Command Palette
Search for a command to run...
Exklusive Chinesische Untertitel! Der KI-Frühlingskurs Des LeCun-Studenten Alfredo Beginnt; Download Des CVPR'24-Fernerkundungsdatensatzes

Kürzlich veröffentlichte Alfredo Canziani, Assistenzprofessor für Informatik an der New York University und Student von Yann LeCun, seinen Frühjahrskurs „KI“, der Themen wie diskrete Wahrscheinlichkeit und naive Bayes-Theorie, Perzeptronen und logistische Regression, Optimierung, Statistik und neuronale Verarbeitung natürlicher Sprache, Klassifizierung neuronaler Netze, rekurrierende neuronale Netze und faltende neuronale Netze behandelt.
Diese Woche überträgt HyperAI den Kurs rund um die Uhr live auf B Station. Lass uns gemeinsam lernen~
Link ansehen:
http://live.bilibili.com/26483094
Vom 24. bis 28. Juni gibt es Updates auf der offiziellen Website von hyper.ai:
- Hochwertige öffentliche Datensätze: 10
- Hochwertige Tutorial-Auswahl: 3
- Community-Artikelauswahl: 4 Artikel
- Beliebte Enzyklopädieeinträge: 5
- Top-Konferenzen mit Deadlines im Juli: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. GeoChat Instruct Remote Sensing Multimodal Instruction Tracking Dataset
Der Datensatz enthält fast 318.000 Anweisungen und zielt darauf ab, die multimodale Anweisungsanpassung auf den Bereich der Fernerkundung auszuweiten, um Multitasking-Konversationsassistenten zu trainieren. Die entsprechenden Ergebnisse des Papiers wurden von CVPR 2024 angenommen.
Direkte Verwendung:https://go.hyper.ai/CXu0K
2. RRSIS-D Großer Datensatz zur Fernerkundungsbildsegmentierung
Der Datensatz enthält 17.402 Bildbeschreibungsmasken-Tripletts, die eine Vielzahl von räumlichen Auflösungen und Objektausrichtungen abdecken. Die entsprechenden Ergebnisse des Papiers wurden von CVPR 2024 angenommen.
Direkte Verwendung:https://go.hyper.ai/1VRQG
3. Earth Parser-Datensatz Fernerkundungs-Kartierungs-Datensatz
Dieser Datensatz wird zum Trainieren und Bewerten von Analysemethoden für große, nicht kuratierte LiDAR-Luftscans verwendet. Der Datensatz enthält 7 Szenen, die eine Fläche von mehr als 7,7 Quadratkilometern und insgesamt 98 Millionen 3D-Punkte abdecken. Die entsprechenden Ergebnisse des Papiers wurden von CVPR 2024 angenommen.
Direkte Verwendung:https://go.hyper.ai/3pFjm
4. Harvard-GF3300-Datensatz zu neurologischen Netzhauterkrankungen (Glaukom)
Bei diesem Datensatz handelt es sich um einen Datensatz zu neurologischen Erkrankungen der Netzhaut (Glaukom), der 3.300 Personen umfasst und 2D- und 3D-Bilddaten enthält. Der Datensatz enthält eine gleiche Anzahl von Personen aus den drei großen ethnischen Gruppen (Weiße, Schwarze und Asiaten), wodurch Probleme mit der Datenausgewogenheit vermieden werden, die zu Problemen beim fairen Lernen führen könnten.
Direkte Verwendung:https://go.hyper.ai/vIhu6
5. Dentale Röntgenbilder zur Analyse Dentaler Röntgenbilddatensatz
Dieser Datensatz enthält verschiedene Röntgenbilder der kieferorthopädischen Zahntomographie (OPG), 70 hochwertige Beispiele. Durch die Bereitstellung von Anmerkungen kann dieser Datensatz zum Trainieren und Testen von Modellen des maschinellen Lernens für Aufgaben der zahnmedizinischen Bildanalyse wie Zahntypklassifizierung, Anomalieerkennung usw. verwendet werden.
Direkte Verwendung:https://go.hyper.ai/vK9zz
6. Röntgendatensatz für Frakturen in mehreren Regionen
Der Datensatz enthält Röntgenbilder von Frakturen und Nichtfrakturen aller anatomischen Körperregionen, einschließlich der unteren und oberen Gliedmaßen, der Lendenwirbelsäule, der Hüften, Knie usw. Der Datensatz ist in Trainings-, Test- und Validierungsordner unterteilt und enthält insgesamt 10.580 radiologische Bilddaten (Röntgenbilder).
Direkte Verwendung:https://go.hyper.ai/Yk1bA
7. Datensatz zur Bilderkennung von Obst und Gemüse
Der Datensatz enthält Bilder von 10 Obstsorten und 26 Gemüsesorten. Jede Kategorie ist in Trainings-, Test- und Validierungssätze unterteilt, wodurch ein vielfältiger Satz für Bilderkennungsaufgaben bereitgestellt wird.
Direkte Verwendung:https://go.hyper.ai/FdfRK
Der Datensatz enthält Informationen zu 15.939 beliebten Charakteren aus verschiedenen Medientypen und Genres. Jeder Eintrag enthält Details zur Figur, zur Medienquelle und zu einer einzigartigen Szene mit der Figur.
Direkte Verwendung:https://go.hyper.ai/wf1q1
9. RepLiQA ist ein möglicher Frage-Antwort-Datensatz für Benchmarking
RepLiQA ist ein Evaluierungsdatensatz mit „Kontext-Frage-Antwort“-Tripeln zu 17 Themen oder Dokumentkategorien, der die Fähigkeit großer Sprachmodelle (LLMs) testen soll, Kontextinformationen in bereitgestellten Dokumenten zu finden und zu verwenden.
Direkte Verwendung:https://go.hyper.ai/ZkSYD
10. CS-Eval Großer Modelldatensatz zur Netzwerksicherheitsbewertung
Der Datensatz umfasst 11 Hauptbereiche der Netzwerksicherheit, 42 Unterbereiche und 4.369 Multiple-Choice-Fragen, Richtig-oder-Falsch-Fragen und Fragen zur Wissensextraktion. Es bietet umfassende, auf Wissen und Praxis basierende Bewertungsaufgaben, unterstützt die Selbstbewertung der Benutzer und bietet Referenz und Inspiration für die Implementierung groß angelegter Modelle in der Netzwerksicherheit.
Direkte Verwendung:https://go.hyper.ai/ziacf
Weitere öffentliche Datensätze finden Sie unter:
Ausgewählte öffentliche Tutorials
1. Demo zur hierarchischen Vorhersage der biologischen Klassifizierung von Bioclip
Mit dieser Tutorial-Demo können Sie ein gegebenes biologisches Bild nach Familie, Gattung, Art usw. klassifizieren. Es handelt sich um die Gradio-Version des Modells in der besten Studentenarbeit „BioCLIP: A Vision Foundation Model for the Tree of Life“ von CVPR2024.
Online ausführen:https://go.hyper.ai/OEWk1
2. InstantStyle - ein konsistenter Bildgenerator
InstantStyle ist ein vom InstantX-Team von Xiaohongshu entwickeltes Framework zur Text-zu-Bild-Generierung, das eine Stilübertragung ermöglicht und gleichzeitig die Textsteuerbarkeit des Inhalts beibehält. Dieses Tutorial hat die entsprechende Umgebung für Sie erstellt und Sie können sie mit einem Klick erleben!
Online ausführen:https://go.hyper.ai/E6GuW
Bei diesem Modell handelt es sich um ein chinesisches Chat-Modell, das auf dem Meta-Llama-3-8b-Instruct-Modell basiert und speziell auf Chinesisch abgestimmt ist. Im Vergleich zum ursprünglichen Meta-Llama-3-8b-Instruct-Modell wurde die Anzahl der „chinesischen Fragen mit englischen Antworten“ und der gemischten chinesischen und englischen Fragen erheblich reduziert. Klonen und starten Sie einfach den Container und kopieren Sie die generierte API-Adresse direkt, um die Inferenz auf dem Modell zu erleben.
Online ausführen:https://go.hyper.ai/BLHcM
Community-Artikel
Wissenschaftler aus Großbritannien und Japan verwendeten maschinelle Lerntechnologie, um ein Forschungssystem zu entwickeln, das forscher- und datengesteuerte Methoden kombiniert, und produzierten erfolgreich den weltweit stärksten bekannten supraleitenden Magneten auf Eisenbasis. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Ereignisdetails anzeigen:https://go.hyper.ai/RxV9x
Auf der Beijing Zhiyuan Conference stellte Professor Li Jianping, Vizepräsident des Ersten Krankenhauses der Peking-Universität und Direktor des Instituts für Herz-Kreislauf-Medizin, unter dem Motto „Methoden und Schwierigkeiten bei der Vorhersage klinischer Myokardischämie“ neue Erkenntnisse und Verfahren der KI bei der Diagnose koronarer Herzkrankheiten und der Vorhersage klinischer Myokardischämie vor. Dies bietet einen neuen Ansatz für die Diagnose und Behandlung von Patienten mit koronarer Herzkrankheit und erweitert den Fokus vom Herzen auf die Nieren, wodurch die KI voraussichtlich eine größere Rolle in der klinischen Medizin spielen wird. Dieser Artikel ist eine ausführliche Zusammenfassung der Rede.
Lesen Sie das ganze Interview:https://go.hyper.ai/5X9jM
Ein Forschungsteam der Tsinghua-Universität schlug ein Großzellmodell namens sc-Foundation vor, das anhand von Genexpressionsdaten von 50 Millionen Zellen trainiert wird. Es verfügt über 100 Millionen Parameter und kann etwa 20.000 Gene gleichzeitig verarbeiten. Als Basismodell zeigt es eine hervorragende Leistungsverbesserung bei verschiedenen nachgelagerten biomedizinischen Aufgaben, wie etwa der Verbesserung der Zellsequenzierungstiefe, der Vorhersage der Zellreaktion auf Arzneimittel und der Vorhersage von Zellstörungen. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/v5i5K
Kürzlich berichtete Professor Zhou Hao vom Institute of Intelligent Industries der Tsinghua-Universität als Informatiker über die zahlreichen Herausforderungen, denen sich KI-Experten beim Proteindesign gegenübersehen, und beschrieb die neuesten Spitzenforschungen im Proteinbereich aus drei Blickwinkeln: Datenstruktur, Generierungsalgorithmus und Protein-Vortraining. Dieser Artikel berichtet über die ausführlichen Ausführungen von Professor Zhou Hao.
Den vollständigen Bericht ansehen:https://go.hyper.ai/PTyAp
Beliebte Enzyklopädieartikel
1. Skalierungstheorem Skalierungsgesetz
2. Reziproke Ranking-Fusion RRF
3. Neuronales Strahlungsfeld (NeRF)
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kolmogorov-Arnold-Darstellungssatz
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Vorschau auf die Live-Übertragung von Station B
AIfredo Canziani ist Assistenzprofessor für Informatik an der New York University und Student von Yann LeCun. Vor Kurzem hat er sein Frühlingsvideo „KI-Kurs“ veröffentlicht. Zu den in jedem Kapitel vermittelten Wissenspunkten gehören: diskrete Wahrscheinlichkeit und naiver Bayes; Perzeptron und logistische Regression; Optimierung, Statistik und neuronale Verarbeitung natürlicher Sprache; Klassifizierung neuronaler Netzwerke usw. Diese Woche überträgt Super Neuro TV den Kurs rund um die Uhr live.
Die folgende Tabelle ist eine Vorschau der vom Herausgeber ausgewählten Inhalte ↓↓↓
| Datum | Zeit | Inhalt |
|---|---|---|
| Montag, 1. Juli | 18:00 | Teil 1: Einführung in Naive Bayes |
| Dienstag, 2. Juli | 18:00 | Teil 2 Naive Bayes-Klassifikation |
| Mittwoch, 3. Juli | 18:00 | Teil 3 Naive Bayes-Parameterschätzung und Laplace-Glättung |
| Donnerstag, 4. Juli | 18:00 | Teil 4. Auswertung binärer Klassifikatoren |
| Freitag, 5. Juli | 18:00 | Teil 5 Multiklassen-Perzeptronen Binäre und Multiklassen-Logistische Regression |
| Samstag, 6. Juli | 18:00 | Teil 6 Optimierung und Gradientenanstieg |
| Sonntag, 7. Juli | 18:00 | Alfredo Canzianis Vortrag über energiebasiertes selbstüberwachtes Lernen |
Super Neuro TV sendet rund um die Uhr live. Klicken Sie hier, um die „elektronischen Gurken“ im KI-Bereich zu erhalten:
http://live.bilibili.com/26483094
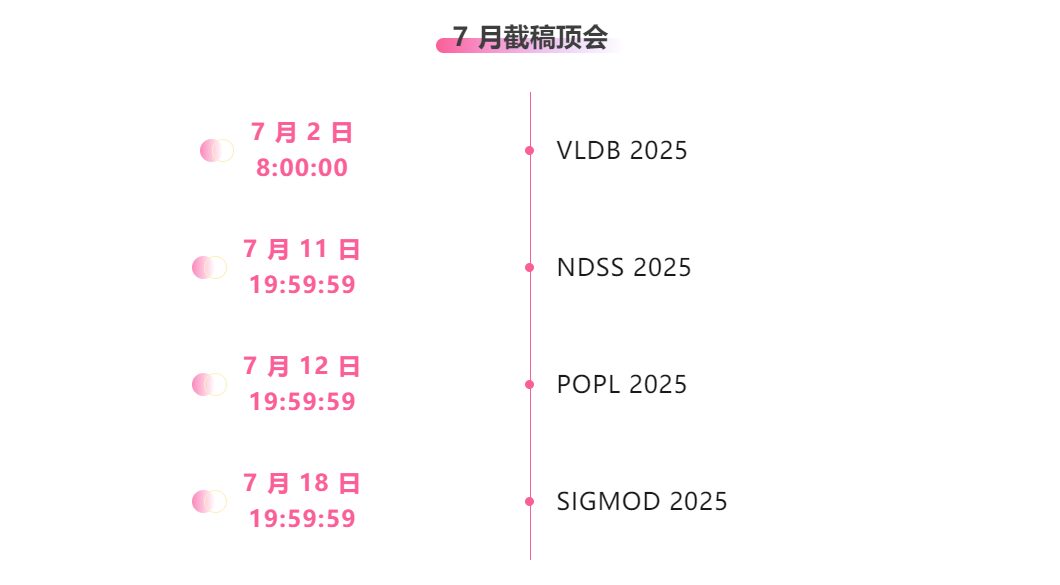
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://hyper.ai/events
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China. Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
- Bereitstellung von inländischen beschleunigten Download-Knoten für über 1300 öffentliche Datensätze
- Enthält über 400 klassische und beliebte Online-Tutorials
- Interpretation von über 100 AI4Science-Papierfällen
- Unterstützt die Suche nach über 500 verwandten Begriffen
- Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








