Command Palette
Search for a command to run...
Siyuan Feng: Apache TVM Und Die Entwicklung Der Machine-Learning-Kompilierung

Dieser Artikel wurde zuerst auf dem offiziellen WeChat-Konto von HyperAI veröffentlicht~
Guten Tag, herzlich willkommen zum 2023 Meet TVM heute. Als Apache TVM PMC,Lassen Sie mich Ihnen etwas über die Entwicklung von TVM und das zukünftige Unity-Framework von TVM erzählen.
Apache TVM-Entwicklung
Zunächst einmal: Warum gibt es MLC (Machine Learning Compilation)? Mit der weiteren Verbreitung von KI-Modellen werden auch in tatsächlichen Produktionsanwendungen höhere Anforderungen entstehen. Die KI-Anwendungen der ersten Ebene vieler Anwendungen (wie in der Abbildung dargestellt) werden gemeinsam genutzt, darunter ResNet, BERT, Stable Diffusion und andere Modelle.

Das Szenario der zweiten Ebene ist anders. Entwickler müssen diese Modelle in verschiedenen Szenarien einsetzen, angefangen beim Cloud Computing und High-Performance Computing, die eine GPU-Beschleunigung erfordern. Angesichts der Beschleunigung des KI-Bereichs besteht die wichtigste Aufgabe darin, diese in Tausende von Haushalten zu bringen, d. h. auf Personal-PCs, Mobiltelefone und Edge-Geräte.
Allerdings stellen unterschiedliche Szenarien unterschiedliche Anforderungen, darunter Kostensenkungen und Leistungsverbesserungen. Out of the Box muss sicherstellen, dass Benutzer es sofort nach dem Öffnen einer Webseite oder dem Herunterladen einer Anwendung verwenden können. Das Mobiltelefon muss Strom sparen. Edge muss auf Hardware ohne Betriebssystem ausgeführt werden. Manchmal muss die Technologie auch auf Chips mit geringem Stromverbrauch und geringer Rechenleistung laufen. Dies sind die Schwierigkeiten, auf die jeder bei unterschiedlichen Anwendungen stößt. Wie kann man sie lösen?
Im MLC-Bereich besteht ein Konsens, nämlich Muli-Level IR Design.Der Kern besteht aus drei Schichten: der ersten Schicht Graph-Level IR, der mittleren Schicht Tensor-Level IR und der nächsten Schicht Hardware-Level IR. Diese Schichten sind notwendig, da das Modell ein Graph ist, die mittlere Schicht Tensor-Level IR ist und der Kern von MLC in der Optimierung des Tensor Computing liegt. Die beiden darunter liegenden Schichten, Hardware-Level-IR und Hardware, sind aneinander gebunden, was bedeutet, dass TVM nicht direkt an der Generierung von Assembly-Anweisungen beteiligt ist, da es in der Mitte einige detailliertere Optimierungstechniken gibt, die vom Hersteller oder Compiler gelöst werden.

ML Compiler wurde mit den folgenden Zielen entwickelt:
- Abhängigkeitsminimierung
Minimieren Sie zunächst die Bereitstellung von Abhängigkeiten.Der Grund, warum KI-Anwendungen nicht wirklich Fuß fassen, liegt darin, dass die Schwelle für den Einsatz zu hoch ist. Mehr Leute haben ChatGPT als Stable Diffusion ausgeführt, nicht weil Stable Diffusion nicht leistungsfähig genug wäre, sondern weil ChatGPT eine Umgebung bietet, die sofort einsatzbereit ist. Meiner Meinung nach müssen Sie bei Stable Diffusion zuerst ein Modell von GitHub herunterladen und dann einen GPU-Server öffnen, um es bereitzustellen, aber ChatGPT funktioniert sofort. Der entscheidende Punkt bei der Out-of-the-Box-Verwendung besteht darin, Abhängigkeiten zu minimieren, sodass die Software von jedem und in allen Umgebungen verwendet werden kann.
- Verschiedene Hardware-Unterstützung
Der zweite Punkt ist, dass es unterschiedliche Hardware unterstützen kann.Der diversifizierte Einsatz von Hardware ist in den frühen Entwicklungsphasen nicht das wichtigste Thema, wird aber mit der Entwicklung von KI-Chips im In- und Ausland immer wichtiger, insbesondere angesichts des aktuellen inländischen Umfelds und des Status Quo der inländischen Chipunternehmen, der von uns eine gute Unterstützung aller Arten von Hardware erfordert.
- Kompilierungsoptimierung
Der dritte Punkt ist die allgemeine Kompilierungsoptimierung.Durch die Kompilierung der vorherigen IR-Ebenen kann die Leistung optimiert werden, einschließlich der Verbesserung der Betriebseffizienz und der Reduzierung des Speicherverbrauchs.
Die meisten Leute betrachten das Kompilieren und Optimieren als den wichtigsten Punkt, aber für die gesamte Community sind die ersten beiden Punkte entscheidend. Da dies aus der Perspektive des Compilers geschieht und diese beiden Punkte Durchbrüche von Null auf Eins darstellen, ist die Leistungsoptimierung oft das Tüpfelchen auf dem i.
Zurück zum Thema der Rede,Ich teile die Entwicklung von TVM in vier Phasen ein:Dies ist nur meine persönliche Meinung.
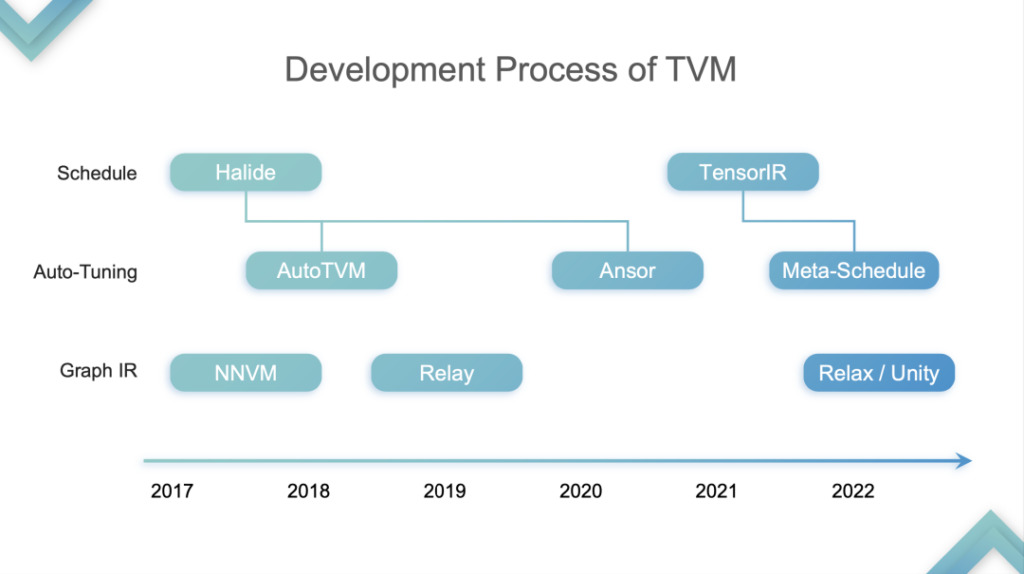
TensorIR-Abstraktion
Stufe 1:In dieser Phase optimiert und beschleunigt TVM die Inferenz auf der CPU und GPU. Die GPU bezieht sich speziell auf den Hardwareteil von SIMT. Zu diesem Zeitpunkt begannen viele Cloud-Computing-Anbieter, TVM zu verwenden, weil sie feststellten, dass es sowohl die CPU als auch die GPU beschleunigen konnte. Warum? Ich habe bereits erwähnt, dass CPU und GPU keine Tensorisierungsunterstützung haben. Die erste Generation des TVM TE Schedule basierte auf Halide und bot keine gute Tensorisierungsunterstützung. Daher folgte die nachfolgende Entwicklung von TVM dem technischen Weg der Halide-Entwicklung, einschließlich Auto-TVM und Ansor, die der Tensorisierungsunterstützung nicht zustimmten.
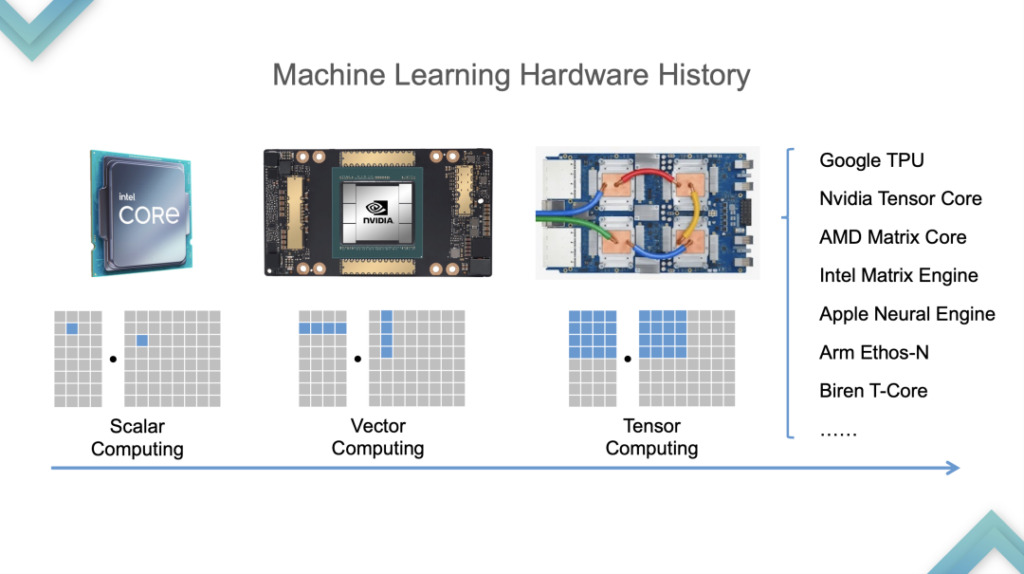
Sehen wir uns zunächst den Hardwareentwicklungsprozess an. Von der CPU zur GPU erfolgte der Wechsel etwa 2015 und 2016, und von der GPU zur TPU etwa 2019. Um die Tensorisierung zu unterstützen,TVM analysierte zunächst die Eigenschaften tensorialisierter Programme.
- Optimierte Schlaufennester mit Fadenbindung
Zunächst ist ein Schleifentest erforderlich, der für alle tensorisierten Programme erforderlich ist. Darunter liegt ein mehrdimensionales Laden von Daten. Dies unterscheidet sich von CMT und CPU. Es speichert und berechnet in Tensoren statt in Skalaren.
- Laden/Speichern mehrdimensionaler Daten in einen speziellen Speicherpuffer
Zweitens wird es in einem speziellen Speicherpuffer gespeichert.
- Opaker tensorisierter Berechnungskörper 16×16 Matrixmultiplikation
Drittens wird es einen Hardware-Pool geben, der Berechnungen ermöglicht. Das folgende Tensor-Primitiv wird als Beispiel zur Berechnung der 16*16-Matrixmultiplikation verwendet. Diese Berechnung wird nicht mehr als Berechnungsmodus mit Skalarkombination ausgedrückt, sondern als Kontoeinheit mit einer Anweisung berechnet.

Basierend auf den oben genannten drei qualitativen Analysen des Tensorized Program hat TVM den Computational Block eingeführt. Ein Block ist eine Recheneinheit mit Verschachtelung auf der äußersten Ebene, Iterationsiterator und Abhängigkeitsbeziehungen in der Mitte und Body unten. Das Konzept besteht darin, die Berechnung der inneren und äußeren Schichten zu trennen, das heißt, die interne Berechnung von der tensorisierten Berechnung zu isolieren.
Stufe 2:In dieser Phase führt TVM eine automatische Tensorisierung durch. Hier ist ein Beispiel, das die Implementierung im Detail erklärt.

Auto-Tensorisierung
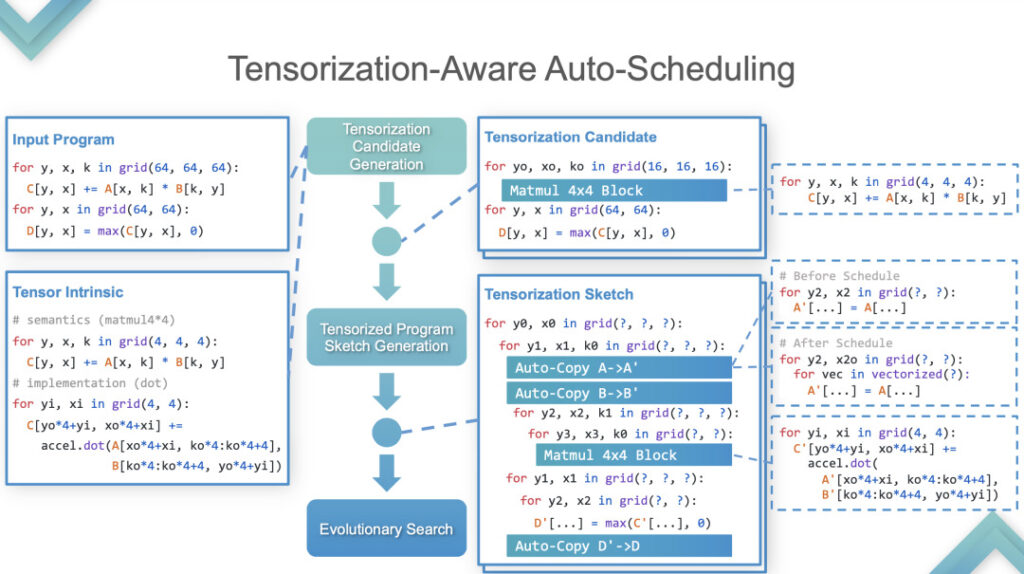
Eingabeprogramm und Tensor Intrinsic sind Eingaben. Die Ergebnisse zeigen, dass TensorIR und TensorRT auf der GPU grundsätzlich gleichauf liegen, die Leistung einiger Standardmodelle jedoch nicht sehr gut ist. Da das Standardmodell die Standardmetrik für ML Perf ist, verbringen die NVIDIA-Ingenieure viel Zeit damit, es zu entwickeln. Es kommt relativ selten vor, dass die Leistung von TensorRT bei Standardmodellen übertroffen wird, was gleichbedeutend damit wäre, die fortschrittlichste Technologie der Branche zu schlagen.
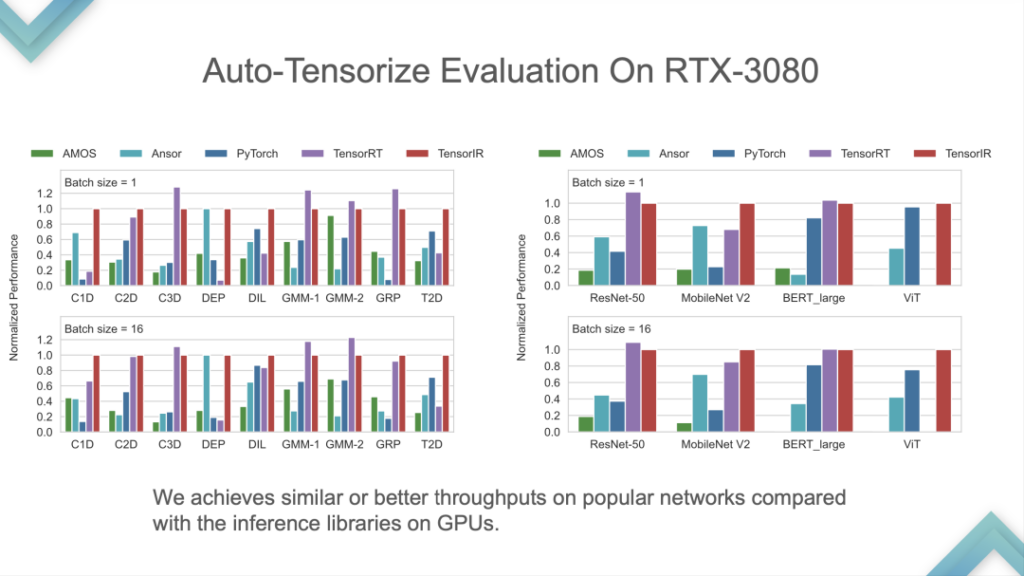
Dies ist ein Leistungsvergleich der von ARM selbst entwickelten CPU. TensorIR und ArmComputeLib können im End-to-End-Vergleich etwa doppelt so schnell sein wie Ansor und PyTorch. Die Leistung ist nicht das Wichtigste, der Kern ist die Idee der Auto-Tensorisierung.
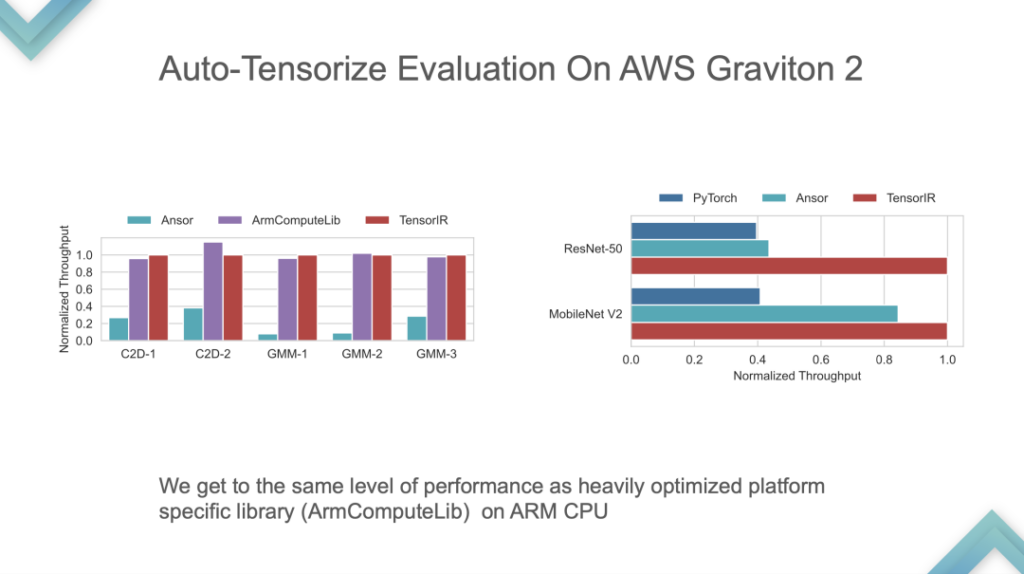
Stufe 3:Ein End-to-End-ML-Compiler für tensorisierte Hardware. In dieser Phase kann es auf die GPU oder einen bereits unterstützten Beschleunigerchip übertragen werden, gefolgt von automatischer Optimierung und Modellimport, wodurch ein selbstkonsistentes System entsteht. In dieser Phase ist End-to-End der Kern von TVM. Ein Modell kann für den direkten Einsatz entwickelt werden, eine Anpassung ist jedoch sehr schwierig.
Als nächstes werde ich etwas langsamer über die Entwicklung und die Denkweise von Relax und Unity sprechen, denn:
- Persönlich denke ich, dass Entspannung und Einheit wichtiger sind.
- Es befindet sich noch im experimentellen Stadium und vieles sind nur Ideen, es fehlt eine End-to-End-Demo und ein vollständiger Code.
Einschränkungen des Apache TVM Stack:
- Große Lücke zwischen Relay und TIR. Das größte Problem bei TVM besteht darin, dass das Kompilierungsparadigma vom Relay zum TIR zu steil ist.
- Feste Pipeline für die meiste Hardware. Der Standardprozess von TVM ist „Relay to TIR to“? Nach dem Kompilieren habe ich festgestellt, dass viele Hardwaregeräte entweder nur BYOC unterstützen oder BYOC+TIR verwenden möchten, Relay dies jedoch nicht gut unterstützt, weder TIR noch Library. Am Beispiel der GPU-Beschleunigung sind die zugrunde liegenden Dinge für Relay festgelegt. Sie können entweder CUDA für die automatische Optimierung schreiben, BYOC für TensorRT verwenden oder cuBLAS zum Optimieren von Bibliotheken von Drittanbietern verwenden. Obwohl es viele Möglichkeiten gibt, ist es immer eine Frage der Entscheidung für die eine oder die andere. Dieses Problem hat große Auswirkungen und ist auf Relay nur schwer zu lösen.
Lösung: TVM Unity.
Apache TVM Unity
Die beiden IR-Ebenen, Relax und TIR, werden als Ganzes behandelt und in das Graph-TIR-Programmierparadigma integriert. Form der Fusion: Am Beispiel des einfachsten linearen Modells ist in diesem Fall die gesamte IR steuerbar und programmierbar. Die Graph-TIR-Sprache löst das Problem, dass die untere Schicht zu steil ist. Operatoren auf hoher Ebene können schrittweise geändert und sogar in beliebige BYOC- oder Funktionsaufrufe geändert werden.

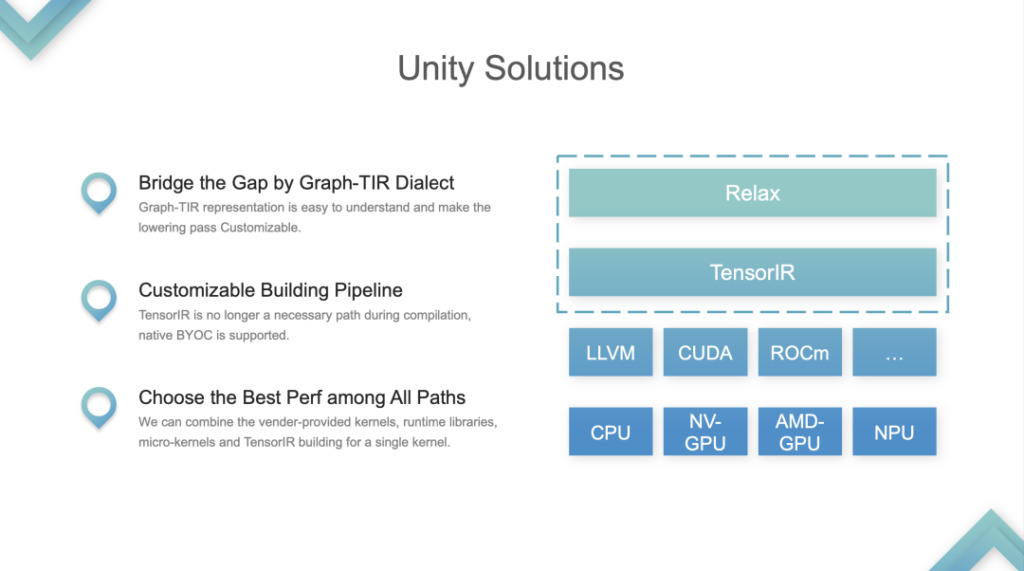
1. Unterstützen Sie benutzerdefinierte Lösungen für Probleme beim Erstellen von Pipelines. Die ursprüngliche TVM-Pipeline bestand darin, ein zusätzliches TIR weiterzuleiten, dann die Feinabstimmung des TIR vorzunehmen und es nach der Feinabstimmung an LLVM oder CUDA weiterzuleiten. Es handelte sich um eine fest installierte Rohrleitung. Jetzt hat sich die Pipeline geändert.
2. Wählen Sie aus allen Pfaden die beste Leistung aus. Entwickler können zwischen Bibliothek oder TIR wählen und alles aufrufen. Dies ist das wichtigste Problem, das Unity löst, und die Community betrachtet es als die einheitliche ML-Kompilierungslösung.
Missverständnis
- TVM und MLIR stehen im Wettbewerb
Tatsächlich besteht zwischen TVM und MLIR kein klares, gleichrangiges Wettbewerbsverhältnis. TVM konzentriert sich auf die MLC-Kompilierung von maschinellem Lernen, während MLIR den Schwerpunkt auf mehrere Ebenen legt und seine Funktionen auch für die ML-Kompilierung verwendet werden können. Entwickler verwenden MLIR für die Kompilierung von maschinellem Lernen, einerseits weil MLIR eine native Integration mit Frameworks wie PyTorch hat und andererseits, weil die Anpassungsmöglichkeiten von TVM vor Unity relativ schwach waren.
- TVM = Inferenz-Engine für CPU/GPU
TVM war nie eine Inferenzmaschine. Es kann Kompilierungen durchführen und Entwickler können es verwenden, um die Inferenz zu beschleunigen. TVM ist eine Compiler-Infrastruktur, aber keine Inferenzmaschine. Die Vorstellung, dass „TVM nur zur Beschleunigung eingesetzt werden kann“, ist falsch. Der Grund, warum TVM zur Beschleunigung verwendet werden kann, liegt im Wesentlichen am Compiler, der schneller ist als die Ausführungsmethoden im Eager-Modus wie PyTorch.
- TVM = Automatisches Tuning
Bevor Relax erschien, war die erste Reaktion aller auf TVM, dass sie durch Auto Tuning eine bessere Leistung erzielen könnten. Die nächste Entwicklungsrichtung von TVM besteht darin, dieses Konzept zu verwässern. TVM bietet verschiedene Möglichkeiten, eine bessere Leistung zu erzielen und den gesamten Kompilierungsprozess anzupassen. Die Aufgabe von TVM Unity besteht darin, einen Rahmen bereitzustellen, der verschiedene Vorteile vereint.
Nächster Schritt
Im nächsten Schritt wird sich TVM zu einer Cross-Layer-Compiler-Infrastruktur für maschinelles Lernen entwickeln und danach streben, eine anpassbare Building-Pipeline für verschiedene Backends zu werden, die die Anpassung auf unterschiedlicher Hardware unterstützt. Dies erfordert die Kombination verschiedener Methoden und die Integration der Stärken verschiedener Parteien.
Fragen und Antworten
F 1: Hat TVM Pläne, große Modelle zu optimieren?
A 1: Was große Modelle angeht, haben wir einige vorläufige Ideen. Derzeit hat TVM mit der Durchführung verteilter Schlussfolgerungen und einigen einfachen Trainings begonnen, es wird jedoch einige Zeit dauern, bis es wirklich implementiert werden kann.
F 2: Welche Unterstützung und Entwicklung wird Relax in Dynamic Shape in Zukunft haben?
A 2: Relay VM unterstützt dynamische Formen, generiert jedoch keine symbolische Deduktion. Beispielsweise ist die Ausgabe der Matrixmultiplikation von nmk n und m, aber in Relay werden die drei nmks zusammen als Any bezeichnet, was unbekannte Dimension bedeutet, und ihre Ausgabe ist auch eine unbekannte Dimension. Relay VM kann diese Aufgaben ausführen, aber während der Kompilierungsphase gehen einige Informationen verloren, daher löst Relax diese Probleme. Dies ist Relaxs Verbesserung von Relay in Dynamic Shape.
F 3: Die Kombination aus TVM-Optimierung und Geräteoptimierung. Wenn Sie Graph verwenden, um Anweisungen direkt zu generieren, scheinen TE und TIR bei der Geräteoptimierung nicht häufig verwendet zu werden. Wenn BYOC verwendet wird, werden anscheinend auch TE und TIR übersprungen. In der Freigabe wurde erwähnt, dass Relax möglicherweise über einige Anpassungsmöglichkeiten verfügt, die dieses Problem anscheinend lösen können.
A 3: Tatsächlich haben viele Hardwarehersteller bereits den TIR-Weg eingeschlagen, während einige Hersteller den verwandten Technologien keine Beachtung geschenkt haben und sich immer noch für die BYOC-Methode entscheiden. BYOC ist keine Kompilierung im strengen Sinne und unterliegt Einschränkungen hinsichtlich des Erstellungsmusters. Im Allgemeinen ist es nicht so, dass Unternehmen keine Community-Technologie nutzen können, sondern dass sie je nach ihren eigenen Umständen unterschiedliche Entscheidungen treffen.
F4: Sind mit der Einführung von TVM Unity höhere Migrationskosten verbunden? Wie können wir aus Sicht von TVM PMC den Benutzern einen reibungslosen Übergang zu TVM Unity ermöglichen?
A 4: Die TVM-Community hat Relay nicht aufgegeben, sondern lediglich die Option Relax hinzugefügt. Daher wird die alte Version weiterhin weiterentwickelt, aber um einige neue Funktionen nutzen zu können, ist möglicherweise eine Migration von Code und Versionen erforderlich.
Nachdem Relax vollständig veröffentlicht ist, wird die Community Migrationstutorials und bestimmte Tool-Unterstützung bereitstellen, um den direkten Import von Relay-Modellen in Relax zu unterstützen. Allerdings erfordert die Migration der auf Relay basierenden, angepassten Version zu Relax noch immer einen gewissen Arbeitsaufwand, der für ein Team von mehr als einem Dutzend Mitarbeitern im Unternehmen etwa einen Monat dauern wird.
F 5: TensorIR hat im Vergleich zu früher große Fortschritte bei Tensor gemacht, aber mir ist aufgefallen, dass TensorIR hauptsächlich auf Programmiermodelle wie SIMT und SIMD ausgerichtet ist, bei denen es sich um ausgereifte Programmiermethoden handelt. Gibt es bei vielen neuen KI-Chips und Programmiermodellen Fortschritte bei TensorIR?
A 5: Aus Sicht der Community liegt der Grund, warum TensorIR das SIMT-Modell verwendet, darin, dass derzeit nur SIMT-Hardware verwendet werden kann. Die Hardware und Befehlssätze vieler Hersteller sind nicht Open Source. Als Hardware stehen bei den großen Herstellern grundsätzlich nur CPU, GPU und einige Handy-SoCs zur Verfügung. Die Communities anderer Hersteller haben grundsätzlich keinen Zugriff darauf und können daher auch nicht auf deren Programmiermodellen basieren. Darüber hinaus kann aus kommerziellen Gründen kein Open Source-Angebot bereitgestellt werden, selbst wenn die Community und Unternehmen zusammenarbeiten, um ein TIR auf ähnlichem Niveau zu erstellen.
Das Obige ist eine Zusammenfassung der Rede von Feng Siyuan beim Meet TVM Shanghai Station 2023.Anschließend werden die von anderen Gästen dieser Veranstaltung geteilten detaillierten Inhalte nacheinander auch auf diesem offiziellen Konto veröffentlicht. Bitte weiterhin aufmerksam sein!
Holen Sie sich die PPT:Folgen Sie dem öffentlichen WeChat-Konto „HyperAI Super Neural Network“ und antworten Sie mit dem Schlüsselwort im Hintergrund TVM Shanghai,Holen Sie sich die vollständige PPT.
Chinesische TVM-Dokumentation:https://tvm.hyper.ai/
GitHub-Adresse:https://github.com/apache/tvm








