")
Obwohl Google Translate bereits seit fast 15 Jahren auf dem Markt ist, hält das Unternehmen noch immer an der Überzeugung fest, dass Android-Telefone sehr schnell seien.
Das letzte große Update von GT war die Einführung eines neuronalen maschinellen Übersetzungssystems (GNMT) im Jahr 2016, das 8 Encoder und 8 Decoder für die Übersetzung in 9 Sprachen umfasst.
Sie trennen nicht nur Sätze, sondern auch Wörter, und so behandeln sie ein seltenes Wort. Wenn das Wort nicht im Wörterbuch steht, hat NMT keine Referenz. Stellen Sie sich beispielsweise die Übersetzung der Buchstabengruppe „Vas3k“ vor. In diesem Fall versucht GMNT, das Wort in Teile aufzuteilen und deren Übersetzung wiederherzustellen.
Es kann jedoch immer noch nicht erklären, warum „卡顿“ mit „sehr schnell“ übersetzt wurde. Darüber hinaus ist diese Übersetzung in den letzten Tagen zu einem weit verbreiteten Witz unter einheimischen Ingenieuren geworden, und Googles stolze Crowdsourcing-Fehlerkorrektur konnte bei dieser fehlerhaften Übersetzung immer noch nicht erfolgreich eingreifen.
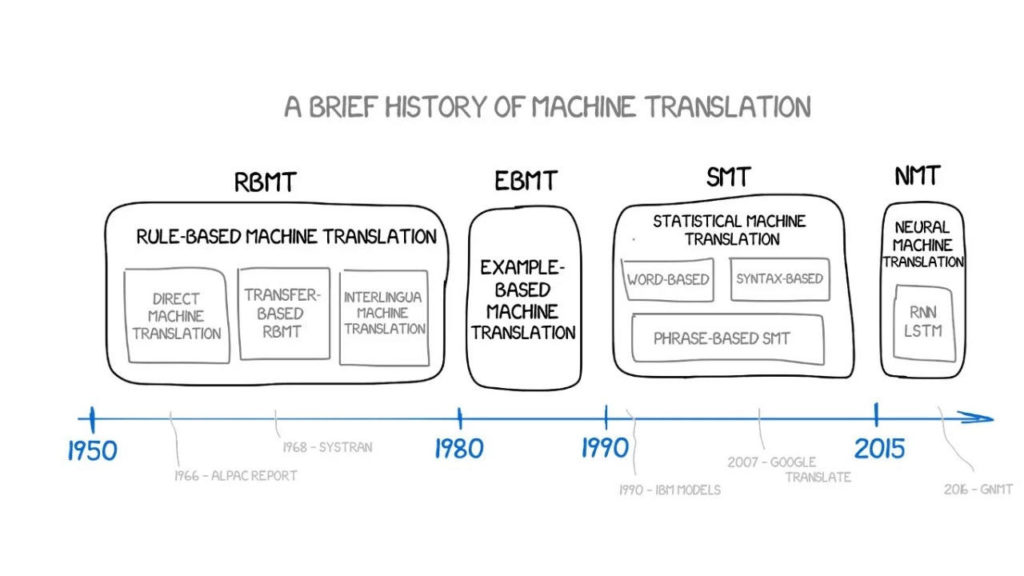
Dieser kleine Witz war der Grund dafür, dass wir mit der Erforschung der maschinellen Übersetzung beginnen wollten. In diesem Artikel wird die Entwicklung der maschinellen Übersetzung in den letzten sechzig Jahren untersucht. Dabei werden gängige Methoden wie die regelbasierte maschinelle Übersetzung (RBMT), die beispielbasierte maschinelle Übersetzung (EBMT), die statistische maschinelle Übersetzung (SMT) und die neuronale maschinelle Übersetzung (NMT) berücksichtigt. Darüber hinaus wird eine Analyse führender Algorithmen von Herstellern wie Google und Yandex durchgeführt.
Sie lesen die erste Hälfte dieser Artikelserie „Maschinelle Übersetzung 1933–1984“.
Die ersten vier Jahrzehnte des langsamen Fortschritts
Die maschinelle Übersetzung tauchte erstmals 1933 während des Kalten Krieges auf.
Damals schlug der sowjetische Wissenschaftler Peter Trojanski an der Sowjetischen Akademie der Wissenschaften vor, „eine Maschine zu entwickeln, die zur Sprachübersetzung und zum Drucken von Texten verwendet werden kann“. Die Maschine war sehr einfach – nur Karten in vier verschiedenen Sprachen, eine Schreibmaschine und eine altmodische Filmkamera.
Der Operator nimmt das erste Wort aus dem Text, sucht die entsprechende Karte, fotografiert es und tippt seine morphologischen Merkmale (Substantiv, Plural, Genitiv usw.) auf einer Schreibmaschine ein. Die Schreibmaschine übersetzte einige dieser Merkmale und stellte sie auf Magnetband und Kamerafilm dar.
")
Obwohl es einfache Übersetzungen durchführen konnte, galt es damals dennoch als „nutzlose“ Erfindung. Leider verbrachte Troyanskii 20 Jahre mit dieser Erfindung und starb schließlich an Angina Pectoris, wodurch die Erfindung ihr Ende fand. Bevor die Maschine 1965 von sowjetischen Wissenschaftlern entdeckt wurde, wusste fast niemand auf der Welt von ihrer Existenz.
Am 7. Januar 1954, zu Beginn des Kalten Krieges, erschien in der IBM-Zentrale in New York die erste echte Übersetzungsmaschine der Geschichte, die IBM 701. Es wurden 60 russische Sätze erfolgreich ins Englische übersetzt. Dies war das berühmte Georgetown-IBM-Experiment.
")
Doch der perfekte Trick bestand darin, ein kleines Detail zu vertuschen. Niemand erwähnte, dass die übersetzten Beispiele sorgfältig ausgewählt und geprüft wurden, um jegliche Mehrdeutigkeiten auszuschließen. Für den alltäglichen Gebrauch ist dieses System nicht besser als ein schnelles Übersetzungshandbuch.
Dennoch wurden die Grundlagen der modernen Verarbeitung natürlicher Sprache von Wissenschaftlern, auch in den Vereinigten Staaten, durch kontinuierliche Experimente, Forschung und Entwicklung geschaffen. Alle heutigen Suchmaschinen, Spamfilter und persönlichen Assistenten basieren darauf.
Regelbasierte maschinelle Übersetzung (RBMT)
Die Idee der regelbasierten maschinellen Übersetzung entstand erstmals in den 1970er Jahren, als Wissenschaftler die Arbeit von Übersetzern aufmerksam beobachteten und versuchten, Computer zu zwingen, diese Aktionen zu wiederholen. Zu diesen Systemen gehören:
-
Zweisprachiges Wörterbuch (RU -> EN)
-
Jede Sprache verfügt über eine Reihe linguistischer Regeln (z. B. Substantive, die mit bestimmten Suffixen enden, wie etwa -heit, -keit, -ung usw.), die die Grundbestandteile der Sprache bilden.
Bei Bedarf kann das System auch einige Tricks hinzufügen, wie etwa Namenslisten, Rechtschreibkorrekturen und Transliteratoren.
")
PROMPT und Systran sind die bekanntesten Beispiele für RBMT-Systeme, auch wenn sie einige Nuancen und Unterarten aufweisen.
-
Direkte maschinelle Übersetzung
Dies ist die direkteste Art der maschinellen Übersetzung. Es übersetzt die Wörter im Text einzeln, korrigiert leicht ihre Morphologie und koordiniert die Grammatik, damit der gesamte Absatz wie eine genauere Übersetzung aussieht. Diese Änderungsregeln werden von professionellen Linguisten festgelegt.
Allerdings versagen diese Übersetzungsregeln manchmal und die Übersetzung ist mangelhaft. Obwohl diese Regel in modernen Systemen überhaupt nicht verwendet wird, erfreut sie sich unter modernen Linguisten großer Beliebtheit.
")
-
Maschinelle Übersetzung basierend auf der grammatikalischen Struktur
Im Vergleich zur wörtlichen Übersetzung legen wir zunächst die grammatische Struktur des Satzes fest, genau wie es uns unsere Lehrer in der Schule beigebracht haben. Wir analysieren dann die gesamte Struktur statt einzelner Wörter, was theoretisch dabei hilft, eine einigermaßen gute Konvertierung der Wortreihenfolge in der Übersetzung zu erreichen.
In der Praxis stößt dieser Ansatz jedoch noch immer an seine Grenzen. Einerseits vereinfacht es allgemeine Grammatikregeln, andererseits wird die Übersetzung durch die Zunahme der Wortstrukturen im Vergleich zu einzelnen Wörtern komplizierter.
")
-
Maschinelle Übersetzung von Interlanguage
Bei diesem Ansatz wird der Ausgangstext in eine Zwischendarstellung umgewandelt und über alle Weltsprachen hinweg vereinheitlicht (Interlingua). Es ist dasselbe, wovon Descartes geträumt hat: eine Metasprache, die universellen Regeln folgt und das Übersetzen zu einer einfachen Hin- und Her-Aufgabe macht. Dadurch ist interlingua in der Lage, in jede beliebige Zielsprache zu übersetzen.
Aufgrund dieser Konvertierung wird Interlingua häufig mit transferbasierten Metasprachensystemen verwechselt. Der Unterschied besteht darin, dass Sprachregeln für jede Sprache und jedes Sprachpaar spezifisch sind und nicht für Sprachpaare. Dies bedeutet, dass wir dem Interlingua-System eine dritte Sprache hinzufügen und zwischen den dreien übersetzen können, was in einem auf grammatikalischer Struktur basierenden Übersetzungssystem schwierig zu erreichen ist.
")
Es sieht perfekt aus, ist es im wirklichen Leben aber nicht. Die Schaffung dieser zwischenmenschlichen Sprache ist äußerst schwierig – viele Wissenschaftler haben ihr ganzes Leben dem Studium dieser Sprache gewidmet. Obwohl sie kein großer Erfolg waren, verfügen wir dank ihnen heute über Darstellungen auf morphologischer, syntaktischer und sogar semantischer Ebene.
")
Allerdings bietet RBMT auch Vorteile, wie etwa seine morphologische Genauigkeit (es kommt nicht zu Wortverwechslungen), die Reproduzierbarkeit der Ergebnisse (alle Übersetzer erhalten die gleichen Ergebnisse) und die Möglichkeit, sie auf Fachgebiete abzustimmen (beispielsweise um Wirtschaftswissenschaftlern oder Ingenieuren Terminologie beizubringen).
Selbst wenn es jemandem gelänge, ein ideales RBMT zu erstellen, und Linguisten es weiterhin mit allen Rechtschreibregeln verbessern würden, gäbe es immer Ausnahmen, mit denen es nicht fertig werden könnte. Zum Beispiel unregelmäßige Verben im Englischen, trennbare Präfixe im Deutschen, Suffixe im Russischen und die unterschiedlichen Ausdrucksweisen der Menschen.
Die Kosten für die Behebung dieser geringfügigen Unterschiede wären enorm. Vergessen Sie nicht die Homonymen. Das bedeutet, dass dasselbe Wort in unterschiedlichen Kontexten unterschiedliche Bedeutungen haben kann, was zu vielen möglichen Übersetzungen desselben Satzes führt. Wenn ich beispielsweise sage: „Ich habe einen Mann gesehen, der auf einem Hügel ein Teleskop benutzt“, wie viele Bedeutungen sind Ihrer Meinung nach damit verbunden?
Sprache entwickelt sich nicht auf der Grundlage eines festen Regelwerks – eine Tatsache, die Linguisten schätzen. Während der 40 Jahre des Kalten Krieges entwickelte sich die maschinelle Übersetzung zwar weiter, es wurde jedoch keine klare Lösung gefunden, um die Genauigkeit und Benutzerfreundlichkeit der Übersetzung zu verbessern.
Daher ist RBMT schon seit langer Zeit tot.
Beispielbasierte maschinelle Übersetzung (EBMT)
Um in der bevorstehenden Globalisierung möglichst schnell Fuß fassen zu können, benötigte Japan, wo nur wenige Menschen Englisch sprachen, in den 1980er Jahren dringend maschinelle Übersetzungen. Dank der starken Unterstützung der nationalen Politik entwickelte sich Japan zu dem Land, das damals das größte Interesse an maschineller Übersetzung hatte.
Da die regelbasierte maschinelle Übersetzung (RBMT) vom Englischen ins Japanische schwierig ist, weil der Übersetzungsprozess eine Neuanordnung fast aller Wörter erfordert und auch neue Wörter beinhaltet, sind die Japaner gezwungen, nach neuen Übersetzungsideen zu suchen.
")
So schlug Makoto Nagao von der Universität Kyoto im Jahr 1984 die Idee vor, wiederholte Übersetzungen durch vorgefertigte Phrasen zu ersetzen, was als sogenannte beispielbasierte maschinelle Übersetzung (EBMT) bezeichnet wird. Je mehr Fälle Sie eingeben, desto schneller und genauer ist die Übersetzung.
Das Aufkommen der EBMT-Idee war wie ein Funke, der die innovative Inspiration der Wissenschaftler entfachte. Dies ist für die Entwicklung der maschinellen Übersetzung von großer Bedeutung, auch wenn es sich noch nicht um eine revolutionäre Neuerung handelt. Doch in fünf Jahren wird auf dieser Grundlage eine revolutionäre statistische Übersetzung entstehen.
Vorschau zum nächsten Artikel
-
Die Ära der maschinellen Übersetzung in den 1990er- und 2000er-Jahren war von der statistischen maschinellen Übersetzung (SMT) dominiert.
-
Die neuronale maschinelle Übersetzung (NMT) feierte 2015 endlich ihr Debüt.
-
Erweitertes Gameplay von Google und Yandex;
")
")
Historische Artikel (zum Lesen auf das Bild klicken)
")
Warum ist der 24. Oktober der Tag der Programmierer? 》
")
„Dieses Papier ist giftig!“ 》
")
„Wie erklärt man seinen Verwandten und Freunden künstliche Intelligenz? 》
")
")








