Command Palette
Search for a command to run...
Online-Tutorial: Das Transaktionsvolumen Beim Digitalen Debüt Von Liu Qiangdong Überstieg 50 Millionen! Generieren Sie Mit GeneFace++ Einen Sprechenden Digitalen Menschen in Echtzeit
Vor Kurzem verwandelte sich JD.com-Gründer Liu Qiangdong in „Purchasing and Sales Dongge AI Digital Human“ und gab sein Live-Übertragungsdebüt im Live-Übertragungsraum für Einkauf und Verkauf der Haushaltsgeräte-, Einrichtungs- und Supermärkte von JD.com. Die Live-Übertragung zog mehr als 20 Millionen Zuschauer an und der Gesamttransaktionsbetrag überstieg 50 Millionen.Es zeigt deutlich das enorme Potenzial digitaler KI-Menschen im Bereich des E-Commerce-Live-Streamings.
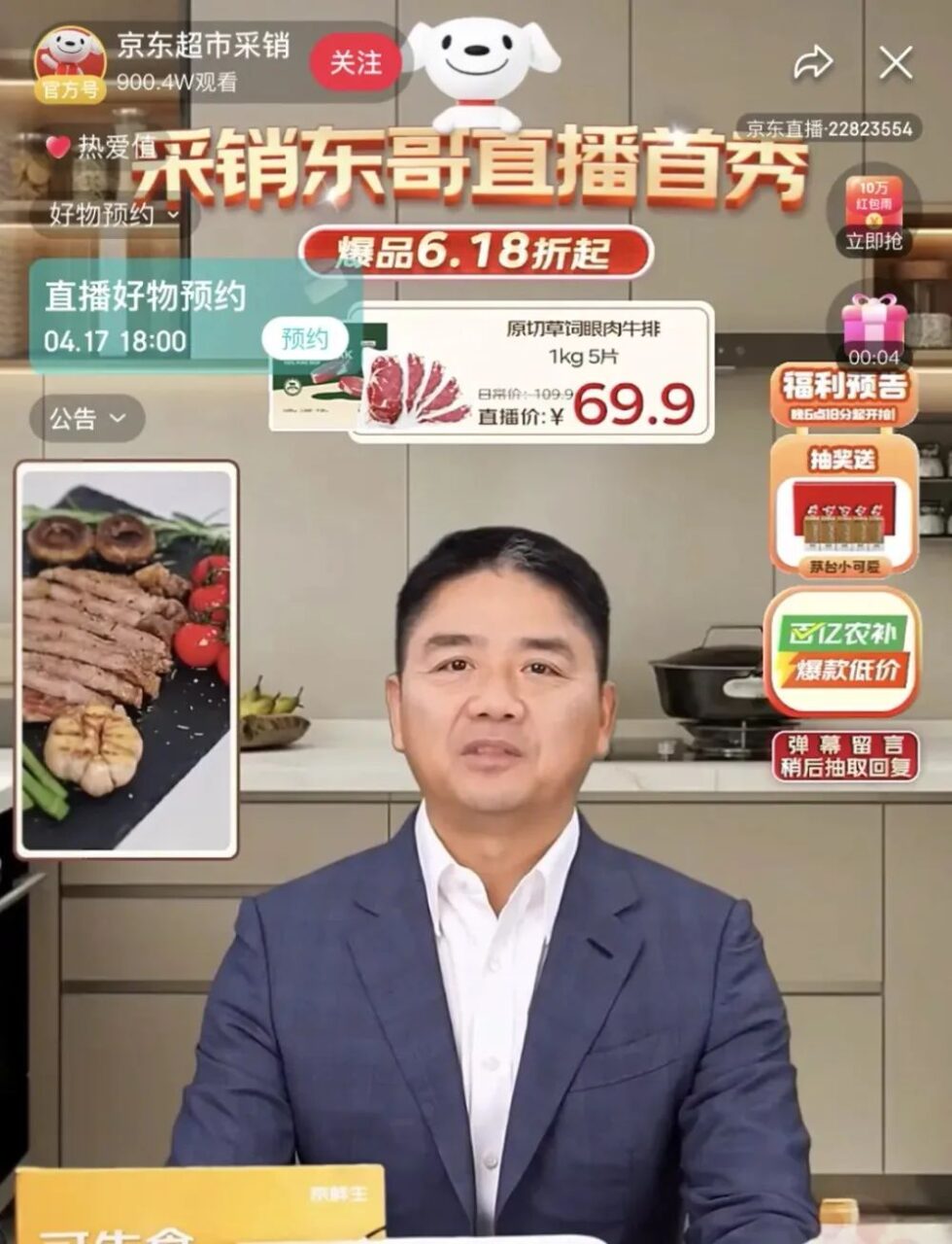
Bildquelle: Observer.com
Es wird davon ausgegangen, dass der „Purchasing and Sales Dongge AI Digital Human“ Liu Qiangdongs personalisierte Ausdrücke, Haltungen, Gesten und Klangfarbenmerkmale genau wiedergeben kann, indem er sein Aussehen und seine Stimme lernt und trainiert. Es ist schwierig, innerhalb von 120 Sekunden mit bloßem Auge den Unterschied zwischen dem digitalen Menschen und der realen Person zu erkennen.

IDC hat in seiner „Analyse des Marktstatus und der Chancen für den digitalen KI-Menschen in China 2022“ einmal angegeben, dass das Ausmaß des chinesischen Marktes für digitale KI-Menschen bis 2026 voraussichtlich 10,24 Milliarden Yuan erreichen wird. Dabei muss erwähnt werden, dass digitale KI-Menschen replizierbar und kostengünstig sind und rund um die Uhr arbeiten können. Ihre Anwendung in Szenarien wie Self-Media-Operationen, dem Verkauf von Kurzvideos, der digitalen Übertragung menschlicher Inhalte und der Unterstützung von Menschen bei der Erledigung verschiedener Aufgaben könnte in Zukunft ein wichtiger Trend werden.
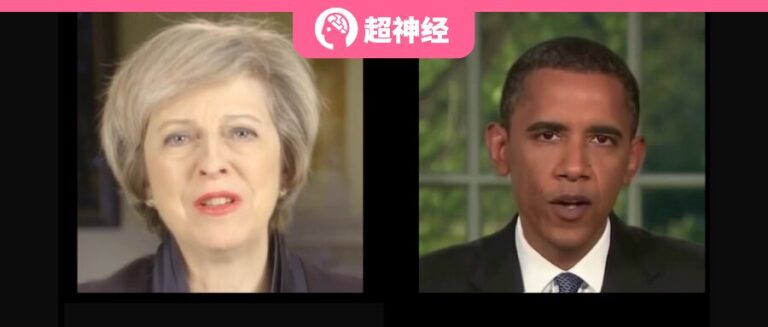
In diesem Bereich ist die audiogesteuerte Generierung sprechender Gesichter ein heißes Thema. Basierend auf dieser Technologie müssen Sie lediglich einen Sprachclip eingeben, um ein Sprechvideo des Gesichts der Zielperson zu erstellen. Dies kann der Zielperson dabei helfen, an einigen Szenen teilzunehmen, in denen echte Personen unpraktisch sind oder nicht erscheinen können. In,GeneFace++ ist eine allgemeine und stabile audiogesteuerte 3D-Technologie zur Generierung sprechender Gesichter in Echtzeit, die als erste die Generierung sprechender Gesichter in Echtzeit durch Verbesserung der Lippensynchronisation, Videoqualität und Systemleistung ermöglicht.
Insbesondere trainiert GeneFace++ das Audio-to-Motion-Modul und das Instant-Motion-to-Video-Modul unabhängig voneinander. Der Trainingsprozess umfasst Mapping-Lernen zwischen Audio und Gesichtsbewegungen, Transferlernen für Domänenanpassungsfähigkeit und landmarkengesteuertes Lernen der Echtzeit-Rendering-Technologie für 3D-Porträts, wodurch das Modell letztendlich in der Lage ist, qualitativ hochwertige, lippensynchrone 3D-Videos sprechender Gesichter in Echtzeit basierend auf beliebigem Audio zu generieren.
Allerdings ist es keine leichte Aufgabe, einen realistischen, lippensynchronen digitalen Menschen zu erstellen. Um Anfängern den Einstieg zu erleichtern und häufige Schwierigkeiten beim Aufbau der Umgebung und bei der Technik zu vermeiden,HyperAIsuper nervösDas Tutorial „GeneFace++ Digital Human Demo“ wurde gestartet.Dieses Tutorial hat eine Umgebung für alle geschaffen und den Prozess der Erstellung digitaler Menschen vereinfacht. Sie müssen sich keine Gedanken über Probleme wie Umgebungskonfiguration, Hardwareanforderungen und Versionskompatibilität machen. Klicken Sie einfach auf „Klonen“, um es mit einem Klick zu starten, und der Effekt ist sehr realistisch!
Adresse des öffentlichen Tutorials zu HyperAI HyperNeural:
https://hyper.ai/tutorials/31157
Vorbereitende Vorbereitung
Bereiten Sie ein 3-5-minütiges Video vor:
* Das Bild sollte klar und quadratisch sein (vorzugsweise 512 x 512).
* Damit das Modell den Hintergrund besser extrahieren kann, sollte der Videohintergrund eine Volltonfarbe ohne andere Störfaktoren aufweisen.
* Die Gesichter der Personen im Video sollten klar und relativ groß sein und frontal zu sehen sein. Die aufgenommenen Bilder sollten vorzugsweise oberhalb der Schultern erfolgen und die Bewegungen der Personen sollten nicht zu groß oder zu klein sein;
* Der Ton im Video ist rauschfrei;
* Am besten benennen Sie das Video auf Englisch.
Hinweis: Dieses Video wird für das Modelltraining verwendet. Je besser die Videoqualität, desto besser die Ergebnisse. Daher ist es notwendig, mehr Zeit und Mühe in die Datenvorbereitung zu investieren.
Nachfolgend sehen Sie ein Beispiel für einen Videobildschirm:

Demo-Lauf
1. Melden Sie sich bei hyper.ai an und wählen Sie auf der Tutorial-Seite „GeneFace++ Digital Human Demo“ aus. Klicken Sie auf „Dieses Tutorial online ausführen“.

2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.

3. Klicken Sie unten rechts auf „Weiter: Hashrate auswählen“.

4. Wählen Sie nach dem Sprung „NVIDIA GeForce RTX 4090“ aus und klicken Sie auf „Weiter: Überprüfen“.Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Rechenzeit zu erhalten!
Exklusiver Einladungslink von HyperAI (zum Registrieren kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej

5. Klicken Sie auf „Weiter“ und warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 3–5 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf „Arbeitsbereich öffnen“. Wenn das Problem länger als 10 Minuten besteht und sich das System immer noch im Status „Ressourcen werden zugewiesen“ befindet, versuchen Sie, den Container zu stoppen und neu zu starten. Wenn das Problem durch einen Neustart immer noch nicht behoben wird, wenden Sie sich bitte an den Kundenservice der Plattform auf der offiziellen Website.



6. Erstellen Sie nach dem Öffnen des Arbeitsbereichs eine neue Terminalsitzung auf der Startseite und geben Sie dann den folgenden Code in die Befehlszeile ein, um die Umgebung zu starten. Kopieren Sie es einfach und fügen Sie es ein.
conda env export -p /output/geneface
conda aktivieren /output/geneface


7. Warten Sie einen Moment und führen Sie den folgenden Befehl im Terminal aus, um die Umgebungsvariablen zu konfigurieren.
Quelle bashrc

8. Warten Sie einen Moment, geben Sie den folgenden Code in die Befehlszeile ein, um die WebUI zu starten, und warten Sie etwa 1 Minute.
/openbayes/home/start_web.sh
9. Wenn in der Befehlszeile „Läuft unter lokaler URL: https://0.0.0.0:8080“ angezeigt wird, kopieren Sie die API-Adresse rechts in die Adressleiste des Browsers, um auf die GeneFace++-Schnittstelle zuzugreifen.Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.

Effektanzeige
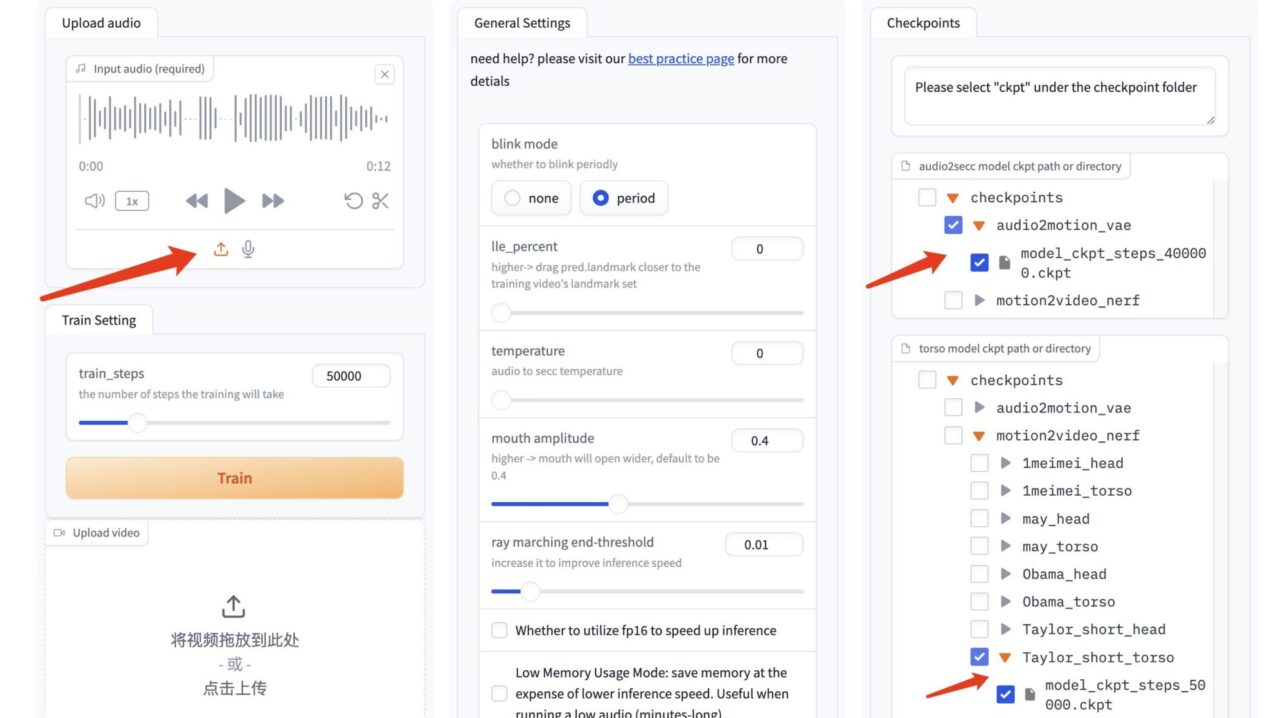
1. Importieren Sie nach dem Öffnen der GeneFace++-Oberfläche das zuvor vorbereitete Video, wählen Sie die Anzahl der Trainingsschritte „50000“ und klicken Sie auf „Trainieren“, um mit dem Training zu beginnen.
Hinweis: Für diesen Schritt ist eine Wartezeit von mehr als 2 Stunden erforderlich. Während dieser Zeit können Sie 1-2 Mal überprüfen, ob das Training normal läuft, um Zeitverluste durch Unterbrechung des Prozesses und dennoches Warten zu vermeiden.
Die Anzahl der Trainingsschritte ist hier standardmäßig auf „50000“ eingestellt. Wenn die Ergebnisse nach 50.000 Trainingsschritten schlecht sind, ändern Sie bitte die Trainingsdaten und führen Sie das Training erneut durch.

2. Wenn „Train Success“ angezeigt wird, aktualisieren Sie die GeneFace++-Schnittstelle.

3. Laden Sie in der GeneFace++-Oberfläche das Audio auf der linken Seite hoch und ändern Sie die Parameter des mittleren Moduls nicht.
Wählen Sie aus dem Modell rechts das Audiotreibermodell „model_ckpt_steps_400000.ckpt“ aus.
Wählen Sie das Torsomodell „model_ckpt_steps_50000.ckpt“ entsprechend dem Training unter 50.000 Schritten aus.
Wählen Sie das Kopfmodell „model_ckpt_steps_50000.ckpt“ entsprechend dem Training unter 50.000 Schritten.
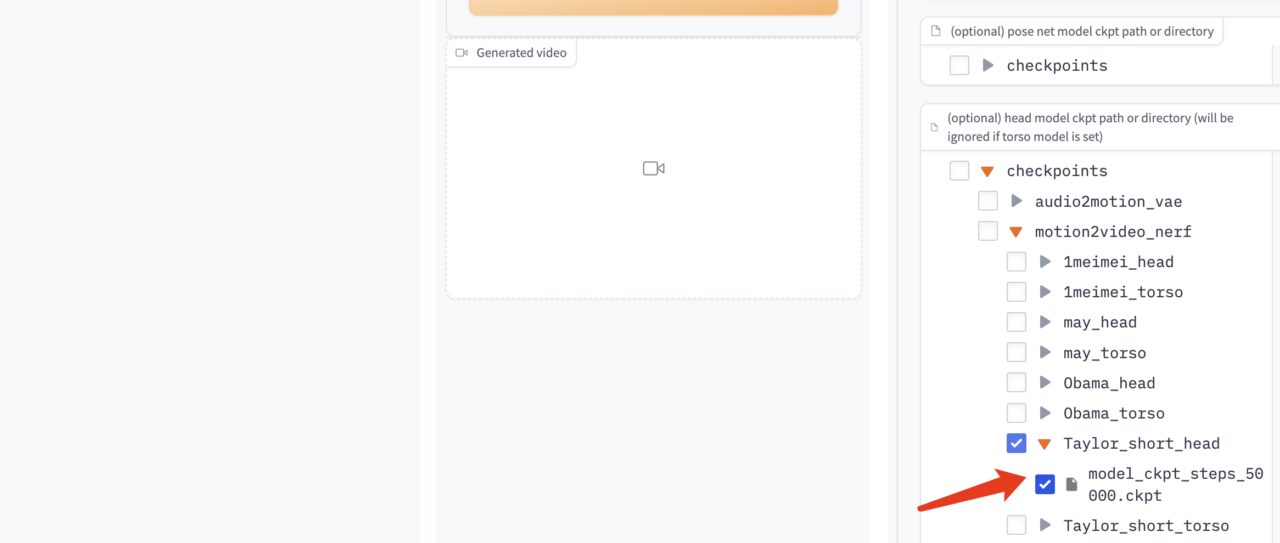
4. Klicken Sie auf „Generieren“, um den Effekt zu generieren.

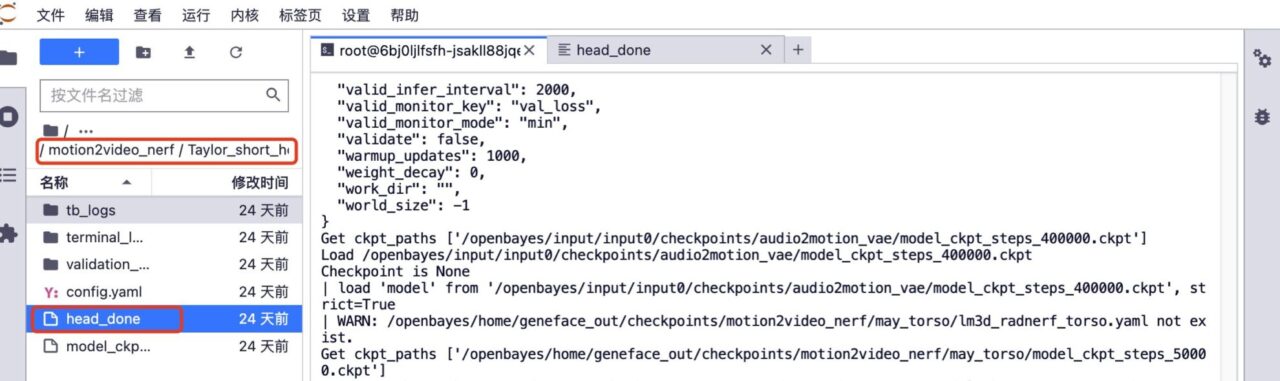
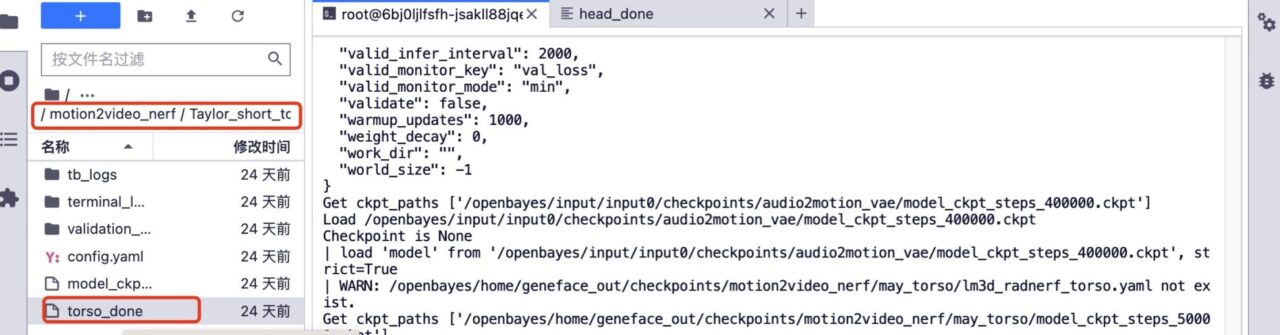
5. Wenn Sie eine Weiterbildung wünschen. Löschen Sie die Ordner „head_done“ und „torso_done“ unter dem entsprechenden Modell.
6. Laden Sie das vorherige Trainingsvideo hoch, lassen Sie den Namen der Videodatei unverändert, erhöhen Sie die Anzahl der Trainingsschritte und klicken Sie auf „Trainieren“, um mit dem Training zu beginnen.


7. Nachdem das Training abgeschlossen ist, wählen Sie in der GeneFace++-Schnittstelle das standardmäßige audiogesteuerte Modell, das Rumpfmodell, das dem 150.000-Schritte-Training entspricht, und das Kopfmodell, das dem 150.000-Schritte-Training entspricht. Klicken Sie auf „Generieren“, um den endgültigen Effekt zu generieren.
Derzeit hat die offizielle Website von HyperAI Hunderte ausgewählter Tutorials zum Thema maschinelles Lernen veröffentlicht, die in Form eines Jupyter-Notebooks organisiert sind.
Klicken Sie auf den Link, um nach verwandten Tutorials und Datensätzen zu suchen:
Das Obige ist der gesamte Inhalt, den der Herausgeber dieses Mal geteilt hat. Ich hoffe, dieser Inhalt ist für Sie hilfreich. Wenn Sie weitere interessante Tutorials erfahren möchten, hinterlassen Sie bitte eine Nachricht oder senden Sie uns eine private Nachricht mit der Projektadresse. Der Herausgeber erstellt einen individuellen Kurs für Sie und bringt Ihnen das Spielen mit KI bei.
Quellen:
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/128895215








