Command Palette
Search for a command to run...
Neue Interpretation Des Millennium-Codes: DeepMind Entwickelt Ithaca Zur Entzifferung Griechischer Inschriften

Inschriften und Stelen spiegeln das Denken, die Kultur und die Sprache vergangener Zivilisationen wider. Um die Codes von vor Tausenden von Jahren zu entziffern, müssen Epigraphiker drei wichtige Aufgaben erfüllen: Textrestaurierung, zeitliche Zuordnung und regionale Zuordnung.
Die gängige Forschungsmethode ist das „String Matching“, bei dem Inschriften mit ähnlichen Schriftarten mithilfe des Gedächtnisses oder einer Abfrage des Korpus abgeglichen werden, was zu Verwirrung und Fehleinschätzungen der Ergebnisse führt.
Zu diesem Zweck haben DeepMind und die Universität Venedig Foscari gemeinsam Ithaca entwickelt, das mithilfe künstlicher Intelligenz menschlichen Wissenschaftlern beim Entziffern griechischer Inschriften hilft.
Autor | Null hinzufügen
Herausgeber | Xuecai, Provinz Sanyang
Die Epigraphik, die Lehre epigraphischer Inschriften, Stelen und antiker Inschriften, verbindet Gedanken, Kultur und Sprache vergangener Zivilisationen. Derzeit steht die wissenschaftliche Gemeinschaft vor einer wichtigen Frage: Wie können diese Kulturdenkmäler gründlich erforscht und verstanden werden?
Im Allgemeinen erfordert die Interpretation von Inschriften von Epigraphikern die Erfüllung der folgenden drei grundlegenden Aufgaben:
- Textrestauration: Ergänzung fehlender Textteile;
- Chronologische Zuordnung: Bestimmung des Zeitpunkts der Entstehung einer Inschrift;
- Geografische Zuordnung: Bestimmen Sie den ursprünglichen Ort, an dem die Inschrift geschrieben wurde.
Um diese Aufgaben zu erfüllen, müssen Epigraphiker umfangreiche Vergleichsstudien durchführen, bei denen sie den Kontext mit vorhandenen Korpora kombinieren. Obwohl die Entstehung digitaler Korpora die Belastung der Forscher bis zu einem gewissen Grad verringern kann, führt die von ihnen angewandte Methode des String-Abgleichs häufig zu Verwirrung und Fehleinschätzung der Ergebnisse. Gleichzeitig wurden viele Inschriften aufgrund ihres Alters beschädigt oder verloren, was die Aufgabe noch komplizierter macht.

Symbol für die Reparatur der Beschriftung
KI ist gut darin, komplexe statistische Muster zu erkennen und anzuwenden, um große Datenmengen zu analysieren, die für Menschen schwer zu verarbeiten sind.. Aus diesem Grund haben Forscher von DeepMind und der Universität Ca' Foscari in Venedig gemeinsam Ithaca entwickelt, das Epigraphiker bei der Textrestaurierung sowie der chronologischen und geografischen Zuordnung unterstützen soll.
Experimente haben bestätigt, dass die Genauigkeit der Textrestaurierung von Ithaca 62% erreichte, der Zeitzuordnungsfehler innerhalb von 30 Jahren lag, die regionale Zuordnungsgenauigkeit 71% erreichte und eine gute Synergie aufwies. Die zugehörige Arbeit wurde in „Nature“ veröffentlicht.

Ähnliche Ergebnisse wurden in Nature veröffentlicht
Holen Sie sich das Papier:
https://www.nature.com/articles/s41586-022-04448-z
Der relevante Code von Ithaca wurde auf der GitHub-Plattform als Open Source bereitgestellt und Epigraphiker können für ihre Recherche auch die öffentliche Schnittstelle nutzen.
Quellcode: https://GitHub.com/deepmind/Ithaca
Öffentliche Schnittstelle: https://Ithaca.deepmind.com
Experimentelle Verfahren
Datensatz
Maschinenbedienbare Inschriftensammlung I.PHI
Die Forscher führten ihre Untersuchung auf der Grundlage des durchsuchbaren öffentlichen Datensatzes griechischer Inschriften (PHI) des Packard Humanities Institute durch.
Hinweis: PHI steht für den öffentlichen Datensatz „Searchable Greek Inscriptions“ des Packard Humanities Institute.
Um die Maschinenbedienung zu erleichtern, filterten die Forscher den Text in PHI, wiesen den ausgewählten Texten digitale IDs, entsprechende annotierte Standorte und Zeitinformationen zu und erhielten schließlich den I.PHI-Datensatz.
Der I.PHI-Datensatz ist derzeit der größte maschinenlesbare Inschriftendatensatz und enthält 78.608 Inschriften.

I. Beispiel für einen PHI-Datensatz
Algorithmus-Training:Training für 3 Hauptaufgaben
1. Textwiederherstellung: Verwenden Sie die Kreuzentropieverlustfunktion, um einen Teil des Eingabetextes zu maskieren und das Ithaca-Modell zu trainieren, um die maskierten Zeichen vorherzusagen.
2. Zeitliche Zuordnung: Ithaka diskretisierte die Zeit um 800 v. Chr. mit 10-Jahres-Intervallen in Zeiträume mit gleicher Wahrscheinlichkeit, was als Zielwahrscheinlichkeitsverteilung bezeichnet wird. Die Kullback-Leibler-Divergenz wird verwendet, um den Unterschied zwischen der vorhergesagten Wahrscheinlichkeitsverteilung und der Zielwahrscheinlichkeitsverteilung zu minimieren.
3. Regionale Zuordnung: Mithilfe der Cross-Entropy-Loss-Funktion werden die regionalen Metadaten als Zielbezeichnung verwendet und die Bezeichnungsglättungstechnik mit einem Glättungskoeffizienten von 10% angewendet, um eine Überanpassung zu vermeiden.
Darauf aufbauend wurde Ithaca eine Woche lang auf 128 TPU v4 Pods auf der Google Cloud Platform mit einer Batchgröße von 8.192 Texten und einem LAMB-Optimierer mit einem 3 × 10 trainiert.-4 Die Lernrate optimiert die Ithaca-Parameter.
Modellstruktur:Das Ithaca-Modell besteht aus 4 Teilen:
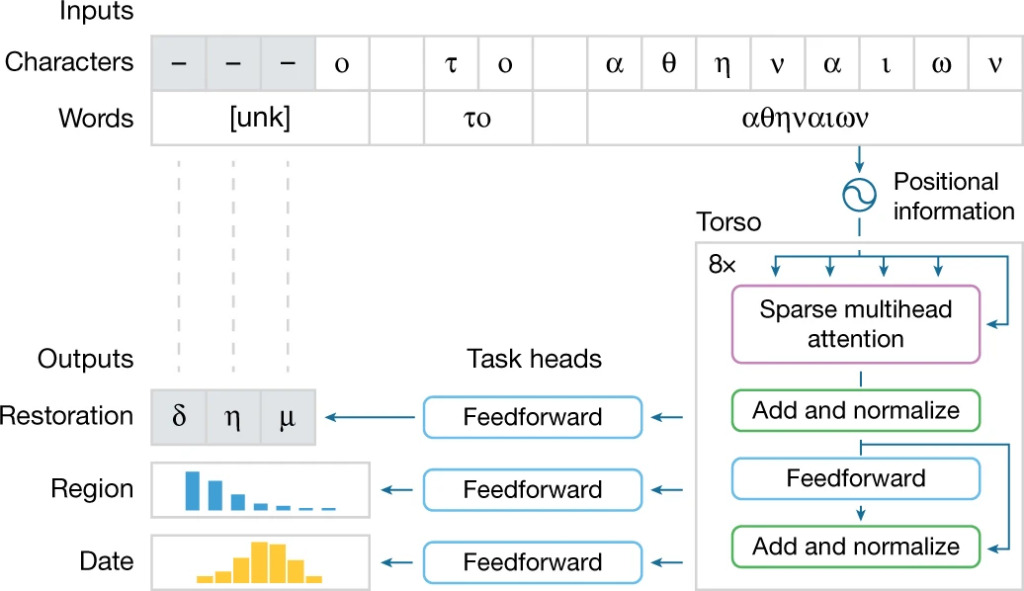
Ablauf der Aufgabenverarbeitung im Ithaca-Modell
Die Struktur des Ithaca-Modells lässt sich in die folgenden vier Teile zusammenfassen:
1. Eingaben: Der Eingabetext wird sowohl als Zeichen als auch als Wörter verarbeitet, um sicherzustellen, dass Ithaca einzelne Zeichen verstehen und sie zum kontextuellen Verständnis in Wörter integrieren kann. Unbekannte und beschädigte Wörter werden durch das Sonderzeichen „unk“ ersetzt.
2. Torso: Der Torso von Ithaca verwendet eine gestapelte Transformer-Neuralnetzwerkarchitektur, die einen Aufmerksamkeitsmechanismus verwendet, um die Auswirkungen der eingegebenen Zeichen und Wörter auf den Entscheidungsprozess des Modells zu messen.
Im Hauptteil kombiniert Ithaca den Eingabetext mit den Positionsinformationen und normalisiert ihn in eine Sequenz, deren Länge der Anzahl der Eingabezeichen entspricht, wobei jedes Element in der Sequenz ein 2.048-dimensionaler Einbettungsvektor ist. Diese Sequenz wird an 3 verschiedene Taskköpfe übertragen;
3. Aufgabenköpfe: Ithaca hat 3 verschiedene Aufgabenköpfe, jeder Kopf besteht aus einem flachen Feedforward-Neuralnetzwerk, das auf Aufgaben zur Textwiederherstellung, zeitlichen Zuordnung und regionalen Zuordnung spezialisiert ist.
4. Ausgaben: Die drei Aufgabenköpfe geben jeweils entsprechende Ergebnisse aus.
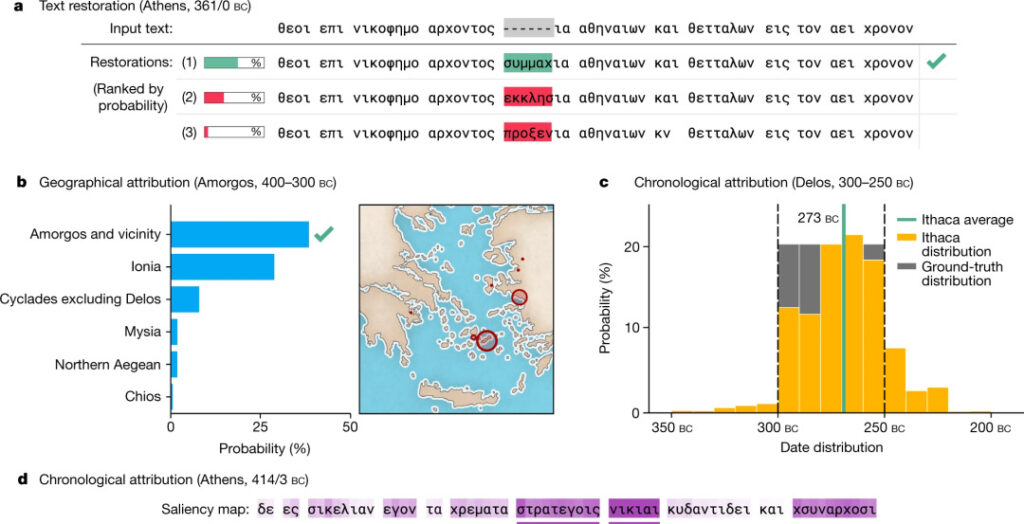
Ithaca-Ausgabe
- Textreparatur: Ithaca sagt 3 fehlende Zeichen voraus und bietet eine Reihe der 20 besten Dekodierungsvorhersagen, sortiert nach Wahrscheinlichkeit (a oben);
- Regionale Zuordnung: Ithaca unterteilt den Eingabetext in 84 Regionen und verwendet Karten und Balkendiagramme, um intuitiv eine mögliche Rangliste für regionale Vorhersagen zu implementieren (Abbildung b oben).
- Zeitzuordnung: Um die Interpretierbarkeit von Zeitzuordnungsaufgaben zu erweitern, wird Ithaca auf die Jahre 800 v. Chr. bis 800 n. Chr. datiert und prognostiziert eine kategorische Verteilung von Daten, anstatt einen einzelnen Datumswert auszugeben (Abbildung 2c oben).
Ergebnisse des Modelltrainings
Umfassender Vergleich:Ithaca hat eine überlegene Leistung
* 4 Kontrastmechanismen
1. Althistoriker: Anthropologen verwenden das Trainingsset, um Ähnlichkeiten in den Texten zu finden und die Ergebnisse mit Ithaka zu vergleichen;
2. Althistoriker und Ithaka: Ithaka bietet Epigraphikern 20 mögliche Restaurierungen und bewertet die Synergie zwischen Ithaka und Anthropologen;
3. Pythia: ein Sequenz-zu-Sequenz-rekurrentes neuronales Netzwerk für Text-Inpainting-Aufgaben, das die Text-Inpainting-Leistung von Ithaca bewertet;
4. Onomastik: Die Forscher nutzten die bekannte zeitliche und räumliche Verteilung griechischer Personennamen, um die zeitliche und regionale Zuordnung einer Reihe von Texten abzuschließen und die zeitliche und regionale Zuordnungsleistung von Ithaka zu bewerten.
* 3 wichtige Bewertungsindikatoren
1. Zeichenfehlerrate (CER): wertet Textreparaturaufgaben aus und berechnet die normalisierte Differenz zwischen der höchsten vorhergesagten Reparatursequenz und der Zielsequenz;
2. Top-k-Genauigkeit: Bewertet Textwiederherstellungs- oder regionale Zuordnungsaufgaben und berechnet den Anteil der Top-k-Ergebnisse mit der höchsten Wahrscheinlichkeit in den Vorhersageergebnissen, die korrekte Beschriftungen enthalten. Die höchste Genauigkeit 1 wird häufig verwendet.
3. Distanzmetrik (Methoden): wertet die zeitliche Zuordnungsaufgabe aus und berechnet die Distanz in Jahren zwischen dem Mittelwert der vorhergesagten Verteilung und dem Ground-Truth-Intervall.
* Experimentelle Ergebnisse
1. Textreparatur

Textreparaturaufgaben
a: Originalinschrift;
b: Restaurierte Inschrift von Rhodes-Osborne;
c: Pythia-Restauration, die 74 Nichtübereinstimmungen mit der Rhodes-Osborne-Version aufweist;
d: Ithaca-Restaurierung, die 45 Abweichungen von der Rhodes-Osborne-Version aufweist;
Die korrekt reparierten Teile sind in der Abbildung grün dargestellt, die Fehler sind rot hervorgehoben.
In der Originalinschrift (IG II² 116) fehlen 378 Zeichen. Basierend auf der von Rhodes-Osborne im Jahr 2003 abgeschlossenen Restaurierung (Abbildung b) beträgt Ithacas CER 26,3% und die Genauigkeit der Top 1 erreicht 61,8%.
Im Vergleich zu den Epigraphikern ist der CER von Ithaca 2,2-mal niedriger. Die Vorhersagegenauigkeit der Top 20 von Ithaca beträgt 78,3% und ist damit 1,5-mal höher als bei Pythia.
2. Geografische Zuordnung
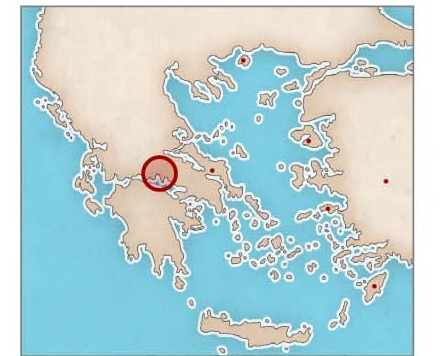
Geografische Zuordnungsaufgaben
Bei der Aufgabe zur Regionenzuordnung erreichte Ithaca eine Top-1-Genauigkeit von 70,81 TP3T und eine Top-3-Genauigkeit von 82,11 TP3T.Das obige Diagramm zeigt, dass Ithaka die Freilassungsinschrift korrekt der Region Delphi zuordnete.
3. Zeitzuordnung
Zeitzuordnungsaufgabe
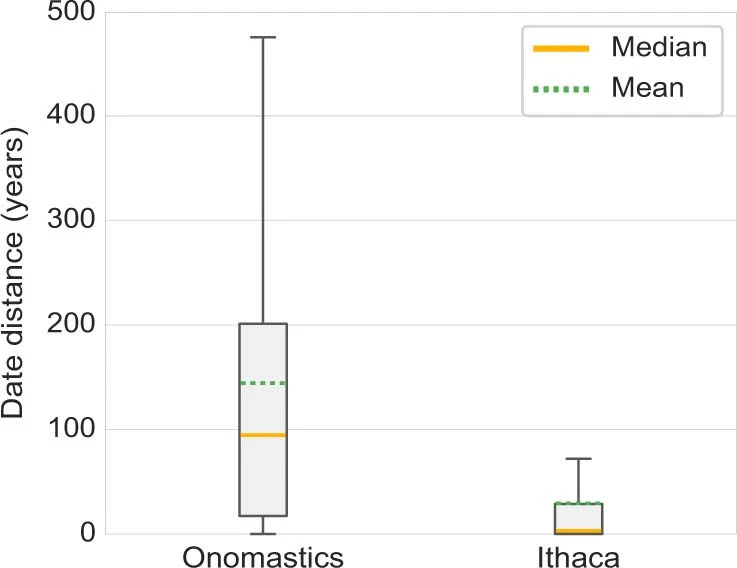
Bei der Zeitzuordnungsaufgabe betrug die durchschnittliche Vorhersage menschlicher Experten 144,4 Jahre und der Median 94,5 Jahre, während Ithacas Vorhersage eine durchschnittliche Abweichung von 29,3 Jahren vom Ground-Truth-Intervall und eine Mediandifferenz von nur 3 Jahren aufwies.
Kombiniert man Ithacas Leistung in den drei Aufgaben, lassen sich die Ergebnisse wie folgt zusammenfassen:
Im Vergleich zu menschlichen Experten und Pythia zeigt Ithaca bei allen drei Aufgaben eine überlegene Leistung.
Als menschliche Experten mit Ithaca zusammenarbeiteten, erreichten sie einen CER von 18,3% und eine Top-1-Genauigkeit von 71,7%., was eine 3,2-fache und 2,8-fache Verbesserung gegenüber den Epigraphikern zeigt, die allein arbeiteten, und eine signifikante Verbesserung gegenüber Ithaca, das die Aufgabe allein erledigte.Demonstration der überlegenen Synergie von Ithaca.
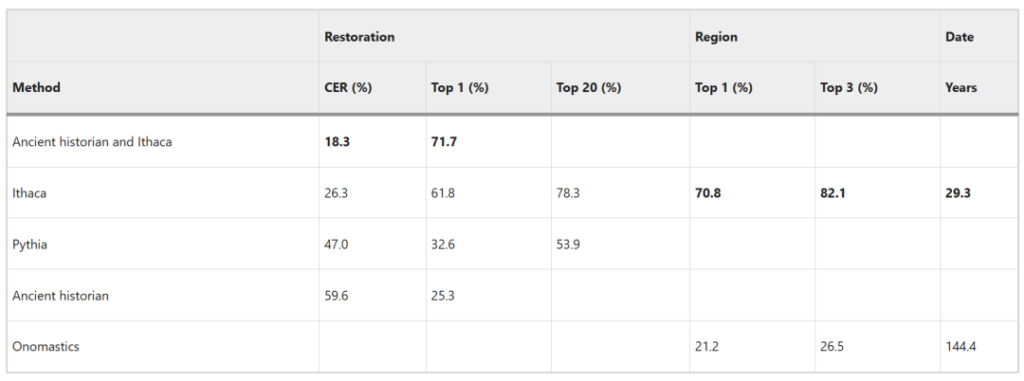
Vergleich der experimentellen Ergebnisse von Ithaca
Zeitzuordnung:ICHthaca Streitigkeiten lösen
Die Datierung einiger Inschriften war umstritten. Das traditionelle Sigma-Datierungskriterium, das zur Datierung verwendet wird, kann keine Genauigkeit garantieren, und Epigraphiker können nicht feststellen, ob diese Inschriften vor oder nach 446/445 v. Chr. angefertigt wurden.
Die unten gezeigte Inschrift wurde traditionell auf 446/445 v. Chr. datiert, wurde jedoch kürzlich auf 424/423 v. Chr. neu datiert.

Eine umstrittene Inschrift (teilweise)
Dieser umstrittene Satz von Inschriften ist im I.PHI-Datensatz vorhanden und die Ergebnisse der Zeitzuordnung von Ithaka widerlegen die traditionelle historische Interpretation auf Grundlage des Sigma-Datierungsstandard. Der Unterschied zu den neu entdeckten grundlegenden Fakten beträgt durchschnittlich 5 Jahre.
Dies beweist, dassIthaca kann Historikern dabei helfen, Datumsbereiche einzugrenzen und die Genauigkeit ihrer Zuordnung historischer Ereignisse zu erhöhen.
KI und Mensch: 1 + 1 > 2?
Der Ergebnisausgabeteil von Ithaca ist sehr interessant. Es wird keine einzelne Antwort ausgegeben, sondern den Forschern stehen mehrere mögliche Ergebnisse zur Auswahl.
Für andere KI-Entwickler und -Benutzer ist dies lehrreich. Anstatt sich auf KI-Ergebnisse zu verlassen, ist es besser, KI zu verwenden, um „den Weg zu erkunden“, einige falsche Antworten zu eliminieren und die Tiefe und Breite des unabhängigen Denkens zu erweitern.
Durch die Kombination der Rechenleistung der KI mit der Kreativität und dem tiefen Denken des Menschen hilft uns Ithaca dabei, ein neues Paradigma für die Zusammenarbeit mit KI zu entwickeln.
Wir erwarten, dass KI und menschliche Wissenschaftler in Zukunft zusammenarbeiten, um das Ziel „1+1 > 2“ zu erreichen.
Quellen:
https://www.nature.com/articles/s41586-022-04448-z
https://www.nature.com/articles/d41586-023-03212-1
-- über--








