasst wurden.Sehr nützlich, um in separaten Feldern erfasste Daten zu ergänzen.Wenn beispielsweise die Erfassung realer Roboterdaten teuer, aber genauer ist und die Erfassung von Simulationsdemonstrationsdaten billiger, aber weniger genau ist, kann zur Vereinfachung der Verarbeitung eine Merkmalsverkettung für Daten aus verschiedenen Modi im selben Feld durchgeführt werden.
Aufgabe zur Nutzung von Visualisierungstools: Bewerten Sie 3 wichtige Strategiekombinationen

Während des Trainings verwendeten die Forscher eine zeitliche U-Net-Struktur mit einem denoisierenden Diffusions-Probabilistikmodell (DDPM) und führten 100 Trainingsschritte durch; Während des Tests verwendeten sie ein implizites Denoising-Diffusion-Modell (DDIM) und führten 32 Testschritte durch. Um verschiedene Diffusionsmodelle zwischen unterschiedlichen Domänen D und Aufgaben T zu kombinieren, verwendeten die Forscher für alle Modelle denselben Aktionsraum und führten eine feste Normalisierung der Aktionsgrenzen des Roboters durch.
Die Forscher bewerteten den vorgeschlagenen PoCo anhand von Roboternutzungsaufgaben für gängige Werkzeuge (Schraubenschlüssel, Hammer, Schaufel und Schraubenschlüssel). Die Aufgabe galt als erfolgreich, wenn ein bestimmter Schwellenwert erreicht wurde. Beispielsweise galt die Hämmeraufgabe als erfolgreich, wenn ein Stift eingetrieben wurde.
Kombinationen auf Verhaltensebene können gewünschte Verhaltensziele verbessern
Die Forscher verwendeten Testzeitinferenz, um Verhaltensweisen wie Glätte und Arbeitsbereichsbeschränkungen zu kombinieren, wobei das Synthesegewicht auf γc=0,1 festgelegt wurde.
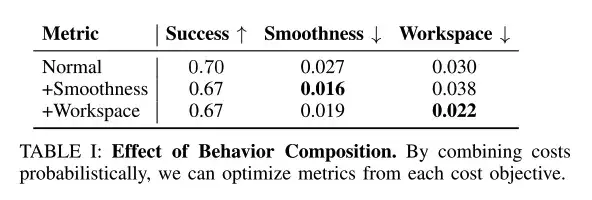
Wie in der obigen Tabelle gezeigt, können Kombinationen von Testverhalten und -ebene gewünschte Verhaltensziele wie Laufruhe und Arbeitsbereichsbeschränkungen verbessern.
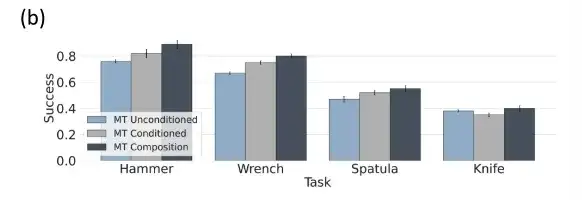
Kombinationen auf Aufgabenebene sind optimal für die Multitasking-Richtlinienbewertung
Wenn die Aufgabengewichtung α=0 ist, wird die Kombinationsrichtlinie auf Aufgabenebene der unbedingten Multitaskingrichtlinie zugeordnet, wenn α=1 ist, wird sie der standardmäßigen aufgabenbedingten Richtlinie zugeordnet und wenn 0 < α < 1 ist, interpolieren die Forscher zwischen aufgabenbedingten und aufgabenunbedingten Richtlinien. Wenn α > 1 ist, können Trajektorien ermittelt werden, die für die Aufgabenbedingungen relevanter sind.
Die obige Abbildung zeigt, dass die Strategie der bedingten und bedingungslosen Verwendung von Multitasking-Tools im Vergleich zur bedingungslosen und aufgabenspezifischen Strategie der bedingten Verwendung von Multitasking-Tools eine bessere Aufgabenkombination aufweist.
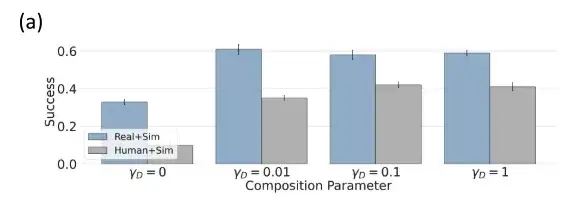
Mensch + simulierte Daten, Kombination auf Domänenebene hat eine bessere Leistung
Die Forscher trainierten separate Richtlinienmodelle mithilfe eines simulierten Datensatzes θsim, eines menschlichen Datensatzes θhuman und eines Roboterdatensatzes θrobot und bewerteten Kombinationen auf Domänenebene in einer simulierten Umgebung.
Da θsim keine Lücke zwischen Trainings- und Testdomäne aufweist, weist es eine gute Leistung auf und kann eine Erfolgsrate von 92% erreichen. In Bereichen wie Humandaten kombinierten die Forscher es mit einer leistungsstärkeren Policy-θsim und verbesserten so die Leistung deutlich.
Die Leistung der Strategiekombination übertrifft die ihrer Einzelkomponenten und ist vielseitiger
Die Forscher wandten PoCo auf Aufgaben im Zusammenhang mit der Verwendung von Roboterwerkzeugen an und kombinierten Daten aus verschiedenen Bereichen und Aufgaben, um die Generalisierungsfähigkeit zu verbessern. Die 4 Aufgaben sind: Schrauben mit Schraubenschlüssel festziehen, Nägel mit Hammer einschlagen, Pfannkuchen mit Schaufel aus der Pfanne heben und Knete mit Messer schneiden.

Durch die Kombination von in Simulationen, mit Menschen und mit realen Daten trainierten Richtlinien können wir auf mehrere Ablenker (Zeile 1), unterschiedliche Objekt- und Werkzeugposen (Zeile 2) und neue Objekt- und Werkzeuginstanzen (Zeile 3) verallgemeinern.
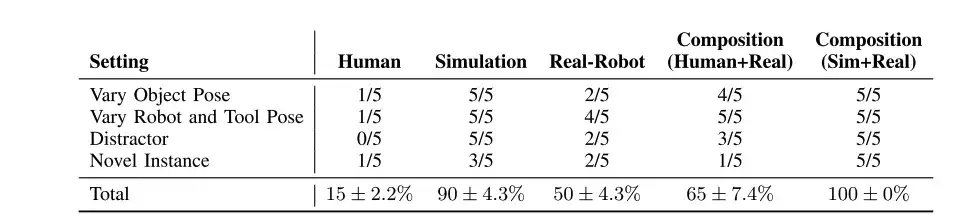
Wie in der obigen Tabelle gezeigt, schneiden die mit menschlichen Daten trainierten Strategien und die mit Daten realer Roboter trainierten Strategien in verschiedenen Szenarien (im Vergleich zur Simulation) schlecht ab.Aber ihre Kombination (Mensch + Realität) kann jede einzelne Komponente übertreffen.
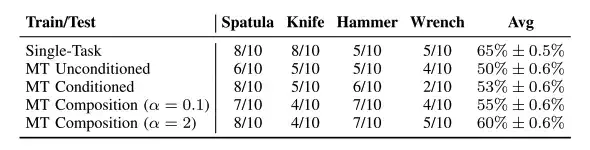
In der realen Welt bewerteten die Forscher die strategische Leistung des Roboters bei vier verschiedenen Aufgaben mit Werkzeugeinsatz und fanden heraus, dass bei Aufgaben mit Werkzeugeinsatz,Die Leistung der Aufgabenkombinationsstrategie wird verbessert.Wie aus der obigen Tabelle hervorgeht, ist die Leistung der Multitasking-Strategie nahezu identisch mit der der spezifischen Aufgaben, die auf Tspatula und Thammer basieren, und sie alle weisen eine gewisse Stabilität bei Feinaktionen auf. Darüber hinaus müssen die kombinierten Hyperparameter innerhalb eines Bereichs gehalten werden, um effektiv und stabil zu sein.
Beste Voraussetzungen für Universalität: Humanoide Roboter sind stark im Kommen
Die Entwicklung von Allzweckrobotern hat in den letzten zwei Jahren einen Aufschwung erlebt. Interessant ist jedoch, dass die Branche derzeit eher die Entwicklung humanoider Allzweckroboter zu fördern scheint.Warum müssen Allzweckroboter humanoid sein?Chen Zhe, Geschäftsführer von 5Y Capital, sagte: „Denn nur humanoide Roboter können sich an verschiedene Interaktionsszenarien im menschlichen Lebensumfeld anpassen!“ Da Roboter den Menschen bei der Arbeit helfen sollen, ist es für sie offensichtlich am besten, Menschen zu imitieren und mit einem humanoiden Aussehen zu lernen.
Als Maßstab für die Branche brachte Tesla bereits im September 2022 den humanoiden Allzweckroboter Optimus auf den Markt. Obwohl er anfangs nicht einmal sicher gehen konnte, verfügt er heute über einen vollständigen humanoiden Roboterprototyp und erfüllt die grundlegenden Fähigkeiten des Menschen in der Fingerfertigkeit. Mit der kontinuierlichen Weiterentwicklung der Software- und Hardwaretechnologie von Tesla wird Optimus über weitere spannende Funktionen verfügen, und die Tatsachen haben sich als wahr erwiesen.

Auf der World Artificial Intelligence Conference 2024 präsentierte Tesla allen die neuesten Forschungsfortschritte seines humanoiden Roboters Optimus: Die aufrechte Gehgeschwindigkeit wurde um 30% erhöht und die zehn Finger entwickelten zudem Wahrnehmung und Tastsinn, sodass sie zerbrechliche Eier sanft halten und schwere Kisten sicher tragen können. Es wird davon ausgegangen, dass Optimus praktische Anwendungen in Tesla-Fabriken erprobt hat, beispielsweise die Verwendung visueller neuronaler Netzwerke und FSD-Chips zur Nachahmung menschlicher Vorgänge, um das Sortieren von Batterien zu trainieren. Es wird erwartet, dass im nächsten Jahr mehr als 1.000 humanoide Roboter in Tesla-Fabriken eingesetzt werden, um Menschen bei der Erledigung von Produktionsaufgaben zu unterstützen.
Auch Shanghai Fourier Intelligent Technology Co., Ltd., ein branchenführendes, 2015 gegründetes Unternehmen für allgemeine Robotik, brachte seinen humanoiden Roboter GR-1 zur Konferenz mit. Seit seiner Markteinführung im Jahr 2023 hat GR-1 eine Vorreiterrolle bei der Massenproduktion und -lieferung eingenommen und fortschrittliche Verbesserungen in den Bereichen Umweltwahrnehmung, Simulationsmodelle, Bewegungssteuerungsoptimierung und anderen Aspekten erreicht.
Darüber hinaus hat NVIDIA im März dieses Jahres auf seiner jährlichen GTC-Entwicklerkonferenz ein humanoides Roboterprojekt namens GR00T vorgestellt. Durch die Beobachtung menschlichen Verhaltens, um natürliche Sprache zu verstehen und Handlungen nachzuahmen, kann der Roboter schnell Koordination, Flexibilität und andere Fähigkeiten erlernen, um in der realen Welt zu navigieren, sich anzupassen und mit ihr zu interagieren.
Angesichts des kontinuierlichen Fortschritts in Wissenschaft und Technologie haben wir Grund zu der Annahme, dass humanoide Roboter zu einer Brücke werden könnten, die Mensch und Maschine, Realität und Zukunft verbindet und uns in eine intelligentere und bessere Gesellschaft führt.
Quellen:
https://m.163.com/dy/article/J69LAFDR0512MLBG.html
https://36kr.com/p/1987021834257154
https://hub.baai.ac.cn/view/211








