Command Palette
Search for a command to run...
Absolut! OpenAI Wird Ende Des Jahres Ein Neues Produkt herausbringen. Eine Einzelne Karte Kann in 1 Minute Eine 3D-Punktwolke generieren. Text-to-3D Verabschiedet Sich Aus Der Ära Des Hohen Rechenleistungsbedarfs
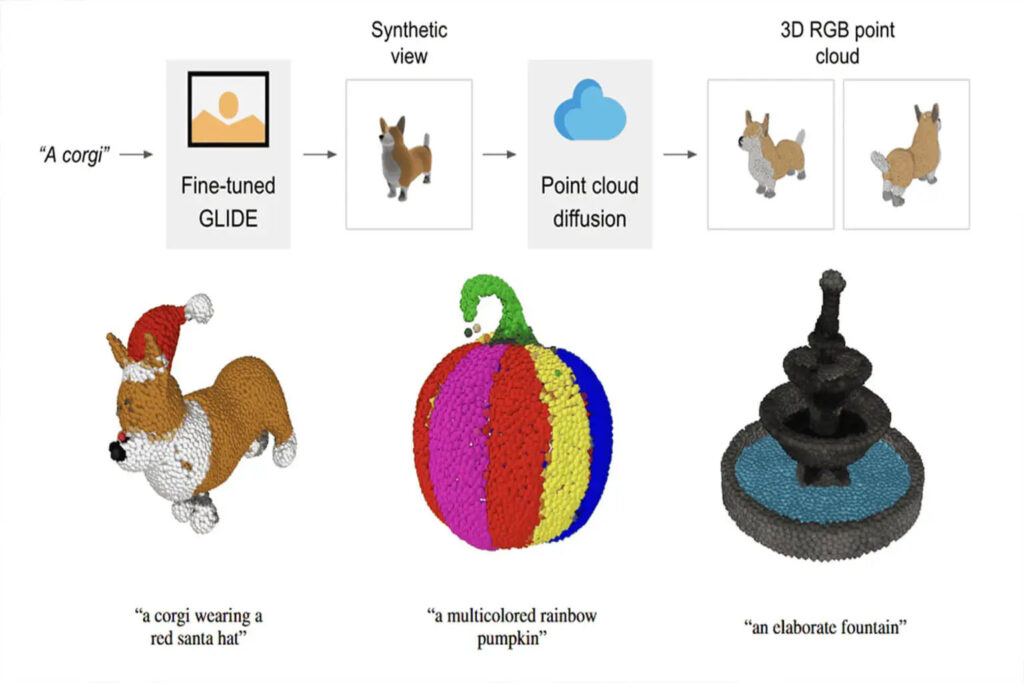
Inhalte im Überblick:Nach DALL-E und ChatGPT hat OpenAI einen weiteren Versuch unternommen und kürzlich Point·E veröffentlicht, das 3D-Punktwolken direkt auf der Grundlage von Textaufforderungen generieren kann. Schlüsselwörter:OpenAI 3D-Punktwolke Punkt E
OpenAI strebt eine Jahresendleistung an. Vor mehr als einem halben Monat wurde ChatGPT veröffentlicht, aber viele Internetnutzer haben es immer noch nicht herausgefunden. Vor Kurzem wurde in aller Stille ein weiteres leistungsstarkes Tool veröffentlicht – Point·E, das 3D-Punktwolken direkt auf der Grundlage von Textaufforderungen generieren kann.
Text-to-3D: Mit dem richtigen Ansatz kann man zwei Dinge tun
Ich glaube, jeder ist mit 3D-Modellierung vertraut. In den letzten Jahren ist 3D-Modellierung in Bereichen wie Filmproduktion, Videospielen, Industriedesign, VR und AR zu sehen.
Allerdings ist die Erstellung realistischer 3D-Bilder mit Hilfe künstlicher Intelligenz immer noch ein zeit- und arbeitsintensiver Prozess.Am Beispiel von Google DreamFusion sind für die Generierung von 3D-Bildern aus gegebenem Text normalerweise mehrere GPUs und eine Laufzeit von mehreren Stunden erforderlich.

Im Allgemeinen lassen sich Text-zu-3D-Synthesemethoden in zwei Kategorien einteilen:
Methode 1:Trainieren Sie generative Modelle direkt anhand gepaarter (Text, 3D) Daten oder unbeschrifteter 3D-Daten.
Obwohl solche Methoden durch die Nutzung vorhandener generativer Modellmethoden effektiv Beispiele generieren können, ist es aufgrund des Mangels an groß angelegten 3D-Datensätzen schwierig, sie auf komplexe Textaufforderungen auszuweiten.
Methode 2:Nutzen Sie vortrainierte Text-zu-Bild-Modelle, um die Optimierung für differenzierbare 3D-Darstellungen zu ermöglichen.
Solche Methoden sind normalerweise in der Lage, komplexe und vielfältige Textaufforderungen zu verarbeiten, aber der Optimierungsprozess für jede Probe ist kostspielig. Darüber hinaus können solche Methoden aufgrund des Fehlens einer starken 3D-Voraussage in lokale Minima fallen (die nicht eins zu eins mit einem aussagekräftigen oder kohärenten 3D-Objekt übereinstimmen können).
Point·E kombiniert Text-zu-Bild-Modell und Bild-zu-3D-Modell.Durch die Kombination der Vorteile der beiden oben genannten MethodenDie Effizienz der 3D-Modellierung wurde weiter verbessert und es werden nur eine GPU und ein oder zwei Minuten benötigt, um die Konvertierung von Text in eine 3D-Punktwolke abzuschließen.
Prinzipanalyse: 3 Schritte zur Generierung einer 3D-Punktwolke
In Punkt E nutzt das Text-Bild-Modell einen großen Korpus (Text-, Bildpaar), um komplexe Textaufforderungen richtig verarbeiten zu können. Das Bild-zu-3D-Modell wird anhand eines kleineren Datensatzes (Bild, 3D-Paar) trainiert.
Der Prozess der Generierung einer 3D-Punktwolke auf Basis von Textaufforderungen mit Point·E gliedert sich in drei Schritte:
1. Generieren Sie eine synthetische Ansicht basierend auf der Textaufforderung
2. Generieren Sie eine grobe Punktwolke (1024 Punkte) basierend auf der synthetischen Ansicht
3. Generieren Sie eine feine Punktwolke (4096 Punkte) basierend auf einer Punktwolke mit niedriger Auflösung und einer synthetischen Ansicht

Da Datenformat und Datenqualität einen großen Einfluss auf die Trainingsergebnisse haben,Point·E verwendete Blender, um alle Trainingsdaten in ein gemeinsames Format zu konvertieren.
Blender unterstützt mehrere 3D-Formate und verfügt über eine optimierte Rendering-Engine. Das Blender-Skript vereinheitlicht das Modell zu einem Begrenzungswürfel, konfiguriert ein Standardbeleuchtungs-Setup und exportiert schließlich ein RGBAD-Bild mithilfe der in Blender integrierten Echtzeit-Rendering-Engine.
""" Skript zur Ausführung in Blender, um ein 3D-Modell als RGBAD-Bilder zu rendern. Beispielverwendung blender -b -P blender_script.py -- \ --input_path ../../examples/example_data/corgi.ply \ --output_path render_out Übergeben Sie `--camera_pose z-circular-elevated` für das Rendering, das zur Berechnung der CLIP R-Precision-Ergebnisse verwendet wird. Das Ausgabeverzeichnis enthält JSON-Metadatendateien für jede gerenderte Ansicht sowie eine globale Metadatendatei für das Rendering. Jedes Bild wird als Sammlung von 16-Bit-PNG-Dateien für jeden Kanal (rgbad) sowie als vollständiges Graustufen-Rendering der Ansicht gespeichert.
Blender-Skriptcode
Durch Ausführen des Skripts wird das 3D-Modell einheitlich als RGBAD-Bild gerendert
Das vollständige Skript finden Sie unter:
Vorheriger Text-zu-3D-KI-Vergleich
In den letzten zwei Jahren gab es viele Untersuchungen zur Generierung von Text-zu-3D-Modellen.Auch große Unternehmen wie Google und NVIDIA haben ihre eigene KI auf den Markt gebracht.
Wir haben drei KIs zur Text-zu-3D-Synthese gesammelt und zusammengestellt, damit Sie die Unterschiede horizontal vergleichen können.
Traumfelder
Verlag:Google
Veröffentlichungszeit:Dezember 2021
Projektadresse:https://ajayj.com/dreamfields
DreamFields kombiniert neuronales Rendering mit multimodalen Bild- und Textdarstellungen.Allein auf Grundlage der Textbeschreibung ist es möglich, eine Vielzahl von 3D-Objektformen und -farben ohne 3D-Überwachung zu generieren.

Während DreamFields 3D-Objekte generiert,Es greift auf das auf einem großen Textbilddatensatz vortrainierte Bild-Text-Modell zurück und optimiert das Neural Radiance Field aus mehreren Perspektiven.Dadurch können mit dem vorab trainierten CLIP-Modell gerenderte Bilder gute Ergebnisse beim Zieltext erzielen.
DreamFusion
Verlag:Google
Veröffentlichungszeit:September 2022
Projektadresse:https://dreamfusion3d.github.io/
DreamFusion kann mithilfe eines vortrainierten 2D-Text-zu-Bild-Diffusionsmodells eine Text-zu-3D-Synthese erreichen.
DreamFusion führt einen Verlust basierend auf der Wahrscheinlichkeitsdichtedestillation ein, wodurch das 2D-Diffusionsmodell als Vorgabe für die Optimierung des parametrischen Bildgenerators verwendet werden kann.

Durch Anwenden dieses Verlusts in einem ähnlichen Verfahren wie DeepDream optimiert Dreamfusion ein zufällig initialisiertes 3D-Modell (ein Neural Radiance Field oder NeRF) auf einen relativ geringen Verlust für 2D-Renderings aus zufälligen Winkeln durch Gradientenabstieg.
Dreamfusion erfordert weder 3D-Trainingsdaten noch muss das Bilddiffusionsmodell geändert werden.Die Wirksamkeit des vorab trainierten Bilddiffusionsmodells als Vorabmodell wird demonstriert.
Magic3D
Verlag:NVIDIA
Veröffentlichungszeit:November 2022
Projektadresse:deepimagination.cc/Magic3D/
Magic3D ist ein Tool zur Text-zu-3D-Inhaltserstellung, mit dem hochwertige 3D-Mesh-Modelle erstellt werden können.Mithilfe von Bildaufbereitungstechnologie und textbasierten Eingabeaufforderungsbearbeitungsmethoden bietet Magic3D neue Möglichkeiten zur Steuerung der 3D-Synthese und eröffnet neue Wege für eine Vielzahl kreativer Anwendungen.
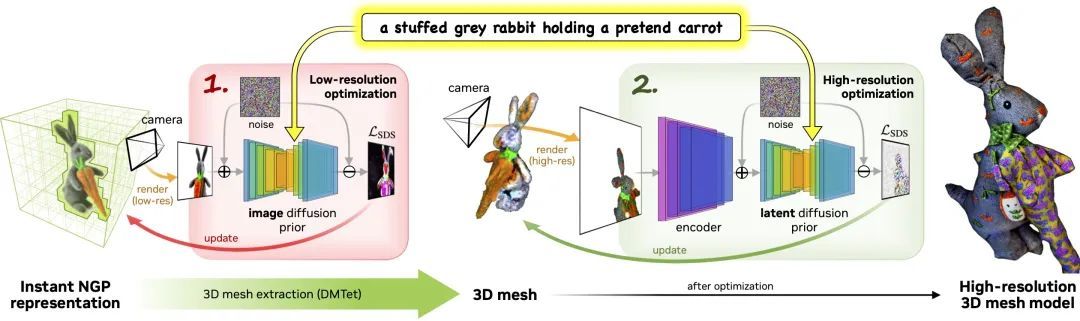
Der Prozess besteht aus zwei Phasen:
Phase 1:Verwenden Sie eine Diffusion mit niedriger Auflösung, bevor Sie ein grobes Modell erhalten, und verwenden Sie ein Hash-Gitter und eine spärliche Beschleunigungsstruktur, um es zu beschleunigen.
Phase 2:Ein aus einer groben neuronalen Darstellung initialisiertes texturiertes Netzmodell wird über einen effizienten differenzierbaren Renderer optimiert, der mit einem hochauflösenden latenten Diffusionsmodell interagiert.
Der technologische Fortschritt muss noch immer Grenzen durchbrechen
Text-zu-3D-KI wird nach und nach veröffentlicht, die textbasierte 3D-Synthese befindet sich jedoch noch in einem frühen Entwicklungsstadium.Es gibt in der Branche keinen allgemein anerkannten Maßstab, anhand dessen entsprechende Aufgaben gerechter bewertet werden könnten.
Point·E ist für die schnelle Text-zu-3D-Synthese von großer Bedeutung.Es verbessert die Verarbeitungseffizienz erheblich und reduziert den Rechenleistungsverbrauch.
Aber es ist unbestreitbar, dassPunkt E unterliegt noch gewissen Einschränkungen.Beispielsweise erfordert die Pipeline ein synthetisches Rendering und die generierte 3D-Punktwolke hat eine niedrige Auflösung, die nicht ausreicht, um feinkörnige Formen oder Texturen zu erfassen.
Was denken Sie über die Zukunft der Text-zu-3D-Synthese? Wie wird die zukünftige Entwicklungstendenz aussehen? Hinterlassen Sie gerne Kommentare zur Diskussion im Kommentarbereich.








