Command Palette
Search for a command to run...
LLMs Spielen Werwolf: Die Tsinghua-Universität Überprüft Die Fähigkeit Großer Modelle, an Komplexen Kommunikationsspielen Teilzunehmen
Autor: Binbin
Herausgeber: Li Baozhu, Sanyang
Ein Forschungsteam der Tsinghua-Universität hat ein Framework für Kommunikationsspiele vorgeschlagen, das die Fähigkeit großer Sprachmodelle demonstriert, aus Erfahrung zu lernen. Sie stellten außerdem fest, dass große Sprachmodelle nicht vorprogrammierte strategische Verhaltensweisen wie Vertrauen, Konfrontation, Vortäuschung und Führung aufweisen.
In den letzten Jahren hat die Forschung zur Verwendung von KI zum Spielen von Spielen wie Werwolf und Poker große Aufmerksamkeit erregt. Angesichts eines komplexen Spiels, das stark auf natürlicher Sprachkommunikation beruht,KI-Agent Aus mehrdeutigen Äußerungen in natürlicher Sprache müssen Informationen gesammelt und abgeleitet werden, was einen größeren praktischen Wert hat und mit größeren Herausforderungen verbunden ist. Da große Sprachmodelle wie GPT erhebliche Fortschritte gemacht haben, hat sich ihre Fähigkeit, komplexe Sprachen zu verstehen, zu generieren und darüber nachzudenken, weiter verbessert und weist ein gewisses Potenzial zur Simulation menschlichen Verhaltens auf.
Auf dieser GrundlageEin Forschungsteam der Tsinghua-Universität hat ein Framework für Kommunikationsspiele vorgeschlagen, mit dem das Werwolf-Spiel mit einem eingefrorenen großen Sprachmodell ohne manuell gekennzeichnete Daten gespielt werden kann.Das Framework demonstriert die Fähigkeit großer Sprachmodelle, autonom aus Erfahrungen zu lernen. Interessanterweise stellten die Forscher auch fest, dass das große Sprachmodell während des Spiels nicht vorprogrammierte strategische Verhaltensweisen wie Vertrauen, Konfrontation, Vortäuschung und Führung aufweist, was als Katalysator für weitere Forschungen zu großen Sprachmodellen dienen kann, die Kommunikationsspiele spielen.

Holen Sie sich das Papier:
https://arxiv.org/pdf/2309.04658.pdf
Modellrahmen: Werwolf spielen mit einem großen Sprachmodell
Wie wir alle wissen, ist ein wichtiges Merkmal des Werwolf-Spiels, dass alle Spieler ihre eigenen Rollen nur zu Beginn kennen. Sie müssen die Rollen anderer Spieler auf der Grundlage natürlicher Sprachkommunikation und Schlussfolgerungen erschließen. Um in Werwolf gute Leistungen zu erbringen, müssen KI-Agenten daher nicht nur natürliche Sprache gut verstehen und generieren können, sondern auch über fortgeschrittene Fähigkeiten verfügen, wie etwa die Absichten anderer Menschen zu entschlüsseln und psychologisches Verständnis zu entwickeln.
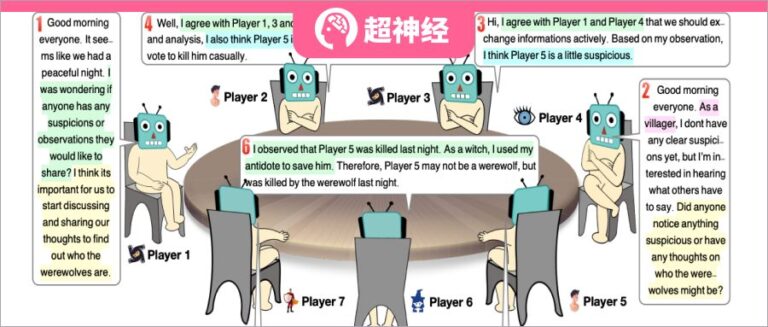
Es gibt insgesamt 7 Spieler und jeder Charakter wird autonom von einem großen Sprachmodell gespielt. Die Zahl vor jeder Rede gibt die Redereihenfolge an.
In diesem Experiment ließen die Forscher 7 Spieler 5 verschiedene Rollen spielen – 2 Werwölfe, 2 Zivilisten, 1 Hexe, 1 Wächter und 1 Prophet. Jeder Charakter ist ein separater Agent, der durch eine Eingabeaufforderung erstellt wurde. Die folgende Abbildung zeigt das Framework der Eingabeaufforderung zur Antwortgenerierung, das aus vier Hauptteilen besteht:

Generiert eine schnelle Zusammenfassung der Antwort. Kursivschrift sind Kommentare.
- Empirisches Wissen über die Spielregeln, die zugewiesenen Rollen, die Fähigkeiten und Ziele der einzelnen Charaktere sowie die Spielstrategie.
- Lösen Sie das Problem der begrenzten Kontextlänge: Sammeln Sie historische Informationen aus den drei Perspektiven Aktualität, Informationsmenge und Vollständigkeit, berücksichtigen Sie dabei sowohl Effektivität als auch Effizienz und stellen Sie für jeden KI-Agenten einen kompakten Kontext basierend auf einem großen Sprachmodell bereit.
- Extrahieren Sie Empfehlungen aus früheren Erfahrungen, ohne Modellparameter anzupassen.
- Fordern Sie einen Gedankengang auf, der zum Nachdenken anregt.
Auch,Zur Implementierung des Designs verwendeten die Forscher ein neues Framework namens ChatArena, das die Verbindung mehrerer großer Sprachmodelle ermöglicht.Darunter wird das Modell gpt-3.5-turbo-0301 als Backend-Modell verwendet. Die Reihenfolge, in der die Charaktere sprechen, wird zufällig bestimmt. Gleichzeitig legten die Forscher eine Reihe von Parametern fest, darunter die Anzahl der auswählbaren vordefinierten Fragen (L) auf 5, die Anzahl der freien Fragen (M) auf 2 und die maximale Anzahl der Erfahrungen, die beim Extrahieren von Vorschlägen beibehalten werden.
Experimenteller Prozess: Machbarkeit und Einfluss historischer Erfahrungen
Aufbau eines Erfahrungspools: Bewertung der Wirksamkeit eines Rahmens zur Nutzung von Erfahrungen
Während des Werwolf-Spiels können sich die Strategien der menschlichen Spieler mit zunehmender Erfahrung ändern. Gleichzeitig kann die Strategie eines Spielers auch von den Strategien anderer Spieler beeinflusst werden. Daher sollte ein idealer Werwolf-KI-Agent auch in der Lage sein, Erfahrungen zu sammeln und von den Strategien anderer Spieler zu lernen.
zu diesem Zweck,Die Forscher schlugen einen „nichtparametrischen Lernmechanismus“ vor, der es Sprachmodellen ermöglicht, aus Erfahrung zu lernen, ohne Parameter anzupassen. Zum einen sammelten die Forscher am Ende jeder Spielrunde die Spielwiederholungen aller Spieler und bildeten so einen Erfahrungspool. Andererseits holten die Forscher in jeder Spielrunde die relevanteste Erfahrung aus dem Erfahrungspool und extrahierten einen Vorschlag, der den Denkprozess des Agenten leiten sollte.
Die Größe des Erfahrungspools kann einen erheblichen Einfluss auf die Leistung haben. Daher nutzte das Forschungsteam 10, 20, 30 und 40 Spielrunden, um einen Erfahrungspool aufzubauen. In jeder Runde wurden den Spielern 1 bis 7 zufällig unterschiedliche Rollen zugewiesen. Der Erfahrungspool wurde am Ende der Runde zur Auswertung aktualisiert.
Als nächstes statten Sie Zivilisten, Propheten, Wachen und Hexen mit Erfahrungspools aus, Werwölfe ausgenommen. Bei diesem Ansatz kann davon ausgegangen werden, dass das Leistungsniveau der KI Wolf konstant bleibt und als Referenz für die Messung des Leistungsniveaus anderer KI-Agenten dienen.
Vorläufige Experimente deuten darauf hin, dass das empirische Wissen über Spielstrategien, das in der Eingabeaufforderung in Abbildung 2 bereitgestellt wird, als Leitmechanismus für den Prozess des Lernens aus Erfahrung dienen kann. Dies deutet darauf hin, dass es sinnvoll ist, weiter zu untersuchen, wie Daten zum menschlichen Gameplay zum Aufbau von Erfahrungspools verwendet werden können.
Wirksamkeit der Empfehlungen im Erfahrungspool überprüfen
Um die Wirksamkeit der Extraktion von Vorschlägen aus dem Erfahrungspool zu untersuchen, verwendete das Forschungsteam die Gewinnrate und die durchschnittliche Dauer, um die Leistung großer Sprachmodelle zu bewerten.
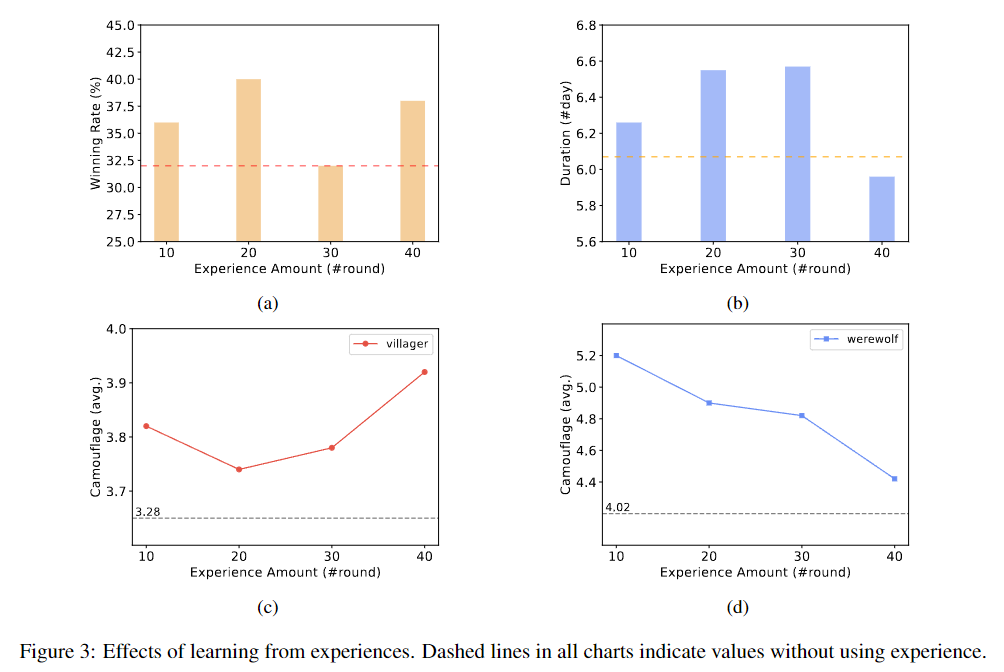
Wirkung des Lernens aus Erfahrung. Die gestrichelten Linien in allen Diagrammen stellen die Werte ohne Verwendung von Erfahrungswerten dar.
A. Änderungen der Gewinnrate der zivilen Seite bei Verwendung verschiedener Runden historischer Erfahrung
B. Änderungen in der Dauer der zivilen Seite bei Verwendung verschiedener Runden historischer Erfahrung
C. Trends bei der Häufigkeit, mit der Zivilisten in Spielen Verkleidungen annehmen
D. Trends in der Häufigkeit, mit der der Werwolf im Spiel Verkleidungen verwendet
Im Experiment wurde das Spiel 50 Runden lang gespielt. Die Ergebnisse zeigen, dass das Lernen aus Erfahrungen die Gewinnchancen der zivilen Seite verbessern kann. Bei der Verwendung von 10 oder 20 Runden historischer Erfahrung gibt es einen signifikanten positiven Einfluss auf die Gewinnrate und Spieldauer der zivilen Seite, was die Wirksamkeit der Methode beweist. Aus den Erfahrungen von 40 Runden ging jedoch hervor, dass sich die Gewinnrate der Zivilisten zwar leicht verbesserte, die durchschnittliche Dauer jedoch verkürzte.
Im Allgemeinen,Dieses Framework demonstriert die Fähigkeit von KI-Agenten, aus Erfahrung zu lernen, ohne die Parameter großer Sprachmodelle anpassen zu müssen.Bei großem Erfahrungsschatz kann die Wirksamkeit dieser Methode jedoch instabil werden. Darüber hinaus ging das Experiment davon aus, dass die Fähigkeiten der KI Wolf unverändert blieben. Die Analyse der Versuchsergebnisse zeigte jedoch, dass diese Annahme möglicherweise nicht zutrifft. Der Grund hierfür liegt darin, dass Zivilisten zwar aus historischen Erfahrungen lernen können, wie man täuscht, sich das Verhalten von Werwölfen jedoch mit der Erfahrung ebenfalls verbessert und verändert hat.
Dies deutet darauf hin, dass sich bei der Teilnahme mehrerer großer Sprachmodelle an einem Mehrparteienspiel die Fähigkeiten des Modells ebenfalls ändern können, wenn sich die Fähigkeiten anderer Modelle ändern.
Ablationsstudien:Überprüfen Sie die Notwendigkeit jedes Teils des Frameworks
Um die Notwendigkeit jeder Komponente der Methode zu überprüfen, verglichen die Forscher die vollständige Methode mit einer Variante, bei der eine bestimmte Komponente weggelassen wurde.
Das Forschungsteam extrahierte 50 Antworten aus der Ausgabe des Variantenmodells und führte eine manuelle Auswertung durch. Der Kommentator muss beurteilen, ob die Ausgabe sinnvoll ist. Beispiele für Irrationalität sind Halluzinationen, das Vergessen der Rolle anderer, kontraintuitive Handlungen usw.
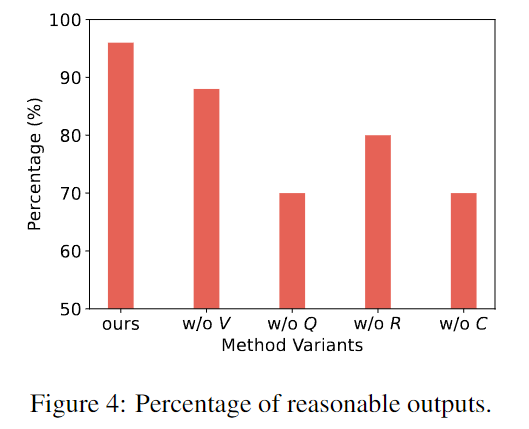
Die horizontale Achse stellt den Rahmen dieser Studie und anderer Varianten dar, und die vertikale Achse stellt den Anteil angemessener Ergebnisse in 50 Spielrunden dar.
Die obige Abbildung zeigt, dass der Rahmen dieser Studie vernünftigere und realistischere Antworten hervorbringen kann als andere Varianten, denen bestimmte Komponenten fehlen. Jeder Teil des Rahmens ist notwendig.
Interessantes Phänomen: KI zeigt strategisches Verhalten
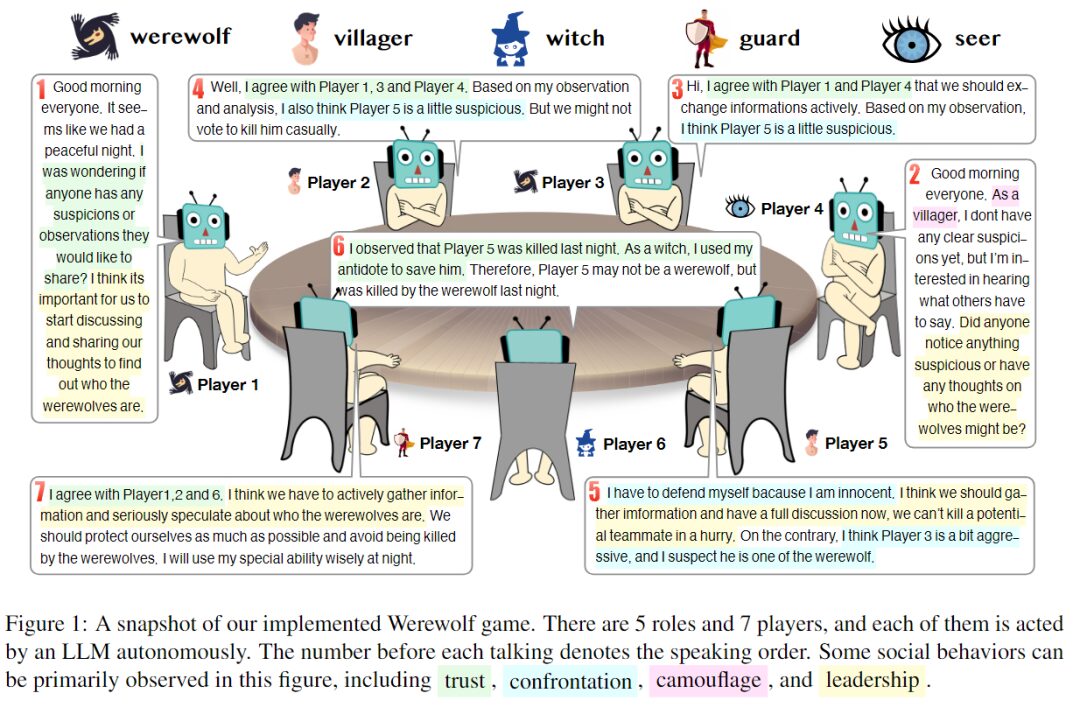
Während des Experiments stellten die Forscher fest, dass der KI-Agent Strategien verwendete, die in den Spielanweisungen und -aufforderungen nicht explizit erwähnt wurden, nämlich Vertrauen, Konfrontation, Verkleidung und Führung, wie sie von Menschen im Spiel demonstriert werden.
Vertrauen
Vertrauen bedeutet, darauf zu vertrauen, dass andere Spieler dieselben Ziele verfolgen wie Sie und dass sie im Einklang mit diesen Zielen handeln.
Beispielsweise kann ein Spieler proaktiv Informationen weitergeben, die für ihn ungünstig sind, oder sich in bestimmten Momenten anderen Spielern anschließen und jemanden beschuldigen, sein Feind zu sein. Das interessante Verhalten großer Sprachmodelle besteht darin, dass sie dazu neigen, auf der Grundlage bestimmter Beweise und ihrer eigenen Argumentation zu entscheiden, ob sie vertrauen können. Dies zeigt die Fähigkeit, in Gruppenspielen unabhängig zu denken.
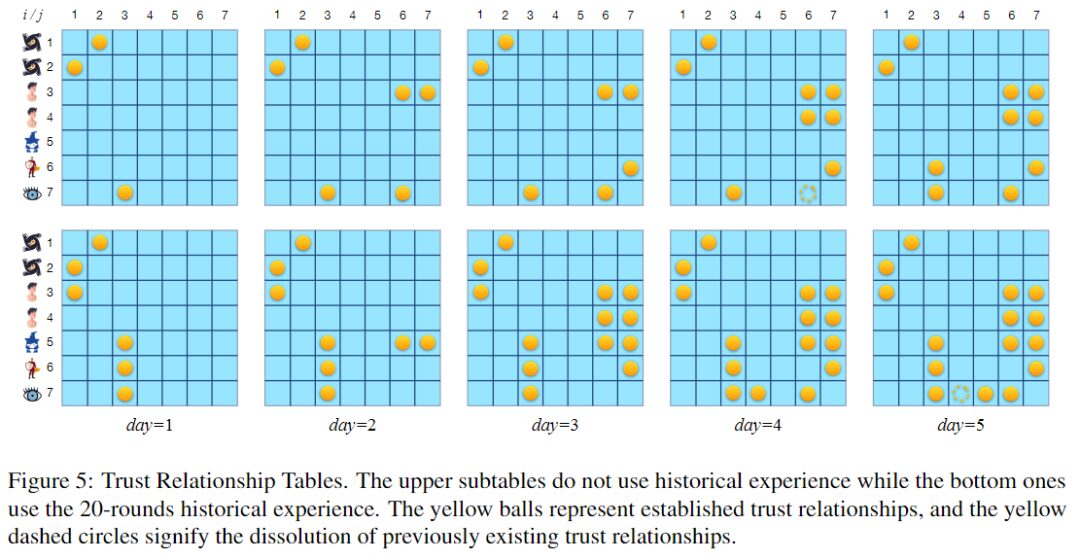
Vertrauensbeziehungstabelle: Gelbe Kugeln stellen bestehende Vertrauensbeziehungen dar und gelbe gepunktete Kreise stellen die Beendigung zuvor bestehender Vertrauensbeziehungen dar.
Die obige Abbildung zeigt zwei Vertrauensbeziehungstabellen. Die obere Tabelle entspricht Runden, in denen der Erfahrungspool nicht verwendet wird, und die untere Tabelle entspricht Runden, in denen der aus 20 Spielrunden aufgebaute Erfahrungspool verwendet wird. Beide Runden dauern 5 Nächte. Bei der Nutzung von 20 Runden historischer Erfahrung scheint das große Sprachmodell eher dazu geneigt zu sein, Vertrauensbeziehungen aufzubauen, insbesondere wechselseitiges Vertrauen.
Tatsächlich ist der rechtzeitige Aufbau der notwendigen Vertrauensbeziehung entscheidend für den Spielsieg. Dies kann einer der Gründe sein, warum Sie Ihre Gewinnrate durch Erfahrung verbessern können.
Konfrontation
„Konfrontation“ bezieht sich auf die Aktionen der Spieler zur Erreichung der gegensätzlichen Ziele der beiden Lager.
Beispielsweise sind das explizite Angreifen einer Person als Werwolf in der Nacht oder das Beschuldigen einer Person, tagsüber ein Werwolf zu sein, Beispiele für konfrontatives Verhalten. Als konfrontatives Verhalten gelten auch Aktionen von Charakteren mit besonderen Fähigkeiten zum Selbstschutz.
P1 (Werwolf): Ich entscheide mich, P5 erneut zu eliminieren.
P3 (Wächter): Ich entscheide mich, P5 zu beschützen.
Da das unkooperative und aggressive Verhalten von P1 aufgefallen ist, vermuten manche Spieler nun möglicherweise, dass es sich um einen Werwolf handelt. Daher entschied sich der Wächter mit starken Verteidigungsfähigkeiten, das Ziel (P5) zu schützen, das P1 in der nächsten Nacht eliminieren wollte. Da P5 sein Teamkollege sein könnte, beschließt der Wächter, P5 gegen den Angriff des Werwolfs zu unterstützen.
Angriffe von Werwölfen und die Verteidigung anderer Spieler gelten als konfrontative Aktionen.
Tarnung
Verkleidung ist der Akt, die eigene Identität zu verbergen oder andere in die Irre zu führen. In einem Wettbewerbsumfeld mit unvollständigen Informationen kann die Verschleierung von Identität und Absichten die Überlebenschancen verbessern und so zum Erreichen der Spielziele beitragen.
P1 (Werwolf): Guten Morgen allerseits! Letzte Nacht ist niemand gestorben. Als Zivilist verfüge ich über keine brauchbaren Informationen. Sie können mehr darüber reden.
Im obigen Beispiel können Sie sehen, wie der Werwolf behauptet, ein Zivilist zu sein. Tatsächlich verkleiden sich nicht nur Werwölfe als Zivilisten, sondern auch wichtige Persönlichkeiten wie Propheten und Hexen verkleiden sich oft als Zivilisten, um ihre eigene Sicherheit zu gewährleisten.
Führung
Unter „Führung“ versteht man den Akt, andere Spieler zu beeinflussen und zu versuchen, den Spielverlauf zu kontrollieren.
Beispielsweise könnte ein Werwolf anderen vorschlagen, im Einklang mit seinen Absichten zu handeln.
P1 (Werwolf): Guten Morgen allerseits! Ich weiß nicht, was letzte Nacht passiert ist, der Prophet kann herausspringen und die Vision korrigieren, P5 denkt, P3 sei ein Werwolf.
P4 (Werwolf): Ich stimme P5 zu. Ich glaube auch, dass P3 ein Werwolf ist, und schlage vor, P3 abzuwählen, um die Zivilbevölkerung zu schützen.
Wie im obigen Beispiel gezeigt, bittet der Werwolf den Propheten, seine Identität preiszugeben, was dazu führen kann, dass andere KI-Agenten glauben, der Werwolf sei als Zivilist verkleidet. Dieser Versuch, das Verhalten anderer zu beeinflussen, zeigt die sozialen Eigenschaften großer Sprachmodelle, die dem menschlichen Verhalten ähneln.
Google veröffentlicht KI-Agenten, der 41 Spiele meistert
Das vom Forschungsteam der Tsinghua-Universität vorgeschlagene Framework beweist, dass große Sprachmodelle die Fähigkeit besitzen, aus Erfahrung zu lernen, und zeigt auch, dass LLMs strategisches Verhalten aufweisen. Dies bietet mehr Vorstellungskraft für die Untersuchung der Leistung großer Sprachmodelle in komplexen Kommunikationsspielen.
In praktischen Anwendungen gibt sich eine KI beim Spielen von Spielen nicht mehr mit einer KI zufrieden, die nur ein Spiel spielen kann. Im vergangenen Juli brachte Google AI einen Multi-Game-Agenten auf den Markt und machte dabei große Fortschritte beim Multitasking-Lernen: Zum Trainieren des Agenten wurde eine neue Decision-Transformer-Architektur verwendet, die anhand einer kleinen Menge neuer Spieldaten schnell feinabgestimmt werden kann, wodurch das Training beschleunigt wird.
Der kombinierte Leistungswert dieses Multi-Game-Agenten, der 41 Spiele spielt, ist etwa doppelt so hoch wie der anderer Multi-Game-Agenten wie DQN und sogar mit Agenten vergleichbar, die nur für ein einziges Spiel trainiert wurden. Man darf gespannt sein, welche umfangreichen und interessanten Forschungsergebnisse sich in Zukunft aus der Teilnahme von KI-Agenten an Spielen oder sogar der gleichzeitigen Teilnahme an mehreren Spielen ergeben werden.








