Rezension der vorherigen Folge
-
Sechzig Jahre langsame Entwicklung der maschinellen Übersetzung
-
Regelbasierte maschinelle Übersetzung (RBMT)
-
Beispielbasierte maschinelle Übersetzung (EBMT)
?")
Klicken Sie auf das Bild, um den ersten Teil dieses Artikels zu lesen
Statistische Maschinenübersetzung (SMT)
Anfang 1990 wurde im IBM Research Center erstmals ein maschinelles Übersetzungssystem vorgeführt, das nichts von Regeln und Linguistik wusste. Es analysiert den Text im Bild unten in zwei Sprachen und versucht, die Muster zu verstehen.
?")
Die Idee ist einfach und schön. In beiden Sprachen wird derselbe Satz in mehrere Wörter zerlegt und dann wieder zusammengesetzt. Dieser Vorgang wurde etwa 500 Millionen Mal wiederholt, beispielsweise wurde das Wort „Das Haus“ mit „house“ vs. „building“ vs. „construction“ usw. übersetzt.
Wenn das Ausgangswort (zum Beispiel „Das Haus“) in den meisten Fällen mit „house“ übersetzt wird, geht die Maschine von dieser Bedeutung aus. Beachten Sie, dass wir weder Regeln festgelegt noch Wörterbücher verwendet haben – alle Schlussfolgerungen wurden von Maschinen gezogen, geleitet von Daten und Logik. Beim Übersetzen schien die Maschine zu sagen: „Wenn die Leute es so übersetzen, mache ich es auch so.“ So entstand die statistische maschinelle Übersetzung.
?")
Seine Vorteile liegen darin, dass es effizienter und genauer ist und keinen Linguisten erfordert. Je mehr Text wir verwenden, desto bessere Übersetzungen erhalten wir.
?")
(Statistische Übersetzung von Google: Sie zeigt nicht nur die Verwendungswahrscheinlichkeit dieser Bedeutung, sondern liefert auch Statistiken zu anderen Bedeutungen.)
Noch eine Frage:
Wie verbindet eine Maschine die Wörter „Das Haus“ und „Gebäude“ – und woher wissen wir, dass dies die richtigen Übersetzungen sind?
Die Antwort ist, wir wissen es nicht.
Zunächst geht die Maschine davon aus, dass das Wort „Das Haus“ mit jedem beliebigen Wort im übersetzten Satz die gleiche Assoziation hat. Wenn dann „Das Haus“ in anderen Sätzen auftaucht, verstärkt sich die Assoziation mit „Haus“. Dies ist der „Wortausrichtungsalgorithmus“, eine typische Aufgabe des maschinellen Lernens auf Schulniveau.
Die Maschine benötigt Millionen von Sätzen in zwei Sprachen, um zu jedem Wort relevante statistische Informationen zu sammeln. Wie erhalte ich diese Sprachinformationen? Wir haben uns entschieden, die Zusammenfassungen der Sitzungen des Europäischen Parlaments und des Sicherheitsrats der Vereinten Nationen zu verwenden – diese Zusammenfassungen liegen in den Sprachen aller Mitgliedstaaten vor, was bei der Materialsammlung viel Zeit sparen kann.
-
Wortbasiertes SMT
Am Anfang zerlegten die ersten statistischen Übersetzungssysteme Sätze in Wörter. Da dieser Ansatz unkompliziert und logisch war, wurde IBMs erstes statistisches Übersetzungsmodell „Modell 1“ genannt.
Modell 1: Wortkorb
?")
Modell 1 verwendete den klassischen Ansatz der Aufteilung in Wörter und der statistischen Zählung, berücksichtigte jedoch nicht die Wortreihenfolge und der einzige Trick bestand darin, ein Wort in mehrere Wörter zu übersetzen. Beispielsweise kann aus „Der Staubsauger“ „The Vacuum Cleaner“ werden, aber das bedeutet nicht, dass daraus „The Vacuum Cleaner“ wird.
Modell 2: Die Reihenfolge der Wörter in einem Satz berücksichtigen
?")
Die fehlende Wortreihenfolge ist die Haupteinschränkung von Modell 1, die im Übersetzungsprozess sehr wichtig ist. Modell 2 löst dieses Problem, indem es sich die gemeinsamen Positionen der Wörter im Ausgabesatz merkt und sie in den Zwischenschritten neu anordnet, um die Übersetzung natürlicher zu gestalten.
Und, ist es besser geworden? NEIN.
Modell 3: Neue Wörter hinzufügen
?")
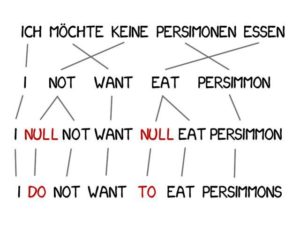
Bei der Übersetzung ist es oft notwendig, neue Wörter hinzuzufügen, um die Semantik zu verbessern, wie zum Beispiel die Verwendung von „do“ im Deutschen, wenn im Englischen eine Negation erforderlich ist.Der deutsche Satz „Ich will keine Kakis“ bedeutet im Englischen „Ich will keine Kakis“.
Um dieses Problem zu lösen, fügt Modell 3 zwei weitere Schritte hinzu, die auf den vorherigen basieren:
-
Wenn die Maschine der Ansicht ist, dass ein neues Wort hinzugefügt werden muss, wird das NULL-Token eingefügt.
-
Wählen Sie für jede Wortausrichtung die richtige Grammatik oder das richtige Wortpaar.
Modell 4: Wortausrichtung
Modell 2 berücksichtigt die Wortausrichtung, weiß aber nichts über die Neuanordnung. Beispielsweise werden Adjektive häufig mit Substantiven vertauscht, und unabhängig von der Reihenfolge, die man sich merkt, ist es schwierig, eine subtile Übersetzung zu erhalten, ohne grammatikalische Faktoren hinzuzufügen. Daher berücksichtigt Modell 4 diese „relative Reihenfolge“ – wenn zwei Wörter immer die Plätze tauschen, weiß das Modell Bescheid.
Modell 5: Fehler beheben
Modell 5 erhält mehr Lernparameter und löst das Problem des Wortpositionskonflikts. So revolutionär sie auch waren, textbasierte Systeme konnten immer noch nicht mit Homonymen umgehen, bei denen jedes Wort auf eine einzige Weise übersetzt wurde.
Diese Systeme werden jedoch nicht mehr verwendet, da sie durch fortschrittlichere phrasenbasierte Übersetzungen ersetzt wurden.
-
Phrasenbasiertes SMT
Die Methode basiert auf allen wortbasierten Übersetzungsprinzipien: Statistik, Neuordnung und lexikalische Techniken. Dabei wird der Text nicht nur in Wörter, sondern auch in Phrasen segmentiert, also in zusammenhängende Folgen mehrerer Wörter.
Dadurch lernte die Maschine, stabile Wortkombinationen zu übersetzen, was die Genauigkeit deutlich verbesserte.
?")
Der Punkt ist, dass diese Sätze nicht immer einfache syntaktische Strukturen aufweisen und dass die Qualität der Übersetzung erheblich nachlässt, wenn man sich der Interferenzen zwischen Linguistik und Satzstruktur bewusst ist. Frederick Jelinek, ein Pionier der Computerlinguistik, scherzte einmal: „Jedes Mal, wenn ich einen Linguisten angreife, verbessert sich die Leistung des Spracherkenners.“
Neben der höheren Genauigkeit bietet die phrasenbasierte Übersetzung mehr Möglichkeiten für zweisprachige Texte. Bei textbasierten Übersetzungen ist eine genaue Übereinstimmung mit der Quelle entscheidend, daher ist es schwierig, einen Mehrwert bei literarischen oder freien Übersetzungen zu erzielen.
Bei der phrasenbasierten Übersetzung gibt es dieses Problem nicht und um das Niveau der maschinellen Übersetzung zu verbessern, haben Forscher sogar damit begonnen, Nachrichten-Websites in verschiedenen Sprachen zu analysieren.
?")
Seit 2006 nutzt fast jeder diese Methode. Google Translate, Yandex, Bing und andere bekannte Online-Übersetzungssysteme waren vor 2016 alle phrasenbasiert. Daher sind die Ergebnisse dieser Übersetzungssysteme entweder perfekt oder bedeutungslos, und ja, das ist das Merkmal der Phrasenübersetzung.
Diese alte regelbasierte Methode führt immer zu verzerrten Ergebnissen. Google hat „dreihundert“ ohne zu zögern mit „300“ übersetzt, aber tatsächlich bedeutet „dreihundert“ auch „300 Jahre“. Dies ist eine häufige Einschränkung statistischer Übersetzungsmaschinen.
Vor 2016 betrachteten fast alle Studien die phrasenbasierte Übersetzung als die fortschrittlichste Methode und setzten sogar „statistische maschinelle Übersetzung“ und „phrasenbasierte Übersetzung“ gleich. Man erkannte jedoch, dass Google die gesamte maschinelle Übersetzung revolutionieren würde.
-
Syntaxbasiertes SMT
Auch diese Methode soll kurz erwähnt werden. Viele Jahre vor der Erfindung neuronaler Netzwerke galt die grammatikalische Übersetzung als „die Zukunft“, doch die Idee konnte sich nicht durchsetzen.
Seine Befürworter argumentieren, dass es mit regelbasierten Ansätzen zusammengeführt werden kann. Es ist möglich, eine präzise grammatikalische Analyse von Sätzen durchzuführen – das Subjekt, das Prädikat und andere Teile des Satzes zu bestimmen und dann einen Satzbaum zu erstellen. Durch die Nutzung dieser Technologie lernen Maschinen, syntaktische Einheiten zwischen Sprachen umzuwandeln und wort- oder satzweise zu übersetzen. Dadurch wird das Problem des „Übersetzungsfehlers“ vollständig gelöst.
?")
Die Idee ist schön, aber die Realität ist sehr düster. Die Grammatikanalyse funktioniert sehr schlecht, obwohl das Problem der Grammatikbibliothek bereits gelöst wurde (da wir bereits über viele vorgefertigte Sprachbibliotheken verfügen).
Neuronale maschinelle Übersetzung (NMT)
Im Jahr 2014 erschien ein interessantes Papier zur maschinellen Übersetzung mit neuronalen Netzwerken, das jedoch nicht viel Aufmerksamkeit erregte, und erst Google begann, sich tiefer mit diesem Gebiet zu befassen. Zwei Jahre später, im November 2016, machte Google eine viel beachtete Ankündigung: Die Spielregeln für maschinelle Übersetzung wurden von uns offiziell geändert.
Die Idee ähnelt der Prisma-Funktion, mit der Sie den Stil der Werke berühmter Künstler nachahmen können. In Prisma wird neuronalen Netzwerken beigebracht, den Stil der Arbeit eines Künstlers zu erkennen, und die daraus resultierenden stilisierten Bilder können beispielsweise ein Foto wie ein Van Gogh aussehen lassen. Obwohl dies eine Illusion des Internets ist, finden wir es schön.
?")
Was wäre, wenn wir einen Stil auf ein Foto übertragen könnten, was wäre, wenn wir versuchten, dem Quelltext eine andere Sprache aufzuzwingen? Der Text würde genau dem „Stil des Künstlers“ entsprechen und wir würden versuchen, ihn zu übertragen und dabei die Essenz des Bildes (mit anderen Worten die Essenz des Textes) zu bewahren.
Stellen Sie sich vor, was passieren würde, wenn diese Art neuronales Netzwerk auf ein Übersetzungssystem angewendet würde?
Angenommen, der Quelltext ist eine Sammlung bestimmter Merkmale, bedeutet dies, dass Sie ihn kodieren und ihn dann von einem anderen neuronalen Netzwerk wieder in Text in einer Sprache dekodieren lassen müssen, die nur der Decoder kennt. Der Ursprung dieser Eigenschaften ist nicht bekannt, aber sie können auf Spanisch ausgedrückt werden.
Es wäre interessant, wenn ein neuronales Netzwerk Sätze nur in einen bestimmten Satz von Merkmalen kodieren könnte, während das andere sie nur wieder in Text dekodieren könnte. Keiner von ihnen wusste, wer der andere war. Sie kannten jeweils nur ihre eigene Sprache. Sie waren einander fremd, konnten sich aber dennoch miteinander abstimmen.
?")
Allerdings besteht auch hier das Problem, diese Merkmale zu finden und zu definieren. Wenn wir über Hunde sprechen, sind ihre Eigenschaften offensichtlich, aber was ist mit Text? Wissen Sie, vor 30 Jahren versuchten Wissenschaftler, einen universellen Sprachcode zu erstellen, scheiterten jedoch letztendlich.
Mittlerweile gibt es jedoch Deep Learning, das dieses Problem sehr gut lösen kann, da es für diesen Zweck existiert. Der Hauptunterschied zwischen Deep Learning und klassischen neuronalen Netzwerken besteht in der zielgenauen Fähigkeit, nach diesen spezifischen Merkmalen zu suchen, unabhängig von ihrer Natur. Wenn das neuronale Netzwerk groß genug ist und über Tausende von Grafikkarten verfügt, kann es diese Merkmale aus dem Text extrahieren.
Theoretisch könnten wir die aus neuronalen Netzen gewonnenen Merkmale an Linguisten weitergeben, sodass diese sich völlig neue Perspektiven eröffnen könnten.
Eine Frage ist, welche Art von neuronalem Netzwerk zur Textkodierung und -dekodierung eingesetzt werden kann.
Wir wissen, dass Convolutional Neural Networks (CNNs) derzeit nur mit Bildern arbeiten, die auf unabhängigen Pixelblöcken basieren. In Texten gibt es jedoch keine unabhängigen Blöcke, und jedes Wort hängt von seiner Umgebung ab, genau wie Sprache und Musik. Rekurrierende neuronale Netze (RNNs) bieten eine optimale Auswahl, da sie sich an alle vorherigen Ergebnisse erinnern – in unserem Fall an die vorherigen Wörter.
Und rekurrente neuronale Netzwerke werden bereits heute verwendet, beispielsweise bei der RNN-Siri-Spracherkennung des iPhones (sie analysiert die Reihenfolge der Laute, der nächste hängt vom vorherigen ab), bei Tastaturansagen (vorherigen merken, nächsten erraten), bei der Musikgenerierung und sogar bei Chatbots.
?")
Innerhalb von zwei Jahren haben neuronale Netzwerke die Übersetzungsleistung der letzten 20 Jahre vollständig übertroffen. Es reduzierte die Wortreihenfolgefehler um 50%, die Wortschatzfehler um 17% und die Grammatikfehler um 19%. Das neuronale Netzwerk lernte sogar, mit Problemen wie Homonymen in verschiedenen Sprachen umzugehen.
Bemerkenswerterweise sind neuronale Netzwerke in der Lage, wirklich direkte Übersetzungen zu erzielen, sodass Wörterbücher gänzlich überflüssig werden. Beim Übersetzen zwischen zwei nicht-englischen Sprachen ist es nicht erforderlich, Englisch als Zwischensprache zu verwenden. Wenn Sie bisher Russisch ins Deutsche übersetzen wollten, mussten Sie zuerst Russisch ins Englische und dann Englisch ins Deutsche übersetzen. Dies würde die Fehlerquote bei wiederholten Übersetzungen erhöhen.
?")
Google Übersetzer (seit 2016)
Im Jahr 2016 entwickelten sie ein System namens Google Neural Machine Translation (GNMT) zur Übersetzung in neun Sprachen. Es umfasst 8 Encoder und 8 Decoder sowie eine Netzwerkverbindung, die für die Online-Übersetzung verwendet werden kann.
?")
Sie trennen nicht nur Sätze, sondern auch Wörter, und so behandeln sie ein seltenes Wort. Wenn das Wort nicht im Wörterbuch steht, hat NMT keine Referenz. Stellen Sie sich beispielsweise die Übersetzung der Buchstabengruppe „Vas3k“ vor. In diesem Fall versucht GMNT, das Wort in Teile aufzuteilen und deren Übersetzung wiederherzustellen.
Tipp: Google Translate verwendet für Website-Übersetzungen im Browser immer noch den alten phrasenbasierten Algorithmus. Aus irgendeinem Grund hat Google es nicht aktualisiert und die Unterschiede zur Online-Version sind deutlich erkennbar.
Der derzeit im Browser zur Website-Übersetzung verwendete Google Translate verwendet jedoch immer noch einen phrasenbasierten Algorithmus. Aus irgendeinem Grund hat Google in dieser Hinsicht kein Upgrade durchgeführt, aber dadurch können wir auch den Unterschied zum herkömmlichen Übersetzungsmodus erkennen.
Google verwendet online einen Crowdsourcing-Mechanismus, bei dem die Leute die Version auswählen können, die sie für die korrekteste halten. Wenn sie vielen Benutzern gefällt, übersetzt Google den Ausdruck weiterhin auf diese Weise und kennzeichnet ihn mit einem speziellen Abzeichen. Dies ist sehr nützlich für kurze, alltägliche Sätze wie „Lass uns ins Kino gehen“ oder „Ich warte auf dich.“
Yandex Translation (seit 2017)
Yandex hat 2017 ein neuronales Übersetzungssystem auf den Markt gebracht, das den CatBoost-Algorithmus verwendet, der neuronale Netzwerke mit statistischen Methoden kombiniert.
Mit dieser Methode lassen sich die Mängel der Übersetzung mithilfe neuronaler Netze wirksam ausgleichen. Bei Phrasen, die nicht häufig vorkommen, kommt es häufig zu Übersetzungsverzerrungen. In diesem Fall kann eine einfache statistische Übersetzung schnell und einfach das richtige Wort finden.
?")
Die Zukunft der maschinellen Übersetzung?
Die Leute sind immer noch begeistert vom Konzept „Babel Fish“ – der sofortigen Sprachübersetzung. Google ist mit seinen Pixel Buds einen Schritt in diese Richtung gegangen, aber in Wirklichkeit ist es sicherlich nicht perfekt, denn Sie müssen ihm mitteilen, wann es mit der Übersetzung beginnen und wann es den Mund halten und zuhören soll. Aber nicht einmal Siri kann das.
Es gibt eine Schwierigkeit, die untersucht werden muss: Alles Lernen ist auf den Korpus des maschinellen Lernens beschränkt. Auch wenn wir komplexere neuronale Netzwerke entwerfen können, sind diese derzeit darauf beschränkt, aus dem bereitgestellten Text zu lernen. Menschliche Übersetzer können relevante Korpusse durch das Lesen von Büchern oder Artikeln ergänzen, um genauere Übersetzungsergebnisse zu gewährleisten. Hier hinkt die maschinelle Übersetzung der menschlichen Übersetzung weit hinterher.
Da menschliche Übersetzer dies jedoch theoretisch können, können neuronale Netzwerke dies auch. Und es scheint, dass einige Leute bereits versucht haben, diese Funktion mithilfe neuronaler Netzwerke zu erreichen. Das heißt, es verwendet die ihm bekannte Sprache, um in einer anderen Sprache zu lesen und Erfahrungen zu sammeln, und gibt diese dann zur späteren Verwendung in sein eigenes Übersetzungssystem zurück. Warten wir es ab.
Weiterführende Literatur
?")
《Statistische maschinelle Übersetzung》
Von Philipp Koehn
Folgen Sie dem öffentlichen Konto und antworten Sie mit „Statistische maschinelle Übersetzung“, um die PDF-Version herunterzuladen
?")
?")








