Command Palette
Search for a command to run...
Kandidat Für Das Beste Papier Des CVPR 2024! Die Universität Shenzhen Und Die Polytechnische Universität Hongkong Haben Gemeinsam MemSAM Veröffentlicht: Anwendung Des Modells „Segment Everything“ Auf Die Segmentierung Medizinischer Videos

Laut Statistiken der Weltgesundheitsorganisation (WHO) sind Herz-Kreislauf-Erkrankungen die weltweit häufigste Todesursache. Sie fordern jedes Jahr etwa 17,9 Millionen Menschenleben und sind für 321 % aller Todesfälle weltweit verantwortlich. Bei der Echokardiographie handelt es sich um eine Ultraschalldiagnostiktechnik für Herz-Kreislauf-Erkrankungen, die aufgrund ihrer Mobilität, geringen Kosten und Echtzeitfähigkeit in der klinischen Praxis häufig eingesetzt wird. Jedoch,Die Echokardiographie erfordert eine manuelle Auswertung durch erfahrene Ärzte und die Qualität der Auswertung hängt weitgehend vom Fachwissen und der klinischen Erfahrung des Arztes ab.Dies führt häufig zu großen Unterschieden in den Bewertungsergebnissen zwischen und innerhalb der Beobachter. Daher besteht in der klinischen Praxis dringender Bedarf an automatisierten Bewertungsmethoden.
In den letzten Jahren wurden viele Deep-Learning-Methoden für die echokardiografische Videosegmentierung vorgeschlagen. Aufgrund der geringen Qualität und der begrenzten Anmerkungen der Ultraschallvideos können diese Methoden jedoch immer noch keine zufriedenstellenden Ergebnisse erzielen. In jüngster Zeit hat ein groß angelegtes visuelles Modell, das Segment Anything Model (SAM), große Aufmerksamkeit erhalten und bei vielen natürlichen Bildsegmentierungsaufgaben bemerkenswerte Erfolge erzielt.Die Anwendung von SAM auf die Segmentierung medizinischer Videos bleibt jedoch eine anspruchsvolle Aufgabe.
Auf dieser Grundlage veröffentlichte ein gemeinsames Team der School of Computer and Software der Universität Shenzhen und des Intelligent Health Research Center der Polytechnischen Universität Hongkong auf der führenden Computer-Vision-Konferenz CVPR 2024 ein Papier mit dem Titel „MemSAM: Taming Segment Anything Model for Echocardiography Video Segmentation“. In dem Papier heißt es:Die Forscher schlugen ein neuartiges Echokardiographie-Videosegmentierungsmodell MemSAM vor, das SAM auf medizinische Videos anwendet.

Das Modell verwendet Erinnerungen mit räumlich-zeitlichen Informationen als Hinweise für die Segmentierung des aktuellen Frames und verwendet einen Speicherverbesserungsmechanismus, um die Qualität des Speichers vor der Speicherung zu verbessern. Experimente mit öffentlichen Datensätzen zeigen, dass das Modell mit einer kleinen Anzahl von Punktaufforderungen eine hochmoderne Leistung erzielt und eine vergleichbare Leistung wie vollständig überwachte Methoden mit begrenzten Anmerkungen erreicht, wodurch die Anforderungen an Eingabeaufforderungen und Anmerkungen für Videosegmentierungsaufgaben erheblich reduziert werden.
Forschungshighlights:
- Diese Studie verwendet den Speicher mit räumlich-zeitlichen Informationen als Hinweis für die Segmentierung des aktuellen Frames, um die Konsistenz der Darstellung und die Segmentierungsgenauigkeit zu verbessern.
- Die Forscher schlugen außerdem ein Modul zur Gedächtnisverbesserung vor, um Erinnerungen vor der Speicherung zu verbessern und so die negativen Auswirkungen von Speckle-Rauschen und Bewegungsartefakten während der Gedächtnisübermittlung zu mildern.
- Das neue Modell weist im Vergleich zu bestehenden Modellen eine Leistung auf dem neuesten Stand der Technik auf, insbesondere erreicht es eine vergleichbare Leistung wie vollständig überwachte Methoden mit begrenzten Anmerkungen.

Papieradresse:
https://github.com/dengxl0520/MemSAM
Datensätze: 2 öffentlich verfügbare Echokardiographie-Datensätze
Die Forscher nutzten zwei weit verbreitete, öffentlich zugängliche Echokardiographie-Datensätze, um CAMUS Die Methode wird auf EchoNet-Dynamic evaluiert:
- Der CAMUS-Datensatz enthält 500 Fälle, darunter 2D-Videos mit apikaler Zweikammer- und Vierkammeransicht, und bietet außerdem Anmerkungen zu allen Frames.
- Der EchoNet-Dynamic-Datensatz enthält 10.030 2D-Apikal-Zweikammeransicht-Videos. Jedes Video stellt die Fläche des linken Ventrikels in Form eines Integrals dar, wobei nur die enddiastolische (ED) und endsystolische (ES) Phase kommentiert sind.
Um die Wirksamkeit der neuen Methode bei der halbüberwachten Videosegmentierung umfassend zu bewerten, haben die Forscher den CAMUS-Datensatz in zwei Varianten angepasst: CAMUS-Full und CAMUS-Semi. CAMUS-Full verwendet während des Trainings Anmerkungen zu allen Frames, während CAMUS-Semi Anmerkungen nur zu enddiastolischen (ED) und endsystolischen (ES) Frames verwendet. Beim Testen werden beide Datensätze anhand vollständiger Annotationen ausgewertet.
Die Forscher wählten gleichmäßig ausgewählte Videos aus dem Datensatz aus und schnitten sie auf jeweils 10 Einzelbilder zu. Durch das Zuschneiden wird sichergestellt, dass das ED-Bild das erste Bild und das ES-Bild das letzte Bild ist und die Auflösung auf 256 × 256 eingestellt wird. Der CAMUS-Datensatz ist im Verhältnis 7:1:2 in Trainingssatz, Validierungssatz und Testsatz unterteilt.
Modellarchitektur: SAM-Komponenten und Speicherkomponenten bilden das Gesamtgerüst von MemSAM
Der Gesamtrahmen des MemSAM-Modells ist in der folgenden Abbildung dargestellt.Es besteht aus zwei Teilen: SAM-Komponente und Speicherkomponente.
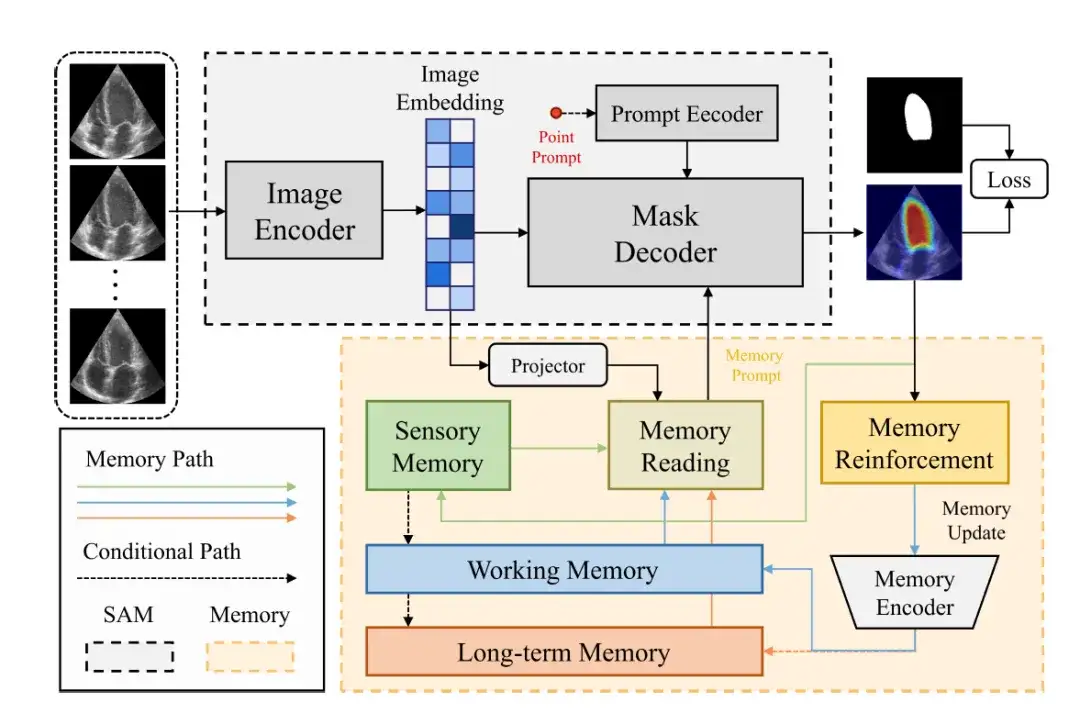
Die SAM-Komponente verwendet dieselbe Architektur wie das ursprüngliche SAM.Es besteht aus einem Bildcodierer (Image Encoder), einem Prompt-Encoder (Prompt Encoder) und einem Maskendecoder (Mask Decoder).
Der Bildcodierer verwendet Vision Transformer (ViT) als Rückgrat, um das Eingabebild in einen Bildvektor zu codieren (Image Embedding).
Der Prompt-Encoder empfängt externe Prompts, wie etwa Punkt-Prompts, und codiert sie in eine c-dimensionale Einbettung. Anschließend kombiniert der Maskendecoder das Bild und den Hinweisvektor, um die Segmentierungsmaske vorherzusagen.
In diesen Komponenten wird der Bildvektor über eine Projektionsschicht in den Merkmalsraum des Gedächtnisses abgebildet. Anschließend führen die Forscher eine Gedächtnislesung durch, um Gedächtnisaufforderungen aus mehreren Merkmalsspeichern (wie etwa dem sensorischen Gedächtnis, dem Arbeitsgedächtnis und dem Langzeitgedächtnis) zu erhalten und sie dem Maskendecoder bereitzustellen. Schließlich wird der Speicher nach dem Durchlaufen von Memory Reinforcement und Memory Encoder aktualisiert.
Die folgende Abbildung zeigt weitere Einzelheiten zum Speicherlese-, Speichererweiterungs- und Speicheraktualisierungsprozess:
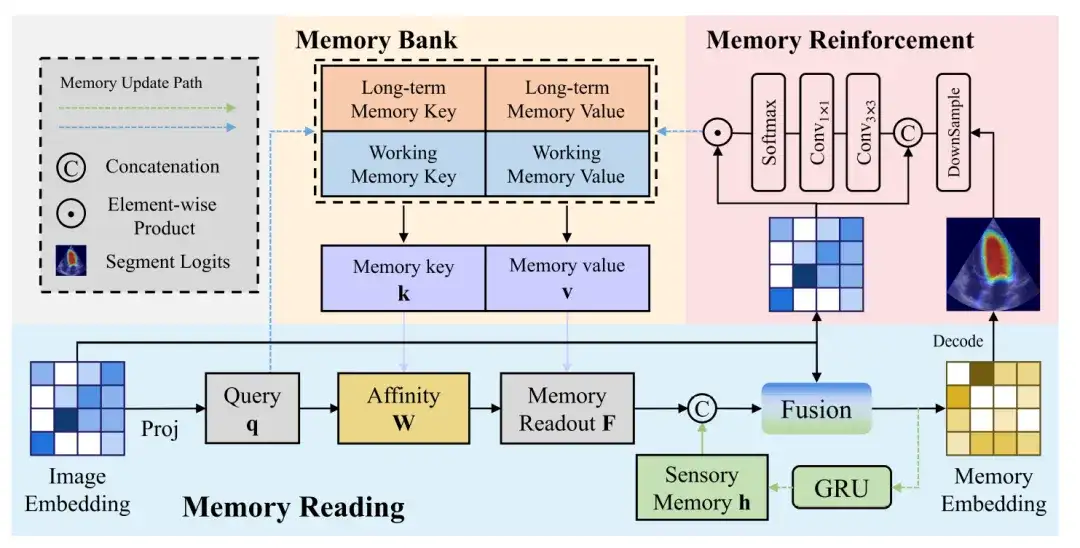
Speicherlesen
Der Speicherleseblock demonstriert den Prozess der Generierung eines Speichervektors aus einem Bildvektor. Der Bildvektor wird projiziert, um eine Abfrage zu generieren, die dann anhand der Speicherwertaffinität abgefragt wird, um den Speicherwert abzurufen. Schließlich wird der Speicherauszug mit dem sensorischen Speicher und dem Bildvektor fusioniert, um den Speichervektor zu erhalten.
Gedächtnisverbesserung
Im Vergleich zu natürlichen Bildern enthalten Ultraschallbilder komplexere Störungen, was bedeutet, dass die vom Bildcodierer erzeugten Bildvektoren zwangsläufig Störungen aufweisen. Wenn diese verrauschten Funktionen ohne jegliche Verarbeitung in den Speicher aktualisiert werden, kann dies zur Anhäufung und Ausbreitung von Fehlern führen.
Um die Auswirkungen von Rauschen auf die Speicheraktualisierung zu verringern, ist ein Speicherverbesserungsmodul erforderlich, um die Unterscheidbarkeit von Merkmalsdarstellungen im Speicher zu verbessern. Der Speicherverbesserungsblock verkettet zuerst den Bildvektor und die vorhergesagte Wahrscheinlichkeitskarte und begrenzt dann das rezeptive Feld jedes Pixels durch eine 3 × 3-Faltung, um ein lokales Aufmerksamkeitsgewichtungsmerkmal zu erzeugen.
Speicheraktualisierung
Schließlich werden die in der Speicherbank zu aktualisierenden Ausgabefunktionen durch das Skalarprodukt der Softmax-Funktion und des Bildvektors erhalten.
Forschungsergebnisse: MemSAM erreicht Spitzenleistung mit begrenzten Annotationen
Um die Leistung von MemSAM zu validieren, wählten die Forscher unterschiedliche Arten von Vergleichsmethoden aus, darunter traditionelle Bildsegmentierungsmodelle und medizinbasierte Modelle. Die drei traditionellen Bildsegmentierungsmodelle sind das CNN-basierte UNet, das Transformer-basierte SwinUNet und der CNN-Transformer-Hybrid H2Former. Zu den im medizinischen Bereich anwendbaren SAM-Modellen gehören MedSAM, MSA, SAMed, SonoSAM und SAMUS. Unter ihnen konzentrieren sich SonoSAM und SAMUS auf Ultraschallbilder.
Zunächst werden die quantitativen Vergleichsergebnisse in der folgenden Tabelle dargestellt:
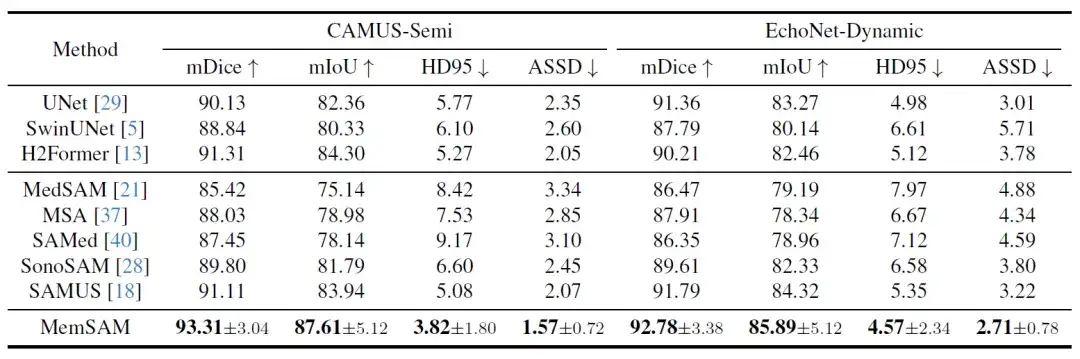
Unter diesen neuesten Methoden schneiden H2Former und SAMUS dank der CNN-Transformer-Architektur und der Ultraschallbildoptimierung bei beiden Datensätzen relativ gut ab. Bei spärlichen Anmerkungen und ohne Ausnutzung der zeitlichen Eigenschaften von Videos hinken die oben genannten Modelle jedoch der in dieser Studie vorgeschlagenen Methode hinterher.Experimente bestätigen, dass MemSAM mit begrenzten Anmerkungen die beste Leistung erzielt.
Um MemSAM weiter zu evaluieren, verglichen die Forscher auch die CAMUS-Semi- und CAMUS-Full-Datensätze unter denselben Bedingungen. Das Ergebnis ist in der folgenden Abbildung dargestellt:
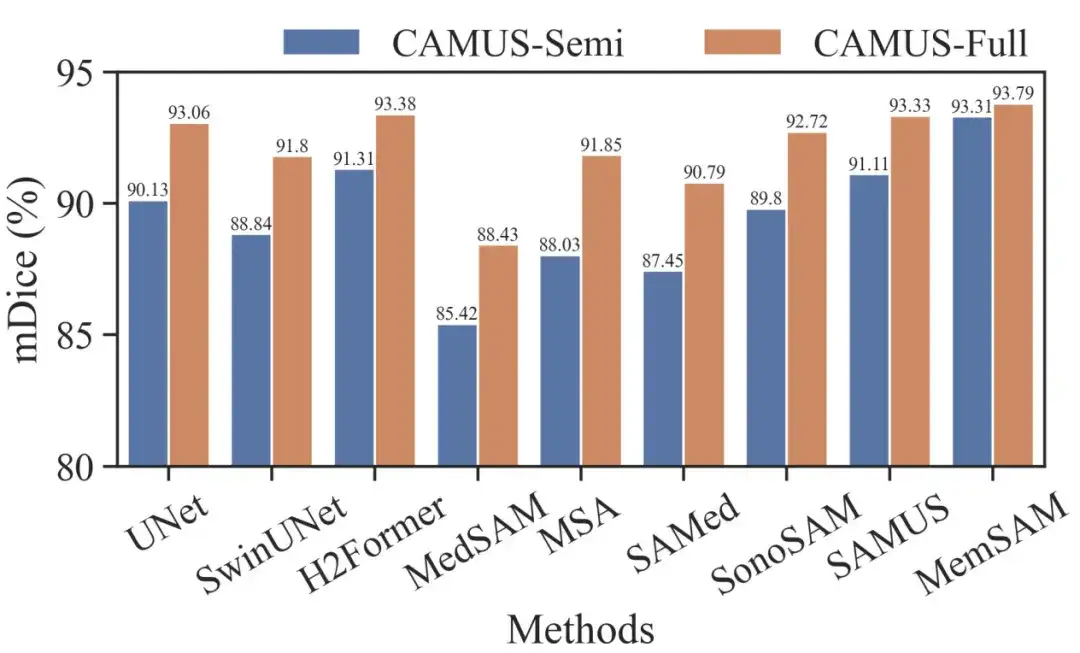
Es ist ersichtlich, dass traditionelle Methoden wie UNet und H2Former sowie auf Ultraschall spezialisierte Methoden wie SonoSAM und SAMUS bei vollständigen Annotationen anständige Segmentierungsergebnisse liefern können. Obwohl unser Ansatz von halbüberwachten zu vollständig überwachten Einstellungen geringere Vorteile bringt, übertrifft er in beiden Fällen immer noch die Leistung anderer Wettbewerber.
Es ist erwähnenswert, dass das Medical Baseline Model pro Frame Hinweise unter vollständiger Aufsicht erfordert, während MemSAM nur einen einzigen Punkthinweis erfordert.Experimente bestätigen, dass die vorgeschlagene Methode eine vergleichbare Leistung wie vollständige Anmerkungen mit spärlichen Beschriftungen und weitaus weniger externen Hinweisen erreicht.
Als nächstes folgt das qualitative Vergleichsergebnis. Die Forscher liefern Visualisierungsergebnisse für einige anspruchsvolle Fälle, wie in der folgenden Abbildung dargestellt:

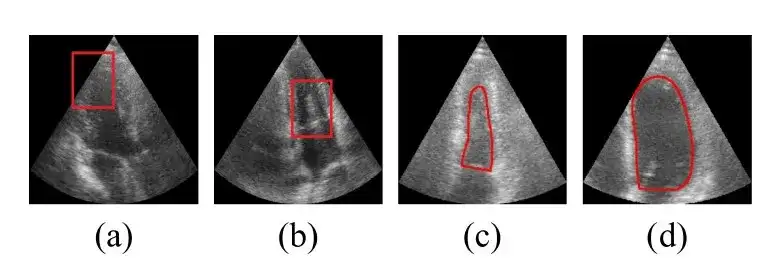
Die Bilder in den Zeilen 1–2 oben enthalten Speckle-Rauschen um die linke Herzkammer, was einige traditionelle und medizinische Modelle dazu verleitet, diese fälschlicherweise als Herzkammerrand zu identifizieren. Die Zeilen 3–4 enthalten Fälle mit stark verschwommenen Grenzen, wobei fast alle verglichenen Modelle Ergebnisse liefern, die über die wahren Ventrikelgrenzen hinausgehen, während die vorgeschlagene Methode die Grenzen genau umreißt.Diese Visualisierungsergebnisse zeigen, dass die vorgeschlagene Methode robust im Umgang mit schlechter Bildqualität ist.
KI bringt neue Ideen zur Prävention und Behandlung von Herz-Kreislauf-Erkrankungen
Herz-Kreislauf-Erkrankungen sind eine Kategorie von Herz- und Blutgefäßerkrankungen, darunter koronare Herzkrankheiten, zerebrovaskuläre Erkrankungen, rheumatische Herzkrankheiten und andere Krankheiten. In der modernen Gesellschaft haben ungesunde Ernährung, Bewegungsmangel, Rauchen und Alkoholkonsum das Risiko von Herz-Kreislauf-Erkrankungen weiter erhöht.
In den letzten Jahren hat „KI + medizinische Versorgung“ mit der Entwicklung von Technologien wie künstlicher Intelligenz und Big Data auf die Überholspur der Entwicklung gelangt. Bei der Diagnose und Vorhersage von Herz-Kreislauf-Erkrankungen hat KI große Fortschritte gemacht. Beispielsweise kann durch die Kombination von KI mit Elektrokardiogramm- und kardiovaskulären Bilddaten eine genaue Diagnose erfolgen. Durch die Kombination von KI mit kardiovaskulären Bildgebungsdaten und anderen klinischen Daten können frühzeitige Screenings und Risikovorhersagen für Herz-Kreislauf-Erkrankungen wie koronare Herzkrankheit, angeborene Herzfehler und Herzinsuffizienz erreicht werden.
Beispiel: Die genaue Klassifizierung von Herzgeräuschen ist der Schlüssel zur Frühdiagnose und Intervention bei Herz-Kreislauf-Erkrankungen. Die Wirksamkeit der künstlichen Herztonauskultation hängt noch immer vom Fachwissen des Arztes ab, aber diese Situation ändert sich langsam. Im November 2023 veröffentlichte das Team von Pan Xiangbin vom Fuwai-Krankenhaus der Chinesischen Akademie der Medizinischen Wissenschaften (Fuwai-Krankenhaus) online im Alexandria Engineering Journal eine Forschungsarbeit mit dem Titel „Klassifizierung von Herztönen basierend auf Bispektrum-Funktionen und Vision-Transformer-Modus“.In dieser Studie wurde eine binäre Klassifizierung von Herztönen auf Grundlage einer bispektral inspirierten Merkmalsextraktion und eines visuellen Transformatormodells erreicht.
Das Modell zeigte hervorragende Klassifizierungsergebnisse in der gesamten Bevölkerung (einschließlich schwangerer und nicht schwangerer Patienten) mit einer Diagnoseleistung, die der von menschlichen Experten überlegen war, was ein großes Anwendungspotenzial zeigt.
Im Oktober 2023 zeigten neue Forschungsdaten, die in der Fachzeitschrift Clinical Medicine veröffentlicht wurden, dass ECG-AI durch die Erkennung von Anzeichen einer koronaren Herzkrankheit, wie etwa Verkalkung und Verstopfungen, sowie von Hinweisen auf frühere Herzinfarkte einige Risiken Jahre früher erkennen kann als aktuelle Risikorechner.
Erst kürzlich veröffentlichte ein britisches Unternehmen namens Caristo Diagnostics das Ergebnis einer bahnbrechenden klinischen Studie im Magazin The Lancet.Ihre CaRi-Heart-KI-Technologie quantifiziert den Schweregrad einer Koronararterienentzündung und sagt Herzerkrankungen präzise voraus.
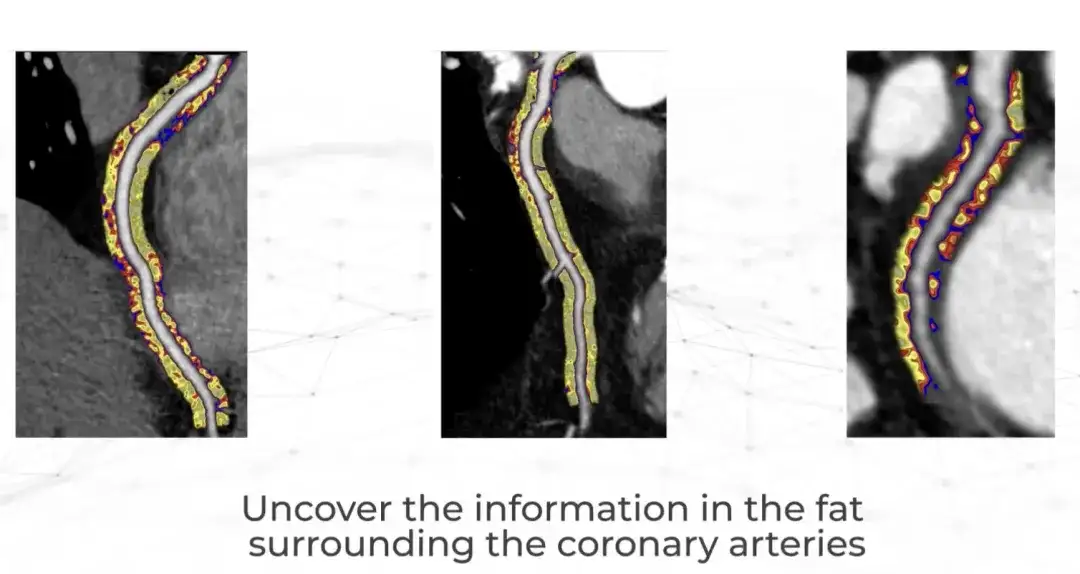
Caristo wurde 2018 von Kardiologen der Universität Oxford gegründet. Das Unternehmen machte vor über 50 Jahren eine bedeutende Forschungsentdeckung: Herzinfarkte werden durch eine Entzündung der Herzkranzgefäße verursacht, doch es war Ärzten nicht möglich, die Entzündung bei routinemäßigen Herzuntersuchungen zu beobachten und zu messen.Jetzt kann die CaRi-Heart-Technologie eingesetzt werden, um CTTA Extrahieren Sie diese Informationen aus dem Scan.Dies stellt einen wissenschaftlichen Durchbruch dar, der den traditionellen Ansatz zur Vorhersage, Vorbeugung und Behandlung von Herzerkrankungen grundlegend verändert. Berichten zufolge wurde CaRi-Heart in Großbritannien, Europa und Australien bereits klinisch eingesetzt.
Mit Blick auf die Zukunft verfügt künstliche Intelligenz über ein enormes Entwicklungspotenzial in der klinischen Diagnose und Behandlung, insbesondere in der Prävention und Behandlung von Herz-Kreislauf-Erkrankungen. Es wird Ärzten dabei helfen, Patienten effizienter und zuverlässiger genaue Diagnosen und Ratschläge zu geben.
Quellen:
1.https://m.chinacdc.cn/jkzt/mxfcrjbhsh/jcysj/201909/t20190906_205347.html
2.https://mp.weixin.qq.com/s/daqoXwnxeZxw7xC6iw1h3A
3.https://www.drvoice.cn/v2/article/12166
4.https://36kr.com/p/280080595174








