Command Palette
Search for a command to run...
PyTorch 2.0 Ist Veröffentlicht: Kompilieren, Kompilieren Und Kompilieren!

Inhalt im Überblick: Auf der gestern Abend stattgefundenen PyTorch-Konferenz 2022 wurde PyTorch 2.0 offiziell veröffentlicht. Dieser Artikel erläutert die größten Unterschiede zwischen PyTorch 2.0 und 1.x. Schlüsselwörter: PyTorch 2.0 Compiler Machine Learning Dieser Artikel wurde zuerst auf dem offiziellen WeChat-Konto veröffentlicht: HypeAI
Auf der PyTorch-Konferenz 2022 hat PyTorch PyTorch 2.0 offiziell veröffentlicht. Die gesamte Veranstaltung hatte eine sehr hohe „Compiler“-Rate. Im Vergleich zur vorherigen Version 1.x wurden in Version 2.0 „disruptive“ Änderungen vorgenommen.
PyTorch 2.0 hat viele neue Funktionen veröffentlicht, die ausreichen, um die Art und Weise, wie Sie PyTorch verwenden, zu verändern.Es bietet denselben Eager-Modus und dieselbe Benutzererfahrung und fügt gleichzeitig einen Kompilierungsmodus über torch.compile hinzu.Das Modell kann während des Trainings und der Inferenz beschleunigt werden, was eine bessere Leistung und Unterstützung für dynamische Formen und verteilte Modelle bietet.
Dieser Artikel bietet eine detaillierte Einführung in PyTorch 2.0.
Zu lang zum Lesen
- PyTorch 2.0 behält seine ursprünglichen Vorteile bei und unterstützt gleichzeitig die Kompilierung
- torch.compile ist eine optionale Funktion, die die Kompilierung mit nur einer Codezeile ausführen kann
- 4 wichtige Technologien: TorchDynamo, AOTAutograd, PrimTorch und TorchInductor
- Ich habe vor 5 Jahren versucht, es zu kompilieren, aber die Ergebnisse waren nicht zufriedenstellend.
- PyTorch 1.x-Code muss nicht auf 2.0 migriert werden. * Die stabile Version von PyTorch 2.0 wird voraussichtlich im März nächsten Jahres veröffentlicht.
Schnellerer, besserer, kompilierter Support
Auf der PyTorch-Konferenz 2022 gestern Abendtorch.compile wurde offiziell veröffentlicht.Es verbessert die Leistung von PyTorch weiter und beginnt, Teile von PyTorch von C++ zurück nach Python zu migrieren.
Zu den neuesten Technologien in PyTorch 2.0 gehören:
TorchDynamo, AOTAutograd, PrimTorch und TorchInductor.
1. TorchDynamo
Mithilfe von Python Frame Evaluation Hooks können PyTorch-Programme sicher abgerufen werden. Diese wichtige Innovation ist eine Zusammenfassung der Forschungs- und Entwicklungsergebnisse von PyTorch im Bereich der sicheren Grapherfassung der letzten fünf Jahre.
2. AOTAutograd
Überladen Sie die PyTorch-Autograd-Engine als Tracing-Autodiff, um erweiterte Rückwärtstraces zu generieren.
3. PrimTorch
Die über 2000 PyTorch-Operatoren werden in einem geschlossenen Satz von etwa 250 primitiven Operatoren zusammengefasst, und Entwickler können für diese Operatoren ein vollständiges PyTorch-Backend erstellen. PrimTorch vereinfacht das Schreiben von PyTorch-Funktionen oder -Backends erheblich.
4. Fackelinduktor Ein Deep-Learning-Compiler, der schnellen Code für mehrere Beschleuniger und Backends generiert. Für NVIDIA-GPUs verwendet es OpenAI Triton als zentralen Baustein.
TorchDynamo, AOTAutograd, PrimTorch und TorchInductor sind in Python geschrieben.Und die Unterstützung dynamischer Formen (die Möglichkeit, Vektoren unterschiedlicher Größe ohne Neukompilierung zu senden) macht sie flexibel und leicht zu erlernen, was die Einstiegshürde für Entwickler und Anbieter senkt.
Um diese Techniken zu validieren,PyTorch verwendet offiziell 163 Open-Source-Modelle im Bereich des maschinellen Lernens.Dazu gehören Aufgaben wie Bildklassifizierung, Objekterkennung, Bildgenerierung und verschiedene NLP-Aufgaben wie Sprachmodellierung, Fragenbeantwortung, Sequenzklassifizierung, Empfehlungssysteme und bestärkendes Lernen.Diese Benchmarks sind in drei Kategorien unterteilt:
- 46 Modelle von HuggingFace Transformers
- 61 Modelle von TIMM: SoTA PyTorch Image Models Collection von Ross Wightman
- 56 Modelle von TorchBench: Eine Sammlung beliebter Repositories auf GitHub.
Für Open-Source-Modelle,PyTorch hat offiziell keine Änderungen vorgenommen, aber einen torch.compile-Aufruf zur Kapselung hinzugefügt.
Als Nächstes haben die PyTorch-Ingenieure die Geschwindigkeit gemessen und die Genauigkeit dieser Modelle überprüft, da die Beschleunigung vom Datentyp abhängen kann.Daher wurde die offizielle Beschleunigung sowohl bei Float32 als auch bei Automatic Mixed Precision (AMP) gemessen.Da AMP in der Praxis häufiger vorkommt, wird das Testverhältnis auf 0,75 * AMP + 0,25 * float32 festgelegt.
Unter diesen 163 Open-Source-Modellentorch.compile kann auf dem Modell 93% normal ausgeführt werden.Nach dem Ausführen erreichte das Modell eine Verbesserung der Laufgeschwindigkeit um 43% auf der NVIDIA A100-GPU. Bei Float32-Präzision wird die Laufgeschwindigkeit um durchschnittlich 21% erhöht; Unter AMP-Präzision wird die Laufgeschwindigkeit um durchschnittlich 51% erhöht.
Hinweis: Bei GPUs der Desktop-Klasse (wie der NVIDIA 3090) sind die gemessenen Geschwindigkeiten niedriger als bei GPUs der Server-Klasse (wie der A100). Ab sofort unterstützt das Standard-Backend TorchInductor von PyTorch 2.0 bereits CPU und NVIDIA Volta- und Ampere-GPUs, unterstützt derzeit jedoch keine anderen GPUs, xPUs oder älteren NVIDIA-GPUs.
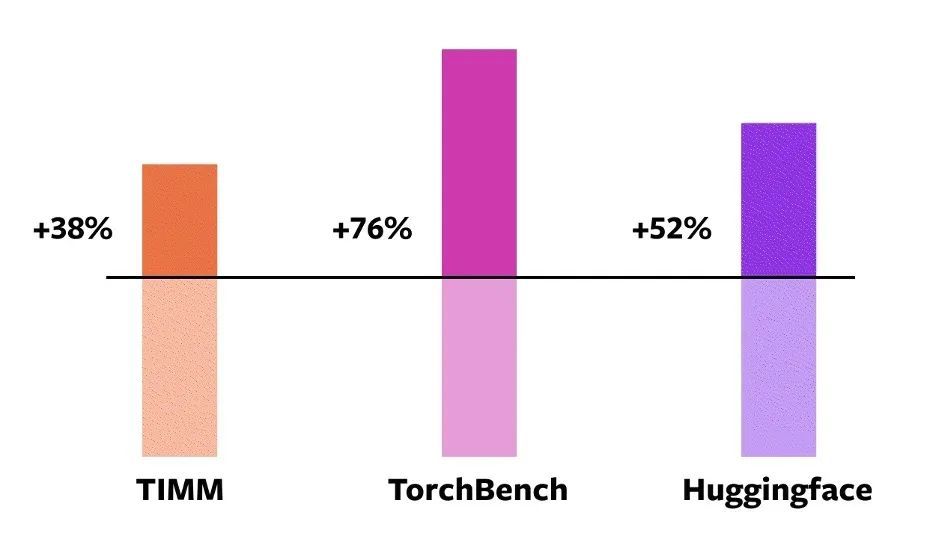 NVIDIA A100 GPU Eager Mode Torch.Compile-Beschleunigung für verschiedene Modelle
NVIDIA A100 GPU Eager Mode Torch.Compile-Beschleunigung für verschiedene Modelle
Probieren Sie torch.compile online aus:Entwickler können es über die nächtliche Binärdatei installieren und ausprobieren. Die stabile Version von PyTorch 2.0 wird voraussichtlich Anfang März 2023 veröffentlicht.
In der PyTorch 2.x-Roadmap werden die Leistung und Skalierbarkeit des kompilierten Modus in Zukunft weiter bereichert und verbessert.
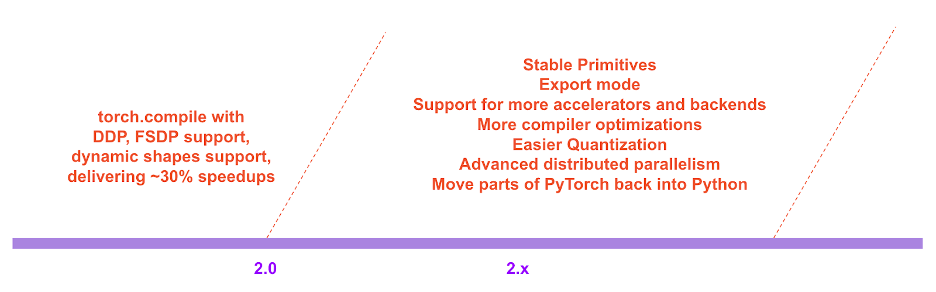 PyTorch 2.x-Roadmap
PyTorch 2.x-Roadmap
Entwicklungshintergrund
Die Entwicklungsphilosophie von PyTorch bestand schon immer darin, Flexibilität und Hackbarkeit an erste Stelle zu setzen und die Leistung an zweite Stelle.Verpflichtet:
1. Leistungsstarke, eifrige Ausführung
2. Pythonisieren Sie kontinuierlich die interne Struktur
3. Gute Abstraktion von Distributed, Autodiff, Datenladen, Beschleunigern usw.
Seit der Einführung von PyTorch im Jahr 2017 haben Hardwarebeschleuniger (wie GPUs) die Rechengeschwindigkeit um etwa das 15-fache und die Speicherzugriffsgeschwindigkeit um etwa das Zweifache erhöht.
Um eine leistungsstarke Eager-Ausführung aufrechtzuerhalten, musste der Großteil des internen Inhalts von PyTorch nach C++ verschoben werden, was die Hackbarkeit von PyTorch verringerte und die Hemmschwelle für Entwickler erhöhte, sich an Code-Beiträgen zu beteiligen.
Vom ersten Tag an waren sich die Verantwortlichen bei PyTorch der Leistungseinschränkungen der Eager-Ausführung bewusst. Im Juli 2017 begannen die Verantwortlichen mit der Entwicklung eines Compilers für PyTorch. Der Compiler muss die Ausführung von PyTorch-Programmen beschleunigen, ohne das PyTorch-Erlebnis zu beeinträchtigen.Das wichtigste Kriterium war die Beibehaltung eines gewissen Maßes an Flexibilität: die Unterstützung dynamischer Formen und dynamischer Programme, die von Entwicklern häufig verwendet werden.

Technische Details zu PyTorch
Seit seiner Einführung wurden mehrere Compilerprojekte in PyTorch erstellt.Diese Compiler können in 3 Kategorien unterteilt werden:
- Graphenerfassung
- Graphenabsenkung
- Graphenkompilierung
Die größte Herausforderung besteht darin, die Graphstruktur zu erfassen.
In den letzten fünf Jahren haben wir torch.jit.trace, TorchScript, FX-Tracing und Lazy Tensors ausprobiert, aber einige davon sind flexibel, aber nicht schnell genug, einige sind schnell genug, aber nicht flexibel, einige sind weder schnell noch flexibel und einige bieten eine schlechte Benutzererfahrung.
Obwohl TorchScript vielversprechend ist,Dies erfordert jedoch viele Code- und Abhängigkeitsänderungen und ist nicht sehr praktikabel.
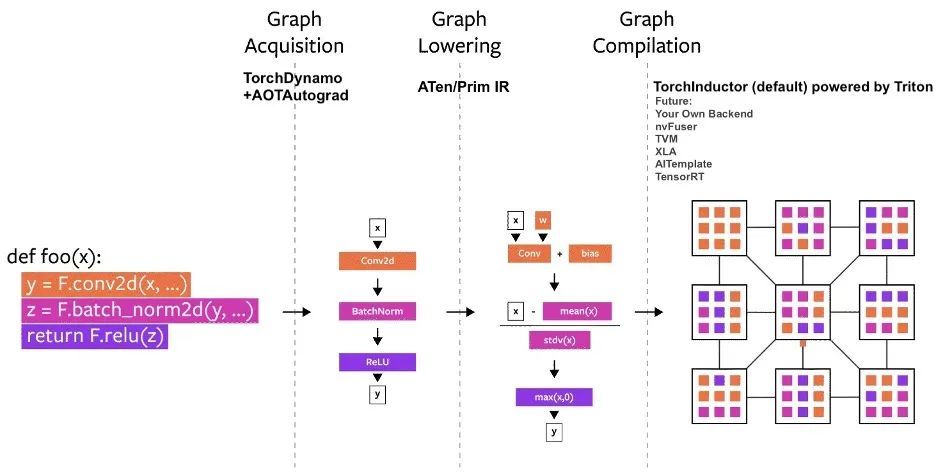 Diagramm des PyTorch-Kompilierungsprozesses
Diagramm des PyTorch-Kompilierungsprozesses
TorchDynamo: Graphstruktur zuverlässig und schnell ermitteln
TorchDynamo verwendet eine in PEP-0523 eingeführte CPython-Funktion namens Frame Evaluation API. Der Beamte wählte einen datengesteuerten Ansatz, um die Wirksamkeit bei Graph Capture zu überprüfen, und verwendete dabei mehr als 7.000 in PyTorch geschriebene Github-Projekte als Validierungssatz.
Experimente zeigen, dassTorchDynamo kann die Graphstruktur in 99%-Zeit korrekt und sicher abrufen und der Overhead ist vernachlässigbar.Weil keine Änderung des Originalcodes erforderlich ist.
TorchInductor: Schnellere Codegenerierung mit Define-by-Run-IR
Immer mehr Entwickler schreiben leistungsstarke benutzerdefinierte Kernel.Kann die Triton-Sprache verwenden.Darüber hinaus hofft der Beamte, dass das neue Compiler-Backend von PyTorch 2.0 ähnliche Abstraktionen wie PyTorch Eager verwenden und über eine ausreichende Gesamtleistung verfügen wird, um eine breite Palette von Funktionen in PyTorch zu unterstützen.
TorchInductor verwendet Pythonic Define-by-Run-Loop-Level-IR, um PyTorch-Modelle automatisch auf generierten Triton-Code auf der GPU und C++/OpenMP auf der CPU abzubilden.
Die IR auf Kernschleifenebene von TorchInductor enthält nur etwa 50 Operatoren und ist in Python implementiert, was sie äußerst hackbar und erweiterbar macht.
AOTAutograd: Wiederverwendung von Autograd für Ahead-of-Time-Diagramme
Um das Training zu beschleunigen, erfasst PyTorch 2.0 nicht nur Code auf Benutzerebene, sondern auch den Backpropagation-Algorithmus. Noch besser wäre es, wenn das bewährte PyTorch-Autograd-System genutzt werden könnte.
AOTAutograd verwendet den PyTorch torch_dispatch-Erweiterungsmechanismus, um die Autograd-Engine zu verfolgen.Ermöglicht Entwicklern, Rückwärtsdurchläufe „vorzeitig“ zu erfassen, sodass Entwickler TorchInductor verwenden können, um Vorwärts- und Rückwärtsdurchläufe zu beschleunigen.
PrimTorch: Stabile primitive Operatoren
Das Schreiben eines Backends für PyTorch ist nicht einfach. Torch verfügt über mehr als 1.200 Operatoren, und wenn Sie die verschiedenen Überlastungen jedes Operators berücksichtigen, beträgt die Zahl sogar mehr als 2.000.
 Übersicht über die Klassifizierung von über 2000 PyTorch-Operatoren
Übersicht über die Klassifizierung von über 2000 PyTorch-Operatoren
Daher wird das Schreiben von Backend- oder Querschnittsfunktionen zu einer zeitaufwändigen Aufgabe. PrimTorch ist bestrebt, einen kleineren und stabileren Satz von Operatoren zu definieren. PyTorch-Programme können durchgängig auf diese Operatorsätze reduziert werden. Das offizielle Ziel besteht darin, zwei Operatorsätze zu definieren:
* Prim Ops enthält etwa 250 Operatoren auf relativ niedrigem Niveau. Da diese Operatoren eine ausreichend niedrige Ebene aufweisen, eignen sie sich besser für Compiler. Entwickler müssen diese Operatoren verschmelzen, um eine gute Leistung zu erzielen.
* ATen ops enthält etwa 750 kanonische Operatoren, die für die direkte Ausgabe geeignet sind. Diese Operatoren eignen sich für Backends, die auf ATen-Ebene integriert wurden, oder für Backends, die nicht kompiliert wurden, um die Leistung des zugrunde liegenden Operatorsatzes wiederherzustellen (z. B. Prim Ops).
Häufig gestellte Fragen
1. Wie installiere ich PyTorch 2.0? Welche zusätzlichen Voraussetzungen gibt es?
Installieren Sie die neuesten Nightly-Versionen:
CUDA 11.7
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117CUDA 11.6
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116CPU
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu2. Ist der PyTorch 2.0-Code abwärtskompatibel mit 1.x?
Ja, 2.0 erfordert keine Änderung des PyTorch-Workflows, nur eine Codezeile Modell = Torch.Kompilieren(Modell)Sie können Ihr Modell dann für die Verwendung des 2.0-Stacks optimieren und es reibungslos mit anderem PyTorch-Code ausführen. Diese Option ist nicht obligatorisch und Entwickler können weiterhin frühere Versionen verwenden.
3. Ist PyTorch 2.0 standardmäßig aktiviert?
Nein, 2.0 muss in Ihrem PyTorch-Code explizit aktiviert werden, indem Sie das Modell mit einem einzigen Funktionsaufruf optimieren.
4. Wie migriere ich PT1.X-Code zu PT2.0?
Für den vorherigen Code ist keine Migration erforderlich. Wenn Sie die neue Funktion des Kompilierungsmodus verwenden möchten, die in 2.0 eingeführt wurde, können Sie das Modell zunächst mit einer Codezeile optimieren:Modell = Torch.Kompilieren(Modell).
Die Geschwindigkeitsverbesserung spiegelt sich hauptsächlich im Trainingsprozess wider. Wenn das Modell schneller als im Eager-Modus läuft, bedeutet dies, dass es für Inferenzen verwendet werden kann.
import torch
def train(model, dataloader):
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
def infer(model, input):
model = torch.compile(model)
return model(\*\*input)5. Welche Funktionen sind in PyTorch 2.0 veraltet?
Derzeit ist PyTorch 2.0 noch nicht stabil und liegt noch in der Nightly-Version vor. Die Unterstützung für dynamische Formen in torch.compile befindet sich noch in der Anfangsphase und wird erst mit der stabilen Version 2.0 im März 2023 empfohlen.
Das heißt, selbst bei statisch geformten Workloads werden sie immer noch im kompilierten Modus erstellt und es können einige Fehler auftreten. Deaktivieren Sie für den Teil Ihres Codes, der abstürzt, den kompilierten Modus und melden Sie ein Problem.
Portal zum Einreichen von Problemen:https://github.com/pytorch/pytorch/issues
Das Obige ist eine detaillierte Einführung in PyTorch 2.0. Wir werden die Einführung „Erste Schritte mit PyTorch 2.0“ in Zukunft fertigstellen. Folgen Sie uns bitte weiterhin!
Sie können auch auf WeChat nach Hyperai01 suchen und an der Gruppendiskussion zur PyTorch-Technologieentwicklung mit Neural Star teilnehmen.








