Command Palette
Search for a command to run...
PyTorchs Neue Bibliothek TorchMultimodal-Nutzungsanweisungen: Erweitern Sie Das Multimodale Allgemeine Modell FLAVA Auf 10 Milliarden Parameter

Im vorherigen Artikel haben wir TorchMultimodal vorgestellt. Heute werden wir anhand eines konkreten Falls demonstrieren, wie das multimodale Basismodell in der TorchMultimodal-Bibliothek mit Unterstützung der Torch Distributed-Technologie erweitert werden kann.
Große Modelle haben sich in den letzten Jahren zu einem Forschungsgebiet entwickelt, das große Aufmerksamkeit auf sich gezogen hat. Am Beispiel der Verarbeitung natürlicher Sprache haben sich Sprachmodelle von Hunderten Millionen Parametern (BERT) auf Hunderte Milliarden Parameter (GPT-3) entwickelt und spielen eine bedeutende Rolle bei der Verbesserung der Leistung nachgelagerter Aufgaben.
In der Branche wurde intensiv an der Skalierung umfangreicher Sprachmodelle geforscht. Ein ähnlicher Trend lässt sich im Bereich Vision beobachten, wo immer mehr Entwickler auf Transformer-basierte Modelle (wie Vision Transformer und Masked Auto Encoders) zurückgreifen.
Offensichtlich wurde aufgrund der Entwicklung groß angelegter Modelle die Forschung an einzelnen Modalitäten (wie Text, Bild, Video) kontinuierlich verbessert und die Frameworks wurden auch schnell an größere Modelle angepasst.
Gleichzeitig hat die Multimodalität mit der Anwendung von Aufgaben in der realen Welt wie Bild-Text-Abruf, visuellem Beantworten von Fragen, visuellem Dialog und Text-zu-Bild-Generierung zunehmend an Aufmerksamkeit gewonnen.
Der nächste Schritt besteht darin, groß angelegte multimodale Modelle zu trainieren. Es gab auch einige Bemühungen in diesem Bereich, wie beispielsweise CLIP von OpenAI, Parti von Google und CM3 von Meta.
Dieser Artikel zeigt anhand einer Fallstudie, wie FLAVA mithilfe der PyTorch Distributed-Technologie auf 10 Milliarden Parameter skaliert werden kann.
Weiterführende Literatur:HyperAI: Ein Blick auf die von Meta verwendeten FX-Tools: Optimierung von PyTorch-Modellen mit Graphtransformation
bearbeiten
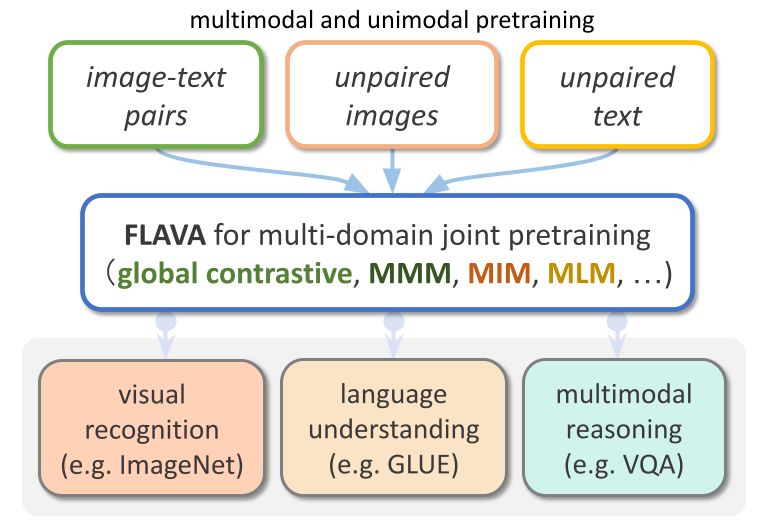
FLAVA ist ein auf Bild- und Sprachverarbeitung basierendes Modell, das in TorchMultimodal verfügbar ist
FLAVA hat sowohl bei ein- als auch bei mehrmodalen Benchmarks herausragende Leistungsvorteile gezeigt. Dieser Artikel zeigt anhand relevanter Codebeispiele, wie FLAVA erweitert wird.
Einzelheiten finden Sie im Code:
multimodal/Beispiele/flava/native bei main · facebookresearch/multimodal · GitHub
Erweiterte FLAVA-Übersicht
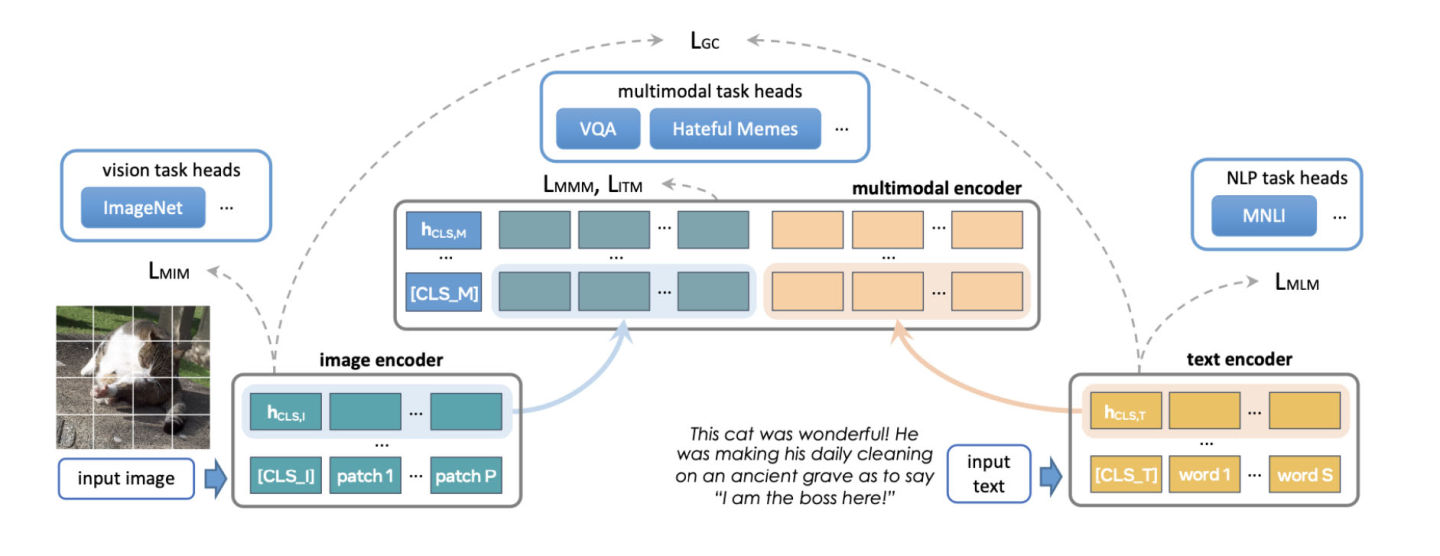
FLAVA ist ein grundlegendes multimodales Modell, das aus transformatorbasierten Bild- und Textcodierern und einem transformatorbasierten multimodalen Fusionsmodul besteht.
FLAVA ist sowohl auf unimodalen als auch auf multimodalen Daten mit unterschiedlichen Verlusten vortrainiert, darunter maskierte Sprach-, Bild- und multimodale Modellverluste, die erfordern, dass das Modell die ursprüngliche Eingabe aus ihrem Kontext rekonstruiert (selbstüberwachtes Lernen).
Darüber hinaus verwendet es einen Bild-Text-Matching-Verlust, einschließlich positiver und negativer Beispiele ausgerichteter Bild-Text-Paare, und einen Kontrastverlust im CLIP-Stil.
Zusätzlich zu multimodalen Aufgaben (wie etwa dem Abrufen von Bild-Text) zeigt FLAVA auch bei unimodalen Benchmarks (wie etwa GLUE-Aufgaben in NLP und visueller Bildklassifizierung) eine hervorragende Leistung.
bearbeiten
Das ursprüngliche FLAVA-Modell hatte etwa 350 Millionen Parameter und verwendete die ViT-B16-Konfiguration sowohl für Bild- als auch für Text-Encoder.
Referenz:https://arxiv.org/pdf/2010.11929.pdf
Der multimodale Fusionstransformator verwendet denselben singlemodalen Encoder, die Anzahl der Schichten ist jedoch nur halb so groß wie beim vorherigen. Das PyTorch-Entwicklungsteam hat untersucht, wie die Größe des Encoders erhöht werden kann, um größere ViT-Varianten unterzubringen.
Ein weiterer Aspekt der Skalierung von FLAVA ist die Erhöhung der Batchgröße. FLAVA nutzt geschickt den negativen Kontrastverlust im Batch aus, der normalerweise nur in einer großen Anzahl von Größen verfügbar ist.
Referenz:https://openreview.net/pdfid=U2exBrf_SJh
Im Allgemeinen wird die maximale Trainingseffizienz oder der maximale Durchsatz erreicht, wenn nahe an der größtmöglichen Batchgröße gearbeitet wird, die durch die Menge des verfügbaren GPU-Speichers bestimmt wird (siehe Abschnitt „Experimentell“).
Die folgende Tabelle zeigt die Ausgabe verschiedener Modellkonfigurationen, wobei wir experimentell die maximale Batchgröße ermittelt haben, die für jede Konfiguration in den Speicher passt.

bearbeiten
Optimierungsübersicht
PyTorch bietet mehrere native Techniken zum effizienten Skalieren von Modellen. In den folgenden Abschnitten werden die drei Ansätze im Detail beschrieben und gezeigt, wie diese Techniken angewendet werden, um das FLAVA-Modell auf 10 Milliarden Parameter zu skalieren.
Verteilte Datenparallelität
Ein häufiger Ausgangspunkt für verteiltes Training ist die Datenparallelität. Durch Datenparallelität wird das Modell zwischen GPUs repliziert und der Datensatz partitioniert. Verschiedene GPUs verarbeiten unterschiedliche Datenpartitionen parallel und synchronisieren ihre Gradienten (über alle Reduzierungen), bevor die Modellgewichte aktualisiert werden.
Die folgende Abbildung zeigt den Prozess der parallelen Verarbeitung von Daten (Vorwärtsiteration, Rückwärtsiteration und Gewichtsaktualisierungsschritt):

bearbeiten
Um Datenparallelität zu erreichen, bietet PyTorch eine native API, DistributedDataParallel (DDP), die wie unten gezeigt als Modul-Wrapper verwendet werden kann:
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.org/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])Vollständig fragmentierte Datenparallelität
Die GPU-Speichernutzung einer Trainingsanwendung kann grob in Modelleingabe, Zwischenaktivierungsspeicher (erforderlich für Gradientenberechnungen), Modellparameter, Gradienten und Optimiererstatus unterteilt werden.
Bei der Erweiterung eines Modells werden diese Elemente normalerweise zusammengefügt. Wenn einer einzelnen GPU der Speicher ausgeht, kann die Skalierung des Modells mit DDP dazu führen, dass auch ihr der Speicher ausgeht, da es Parameter, Gradienten und Optimiererzustände auf allen GPUs repliziert.
Um dieses Kopieren zu reduzieren und GPU-Speicher zu sparen, können die Modellparameter, Gradienten und der Optimiererstatus auf alle GPUs aufgeteilt werden, wobei jede GPU nur einen Shard verwaltet. Diese Methode bezieht sich auf das von Microsoft vorgeschlagene ZeRO-3.
Eine PyTorch-native Implementierung dieses Ansatzes ist als FullyShardedDataParallel (FSDP)-API verfügbar, die als Beta-Funktion in PyTorch 1.12 veröffentlicht wurde.
Während der Vorwärts- und Rückwärtsiterationen des Moduls integriert FSDP die Modellparameter (unter Verwendung von All-Gather) entsprechend den Rechenanforderungen und teilt sie nach der Berechnung erneut in Shards auf. Es verwendet ein Scatter-Reduce-Ensemble zur Synchronisierung von Gradienten, um sicherzustellen, dass die Gradienten der Shards global gemittelt werden. Die Vorwärts- und Rückwärtsiterationsprozesse des Modells in FSDP sind wie folgt:

bearbeiten
Wenn Sie FSDP verwenden, müssen Sie die Untermodule des Modells mit einer API kapseln, um zu steuern, wann ein bestimmtes Untermodul geteilt wird oder nicht. FSDP bietet eine sofort einsatzbereite Auto-Wrapping-API, mehrere Wrapping-Richtlinien und die Möglichkeit, Richtlinien zu schreiben.
Das folgende Beispiel zeigt, wie ein FLAVA-Modell mit FSDP umschlossen wird. Geben Sie die automatische Umbruchrichtlinie an: transformer_auto_wrap_policy . Dadurch werden eine einzelne Transformatorschicht (TransformerEncoderLayer), ein Bildtransformator (ImageTransformer), ein Textcodierer (BERTTextEncoder) und ein multimodaler Codierer (FLAVATransformerWithoutEmbeddings) in einer einzigen FSDP-Einheit gekapselt.
Dabei wird ein rekursiver Kapselungsansatz für eine effiziente Speicherverwaltung verwendet. Beispielsweise werden nach Abschluss der Vorwärts- oder Rückwärtsiteration einer einzelnen Transformatorschicht Parameter gelöscht, wodurch Speicher freigegeben und die Spitzenspeichernutzung reduziert wird.
FSDP bietet auch einige konfigurierbare Optionen zum Optimieren der Leistung der Anwendung, wie in diesem Beispiel die Verwendung von limit_all_gathers. Es verhindert die vorzeitige Erfassung aller Modellparameter und reduziert den Speicherdruck der Anwendung.
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)Aktivierungs-Checkpointing
Wie oben erwähnt, wirken sich Zwischenaktivierungsspeicher, Modellparameter, Gradienten und der Optimiererstatus auf die GPU-Speichernutzung aus. FSDP kann den durch die letzten drei verursachten Speicherverbrauch reduzieren, kann jedoch den durch die Aktivierung verbrauchten Speicher nicht reduzieren. Der von Aktivierungen verwendete Speicher steigt mit der Batchgröße oder der Anzahl der verborgenen Ebenen.
Durch Aktivierungs-Checkpointing wird die Speichernutzung reduziert, indem Aktivierungen während Rückwärtsiterationen neu berechnet werden, anstatt sie im Speicher des spezifischen Checkpoint-Moduls zu behalten.
Durch die Anwendung von Aktivierungs-Checkpointing auf das 2,7 Milliarden Parameter umfassende Modell konnte beispielsweise der maximale aktive Speicher nach einer Vorwärtsiteration um den Faktor 4 reduziert werden.
PyTorch bietet eine Wrapper-basierte Aktivierungs-Checkpointing-API. Und mit checkpoint_wrapper können Benutzer ein einzelnes Modul mit Check umschließen, und mit apply_activation_checkpointing können Benutzer eine Strategie angeben, um das Modul mit Checkpointing im gesamten Modul zu umschließen.
Diese beiden APIs können auf die meisten Modelle angewendet werden, da sie keine Änderungen am Modelldefinitionscode erfordern.
Wenn Sie jedoch eine feinere Kontrolle über die mit Checkpoints versehenen Segmente benötigen, z. B. das Setzen von Checkpoints für bestimmte Funktionen innerhalb eines Moduls, können Sie die API torch.utils.checkpoint verwenden, was eine Änderung des Modellcodes erfordert.
Die Anwendung des Aktivierungs-Checkpointing-Wrappers auf eine einzelne FLAVA-Transformatorschicht (bezeichnet als TransformerEncoderLayer) wird unten dargestellt:
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
Wie oben gezeigt, ermöglicht das Umhüllen der FLAVA-Transformatorschicht mit Aktivierungs-Checkpointing und des Gesamtmodells mit FSDP die Skalierung von FLAVA auf 10 Milliarden Parameter.
Experiment
Wir werden die Auswirkungen der oben genannten Optimierungsmethoden auf die Systemleistung weiter untersuchen.
Hintergrund:
- Verwendung eines einzelnen Knotens mit 8 A100 40 GB GPUs
- Führen Sie 1000 Iterationen vor dem Training aus
- PyTorch-Training mit gemischter Genauigkeit unter Verwendung des Datentyps bfloat16 (automatische gemischte Genauigkeit)
- Aktivieren Sie das TensorFloat32-Format, um die Matmul-Leistung auf A100 zu verbessern
- Definieren Sie den Durchsatz als die durchschnittliche Anzahl der pro Sekunde verarbeiteten Elemente (ignorieren Sie die ersten 100 Iterationen bei der Messung des Durchsatzes).
- Die Konvergenz der Ausbildung und ihre Auswirkungen auf nachgelagerte Aufgabenindikatoren werden als neue Richtung für die zukünftige Forschung dienen
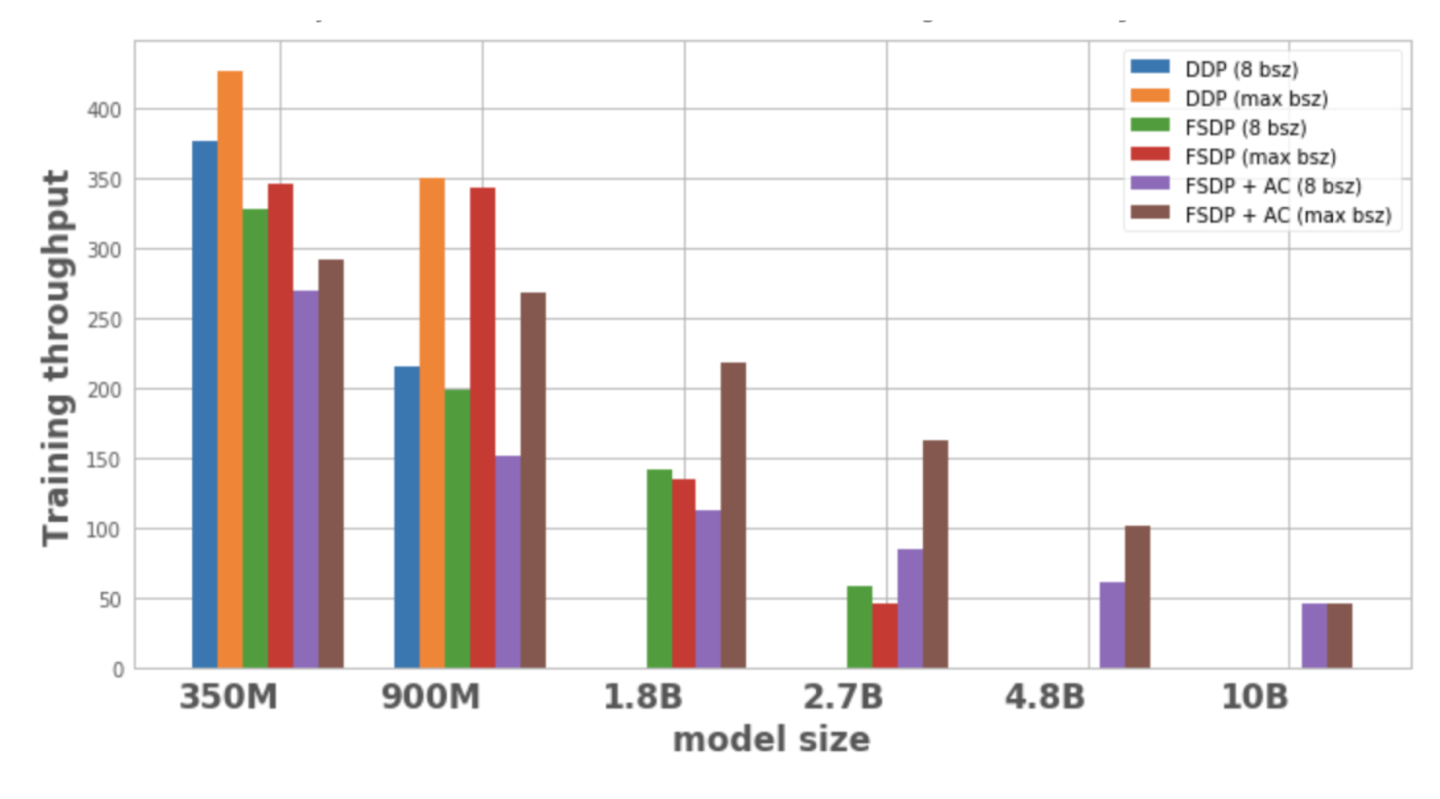
Abbildung 1 zeigt den Durchsatz für jede Modellkonfiguration und -optimierung mit einer lokalen Batchgröße von 8, der maximal möglichen Batchgröße auf einem Knoten. Die optimierte Modellvariante weist keine Datenpunkte auf, was darauf hinweist, dass das Modell nicht auf einem einzelnen Knoten trainiert werden kann.
bearbeiten
Abbildung 1: Trainingsdurchsatz unter verschiedenen Konfigurationen
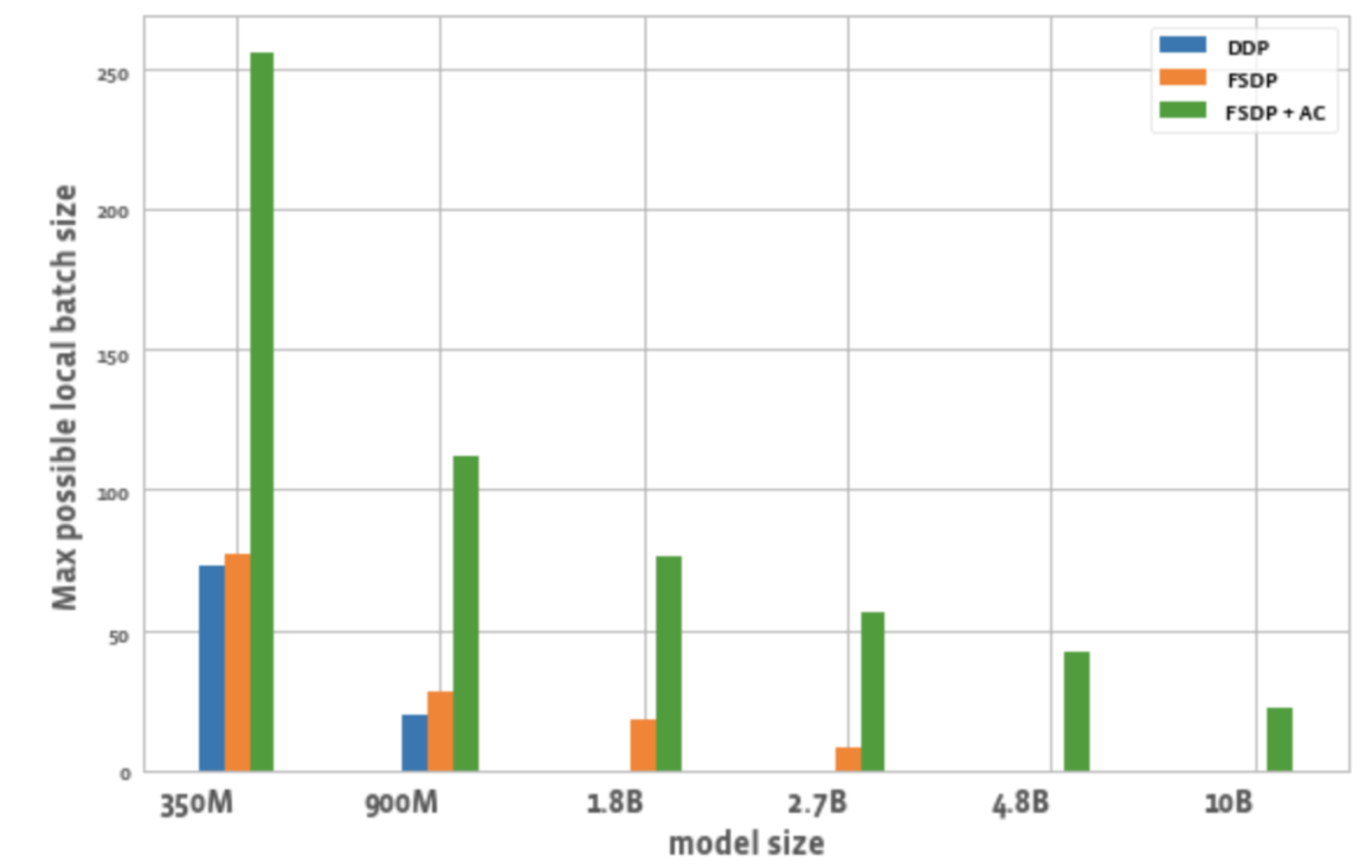
Abbildung 2 zeigt die maximal mögliche Batchgröße für alle GPUs in jeder Optimierung.
bearbeiten
Abbildung 2: Maximal mögliche lokale Batchgröße bei verschiedenen Konfigurationen
Daraus können wir Folgendes ableiten:
1. Erweitern Sie die Modellgröße:
DDP kann nur 350M- und 900M-Modelle auf einem Knoten unterbringen. Durch die Verwendung von FSDP wird Speicher gespart, sodass es möglich ist, Modelle zu trainieren, die dreimal größer sind als DDP (d. h. 1,8 B- und 2,7 B-Varianten). Durch die Kombination von Aktivierungs-Checkpointing (AC) mit FSDP können größere Modelle trainiert werden, die etwa zehnmal größer sind als DDP (wie die Varianten 4,8B und 10B).
2. Durchsatz:
– Bei kleineren Modellen ist der Durchsatz von DDP bei einer Batchgröße von 8 etwas höher oder gleich dem von FSDP, was durch die zusätzliche Kommunikation erklärt werden kann, die FSDP erfordert. Die Kombination aus FSDP und AC hat den niedrigsten Durchsatz. Dies liegt daran, dass AC den mit einem Checkpoint versehenen Vorwärtsiterationskanal während des Rückwärtsiterationsprozesses erneut ausführt und dabei zusätzliche Berechnungen opfert, um Speicher zu sparen. Beim 2.7B-Modell weist FSDP + AC jedoch tatsächlich einen höheren Durchsatz auf als FSDP allein. Dies liegt daran, dass das 2,7-B-Modell mit FSDP selbst bei einer Batchgröße von 8 nahe an der Speichergrenze liegt und einen CUDA-Malloc-Wiederholungsversuch auslöst, der das Training verlangsamt. AC trägt dazu bei, den Speicherdruck zu reduzieren, der dazu führt, dass kein erneuter Versuch unternommen wird.
– Bei DDP und FSDP + AC steigt der Durchsatz des Modells mit zunehmender Batchgröße. Gleiches gilt für die kleineren Varianten von FSDP. Bei den Parametermodellen 1,8 B und 2,7 B verringert sich der Durchsatz jedoch, wenn die Batchgröße zunimmt. Ein möglicher Grund ist, dass die CUDA-Speicherverwaltung von PyTorch bei Speichergrenzen möglicherweise cudaMalloc-Aufrufe wiederholen oder eine aufwändige Defragmentierung durchführen muss, um freie Speicherblöcke zur Bewältigung des Speicherbedarfs der Arbeitslast zu finden, was zu einem langsameren Training führen kann.
– Bei großen Modellen (1,8 B, 2,7 B, 4,8 B), die nur mit FSDP trainiert werden können, ist die höchste Durchsatzeinstellung die Skalierung auf die größte Batchgröße mit FSDP+AC. Bei 10B lässt sich beobachten, dass der Durchsatz bei kleinen und maximalen Batchgrößen nahezu gleich ist. Dies liegt daran, dass AC zu einem erhöhten Rechenaufwand führt und die maximale Batchgröße aufgrund der Ausführung unter CUDA-Speichergrenzen zu teuren Defragmentierungsvorgängen führen kann. Bei diesen großen Modellen gleicht die Erhöhung der Batchgröße diesen Mehraufwand jedoch mehr als aus.
3. Losgröße:
Im Vergleich zu DDP können mit FSDP allein etwas höhere Chargengrößen erreicht werden. Beim 350M-Parametermodell kann durch die Verwendung von FSDP+AC eine dreimal höhere Batchgröße als bei DDP erreicht werden, und beim 900M-Parametermodell kann eine 5,5-mal höhere Batchgröße erreicht werden. Selbst bei 10 B beträgt die maximale Batchgröße etwa 20, was ziemlich gut ist. FSDP+AC kann grundsätzlich eine größere globale Batchgröße mit weniger GPUs erreichen, was besonders für kontrastive Lernaufgaben effektiv ist.
abschließend
Mit der Entwicklung multimodaler Basismodelle werden die Skalierung von Modellparametern und effizientes Training zu einem Schlüsselbereich. Das PyTorch-Ökosystem zielt darauf ab, das Training und die Skalierung multimodaler Modelle durch die Bereitstellung verschiedener Tools zu beschleunigen.
In Zukunft wird PyTorch Unterstützung für andere Modelltypen hinzufügen, beispielsweise multimodale generative Modelle, und die Automatisierung verwandter Technologien verbessern. Herzlich willkommen an alle, die weiterhin dem offiziellen Konto der PyTorch-Entwickler-Community folgen möchten. Sie können auch den QR-Code scannen und „PyTorch“ notieren, um der PyTorch-Community beizutreten.

Offizieller PyTorch-Blog, Tutorials
Neueste Entwicklungen und Best Practices
Scannen Sie den QR-Code, um der Diskussionsgruppe beizutreten








