Command Palette
Search for a command to run...
Sim Computing: DSA AI Compiler Build Basierend Auf TVM

Hallo zusammen, ich bin Dan Xiaoqiang von Shim Computing. Heute werde ich zusammen mit drei Kollegen mit Ihnen teilen, wie Sie NPU auf TVM unterstützen können.
Das wesentliche Problem, das der DSA-Compiler löst, besteht darin, dass auf der Hardware unterschiedliche Modelle bereitgestellt werden müssen. Dabei kommen Optimierungsmethoden auf verschiedenen abstrakten Ebenen zum Einsatz, damit das Modell den Chip so weit wie möglich ausfüllt, d. h. die Blasen komprimiert werden. Was die Planung betrifft, so ist das von Halide beschriebene Planungsdreieck der Kern des Problems.
Welches Hauptproblem löst der DSA-Compiler? Zuerst abstrahieren wir eine DSA-Architektur. Wie in der Abbildung gezeigt, sind Habana, Ascend und IPU allesamt Instanziierungen dieser abstrakten Architektur. Im Allgemeinen verfügt jeder Kern über Vektor-, Skalar- und Tensor-Recheneinheiten. Aus der Perspektive der Befehlsoperationen und der Datengranularität neigen viele DSAs dazu, relativ grobkörnige Befehle zu verwenden, wie etwa zwei- und dreidimensionale Vektor- und Tensorbefehle. Es gibt auch viele Hardwares, die feinkörnige Anweisungen verwenden, wie etwa eindimensionales SIMD und VLIW. Einige der Abhängigkeiten zwischen Anweisungen werden durch explizite Schnittstellen zur Softwaresteuerung offengelegt, während andere von der Hardware selbst gesteuert werden. Der Speicher ist ein mehrstufiger Speicher, meist ein Scratchpad-Speicher. Es gibt verschiedene Granularitäten und Dimensionen der Parallelität, wie etwa Stream-Parallelität, Cluster-Parallelität, Multi-Core-Parallelität und Pipeline-Parallelität zwischen verschiedenen Computerkomponenten.
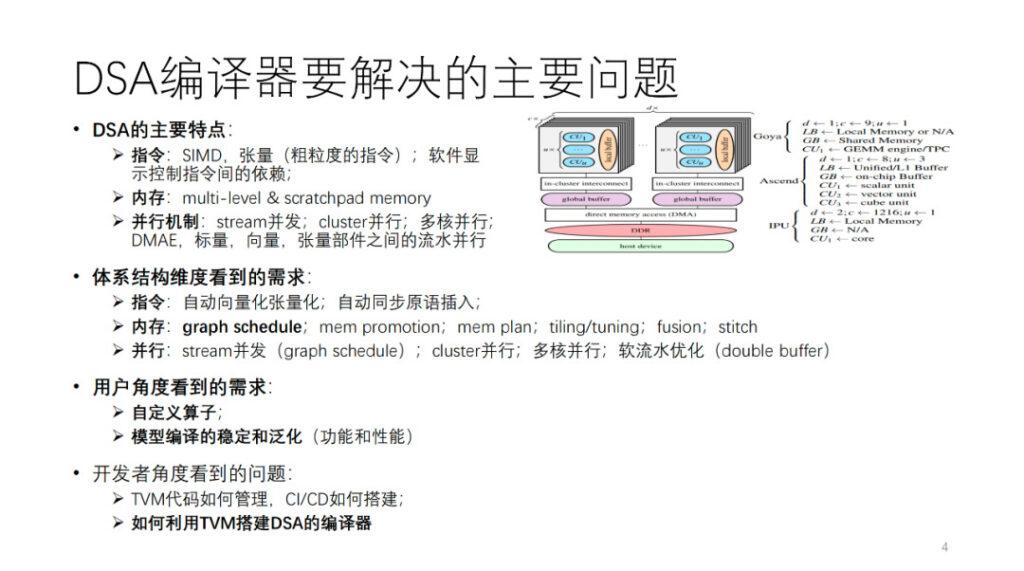
Um diese Art von Architektur zu unterstützen, werden aus Sicht der Compilerentwickler unterschiedliche Anforderungen an den KI-Compiler aus mehreren Aspekten der oben genannten Architektur gestellt. Wir werden diesen Teil später näher erläutern.
Aus Anwendersicht muss zunächst ein stabiler und verallgemeinerter Compiler vorhanden sein, der möglichst viele Modelle bzw. Operatoren erfolgreich kompilieren kann. Darüber hinaus hoffen die Benutzer, dass der Compiler eine programmierbare Schnittstelle zur Anpassung von Algorithmen und Operatoren bereitstellen kann, um sicherzustellen, dass einige wichtige Arbeiten zur Algorithmusinnovation unabhängig durchgeführt werden können. Schließlich könnten sich Teams wie unseres oder die unserer Konkurrenten auch Gedanken darüber machen, wie sie TVM zum Erstellen eines KI-Compilers verwenden können, beispielsweise wie sie selbst entwickelte und Open-Source-TVM-Codes verwalten, wie sie eine effiziente CI erstellen usw. Darüber werden wir heute sprechen. Mein Kollege wird jetzt über den Teil zur Kompilierungsoptimierung sprechen.
Wang Chengke von Shim Computing: DSA-Kompilierungsoptimierungsprozess
Dieser Teil wird vor Ort von Wang Chengke, einem Computeringenieur bei Shim, geteilt.
Lassen Sie mich zunächst den Gesamtprozess der Kompilierungspraxis von Shim vorstellen.
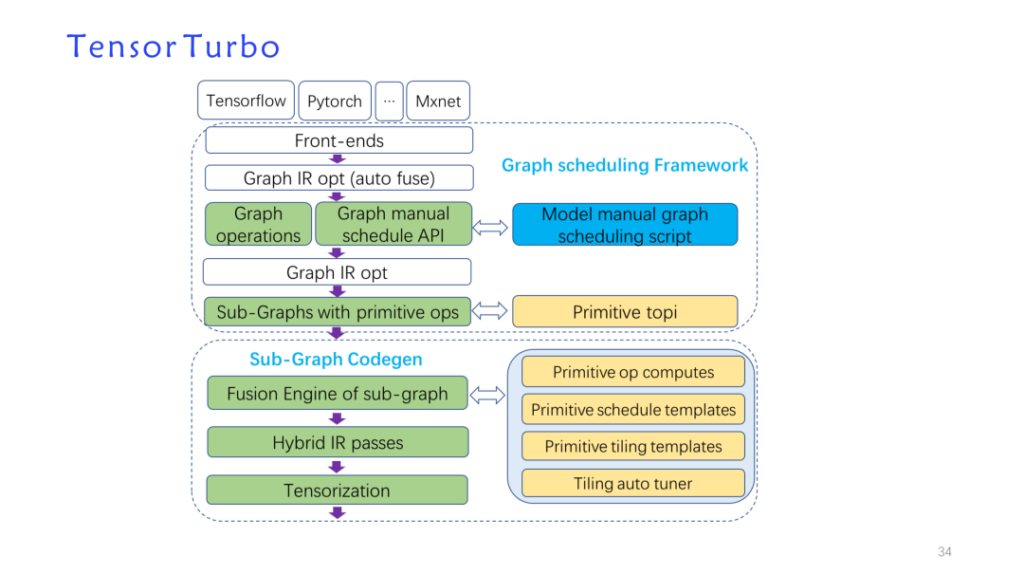
Als Reaktion auf die oben genannten Architekturmerkmale haben wir einen selbst entwickelten Optimierungsdurchlauf basierend auf der TVM-Datenstruktur erstellt und TVM wiederverwendet, um eine neue Modellimplementierung zu erstellen: Tensorturbo.
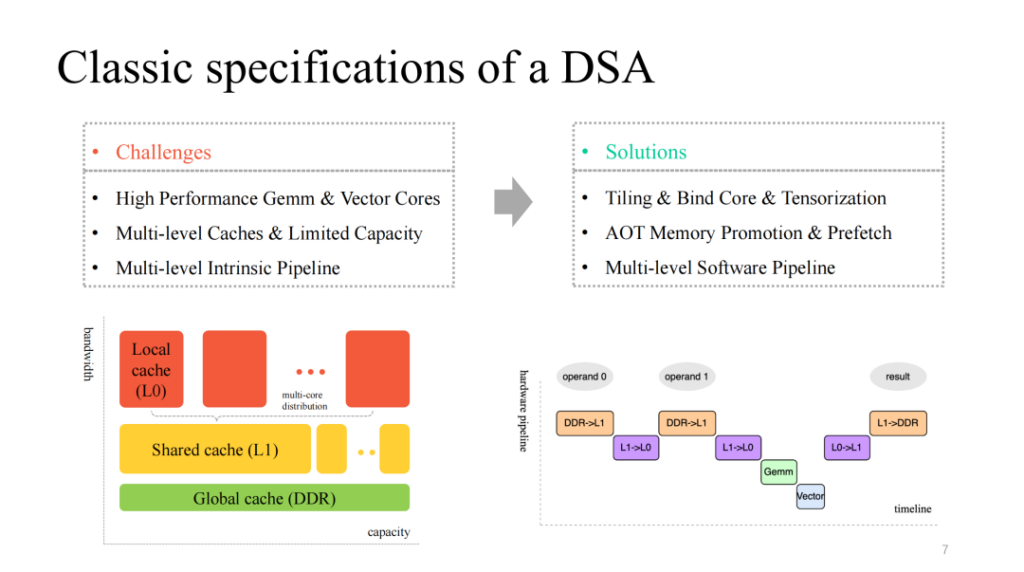
Wir sehen eine relativ klassische DSA-Architektur, die im Allgemeinen einige effiziente, angepasste Multi-Core-Rechenkerne mit Matrix- und Vektorschicht bereitstellt, über einen dazu passenden Multi-Layer-Cache-Mechanismus verfügt und außerdem Ausführungseinheiten mit mehreren Modulen bereitstellt, die parallel ausgeführt werden können. Dementsprechend müssen wir uns mit den folgenden Fragen befassen:
- Teilen Sie Datenberechnungen auf, binden Sie Kerne effizient und vektorisieren Sie benutzerdefinierte Anweisungen effizient.
- Verwalten Sie den begrenzten On-Chip-Cache genau und rufen Sie die Daten entsprechend auf verschiedenen Cache-Ebenen vorab ab.
- Optimieren Sie die mehrstufige Pipeline, die von mehreren Modulen ausgeführt wird, und streben Sie ein besseres Beschleunigungsverhältnis an.
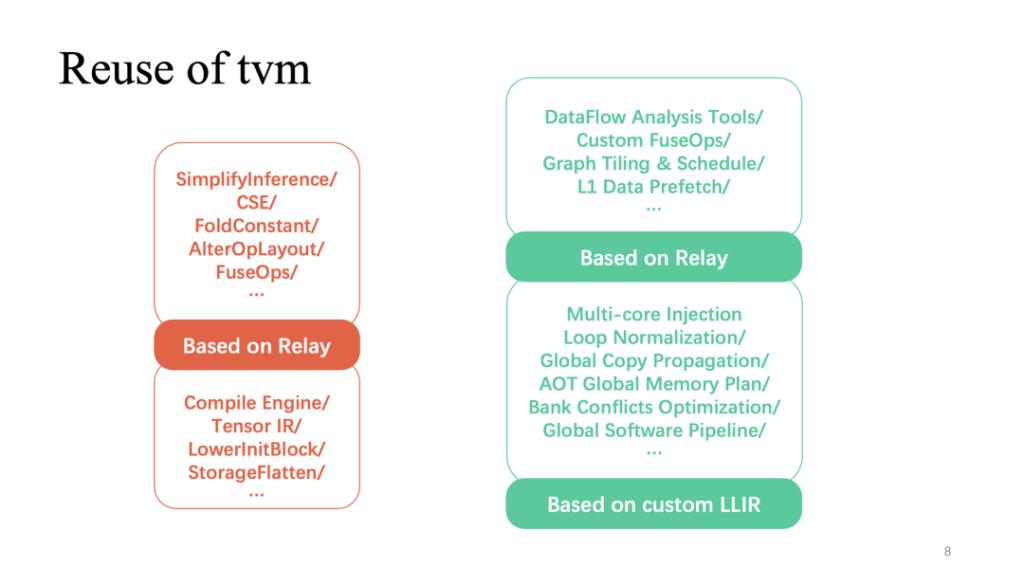
Der rote Teil (oben) zeigt den Teil mit der höchsten Wiederverwendung von TVM im gesamten Prozess. Die häufigeren, auf dem Relais implementierten schichtbezogenen Optimierungen können direkt wiederverwendet werden. Darüber hinaus wird auch die auf TensorIR und benutzerdefiniertem LLIR basierende Operatorimplementierung häufig wiederverwendet. Eine individuelle Optimierung im Zusammenhang mit Hardwarefunktionen erfordert, wie bereits erwähnt, mehr eigene Recherchearbeit.
Schauen wir uns zunächst eine selbst entwickelte Arbeit zum Thema Ebenen an.
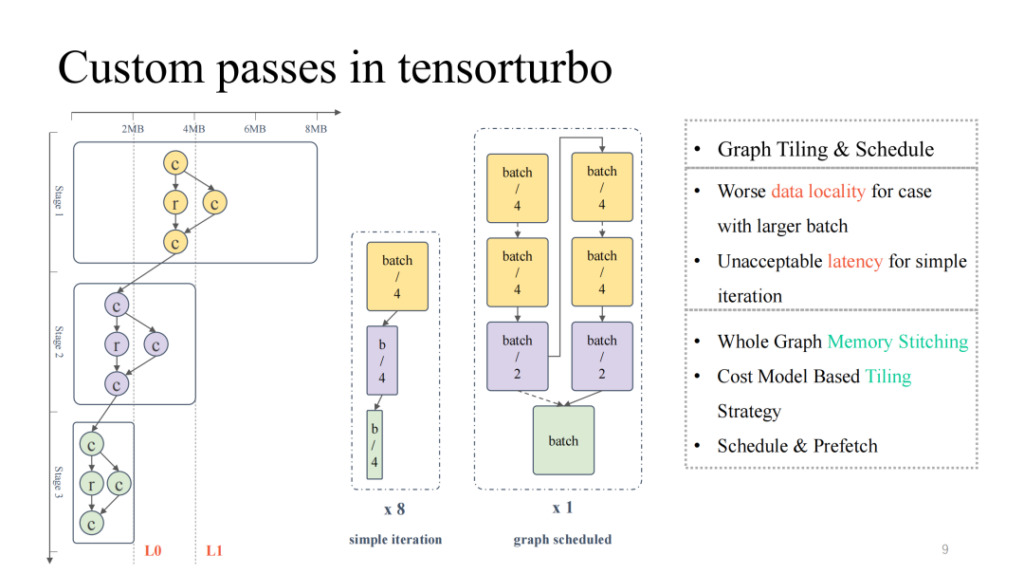
Wenn wir uns das typischere Computerflussdiagramm ganz links ansehen, können wir erkennen, dass die Gesamtcachebelegung und die Computerbelegung von oben nach unten ständig abnehmen und einen umgekehrten Pyramidenzustand darstellen. In der ersten Hälfte, wenn die Modellgröße groß ist, müssen wir uns auf die Lösung des Problems der On-Chip-Cache-Residenz konzentrieren. In der zweiten Hälfte hingegen, wenn die Modellgröße klein ist, müssen wir uns mit dem Problem der geringen Auslastung der Recheneinheiten auseinandersetzen. Wenn Sie einfach die Modellgröße anpassen, z. B. die Batchgröße, kann eine kleinere Batchgröße zu einer geringeren Latenz führen, der entsprechende Durchsatz wird jedoch reduziert. Ebenso führt eine größere Batchgröße zu einer höheren Latenz, kann aber den Gesamtdurchsatz verbessern.
Dann können wir die Graphenplanung verwenden, um dieses Problem zu lösen. Erstens ist die Eingabe einer relativ großen Batchgröße zulässig, um eine relativ hohe Auslastung der Berechnung während des gesamten Prozesses sicherzustellen. Anschließend wird eine Speicheranalyse des gesamten Graphen durchgeführt und eine Segmentierungs- und Planungsstrategie hinzugefügt, sodass die Ergebnisse der ersten Hälfte des Modells besser auf dem Chip zwischengespeichert werden können und gleichzeitig eine höhere Auslastung des Rechenkerns erreicht wird. In der Praxis können wir sowohl bei der Latenz als auch beim Durchsatz gute Ergebnisse erzielen (weitere Einzelheiten finden Sie im Artikel „Effectively Scheduling Computational Graphs of Deep Neural Networks towards Their Domain-Specific Accelerators“ von OSDI 23 Shim, der im Juni verfügbar sein wird).
Das Folgende ist eine weitere Beschleunigungsarbeit des weichen Wasserflusses.
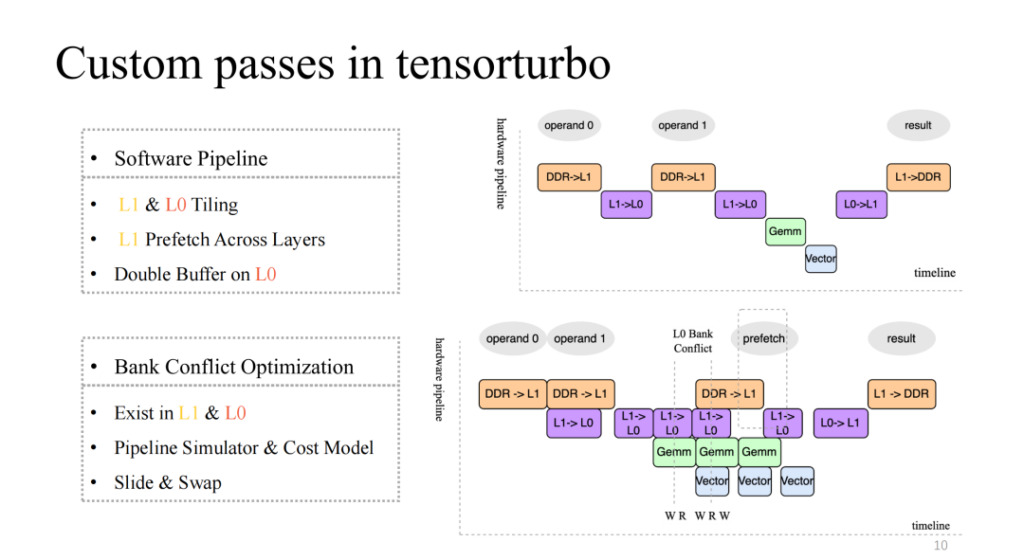
Achten Sie auf das Bild oben rechts, das eine relativ native vierstufige Pipeline implementiert, aber es handelt sich offensichtlich nicht um eine effiziente Pipeline. Im Allgemeinen sollte eine effiziente Pipeline in der Lage sein, die vier Ausführungseinheiten nach mehreren Iterationen zu synchronisieren und zu parallelisieren. Dies erfordert einige Arbeit, darunter Segmentierung auf L1 und L0, schichtübergreifendes Vorabrufen von Daten auf L1 und Doppelpuffervorgänge auf der L0-Ebene. Durch diese Arbeit können wir eine Pipeline mit relativ hoher Beschleunigung erreichen, wie in der unteren rechten Abbildung dargestellt.
Dies wird auch ein neues Problem mit sich bringen. Wenn beispielsweise die Anzahl gleichzeitiger Lese- und Schreibvorgänge mehrerer Ausführungseinheiten im Cache höher ist als die vom aktuellen Cache unterstützte Gleichzeitigkeit, kommt es zu Konkurrenz. Dieses Problem führt zu einem exponentiellen Rückgang der Speicherzugriffseffizienz, was als Bankkonfliktproblem bezeichnet wird. Um dieses Problem zu beheben, werden wir die Pipeline zur Kompilierzeit statisch simulieren, widersprüchliche Objekte extrahieren und das Kostenmodell verwenden, um die zugewiesenen Adressen auszutauschen und zu verschieben, wodurch die Auswirkungen dieses Problems erheblich verringert werden können.
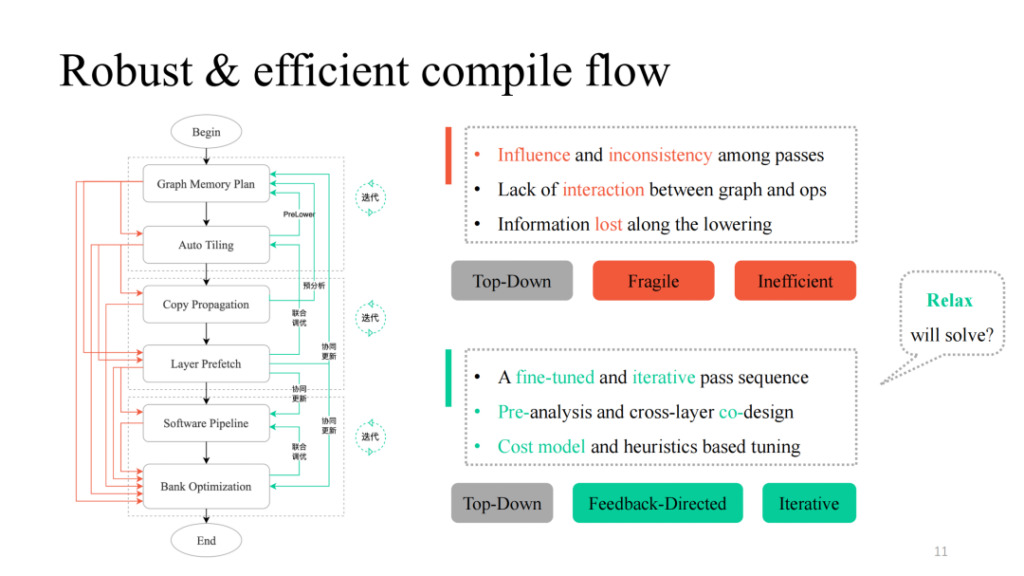
Nachdem wir verschiedene Durchgänge durchgeführt haben, können wir diese auf einfache Weise von oben nach unten kombinieren. Wenn wir dem schwarzen Prozess in der linken Abbildung folgen, erhalten wir eine funktional durchführbare Kompilierungspipeline. In der Praxis wurden jedoch viele Probleme festgestellt, darunter die von Siyuan erwähnte gegenseitige Beeinflussung zwischen den Durchläufen, das Fehlen einer Interaktionslogik und das Fehlen einer Kommunikationslogik zwischen Schichten und Operatoren. Sie können den Vorgang durch den roten Teil in der linken Abbildung erkennen. In der Praxis zeigt sich, dass jeder Pfad oder jede Kombination davon zu Kompilierungsfehlern führt. Wie kann man es robuster machen? Shim bietet in jedem Durchgang, der fehlschlagen kann, einen Feedback-Pfad, führt interaktive Logik zwischen Ebenen und Operatoren ein, führt Voranalysen und Prelower-Operationen durch und führt einige iterative Abstimmungsmechanismen in Schlüsselteilen ein, wodurch letztendlich eine Gesamt-Pipeline-Implementierung mit hoher Generalisierung und starken Abstimmungsmöglichkeiten erreicht wird.
Wir haben auch festgestellt, dass die Transformation der Datenstruktur und die zugehörigen Designideen in der obigen Arbeit viele Ähnlichkeiten mit dem aktuellen TVM Unity-Design aufweisen. Wir erwarten auch, dass Relax mehr Möglichkeiten bietet.
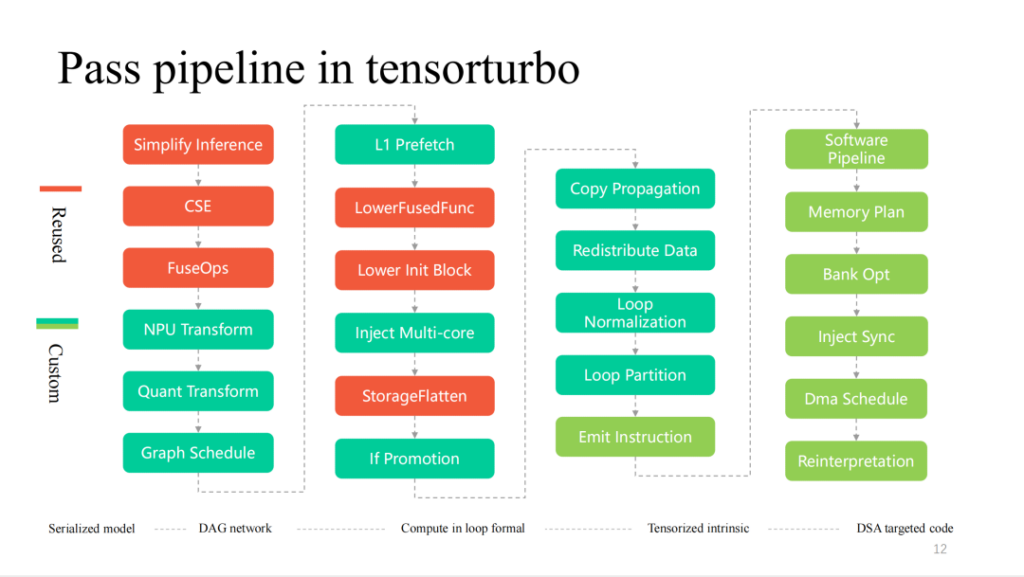
Hier sind detailliertere Durchläufe im Kompilierungsprozess von Xim. Von links nach rechts ist es ein Prozess der schichtweisen Abnahme. Der rote Teil wird von TVM häufig wiederverwendet. Je näher die Hardwarefunktionen sind, desto individueller wird es Pässe geben.
Nachfolgend finden Sie eine detaillierte Einführung in einige der Module.
Sim Computing Liu Fei: Vektorisierung und Tensorisierung von DSA
Dieser Teil wird vor Ort von Liu Fei, einem Computeringenieur bei Shim, geteilt.
In diesem Kapitel wird die Funktionsweise der Shim-Vektorisierung und Tensorquantisierung vorgestellt. Aus Sicht der Befehlsgranularität gilt: Je gröber die Befehlsgranularität, desto näher kommt sie dem mehrschichtigen Schleifenausdruck von Tensor IR, sodass die Schwierigkeit der vektorisierten Tensorquantisierung geringer ist. Im Gegenteil: Je feiner die Anweisungsgranularität, desto größer die Schwierigkeit. Unsere NPU-Anweisungen unterstützen eindimensionale/zweidimensionale/dreidimensionale Tensordatenberechnungen. Shim hat auch den nativen TVM-Tensorisierungsprozess in Betracht gezogen, aber angesichts der begrenzten Fähigkeit von Compute Tensorize, komplexe Ausdrücke auszudrücken, ist es schwierig, komplexe Ausdrücke wie eine if-Bedingung zu tensifizieren, und nach der Tensorisierungsvektorisierung kann dies nicht geplant werden.
Darüber hinaus befand sich TensorIR Tensorize zu diesem Zeitpunkt in der Entwicklung und konnte den Entwicklungsanforderungen nicht gerecht werden. Daher stellte Shim einen eigenen Satz von Befehlsvektorisierungsprozessen bereit, die wir als Befehlsemission bezeichnen. Im Rahmen dieses Prozesses unterstützen wir etwa 120 Tensor-Anweisungen, darunter Anweisungen verschiedener Dimensionen.

Unser Unterrichtsablauf ist grob in drei Module unterteilt:
- Optimierung vor dem Start. Durch die Transformation der Zyklusachse ergeben sich mehr Voraussetzungen und Möglichkeiten zur Befehlsausgabe;
- Befehlsübertragungsmodul. Analysieren Sie die Ergebnisse und Informationen der Schleife und wählen Sie eine optimale Methode zur Befehlsgenerierung aus.
- Das Modul nach der Ausgabe des Befehls. Verarbeiten Sie die angegebene Übertragung, nachdem ein Fehler aufgetreten ist, um eine korrekte Ausführung auf der CPU sicherzustellen.
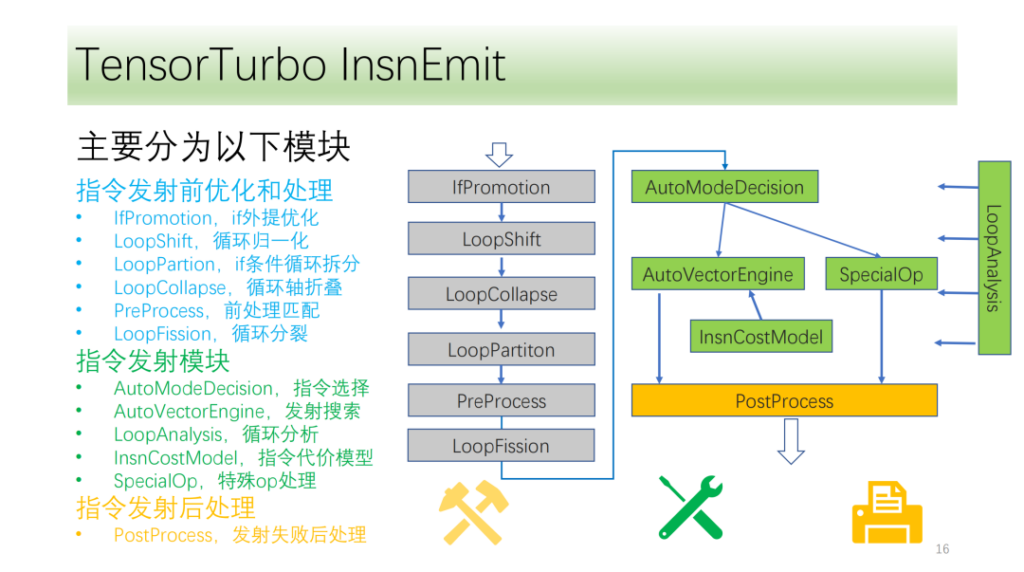
Unten istOptimierungs- und Verarbeitungsmodul vor der Befehlsausgabe,Sie bestehen alle aus einer Reihe von Optimierungsdurchläufen, darunter IfPromotion zum Entfernen von if-Anweisungen, die die Ausgabe von Schleifenachsen behindern, PreProcess zum Aufteilen von Operatoren ohne entsprechende Anweisungen, LoopShift zum Normalisieren der Schleifenachsengrenzen, LoopCallapse zum Zusammenführen aufeinanderfolgender Schleifenachsen, LoopPartition zum Aufteilen der mit if verbundenen Schleifenachsen und LoopFission zum Aufteilen mehrerer Store-Anweisungen in der Schleife.
Anhand dieses Beispiels können wir erkennen, dass der IR zunächst keine Anweisungen ausgeben kann. Nach der Optimierung kann es schließlich zwei Tensor-Anweisungen ausgeben und alle Schleifenachsen können Anweisungen ausgeben.
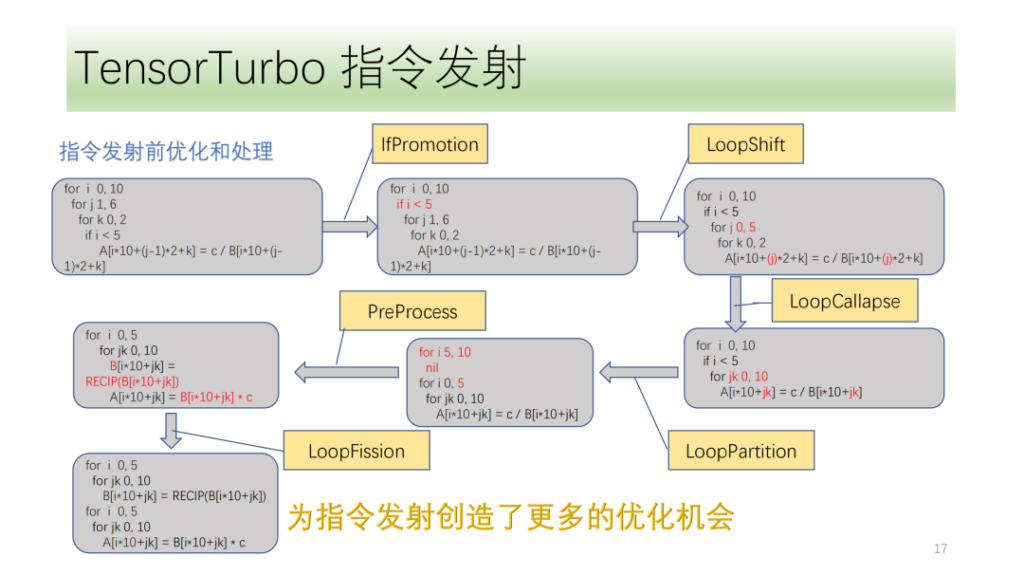
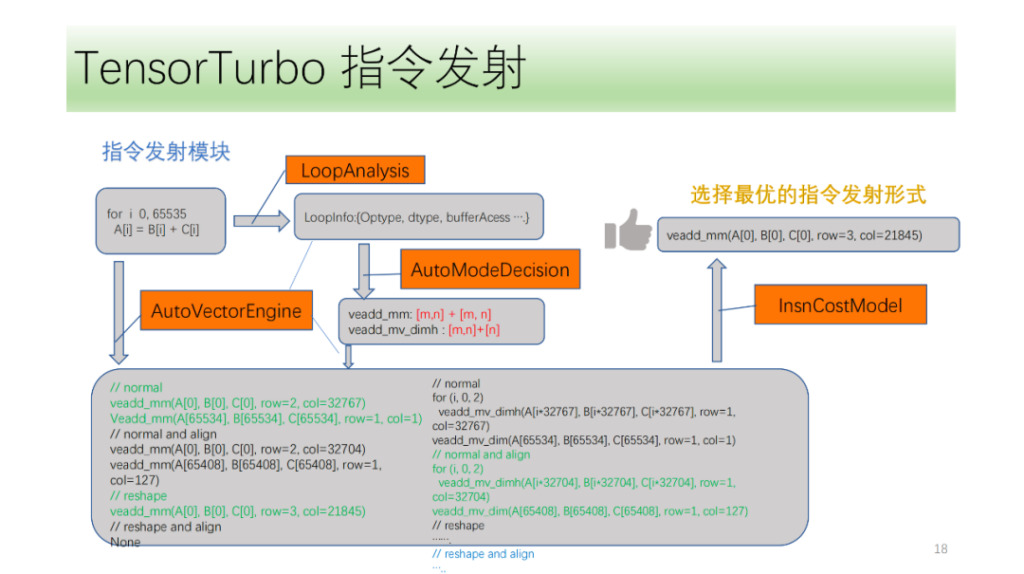
Dann gibt es noch das Befehlsübertragungsmodul. Zunächst analysiert das Befehlsemissionsmodul zyklisch die Struktur in der Schleife und erhält Informationen wie Optype, dtype, bufferAcess usw. Nach Erhalt dieser Informationen ermittelt die Befehlserkennung, welche Befehle die Schleifenachse ausgeben darf. Da eine IR-Struktur mehreren NPU-Anweisungen entsprechen kann, identifizieren wir alle möglichen auszugebenden Anweisungen und lassen die Suchmaschine von VectorEngine anhand einer Reihe von Informationen wie der Anweisungsausrichtung und -umformung nach der Möglichkeit suchen, jede Anweisung auszugeben. Abschließend berechnet und findet CostModel die optimale Emissionsform für die Emission.
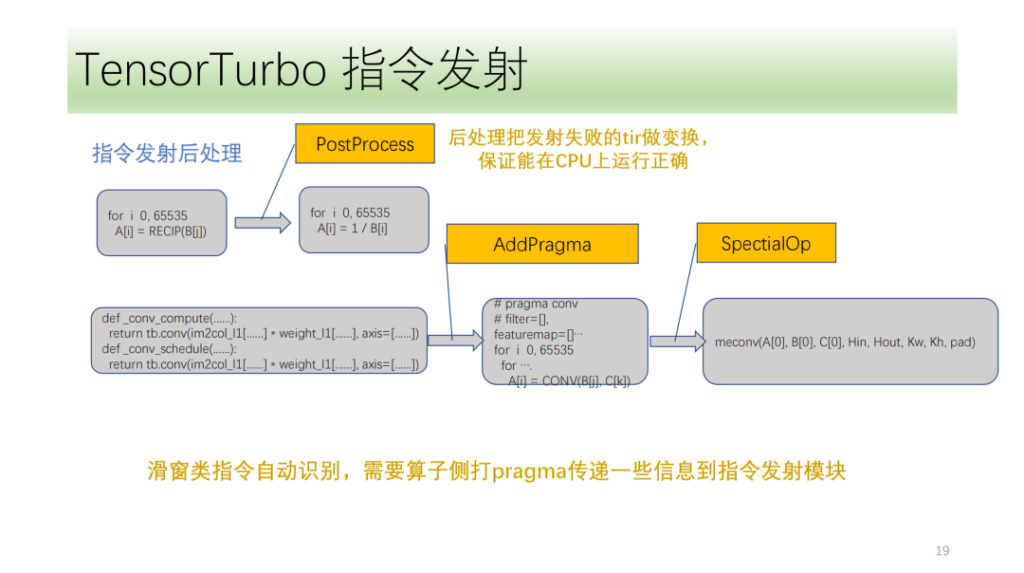
Das letzte ist das Modul zur Nachbearbeitung von Anweisungen. Der Hauptzweck besteht darin, den TIR zu verarbeiten, der die Anweisung nicht ausgeben konnte, um sicherzustellen, dass er auf der CPU korrekt ausgeführt werden kann. Es gibt auch einige spezielle Anweisungen, die Shim am vorderen Ende des Algorithmus markieren muss. Das Befehlsübertragungsmodul verwendet diese Markierungen und eine eigene IR-Analyse, um die entsprechenden Befehle korrekt zu übertragen.
Oben sehen Sie Shims gesamten DSA-Tensorquantisierungs- und -Vektorisierungsprozess. Wir haben auch einige Richtungen erkundet, beispielsweise die Mikrokernel-Lösung, die in letzter Zeit ebenfalls ein heiß diskutiertes Thema ist. Die Grundidee besteht darin, einen Rechenprozess in zwei Schichten aufzuteilen, wobei eine Schicht in Form eines kombinierten Mikrokernels gespleißt und die andere durchsucht wird. Abschließend werden die Ergebnisse der beiden Schichten zusammengefügt, um das optimale Ergebnis auszuwählen. Der Vorteil besteht darin, dass die Hardwareressourcen vollständig genutzt werden, während gleichzeitig die Suchkomplexität reduziert und die Sucheffizienz verbessert wird.
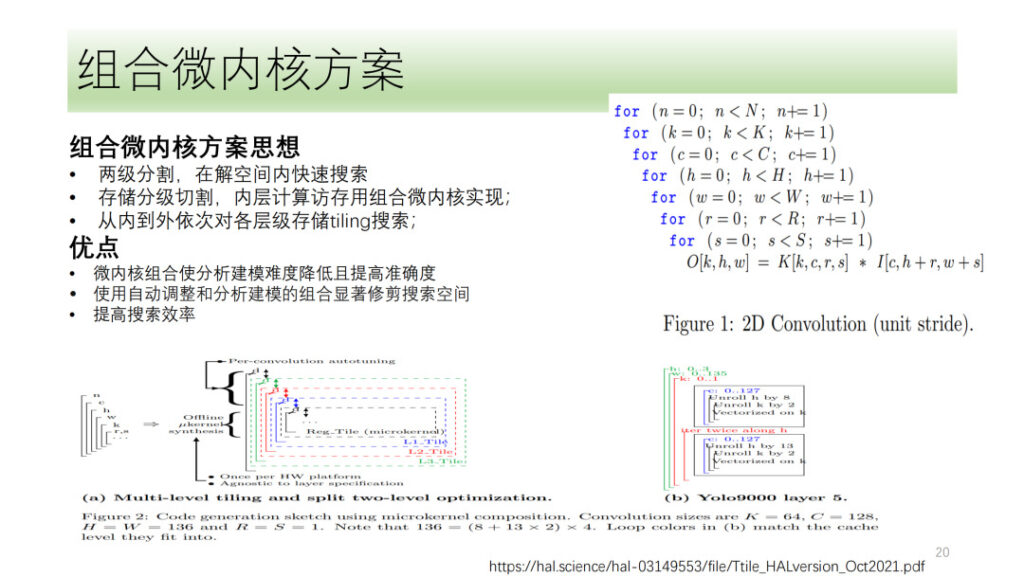

Shim hat auch den Mikrokernel erforscht, aber angesichts der Tatsache, dass die Mikrokernel-Lösung im Vergleich zu aktuellen Lösungen keine signifikante Leistungsverbesserung mit sich bringt, befindet sich Shim in Bezug auf den Mikrokernel noch immer in der Erkundungsphase.
Yuan Sheng, Shim Computing: Benutzerdefinierte Operatoren für DSA
Dieser Teil wird vor Ort vom Shim-Computeringenieur Yuan Sheng geteilt.
Zunächst einmal wissen wir, dass die Operatorentwicklung derzeit auf vier große Probleme stößt:
- Es gibt viele neuronale Netzwerkoperatoren, die unterstützt werden müssen. Nach der Klassifizierung gibt es mehr als 100 Basisoperatoren.
- Da die Hardwarearchitektur ständig iteriert wird, müssen die entsprechenden Anweisungen und die Logik der Operatoren geändert werden.
- Leistungsüberlegungen. Operatorfusion (lokaler Speicher, gemeinsam genutzter Speicher) und die zuvor erwähnte Informationsübertragung beim Graph Computing (Segmentierung usw.);
- Operatoren müssen für Benutzer offen sein und Benutzer können die Software nur aufrufen, um Operatoren anzupassen.
Ich habe es hauptsächlich in die folgenden drei Aspekte unterteilt. Der erste ist der Graphoperator, der auf der Relay-API basiert und auf grundlegende Sprachoperatoren zugeschnitten ist.
Nehmen Sie die folgende Abbildung als Beispiel:
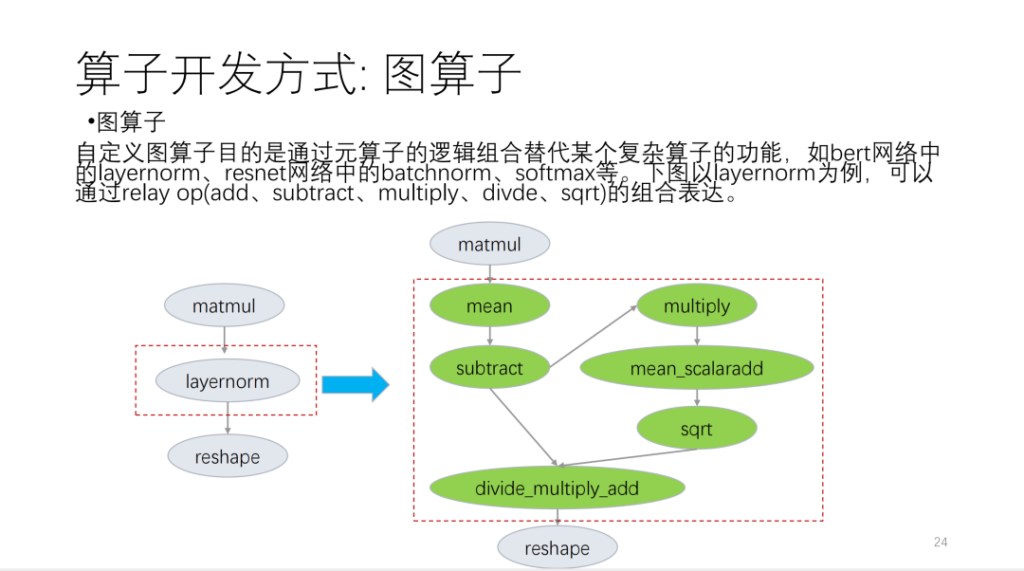
Der zweite ist der Metaoperator. Der sogenannte Metaoperator basiert auf TVM Topi und verwendet Compute/Schedule, um die Logik des Operatoralgorithmus und die mit der Schleifentransformation verbundene Logik zu beschreiben. Bei der Entwicklung von Operatoren stellen wir fest, dass viele Operatorpläne wiederverwendet werden können. Basierend auf dieser Situation bietet Shim eine Reihe von Vorlagen, die Zeitplänen ähneln. Nun unterteilen wir Operatoren in viele Kategorien. Basierend auf diesen Kategorien verwenden neue Betreiber eine große Anzahl von Zeitplanvorlagen wieder.
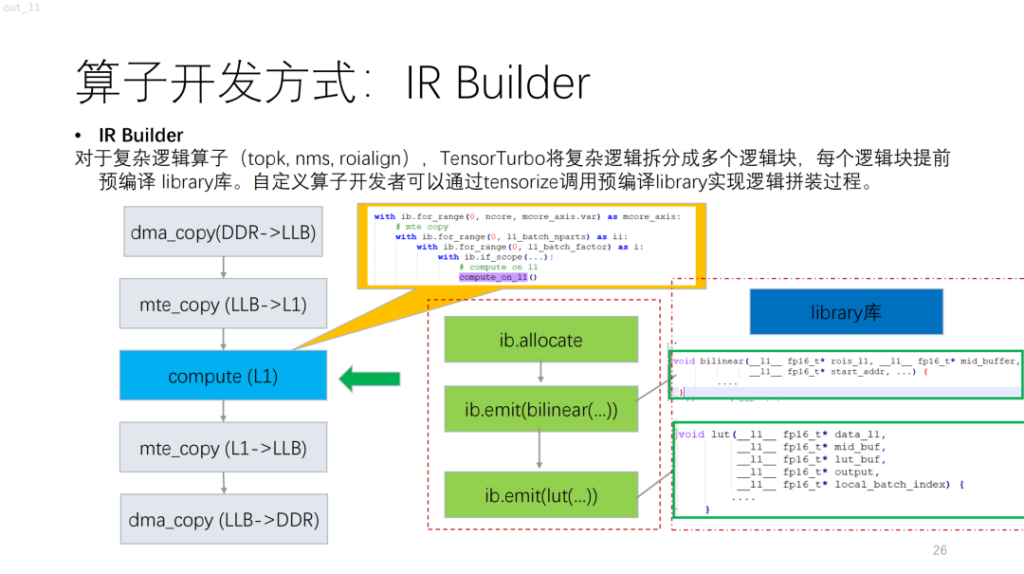
Als nächstes folgt ein komplexerer Operator. Basierend auf NPU werden Sie feststellen, dass Algorithmen mit Kontrollfluss wie topk und nms viele Skalarberechnungen beinhalten, die derzeit mit compute/schedule nur schwer beschrieben werden können. Um dieses Problem zu lösen, bietet Shim eine ähnliche Bibliothek. Dies entspricht dem Kompilieren einer komplexen Logik zuerst in der Bibliothek und der anschließenden Ausgabe der Logik des gesamten Operators durch Kombination mit dem IR Builder.
Als nächstes folgt die Segmentierung der Betreiber. Im Vergleich zu GPU und CPU wird bei NPU jeder Befehl von TVM auf einem zusammenhängenden Speicherblock ausgeführt und es gibt eine Speichergrößenbeschränkung. Gleichzeitig ist der Suchraum in diesem Fall nicht groß. Basierend auf diesen Problemen bot Shim Lösungen an. Zunächst wird ein Kandidatensatz erstellt und die möglichen Lösungen werden in den Kandidatensatz eingefügt. Zweitens wird die Machbarkeit erläutert, wobei hauptsächlich die Leistungsanforderungen und NPU-Befehlsbeschränkungen berücksichtigt werden. Abschließend wird die Kostenfunktion eingeführt, welche die Betreibereigenschaften und die Eigenschaften der ggf. eingesetzten Recheneinheiten berücksichtigt.
Der nächste schwierigste Aspekt der Operatorentwicklung ist der Fusionsoperator. Derzeit stehen wir vor zwei brisanten Problemen. Das erste ist, dass wir nicht wissen, wie wir unsere eigenen Operatoren mit anderen Operatoren kombinieren können. Zweitens können wir sehen, dass es in der NPU viele Speicherebenen gibt und dass es zu einer explosiven Verschmelzung von Speicherebenen kommt. Shim LLB wird über eine Fusionskombination aus gemeinsam genutztem Speicher und lokalem Speicher verfügen. Basierend auf dieser Situation stellen wir auch ein Framework zur automatischen Generierung bereit. Zuerst wird der Datenverschiebungsvorgang gemäß den von der Schicht bereitgestellten Planungsinformationen eingefügt, und dann werden die Planungsinformationen gemäß der Master-Operation und der Slave-Operation im Zeitplan verfeinert. Abschließend wird eine Nachbearbeitung basierend auf den Einschränkungen der aktuellen Anweisungen und anderen Problemen durchgeführt.

Abschließend werden hauptsächlich die von Shim unterstützten Operatoren angezeigt. Es gibt etwa 124 ONNX-Operatoren, und derzeit werden etwa 112 unterstützt, was 90,31 TP3T entspricht. Gleichzeitig verfügt Shim über eine Reihe von Zufallstests, mit denen große Primzahlen, Fusionskombinationen und einige Musterfusionskombinationen getestet werden können.
Zusammenfassen
Dieser Teil wird vor Ort vom Shim-Computeringenieur Dan Xiaoqiang geteilt.
Dies ist die von Shim auf Basis von TVM erstellte CI, die mehr als 200 Modelle und zahlreiche Unit-Tests ausführt. Wenn MR keine CI-Ressourcen belegt, dauert das Senden eines Codes mehr als 40 Minuten. Der Rechenaufwand ist sehr groß und umfasst mehr als 20 selbst entwickelte Rechenkarten und einige CPU-Maschinen.
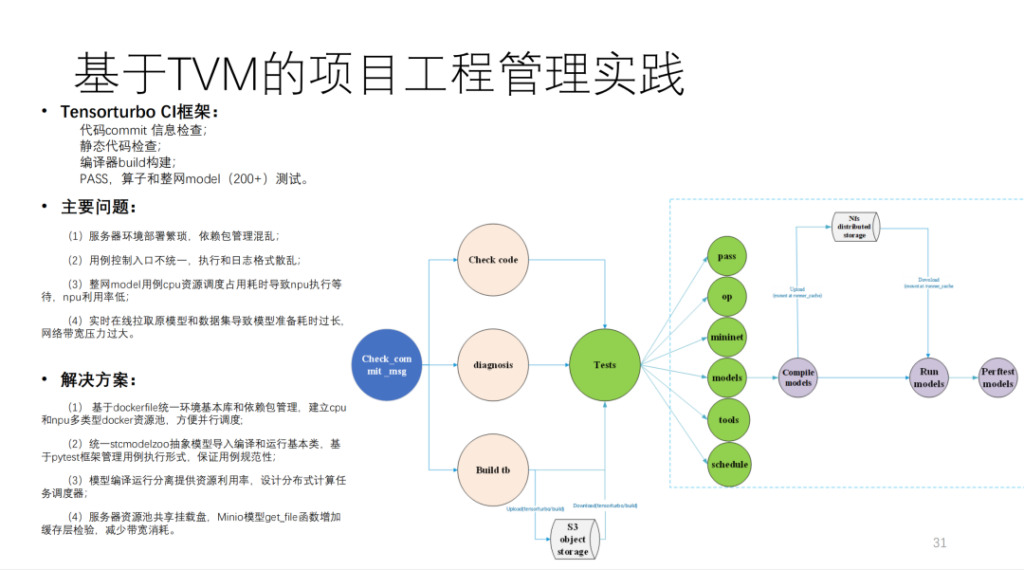
Zusammenfassend ist dies das Architekturdiagramm von Shim, wie unten gezeigt:
Die Ergebnisse zeigen, dass die Leistung erheblich verbessert wurde. Darüber hinaus kann die automatische Generierung im Vergleich zu einem anderen Handschriftmodellteam grundsätzlich deren 90% oder höher erreichen.

Dies ist die Situation des Xim-Codes. Auf der linken Seite wird gezeigt, wie TVM und selbst entwickelte Codes verwaltet werden. TVM wird als Datenstruktur in third_party verwendet. Xim hat seine eigene Quelle und Python-Dinge. Wenn wir Änderungen an TVM vornehmen müssen, können wir TVM im Patch-Ordner ändern. Dabei gelten drei Grundsätze:
- Die meisten von ihnen verwenden selbst entwickelte Pässe und entwickeln auch benutzerdefinierte Module.
- Der Patch wird die Änderung des TVM-Quellcodes einschränken und ihn, wenn möglich, rechtzeitig hochladen.
- Synchronisieren Sie regelmäßig mit der TVM-Community und aktualisieren Sie den neuesten Code im Repository.
Der gesamte Codeumfang ist auch in der Abbildung oben dargestellt.
Zusammenfassen:
- Wir unterstützen die Chips der ersten und zweiten Generation von HIMU durchgängig auf TVM-Basis.
- Implementieren Sie alle Anforderungen zur Kompilierungsoptimierung basierend auf Relay und Tir.
- Automatische Generierung von über 100 Vektortensoranweisungen basierend auf tir abgeschlossen;
- Implementierung einer benutzerdefinierten Betreiberlösung auf Basis von TVM;
- Die erste Generation des Modells unterstützt 160+ und die zweite Generation hat 20+ ermöglicht;
- Die Modellleistung kommt der Handschrift nahe.
Fragen und Antworten
F1: Ich interessiere mich für den Fusionsoperator. Wie lässt es sich mit dem TIR von TVM kombinieren?
A1: Für die rechte Abbildung gilt zunächst: Wenn der Operator zwei Eingänge und einen Ausgang hat, dann gibt es 27 Operatorformen. Zweitens kann der Geltungsbereich bei der Verbindung verschiedener Operatoren einer der drei sein, sodass wir nicht von einem festen Muster ausgehen. Wie kann es also auf TVM implementiert werden? Entscheiden Sie zunächst entsprechend der Ebenenplanung, wo sich die Front- und Back-Adds sowie der Zwischenbereich befinden. Das Schichten ist ein sehr komplexer Vorgang. Das Ausgabeergebnis soll bestimmen, in welchem Cache der Operator vorhanden ist und wie viel Cache verfügbar ist. Mit dem Ergebnis dieser Planung generieren wir automatisch fusionierte Operatoren auf der Operatorebene. Beispielsweise fügen wir basierend auf Umfangsinformationen automatisch Datenmigrationsvorgänge ein, um die Konstruktion des Datenflusses abzuschließen.
Der Mechanismus in den Zeitplaninformationen ist dem von TVM Native sehr ähnlich. Die von jedem Mitgliedsbereich verwendete Größe muss während des Fusionsprozesses berücksichtigt werden. Das ist also natives TVM-Material. Wir verwenden lediglich ein spezielles Framework, um es hier zu integrieren und zu automatisieren.
Zeitplan erstellen Auf dieser Grundlage wird der vom Entwickler benötigte Zeitplan erstellt, und es können auch einige Nachbearbeitungen erfolgen.

F2: Können Sie uns bitte weitere Einzelheiten zu CostModel mitteilen? Ist die Kostenfunktion auf der Grundlage von Funktionen auf Betreiberebene oder auf der Grundlage von Funktionen auf Hardwareebene konzipiert?
A1: Die Grundidee ist hier. Zunächst wird ein Kandidatensatz generiert. Der Generierungsprozess hängt mit der NPL-Struktur zusammen. Anschließend erfolgt ein Bereinigungsprozess, bei dem Befehlsbeschränkungen und nachfolgende Optimierungen, Multi-Core, Doppelpuffer usw. berücksichtigt werden. Abschließend gibt es eine Kostenfunktion zum Sortieren.
Wir wissen, dass das Wesentliche der Optimierungsroutine darin besteht, Datenbewegungen in Berechnungen zu verbergen. Es handelt sich lediglich um eine Simulation des Betriebs nach diesem Standard und die abschließende Berechnung der Kosten.
F3: Hat TVM zusätzlich zu den von TVM unterstützten Standardfusionsregeln neue Fusionsregeln generiert, beispielsweise eine einzigartige, für unterschiedliche Hardware in der Computerebene angepasste Fusion?
A3: Was die Fusion betrifft, gibt es eigentlich zwei Ebenen. Die erste ist die Pufferfusion und die zweite die Loopfusion. Genau auf Letzteres zielt das TVM-Fusionsverfahren ab. Shim folgt grundsätzlich dem von Ihnen erwähnten TVM-Fusionsmuster, allerdings mit einigen Einschränkungen.








