Command Palette
Search for a command to run...
PipeTransformer: Automatisierte Elastische Pipeline Für Das Training Verteilter Modelle Im Großen Maßstab

Titel des Artikels:
PipeTransformer: Automatisiertes elastisches Pipelining für das verteilte Training von Großmodellen
Pipeptransformer verwendet automatisierte elastische Pipelines, um ein effizientes verteiltes Training von Transformer-Modellen durchzuführen. In PipeTransformer entwickeln wir einen adaptiven dynamischen Einfrieralgorithmus, der während des Trainings schrittweise bestimmte Schichten identifizieren und einfrieren kann, sowie ein flexibles Pipeline-System, das Ressourcen dynamisch zuweisen kann, um die verbleibenden aktiven Schichten zu trainieren.
Insbesondere schließt PipeTransformer eingefrorene Ebenen automatisch aus der Pipeline aus, packt aktive Ebenen in weniger GPUs und verzweigt mit mehr Replikaten, um die parallele Datenbreite zu erhöhen.
Auswertungen von ViT (mit dem ImageNet-Datensatz) und BERT (mit den SQuAD- und GLUE-Datensätzen) zeigen, dass PipeTransformer im Vergleich zu den modernsten Baselines eine bis zu 2,83-fache Beschleunigung erreicht, ohne dass es zu Genauigkeitsverlusten kommt.
Das Dokument enthält außerdem zahlreiche Leistungsanalysen, die den Benutzern ein umfassenderes Verständnis des Algorithmus und des Systemdesigns ermöglichen.
Als Nächstes stellt dieser Artikel detailliert den Forschungshintergrund, die Motivation, die Designideen und Designlösungen des Systems vor und erläutert, wie der Algorithmus und das System mithilfe der verteilten PyTorch-API implementiert werden.
Einführung

Große Transformer-Modelle haben sowohl in der Verarbeitung natürlicher Sprache als auch in der Computervision Durchbrüche in der Genauigkeit erzielt. GPT-3 stellt für die meisten NLP-Aufgaben neue Genauigkeitsrekorde auf. In ImageNet erreichte Vision Transformer (kurz ViT) ebenfalls eine Top-1-Genauigkeit von 89% und übertraf damit die fortschrittlichsten Faltungsnetzwerke ResNet-152 und EfficientNet.
Um das Problem der immer größer werdenden Modelle zu lösen, haben Forscher verschiedene verteilte Trainingstechniken vorgeschlagen, darunter Parameterserver, Pipeline-Parallelität, Intra-Layer-Parallelität und redundanzfreie Datenparallelität.
Allerdings handelt es sich bei den vorhandenen verteilten Trainingslösungen lediglich um Forschungsszenarien, und alle Modellgewichte müssen während des Trainingsvorgangs optimiert werden (d. h. der Rechen- und Kommunikationsaufwand muss während verschiedener Iterationen relativ stabil bleiben). Aktuelle Forschungen zum progressiven Training zeigen, dass die Parameter in einem neuronalen Netzwerk dynamisch trainiert werden können:
- Kanonische Korrelationsanalyse singulärer Vektoren für die Dynamik und Interpretierbarkeit von Deep Learning. NeurIPS 2017
- Effizientes Training von BERT durch progressives Stapeln. ICML 2019
- Beschleunigen des Trainings transformatorbasierter Sprachmodelle durch progressives Layer Dropping. NeurIPS 2020
- Zum Transformer-Wachstum für progressives BERT-Training. NACCL 2021

Abbildung 2: Interpretierbares Frozen-Training: DNN-Bottom-Up-Konvergenz (mit ResNet zum Testen der Ergebnisse auf CIFAR10). Jeder Bereich zeigt die Ähnlichkeit der einzelnen Schichten durch SVCCA.
Beispielsweise konvergieren neuronale Netzwerke beim Frozen Training typischerweise von unten nach oben (d. h., es müssen nicht alle Schichten trainiert werden, um bestimmte Ergebnisse zu erzielen).
Die obige Abbildung zeigt ein Beispiel dafür, wie sich die Gewichte im Laufe des Trainings mit einem ähnlichen Ansatz stabilisieren. Auf dieser GrundlageWir nutzen Frozen Training, um ein verteiltes Training von Transformer-Modellen durchzuführen, und beschleunigen das Training durch die dynamische Zuweisung von Ressourcen, um uns auf eine reduzierte Anzahl aktiver Ebenen zu konzentrieren.
Diese Layer-Freezing-Strategie eignet sich besonders für die Pipeline-Parallelität, da durch das Ausschließen aufeinanderfolgender unterer Schichten aus der Pipeline der Rechen-, Speicher- und Kommunikationsaufwand reduziert werden kann.
Abbildung 3: Der automatisierte und flexible Pipeline-Prozess von PipeTransformer beschleunigt das verteilte Training von Transformer-Modellen
PipeTransformer ist ein flexibles Framework zur Beschleunigung des Pipeline-Trainings, das automatisch auf eingefrorene Ebenen reagiert, indem es den Umfang der Pipeline-Modelle und die Anzahl der Pipeline-Replikate dynamisch transformiert.
Nach unserem besten Wissen ist dies die erste Arbeit, die sich mit dem Layer Freezing im Kontext von Pipeline- und datenparallelem Training befasst.
Abbildung 3 veranschaulicht die Vorteile dieser Kombination.
Erstens kann durch das Ausschließen eingefrorener Ebenen aus der Pipeline dasselbe Modell auf weniger GPUs gepackt werden, was zu weniger GPU-übergreifender Kommunikation und kleineren Pipeline-Blasen führt.
Zweitens kann derselbe Cluster nach dem Packen des Modells auf weniger GPUs mehr Pipeline-Replikate aufnehmen und so die Breite der Datenparallelität erhöhen.
Noch wichtiger ist, dass die beiden Vorteile multiplikativ und nicht additiv sind, was den Trainingsfortschritt weiter beschleunigt.
Das Design von PipeTransformer steht vor vier großen Herausforderungen.
Erstens muss der Einfrieralgorithmus dynamische und adaptive Einfrierentscheidungen treffen. Die vorhandene Arbeit stellt jedoch lediglich ein Post-hoc-Analysetool bereit.
Zweitens wird die Effizienz der Pipeline-Neupartitionierung von vielen Faktoren beeinflusst, darunter Partitionsgranularität, partitionsübergreifende Aktivierungsgröße und Anzahl der Mini-Batch-Blöcke, was eine Argumentation und Suche in einem größeren Lösungsraum erfordert.
Um als Nächstes zusätzliche Pipeline-Replikate dynamisch einzuführen, muss PipeTransformer die statische Natur der kollektiven Kommunikation überwinden und potenziell komplexe prozessübergreifende Nachrichtenprotokolle vermeiden (eine Pipeline kann nur von einem Prozess verwaltet werden), wenn neue Prozesse online gehen.
Schließlich kann der Cache Zeit für die wiederholte Vorwärtsausbreitung eingefrorener Ebenen sparen, er muss jedoch zwischen vorhandenen und neu hinzugefügten Pipelines gemeinsam genutzt werden, da das System nicht für jede Replik einen dedizierten Cache erstellen und aufwärmen kann.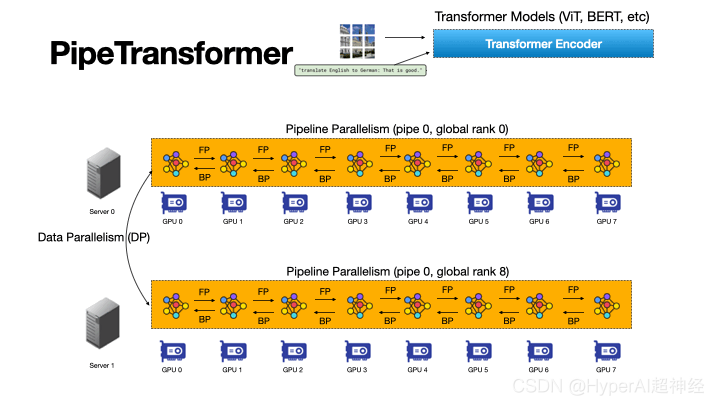
Abbildung 4: Schematische Darstellung der PipeTransformer-Dynamik
Um die oben genannten Herausforderungen zu meistern, müssen, wie in Abbildung 4 dargestellt,Das Design von PipeTransformer besteht aus vier Kernbausteinen.
Der erste ist ein anpassbarer adaptiver Algorithmus, der Signale generiert, die die Auswahl der eingefrorenen Schichten bei verschiedenen Iterationen steuern (Einfrieralgorithmus). Sobald das Modul für die elastische Pipeline (AutoPipe) durch diese Signale ausgelöst wird, packt es die verbleibenden aktiven Ebenen in weniger GPUs, indem es die Änderungen in den Aktivitätsgrößen und Arbeitslasten der heterogenen Partitionen (eingefrorene und aktive Ebenen) auswertet.
Als nächstes wird basierend auf den vorherigen Analyseergebnissen verschiedener Pipelinelängen ein Mini-Batch in eine Reihe besserer Mikro-Batches zerlegt.
Das nächste Modul, AutoDP, generiert zusätzliche Pipeline-Kopien, um die freigegebenen GPUs zu belegen, und verwaltet hierarchische Kommunikationsprozessgruppen, um eine dynamische Mitgliedschaft für die kollektive Kommunikation zu erreichen.
Das letzte Modul, AutoCache, teilt Aktivierungen effizient zwischen vorhandenen und neu hinzugefügten datenparallelen Prozessen und ersetzt während Transformationen automatisch veralteten Cache.
Im Allgemeinen kombiniert PipeTransformer den Einfrieralgorithmus sowie die Module AutoPipe, AutoDP und AutoCache, um eine erhebliche Trainingsbeschleunigung zu ermöglichen.
Wir bewerten PipeTransformer mit den Modellen ViT (unter Verwendung des ImageNet-Datensatzes) und BERT (unter Verwendung der SQuAD- und GLUE-Datensätze) und zeigen, dass PipeTransformer im Vergleich zu den modernsten Baselines eine bis zu 2,83-fache Beschleunigung erreicht, ohne dass es zu Genauigkeitsverlusten kommt.
Darüber hinaus bieten wir verschiedene Leistungsanalysen an, die den Benutzern ein umfassenderes Verständnis der algorithmischen und systemischen Designs ermöglichen. Schließlich haben wir eine flexible Open-Source-API für PipeTransformer entwickelt, die eine klare Trennung zwischen Einfrieralgorithmen, Modelldefinition und Trainingsbeschleunigung bietet und so die Migration zu Algorithmen ermöglicht, die ähnliche Einfrierstrategien erfordern.
Gesamtdesign
Angenommen, unser Ziel besteht darin, ein groß angelegtes Modell in einem verteilten Trainingssystem zu trainieren. Dieses System kombiniert Pipeline-Modellparallelität und Datenparallelität und kann zur Handhabung der folgenden Szenarien verwendet werden:
Das Modell passt nicht in den Speicher eines einzelnen GPU-Geräts oder die Batchgröße ist klein genug, um einen Speichermangel zu vermeiden. Im Einzelnen sind folgende Einstellungen definiert:
- Trainingsaufgaben und Modelldefinitionen. Trainieren Sie Transformer-Modelle (wie Vision Transformer, BERT usw.) anhand großer Bild- oder Textdatensätze. Das Transformer-Modell mathcalF verfügt über insgesamt L Schichten, wobei die i-te Schicht aus einer Vorwärtsberechnungsfunktion fi und einem Satz entsprechender Parameter besteht.
- Trainingsinfrastruktur. Angenommen, die Trainingsinfrastruktur besteht aus einem GPU-Cluster mit N GPU-Servern (d. h. Knoten). Jeder Knoten verfügt über 1 GPU. Der Cluster ist homogen, was bedeutet, dass die Hardwarekonfiguration jeder GPU und jedes Servers identisch ist. Die Speicherkapazität jeder GPU beträgt MGPU. Die Server sind über Netzwerkschnittstellen mit hoher Bandbreite wie InfiniBand miteinander verbunden.
- Pipeline-Parallelität. In jeder Maschine laden wir ein Modell F in eine Pipeline mit K Partitionen (K stellt auch die Pipelinelänge dar). Die k-te Partition besteht aus Pk aufeinanderfolgenden Schichten. Gehen Sie davon aus, dass jede Partition von einem GPU-Gerät verarbeitet wird. 1≤K≤I bedeutet, dass wir mehrere Pipelines für mehrere Modellreplikate auf einem einzigen Gerät erstellen können.
Angenommen, alle GPU-Geräte in einer Pipeline gehören zur selben Maschine, die Pipeline ist eine synchrone Pipeline, es sind keine abgelaufenen Gradienten beteiligt und die Anzahl der Mikro-Batches beträgt M. Im Linux-Betriebssystem wird jede Pipeline von einem Prozess verwaltet. Weitere Einzelheiten finden Sie unter GPipe.
- Datenparallelität. DDP ist eine maschinenübergreifende, verteilte Datenparallelverarbeitungsgruppe innerhalb von R Parallel Workern. Jeder Worker ist eine Kopie der Pipeline (ein einzelner Prozess). Der Index (ID) des r-ten Workers ist Rang r.
Zwei beliebige Pipelines in DDP können zum selben oder zu verschiedenen GPU-Servern gehören und mit dem AllReduce-Algorithmus auch Gradienten austauschen.
In diesen Fällen besteht unser Ziel darin, das Training zu beschleunigen, indem wir die Vorteile des Frozen Trainings nutzen, wodurch die Notwendigkeit entfällt, während des gesamten Trainingsprozesses alle Schichten zu trainieren.
Darüber hinaus trägt dies dazu bei, Berechnungen, Kommunikation und Speicherverluste zu sparen und vermeidet bis zu einem gewissen Grad eine Überanpassung, die durch das kontinuierliche Einfrieren von Schichten verursacht wird.
Um diese Vorteile nutzen zu können, müssen jedoch die vier oben genannten Herausforderungen bewältigt werden, nämlich die Entwicklung eines adaptiven Einfrieralgorithmus, eine dynamische Neupartitionierung der Pipeline, eine effiziente Neuzuweisung von Ressourcen und ein prozessübergreifendes Caching.
Abbildung 5: Übersicht über das PipeTransformer-Trainingssystem
PipeTransformer entwickelt gemeinsam einen Algorithmus zum sofortigen Einfrieren und ein automatisches, elastisches Pipeline-Trainingssystem, das den Umfang von Pipeline-Modellen und die Anzahl der Pipeline-Replikate dynamisch transformieren kann. Die gesamte Systemarchitektur ist in Abbildung 5 dargestellt.
Um die flexible Pipeline von PipeTransformer zu unterstützen, pflegen wir eine angepasste Version der PyTorch Pipeline. Für die Datenparallelität verwenden wir PyTorch DDP als Basis. Andere Bibliotheken sind Standardmechanismen des Betriebssystems (wie beispielsweise Multi-Processing), wodurch ebenfalls keine benutzerdefinierte Software oder Hardware erforderlich ist.
Um die Universalität des Frameworks zu gewährleisten, entkoppeln wir das Trainingssystem in vier Kernkomponenten: Einfrieralgorithmus, AutoPipe, AutoDP und AutoCache.
Der Einfrieralgorithmus (grau) entnimmt der Trainingsschleife Messdaten und trifft Schicht für Schicht Einfrierentscheidungen, die mit der AutoPipe (grün) geteilt werden.
AutoPipe ist ein flexibles Pipeline-Modul, das das Training beschleunigt, indem es eingefrorene Ebenen aus der Pipeline ausschließt und aktive Ebenen auf weniger GPUs (pink) packt, wodurch die grafikprozessorübergreifende Kommunikation reduziert und Pipeline-Stalls kleiner gehalten werden.
AutoPipe übergibt dann die Informationen zur Pipelinelänge an AutoDP (lila), das dann, wenn möglich, weitere Pipelinekopien generiert, um die Breite der Datenparallelität zu erhöhen.
Die Abbildung enthält auch ein Beispiel, bei dem AutoDP eine neue Replik einführt (in Lila). AutoCache (orangefarbener Umriss) ist ein Pipeline-übergreifendes Cache-Modul. Aus Gründen der Lesbarkeit und Allgemeingültigkeit bleibt die Quellcodearchitektur mit Abbildung 5 konsistent.
Implementierung mit der PyTorch-API
Wie aus Abbildung 5 ersichtlich, besteht PipeTransformer aus vier Komponenten: Freeze Algorithm, AutoPipe, AutoDP und AutoCache.
Unter diesen sind AutoPipe und AutoDP jeweils von PyTorch DDP (torch.nn.parallel.DistributedDataParallel) und Pipeline (torch.distributed.pipeline) abhängig.
In diesem Blog heben wir nur die wichtigsten Implementierungsdetails von AutoPipe und AutoDP hervor. Weitere Informationen zum Einfrieralgorithmus und zu AutoCache finden Sie im Dokument.
AutoPipe: Flexible Pipeline
AutoPipe kann das Training beschleunigen, indem eingefrorene Ebenen aus der Pipeline ausgeschlossen und aktive Ebenen auf weniger GPUs komprimiert werden.In diesem Abschnitt werden die Hauptkomponenten von AutoPipe detailliert beschrieben:
1) Dynamische Partitionspipeline;
2) Reduzierung der Anzahl der Rohrleitungsausrüstung;
3) Optimieren Sie die Mini-Batch-Blockgröße entsprechend
Grundlegende Verwendung der PyTorch-Pipeline
Bevor wir uns mit den Details von AutoPipe befassen, machen wir uns zunächst mit der grundlegenden Verwendung der PyTorch Pipeline (torch.distributed.pipeline.sync.Pipe) vertraut:
Um das Pipeline-Design in Aktion zu verstehen, betrachten Sie das folgende einfache Beispiel:
# Step 1: build a model including two linear layers
fc1 = nn.Linear(16, 8).cuda(0)
fc2 = nn.Linear(8, 4).cuda(1)
# Step 2: wrap the two layers with nn.Sequential
model = nn.Sequential(fc1, fc2)
# Step 3: build Pipe (torch.distributed.pipeline.sync.Pipe)
model = Pipe(model, chunks=8)
# do training/inference
input = torch.rand(16, 16).cuda(0)
output_rref = model(input)In diesem einfachen Beispiel können Sie sehen, dass Sie vor der Initialisierung von Pipe das nn.Sequential-Modell in mehrere GPU-Geräte partitionieren und die optimale Anzahl von Chunks festlegen müssen.
Das Ausbalancieren der Berechnungen über Partitionen hinweg ist für die Trainingsgeschwindigkeit der Pipeline von entscheidender Bedeutung, da eine ungleichmäßige Verteilung der Arbeitslast über die Phasen zu Verzögerungen führen kann und Geräte mit weniger Aufgaben zum Warten gezwungen werden. Auch die Anzahl der Chunks kann einen erheblichen Einfluss auf den Durchsatz der Pipeline haben.
Ausgleichen von Pipeline-Partitionen
In dynamischen Trainingssystemen wie PipeTransformer garantiert die bloße Tatsache, dass in jeder Partition die gleiche Anzahl Parameter vorhanden ist, nicht die schnellste Trainingsgeschwindigkeit. Darüber hinaus spielen auch andere Faktoren eine wichtige Rolle:
Abbildung 6: Die Partitionsgrenze befindet sich in der Mitte der Sprungverbindung
1. Kommunikations-Overhead zwischen Partitionen. Das Platzieren der Partitionsgrenze in der Mitte einer Sprungverbindung führt zu zusätzlicher Kommunikation, da Tensoren in der Sprungverbindung dann auf verschiedene GPUs kopiert werden müssen.
Beispielsweise muss Partition k für die BERT-Partitionen in Abbildung 6 Zwischenausgaben von Partition k-2 und Partition k-1 erhalten. Wenn die Grenze dagegen nach der Additionsschicht platziert wird, wird der Kommunikationsaufwand zwischen Partition k-1 und Partition k erheblich geringer.
Messungen zeigen, dass die geräteübergreifende Kommunikation teurer ist als leicht unausgeglichene Partitionen. Daher ziehen wir das Unterbrechen von Skip-Verbindungen nicht in Betracht.
2. Speichernutzung der Ebene einfrieren. Während des Trainings muss AutoPipe die Partitionsgrenzen mehrmals neu berechnen, um zwei verschiedene Arten von Ebenen auszugleichen: eingefrorene Ebenen und aktive Ebenen.
Da für eingefrorene Ebenen keine Rückwärtsaktivierungskarten, Optimiererzustände und Gradienten erforderlich sind, beträgt der Speicheraufwand für eingefrorene Ebenen nur einen Bruchteil des Speicheraufwands für inaktive Ebenen.
Anstatt einen aufdringlichen Profiler zu starten, um die zugrunde liegenden Messdaten für Speicher- und Rechenkosten zu erhalten, definieren wir einen anpassbaren Kostenfaktor „lambdafrozen“, um die Speichernutzung einer eingefrorenen Ebene im Verhältnis zur gleichen aktiven Ebene zu bewerten. Basierend auf empirischen Messungen an experimenteller Hardware haben wir es auf 1/6 eingestellt.
Basierend auf den beiden oben genannten Punkten kann AutoPipe Pipeline-Partitionen entsprechend der Parametergrößen ausgleichen.Insbesondere verwendet AutoPipe einen Greedy-Algorithmus, um eingefrorene und aktive Ebenen zuzuweisen, sodass die Unterebenen des Bewertungsbereichs gleichmäßig auf K GPU-Geräte verteilt werden können.
Pseudocode ist die Funktion load_balance() in Algorithmus 1. Die eingefrorenen Ebenen werden aus dem Originalmodell extrahiert und in einer separaten Modellinstanz Ffrozen im ersten Gerät der Pipeline gespeichert.
Beachten Sie, dass der in diesem Artikel verwendete Segmentierungsalgorithmus nicht die einzige Option ist.PipeTransformer ist modular und kann in Verbindung mit allen Alternativen ausgeführt werden.
Pipeline-Komprimierung
Durch die Pipeline-Komprimierung wird die GPU frei, sodass mehr Pipeline-Kopien möglich sind, und die geräteübergreifende Kommunikation zwischen Partitionen wird reduziert. Um zu bestimmen, wie lange die Komprimierung dauert, können wir den Speicherverbrauch der größten Partition nach der Komprimierung schätzen und ihn dann mit dem Speicherverbrauch der größten Partition der Pipeline zum Zeitpunkt T=0 vergleichen.
Um eine umfangreiche Speicherprofilierung zu vermeiden, verwendet der Komprimierungsalgorithmus die Parametergröße als Proxy für die Trainingsspeichernutzung. Basierend auf dieser Vereinfachung lauten die Richtlinien für die Pipeline-Komprimierung wie folgt: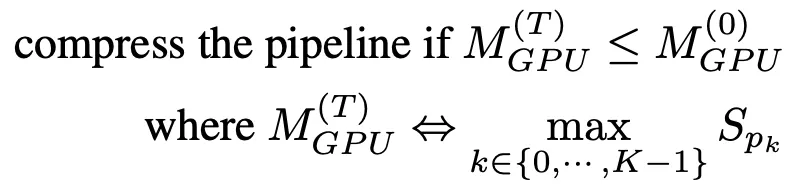
Sobald eine Einfrierbenachrichtigung eingeht, versucht AutoPipe, die Rohrlänge K durch 2 zu teilen (z. B. von 8 auf 4, dann auf 2). Durch Eingabe von K/2 kann der Komprimierungsalgorithmus überprüfen, ob das Komprimierungsergebnis die Kriterien in Formel (1) erfüllt.
Der Pseudocode wird in den Zeilen 25–33 von Algorithmus 1 angezeigt. Beachten Sie, dass diese Komprimierung die Beschleunigung während des Trainings exponentiell ansteigen lässt. Dies bedeutet, dass die Beschleunigung weiter zunimmt, wenn ein GPU-Server mehr GPUs enthält (z. B. mehr als 8). Abbildung 7: Pipeline-Blase
Abbildung 7: Pipeline-Blase
Fd, b und Ud stellen die Vorwärts-, Rückwärts- und Optimierer-Updates von Micro=Batch b auf Gerät d dar.
Die Gesamtblasengröße in jeder Iteration beträgt K-1 mal die Vorwärts- und Rückwärtskosten pro Mikrobatch.
Darüber hinaus kann diese Technik auch das Training beschleunigen, indem die Größe der Pipeline-Blase reduziert wird. Um die Blasengröße in der Pipeline zu erklären, zeigt Abbildung 7, wie 4 Mikrobatches mit K=4 durch 4 Gerätepipelines laufen.
Im Allgemeinen beträgt die Gesamtblasengröße das K-1-fache der Vorwärts- und Rückwärtskosten jedes Mikrobatches. Daher ist es offensichtlich, dass kürzere Rohrleitungen kleinere Blasengrößen aufweisen.
Dynamische Anzahl von Mikro-Batches
Frühere Pipeline-Parallelsysteme verwendeten eine feste Anzahl von Mikro-Batches pro Mini-Batch (M). GPipe empfiehlt M ≥ 4 x K, wobei K die Anzahl der Partitionen (Pipelinelänge) ist. Da PipeTransformer K jedoch dynamisch konfiguriert, haben wir festgestellt, dass es nicht gut funktioniert, M während des Trainings statisch zu halten.
Darüber hinaus wirkt sich der Wert von M bei Integration mit DDP auch auf die Effizienz der DDP-Gradientensynchronisierung aus. Da DDP warten muss, bis der letzte Mikrobatch die Rückwärtsberechnung eines Parameters abgeschlossen hat, bevor die Gradientensynchronisierung erfolgen kann, ist die Überschneidung von Berechnung und Kommunikation umso geringer, je feiner der Mikrobatch ist.
Anstatt einen statischen Wert zu verwenden, sucht PipeTransformer daher dynamisch nach dem optimalen Wert von M im Hybrid der DDP-Umgebung, indem es die Werte von M im Bereich von K-6K aufzählt. Für eine bestimmte Trainingsumgebung muss die Profilerstellung nur einmal durchgeführt werden (siehe Zeile 35 von Algorithmus 1).
Den vollständigen Quellcode finden Sie unter
AUTODP: Weitere Pipeline-Kopien generieren
Da AutoPipe dieselbe Pipeline auf weniger GPUs komprimieren kann, kann AutoDP automatisch neue Pipeline-Kopien generieren, um die Breite der Datenparallelität zu erhöhen.
Obwohl das Konzept einfach ist, ist die Abhängigkeit von Kommunikation und Status subtil und erfordert eine sorgfältige Planung.Es gibt drei potenzielle Hauptherausforderungen:
1. DDP-Kommunikation: Die kollektive Kommunikation in PyTorch DDP erfordert eine statische Mitgliedschaft, die verhindert, dass neue Pipelines eine Verbindung zu bestehenden herstellen.
2. Statussynchronisierung: Der neu aktivierte Prozess muss hinsichtlich der Trainingsverfahren (wie Anzahl der Epochen und Lernrate), der Gewichtung und der Optimiererzustände, der Grenzen eingefrorener Schichten und des GPU-Bereichs der Pipeline mit der vorhandenen Pipeline übereinstimmen.
3. Neuverteilung des Datensatzes: Der Datensatz sollte neu ausbalanciert werden, um der dynamischen Anzahl von Pipelines zu entsprechen. Dadurch werden nicht nur Nachzügler vermieden, sondern es wird auch sichergestellt, dass die Gradienten aller DDP-Prozesse gleich gewichtet sind.
Abbildung 8: AutoDP: Dynamische Datenparallelität mit Informationen zwischen zwei Prozessgruppen
Hinweis: Die Prozesse 0-7 gehören zur Maschine 0, die Prozesse 8-15 gehören zur Maschine 1
Um diese Herausforderungen zu bewältigen, haben wir duale Kommunikationsprozessgruppen für DDP erstellt. Wie in Abbildung 8 dargestellt, ist die Informationsprozessgruppe (lila) für leichtgewichtige Steuerinformationen verantwortlich und deckt alle Prozesse ab, während die aktive Trainingsprozessgruppe (gelb) nur aktive Prozesse enthält und während des Trainings als Werkzeug für die schwergewichtige Tensorkommunikation fungiert.
Der Informationssatz ist statisch, während der Trainingssatz aufgeteilt und entsprechend dem Aktivitätsprozess neu konstruiert wird. Zu T0 sind nur die Prozesse 0 und 8 aktiv. Während des Übergangs zu T1 aktiviert Prozess 0 die Prozesse 1 und 9 (die neu hinzugefügten Pipeline-Kopien) und synchronisiert die oben genannten erforderlichen Informationen mithilfe von Nachrichtengruppen.
Die vier aktiven Prozesse bilden dann eine neue Trainingsgruppe und passen die statische kollektive Kommunikation an die dynamische Mitgliedschaft an. Um den Datensatz neu zu verteilen, haben wir eine DistributedSampler-Variante implementiert, die die Datenstichprobe nahtlos an die Anzahl der aktiven Pipeline-Replikate anpasst.
Das obige Design trägt dazu bei, den Kommunikationsverlust von DDP zu reduzieren. Genauer gesagt können die Prozesse 0 und 1 beim Übergang von T0 zu T1 die vorhandene DDP-Instanz zerstören und der aktive Prozess erstellt mithilfe des zwischengespeicherten Pipeline-Modells eine neue DDP-Trainingsgruppe (AutoPipe speichert das eingefrorene Modell und das zwischengespeicherte Modell separat).
Um die oben genannten Vorgänge durchzuführen, haben wir die folgenden APIs verwendet:
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# initialize the process group (this must be called in the initialization of PyTorch DDP)
dist.init_process_group(init_method='tcp://' + str(self.config.master_addr) + ':' +
str(self.config.master_port), backend=Backend.GLOO, rank=self.global_rank, world_size=self.world_size)
...
# create active process group (yellow color)
self.active_process_group = dist.new_group(ranks=self.active_ranks, backend=Backend.NCCL, timeout=timedelta(days=365))
...
# create message process group (yellow color)
self.comm_broadcast_group = dist.new_group(ranks=[i for i in range(self.world_size)], backend=Backend.GLOO, timeout=timedelta(days=365))
...
# create DDP-enabled model when the number of data-parallel workers is changed. Note:
# 1. The process group to be used for distributed data all-reduction.
If None, the default process group, which is created by torch.distributed.init_process_group, will be used.
In our case, we set it as self.active_process_group
# 2. device_ids should be set when the pipeline length = 1 (the model resides on a single CUDA device).
self.pipe_len = gpu_num_per_process
if gpu_num_per_process > 1:
model = DDP(model, process_group=self.active_process_group, find_unused_parameters=True)
else:
model = DDP(model, device_ids=[self.local_rank], process_group=self.active_process_group, find_unused_parameters=True)
# to broadcast message among processes, we use dist.broadcast_object_list
def dist_broadcast(object_list, src, group):
"""Broadcasts a given object to all parties."""
dist.broadcast_object_list(object_list, src, group=group)
return object_listExperimenteller Teil
In diesem Abschnitt wird zunächst der Versuchsaufbau zusammengefasst und anschließend die Leistung von PipeTransformer bei Computer Vision- und natürlicher Sprachverarbeitungsaufgaben bewertet.
Hardware. Die Experimente wurden auf zwei identischen Maschinen durchgeführt, die über InfiniBand CX353A (GB/s) verbunden waren und jeweils mit 8 NVIDIA Quadro RTX 5000 (16 GB GPU-Speicher) ausgestattet waren. Die GPU-zu-GPU-Bandbreite innerhalb der Maschine (PCI 3.0, 16 Lanes) beträgt 15,754 GB/s.
erreichen. Wir verwenden PyTorch Pipe als Baustein. Die Definition, Konfiguration und zugehörigen Tokenisierer des BERT-Modells stammen alle von HuggingFace 3.5.0. Wir haben den Vision Transformer mit TensorFlow in PyTorch implementiert.
Modelle und Datensätze. Im Experiment wurden zwei repräsentative Transformer-Modelle aus den Bereichen CV und NLP verwendet: Vision Transformer (ViT) und BERT. ViT wird auf die Bildklassifizierungsaufgabe angewendet, mit auf ImageNet21K vortrainierten Gewichten initialisiert und auf ImageNet und CIFAR-100 feinabgestimmt. BERT führt zwei Aufgaben aus: Textklassifizierung auf dem SST-2-Datensatz aus dem General Language Understanding Evaluation (GLUE)-Benchmark und intelligente Fragebeantwortung auf dem SQuAD v1.1-Datensatz (Stanford Question Answering). Der SQuAD v1.1-Datensatz besteht aus 100.000 Crowdsourcing-Frage-Antwort-Paaren.
Trainingsplan. Große Modelle erfordern typischerweise Tausende von GPU-Tagen (z. B. GPT-3), wenn sie von Grund auf trainiert werden. Daher ist die Feinabstimmung nachgelagerter Aufgaben mit vortrainierten Modellen zu einem Trend in den Bereichen CV und NLP geworden. Darüber hinaus ist PipeTransformer ein komplexes Trainingssystem mit mehreren Kernkomponenten. Daher ist es für die Systementwicklung und Algorithmusforschung der ersten Version von PipeTransformer nicht kosteneffizient, diese von Grund auf neu zu entwickeln und zu evaluieren und dafür ein umfangreiches Vortraining durchzuführen. Daher konzentrieren sich die in diesem Abschnitt vorgestellten Experimente auf vortrainierte Modelle. Beachten Sie, dass PipeTransformer beide Anforderungen erfüllen kann, da die Modellarchitektur beim Vortraining und bei der Feinabstimmung dieselbe ist. Wir besprechen die Ergebnisse vor dem Training im Anhang.
Grundlinie. Die Experimente in diesem Abschnitt vergleichen PipeTransformer mit den hochmodernen Frameworks PyTorch Pipeline (PyTorch-Implementierung GPipe) und PyTorch DDP. Da dies die erste Arbeit ist, die sich mit dem Einfrieren von Schichten zur Beschleunigung des verteilten Trainings befasst, gibt es noch keine vollständig konsistente entsprechende Lösung.
Hyperparameter. Für die ImageNet- und CIFAR-100-Datensätze wurde in den Experimenten ViT-B/16 (12 Transformer-Ebenen und 16x16 Eingabepatchgröße) verwendet. Für SQuAD 1.1 wird in den Experimenten BERT-large-uncased (24 Schichten) verwendet. SST-2 verwendet BERT-base-uncased (12 Schichten). Mit PipeTransformer-, ViT- und BERT-Training kann die Batchgröße pro Pipeline auf etwa 400 bzw. 64 eingestellt werden. Weitere Hyperparameter (wie Epoche, Lernrate usw.) finden Sie im Anhang.
Gesamtbeschleunigungstraining
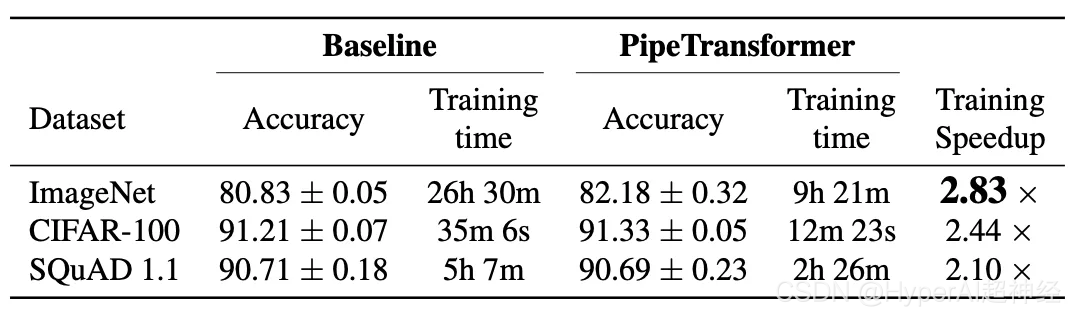
Die obige Tabelle fasst die gesamten Versuchsergebnisse zusammen. Beachten Sie, dass die Beschleunigung hier auf einem konservativen Wert basiert a(1/3) kann dieser Wert eine ähnliche oder sogar höhere Genauigkeit erreichen. Wenn der Wert a(2/5,1/2) kann eine höhere Beschleunigung erreichen, allerdings mit einem leichten Verlust an Genauigkeit. Darüber hinaus ist BERT (24 Schichten) größer als ViT-B/16 (12 Schichten) und erfordert daher mehr Kommunikationszeit.
Leistungsanalyse
Beschleunigungsaufschlüsselung
In diesem Abschnitt werden die Auswertungsergebnisse präsentiert und die Leistung verschiedener Komponenten in /AutoPipe analysiert.
Um die Wirksamkeit dieser vier Komponenten und ihre Auswirkungen auf die Trainingsgeschwindigkeit zu verstehen, haben wir Experimente mit verschiedenen Kombinationen durchgeführt und ihren Trainingsbeispieldurchsatz (Beispiele/Sekunde) und ihre Beschleunigung als Messgrößen verwendet. Die Ergebnisse sind in Abbildung 9 dargestellt.Zu den wichtigsten Erkenntnissen aus den Versuchsergebnissen zählen:
1. Die Hauptbeschleunigung ist das Ergebnis der elastischen Pipeline, die von AutoPipe und AutoDP implementiert wird.
2. Die Wirkung von AutoCache wird durch AutoDP verstärkt;
3. Das Freeze-Training wird unabhängig durchgeführt, ohne dass es zu Systemanpassungen oder Trainingsverlangsamungen kommt.
Passen Sie a im Einfrieralgorithmus an

Abbildung 10: Anpassen von a im Einfrieralgorithmus
Wir haben einige Experimente durchgeführt, um zu veranschaulichen, wie sich das Einfrieren des Algorithmus auf die Trainingsgeschwindigkeit auswirkt. Die Ergebnisse zeigen, dass die Beschleunigung umso größer ist, je größer das a (übermäßige Einfrieren) ist, es jedoch zu einer leichten Leistungsverschlechterung kommt. Im Beispiel in Abbildung 10 ist bei a = 1/5 die Leistung des Frozen-Trainings besser als die des normalen Trainings, mit einem Beschleunigungsverhältnis von 2,04.
Optimale Anzahl von Chunks in einer elastischen Pipeline

Abbildung 11: Optimale Anzahl von Chunks in einer elastischen Pipeline
Wir analysieren die optimale Mikrobatch-Anzahl M für unterschiedliche Pipeline-Längen K. Die Ergebnisse sind in Abbildung 11 dargestellt. Wie wir sehen können, ändert sich die optimale Zahl M entsprechend mit unterschiedlichen Werten von K. Wenn M unterschiedlich ist, wird die Durchsatzlücke größer (wie in der Abbildung bei K=8 gezeigt), was auch die Notwendigkeit der Verwendung eines Anterior-Profilers in elastischen Pipelines bestätigt.
Cache-Timing verstehen

Abbildung 12: Cache-Timing
Um AutoCache zu bewerten, haben wir den Beispieldurchsatz von Trainingsjobs ab Epoche 0 mit AutoCache (blaue Linie) und ohne AutoCache (rote Linie) verglichen.
Abbildung 12 zeigt, dass eine zu frühe Aktivierung des Caching das Training verlangsamen kann, da dies teurer ist als die Vorwärtsausbreitung über eine kleinere Anzahl eingefrorener Schichten. Nach dem Einfrieren mehrerer Ebenen ist die Leistung der zwischengespeicherten Aktivierungen deutlich besser als beim entsprechenden Vorwärtsdurchlauf. Daher verwendet AutoCache einen Profiler, um den richtigen Zeitpunkt zum Aktivieren des Caching zu bestimmen.
In unserem System beginnt das Caching für ViT (12 Schichten) ab der 3. eingefrorenen Schicht; Bei BERT (24 Schichten) beginnt das Caching ab der 5. eingefrorenen Schicht.
Zusammenfassen
In diesem Dokument wird PipeTransformer vorgestellt, eine ganzheitliche Lösung, die elastische Pipeline-Parallelität und Datenparallelität für verteiltes Training mithilfe der verteilten PyTorch-API kombiniert.
Insbesondere kann PipeTransformer Schichten in der Pipeline schrittweise einfrieren, die verbleibenden aktiven Schichten auf weniger GPUs packen und mehr Pipeline-Kopien erstellen, um die parallele Datenbreite zu erhöhen. Die Auswertung anhand von ViT- und BERT-Modellen zeigt, dass PipeTransformer im Vergleich zur aktuellen Basislinie eine 2,83-fache Beschleunigung erreicht, ohne dass es zu Genauigkeitsverlusten kommt.








