Command Palette
Search for a command to run...
Das Team Der Chinesischen Akademie Der Wissenschaften Analysierte Und Trainierte Daten Von Über 2.000 Hydrologischen Stationen Weltweit Und Veröffentlichte ED-DLSTM, Um Hochwasservorhersagen in Gebieten Ohne Überwachungsdaten Zu ermöglichen.

Mit dem fortschreitenden globalen Klimawandel kommt es immer häufiger zu Überschwemmungskatastrophen. In einem gemeinsam vom Büro der Vereinten Nationen für Katastrophenvorsorge und dem Zentrum für Forschung zur Epidemiologie von Katastrophen an der Universität Leuven in Belgien veröffentlichten Bericht heißt es:In den letzten 20 Jahren hat sich die Zahl der Hochwasserkatastrophen weltweit von 1.389 auf 3.254 mehr als verdreifacht. Sie machen 401 Prozent der Gesamtzahl aller Katastrophen aus und betreffen 1,65 Millionen Menschen.
Überschwemmungen können enorme Opferzahlen und Sachschäden verursachen. Im April dieses Jahres erlitten 1,598 Millionen Menschen in 17 Provinzen (Regionen und Städten), darunter Jiangxi und Guangdong, durch Überschwemmungen und geologische Katastrophen Schäden unterschiedlichen Ausmaßes, 24 Menschen starben oder wurden vermisst, 140.300 Hektar Ackerland waren betroffen und der direkte wirtschaftliche Verlust belief sich auf 11,98 Milliarden Yuan. Die durch die Naturkatastrophen verursachten Schäden waren die höchsten im gleichen Zeitraum der letzten zehn Jahre.
Um das Risiko von Hochwasserkatastrophen zu verringern, ist es entscheidend, den Hochwasserabfluss effektiv vorherzusagen. In den letzten Jahrzehnten wurden bei der Hochwasservorhersage auf Grundlage hydrologischer Prozesse erhebliche Fortschritte erzielt. Allerdings basieren die Vorhersageergebnisse der aktuellen Methoden noch immer stark auf Überwachungsdaten und Parameterkalibrierung. Tatsächlich gibt es weltweit keine Überwachungsdaten für Becken mit mehr als 951 TP3T.Die Vorhersage von Abfluss und Hochwasser in Gebieten ohne oder mit unzureichenden Überwachungsdaten ist seit langem ein Problem der Hydrologie.
Im April 2024 veröffentlichte das Team von Ouyang Chaojun vom Chengdu Institute of Mountain Hazards and Environment der Chinesischen Akademie der Wissenschaften in The Innovation einen Artikel mit dem Titel „Deep Learning für regionenübergreifende Abfluss- und Hochwasservorhersage auf globaler Ebene“.Es wird ein KI-basiertes Abflusshochwasservorhersagemodell ED-DLSTM vorgeschlagen. Durch die Kodierung der statischen Eigenschaften des Einzugsgebiets und der meteorologischen Faktoren wird das Modell mit Daten von mehr als 2.000 hydrologischen Stationen auf der ganzen Welt trainiert. Dabei wird versucht, das Problem der Abflussvorhersage in Einzugsgebieten mit und ohne weltweit überwachte Daten zu lösen.
Forschungshighlights:
- Das ED-DLSTM-Modell liefert in beiden Becken mit und ohne Überwachungsdaten gute Ergebnisse bei der Hochwasservorhersage.
- Erstmals wurden weltweit mehrere hydrologische KI-Modelle trainiert und verglichen
- Die Kodierung räumlicher Attribute verbessert die Vorhersagekraft von Zeitreihen deutlich und erklärt die Übertragbarkeit gut.
Papieradresse:
https://doi.org/10.1016/j.xinn.2024.100617
Datensatz: Beckendaten mit signifikanten Verteilungsunterschieden
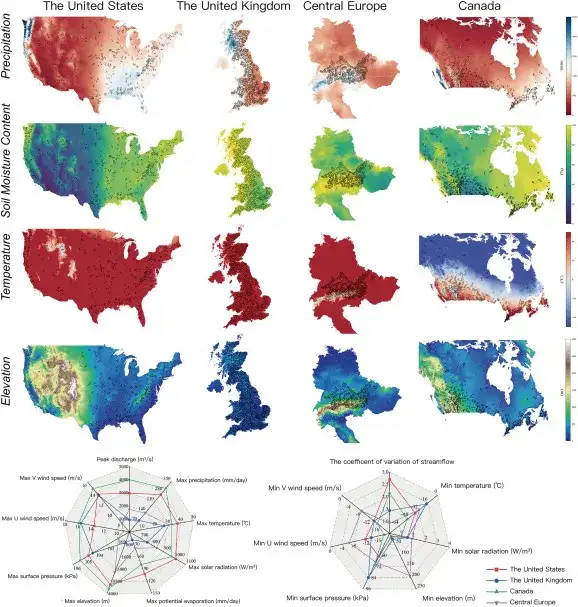
Der in dieser Studie verwendete Trainingsdatensatz stammt aus 2.089 Flusseinzugsgebieten in den Vereinigten Staaten (482 Flusseinzugsgebiete), dem Vereinigten Königreich (406 Flusseinzugsgebiete), Mitteleuropa (461 Flusseinzugsgebiete), Kanada (740 Flusseinzugsgebiete) usw., wie in der folgenden Abbildung dargestellt:
Adresse zum Herunterladen des Datensatzes:
- Amerikanische Kamele:https://go.hyper.ai/nCkDT
- CAMELS-GB:https://go.hyper.ai/DdUEf
- Mitteleuropa LamaH-CE:https://go.hyper.ai/rMHSO
- CHILE-KAMELLE-CL:https://camels.cr2.cl/
- Kanadische HYSETS:https://go.hyper.ai/l4etG
Im Allgemeinen sind die Gesamtniederschlagsmenge und der Bodenfeuchtigkeitsgehalt in der östlichen Region höher als im Westen der Vereinigten Staaten und Kanadas. Der Westen des Vereinigten Königreichs und die nördlichen schottischen Highlands weisen im Allgemeinen eine höhere durchschnittliche Bodenfeuchtigkeit und Niederschlagsmenge im Jahresdurchschnitt auf, während die Variabilität anderer Variablen relativ gering ist. In Mitteleuropa liegen die meisten Flusseinzugsgebiete im österreichischen Raum hoch im Gelände, mit hohen Niederschlägen und niedrigen Temperaturen. Die Rocky Mountains verlaufen durch die Vereinigten Staaten und Kanada. Die nahegelegenen Becken liegen hoch im Gelände, weisen hohe Niederschläge und einen hohen Bodenfeuchtigkeitsgehalt sowie niedrige Temperaturen auf. Durch die komplexen Verdunstungs- und Schneeschmelzeffekte wird der Variationskoeffizient des Abflusses noch größer.
Nach Ansicht der ForscherDie Verteilungsunterschiede der oben genannten regionalen Wassereinzugsgebiete sind erheblich und die räumliche Variabilität ist groß genug, um eine Datenvielfalt sicherzustellen, die ausreicht, um die Fähigkeit von ED-DLSTM zur regionsübergreifenden Abflussvorhersage (CSF) zu überprüfen.
Modellarchitektur: neuartiges regionsübergreifendes räumlich-zeitliches integriertes Modell ED-DLSTM
In diesem Artikel schlugen Forscher ein neuartiges regionsübergreifendes räumlich-zeitliches Integrationsmodell ED-DLSTM vor.Das Modell kombiniert statische räumliche Attribute und zeitliche Zwangsattribute.Um eine regionsübergreifende Verkehrsvorhersage zu erreichen, zeigt die folgende Abbildung die Gesamtarchitektur des ED-DLSTM-Modells:
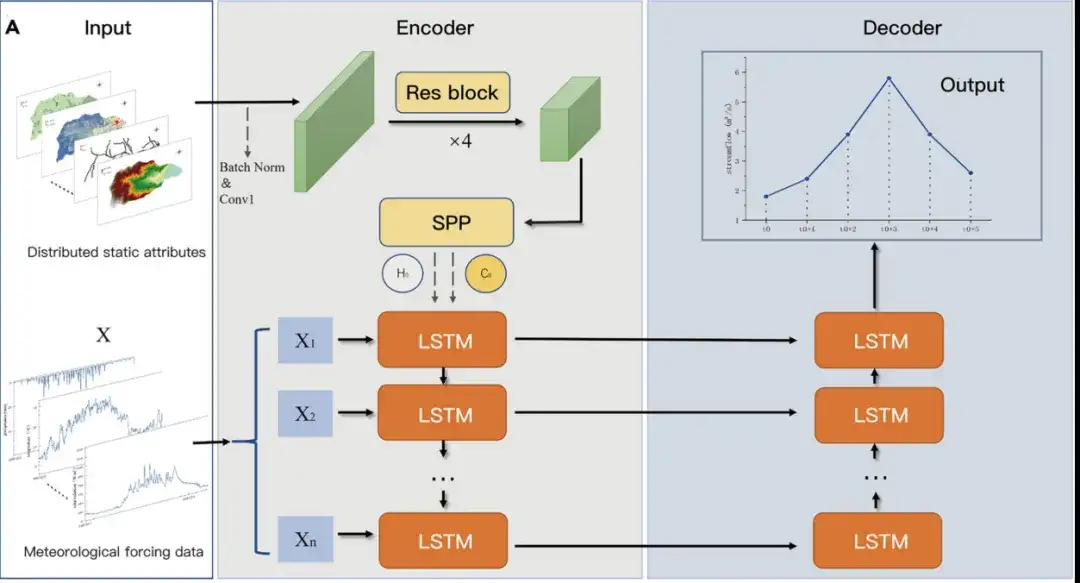
Das ED-DLSTM-Modell verwendet eine Encoder-Decoder-Struktur.Es umfasst zwei Untermodelle, die symbiotisch arbeiten und ist besser geeignet, um durch gemeinsame Modellierung globale und lokale Beckenbeziehungen zu erfassen. Wie in der obigen Abbildung gezeigt, besteht die Eingabe des Modells aus multimodalen Daten, und die eingegebenen räumlichen statischen Gitterattributdaten bilden eine relativ spärliche Matrix.
In,Der Encoder kombiniert statische Attribute mit Force-Daten.Zu den statischen Daten gehören digitale Höhenmodelle (DEMs), Ausmaß der Schneedecke, Bodenfeuchtigkeitsgehalt, Grundwassertiefe, potenzielle Evapotranspiration, Dürreindex und Flussbettgeometrie. Diese Attribute dienen dem Modell als Orientierung bei der Unterscheidung des hydrologischen Verhaltens verschiedener Regionen. Zu den erzwungenen Daten gehören Niederschlag, Sonneneinstrahlung, Lufttemperatur, Taupunkttemperatur, Oberflächendruck sowie Ost- und Nordwindgeschwindigkeiten. Diese Daten haben eine zeitliche Auflösung von 24 Stunden.
Statische Informationen verwenden gewöhnliche Faltung, um Kanäle zu integrieren, und Restfaltung wird verwendet, um räumliche statische Eigenschaften zu extrahieren. Anschließend wird Spatial Pyramid Pooling (SPP) verwendet, um die Matrixinformationen verschiedener Regionen in einen festen hochdimensionalen Raum abzubilden und so bestimmte Regionen räumlich zu kodieren. Anschließend wird der codierte Vektor als anfängliche Zustandsschicht der LSTM-Einheit verwendet.
Der Decoder ist dafür verantwortlich, mithilfe einer umgekehrten LSTM-Schicht hochrangige Funktionen auf vorhergesagte Verkehrswerte abzubilden.Die Forscher entschieden sich dafür, die Verkehrszuordnung in der letzten LSTM-Einheit durchzuführen, da die vollständigen Informationen des Seq2Seq-Modells am Ende dekodiert werden sollten und diese Dekodierungsschicht den Informationstrend umgekehrt erfassen kann. Forscher können verschiedene hydrologische Reaktionsverhalten für unterschiedliche Wassereinzugsgebiete separat kodieren und dekodieren.
Letztendlich lernt das Netzwerk die Zuordnungsbeziehung von dynamischen Zeitreihen zum beobachteten Fluss unter regionalen statischen Attributen und bietet dadurch konsistente CSF-Funktionen, die es dem Modell ermöglichen, die hydrologischen Reaktionseigenschaften verschiedener Becken abstrakt zu „erkennen“.
Forschungsergebnisse: Das ED-DLSTM-Modell verfügt über hervorragende Vorhersage- und Generalisierungsfähigkeiten
Zunächst führten die Forscher eine vergleichende Bewertung der Vorhersageglaubwürdigkeit des ED-DLSTM-Modells vom 1. Januar 2010 bis zum 1. Januar 2012 durch und bewerteten es quantitativ mithilfe der Nash-Sutcliffe-Effizienz (NSE).
- NSE (Wertebereich ist (-∞, 1]) wird verwendet, um die Simulationsergebnisse hydrologischer Modelle zu bewerten (je näher der NSE-Wert bei 1 liegt, desto konsistenter sind die Ergebnisse der Modellsimulation mit den tatsächlichen Beobachtungen, und der NSE-Wert kleiner als 0 zeigt an, dass die Ergebnisse der Modellsimulation schlecht sind).
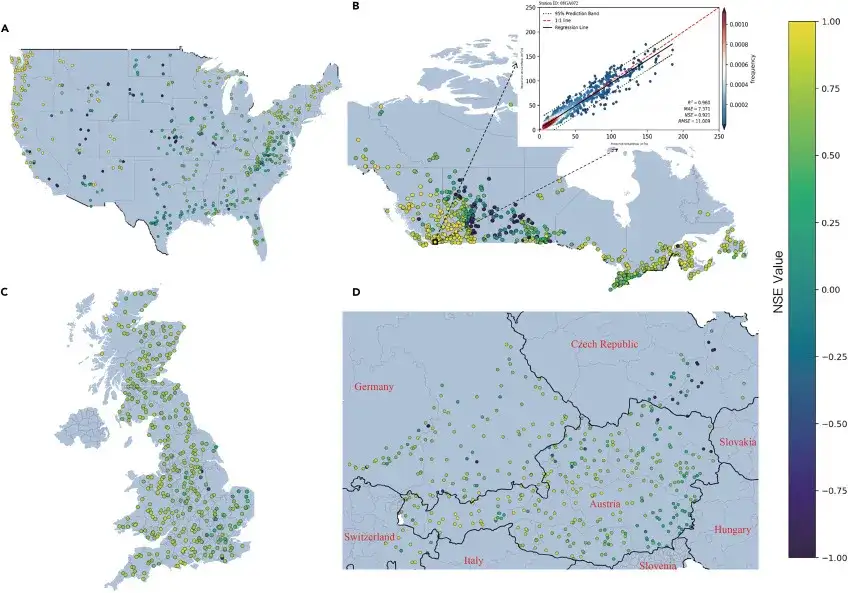
Wie in der Abbildung oben gezeigt:
- In den Vereinigten Staaten wiesen 438 der 482 analysierten Wassereinzugsgebiete einen NSE-Wert größer als 0 auf, mit einem durchschnittlichen NSE-Wert von 0,78 und einem Median-NSE-Wert von 0,80.
- In der kanadischen Region wiesen 695 der 740 analysierten Wassereinzugsgebiete NSEs größer als 0 auf, mit einem durchschnittlichen NSE von 0,80 und einem Median-NSE von 0,82.
- In Großbritannien wiesen 391 der 406 analysierten Einzugsgebiete NSEs über 0 auf, mit einem durchschnittlichen NSE von 0,68 und einem Median-NSE von 0,70.
- In Mitteleuropa weisen 433 der 461 untersuchten Flusseinzugsgebiete NSEs über 0 auf, mit einem durchschnittlichen NSE von 0,73 und einem Median-NSE von 0,79.
Gesamt,Wassereinzugsgebiete mit höheren Niederschlagsmengen oder größeren Abflusskoeffizienten liefern im Allgemeinen bessere Vorhersageergebnisse. Es ist erwähnenswert, dass der durchschnittliche NSE der 81.8%-Wassereinzugsgebiete höher als 0,6 ist, was die hervorragenden Vorhersage- und Generalisierungsfähigkeiten des ED-DLSTM-Modells unterstreicht.
Basierend auf den vorab trainierten Modellen der oben genannten vier Regionen (nördliche Hemisphäre) erstellten die Forscher Vorhersagen für 160 neue und unbekannte Becken in Chile (südliche Hemisphäre) (ohne Training mit historischen Überwachungsdaten), um die Vorhersagefähigkeit des Modells in Becken ohne Überwachungsdaten zu testen. Die Ergebnisse sind in der folgenden Abbildung dargestellt:
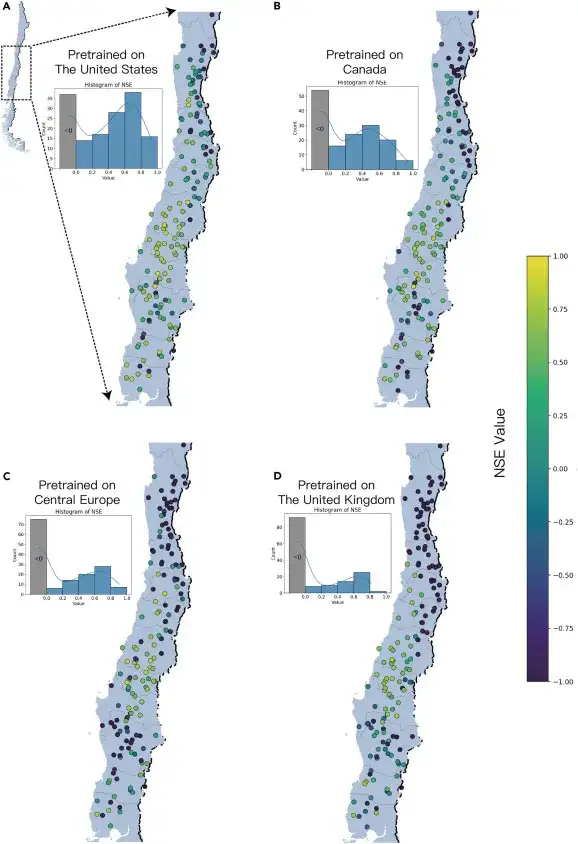
Als ED-DLSTM direkt in der neuen Region Chiles eingesetzt wurde, zeigte das in den Vereinigten Staaten vorab trainierte Modell, dass NSE in 76,9% der Wassereinzugsgebiete größer als 0 war; das in Kanada vortrainierte Modell erreichte in 66,2% der Wassereinzugsgebiete einen NSE größer als 0; das in Mitteleuropa vortrainierte Modell erreichte in 53,1% der Wassereinzugsgebiete einen NSE größer als 0; und das im Vereinigten Königreich vortrainierte Modell schnitt am schlechtesten ab, da nur 42,5% der Wassereinzugsgebiete einen NSE größer als 0 aufwiesen.
Die Vorhersageergebnisse verschiedener vortrainierter Modelle zeigten eine starke Übereinstimmung in der räumlichen Verteilung und demonstrierten damit das große Potenzial der KI für die Wasserfluss- und Hochwasservorhersage in nicht gemessenen Flusseinzugsgebieten.
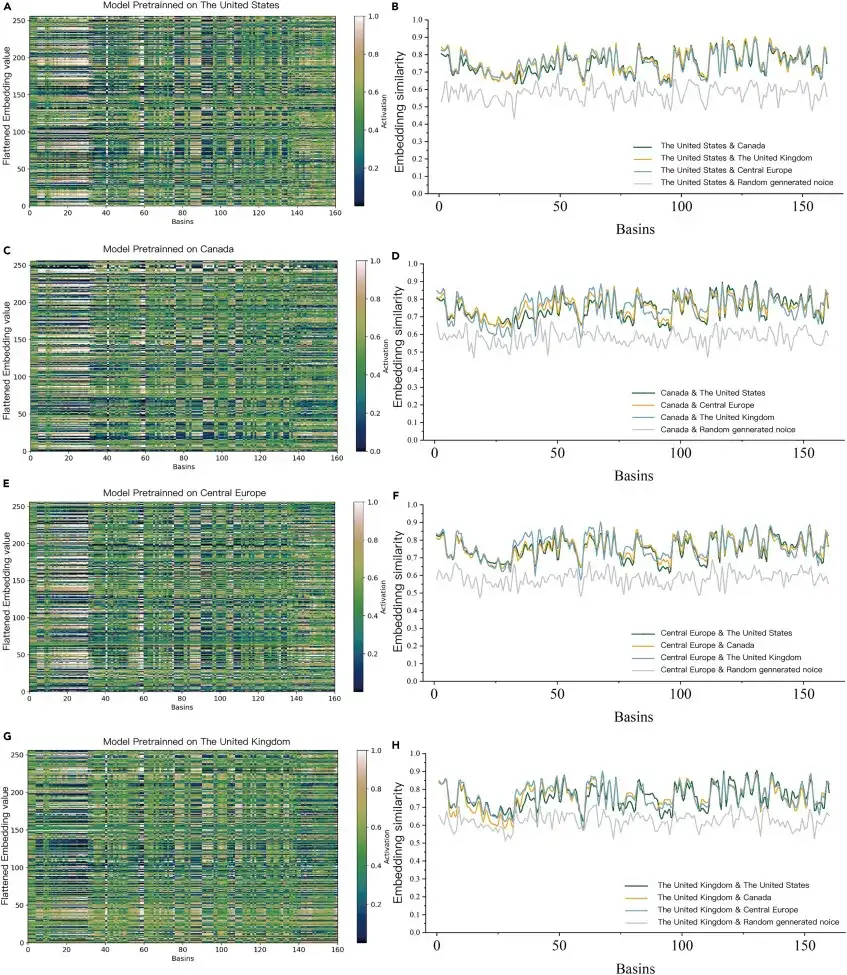
Als das vorab trainierte Modell zur Vorhersage von 160 Wassereinzugsgebieten in Chile ohne Überwachungsdaten verwendet wurde, wurden die Merkmale jedes Wassereinzugsgebiets visualisiert (linke Seite der Abbildung unten) und die Ähnlichkeit mithilfe des ED-DLSTM-Encoders analysiert (rechte Seite der Abbildung unten). Es wurde festgestellt, dass die durchschnittliche Kodierungsähnlichkeit zwischen den vorab trainierten Modellen 38,4% höher war als die des zufälligen Rauschens, was darauf hindeutet, dass die Einbettungsschicht von ED-DLSTM kein ungeordnetes Zufallssignal ist, sondern eine hochdimensionale Merkmalsinformation, die vom Modell erkannt und genutzt wird.Es beweist, dass KI „hydrologisches Wissen“ in verschiedenen Flussbecken erlernen kann.
KI + Hydrologie: Förderung der Entwicklung intelligenter Wasserwirtschaft
Die Hochwasservorhersage ist einer der wichtigsten Zweige der Hydrologie. Apropos Hydrologie: In meinem Land gibt es bereits seit der Zeit vor der Qin-Dynastie die Möglichkeit, Niederschlag und Wasserstand zu messen. Während der Zeit der Streitenden Reiche war im „Landgesetz“ des Staates Qin festgelegt, dass lokale Beamte rechtzeitig Niederschlagsmengen und die Anzahl der Hektar Land melden mussten, die davon profitierten bzw. betroffen waren. Seitdem verfügen alle Dynastien über ein Hochwassermeldesystem.
Hydrologische Vorhersagen sind eine wichtige Grundlage für Entscheidungen im Hochwasserschutz und bei Dürreperioden, für die rationelle Nutzung der Wasserressourcen, den ökologischen Umweltschutz sowie für den Betrieb und die Verwaltung von Wasserschutz- und Wasserkraftprojekten.Herkömmliche hydrologische Prognosemethoden verwenden meist prozessgesteuerte hydrologische Modelle in Kombination mit Hydraulik, um komplexe physikalische Prozesse zu simulieren. Hochwertige physikalische Daten, komplexe mathematische Werkzeuge und eine große Anzahl vereinfachter Annahmen stellen jedoch Herausforderungen für die Kalibrierung und Verifizierung dar.Mit der Entwicklung der Technologie der künstlichen Intelligenz und interdisziplinärer Themen haben viele Forscher eingehende Untersuchungen zu hydrologischen Vorhersagemodellen auf Basis künstlicher Intelligenz durchgeführt.
Im Jahr 2019 schlug ein Forschungsteam des State Key Laboratory of Water Resources and Hydropower Engineering Science der Wuhan University ein Deep-Learning-Netzwerk vor, das ein LSTM-Long-Short-Term-Memory-Neuralnetzwerk mit Batch-Size-Learning, Regularisierung und Drop-Out-Neuronen kombiniert, und wandte es auf die Hochwasservorhersage des Drei-Schluchten-Stausees an. Aus der umfassenden Auswertung der vier Indikatoren Prognosequalifikationsrate, relativer Hochwasserspitzenfehler, quadratischer Mittelwertfehler und Benchmark-Anpassungsgrad geht hervor, dass das neuronale Netzwerk mit langem Kurzzeitgedächtnis LSTM in Kombination mit drei Deep-Learning-Hilfsalgorithmen die Prognosegenauigkeit des Zuflusses zum Drei-Schluchten-Stausee im Vergleich zum statischen neuronalen Netzwerk BPNN und dem dynamischen neuronalen Netzwerk NARX effektiv verbessert hat.
Im Jahr 2020 arbeitete ein Forschungsteam der Northwestern Polytechnical University mit dem Yellow River Conservancy Research Institute zusammen, um das Yellow River Hydrological Yearbook zu digitalisieren und eine Vielzahl von Faktoren zusammenzustellen, darunter Boden, Klima, Topografie und Geologie.Die ersten systematischen hydrologischen Big Data des Gelben Flussbeckens in China wurden erstellt.Im Hinblick auf die Modellalgorithmen erzielten sie Durchbrüche beim intelligenten Vorhersagemodell für einzelne Standorte, leisteten Pionierarbeit bei der Entwicklung eines intelligenten Vorhersagemodells für Standortgruppen und bewältigten eine der zehn größten Herausforderungen im Bereich der Hydrologie, nämlich die Hochwasservorhersage in Gebieten mit fehlenden historischen Daten. Dadurch konnte die Genauigkeit der Hochwasservorhersagen deutlich verbessert und der Prognosezeitraum verlängert werden. Intelligente Vorhersagealgorithmen wurden erfolgreich auf die wichtigsten Sand produzierenden Gebiete des Lössplateaus, die unkontrollierten Gebiete von Sanmenxia bis Huayuankou im Mittel- und Unterlauf des Gelben Flusses und Tangnaihai im Oberlauf des Gelben Flusses angewendet, wodurch die Möglichkeiten zur Hochwasservorhersage deutlich verbessert wurden.
Im März 2024 entwickelten Grey Nearing und seine Kollegen vom Flood Prediction Team bei Google Research ein KI-Modell, das den täglichen Abfluss in nicht gemessenen Becken über einen 7-tägigen Vorhersagezeitraum vorhersagen kann, indem es mit 5.680 vorhandenen Messgeräten trainiert wird. Anschließend testeten sie das KI-Modell mit dem Global Flood Alert System (GloFAS), der weltweit führenden Software zur kurz- und langfristigen Hochwasservorhersage.
Die Ergebnisse zeigen, dass die Genauigkeit der Vorhersagen des Modells für denselben Tag mit der aktueller Systeme vergleichbar oder sogar höher ist. Darüber hinaus ist die Genauigkeit des Modells bei der Vorhersage extremer Wetterereignisse mit einem Wiederkehrfenster von fünf Jahren vergleichbar mit oder besser als die Genauigkeit von GloFAS bei der Vorhersage von Ereignissen mit einem Wiederkehrfenster von einem Jahr. Die entsprechende Forschungsarbeit mit dem Titel „Global prediction of extreme floods in ungauged watersheds“ wurde in der renommierten Fachzeitschrift „Nature“ veröffentlicht. (Klicken Sie hier für einen ausführlichen Bericht: Googles Hochwasservorhersagemodell wird erneut in Nature veröffentlicht, übertrifft das weltweit führende System und deckt über 80 Länder ab)

Heute ist die intelligente Wasserwirtschaft vom ursprünglichen Internet der Dinge zum intelligenten Internet weiterentwickelt worden. Das bedeutet, dass IoT-Geräte Daten erfassen, KI diese analysiert und auf Grundlage dieser Daten Prognosen erstellt und die Prognoseergebnisse in Echtzeit an das zuständige Personal zurückmeldet, um die Evakuierung der Menschen und den Schutz öffentlichen Eigentums abzuschließen, bevor es zu Überschwemmungen kommt. Auch in Zukunft wird eine intelligente Wasserwirtschaft auf Grundlage der Entwicklung von KI-Technologien die Intelligenz in der Wasserwirtschaftsplanung, im Projektbau, im Betriebsmanagement und in den sozialen Diensten weiter vorantreiben, die Effizienz der Wasserressourcennutzung verbessern, Wasser- und Dürrekatastrophen verhindern und die Wasserumwelt und -ökologie verbessern.
Quellen:
1.https://mp.weixin.qq.com/s/sKPl55AEVf9GoXsLv0-8Hg
2.https://www.hanspub.org/journal/PaperInformation?paperID=28786








