Command Palette
Search for a command to run...
30 Wissenschaftler Veröffentlichten Gemeinsam Eine Nature-Rezension, in Der Sie 10 Jahre Revue Passieren Ließen Und Analysierten, Wie KI Das Wissenschaftliche Forschungsparadigma Veränderte

Wissenschaftliche Entdeckungen sind ein komplexer Prozess, der mehrere miteinander verbundene Phasen umfasst, darunter die Bildung von Hypothesen, die Versuchsplanung sowie die Erhebung und Analyse von Daten. In den letzten Jahren hat die Integration von KI und wissenschaftlicher Grundlagenforschung immer stärker zugenommen. Mithilfe von KI konnten Wissenschaftler den Fortschritt der wissenschaftlichen Forschung beschleunigen und die Umsetzung wissenschaftlicher Forschungsergebnisse fördern.
Die renommierte Fachzeitschrift „Nature“ veröffentlichte einen Artikel von Hanchen Wang, einem Postdoktoranden an der School of Computer Science and Gene Technology der Stanford University, Tianfan Fu vom Department of Computer Science and Engineering des Georgia Institute of Technology, Yuanqi Du vom Department of Computer Science der Cornell University und 30 weiteren Personen.In diesem Artikel wird die Rolle der KI in der wissenschaftlichen Grundlagenforschung im letzten Jahrzehnt untersucht und auf die verbleibenden Herausforderungen und Mängel hingewiesen.
Dieses Dokument fasst die Dokumente zusammen.
Lesen Sie das vollständige Dokument:https://www.nature.com/articles/s41586-023-06221-2

Fallstudie zur Integration von KI und wissenschaftlicher Grundlagenforschung Bildquelle: Originaldokument, ins Chinesische übersetzt von HyperAI
01 KI-gestützte Erfassung und Organisation wissenschaftlicher Forschungsdaten
Da Umfang und Komplexität der von experimentellen Plattformen gesammelten Daten weiter zunehmen, sind Echtzeitverarbeitung und Hochleistungsrechnen (HPC) erforderlich, um die schnell generierten Daten selektiv zu speichern und zu analysieren.
Datenauswahl
Bei Teilchenkollisionsexperimenten beispielsweise werden pro Sekunde über 100 TB Daten erzeugt, was für die bestehenden Datenübertragungs- und Speichertechnologien eine enorme Herausforderung darstellt. Bei diesen physikalischen Experimenten müssen Metadaten über 99,99% in Echtzeit erkannt und irrelevante Daten verworfen werden.Technologien wie Deep Learning und automatische Encoder können dabei helfen, abnormale Ereignisse in ähnlichen wissenschaftlichen Forschungsarbeiten zu erkennen und den Druck bei der Datenübertragung und -verarbeitung erheblich zu reduzieren.
Derzeit werden diese Technologien in Bereichen wie Physik, Neurowissenschaften, Geowissenschaften, Ozeanographie und Astronomie breit eingesetzt.
Datenannotation
Pseudo-Labeling- und Label-Propagation-Algorithmen sind von großer Bedeutung, um mühsames Daten-Labeling zu ersetzen. Sie können dem Modell ermöglichen, große Datenmengen automatisch zu beschriften, wobei nur eine kleine Menge genau beschrifteter Daten verwendet wird.
Datengenerierung
Durch automatische Datenerweiterung und tiefe generative Modelle können zusätzliche synthetische Datenpunkte generiert werden, um die Trainingsdaten zu erweitern.Experimente haben gezeigt, dass Generative Adversarial Networks (GANs) in vielen Bereichen realistische Bilder synthetisieren können.Diese reichen von Partikelkollisionsereignissen, pathologischen Schnitten, Röntgenaufnahmen des Brustkorbs, Magnetresonanzkontrasten, dreidimensionalen (3D) Materialmikrostrukturen, Proteinfunktionen bis hin zu Gensequenzen.
Datenoptimierung
KI kann die Bildauflösung erheblich verbessern, Rauschen reduzieren und Fehler bei der Rundheitsmessung eliminieren und so eine hohe Genauigkeitskonsistenz über alle Standorte hinweg gewährleisten.Zu den Anwendungsbeispielen zählen die Visualisierung von Raum-Zeit-Bereichen wie Schwarzen Löchern, die Erfassung physikalischer Teilchenkollisionen, die Verbesserung der Auflösung von Bildern lebender Zellen und die bessere Erkennung von Zelltypen in unterschiedlichen biologischen Umgebungen.
02 Erlernen aussagekräftiger Darstellungen wissenschaftlicher Daten
Deep Learning kann aussagekräftige Darstellungen wissenschaftlicher Daten auf verschiedenen Abstraktionsebenen extrahieren und optimieren. Eine qualitativ hochwertige Darstellung sollte möglichst viele Informationen über die Daten bewahren und gleichzeitig prägnant und zugänglich bleiben. Hier sind 3 neue Strategien, die diese Anforderungen erfüllen:Geometrische Vorhersagen, selbstüberwachtes Lernen und Sprachmodellierung.
Geometrische Vorhersagen
Geometrie und Struktur sind für die wissenschaftliche Forschung von entscheidender Bedeutung. Symmetrie ist ein wichtiges Konzept in der Geometrie und wichtige strukturelle Eigenschaften sind in räumlichen Richtungen stabil und ändern sich nicht. Die Integration geometrischer Vorannahmen in erlernte Darstellungen hat sich in der wissenschaftlichen Bildanalyse als effektiv erwiesen.
Geometrisches Deep Learning
Graph-Neuralnetze haben sich zum führenden Ansatz für Deep Learning auf Datensätzen mit zugrunde liegenden geometrischen und relationalen Strukturen entwickelt. Abhängig von den wissenschaftlichen Fragestellungen haben Forscher verschiedene grafische Darstellungen entwickelt, um komplexe Systeme zu erfassen.
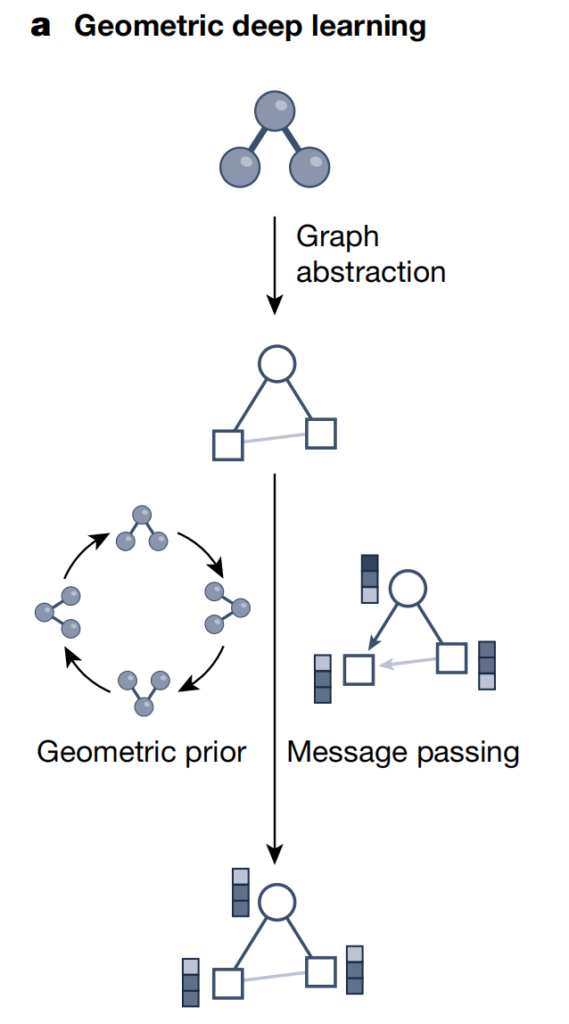
Wie in der Abbildung oben gezeigt, verwendet geometrisches Deep Learning Graphstrukturen und Strategien zur neuronalen Informationsübertragung, um die Geometrie-, Struktur- und Symmetrieinformationen wissenschaftlicher Daten wie Moleküle/Materialien zu integrieren. Bei diesem Ansatz werden neuronale Informationen entlang der Kanten in der Graphstruktur ausgetauscht, um latente Darstellungen (Einbettungsvektoren) zu generieren und dabei andere geometrische Vorbedingungen (wie Invarianz und arithmetische Progressionsbeschränkungen) zu berücksichtigen. daher,Geometrisches Deep Learning kann komplexe Strukturinformationen in Deep-Learning-Modelle integrieren und so die zugrunde liegenden geometrischen Datensätze besser verstehen und verarbeiten.
Selbstüberwachtes Lernen
Durch selbstüberwachtes Lernen kann das Modell die allgemeinen Merkmale des Datensatzes verstehen, ohne auf explizite Beschriftungen angewiesen zu sein. Es kann als wichtiger Vorverarbeitungsschritt dienen, um übertragbare Merkmale aus großen, unbeschrifteten Daten zu lernen, bevor das Modell für die Durchführung nachgelagerter Aufgaben optimiert wird. Ein solches vortrainiertes Modell mit umfassendem wissenschaftlichen Fachwissen ist ein Allzweck-Prädiktor.Es lässt sich an vielfältige Aufgaben anpassen, verbessert dadurch die Effizienz und übertrifft rein überwachte Methoden.
Wie in der Abbildung oben gezeigt, ist es für die effektive Darstellung unterschiedlicher Proben, beispielsweise Satellitenbilder, erforderlich, sowohl ihre Ähnlichkeiten als auch ihre Unterschiede zu erfassen. Selbstüberwachte Lernstrategien wie kontrastives Lernen können dieses Ziel erreichen, indem sie erweiterte Peer-Daten generieren, positive Daten ausrichten und negative Datenpaare trennen. Dieser iterative Prozess verbessert die Einbettungen, was zu informativen latenten Darstellungen und einer besseren Leistung bei nachgelagerten Vorhersageaufgaben führt.
Sprachmodellierung
Maskierte Sprachmodellierung ist eine beliebte Methode zum selbstüberwachten Lernen natürlicher Sprache und biologischer Sequenzen (siehe Abbildung unten).

Natürliche Sprachverarbeitung und biologische Sequenzverarbeitung beeinflussen sich gegenseitig.Während des Trainings besteht das Ziel darin, das nächste Token in der Sequenz vorherzusagen, während beim maskenbasierten Training die selbstüberwachte Aufgabe darin besteht, die maskierten Token in der Sequenz mithilfe des bidirektionalen Sequenzkontexts wiederherzustellen. Proteinsprachmodelle können Aminosäuresequenzen kodieren, strukturelle und funktionelle Eigenschaften erfassen und die evolutionäre Fitness viraler Varianten bewerten. Beim Umgang mit biochemischen Sequenzen können chemische Sprachmodelle den riesigen chemischen Raum effektiv erkunden.
Wie in der obigen Abbildung gezeigt, kann die maskierte Sprachmodellierung die Semantik von Sequenzdaten, wie beispielsweise natürlicher Sprache und biologischen Sequenzen, effektiv erfassen. Bei diesem Ansatz werden die maskierten Elemente in der Eingabe in ein Transformer-Modul eingespeist, das Vorverarbeitungsschritte wie die Positionskodierung umfasst. Die graue Linie stellt den Selbstaufmerksamkeitsmechanismus dar und die Farbtiefe spiegelt die Größe des Aufmerksamkeitsgewichts wider. Es kombiniert die Darstellung der nicht maskierten Eingabe, um die maskierte Eingabe genau vorherzusagen. Die Methode erzeugt qualitativ hochwertige Sequenzdarstellungen, indem dieser Autovervollständigungsprozess für viele Elemente der Eingabe wiederholt wird.
Transformatorarchitektur
Transformer vereint Graph-Neuralnetzwerke und Sprachmodelle, dominiert die Verarbeitung natürlicher Sprache und wird erfolgreich in Bereichen wie der Erkennung seismischer Signale, der Modellierung von DNA- und Proteinsequenzen, der Modellierung der Auswirkungen von Sequenzvariationen auf biologische Funktionen und der symbolischen Regression eingesetzt.
Neuronale Operatoren
Durch das Erlernen einer Abbildung zwischen Funktionsräumen ist der neuronale Operator diskretisierungsinvariant, kann mit jeder beliebigen Eingabediskretisierung arbeiten und konvergiert gegen einen Grenzwert, wenn das Gitter verfeinert wird. Sobald ein neuronaler Operator trainiert ist, kann er ohne erneutes Training mit jeder Auflösung ausgewertet werden.
03 Generieren Sie KI-basierte wissenschaftliche Hypothesen
KI kann Hypothesen generieren, indem sie aus verrauschten Beobachtungen mögliche symbolische Ausdrücke identifiziert. Sie können beim Entwerfen von Objekten helfen, Bayes'sche Posterior-Wahrscheinlichkeiten von Hypothesen erlernen und diese verwenden, um Hypothesen zu generieren, die mit wissenschaftlichen Daten und Erkenntnissen kompatibel sind.
Black-Box-Prädiktor wissenschaftlicher Hypothesen
Schwach überwachtes Lernen kann zum Trainieren von Modellen verwendet werden, bei denen eine verrauschte, begrenzte oder ungenaue Überwachung als Trainingssignal verwendet wird.
KI-Methoden wurden mit hochpräzisen Simulationen trainiert und zum effektiven Screening großer Molekülbibliotheken eingesetzt. In der Genomik wird die Transformer-Architektur trainiert, um Genexpressionswerte anhand von DNA-Sequenzen vorherzusagen und so Genmutationen zu identifizieren. Bei der Proteinfaltung kann AlphaFold2 die 3D-Atomkoordinaten von Proteinen anhand von Aminosäuresequenzen vorhersagen. In der Teilchenphysik erfordert die Identifizierung der in Protonen enthaltenen Charm-Quarks das Screening aller möglichen Strukturen und die Anpassung experimenteller Daten an alle potenziellen Strukturen.
Neben Vorwärtsproblemen wird KI zunehmend auch zur Lösung inverser Probleme eingesetzt.
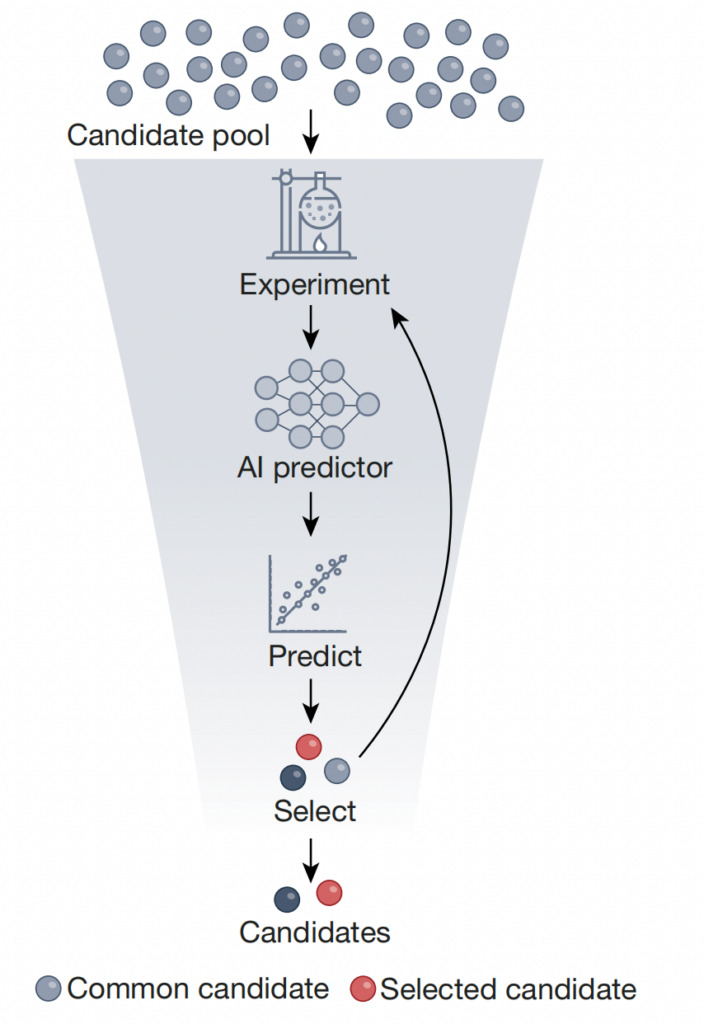
Wie in der Abbildung oben dargestellt, bezieht sich Hochdurchsatz-Screening auf die Verwendung von KI-Prädiktoren, die anhand experimentell generierter Datensätze trainiert wurden, um eine kleine Anzahl von Zielobjekten mit idealen Eigenschaften herauszufiltern.Dadurch wird die Gesamtgröße der Kandidatenbibliothek um mehrere Größenordnungen reduziert.Bei diesem Ansatz kann selbstüberwachtes Lernen verwendet werden, um den Prädiktor anhand einer großen Anzahl ungeprüfter Objekte vorab zu trainieren und ihn dann anhand eines Datensatzes geprüfter Objekte mit beschrifteten Messwerten zu optimieren. Dieser Ansatz kann durch Laborauswertungen und Unsicherheitsquantifizierungen ergänzt werden. Dadurch wird der Screening-Prozess rationalisiert, kostengünstiger und zeitsparender und die Identifizierung von Kandidatenverbindungen, Materialien und Biomolekülen wird letztendlich beschleunigt.
Erkundung kombinatorischer Hypothesenräume
Im Vergleich zu herkömmlichen Methoden, die auf manuell erstellten Regeln basieren, können KI-Strategien verwendet werden, um die Belohnung jeder Suche zu bewerten und Suchrichtungen mit höherem Wert zu identifizieren.
Für Optimierungsprobleme können evolutionäre Algorithmen verwendet werden, um symbolische Regressionsaufgaben zu lösen. Die kombinatorische Optimierung ist auch auf Aufgaben wie die Entdeckung von Molekülen mit wünschenswerten Arzneimitteleigenschaften anwendbar, bei denen jeder Schritt im Moleküldesign ein diskreter Entscheidungsprozess ist. Darüber hinaus wurden Methoden des bestärkenden Lernens erfolgreich auf verschiedene Optimierungsprobleme angewendet, beispielsweise auf die Maximierung der Proteinexpression, die Planung von Wasserkraft in der Amazonasebene und die Erforschung des Parameterraums von Teilchenbeschleunigern.
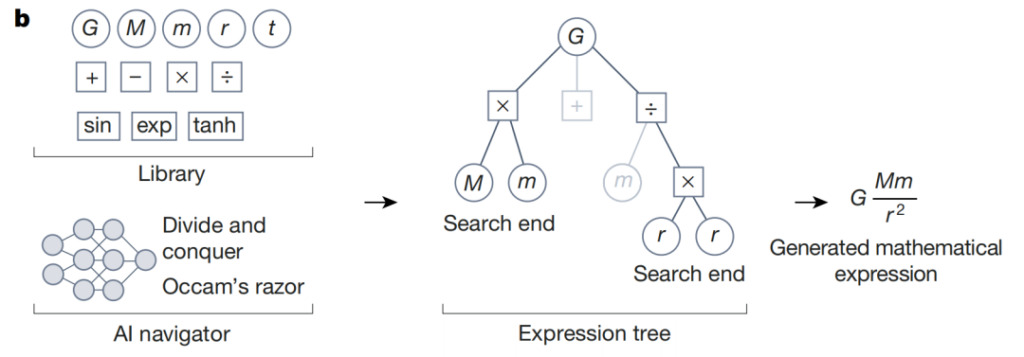
Wie in der obigen Abbildung gezeigt, nutzt der KI-Navigator während der symbolischen Regression die vom Reinforcement-Learning-Agenten vorhergesagten Belohnungen und Designkriterien wie Ockhams Rasiermesser, um sich auf die vielversprechendsten Elemente der Kandidatenhypothesen zu konzentrieren. Das folgende Beispiel veranschaulicht den Denkprozess für den mathematischen Ausdruck des Newtonschen Gravitationsgesetzes. Suchpfade mit niedriger Punktzahl werden im symbolischen Ausdrucksbaum als graue Zweige angezeigt. Geleitet von der Aktion, die mit der höchsten vorhergesagten Belohnung verbunden ist,Dieser iterative Prozess konvergiert zu einem mathematischen Ausdruck, der mit den Daten übereinstimmt und die anderen Entwurfskriterien erfüllt.
Optimierung differenzierbarer Hypothesenräume
Differenzierbare Räume eignen sich für gradientenbasierte Methoden, mit denen sich effektiv lokale Optimallösungen finden lassen.Um eine gradientenbasierte Optimierung zu ermöglichen, werden üblicherweise zwei Ansätze verwendet:
* Verwenden Sie Modelle wie VAEs, um diskrete Kandidatenhypothesen in einen latenten differenzierbaren Raum abzubilden;
* Lockern Sie die diskrete Annahme in ein differenzierbares Objekt, das in einem differenzierbaren Raum optimiert werden kann (diese Lockerung kann verschiedene Formen annehmen, z. B. das Ersetzen diskreter Variablen durch kontinuierliche Variablen oder die Verwendung einer weichen Version der ursprünglichen Einschränkungen).
In der Astrophysik wurden VAEs verwendet, um Parameter von Gravitationswellendetektoren auf der Grundlage vorab trainierter Wellenformmodelle Schwarzer Löcher zu schätzen. Diese Methode ist sechs Größenordnungen schneller als herkömmliche Methoden. In der Materialwissenschaft werden thermodynamische Regeln mit Autoencodern kombiniert, um einen interpretierbaren latenten Raum zur Identifizierung von Kristallstrukturkarten zu entwerfen.
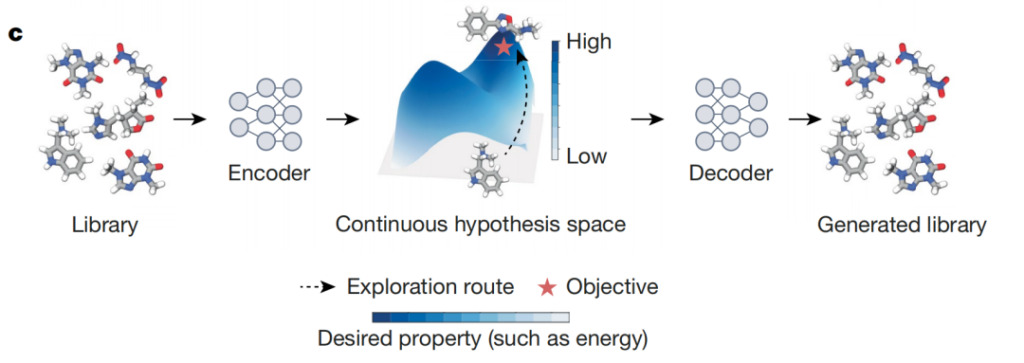
Wie in der obigen Abbildung gezeigt, handelt es sich bei KI-Differenzierern um ein Autoencoder-Modell, das diskrete Objekte (wie etwa Verbindungen) auf Punkte in einem differenzierbaren kontinuierlichen latenten Raum abbildet. Dieser Raum ermöglicht die Optimierung von Zielen, beispielsweise die Auswahl von Verbindungen aus großen chemischen Bibliotheken, die bestimmte biochemische Endpunkte maximieren. Der ideale Entwurf stellt den erlernten latenten Raum dar, wobei dunklere Farben Bereiche anzeigen, in denen Objekte mit höheren Vorhersagewerten konzentriert sind. Mithilfe dieses latenten Raums kann der KI-Differenzierer effizient Objekte identifizieren, die die erwarteten Eigenschaften der roten Sternanmerkungen maximieren.
04 KI-gesteuerte Experimente und Simulationen
Computersimulationen können kostspielige Laborexperimente ersetzen und effizientere und flexiblere Testmöglichkeiten bieten.Deep Learning kann Hypothesen identifizieren und verfeinern, um sie effizient zu testen, und ermöglicht Computersimulationen, um Beobachtungen mit Hypothesen zu verknüpfen.
Wissenschaftliche Hypothesen effizient bewerten
KI-Systeme bieten experimentelle Design- und Optimierungstools.Diese Tools können traditionelle wissenschaftliche Methoden ergänzen, die Anzahl der erforderlichen Experimente reduzieren und Ressourcen sparen.
Insbesondere können KI-Systeme bei zwei wichtigen Schritten experimenteller Tests unterstützen: Planung und Anleitung. KI-Planung bietet einen systematischen Ansatz zum Entwerfen von Experimenten, zur Optimierung der Effizienz und zur Erkundung unbekannter Bereiche. Gleichzeitig lenkt die KI-Steuerung den Versuchsprozess in Richtung ertragreicher Hypothesen, sodass das System aus früheren Beobachtungen lernen und den Versuchsprozess anpassen kann. Diese KI-Ansätze können modellbasiert (unter Verwendung von Simulationen und Vorwissen) oder modellfrei sein und ausschließlich auf Algorithmen des maschinellen Lernens basieren.
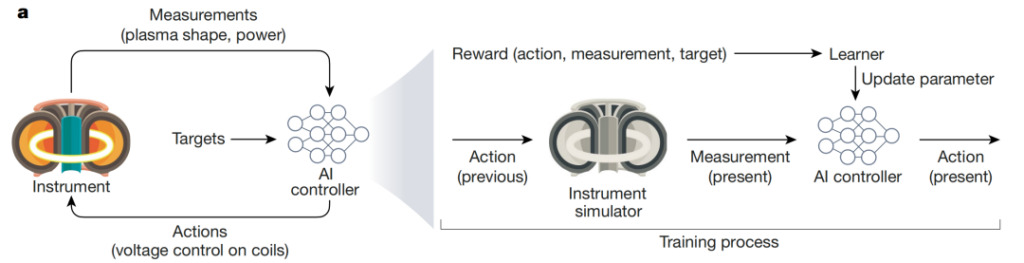
Das obige Bild zeigt den Einsatz von KI zur Steuerung des komplexen und dynamischen Kernfusionsprozesses: Degrave et al. einen KI-Controller entwickelt, der die Kernfusion über das Magnetfeld im Tokamak-Reaktor regulieren kann. Der KI-Agent empfängt Echtzeitmessungen der elektrischen Spannungspegel und der Plasmakonfiguration und ergreift Maßnahmen zur Steuerung des Magnetfelds, um experimentelle Ziele zu erreichen (wie etwa die Aufrechterhaltung einer normalen Stromversorgung). Der Controller wird durch Simulation trainiert und aktualisiert die Modellparameter mithilfe der Belohnungsfunktion.
Ableitung von Observablen aus Hypothesen mithilfe von Simulationen
Die bestehende Computersimulationstechnologie basiert in hohem Maße auf dem menschlichen Verständnis und der Erkenntnis der zugrunde liegenden Mechanismen des Systems. KI-Systeme können die Computersimulation verbessern, indem sie sich genauer und effizienter an die Schlüsselparameter komplexer Systeme anpassen, Differentialgleichungen lösen, mit denen komplexe Systeme gesteuert werden können, und die Zustände komplexer Systeme modellieren.
Nehmen wir als Beispiel molekulare Kraftfelder. Obwohl sie interpretierbar sind, sind sie in der Darstellung verschiedener Funktionen begrenzt und ihr Generierungsprozess erfordert starke induktive Voreingenommenheit und eine Fülle wissenschaftlicher Erkenntnisse. Um die Genauigkeit molekularer Simulationen zu verbessern, wurde ein KI-basiertes neuronales Potenzial entwickelt, das sich an teure und präzise quantenmechanische Daten anpasst und herkömmliche Kraftfelder ersetzen soll.
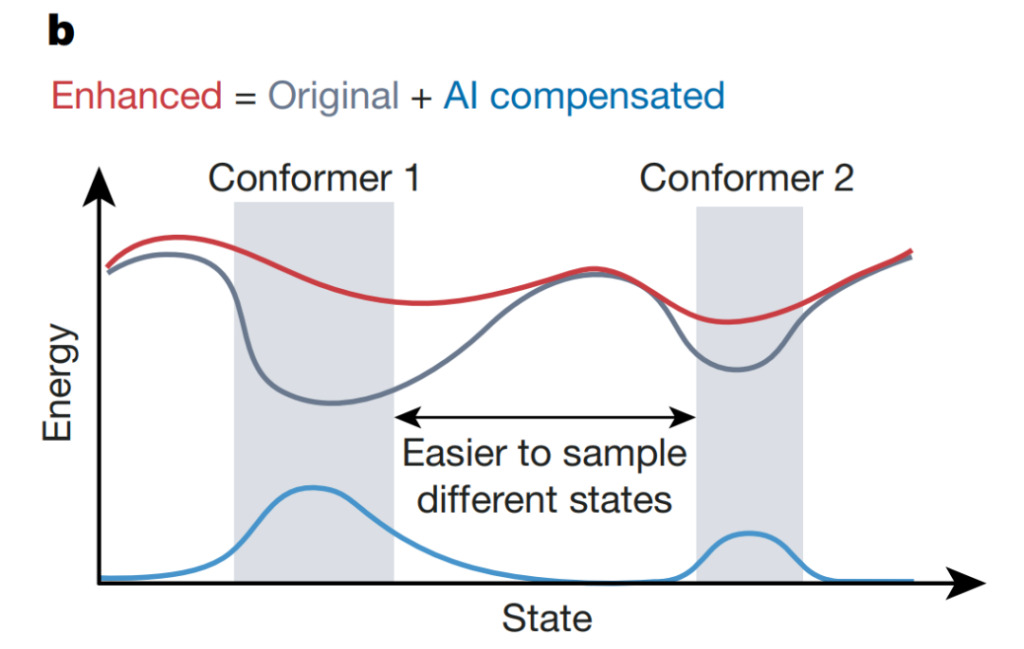
Bei computergestützten Simulationen komplexer Systeme können KI-Systeme die Erkennung ungewöhnlicher Ereignisse, wie etwa Übergänge zwischen Proteinkonformationsstrukturen, beschleunigen. Wie in der Abbildung oben gezeigt, haben Wang et al. verwendete einen auf neuronalen Netzwerken basierenden Unsicherheitsschätzer, um die Erhöhung der potenziellen Energie zu steuern, die die ursprüngliche potenzielle Energie kompensiert, wodurch das System dem lokalen Minimum (grau) entkommen und den Konfigurationsraum schneller erkunden kann. Dieser Ansatz könnte die Effizienz und Genauigkeit von Simulationen verbessern und zu einem tieferen Verständnis komplexer biologischer Phänomene führen.
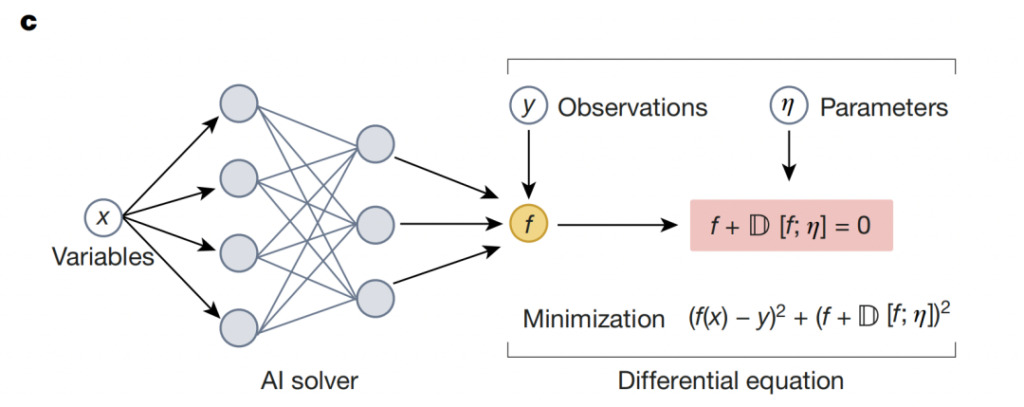
Neuronale Löser kombinieren Physik mit der Flexibilität von Deep Learning:Aufbau neuronaler Netzwerke basierend auf Domänenwissen
05 KI für die Wissenschaft: Noch ein langer Weg
KI-Systeme tragen zum wissenschaftlichen Verständnis bei und haben sich als in der Lage erwiesen, Prozesse und Objekte zu untersuchen, die schwer zu visualisieren oder zu erkennen sind. Außerdem können sie systematisch neue Ideen generieren, indem sie Modelle aus Daten erstellen und Daten mit Simulationen und skalierbarem Computing kombinieren. Um jedoch die Sicherheit und den Datenschutz der KI zu gewährleisten,Dieser Prozess erfordert noch immer den Einsatz ausgereifter Technologien.
Um KI in der wissenschaftlichen Forschung verantwortungsvoll einzusetzen, müssen Forscher die Unsicherheits-, Fehler- und Nutzengrade von KI-Systemen messen. Mit der Weiterentwicklung von KI-Systemen dürfte KI Türen zu wissenschaftlichen Entdeckungen öffnen, die bisher unerreichbar lagen. Allerdings ist es noch ein weiter Weg, bis die unterstützenden Theorien, Methoden sowie die Software- und Hardware-Infrastruktur verfügbar sind.
Quellen:








