Command Palette
Search for a command to run...
Das KI-Unternehmen Hinter „Instant Universe“ War an Der Entwicklung Von Stable Diffusion Beteiligt Und Erhielt Im Vergangenen Jahr Eine Finanzierung in Höhe Von 50 Millionen US-Dollar.

Dieser Artikel wurde zuerst auf dem offiziellen WeChat-Konto von HyperAI veröffentlicht~
Am Morgen des 13. März (Peking-Zeit) fand in Los Angeles die Oscar-Verleihung 2023 statt.Der Film „Blink of an Eye“ räumte auf einen Schlag sieben Preise ab und wurde zum größten Gewinner.Die Hauptdarstellerin Michelle Yeoh gewann für diesen Film auch den Oscar als beste Schauspielerin und war damit die erste chinesische Schauspielerin in der Oscar-Geschichte.

Es wird davon ausgegangen, dass das Team für visuelle Effekte hinter diesem heiß diskutierten Science-Fiction-Film nur aus fünf Personen besteht. Um diese Spezialeffektaufnahmen so schnell wie möglich fertigzustellen, entschieden sie sich für die Technologie von Runway, um bestimmte Szenen zu erstellen, beispielsweise das Greenscreen-Tool (The Green Screen), um den Bildhintergrund zu entfernen.
„Schon mit wenigen Klicks spare ich Stunden, die ich nutzen kann, um drei oder vier verschiedene Effekte auszuprobieren und den Film so besser zu machen“, sagte Regisseur und Drehbuchautor Evan Halleck in einem Interview.

Runway: Beteiligte sich an der Entwicklung der ersten Generation von Stable Diffusion
Ende 2018 gründeten Cristóbal Valenzuela und andere Mitglieder Runway.Es handelt sich um einen Anbieter von Videobearbeitungssoftware mit künstlicher Intelligenz, der sich dafür einsetzt, die neuesten Fortschritte in der Computergrafik und im maschinellen Lernen zu nutzen, um Designern, Künstlern und Entwicklern die Hemmschwelle zur Inhaltserstellung zu senken und die Entwicklung kreativer Inhalte zu fördern.

Nur rund 40 Mitarbeiter
außerdem,Runway hat auch eine weniger bekannte Identität – es war ein wichtiger Teilnehmer an der ersten Version von Stable Diffusion.
Im Jahr 2021 ging Runway eine Partnerschaft mit der Universität München in Deutschland ein, um die erste Version von Stable Diffusion zu entwickeln. Anschließend brachte das britische Startup Stability AI „Kapital in die Gruppe ein“ und stellte Stable Diffusion weitere Rechenressourcen und Mittel zur Verfügung, die für das Modelltraining benötigt wurden. Allerdings arbeiten Runway und Stability AI nicht mehr zusammen.
Im Dezember 2022 erhielt Runway 50 Millionen US-Dollar im Rahmen einer Finanzierung der Serie C. Zu seinen Kunden zählen neben dem „Blink“-Team auch die Medienkonzerne CBS und MBC, die Werbefirmen Assembly und VaynerMedia sowie das Designunternehmen Pentagram.
Am 6. Februar 2023 veröffentlichte der offizielle Twitter-Account von Runway das Gen-1-Modell.Sie können ein vorhandenes Video in ein neues umwandeln, indem Sie einen beliebigen durch Texthinweise oder Referenzbilder angegebenen Stil anwenden.
Gen-1: Struktur + Inhalt
Forscher schlugen ein struktur- und inhaltsgesteuertes Videodiffusionsmodell der ersten Generation vor, das Videos basierend auf der visuellen oder textlichen Beschreibung der erwarteten Ausgabe bearbeiten kann.
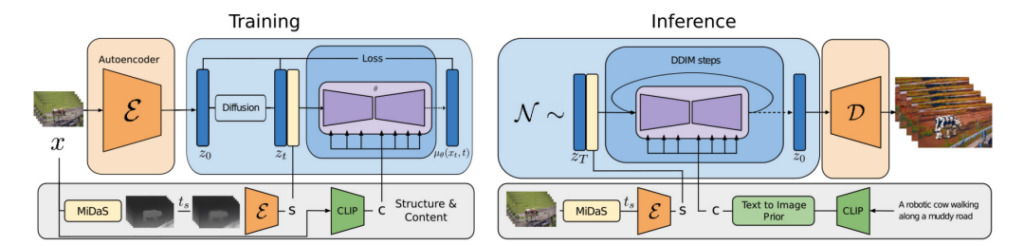
Der sogenannte Inhalt bezieht sich auf die Merkmale, die das Erscheinungsbild und die Semantik des Videos beschreiben, wie beispielsweise die Farbe und den Stil des Zielobjekts und die Beleuchtung der Szene.
Unter Struktur versteht man die Beschreibung der geometrischen und dynamischen Eigenschaften, wie etwa Form, Position und zeitliche Veränderungen des Zielobjekts.
Das Ziel des Gen-1-Modells besteht darin, Videoinhalte zu bearbeiten und dabei die Videostruktur beizubehalten.
Während des Modelltrainingsprozesses verwendeten die Forscher einen umfangreichen Datensatz, der aus Videos ohne Untertitel und Text-Bild-Paaren bestand. Gleichzeitig wurden monokulare Tiefenschätzungen der Szene zur Darstellung der Struktur und die von einem vorab trainierten neuronalen Netzwerk vorhergesagten Einbettungen zur Darstellung des Inhalts verwendet.
Dieser Ansatz bietet mehrere leistungsstarke Steuerungsmöglichkeiten für den Generierungsprozess:
1. Beziehen Sie sich auf das Bildsynthesemodell und trainieren Sie das Modell, sodass der abgeleitete Videoinhalt (wie Präsentation oder Stil) mit dem vom Benutzer bereitgestellten Bild oder der Eingabeaufforderung übereinstimmt.

2. Beziehen Sie sich auf den Diffusionsprozess und führen Sie eine Informationsverschleierung der Strukturdarstellung durch, die es Entwicklern ermöglicht, den Grad der Ähnlichkeit der Modellanhaftung an eine bestimmte Struktur festzulegen.
3. Beachten Sie die klassifikatorfreie Anleitung und verwenden Sie benutzerdefinierte Anleitungsmethoden, um den Denkprozess anzupassen und die zeitliche Konsistenz der generierten Clips zu steuern.
In diesem Experiment haben die Forscher Folgendes getan:
- Wir erweitern das latente Diffusionsmodell auf die Videogenerierung, indem wir eine zeitliche Ebene in das vortrainierte Bildmodell einführen und Bilder und Videos gemeinsam trainieren.
- Wir schlagen ein struktur- und inhaltsbewusstes Modell vor, das Videos anhand von Beispielbildern oder -texten ändern kann. Die Videobearbeitung erfolgt vollständig in der Inferenzphase, ohne dass ein Training oder eine Vorverarbeitung für jedes Video erforderlich ist.
- Vollständige Kontrolle über zeitliche, inhaltliche und strukturelle Konsistenz. Experimente zeigen, dass durch gemeinsames Training mit Bild- und Videodaten die zeitliche Konsistenz während der Inferenz aufrechterhalten werden kann. Um eine Strukturkonsistenz zu gewährleisten, ermöglicht das Training auf unterschiedlichen Detailebenen der Darstellung dem Benutzer, während der Inferenz die gewünschte Einstellung auszuwählen.
- Eine Benutzerumfrage ergab, dass diese Methode beliebter war als mehrere andere Methoden.
- Durch Feinabstimmung einer kleinen Teilmenge von Bildern kann das trainierte Modell weiter angepasst werden, um genauere Videos von bestimmten Motiven zu erstellen.
Um die Leistung von Gen-1 zu bewerten, verwendeten die Forscher Videos aus dem DAVIS-Datensatz und eine Vielzahl anderer Materialien.Um automatisch Bearbeitungsaufforderungen zu erstellen, führten die Forscher zunächst ein Untertitelungsmodell aus, um eine Beschreibung des ursprünglichen Videoinhalts zu erhalten, und verwendeten dann GPT3, um Bearbeitungsaufforderungen zu generieren.
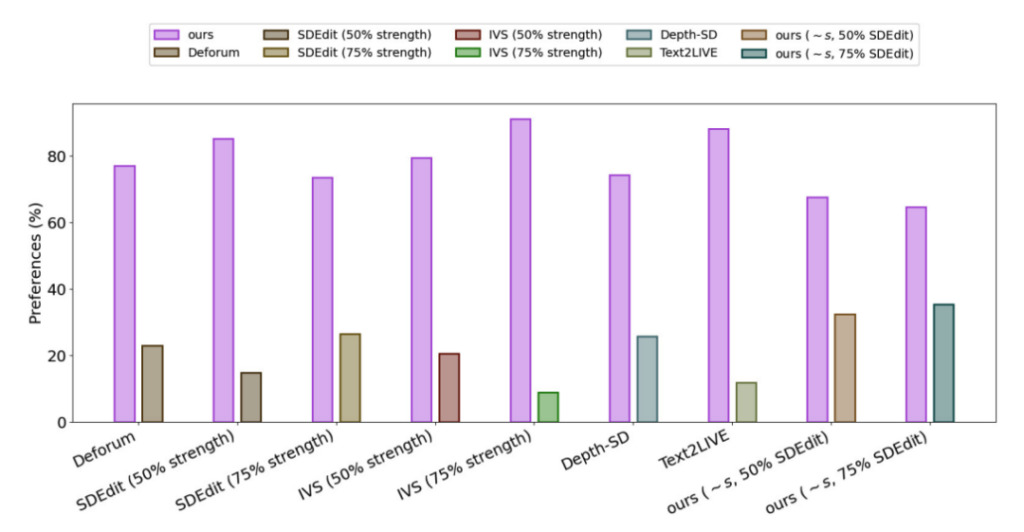
Die experimentellen Ergebnisse zeigen, dass in der Zufriedenheitsumfrage aller Methoden,Benutzer von 75% bevorzugen den Effekt der Gen-1-Generation.
AIGC: Fortschritte trotz Kontroversen
Im Jahr 2022 ist die generative KI die auffälligste Technologie seit dem Aufstieg des Mobil- und Cloud-Computing vor über einem Jahrzehnt und wir haben das Glück, das Aufkeimen ihrer Anwendungsebene mitzuerleben.Zahlreiche große Modelle entstehen rasch in Laboren und werden auf verschiedene Szenarien in der realen Welt angewendet.
Trotz der vielen Vorteile, wie etwa der Verbesserung der Effizienz und der Kostenersparnis, müssen wir jedoch auch erkennen, dass die generative künstliche Intelligenz noch mit zahlreichen Herausforderungen konfrontiert ist. Dazu gehören die Verbesserung der Ausgabequalität und Vielfalt des Modells, die Erhöhung der Generierungsgeschwindigkeit sowie Fragen der Sicherheit, des Datenschutzes sowie ethischer und religiöser Aspekte während des Anwendungsprozesses.
Manche Menschen stellen die Schaffung von Kunstwerken durch KI in Frage und manche meinen sogar, es handele sich um eine „Invasion“ der Kunst durch KI. Angesichts dieser Stimme glaubt Cristóbal Valenzuela, Mitbegründer und CEO von Runway, dass KI lediglich ein Werkzeug im Werkzeugkasten ist, mit dem Bilder und andere Inhalte eingefärbt oder geändert werden können, und sich nicht von Photoshop oder LightRoom unterscheidet.Obwohl generative KI noch immer umstritten ist, öffnet sie sowohl Laien als auch kreativen Menschen die Tür zur Schöpfung und wird dem Bereich der Inhaltserstellung neue Möglichkeiten eröffnen.
Referenzlinks:
[1]https://hub.baai.ac.cn/view/23940
[2]https://cloud.tencent.com/developer/article/2227337?








