Command Palette
Search for a command to run...
Nehmen Sie Die Animated Drawings APP Als Beispiel, Um TorchServe Zum Optimieren Des Modells Zu Verwenden
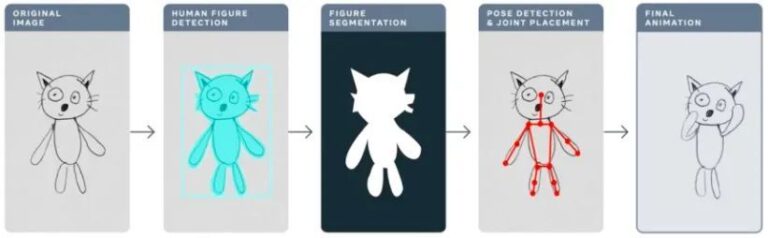
Inhalt Im vorherigen Abschnitt wurden die fünf Schritte der Bereitstellung und Optimierung des TorchServe-Modells vorgestellt, um das Modell in einer Produktionsumgebung bereitzustellen. In diesem Abschnitt wird die App „Animated Drawings“ als Beispiel verwendet, um den Modelloptimierungseffekt von TorchServe zu demonstrieren. Dieser Artikel wurde zuerst auf dem offiziellen WeChat-Konto veröffentlicht:PyTorch-Entwickler-Community
Letztes Jahr nutzte Meta die App „Animated Drawings“, um handgezeichnete Zeichnungen von Kindern mithilfe von KI zu „animieren“ und so statische Strichzeichnungen in Sekundenschnelle in Animationen umzuwandeln.


Animierte Zeichnungensketch.metademolab.com/
Für KI ist das nicht einfach. KI wurde ursprünglich für die Verarbeitung von Bildern in der realen Welt entwickelt. Im Vergleich zu realen Bildern unterscheiden sich Kinderzeichnungen stark in Form und Stil und sind komplexer und unvorhersehbarer. Daher sind frühere KI-Systeme möglicherweise nicht für die Verarbeitung von Aufgaben geeignet, die animierten Zeichnungen ähneln.
In diesem Artikel wird anhand von Animated Drawings ausführlich erklärt, wie Sie mit TorchServe das Modell optimieren, das in der Produktionsumgebung bereitgestellt wird.
4 Faktoren, die die Modelloptimierung in Produktionsumgebungen beeinflussen
Der folgende Workflow zeigt die allgemeine Idee der Verwendung von TorchServe zum Bereitstellen eines Modells in einer Produktionsumgebung.

In den meisten Fällen werden in Produktionsumgebungen bereitgestellte Modelle auf Grundlage von Service Level Agreements (SLAs) hinsichtlich Durchsatz oder Latenz optimiert.
Normalerweise geht es bei Echtzeitanwendungen eher um die Latenz, während es bei Offlineanwendungen eher um den Durchsatz geht.
Es gibt viele Faktoren, die die Leistung von Modellen beeinflussen, die in Produktionsumgebungen eingesetzt werden. Dieser Artikel konzentriert sich auf vier davon:
1. Modelloptimierungen
Dies ist ein vorbereitender Schritt zur Bereitstellung von Modellen für die Produktion und umfasst Quantisierung, Beschneiden, die Verwendung von IR-Diagrammen (TorchScript in PyTorch), das Zusammenführen von Kerneln und viele andere Techniken. Derzeit sind viele ähnliche Techniken in TorchPrep als CLI-Tools verfügbar.
2. Batch-Inferenz
Es bezieht sich auf die Einspeisung mehrerer Eingaben in ein Modell. Es wird häufig während des Trainingsprozesses verwendet und ist auch hilfreich für die Kostenkontrolle während der Inferenzphase.
Hardwarebeschleuniger sind auf Parallelität optimiert und Batching hilft dabei, die Rechenleistung voll auszunutzen, was oft zu einem höheren Durchsatz führt. Der Hauptunterschied bei der Inferenz besteht darin, dass Sie nicht zu lange warten müssen, um einen Batch vom Client zu erhalten. Dies wird oft als dynamisches Batching bezeichnet.
3. Anzahl der Arbeitnehmer
TorchServe stellt das Modell über Mitarbeiter bereit. Worker in TorchServe sind Python-Prozesse, die über eine Kopie der für die Inferenz verwendeten Modellgewichte verfügen. Zu wenige Arbeitnehmer werden nicht von ausreichender Parallelität profitieren; zu viele Mitarbeiter führen zu einer geringeren Mitarbeiterkonkurrenz und einer schlechteren End-to-End-Leistung.
4. Hardware
Wählen Sie basierend auf Ihrem Modell, Ihrer Anwendung, Ihrer Latenz und Ihrem Durchsatzbudget eine geeignete Hardware aus TorchServe, CPU, GPU, AWS Inferentia.
Einige Hardwarekonfigurationen sind darauf ausgelegt, die beste Leistung ihrer Klasse zu erzielen, während andere darauf ausgelegt sind, die erwartete Kostenkontrolle besser zu erfüllen. Experimente zeigen, dass GPU besser geeignet ist, wenn die Batchgröße groß ist. Wenn die Batchgröße klein ist oder eine geringe Latenz erforderlich ist, sind CPU und AWS Inferentia kostengünstiger.
Tipps: Was Sie bei der Optimierung der TorchServe-Leistung beachten sollten
Bevor Sie beginnen,Lassen Sie uns zunächst einige Tipps zum Bereitstellen von Modellen mit TorchServe und zum Erzielen der besten Leistung geben.
* Lernen Sie das offizielle PyTorch-Tutorial
Die Hardwareauswahl ist auch eng mit der Auswahl der Modelloptimierung verknüpft.
* Die Wahl der Hardware für die Modellbereitstellung hängt eng mit der Latenz, den Durchsatzerwartungen und den Kosten jeder Inferenz zusammen.
Aufgrund der Unterschiede in Modellgröße und Anwendung können CPU-Produktionsumgebungen den Einsatz ähnlicher Computer-Vision-Modelle normalerweise nicht leisten.Sie können sich für die Nutzung von OpenBayes.com registrieren und erhalten bei der Registrierung 3 Stunden RTX3090 kostenlos sowie jede Woche 10 Stunden RTX3090 kostenlos, um den allgemeinen GPU-Bedarf zu decken.
Darüber hinaus sorgen Optimierungen wie IPEX, die kürzlich zu TorchServe hinzugefügt wurden, dafür, dass solche Modelle kostengünstiger bereitgestellt werden können und die CPU-Auslastung geringer ist.
Weitere Informationen zur Bereitstellung des IPEX-Optimierungsmodells finden Sie unter
* Der Worker in TorchServe gehört zum Python-Prozess.Kann parallele,Die Anzahl der Mitarbeiter sollte mit Bedacht festgelegt werden.Standardmäßig startet TorchServe eine Anzahl von Workern, die der Anzahl der VCPUs oder verfügbaren GPUs auf dem Host entspricht, was den Start von TorchServe erheblich verlängern kann.
TorchServe stellt eine Konfigurationseigenschaft bereit, um die Anzahl der Worker festzulegen. Um eine effiziente Parallelität für mehrere Worker zu gewährleisten und zu vermeiden, dass diese um Ressourcen konkurrieren, wird empfohlen, die folgenden Baselines für CPU und GPU festzulegen:
CPU:Im Handler festlegen torch.set_num_threads(1) . Stellen Sie dann die Anzahl der Arbeiter auf Anzahl physischer Kerne / 2 . Die beste Thread-Konfiguration lässt sich jedoch durch die Verwendung des Intel CPU-Starterskripts erreichen.
Grafikkarte:Die Anzahl der verfügbaren GPUs kann in config.properties eingestellt werden Anzahl_GPUs um es einzurichten. TorchServe verwendet Round-Robin, um Arbeiter GPUs zuzuweisen. Anregung:Anzahl der Arbeiter = (Anzahl der verfügbaren GPUs) / (Anzahl der einzigartigen Modelle). Beachten Sie, dass GPUs vor Ampere keine Ressourcenisolierung mit Multi-Instance-GPUs bieten.
* Die Batchgröße wirkt sich direkt auf Latenz und Durchsatz aus.Um die Rechenressourcen besser zu nutzen, muss die Batchgröße erhöht werden. Es gibt einen Kompromiss zwischen Latenz und Durchsatz; Eine größere Batchgröße kann den Durchsatz erhöhen, führt aber auch zu einer höheren Latenz.
Es gibt zwei Möglichkeiten, die Batchgröße in TorchServe festzulegen.Eine Möglichkeit besteht in der Modellkonfiguration in config.properties, die andere in der Registrierung des Modells mithilfe der Management-API.
Der nächste Abschnitt zeigt, wie Sie mit der TorchServe-Benchmark-Suite die beste Kombination aus Hardware, Workern und Batchgröße für die Modelloptimierung ermitteln.
Lernen Sie die TorchServe Benchmark Suite kennen
Um die TorchServe-Benchmark-Suite zu verwenden, benötigen Sie zunächst eine archivierte Datei, nämlich die oben erwähnte. .beschädigen dokumentieren. Diese Datei enthält das Modell, den Handler und alle anderen Artefakte, die zum Laden und Ausführen der Inferenz verwendet werden. Die App zum animierten Zeichnen verwendet das Mask-rCNN-Objekterkennungsmodell von Detectron2
Ausführen der Benchmark-Suite
Die automatisierte Benchmark-Suite in TorchServe kann mehrere Modelle mit unterschiedlichen Batchgrößen und Worker-Einstellungen vergleichen und Berichte ausgeben.
lernen Automatisierte Benchmark-Suite
Starten Sie den Lauf:
git clone https://github.com/pytorch/serve.git cd serve/benchmarks pip install -r requirements-ab.txt apt-get install apache2-utils
Konfigurieren Sie die Einstellungen auf Modellebene in der YAML-Datei:
Modellname: eager_mode: benchmark_engine: "ab" url: "Pfad zur .mar-Datei" Worker: - 1 - 4 Batch_Delay: 100 Batch_Größe: - 1 - 2 - 4 - 8 Anfragen: 10000 Parallelität: 10 Eingabe: "Pfad zur Modelleingabe" Backend_Profiling: False exec_env: "lokal" Prozessoren: - "CPU" - "GPUs": "alle"
Diese YAML-Datei wird benchmark_config_template.yaml Zitat. Die YAML-Datei enthält zusätzliche Einstellungen zum Generieren von Berichten und Anzeigen von Protokollen mithilfe von AWS Cloud.
python benchmarks/auto_benchmark.py --input benchmark_config_template.yaml
Führen Sie den Benchmark aus und die Ergebnisse werden in einer CSV-Datei gespeichert. _/tmp/benchmark/ab_report.csv_ oder vollständigen Bericht /tmp/ts_benchmark/report.md Gefunden in.
Zu den Ergebnissen gehören die durchschnittliche Latenz von TorchServe, die Latenz des Modells P99, der Durchsatz, die Parallelität, die Anzahl der Anfragen, die Handlerzeit und andere Messwerte.
Konzentrieren Sie sich auf die Verfolgung der folgenden Faktoren, die sich auf die Modelloptimierung auswirken: Parallelität, Modell-P99-Latenz und Durchsatz.
Diese Zahlen müssen im Zusammenhang mit der Losgröße, der verwendeten Ausrüstung, der Anzahl der Arbeiter und der Frage betrachtet werden, ob eine Modelloptimierung durchgeführt wurde.
Die Latenz-SLA für dieses Modell wurde auf 100 ms festgelegt. Dies ist eine Echtzeitanwendung. Die Latenz ist ein wichtiges Thema und der Durchsatz sollte so hoch wie möglich sein, ohne die Latenz-SLA zu verletzen.
Indem wir den Raum durchsuchen, führen wir eine Reihe von Experimenten mit unterschiedlichen Batchgrößen (1–32), Anzahlen von Arbeitern (1–16) und Geräten (CPU, GPU) durch und fassen die besten experimentellen Ergebnisse wie in der folgenden Tabelle dargestellt zusammen:

Dieses Modell hat die gesamte Latenzzeit in Bezug auf CPU, Batchgröße, Parallelität und Anzahl der Mitarbeiter getestet, konnte jedoch die SLA nicht einhalten und die Latenzzeit wurde tatsächlich um das 13-fache reduziert.
Durch die Verlagerung der Modellbereitstellung auf die GPU wurde die Latenz sofort von 305 ms auf 23,6 ms reduziert.
Eine der einfachsten Optimierungen, die Sie für Ihr Modell vornehmen können, besteht darin, seine Genauigkeit auf fp16 zu reduzieren. Dies ist ein einzeiliger Code (Modell.halb()) , kann die Latenz des Modells P99 von 32% reduzieren und den Durchsatz um fast den gleichen Betrag erhöhen.
Eine weitere Möglichkeit zur Optimierung des Modells besteht darin, das Modell in TorchScript zu konvertieren und zu verwenden Optimierung_für_Inferenz oder andere Techniken (einschließlich Onnx- oder Tensor-Laufzeitoptimierungen), die aggressive Fusionen ausnutzen.
Auf CPU und GPU einstellen Anzahl der Arbeiter=1 Dies funktioniert im Fall dieses Artikels am besten.
* Stellen Sie das Modell auf der GPU bereit und legen Sie fest Anzahl der Arbeiter = 1, Batchgröße = 1, Durchsatz um das 12-fache erhöht und Latenz um das 13-fache reduziert im Vergleich zur CPU.
* Stellen Sie das Modell auf der GPU bereit und legen Sie fest model.half(), Anzahl der Arbeiter = 1 , Batchgröße = 8können die besten Ergebnisse hinsichtlich Durchsatz und tolerierbarer Latenz erzielt werden. Im Vergleich zur CPU erhöhte sich der Durchsatz um das 25-fache und die Latenz entsprach immer noch dem SLA (94,4 ms).
Hinweis: Wenn Sie eine Benchmark-Suite ausführen, achten Sie darauf, dass Sie die entsprechenden Batchverzögerung, legt die Gleichzeitigkeit der Anforderungen auf eine Zahl fest, die proportional zur Batchgröße ist. Mit Parallelität ist hier die Anzahl gleichzeitig an den Server gesendeter Anfragen gemeint.
Zusammenfassen
Dieser Artikel stellt die Überlegungen zur Feinabstimmung des TorchServe-Modells in einer Produktionsumgebung und der TorchServe-Benchmark-Suite zur Leistungsoptimierung vor und vermittelt Benutzern ein tieferes Verständnis der möglichen Optionen zur Modelloptimierung, Hardwareauswahl und den Gesamtkosten.
konzentrieren Sie sich auf PyTorch-Entwickler-CommunityOffizielles Konto, um weitere PyTorch-Technologie-Updates, Best Practices und zugehörige Informationen zu erhalten!








