Command Palette
Search for a command to run...
Bereitstellung Von LLaMA 3 Chinese Chat Mit Einem Klick, Einschließlich Chinesischem Trainingsdatensatz; Download Des Food2K-Datensatzes Mit 2.000 Kategorien Und 1 Million Bildern

Die kürzlich erfolgte Open-Source-Veröffentlichung von Llama 3 hat alle im KI-Kreis begeistert, die Unterstützung für reines Chinesisch ist jedoch nicht sehr gut und es ist nicht möglich, flexibel auf die entsprechende Sprache umzuschalten, um chinesische Fragen zu beantworten.
Diese Woche hat hyper.ai das Bereitstellungs- und Argumentations-Tutorial von Llama 3 Chinese Chat, der chinesischen Version von Llama 3, veröffentlicht.Es löst effektiv die Peinlichkeit, „chinesische Fragen auf Englisch zu beantworten“, und macht das Gespräch natürlicher und flüssiger.Das Tutorial hat das Modell und die Umgebung bereitgestellt. Sie müssen nur die API-Adresse öffnen, um die Schlussfolgerung zu erleben!
Ich kann es kaum erwarten, ich werde es ausprobieren:
Derselbe chinesische Trainingsdatensatz:
Vom 27. bis 31. Mai gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Ausgewählte hochwertige Tutorials: 2
* Community-Artikelauswahl: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Juni: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Datensatz der chinesischen Version von Llama 3
Dieser Datensatz ist eine Sammlung chinesischer Llama 3-Datensätze. Die Daten wurden einheitlich in das Firefly-Format verarbeitet und können mit dem Firefly-Tool verwendet werden, um das chinesische Llama 3-Modell direkt zu trainieren.
Direkte Verwendung:https://go.hyper.ai/uJlfk
2. LCCC Großes, sauberes chinesisches Konversationskorpus
Der Datensatz besteht hauptsächlich aus zwei Teilen: LCCC-Basis (6,8 Millionen Dialoge) und LCCC-groß (12 Millionen Dialoge). Das Forschungsteam entwickelte einen strengen Datenfilterprozess, um die Qualität der Konversationsdaten im Datensatz sicherzustellen. Der gefilterte Datensatz kann die Forschung zur Modellierung kurzer Textkonversationen erleichtern.
Direkte Verwendung:https://go.hyper.ai/bDzEG
3. Food2K Großer Lebensmittelerkennungsdatensatz
Food2K ist ein umfangreicher Datensatz zur Lebensmittelerkennung, der 2.000 Lebensmittelkategorien und über 1 Million Bilder enthält.
Direkte Nutzung: https://go.hyper.ai/TpfUJ
4. COYO-700M Bild-Text-Paar-Datensatz
COYO-700M enthält 747 Millionen Bild-Text-Paare und viele andere Metaattribute und sammelt viele informative Alternativtexte und die zugehörigen Bildpaare in HTML-Dokumenten.
Direkte Nutzung: https://go.hyper.ai/fWI1i
5. GLH-Bridge Großflächiger Fernerkundungsbild-Brücken-Zielerkennungsdatensatz
Der Datensatz enthält 6.000 großformatige Fernerkundungsbilder mit ultrahoher Auflösung und fast 60.000 manuell annotierten Brückeninstanzen vor unterschiedlichen Hintergründen. Das Bildformat beträgt 2048 × 2048 – 16384 × 16384 Pixel und verfügt über zwei Sätze von Zielerkennungsbeschriftungen: Rotationsbox und horizontale Box.
Direkte Nutzung: https://go.hyper.ai/cHPeb
6. MMDialog Multimodaler Open Domain Multi-Turn-Dialog-Datensatz
Bei dem Datensatz handelt es sich um einen umfangreichen multimodalen Open-Domain-Dialogdatensatz, der 1,08 Millionen vollständige Dialogsitzungen, mehr als 4.000 Dialogthemen und 1,53 Millionen nicht wiederholte Bilder mit durchschnittlich 2,59 Bildern pro Dialogsitzung enthält.
Direkte Nutzung: https://go.hyper.ai/iAbI2
7. Pima Indian Diabetes-Datensatz
Der Datensatz stammt ursprünglich vom National Institute of Diabetes and Digestive and Kidney Diseases und sein Zweck besteht darin, anhand bestimmter im Datensatz enthaltener diagnostischer Messungen diagnostisch vorherzusagen, ob ein Patient an Diabetes leidet.
Direkte Nutzung: https://go.hyper.ai/XqJXe
8. LamaH-CE Mitteleuropäischer Hydrologie- und Umweltwissenschafts-Großprobendatensatz
LamaH-CE enthält Abfluss- und meteorologische Zeitreihen für 859 gemessene Wassereinzugsgebiete sowie verschiedene (Einzugsgebiets-)Attribute. Die hydrometeorologischen Zeitreihen liegen mit täglicher und stündlicher zeitlicher Auflösung vor und beinhalten Qualitätsmarker. Alle meteorologischen und die meisten Abfluss-Zeitreihen umfassen mehr als 35 Jahre.
Direkte Verwendung:https://go.hyper.ai/UPZvA
9. CAMELS-GB UK-Einzugsgebietseigenschaften und hydrometeorologischer Zeitreihendatensatz
Dieser Datensatz bietet hydrometeorologische Zeitreihen und Landschaftsattribute für 671 Einzugsgebiete im Vereinigten Königreich. Es stellt Flussströme, Einzugsgebietseigenschaften und Einzugsgebietsgrenzen aus dem britischen National River Flow Archive sowie einen neuen Satz meteorologischer Zeitreihen und Einzugsgebietseigenschaften zusammen.
Direkte Verwendung:https://go.hyper.ai/KA29l
10. HQ-Edit-Anweisungsbasierter Bildbearbeitungsdatensatz
HQ-Edit enthält etwa 200.000 Bearbeitungsbeispiele, jeweils mit einem Eingabebild, einem Ausgabebild und detaillierten Bearbeitungsanweisungen.
Direkte Verwendung:https://go.hyper.ai/xjahh
Weitere öffentliche Datensätze finden Sie unter:
Ausgewählte öffentliche Tutorials
1. Ein-Klick-Bereitstellung der Llama 3-Chinese-Chat-8b-Demo
Das in diesem Tutorial verwendete Modell ist die erste chinesische Version von Llama 3, einem Sprachmodell mit fein abgestimmten Anweisungen für chinesische und englische Benutzer und mehreren Funktionen wie Rollenspielen und Werkzeugnutzung. Klonen und starten Sie einfach den Container und kopieren Sie die generierte API-Adresse direkt, um die Inferenz auf dem Modell zu erleben.
Online ausführen:https://go.hyper.ai/i3r7D
Latte ist ein innovatives Modell zur Videogenerierung, das im November 2023 als Open Source veröffentlicht wurde. Als weltweit erstes Open-Source-Vincent-Video-DiT hat Latte vielversprechende Ergebnisse erzielt. Dieses Tutorial ist eine Demo für das Latte-Projekt.
Online ausführen: https://go.hyper.ai/LFfmt
Vorschau auf die Live-Übertragung von Station B
Apple veranstaltet die WWDC 2024 vom 10. bis 14. Juni. Damit jeder umfassende Informationen über Apple erhält, sendet der Super Neurological B Station Live Room weiterhin „Apple Special“-Videos mit Themen wie WWDC-Konferenzen der vergangenen Jahre, Interviews mit Führungskräften, entsprechenden Dokumentationen und anderen umfangreichen Inhalten.Zu diesem Zeitpunkt wird Chao Shenjing es auch live auf Video Account und Bilibili übertragen, also vereinbaren Sie jetzt einen Termin und verpassen Sie es nicht~

Die folgende Tabelle ist eine Vorschau auf die vom Herausgeber ausgewählten Live-Übertragungsinhalte für die nächste Woche ↓↓↓
| Datum | Zeit | Inhalt |
| 1. Juni Montag | 18:00 | Steve Jobs |
| Dienstag, 2. Juni | 18:00 | Was einen Apfel zu einem Apfel macht |
| Mittwoch, 3. Juni | 18:00 | Interview mit Steve Jobs vs. Bill Gates |
| Donnerstag, 4. Juni | 18:00 | Erste Veröffentlichung des iPhone |
| Freitag, 5. Juni | 18:00 | Geschichte von Steve Jobs |
| Samstag, 6. Juni | 18:00 | Wie Apple die Beinahe-Pleite überlebte |
| Sonntag, 7. Juni | 18:00 | Tim Cooks Geschichte |
Super Neuro TV sendet rund um die Uhr live. Klicken Sie hier, um die „elektronischen Gurken“ im KI-Bereich zu erhalten:
http://live.bilibili.com/26483094
Community-Artikel
Letzte Woche veröffentlichte die China Meteorological Administration erstmals den „Special Data Catalogue for Artificial Intelligence Meteorological Large Model Training“, der riesige Mengen meteorologischer Daten zusammenfasst. Der Katalog steht ab sofort auf der offiziellen Website des Meteorologischen Büros zum Download bereit. Um allen dabei zu helfen, relevante Datenressourcen zu verstehen und zu nutzen, hat HyperAI diese Woche außerdem zehn hochwertige Datensätze zu meteorologischen Katastrophen zusammengestellt, um den Fortschritt der entsprechenden Forschung besser zu fördern und ein neues Kapitel in der meteorologischen Forschung aufzuschlagen.
Detaillierte Informationen erhalten Sie:https://go.hyper.ai/kK87m
Das Team von Ouyang Chaojun vom Chengdu Institute of Mountain Hazards and Environment der Chinesischen Akademie der Wissenschaften schlug ein KI-basiertes Abfluss- und Hochwasservorhersagemodell namens ED-DLSTM vor. Durch die Kodierung der statischen Eigenschaften des Einzugsgebiets und der meteorologischen Einflussfaktoren sowie durch die Verwendung von Daten von über 2.000 hydrologischen Stationen auf der ganzen Welt zum Trainieren des Modells versuchten sie, das Problem der Abflussvorhersage in Einzugsgebieten mit und ohne weltweite Überwachungsdaten zu lösen. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/eG6H5
Die Tsinghua-Universität, die Zhejiang-Universität, die Stanford-Universität, die Brown-Universität, die Johns-Hopkins-Universität und andere in- und ausländische Universitäten haben relevante Forschungen zu Gehirn-Computer-Schnittstellen durchgeführt. Dieser Artikel beginnt mit dem Konzept und stellt die drei Hauptformen der Implementierung von Gehirn-Computer-Schnittstellen, spezifische Forschungsfälle von berühmten Universitäten im In- und Ausland, die Ethik und Sicherheit von Gehirn-Computer-Schnittstellen usw. vor.
Den vollständigen Bericht ansehen:https://go.hyper.ai/W3pPf
Das Team unter der Leitung von Ge Jian, einem Forscher am Shanghai Astronomical Observatory der Chinesischen Akademie der Wissenschaften, suchte mithilfe von Deep-Learning-Methoden in den vom Sloan Sky Survey III veröffentlichten Daten nach neutralen Kohlenstoffabsorptionslinien. Dadurch lüftete es das Geheimnis der Zusammensetzung kalter Gaswolken in frühen Galaxien und entdeckte 107 Beispiele neutraler Kohlenstoffabsorptionslinien im frühen Universum. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/qirkz
Beliebte Enzyklopädieartikel
1. Epoche
2. Neuronales Strahlungsfeld (NeRF)
3. Skalierungsgesetz
4. YOLOv10 Echtzeit-End-to-End-Objekterkennung
5. Kolmogorov-Arnold-Netzwerke
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
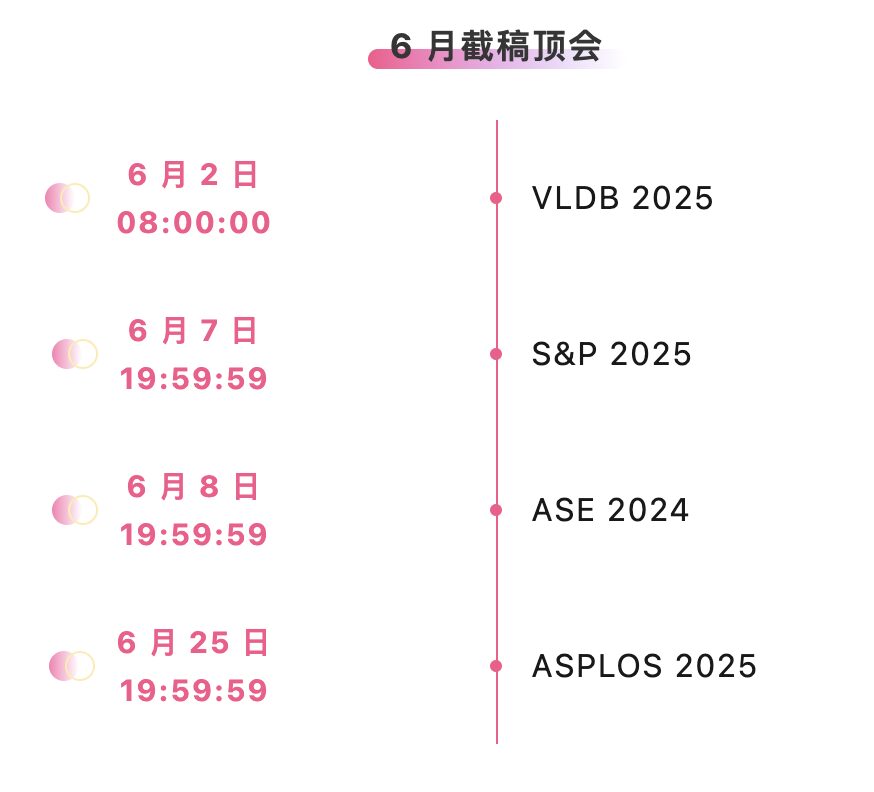
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:
https://hyper.ai/events
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1200 öffentliche Datensätze
* Enthält über 300 klassische und beliebte Online-Tutorials
* Interpretation von über 100 AI4Science-Papierfällen
* Unterstützt die Suche nach über 500 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








