Command Palette
Search for a command to run...
Das Offline-Treffen „Meet AI Compiler Beijing“ 2024 Ist Geplant! InfinityInstruct, Ein Datensatz Zur Feinabstimmung Von Zig Millionen Anweisungen, Ist Jetzt Open Source

Hochwertige Anweisungsdaten sind eine unverzichtbare Ressource für das Training und die Optimierung großer Sprachmodelle und bilden den Grundstein für die Verbesserung der Modellleistung. Vor Kurzem hat die Beijing Academy of Artificial Intelligence das Open-Source-Projekt InfinityInstruct veröffentlicht, das zig Millionen hochwertige Datensätze zur Feinabstimmung von Anweisungen enthält, darunter hochwertige, gefilterte Daten auf der Grundlage von Open-Source-Datensätzen und hochwertige, durch Datensynthesemethoden erstellte Anweisungsdaten.
Die erste Charge von 3 Millionen hochwertigen chinesischen und englischen Anweisungsdatensätzen InfInstruct-3M, die modellverifiziert wurden, wurden auf dieser Konferenz als Open Source bereitgestellt.Jetzt auf der offiziellen Website von hyper.ai verfügbar. Sie können diesen Datensatz verwenden und das Basismodell mit Ihren eigenen Anwendungsdaten optimieren, um schnell ein hochwertiges, exklusives zweisprachiges Dialogmodell für Chinesisch und Englisch zu erstellen.
Vom 10. bis 14. Juni gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Ausgewählte hochwertige Tutorials: 2
* Community-Artikelauswahl: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
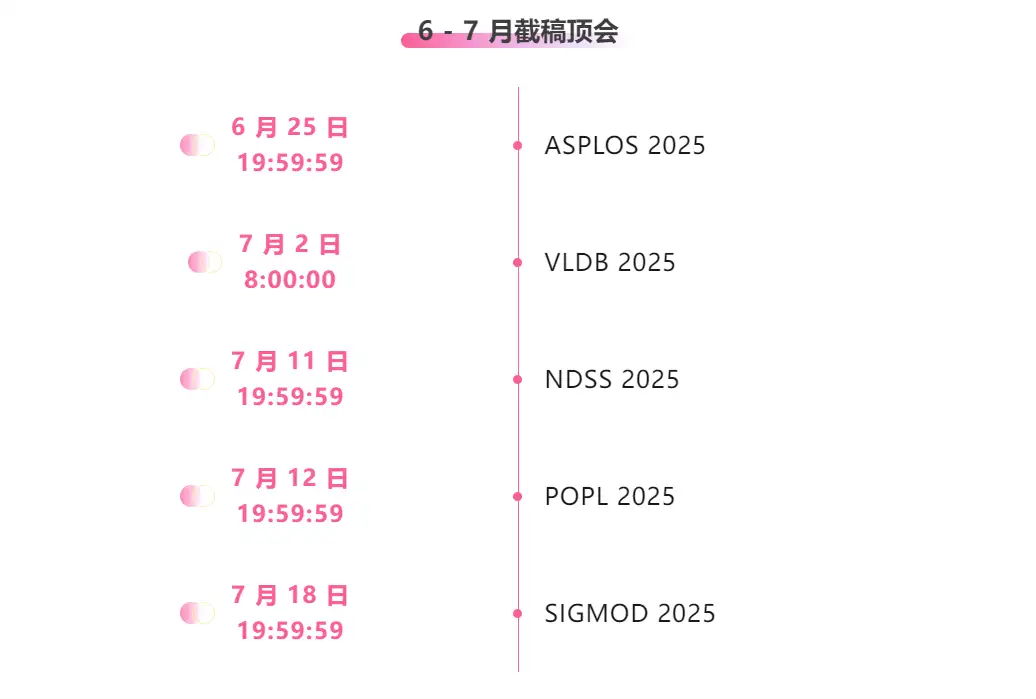
* Top-Konferenzen mit Deadlines im Juni und Juli: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. InfInstruct-3M startet einen Datensatz mit 10 Millionen Anweisungen zur Feinabstimmung
Der Datensatz wurde von der Beijing Academy of Artificial Intelligence veröffentlicht. Das Ziel des Projekts besteht darin, einen Datensatz mit Millionen von Anweisungen zu entwickeln, um die Anweisungsverfolgungsfunktionen großer Sprachmodelle zu unterstützen und dadurch die Modellleistung zu verbessern. Bei dieser Version handelt es sich um den InfinityInstruct-3M-Befehlsdatensatz. Die endgültige Version wird voraussichtlich Ende Juni veröffentlicht.
Direkte Verwendung:https://go.hyper.ai/iG7gN
2. LooGLE Long Context Understanding Benchmark-Datensatz
Bei diesem Datensatz handelt es sich um einen Benchmark-Datensatz, der dazu dient, die Fähigkeiten künstlicher Intelligenzsysteme im Hinblick auf das Verständnis langfristiger Zusammenhänge zu bewerten und zu verbessern. Das zugehörige Forschungspapier wurde von ACL2024 angenommen.
Direkte Verwendung:https://go.hyper.ai/S6dSZ
3. InternVid-Full Hochwertiger, groß angelegter Video-Text-Datensatz
Der Datensatz enthält über 7 Millionen Videos mit detaillierten Textbeschreibungen, die 16 Szenen und etwa 6.000 Aktionsbeschreibungen mit einer Gesamtdauer von fast 760.000 Stunden abdecken. Das zugehörige Papier wurde auf der International Conference on Representation Learning (ICLR 2024) 2024 im Rampenlicht gerückt.
Direkte Verwendung:https://go.hyper.ai/AnaLl
4. LoveDA Fernerkundungs-Landbedeckungsdatensatz für domänenadaptive semantische Segmentierung
Bei diesem Datensatz handelt es sich um einen Landbedeckungsdatensatz für die Fernerkundung, der speziell für die domänenadaptive semantische Segmentierung entwickelt wurde und 5.987 hochauflösende Bilder und 166.768 annotierte semantische Objekte enthält.
Direkte Verwendung:https://go.hyper.ai/ShKyN
5. CityGen-Bilddatensatz für städtische Gebäude
Bei diesem Datensatz handelt es sich um einen Bilddatensatz mit Schwerpunkt auf städtischen Gebäuden. Es enthält normalerweise eine große Anzahl von Bildern städtischer Gebäude. Diese Bilder können zum Trainieren und Bewerten von Computer-Vision-Modellen verwendet werden, insbesondere bei Aufgaben wie Gebäudeerkennung, semantischer Segmentierung und Instanzsegmentierung. Die entsprechenden Ergebnisse wurden in CVPR 2024 aufgenommen.
Direkte Verwendung:https://go.hyper.ai/ddNqv
6. Abfallklassifizierung Datensatz zur Klassifizierung von Wertstoffen und Hausmüll
Der Datensatz enthält 15.000 Bilder (je 256 × 256 Pixel) zu verschiedenen wiederverwertbaren Materialien, allgemeinem Abfall und Haushaltsgegenständen in 30 verschiedenen Kategorien und stellt eine reichhaltige und vielfältige Ressource für Forschung und Entwicklung im Bereich der Abfallsortierung und des Recyclings dar.
Direkte Verwendung:https://go.hyper.ai/kOiKG
7. VÖGEL 525 ARTEN 525 Vogelbilddatensatz
Der Datensatz enthält 525 Vogelarten, 84.635 Trainingsbilder, 2.625 Testbilder und 2.625 Validierungsbilder.
Direkte Verwendung:https://go.hyper.ai/pfw5d
8. OpenEarthMap Globaler hochauflösender Benchmark-Datensatz zur Landbedeckungskartierung
Der Datensatz besteht aus 2,2 Millionen Clips aus 5.000 Luft- und Satellitenbildern, die 97 Regionen in 44 Ländern auf 6 Kontinenten abdecken, mit manuell annotierten Landbedeckungsbezeichnungen von 8 Klassen bei einer Bodenabtastdistanz von 0,25–0,5 Metern. Die relevanten Ergebnisse der Studie wurden in WACV 2023 aufgenommen.
Direkte Verwendung:https://go.hyper.ai/ubxmO
9. OpenMantra-Datensatz zur Auswertung maschineller Comic-Übersetzungen
Dieser Datensatz ist ein Datensatz zur maschinellen Übersetzungsbewertung für japanische Comics. Es enthält Comics in fünf verschiedenen Stilen (Fantasy, Romantik, Kampf, Spannung und Leben). Der Datensatz enthält insgesamt 1.593 Sätze, 848 Szenen und 214 Comicseiten. Es wurde vom Mantra-Team der Universität Tokio veröffentlicht.
Direkte Verwendung:https://go.hyper.ai/ISqUR
10. DTD-Texturerkennungsdatensatz
Der Datensatz besteht aus 5.640 Bildern, die entsprechend der menschlichen Wahrnehmung in 47 Kategorien mit jeweils 120 Bildern unterteilt sind. Für jedes Bild wird außerdem eine Liste mit Schlüsselattributen und gemeinsamen Attributen bereitgestellt.
Direkte Verwendung:https://go.hyper.ai/aUYi3
Weitere öffentliche Datensätze finden Sie unter:
Ausgewählte öffentliche Tutorials
1. Führen Sie die Demo des TripoSR-Modells online aus
TripoSR wurde gemeinsam von Stability AI und Tripo AI entwickelt. Es kann innerhalb von 1 Sekunde hochwertige 3D-Modelle aus einem einzigen Bild generieren und hat einen geringen Rechenleistungsbedarf, sodass normale Benutzer es problemlos auf lokalen Geräten verwenden können. Dieses Tutorial hat die Umgebung für Ihre Bequemlichkeit eingerichtet.
Online ausführen:https://go.hyper.ai/is9qe
2. LGM Große Multi-View-Gaußsche Modellgenerierungsdemo
LGM (Large Multi-View Gaussian Model) ist ein innovatives Framework zum Generieren hochauflösender 3D-Modelle aus Textaufforderungen oder Einzelansichtsbildern. Mit dieser Methode können 3D-Objekte innerhalb von 5 Sekunden generiert und die Trainingsauflösung auf 512 erhöht werden, wodurch die Generierung hochauflösender 3D-Inhalte erreicht wird. Dieses Tutorial ist eine Demoimplementierung von LGM.
Online ausführen:https://go.hyper.ai/pFnhg
Wir haben außerdem eine Tutorial-Austauschgruppe zum Thema „Stabile Diffusion“ eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~
Community-Artikel
1. Eventvorschau | 2024 Meet AI Compiler – Premiere in Peking für den 6. Juli geplant!
Das erste Meet AI Compiler Beijing-Treffen findet am 6. Juli 2024 im Hörsaal im ersten Stock des Instituts für Computertechnologie der Chinesischen Akademie der Wissenschaften statt! Wir haben das Glück, zu diesem Meetup viele hochrangige KI-Compiler-Experten von der Shanghai Jiao Tong University, dem Institute of Computing Technology der Chinesischen Akademie der Wissenschaften, Microsoft Research Asia usw. einladen zu können. Sie werden Ihnen großartige Grundsatzreden und Diskussionsrunden bieten und mit Ihnen die Anwendung und Durchbrüche der KI-Compiler-Technologie in praktischen Szenarien diskutieren.Klicken Sie auf „Originaltext lesen“, um sich anzumelden und teilzunehmen!
Vollständige Veranstaltungsinformationen anzeigen:https://go.hyper.ai/EA1uw
Letzte Woche hat Apple Apple Intelligence veröffentlicht und wichtige Updates für iOS 18 und Siri vorgestellt. Die zuvor gemunkelte Zusammenarbeit zwischen Apple und OpenAI wurde endlich offiziell angekündigt. Siri, das ChatGPT integriert, ist natürlicher, kontextbezogener und personalisierter geworden und kann tägliche Aufgaben vereinfachen und beschleunigen. Dieser Artikel stellt die Updates von Apple Intelligence, Siri und iOS 18 vor und geht auch auf die Entwicklungsgeschichte von Siri ein, was die Bedeutung der Aktualisierung der KI-Funktionen von Apple für Siri weiter verdeutlichen kann.
Den vollständigen Bericht ansehen:https://go.hyper.ai/kWmHC
Ein gemeinsam von der School of Computer and Software der Universität Shenzhen und dem Intelligent Health Research Center der Hong Kong Polytechnic University gebildetes Team hat ein neuartiges Echokardiographie-Videosegmentierungsmodell MemSAM vorgeschlagen. Das Modell erreicht mit einer kleinen Anzahl von Punkthinweisen eine Leistung auf dem neuesten Stand der Technik und eine Leistung, die mit vollständig überwachten Methoden mit begrenzten Anmerkungen vergleichbar ist, wodurch die für Videosegmentierungsaufgaben erforderlichen Hinweis- und Anmerkungsanforderungen erheblich reduziert werden. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/2s73Q
Dr. Jianmin Wang und andere von der Yonsei-Universität kombinierten Deep Learning mit generativer KI, indem sie ein Transformer-basiertes generatives neuronales Netzwerk verwendeten, um den Konformationssatz von Protein-Protein-Komplexen zu erlernen und zu erforschen und die Schlüsselreste zu erlernen, die die Konformation und den dynamischen Mechanismus von Protein-Protein-Komplexen aus mehreren molekulardynamischen Trajektorien beeinflussen, und so mechanistische Einblicke in die Protein-Protein-Bindung zu gewinnen. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/MdgoV
Beliebte Enzyklopädieartikel
1. Reziproke Ranking-Fusion RRF
2. Maskierte Sprachmodellierung (MLM)
3. Lernrate
4. YOLOv10 Echtzeit-End-to-End-Objekterkennung
5. Kolmogorov-Arnold-Darstellungssatz
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Vorschau auf die Live-Übertragung von Station B
Jeff Dean ist leitender Forscher und Informatiker bei Google. Er ist bekannt für seine Pionierarbeit im Bereich verteilter Systeme und künstlicher Intelligenz, einschließlich der Entwicklung von MapReduce und TensorFlow, und eine der Schlüsselfiguren in der technologischen Entwicklung von Google. Diese Woche überträgt Super Neuro TV die Reden und Interviews von Jeff Dean live.
Die folgende Tabelle ist eine Vorschau der vom Herausgeber ausgewählten Inhalte ↓↓↓
| Datum | Zeit | Inhalt |
| Montag, 17. Juni | 18:00 | Jeff Dean über die fünf Trends im maschinellen Lernen |
| Dienstag, 18. Juni | 18:00 | Lassen Sie KI allen dienen |
| Mittwoch, 19. Juni | 18:00 | Jeff Deans positiver Ausblick auf die Zukunft der KI |
| Donnerstag, 20. Juni | 18:00 | Jeff Deans Rede auf der Stanford Medical Big Data Conference |
| Freitag, 21. Juni | 18:00 | Jeff Deans Vortrag über Deep Learning |
| Samstag, 22. Juni | 18:00 | Google Brain & Brain Residency |
| Sonntag, 23. Juni | 18:00 | Jeff Dean erläutert, wie Deep Learning zur Problemlösung eingesetzt werden kann |
Super Neuro TV sendet rund um die Uhr live. Klicken Sie hier, um die „elektronischen Gurken“ im KI-Bereich zu erhalten:
http://live.bilibili.com/26483094
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://hyper.ai/events
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung inländischer beschleunigter Download-Knoten für über 1300 öffentliche Datensätze
* Enthält über 400 klassische und beliebte Online-Tutorials
* Interpretation von über 100 AI4Science-Papierfällen
* Unterstützt die Suche nach über 500 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








