Command Palette
Search for a command to run...
NVIDIA Huang Renxun Hat GB200 Veröffentlicht, Das Eine 30-mal Höhere Denkfähigkeit Als H100 Und Einen 25-mal Geringeren Energieverbrauch Aufweist Und AI4S-Funktionen in Mikrodienste Verwandelt

„Der iPhone-Moment der KI ist gekommen.“ Die goldenen Worte von Huang Renxun bei NVIDIA GTC 2023 sind uns noch frisch im Gedächtnis. Die Entwicklung der KI hat in diesem Jahr auch bewiesen, dass seine Aussage stimmt.
Im Laufe der Jahre hat sich die GTC angesichts der Beschleunigung der KI-Entwicklung und der Tatsache, dass Nvidias Technologie und ökologischer Schutzgraben nur schwer zu erschüttern sind, schrittweise von einer anfänglichen technischen Konferenz zu einem KI-Branchenevent entwickelt, dem die gesamte Industriekette Aufmerksamkeit schenkt. Die Muskelkraft, die Nvidia an den Tag legt, könnte ein wichtiger Katalysator für Innovationen in der Branche sein.
Die diesjährige GTC AI-Konferenz 2024 findet wie geplant statt. Vom 18. bis 21. März finden über 900 Meetings und über 20 Fachvorträge statt. Die auffälligste Rede war natürlich immer noch die „Leather Yellow“-Rede. Gemäß dem zuvor angekündigten Zeitplan beginnt Huang Renxuns Rede am 19. März um 4:00 Uhr Pekinger Zeit und dauert bis 6:00 Uhr. Gerade eben warf Huang in einer zweistündigen Rede eine Reihe von „KI-Atombomben“ ab:
* Blackwell, die GPU-Plattform der neuen Generation
* Der erste Chip basierend auf Blackwell, GB200 Grace Blackwell
* KI-Supercomputer der nächsten Generation DGX SuperPOD
* KI-Supercomputing-Plattform DGX B200
* Netzwerk-Switch der neuen Generation der X800-Serie
* Cloud-Dienst für Quantencomputer
* Earth-2, eine Cloud-Plattform für digitale Klimazwillinge
* Generative KI-Microservices
* 5 neue Omniverse Cloud-APIs
* DRIVE Thor, eine fahrzeuginterne Computerplattform für generative KI-Anwendungen
* BioNeMo Basismodell
Link zur Live-Wiederholung:
https://www.bilibili.com/video/BV1Z6421c7V6/?spm_id_from=333.337.search-card.all.click
cuLitho in Aktion
Auf der letztjährigen GTC-Konferenz stellte NVIDIA eine Bibliothek für computergestützte Lithografie vor – cuLitho – und behauptete, sie könne die computergestützte Lithografie um mehr als das 40-fache beschleunigen. Heute gab Huang Renxun bekannt, dass TSMC und Synopsys NVIDIA cuLipo in ihre Software, Herstellungsprozesse und Systeme integriert haben, um die Chipherstellung zu beschleunigen.Beim Testen von cuLitho in einem gemeinsamen Workflow erreichten die beiden Unternehmen gemeinsam eine 45-fache Beschleunigung für kurvilineare Abläufe und eine fast 60-fache Effizienzsteigerung für traditionellere Abläufe im Manhattan-Stil.
Darüber hinaus hat NVIDIA Algorithmen zur Anwendung generativer KI entwickelt, um den Wert der cuLitho-Plattform weiter zu steigern. Insbesondere basierend auf der Verbesserung der Effizienz des Produktionsprozesses auf Basis von cuLitho,Dieser generative KI-Algorithmus ist außerdem doppelt so schnell.
Es wird berichtet, dass durch die Anwendung generativer KI eine nahezu perfekte umgekehrte Maskenlösung erstellt werden kann, bei der die Lichtbeugung berücksichtigt wird und die endgültige Maske dann durch traditionelle physikalische Methoden abgeleitet wird, wodurch die Geschwindigkeit des gesamten Prozesses der optischen Näherungskorrektur (OPC) letztendlich um das Zweifache erhöht wird.
Blackwell-Plattform für generative KI im Billionen-Parameter-Bereich

Die obige Einführung in die Anwendung von cuLitho ist eher ein „Appetitanreger“, der die Entwicklungsperspektiven der Computerlithografietechnologie demonstriert und bis zu einem gewissen Grad eine grundlegende Garantie für das Generations-Upgrade der KI-Chips von NVIDIA bietet.
Als nächstes beginnt der Hauptgang. Gemäß der NVIDIA-Tradition, die GPU-Architektur alle zwei Jahre zu aktualisieren, ist das erste Blockbuster-Produkt von Huang die neue, größere GPU – die Blackwell-Plattform. Er sagte:Hopper ist großartig, aber wir brauchen leistungsstärkere GPUs.
Die Blackwell Architecture ist nach David Harold Blackwell benannt, dem ersten Afroamerikaner, der in die National Academy of Sciences gewählt wurde.

In Bezug auf die Leistung verfügt Blackwell über 6 revolutionäre Technologien:
* Der leistungsstärkste Chip der Welt:Die GPU mit Blackwell-Architektur wird mit einem benutzerdefinierten 4NP-TSMC-Prozess hergestellt und enthält 208 Milliarden Transistoren. Es verbindet zwei extreme GPU-Chips über eine Chip-zu-Chip-Verbindung mit 10 TB/Sekunde zu einer einheitlichen GPU. Transformer Engine der zweiten Generation: Blackwell unterstützt die doppelte Rechen- und Modellgröße basierend auf neuen 4-Bit-Gleitkomma-KI-Inferenzfunktionen.
* NVLink der fünften Generation:Die neueste Version von NVIDIA NVLink bietet einen bahnbrechenden bidirektionalen Durchsatz von 1,8 TB/s pro GPU und gewährleistet eine nahtlose Hochgeschwindigkeitskommunikation zwischen bis zu 576 GPUs zur Implementierung der komplexesten LLMs.
* RAS-Engine:GPUs mit Blackwell-Technologie verfügen über eine dedizierte Engine für Zuverlässigkeit, Verfügbarkeit und Wartungsfreundlichkeit. Darüber hinaus fügt die Blackwell-Architektur Funktionen auf Chipebene hinzu, um mithilfe KI-basierter vorbeugender Wartung Diagnosen durchzuführen und Zuverlässigkeitsprobleme vorherzusagen. Dies maximiert die Systemverfügbarkeit, verbessert die Belastbarkeit groß angelegter KI-Bereitstellungen, ermöglicht deren unterbrechungsfreien Betrieb über Wochen oder sogar Monate und senkt die Betriebskosten.
* Sichere KI:Es schützt KI-Modelle und Kundendaten ohne Leistungseinbußen und unterstützt neue native Schnittstellenverschlüsselungsprotokolle, was für datenschutzsensible Branchen wie das Gesundheitswesen und den Finanzdienstleistungssektor von entscheidender Bedeutung ist.
* Dekompressions-Engine:Eine dedizierte Dekomprimierungs-Engine unterstützt die neuesten Formate und beschleunigt Datenbankabfragen, wodurch die höchste Leistung für Datenanalyse und Datenwissenschaft bereitgestellt wird.
Derzeit haben AWS, Google, Meta, Microsoft, OpenAI, Tesla und andere Unternehmen die Führung bei der „Reservierung“ der Blackwell-Plattform übernommen.
GB200 Grace Blackwell

Der erste auf Blackwell basierende Chip wurde GB200 Grace Blackwell Superchip genannt.Es verbindet zwei NVIDIA B200 Tensor Core GPUs über eine extrem stromsparende 900 GB/s NVLink-Chip-zu-Chip-Verbindung mit der NVIDIA Grace CPU.
Unter ihnen verfügt die B200-GPU mit 208 Milliarden Transistoren über mehr als die doppelte Anzahl an Transistoren wie die bestehende H100. Außerdem kann es über eine einzelne GPU eine hohe Rechenleistung von 20 Petaflops bereitstellen, während ein einzelner H100 nur maximal 4 Petaflops KI-Rechenleistung bereitstellen kann. Darüber hinaus ist die B200-GPU mit 192 GB HBM3e-Speicher ausgestattet und bietet eine Bandbreite von bis zu 8 TB/s.

GB200 ist eine Schlüsselkomponente von NVIDIA GB200 NVL72.Das NVL72 ist ein flüssigkeitsgekühltes Rack-Montagesystem mit mehreren Knoten.Es ist ideal für die rechenintensivsten Workloads und kombiniert 36 Grace Blackwell-Superchips, darunter 72 Blackwell-GPUs und 36 Grace-CPUs, die über NVLink der fünften Generation miteinander verbunden sind.
Darüber hinaus enthält der GB200 NVL72 die NVIDIA BlueField®-3-Datenverarbeitungseinheit, die Cloud-Netzwerkbeschleunigung, zusammensetzbaren Speicher, Zero-Trust-Sicherheit und GPU-Rechenelastizität in Hyperscale-KI-Clouds ermöglicht. Der GB200 NVL72 bietet bei LLM-Inferenz-Workloads eine bis zu 30-mal bessere Leistung bei bis zu 25-mal geringeren Kosten und Energieverbrauch als eine NVIDIA H100 Tensor Core GPU mit der gleichen Anzahl an GPUs.
KI-Supercomputer der nächsten Generation DGX SuperPOD
NVIDIA DGX SuperPOD verwendet eine neue flüssigkeitsgekühlte Rack-Architektur und basiert auf NVIDIA DGX GB200-Systemen.Es bietet 11,5 Exaflops KI-Superrechenleistung mit FP4-Präzision und 240 TB schnellen Speicher.Und es kann mit zusätzlichen Racks auf höhere Leistung erweitert werden. DGX SuperPOD verfügt über ein intelligentes prädiktives Management, das kontinuierlich Tausende von Datenpunkten in Hardware und Software überwacht, um Ausfallzeiten und Ineffizienzen vorherzusagen und zu unterbinden und so Zeit, Energie und Rechenkosten zu sparen.
Das DGX GB200-System ist mit 36 NVIDIA GB200-Superchips ausgestattet, darunter 36 NVIDIA Grace-CPUs und 72 NVIDIA Blackwell-GPUs, die über NVLink der fünften Generation zu einem Supercomputer verbunden sind.
Jeder DGX SuperPOD kann acht oder mehr DGX GB200s tragen, skalierbar auf Zehntausende von GB200-Superchips, die über NVIDIA Quantum InfiniBand verbunden sind. Beispielsweise können Benutzer 576 Blackwell-GPUs auf Basis der NVLink-Verbindung mit acht DGX GB200 verbinden.
KI-Supercomputing-Plattform DGX B200
DGX B200 ist eine Computerplattform für das Training, die Feinabstimmung und die Inferenz von KI-Modellen, die ein luftgekühltes, traditionelles DGX-Design zur Rackmontage verwendet. Das DGX B200-System erreicht FP4-Präzision in der neuen Blackwell-Architektur und bietet bis zu 144 Petaflops KI-Rechenleistung, 1,4 TB riesigen GPU-Speicher und 64 TB/s Speicherbandbreite.Die Echtzeit-Inferenzgeschwindigkeit für Billionen-Parameter-Modelle ist im Vergleich zur vorherigen Generation um das 15-fache erhöht.
Der DGX B200 basiert auf der neuen Blackwell-Architektur und ist mit acht Blackwell-GPUs und zwei Intel Xeon-Prozessoren der fünften Generation ausgestattet. Benutzer können mit dem DGX B200-System auch einen DGX SuperPOD erstellen. Für die Netzwerkkonnektivität ist DGX B200 mit acht NVIDIA ConnectX™-7-Netzwerkkarten und zwei BlueField-3-DPUs ausgestattet, die eine Bandbreite von bis zu 400 Gigabit pro Sekunde bieten.
Netzwerk-Switch-Serie der neuen Generation – X800
Berichten zufolge ist die neue Generation der Netzwerk-Switches der X800-Serie für künstliche Intelligenz im großen Maßstab konzipiert und durchbricht die Netzwerkleistungsgrenzen von Computer- und KI-Workloads.
Die Plattform umfasst NVIDIA Quantum Q3400-Switches und NVIDIA ConnectX@-8-Supernetzwerkkarten und erreicht einen branchenführenden End-to-End-Durchsatz von 800 Gb/s.Die Bandbreitenkapazität ist im Vergleich zur vorherigen Produktgeneration um das Fünffache erhöht.Gleichzeitig wurde durch die Übernahme des Scalable Hierarchical Aggregation and Reduction Protocol (SHARPv4) von NVIDIA eine In-Network-Rechenleistung von bis zu 14,4 Tflops erreicht.Die Leistungssteigerung beträgt bis zu 9-mal im Vergleich zur vorherigen Generation.
Quantencomputing-Clouddienste beschleunigen die wissenschaftliche Forschung
Der Quantencomputing-Cloud-Dienst von NVIDIA basiert auf der Open-Source-Quantencomputing-Plattform CUDA-Q des Unternehmens.Drei Viertel der Unternehmen, die derzeit Quantenverarbeitungseinheiten (QPUs) in der Branche einsetzen, verwenden die Plattform. Mit dem Cloud-Dienst für Quantencomputing von Nvidia können Benutzer erstmals neue Quantenalgorithmen und -anwendungen in der Cloud erstellen und testen, darunter leistungsstarke Simulatoren und Tools für die Quantenhybridprogrammierung.
Die Quantum Computing Cloud verfügt über leistungsstarke Funktionen und Softwareintegrationen von Drittanbietern zur Beschleunigung wissenschaftlicher Entdeckungen, darunter:
* Ein generativer Quanteneigenlöser, der in Zusammenarbeit mit der Universität Toronto entwickelt wurde und große Sprachmodelle verwendet, um es Quantencomputern zu ermöglichen, die Grundzustandsenergie von Molekülen schneller zu ermitteln.
* Die Integration von Classiq mit CUDA-Q ermöglicht Quantenforschern, große, komplexe Quantenprogramme zu generieren und Quantenschaltkreise gründlich zu analysieren und auszuführen.
* QC Ware Promethium kann komplexe Probleme der Quantenchemie wie Molekülsimulationen lösen.
Veröffentlichung von Earth-2, einer Cloud-Plattform für digitale Klimazwillinge
Ziel von Earth-2 ist es, Wetter und Klima im großen Maßstab zu simulieren und zu visualisieren und so die Vorhersage extremer Wetterereignisse zu ermöglichen. Die Earth-2-API bietet KI-Modelle und verwendet das CorrDiff-Modell.
CorrDiff ist ein neues generatives KI-Modell, das von NVIDIA eingeführt wurde. Es verwendet das SOTA-Diffusionsmodell.Die resultierenden Bilder haben eine 12,5-mal höhere Auflösung als bestehende numerische Modelle, sind 1.000-mal schneller und 3.000-mal energieeffizienter.Es überwindet die Ungenauigkeit von Vorhersagen mit grober Auflösung und integriert Metriken, die für die Entscheidungsfindung entscheidend sind.

CorrDiff ist das erste generative KI-Modell seiner Art, das Superauflösung bietet, neue wichtige Messgrößen synthetisiert und die Physik des lokalen, feinkörnigen Wetters aus hochauflösenden Datensätzen lernt.
Veröffentlichung generativer KI-Mikrodienste zur Förderung der Arzneimittelentwicklung, der Iteration medizintechnischer Verfahren und der digitalen Gesundheit
Die neue NVIDIA-Microservices-Suite für das Gesundheitswesen umfasst optimierte NVIDIA NIM™-KI-Modelle und branchenübliche API-Workflows, die als Bausteine für die Erstellung und Bereitstellung Cloud-nativer Anwendungen dienen. Diese Mikrodienste umfassen Funktionen wie erweiterte Bildgebung, natürliche Sprach- und Sprecherkennung, Generierung digitaler Biologie, Vorhersage und Simulation.
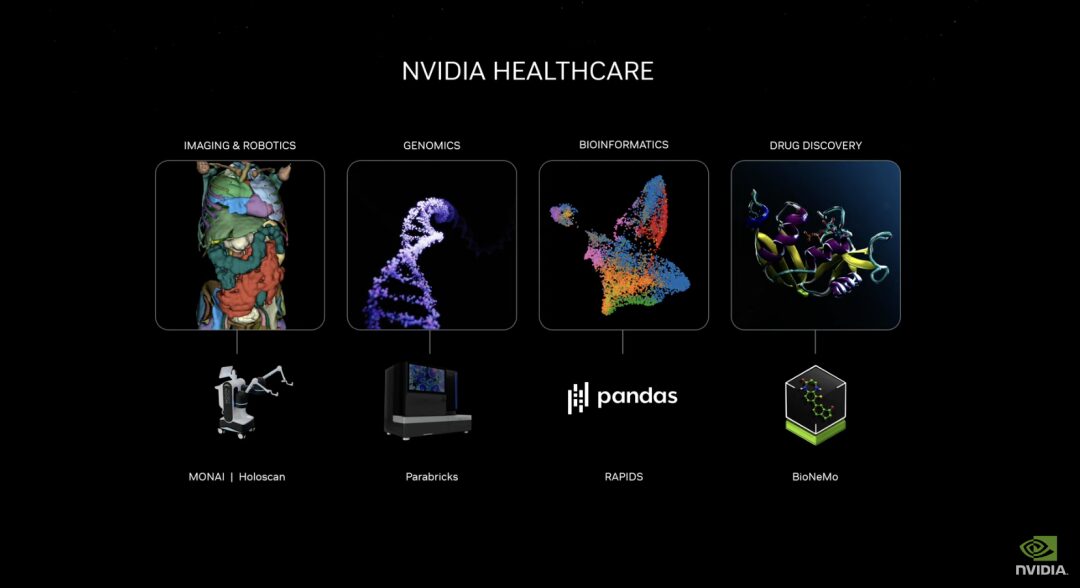
Darüber hinaus sind NVIDIA Accelerated Software Development Kits und zugehörige Tools, darunter Parabricks®, MONAI, NeMo™, Riva und Metropolis, jetzt über NVIDIA CUDA-X™-Mikroservices zugänglich.
Inferenz-Mikrodienst
Geben Sie Dutzende generativer KI-Microservices auf Unternehmensniveau frei, mit denen Unternehmen benutzerdefinierte Anwendungen auf ihren eigenen Plattformen erstellen und bereitstellen können, während ihr geistiges Eigentum erhalten bleibt.
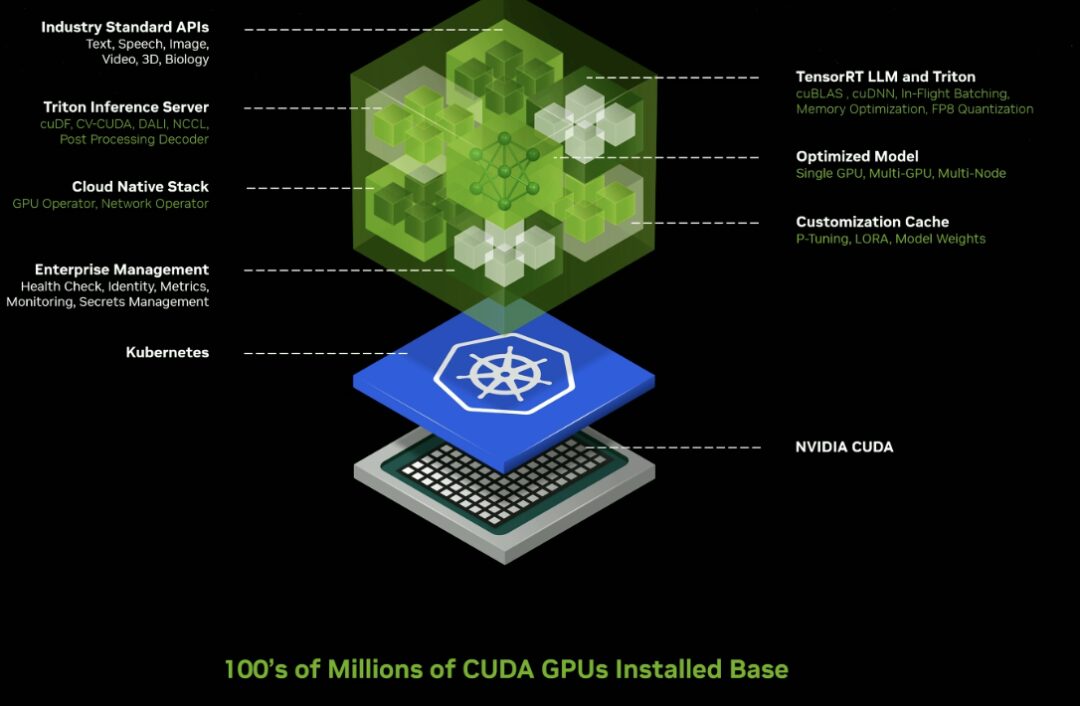
Neue GPU-beschleunigte NVIDIA NIM Microservices und Cloud Endpoints für vortrainierte KI-Modelle, die für die Ausführung auf Hunderten Millionen CUDA-fähiger GPUs in Clouds, Rechenzentren, Workstations und PCs optimiert sind.
Unternehmen können Microservices nutzen, um die Datenverarbeitung, LLM-Anpassung, Argumentation, Generierung von Abrufverbesserungen und den Schutz zu beschleunigen.
Wird von einem breiten KI-Ökosystem übernommen, darunter führende Anwendungsplattformanbieter wie Cadence, CrowdStrike, SAP, ServiceNow und andere.
NIM Microservices bietet vorgefertigte Container auf Basis von NVIDIA-Inferenzsoftware, darunter Triton Inference Server™ und TensorRT™-LLM, wodurch die Bereitstellungszeit von Wochen auf Minuten reduziert werden kann.
Veröffentlichung der Omniverse Cloud API zur Unterstützung industrieller Digital-Twin-Softwaretools
Mithilfe von fünf neuen Omniverse Cloud-APIs können Entwickler die Kerntechnologien von Omniverse direkt in vorhandene Softwareanwendungen für das Design digitaler Zwillinge und die Automatisierung sowie in Simulations-Workflows zum Testen und Validieren von Robotern oder selbstfahrenden Autos integrieren, beispielsweise durch das Streamen interaktiver industrieller digitaler Zwillinge auf Apple Vision Pro.
Zu diesen APIs gehören:
* USD-Rendering:Generieren von NVIDIA RTX™-Rendering von globalen Raytracing-OpenUSD-Daten
* USD Schreiben:Ermöglicht Benutzern, OpenUSD-Daten zu ändern und mit ihnen zu interagieren.
* USD-Abfrage:Unterstützt Szenenabfragen und Szeneninteraktionen.
* USD-Benachrichtigung:Verfolgen Sie USD-Änderungen und stellen Sie Updates bereit.
* Omniverse-Kanal:Verknüpfung von Benutzern, Tools und Realität für eine szenarioübergreifende Zusammenarbeit
Huang Renxun glaubt, dass in Zukunft alles, was hergestellt wird, einen digitalen Zwilling haben wird. Omniverse ist das Betriebssystem zum Erstellen und Ausführen digitaler Zwillinge der physischen Realität. Omniverse und generative künstliche Intelligenz sind die grundlegenden Technologien für die Digitalisierung des 50 Billionen Dollar schweren Schwerindustriemarktes.
DRIVE Thor: Generative KI mit Blackwell Architecture für autonomes Fahren
DRIVE Thor ist eine fahrzeuginterne Computerplattform, die für generative KI-Anwendungen entwickelt wurde und funktionsreiches simuliertes Fahren sowie hochautomatisierte Fahrfunktionen auf einer zentralen Plattform bietet. Als Zentralcomputer der nächsten Generation für autonome Fahrzeuge ist er sicher und zuverlässig und vereint intelligente Funktionen in einem System, um die Effizienz zu verbessern und die Kosten des gesamten Systems zu senken.
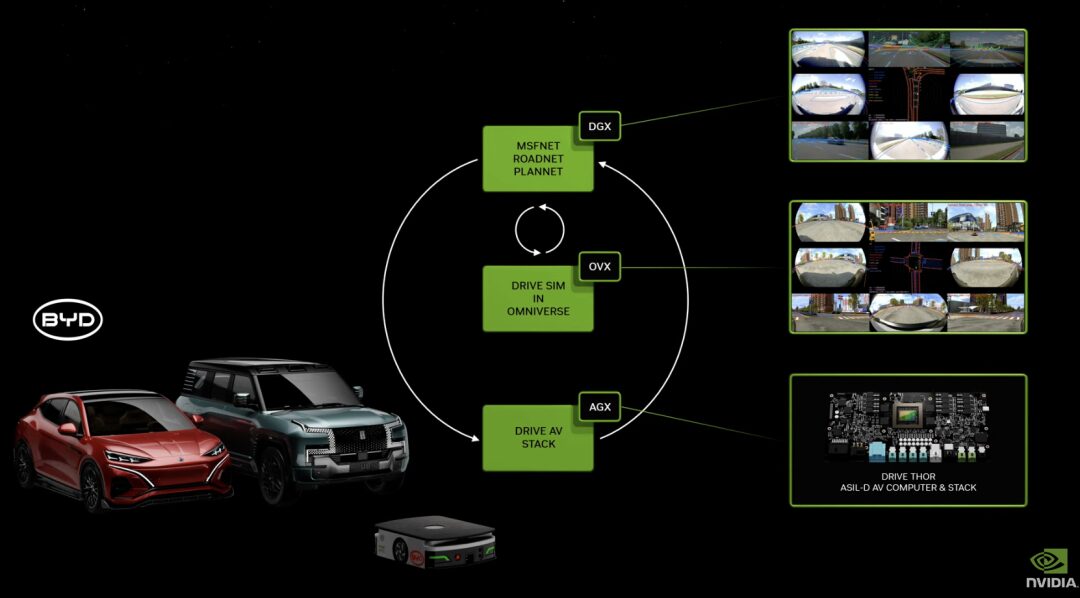
DRIVE Thor wird auch die neue NVIDIA Blackwell-Architektur integrieren.Die Architektur ist für Transformer-, LLM- und generative KI-Workloads konzipiert.
BioNeMo: Unterstützung bei der Arzneimittelforschung
Das Basismodell von BioNeMo kann DNA-Sequenzen analysieren, die Formänderungen von Proteinen unter der Einwirkung von Arzneimittelmolekülen vorhersagen und die Funktion von Zellen auf der Grundlage von RNA bestimmen.
Derzeit basiert das erste von BioNeMo bereitgestellte Genommodell DNABERT auf DNA-Sequenzen und kann verwendet werden, um die Funktionen bestimmter Regionen des Genoms vorherzusagen, die Auswirkungen von Genmutationen und -variationen zu analysieren usw. Das zweite Modell, scBERT, das in Kürze auf den Markt kommt, wird auf der Grundlage von Einzelzell-RNA-Sequenzierungsdaten trainiert. Benutzer können es für nachgelagerte Aufgaben verwenden, beispielsweise zur Vorhersage der Auswirkungen eines Gen-Knockouts (d. h. Löschen oder Deaktivieren bestimmter Gene) und zur Identifizierung von Zelltypen wie Neuronen, Blutzellen oder Muskelzellen.
Berichten zufolge gibt es derzeit weltweit mehr als 100 Unternehmen, die ihren Forschungs- und Entwicklungsprozess auf der Grundlage von BioNeMo vorantreiben, darunter das in Tokio ansässige Unternehmen Astellas Pharma, der Computersoftwareentwickler Cadence, das Arzneimittelentwicklungsunternehmen Iambic und so weiter.
Letzte Worte
Zusätzlich zu den vielen oben genannten neuen Produkten stellte Huang Renxun auch NVIDIAs Layout im Bereich Robotik vor. Huang sagte, dass alles, was sich bewegt, ein Roboter sei und die Automobilindustrie ein wichtiger Teil davon sein werde. Derzeit werden NVIDIA-Computer in Autos, Lastwagen, Lieferrobotern und Robotertaxis eingesetzt. Anschließend brachte das Unternehmen auch das Software Development Kit Isaac Perceptor, das universelle Basismodell für humanoide Roboter GR00T und den neuen Computer Jetson Thor für humanoide Roboter auf Basis des NVIDIA Thor-System-on-Chip auf den Markt und nahm umfangreiche Upgrades an der NVIDIA Isaac-Roboterplattform vor.
Zusammenfassend war die zweistündige Sharing-Session voller Vorstellungen leistungsstarker Produkte und Modelle. Eine derart rasante und inhaltsreiche Pressekonferenz spiegelt genau den aktuellen Entwicklungsstand der KI-Branche wider – schnell und erfolgreich.
Als Grundlage des KI-Zeitalters ist die Rechenleistung von Hochleistungschips der Schlüssel zur Bestimmung des Entwicklungszyklus und der Richtung der Branche. Es besteht kein Zweifel, dass Nvidia derzeit über einen unerschütterlichen Burggraben verfügt. Obwohl viele Unternehmen begonnen haben, Huang anzugreifen, und OpenAI, Microsoft, Google usw. ebenfalls ihre eigenen „Armeen“ aufbauen, könnte dies ein größerer Anstoß für Nvidia sein, das sich weiterhin mit hoher Geschwindigkeit weiterentwickelt.
Nun ist die Online-Liveübertragung beendet. Nach jeder neuen Produktveröffentlichung gibt Huang Renxun bekannt, welche Partner die neuen Dienste „reserviert“ haben, und auf der Liste stehen ausnahmslos alle großen Unternehmen. Wir gehen außerdem davon aus, dass die derzeit führenden Unternehmen der Branche in der Zukunft die höhere Produktivität der Branche nutzen können, um noch mehr innovative Produkte und Anwendungen auf den Markt zu bringen.








