Command Palette
Search for a command to run...
Neue Einsatzmöglichkeiten Für Alte Medikamente: Das Team Der Central South University Veröffentlicht AdaDR Zur Neupositionierung Von Medikamenten Auf Basis Adaptiver Graph-Convolutional-Netzwerke

In der modernen Gesellschaft müssen die Menschen weiterhin gegen immer häufiger auftretende komplexe Krankheiten wie Krebs, Diabetes und Herz-Kreislauf-Erkrankungen kämpfen. Die vorhandenen Medikamente können die Marktnachfrage nicht mehr vollständig decken und die Entwicklung neuer Medikamente ist zwingend erforderlich. Der traditionelle Prozess der Arzneimittelentdeckung ist jedoch zeitaufwändig und investitionsintensiv. Wenn wir proaktiv neue Arzneimittel und therapeutische Ziele von älteren Arzneimitteln und aufgegebenen Verbindungen unterscheiden können, können wir offensichtlich erhebliche F&E-Kosten einsparen und die F&E-Effizienz verbessern.
Bei der Neupositionierung von Medikamenten oder „neuen Einsatzmöglichkeiten für alte Medikamente“ handelt es sich um einen von der FDA zugelassenen Ansatz in der Arzneimittelentwicklung, bei dem bestehende Behandlungsmethoden auf neue Krankheitsprozesse angewendet werden. Sildenafil wurde beispielsweise ursprünglich zur Behandlung von Brustschmerzen eingesetzt, stellte sich jedoch später als PDE5-Hemmer (Phosphodiesterase-Typ-5-Hemmer) heraus, was Sildenafil auf dem Markt sehr beliebt machte.
Aufgrund ihrer Vorteile wie der Verringerung der Arzneimittelrisiken, der Verkürzung klinischer Bewertungszyklen, der geringen Kosten und der hohen Effizienz ist die Neupositionierung bestehender Arzneimittel zu einem heißen Thema in der aktuellen Branchenforschung geworden.Mit der rasanten Entwicklung des Deep Learning werden Graph Convolutional Networks (GCNs) häufig bei Aufgaben zur Arzneimittelneulokalisierung eingesetzt. Allerdings weisen bestehende GCN-basierte Methoden bei der tiefen Integration von Knotenfunktionen und topologischen Strukturen Einschränkungen auf. Als Reaktion darauf veröffentlichten Forscher der Central South University in Bioinformatics einen Artikel mit dem Titel „Drug repositioning with adaptive graph convolutional networks“.
In dieser Studie wurde eine adaptive GCN-Methode namens AdaDR vorgeschlagen, um eine Neupositionierung von Medikamenten durch die tiefe Integration von Knotenmerkmalen und topologischen Strukturen durchzuführen.Anders als herkömmliche Graph-Convolutional-Netzwerke simuliert AdaDR die interaktiven Informationen zwischen ihnen durch adaptive Graph-Convolution-Operationen und verbessert so die Ausdruckskraft des Modells.
Insbesondere extrahiert AdaDR Einbettungen sowohl aus Knotenmerkmalen als auch aus topologischen Strukturen und verwendet einen Aufmerksamkeitsmechanismus, um adaptive Wichtigkeitsgewichte der Einbettungen zu lernen.
Experimentelle Ergebnisse zeigen, dass AdaDR mehrere Basismethoden bei der Neupositionierung von Medikamenten übertrifft. Darüber hinaus werden in Fallstudien explorative Analysen zur Entdeckung neuer Arzneimittel-Krankheits-Zusammenhänge bereitgestellt.
Forschungshighlights:
* Diese Studie schlägt ein adaptives Graph-Convolutional-Netzwerk-Framework für Aufgaben zur Arzneimittel-Relokalisierung vor, das Graph-Convolution-Operationen an topologischen Strukturen und Merkmalsräumen durchführt.
* Unter Berücksichtigung der Unterschiede zwischen topologischen Strukturen und Merkmalen nutzt diese Studie den Aufmerksamkeitsmechanismus, um sie vollständig zu integrieren und ihre Beiträge zu den Modellergebnissen zu unterscheiden
* Das in dieser Studie vorgeschlagene Modell ist bei der Neupositionierung von Arzneimitteln praktisch und trägt dazu bei, das Risiko eines Scheiterns der Arzneimittelentwicklung zu verringern
Papieradresse:
https://academic.oup.com/bioinformatics/article/40/1/btad748/7467059
Adresse zum Herunterladen des Datensatzes:
Folgen Sie dem offiziellen Konto und antworten Sie mit „Umzug“, um das vollständige PDF zu erhalten
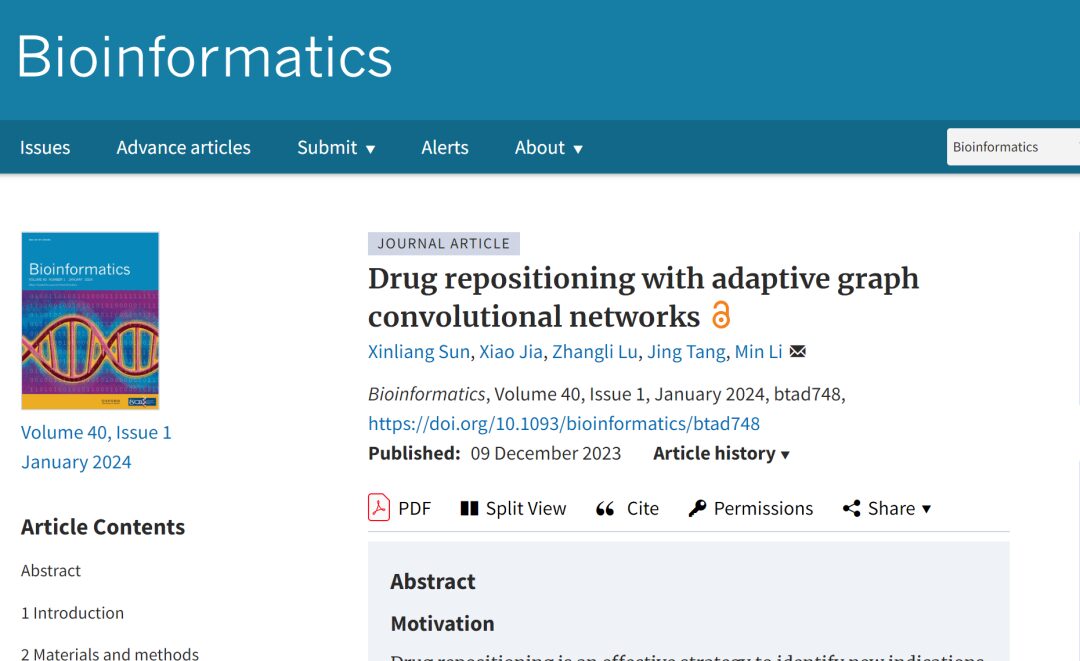
Datensatz: Verwendung von vier wichtigen Benchmark-Datensätzen
Um die Leistung des vorgeschlagenen Modells umfassend zu bewerten,In dieser Studie wurden vier Benchmark-Datensätze verwendet, die bei der Neupositionierung von Arzneimitteln häufig verwendet werden, nämlich Gdataset, Cdataset, Ldataset und LRSSL.
* Gdataset:Er gilt als Goldstandard-Datensatz und umfasst 593 Arzneimittel aus der DrugBank sowie 1.933 bestätigte Arzneimittel-Krankheits-Assoziationen zwischen 313 in der OMIM-Datenbank aufgeführten Krankheiten.
* Datensatz:Enthält 663 Medikamente, 409 Krankheiten und 2.352 Wechselwirkungen zwischen Medikamenten und Krankheiten.
* Datensatz:Zusammengestellt aus dem CTD-Datensatz enthält es 18.416 Assoziationen zwischen 269 Medikamenten und 598 Krankheiten.
*LRSSL:Insgesamt wurden 3.051 validierte Arzneimittel-Krankheits-Assoziationen einbezogen, die 763 Arzneimittel und 681 Krankheiten betrafen.
Gleichzeitig wurden in der Studie zur Erstellung einer Arzneimittel-/Krankheitsmerkmalskarte auch die Ähnlichkeitsmerkmale von Arzneimitteln und Krankheiten herangezogen. Die Datensatzstatistiken sind in der folgenden Tabelle aufgeführt:
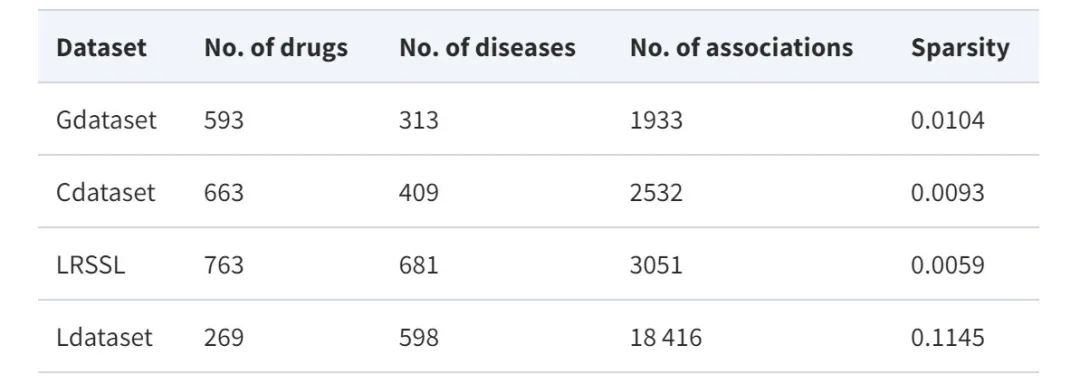
Modellarchitektur: Ein neues adaptives GCNs-Framework AdaDR
Das in dieser Studie vorgeschlagene AdaDR-Modell-Framework umfasst hauptsächlich drei Komponenten. Wie in der folgenden Abbildung dargestellt:
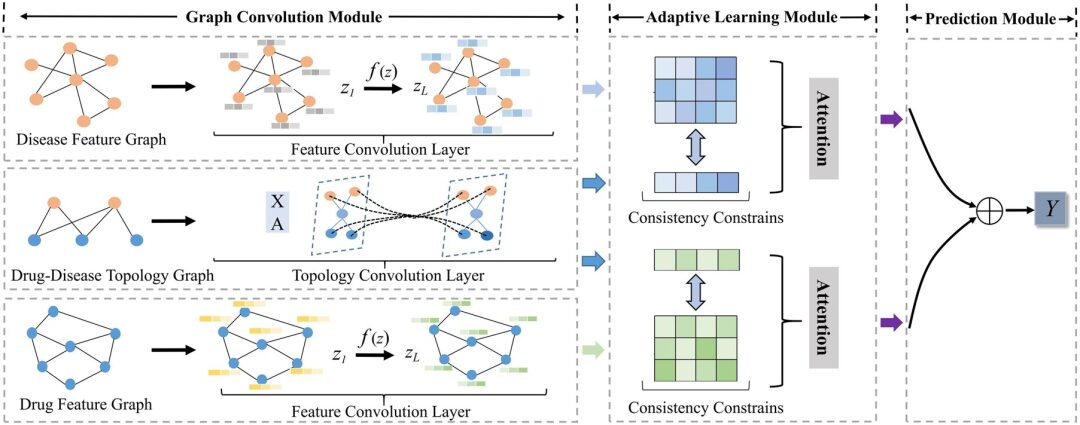
* Graph-Faltungsmodul:Enthält Feature-Convolutional-Schichten und topologische Convolutional-Schichten zur Darstellung von Arzneimittel-/Krankheitseinbettungen im Feature-Raum und topologischen Raum.
* Adaptives Lernmodul:Der Aufmerksamkeitsmechanismus wird verwendet, um die Wichtigkeit der erworbenen Einbettungen zu unterscheiden. In diesem Modul werden Konsistenzbeschränkungen verwendet, um gemeinsame semantische Informationen zwischen Feature- und topologischen Räumen zu extrahieren.
* Vorhersagemodul:Die Einbettungen werden als Ausgabe miteinander verkettet, um das Ergebnis vorherzusagen.
Forschungsergebnisse: AdaDR übertrifft mehrere Basismethoden bei der Neupositionierung von Medikamenten
Insgesamt kann AdaDR als neues Modell die Leistung bei Aufgaben zur Neupositionierung von Medikamenten erheblich verbessern.
Zunächst die Leistung bei der Kreuzvalidierung:In dieser Studie wurde eine 10-fache Kreuzvalidierung von AdaDR und anderen Modellen durchgeführt und der Mittelwert und die Standardabweichung der Ergebnisse berechnet.
Den Ergebnissen zufolge übertrafen die endgültigen Durchschnittsergebnisse von AdaDR aus vier Datensätzen, die in 10-fachen Kreuzvalidierungen erzielt wurden, aufgrund der Feature-Integrationsfähigkeit alle verglichenen Methoden.
Beispielsweise auf den vier Benchmark-Datensätzen Gdataset, Cdataset, LRSSL und Ldataset,Die Ergebnisse dieser Studie liegen 9,8%, 9,1%, 9,1% und 7,1% über der AUPRC (Fläche unter dem Präzisions-Recall) der zweitbesten Methode DRHGCN und beweisen damit voll und ganz die Wirksamkeit der neuen Methode.
Als nächstes kommt die Fähigkeit, die potenziellen Indikationen neuer Medikamente vorherzusagen:In dieser Studie wurde ein neues Experiment durchgeführt, um die Fähigkeit von AdaDR zu bewerten, die potenziellen Indikationen neuer Medikamente vorherzusagen.
Im Vergleich zu den anderen 7 Methoden erzielt AdaDR die beste Leistung (der blaue Balken in der Abbildung unten stellt AdaDR dar). In Bezug auf AUROC (Fläche unter der ROC-Kurve) erreicht AdaDR, wie in Abbildung (a) unten dargestellt, einen AUROC-Wert von 0,948, was besser ist als bei anderen Methoden. Gleichzeitig erreicht AdaDR, wie in Abbildung (b) unten gezeigt, einen AUPRC von 0,393, der höher ist als bei allen anderen Methoden.
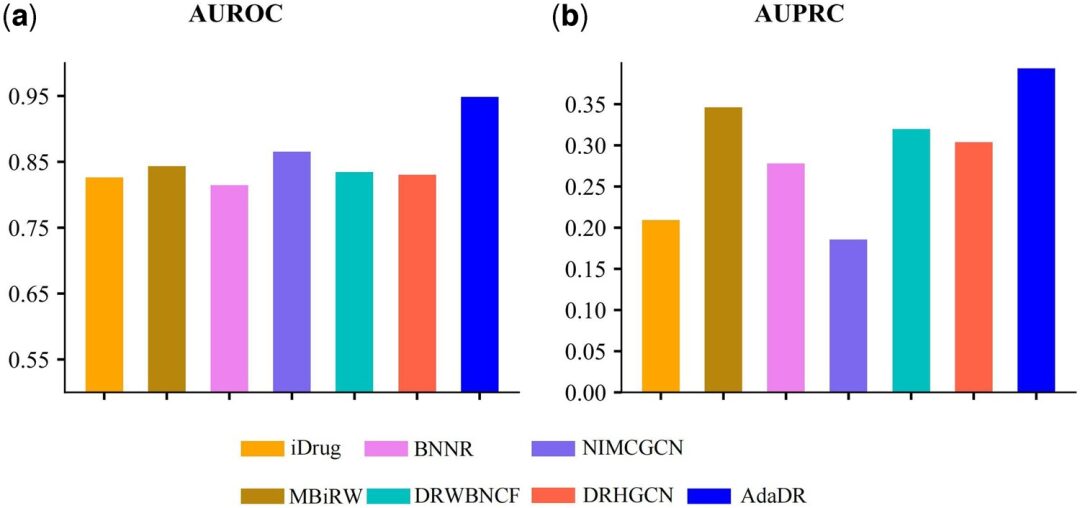
(a) AUROC der Vorhersageergebnisse, die mit AdaDR und anderen konkurrierenden Methoden erzielt wurden.
(b) AUPRC der Vorhersageergebnisse, die durch Anwendung von AdaDR und anderen konkurrierenden Methoden erzielt wurden.
Es ist erwähnenswert, dass das Forschungsteam zur weiteren Überprüfung der Leistung von AdaDR AdaDR auch zur Vorhersage von Medikamentenkandidaten für die Alzheimer-Krankheit (AD) und Brustkrebs (BRCA) eingesetzt hat.
Darunter ist die Alzheimer-Krankheit eine sich schleichend entwickelnde neurodegenerative Erkrankung, für die es derzeit kein wirksames Medikament gibt. Brustkrebs ist ein Phänomen, bei dem sich Brustepithelzellen unter dem Einfluss mehrerer krebserregender Faktoren unkontrolliert vermehren. Obwohl es bereits eine Vielzahl von Medikamenten zur Behandlung von Brustkrebs gibt, wie etwa Paclitaxel, Carboplatin usw., könnten mehr Medikamentenoptionen bessere Behandlungsmöglichkeiten bieten. In der folgenden Tabelle sind die Arzneimittelkandidaten aufgeführt, für die Belege vorliegen:
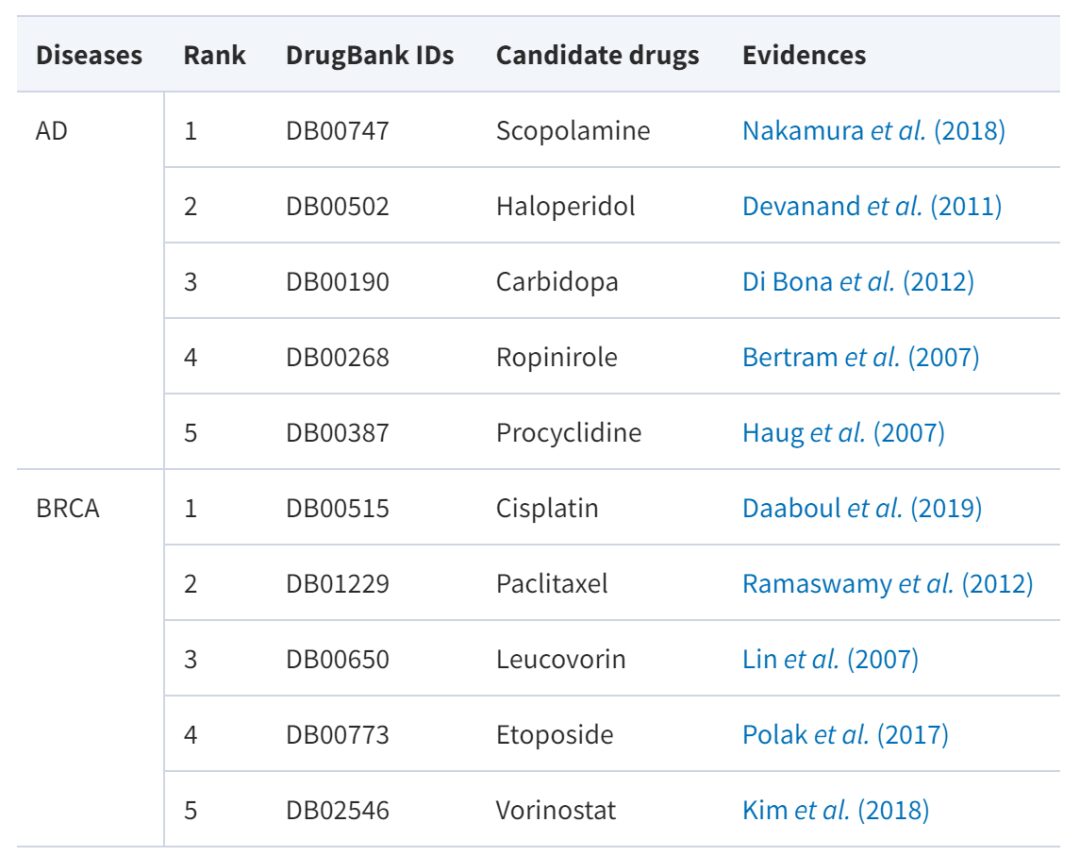
Es ist ersichtlich, dass viele der fünf Medikamente mit den höchsten AdaDR-Vorhersagewerten durch maßgebliche Quellen und Literatur verifiziert wurden (Erfolgsrate 100%). Darüber hinaus kann das Modell der Studie interpretierbare Ergebnisse liefern. Am Beispiel von Paclitaxel sagt das Modell voraus, dass es Brustkrebs behandeln kann. Dies wird tatsächlich durch maßgebliche Quellen und Literatur gestützt.
Interessanterweise stellten die Forscher fest, dass Docetaxel in ihrem Trainingsset vorkam. Wohingegen Paclitaxel und Docetaxel ähnliche Moleküle mit demselben Paclitaxelkern sind.Dies zeigt, dass das neue Modell Informationen zur Arzneimittelähnlichkeit nutzen kann, um aussagekräftige Vorhersagen zu treffen.
Die Kapitalrendite in der pharmazeutischen Forschung und Entwicklung sinkt weiter, und die Neupositionierung von Medikamenten könnte der Schlüssel zur Überwindung der Sackgasse sein
Heute durchlaufen Pharmaunternehmen beispiellose Veränderungen. Die COVID-19-Pandemie und die darauffolgende Wirtschaftsrezession haben Pharmaunternehmen mit einer Reihe von Herausforderungen und Unsicherheiten konfrontiert, wobei die Rendite aus Innovationen für jedes Pharmaunternehmen zur obersten Priorität geworden ist.
Obwohl Biopharmaunternehmen im letzten Jahrzehnt massiv in Forschung und Entwicklung für Innovationen investiert haben, sind die Erträge im gleichen Zeitraum erheblich gesunken. Aus der vom Deloitte Centre for Health Solutions veröffentlichten „2019 Pharmaceutical Innovation Return Rate Assessment“ geht hervor, dass die Kapitalrendite für Forschung und Entwicklung in der Pharmaindustrie im Jahr 2019 mit nur 1,81 TP3B auf dem niedrigsten Stand seit 2010 lag. Den Daten aus den zehn Berichten zufolge war die Rendite der F&E-Investitionen der Pharmaunternehmen im letzten Jahrzehnt rückläufig.
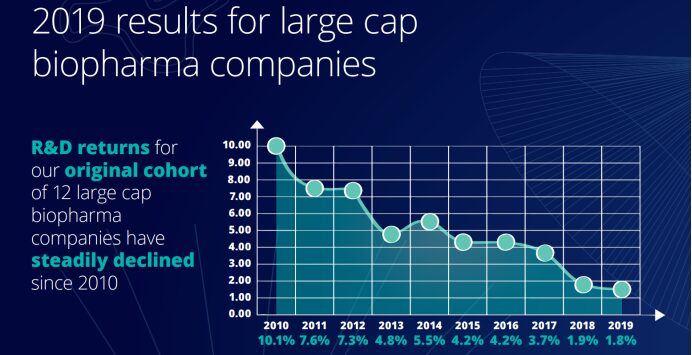
Darüber hinaus sanken auch die Spitzenumsätze jedes neuen Medikaments nach der Markteinführung von 407 Millionen US-Dollar im Jahr 2018 auf 376 Millionen US-Dollar im Jahr 2019. Sie lagen damit erstmals unter 400 Millionen US-Dollar und unter der Hälfte der 816 Millionen US-Dollar des Jahres 2010. Die Kosten für die Markteinführung eines neuen Medikaments stiegen im Vergleich zu 2010 um 671 TP3B-Dollar, von 1,188 Milliarden US-Dollar im Jahr 2010 auf 1,981 Milliarden US-Dollar im Jahr 2019.Der Rückgang der Spitzenumsätze steht in krassem Gegensatz zu den gestiegenen durchschnittlichen Kosten für die Markteinführung eines neuen Medikaments. Dies lässt darauf schließen, dass die Pharmaunternehmen mehr Zeit als je zuvor in den Forschungs- und Entwicklungsprozess investieren.
Durch die Neupositionierung von Medikamenten können die anfänglichen Kosten und die Zeit eingespart werden, die für die Markteinführung eines Arzneimittels erforderlich sind. Dadurch wird der Übergang von der Grundlagenforschung zur klinischen Behandlung beschleunigt. Brancheninsidern zufolge muss ein neues Medikament vom Beginn der Forschung und Entwicklung bis zur Marktzulassung eine Reihe von Studien durchlaufen, darunter In-vitro-Studien, präklinische Studien an Tieren sowie klinische Phasen I, II und III. Zehn bis 15 Jahre sind ein normaler Zeitraum und es kostet mindestens eine Milliarde Dollar. Zum Vergleich: Einige Umfragen zeigen, dass die Neupositionierung eines Medikaments durchschnittlich 300 Millionen Dollar kostet und es etwa 6,5 Jahre dauert, bis es auf den Markt kommt.
Die Neupositionierung von Arzneimitteln umfasst hauptsächlich Methoden, die auf maschinellem Lernen basieren, Methoden, die auf Big Data Mining und Positionierung basieren, und Methoden, die auf In-vivo-Positionierung basieren.Im Vergleich zu In-vivo-Methoden bietet die auf maschinellem Lernen und Big Data Mining basierende Technologie zur Neupositionierung von Arzneimitteln die Vorteile hoher Geschwindigkeit und geringer Kosten und hat sich zu einer potenziell leistungsstarken Technologie entwickelt.
Der Artikel „A Review of Drug Repositioning Algorithms Based on Machine Learning and Big Data Mining“ stellt den Forschungsfortschritt der computergestützten Arzneimittelneupositionierung in den letzten Jahren vor.
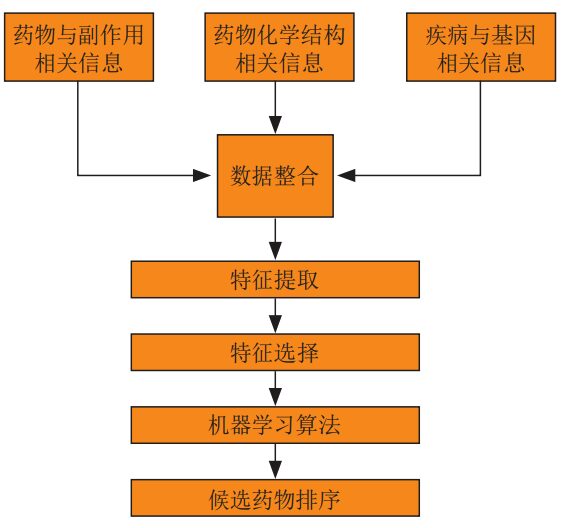
In,Basierend auf der traditionellen Methode des maschinellen Lernens,Zunächst werden die Informationen zu Arzneimittel und Nebenwirkungen, zur chemischen Struktur des Arzneimittels sowie zu Krankheiten und Genen integriert. Anschließend werden die Trainingsdaten durch Merkmalsextraktion und Merkmalsauswahl ermittelt. Anschließend wird der relevante Algorithmus des maschinellen Lernens für das Training ausgewählt. Schließlich wird das trainierte Algorithmusmodell verwendet, um die Ergebnisse der Neupositionierung des Arzneimittels zu erhalten.
Bei Deep Learning-basierten MethodenEinige Forscher haben tiefe neuronale Netzwerke in mehreren Aspekten der Arzneimittelentwicklung systematisch mit einer Reihe anderer Methoden des maschinellen Lernens verglichen. Die Ergebnisse zeigen, dass Deep Learning bessere Ergebnisse liefert als herkömmliche Algorithmen des maschinellen Lernens.
Bei der Methode der NetzwerkähnlichkeitsbegründungEin Forschungsteam der East China University of Science and Technology hat eine Methode zur netzwerkbasierten Inferenz (NBI) vorgeschlagen, die allein anhand der topologischen Ähnlichkeit bipartiter Netzwerke zwischen Arzneimittel und Ziel auf neue Ziele bekannter Arzneimittel schließt.
Mit der Entwicklung der Big Data Mining-Technologie wird die Neupositionierung von Medikamenten auf der Grundlage von maschinellem Lernen und Big Data Mining-Algorithmen immer wirksamere Methoden zur Behandlung von Krankheiten ermöglichen und ist in den Fokus der biomedizinischen Forschung gerückt. Es gibt Grund zur Annahme, dass rationales Denken und computergestützte Modellierung bei zukünftigen Prozessen zur Neupositionierung von Arzneimitteln eine wichtige Rolle spielen werden.
Quellen:
1.https://www.cn-healthcare.com/article/20191224/content-527902.html
2.https://pps.cpu.edu.cn/cn/article/pdf/preview/b286f85e-a37a-4007-ab94-918629aef556.pdf
3.https://mp.weixin.qq.com/s/lD-HyfwUHiX4f-llS6lykQ








