Command Palette
Search for a command to run...
Tippfehlerkorrektur | Stellen Sie 1 Modell Zur Rechtschreibkorrektur Für Chinesischen Text Bereit
Inhalt auf einen Blick: Eine Art von Fehlern in chinesischen Texten sind Rechtschreibfehler. Dieser Artikel ist ein Modellbereitstellungstutorial zur Implementierung der Fehlerkorrektur in chinesischem Text mithilfe der BART-Vortrainingsmethode.
Schlüsselwörter: BART, chinesische Rechtschreibkorrektur, NLP
Dieser Artikel wurde zuerst auf dem offiziellen WeChat-Konto HyperAI veröffentlicht.
3 Haupthindernisse für Fehler in chinesischen Texten: Rechtschreibung, Grammatik und Semantik
Die Fehlerkorrektur chinesischer Texte ist ein wichtiger Zweig im aktuellen Bereich der natürlichen Sprachverarbeitung, dessen Ziel darin besteht, Fehler in chinesischen Texten zu erkennen und zu korrigieren.Zu den häufigsten Fehlern in chinesischen Texten zählen Rechtschreibfehler, Grammatikfehler und semantische Fehler.
1. Rechtschreibfehler:
Bezieht sich auf die falsche Verwendung von Wörtern oder Ausdrücken aufgrund von Eingabemethoden, Spracherkennungssoftware usw., die sich hauptsächlich in der falschen Verwendung von Homophonen, ähnlichen Zeichen, gemischten Lauten usw. äußert, wie z. B. „天气晴郎 – 天气晴“ und „时侯 – 当时“.
2. Syntaxfehler:
Bezieht sich auf fehlende, redundante, ungeordnete oder falsche Wortzusammenstellungen aufgrund von Eingabemethoden, nachlässiger Handschrift, ungeordneter OCR-Erkennung usw., wie z. B. „Bescheidenheit bringt Menschen voran – Bescheidenheit bringt Menschen voran.“
3. Semantischer Fehler:
Wissens- und Logikfehler, die durch mangelndes Verständnis bestimmter Kenntnisse oder mangelnde Fähigkeiten zur Sprachorganisation verursacht werden, wie z. B. „Ein Jahr hat 3 Quartale – ein Jahr hat 4 Quartale“.
In diesem Artikel verwenden wir die häufigsten Rechtschreibfehler als Beispiele.Zeigen Sie, wie Sie mithilfe des BART-Modells ein chinesisches Textfehlerkorrekturmodell bereitstellen.
Um das Tutorial direkt auszuführen, besuchen Sie bitte:
BART: Ein SOTA-Modell, das die Stärken vieler nutzt
BART steht für Bidirectional and Autoregressive Transformers.Es handelt sich um einen Rauschunterdrückungs-Autoencoder, der für das Vortraining von seq2seq-Modellen entwickelt wurde. Geeignet für Aufgaben zur natürlichen Sprachgenerierung, Übersetzung und zum Verstehen, vorgeschlagen von Meta (ehemals Facebook) im Jahr 2019.
Weitere Einzelheiten finden Sie unter:
https://arxiv.org/pdf/1910.13461.pdf
Das BART-Modell nutzt die Vorteile von BERT und GPT und verwendet die Standard-Transformer-Struktur als Grundlage:
- Decodermodulreferenz GPT: Ersetzen Sie die ReLU-Aktivierungsfunktion durch die GeLU-Aktivierungsfunktion
- Das Encodermodul unterscheidet sich von BERT: Das Feedforward-Neuralnetzwerkmodul wurde aufgegeben und die Modellparameter wurden vereinfacht.
- Der Codec-Verbindungsteil bezieht sich auf Transformer: Jede Schicht des Decoders muss Cross-Attention-Berechnungen für die Ausgabeinformationen der letzten Schicht des Encoders durchführen (d. h. den Encoder-Decoder-Aufmerksamkeitsmechanismus).

In diesem TutorialWir verwenden das Modell nlp_bart_text-error-correction_chinese für die Modellbereitstellung.
Weitere Informationen finden Sie unter:
Tutorialdetails: Erstellen einer Online-Textkorrektur-Demo
Umgebungsvorbereitung
Führen Sie den folgenden Befehl im Jupyter-Terminal aus, um Abhängigkeiten zu installieren:
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install fairseqModell-Download
Führen Sie den folgenden Befehl im Terminal aus, um das Modell herunterzuladen:
git clone http://www.modelscope.cn/damo/nlp_bart_text-error-correction_chinese.gitDas Herunterladen des Modells dauert lange. Das Modell wurde in diesem Container heruntergeladen und kann direkt verwendet werden. nlp_bart_text-error-correction_chinese Verzeichnis.
Schnelle Verwendung
Modellbereitstellung
Servieren Service Schreiben
schreiben predictor.py dokumentieren:
- Abhängige Bibliotheken importieren: Zusätzlich zu den im Unternehmen verwendeten Bibliotheken müssen Sie sich zusätzlich auf OpenBayes-Serving verlassen.
import openbayes_serving as serv
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks- Prädiktorklasse: Keine Notwendigkeit, andere Klassen zu erben, zumindest bieten init Und Schnittstellen vorhersagen.
- existieren
__init__Geben Sie den Modellpfad im Lademodell an - existieren
predictFühren Sie eine Inferenz durch und geben Sie das Ergebnis zurück
class Predictor:
def __init__(self):
self.model_path = './nlp_bart_text-error-correction_chinese'
self.corrector = pipeline(Tasks.text_error_correction, model=self.model_path)
def predict(self, json):
text = json["input"].lower()
result = self.corrector(text)
return result- Ausführen: Starten Sie den Dienst
if __name__ == '__main__':
serv.run(Predictor)prüfen
Im Terminal ausführen python predictor.pyFühren Sie nach dem erfolgreichen Start des Dienstes den folgenden Code zum Testen in diesem Notebook aus.
Hinweis: Wenn beim Testen in einem Container die Flask-Version höher als 2.1 ist, können doppelte Registrierungsfehler auftreten. Sie können es ausführen, indem Sie die Version verringern.
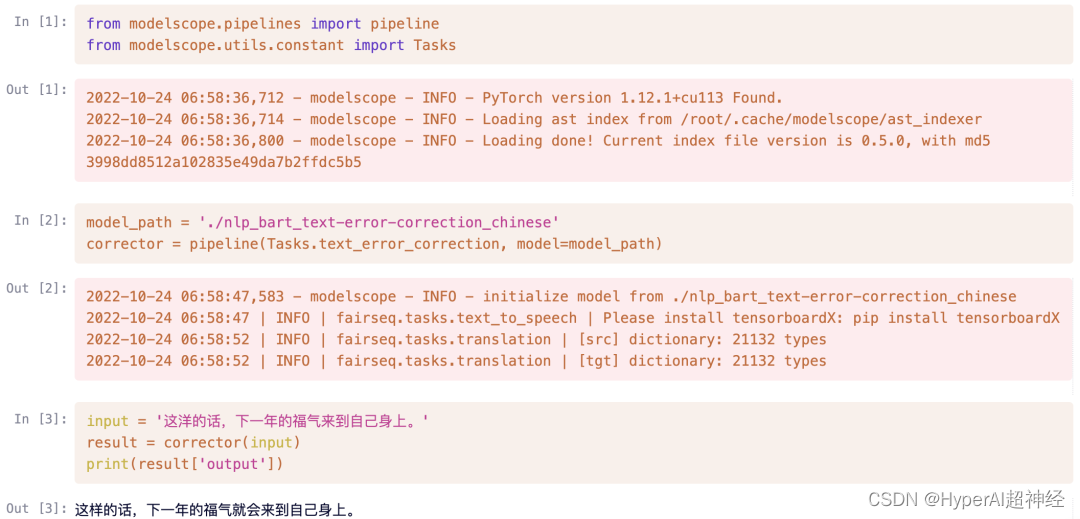
import requests
text = {"input": "这洋的话,下一年的福气来到自己身上。"}
result = requests.post('http://localhost:8080', json=text)
result.json()
{'output': '这样的话,下一年的福气就会来到自己身上。'}Zusätzlich zum lokalen Zugriff auf die Adresse http://localhost:8080,Sie können es auch über eine extern zugängliche URL testen, die im Terminal angezeigt wird.

Hinweis: Für verschiedene OpenBayes-Rechenleistungscontainer ist die extern zugängliche URL unterschiedlich. Die direkte Verwendung des Links in diesem Tutorial ist ungültig. Sie müssen es durch den im Terminal angezeigten Link ersetzen..
result = requests.post('https://openbayes.com/jobs-auxiliary/open-tutorials/t23g93jjm95d', json=text)
result.json()einsetzen
Nachdem der Test erfolgreich war, stoppen Sie den Computing-Container und warten Sie, bis die Datensynchronisierung abgeschlossen ist.
Klicken Sie unter „Computing Container – Model Deployment“ auf „Create New Deployment“, wählen Sie dasselbe Image aus, das in der Entwicklung verwendet wurde, binden Sie diesen Computing Container ein und klicken Sie auf „Deploy“.Sie können Online-Tests durchführen.
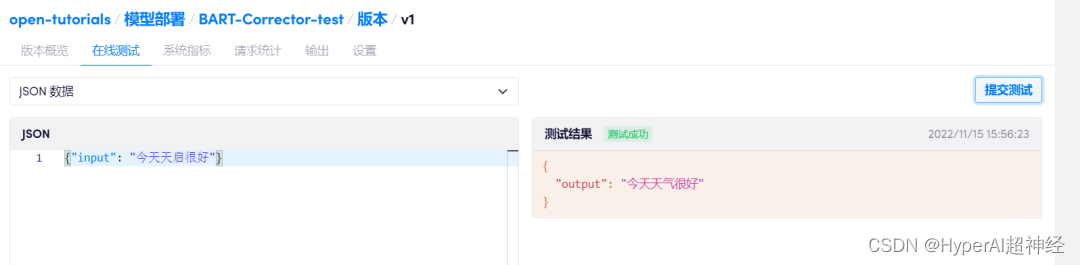
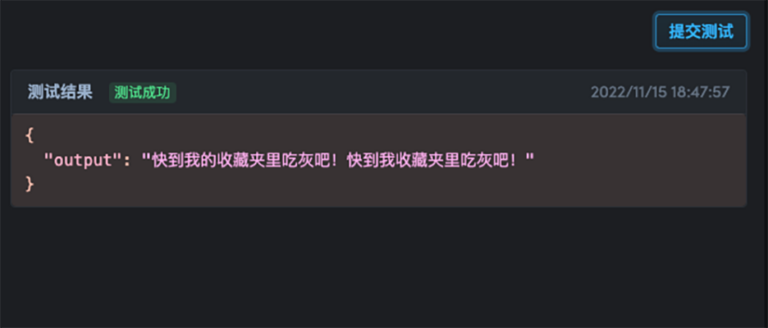
Weitere Informationen zur Modellbereitstellung finden Sie unter:
Zu diesem Zeitpunkt wurde ein chinesisches Textfehlerkorrekturmodell trainiert und bereitgestellt, das Online-Tests unterstützt!
Um das vollständige Lernprogramm anzuzeigen und auszuführen, besuchen Sie den folgenden Link:
Kommen Sie und probieren Sie Ihr chinesisches Fehlerkorrekturmodell aus!
-- über--
Referenzlinks:
[1] https://www.51cto.com/article/715865.html
[2] https://arxiv.org/pdf/1910.1346








